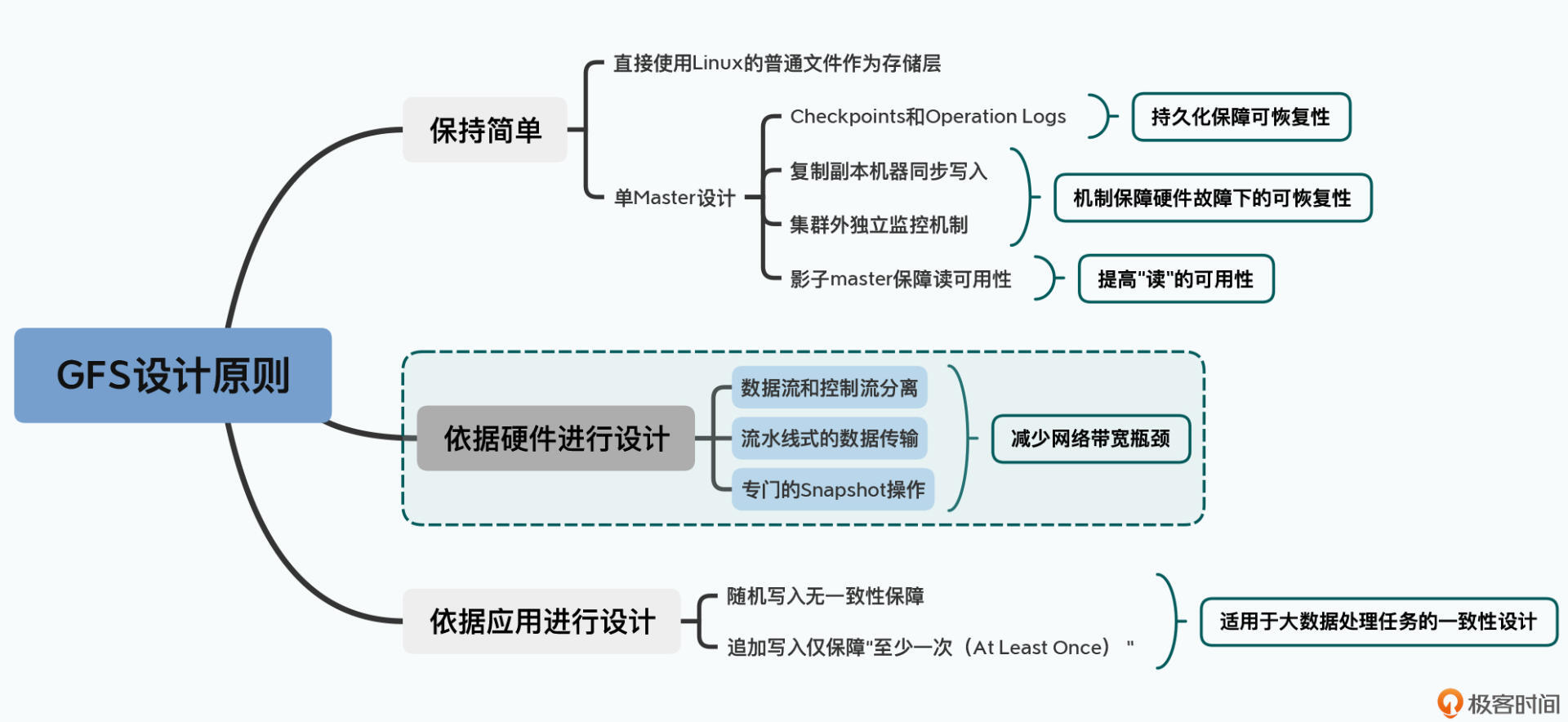
04 The Google File System (二): 如何应对网络瓶颈?
你好,我是徐文浩。今天这一讲,我们接着来学习GFS论文中第二个重要的设计决策,也就是根据实际的硬件情况来进行系统设计。
大数据系统本就是为“性能”而生的,因为单台服务器已经满足不了我们的性能需要。所以我们需要通过搭建成百上千台服务器,组成一个大数据集群。然而,上千台服务器的集群一样有来自各种硬件性能的限制。
在单台服务器下,我们的硬件瓶颈常常是硬盘。而到了一个分布式集群里,我们又有了一个新的瓶颈,那就是网络。
那么在这一讲里,我们就来看看网络层面的硬件瓶颈,是如何影响了GFS的设计的。在学完这一讲之后,希望你能够理解,任何一个系统设计,都需要考虑硬件性能。并且学会在对自己的设计进行评估的时候,能够寻找到系统的硬件瓶颈在哪里。
GFS的硬件配置
不知道你有没有想过,2003年的GFS是跑在什么样的硬件服务器上的呢?论文的第6部分还真的透露了一些信息给我们。Google拿来做微基准测试(Micro-Benchmark)的服务器集群的配置是这样的:
- 19台服务器、1台master、2台master的只读副本、16台chunkserver,以及另外16台GFS的客户端;
- 所有服务器的硬件配置完全相同,都是双核1.45 GHz的奔腾3处理器 + 2GB内存 + 两块80GB的5400rpm的机械硬盘 + 100 Mbps的全双工网卡。
- 然后把所有的19台GFS集群的机器放在一台交换机上,所有的16台GFS的客户端放在另外一台交换机上,两台交换机之间通过带宽是1Gbps的网线连接起来。
而Google跑在内部实际使用的真实集群,虽然论文里没有给出具体的硬件配置,但我们也可以反向推算一下。论文第6部分有一个Table 2,里面有A和B两个集群。根据表格里面的数据可以计算得出,里面的A集群平均每台chunkserver大约有200GB的硬盘,每台chunkserver需要的Metadata(元数据)大约是38MB。而里面的B集群则是800GB的硬盘,以及93MB的Metadata。这样看起来,除了可以多插几块硬盘增加一些存储空间之外,前面测试集群的硬件配置完全够用了。

在这个硬件配置中,5400转(rpm)的硬盘,读写数据的吞吐量通常是在60MB/s~90MB/s左右。而且我们通常会插入多块硬盘,比如集群B,就需要10块80GB的硬盘,这样就意味着整体硬盘的吞吐量可以达到500MB/s以上。但是,100Mbps的网卡的极限吞吐率只有12.5MB/s,这个也就意味着,当我们从GFS读写数据的时候,瓶颈就在网络上。
那么下面,我们就来看一看针对这样的硬件瓶颈,GFS都做了哪些针对性的设计。
GFS的数据写入
我们先来看看一个客户端是怎么向GFS集群里面写数据的。在上一讲里,我带你了解了一个GFS客户端怎么从集群里读取数据。相信你学完之后会觉得特别简单,感觉也就是个几千行代码的事儿。不过,写文件可就没有那么简单了。
实际上,读数据简单,是因为不管我们有多少个客户端并发去读一个文件,读到的内容都不会有区别,即使它们读同一个chunk是分布在不同chunkserver。我们不是靠在读取中做什么特殊的动作,来保障客户端读到的数据都一样。“保障读到的数据一样”这件事情,其实是在数据写入的过程中来保障的。
