37 如何对数据进行分类和预测?
今天我们进入专栏的最后一个模块,补全大数据知识体系最后一块拼图,一起来学习大数据算法。大数据越来越多的和人工智能关联起来,所谓人工智能就是利用数学统计方法,统计数据中的规律,然后利用这些统计规律进行自动化数据处理,使计算机表现出某种智能的特性,而各种数学统计方法,就是大数据算法。关于专栏算法模块的设置,我会围绕数据分类、数据挖掘、推荐引擎、大数据算法的数学原理、神经网络算法几个方面,为你展开大数据算法的“全景图”。
分类是人们认知事物的重要手段,如果你能将某个事物分类得足够细,你实际上就已经认知了这个事物。如果你能将一个人从各个维度,比如专业能力、人际交往、道德品行、外貌特点各个方面都进行正确的分类,并且在每个维度的基础上还能再细分,比如大数据专业能力、Java编程能力、算法能力也能正确分类,那么可以说你已经完全了解这个人了。
现实中,几乎没有人能够完全将另一个人分类。也就是说,几乎没有人能完全了解另一个人。但是在互联网时代,一个人在互联网里留下越来越多的信息,如果计算机利用大数据技术将所有这些信息都统一起来进行分析,理论上可以将一个人完全分类,也就是完全了解一个人。
分类也是大数据常见的应用场景之一,通过对历史数据规律的统计,将大量数据进行分类然后发现数据之间的关系,这样当有新的数据进来时,计算机就可以利用这个关系自动进行分类了。更进一步讲,如果这个分类结果在将来才会被证实,比如一场比赛的胜负、一次选举的结果,那么在旁观者看来,就是在利用大数据进行预测了。其实,现在火热的机器学习本质上说就是统计学习。
下面我通过一个相对比较简单的KNN分类算法,向你展示大数据分类算法的特点和应用,以及各种大数据算法都会用到的数据距离计算方法和特征值处理方法。
KNN分类算法
KNN算法,即K近邻(K Nearest Neighbour)算法,是一种基本的分类算法。其主要原理是:对于一个需要分类的数据,将其和一组已经分类标注好的样本集合进行比较,得到距离最近的K个样本,K个样本最多归属的类别,就是这个需要分类数据的类别。下面我给你画了一个KNN算法的原理图。