写入和读取不同的是,读取只需要读一个chunkserver,最坏的情况无非是读不到重试。而写入,则是同时要写三份副本,如果一个写失败,两个写成功了,数据就已经不一致了。
那么,GFS是怎么解决这样的问题的呢?下面我就带你来看一下,GFS写入数据的具体步骤。
- 第一步,客户端会去问master要写入的数据,应该在哪些chunkserver上。
- 第二步,和读数据一样,master会告诉客户端所有的次副本(secondary replica)所在的chunkserver。这还不够,master还会告诉客户端哪个replica是“老大”,也就是主副本(primary replica),数据此时以它为准。
- 第三步,拿到数据应该写到哪些chunkserver里之后,客户端会把要写的数据发给所有的replica。不过此时,chunkserver拿到发过来的数据后还不会真的写下来,只会把数据放在一个LRU的缓冲区里。
- 第四步,等到所有次副本都接收完数据后,客户端就会发送一个写请求给到主副本。我在上节课一开始就说过,GFS面对的是几百个并发的客户端,所以主副本可能会收到很多个客户端的写入请求。主副本自己会给这些请求排一个顺序,确保所有的数据写入是有一个固定顺序的。接下来,主副本就开始按照这个顺序,把刚才LRU的缓冲区里的数据写到实际的chunk里去。
- 第五步,主副本会把对应的写请求转发给所有的次副本,所有次副本会和主副本以同样的数据写入顺序,把数据写入到硬盘上。
- 第六步,次副本的数据写入完成之后,会回复主副本,我也把数据和你一样写完了。
- 第七步,主副本再去告诉客户端,这个数据写入成功了。而如果在任何一个副本写入数据的过程中出错了,这个出错都会告诉客户端,也就意味着这次写入其实失败了。
所以在GFS的数据写入过程中,可能会出现主副本写入成功,但是次副本写入出错的情况。在这种情况下,客户端会认为写入失败了。但是这个时候,同一个chunk在不同chunkserver上的数据可能会出现不一致的情况,这个问题我们会放到下一讲来深入讨论。

我在这里也放了一张图,来帮助你理解这个数据写入的流程。从这张图上你会发现,GFS的数据写入使用了两个很有意思的模式,来解决这节课一开始我提到的网络带宽的瓶颈问题。
分离控制流和数据流
第一个模式是控制流和数据流的分离。
和之前从GFS上读数据一样,GFS客户端只从master拿到了chunk data在哪个chunkserver的元数据,实际的数据读写都不再需要通过master。另外,不仅具体的数据传输不经过master,后续的数据在多个chunkserver上同时写入的协调工作,也不需要经过master。
这也就是说,控制流和数据流的分离,不仅仅是数据写入不需要通过master,更重要的是实际的数据传输过程,和提供写入指令的动作是完全分离的。
其次,是采用了流水线(pipeline)式的网络传输。数据不一定是先给到主副本,而是看网络上离哪个chunkserver近,就给哪个chunkserver,数据会先在chunkserver的缓冲区里存起来,就是前面提到的第3步。但是写入操作的指令,也就是上面的第4~7步,则都是由客户端发送给主副本,再由主副本统一协调写入顺序、拿到操作结果,再给到客户端的。
流水线式的网络数据传输
之所以要这么做,还是因为GFS最大的瓶颈就在网络。如果用一个最直观的想法来进行数据传输,我们可以把所有数据直接都从客户端发给三个chunkserver。
但是这种方法的问题在于,客户端的出口网络会立刻成为瓶颈。
比如,我们要发送1GB的数据给GFS,客户端的出口网络带宽有100MB/秒,那么我们只需要10秒就能把数据发送完。但是因为三个chunkserver的数据都要从客户端发出,所以要30s才能把所有的数据都发送完,而且这个时候,三个chunkserver的网络带宽都没有用满,各自只用了1/3,网络并没有被有效地利用起来。
而在流水线式的传输方式下,客户端可以先把所有数据,传输给到网络里离自己最近的次副本A,然后次副本A一边接收数据,一边把对应的数据传输给到离自己最近的另一个副本,也就是主副本。
同样的,主副本可以如法炮制,把数据也同时传输给次副本B。在这样的流水线式的数据传输方式下,只要网络上没有拥堵的情况,只需要10秒多一点点,就可以把所有的数据从客户端,传输到三个副本所在的chunkserver上。

不过到这里你可能要问了:为什么客户端传输数据,是先给离自己最近的次副本A,而不是先给主副本呢?
这个问题,也和数据中心的实际网络结构有关,你可以先看看下面这张数据中心的网络拓扑图。

要知道,我们几百台服务器所在的数据中心,一般都是通过三层交换机连通起来的:
- 同一个机架(Rack)上的服务器,都会接入到一台接入层交换机(Access Switch)上;
- 各个机架上的接入层交换机,都会连接到某一台汇聚层交换机(Aggregation Switch)上;
- 而汇聚层交换机,再会连接到多台核心交换机(Core Switch)上。
那么根据这个网络拓扑图,你会发现,两台服务器如果在同一个机架上,它们之间的网络传输只需要通过接入层的交换机即可。在这种情况下,除了两台服务器本身的网络带宽之外,它们只会占用所在的接入层交换机的带宽。
但是,如果两台服务器不在一个机架,乃至不在一个VLAN的情况下,数据传输就要通过汇聚层交换机,甚至是核心交换机了。而如果大量的数据传输,都是在多个不同的VLAN之间进行的,那么汇聚层交换机乃至核心交换机的带宽,就会成为瓶颈。
所以我们再回到之前的链式传输的场景,GFS最大利用网络带宽,同时又减少网络瓶颈的选择就是这样的:
- 首先,客户端把数据传输给离自己“最近”的,也就是在同一个机架上的次副本A服务器;
- 然后,次副本A服务器再把数据传输给离自己“最近”的,在不同机架,但是处于同一个汇聚层交换机下的主副本服务器上;
- 最后,主副本服务器,再把数据传输给在另一个汇聚层交换机下的次副本B服务器。
这样的传输顺序,就最大化地利用了每台服务器的带宽,并且减少了交换机的带宽瓶颈。而如果我们非要先把数据从客户端传输给主副本,再从主副本传输到次副本A,那么同样的数据就需要多通过汇聚层交换机一次,从而就占用了更多的汇聚层交换机的资源。
独特的Snapshot操作
那么,在做了分离控制流和数据流,以及使用流水线式的数据传输方式之后,对于GFS的网络传输上,还有什么其他的优化空间吗?
你别说还真的有,那就是为常见的文件复制操作单独设计一个指令。
复制文件,相信这个是你用自己的电脑的时候,会常常做的事儿。在GFS上,如果我们用笨一点的办法,自然是通过客户端把文件从chunkserver读回来,再通过客户端把数据写回去。这样的话,读数据也经过一次网络传输,写回三个副本服务器,即使是流水线式的传输,也要三次传输,一共需要把数据在网络上搬运四次。
所以,GFS就专门为文件复制设计了一个Snapshot指令,当客户端通过这个指令进行文件复制的时候,这个指令会通过控制流,下达到主副本服务器,主副本服务器再把这个指令下达到次副本服务器。不过接下来,客户端并不需要去读取或者写入数据,而是各个chunkserver会直接在本地把对应的chunk复制一份。
这样,数据流就完全不需要通过网络传输了。相信这个聪明的方法你也一定想到了。
小结
好了,通过这节课的学习,现在你对GFS是如何写入数据和复制文件应该就已经非常清楚了。那么,这里我们一起来回顾一下吧。
这节课,我先带你看了一下GFS的分布式集群的硬件配置,你会发现2003年GFS的最大的硬件瓶颈就是在网络。于是,在GFS设计数据写入机制的时候,就是经过仔细分析后针对这个问题来设计的。你可以重点关注以下这三个要点。
第一,和读数据一样,GFS采用了控制流和数据流分离的方式。在写入数据的时候,客户端只是从master拿到chunk所在位置的元数据,而在实际的数据传输过程中,并不需要master参与,从而就避免了master成为瓶颈。
第二,在客户端向多个chunkserver写入数据的时候,采用了“就近”的流水线式传输的方案。这种方式,就尽可能有效地利用了客户端、chunkserver乃至于交换机的带宽。
第三,对于常见的文件复制这个操作,GFS专门设计了一个Snapshot的指令,针对文件复制,会直接在chunkserver本地进行,完全避免了网络传输。
其实,这三个动作,都不是什么理论上的创新,而是完全针对当时数据中心的网络架构、服务器硬件规格所进行的设计。也就是说,基于硬件设计,实际上不只是GFS的一个非常重要的核心设计思想,它更是贯穿整个大数据系统领域的一个重要的主题。
推荐阅读
学完了这一讲之后,如果你对数据中心的网络架构有了一些设计思路,可以再去读一读Facebook工程团队在2014年写的这篇文章:Introducing data center fabric, the next-generation Facebook data center network。
而如果你觉得自己对于计算机的各类硬件性能不熟悉,我推荐你回头看一看我之前的《深入浅出计算机组成原理》的专栏,特别是其中关于存储器的部分。我们在后面的论文解读中,还会不断根据各种硬件特性和性能来思考我们的设计。
回头看起来,在“大数据”爆发之前,数据中心的数据流量通常是“南北大,东西小”,也就是大部分数据都是从某一台服务器,经过几层交换机,进入互联网,返回给终端用户。而在“大数据”爆发之后,数据中心的大量数据传输变成了数据中心的服务器横向之间的传输,而这个也让工程师们开始重新基于需求,重新设计数据中心需要的硬件和网络拓扑。那么,在学完今天这节课之后,我想你一定会对基于硬件性能设计系统,有更多的思考。
思考题
最后我想说,学习论文并不是背诵,重要是得总结和思考。所以我给你留了一道思考题,欢迎你和其他同学一起讨论一下。
在你接触过的系统和代码中,有没有什么设计,也是深度考虑了实际的硬件性能和瓶颈的呢?你可以留言说说,我们共同交流、互相进步。
- 峰 👍(24) 💬(1)
mysql利用b+出度打,层级底的特性,尽可能减少一次查询中随机io开销。 kafka利用磁盘顺序写入较随机写入快的特性,批量顺序写文件。 redis ignite 等内存数据库都基于内存性能远胜于磁盘等持久化外部存储,从而基于内存做存储系统。
2021-09-27 - Ping 👍(9) 💬(2)
能再解释下“南北大,东西小”是什么意思吗?
2021-09-27 - webmin 👍(8) 💬(1)
今天课程中关于网络优化的内容,基本是出自GFS论文中的3.2节Data Flow,我很好奇是因为老师有关于广告系统的开发经验,所以能从一个300个单词左右的小节中看出这么丰富的信息,还是老师有其它的分析框架或辨识方法?还望老师抽时间传授。 另加一个注解流水线(pipeline)式的网络传输是有效利用了网络是全双工的原理,即左手进右手出,左右各100Mb。
2021-09-27 - 陈迪 👍(7) 💬(1)
思考一个问题,20年过去了,硬件环境已经哪些发生了根本性的变化?现代的分布式文件系统应该什么样的?
2021-09-28 - 在路上 👍(2) 💬(1)
徐老师好,GFS论文3.2 Data Flow中提到“Without networkcongestion, the ideal elapsed time for transferring B bytes to R replicas is B/T + RL where T is the network throughput and L is latency to transfer bytes between two machines. Our network links are typically 100 Mbps (T), and L is far below 1 ms. Therefore, 1 MB can ideally be distributed in about 80 ms.” 我不明白的是RL部分的计算,为什么L<1ms,L的大小和要传输的数据大小无关吗?为什么不是B/T1 + R*B/T2,T1表示客户端到GFS的网速,T2表示GFS集群内的网速?希望能得到老师的指点。
2021-09-27 - leslie 👍(1) 💬(1)
UDP替代TCP去实现网络的传输,传完了就好了;监控而已-丢失了再传即可;不过当时忽略了一个关键问题-windows并不适合去用很多适合在linux下的软件,导致了备份和恢复的灾难性隐患。
2021-09-30 - Geek_2e6a7e 👍(1) 💬(2)
阿里自研MaxCompute大规模集群计算有什么特别创新的地方么,这块有相关资料或者论文参考下么?
2021-09-28 - zhanyd 👍(1) 💬(1)
适合自己的就是最好的,不一定要去追求什么高大上的技术,能够低成本满足需求的就是好方案。创新不一定是要创造出什么新东西, 把一些东西按适当的方式组合在一起也是创新。
2021-09-28 - 核桃 👍(8) 💬(0)
这里其实是隐藏了一个功能,就是GFS能识别到机架上的服务器拓扑结构的,不然分配的时候是无法感知到到底哪个节点是离客户端比较近的。另外一般分配数据节点的时候,有时候客户端并不一定在集群内发起的,而是在外部的。那么这时候分配的原则也是两个节点可能会近点,但是第三个会远离,甚至在不同机房中。
2021-11-16 - Spoon 👍(2) 💬(0)
零拷贝,利用DMA避免了两次内核态和用户态的切换。
2022-09-08 - 香樟树 👍(2) 💬(1)
抛个砖,分享一个MySQL关于磁盘IO的优化策略。大并发写入数据时磁盘IO是性能瓶颈,MySQL通过批量写(比如两个维度:攒够一定量的数据或者达到一定的时间间隔)来减少IO;同样的,大量并发读取数据时,磁盘IO也是性能瓶颈,MySQL通过连续读(将所需要的数据页以及与其相邻的数据页一起读入内存)来减少IO
2022-01-03 - 音速起子代购 👍(2) 💬(1)
请问一个问题,,chunk的副本位置关系不是由master掌握吗?那在复制过程中,由主副本如何转发通知次副本消息呢?主副本如何知道次副本的位置?
2021-10-06 - zixuan 👍(1) 💬(0)
snapshot不是直接复制各个副本,而是用了chunk引用数来做copy on write。
2021-12-29 - Helios 👍(1) 💬(1)
请教一下老师,现在网络带宽还会成为设计的瓶颈么?
2021-10-23 - Helios 👍(1) 💬(0)
“主副本自己会给这些请求排一个顺序,确保所有的数据写入是有一个固定顺序的” 并发保证顺序是很难得,尤其是在分布式的情况下,各个机器的clock可能不一致,同步NTP也有早晚,请教老师GFS是如何保证顺序呢
2021-10-23