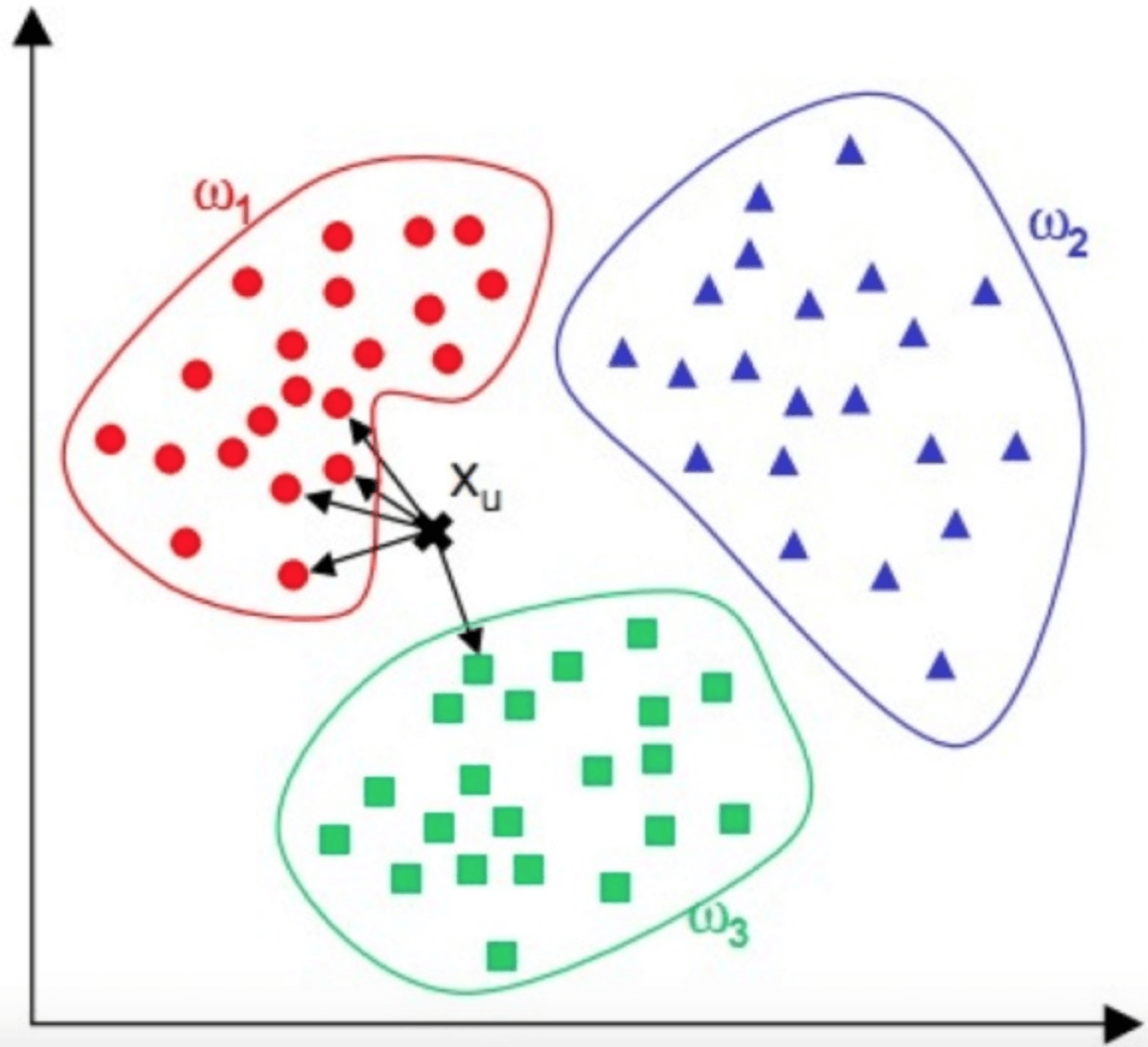
图中,红蓝绿三种颜色的点为样本数据,分属三种类别$w_{1}$、$w_{2}$、 $w_{3}$ 。对于待分类点$X_{u}$ ,计算和它距离最近的5个点(即K为5),这5个点最多归属的类别为$w_{1}$(4个点归属$w_{1}$,1个点归属$w_{3}$),那么$X_{u}$的类别被分类为$w_{1}$。
KNN的算法流程也非常简单,请看下面的流程图。
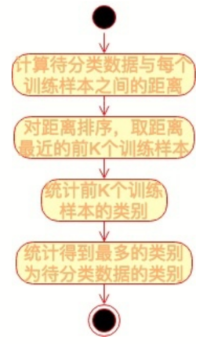
KNN算法是一种非常简单实用的分类算法,可用于各种分类的场景,比如新闻分类、商品分类等,甚至可用于简单的文字识别。对于新闻分类,可以提前对若干新闻进行人工标注,标好新闻类别,计算好特征向量。对于一篇未分类的新闻,计算其特征向量后,跟所有已标注新闻进行距离计算,然后进一步利用KNN算法进行自动分类。
读到这你肯定会问,如何计算数据的距离呢?如何获得新闻的特征向量呢?
数据的距离
KNN算法的关键是要比较需要分类的数据与样本数据之间的距离,这在机器学习中通常的做法是:提取数据的特征值,根据特征值组成一个n维实数向量空间(这个空间也被称作特征空间),然后计算向量之间的空间距离。空间之间的距离计算方法有很多种,常用的有欧氏距离、余弦距离等。
对于数据$x_{i}$和$x_{j}$,若其特征空间为n维实数向量空间$R^{n}$,即$x_{i}=(x_{i1},x_{i2},…,x_{in})$,$x_{j}=(x_{j1},x_{j2},…,x_{jn})$,则其欧氏距离计算公式为
$$d(x_{i},x_{j})=\sqrt{\sum_{k=1}{n}{(x_{ik}-x_{jk})2}}$$
这个欧式距离公式其实我们在初中的时候就学过,平面几何和立体几何里两个点之间的距离,也是用这个公式计算出来的,只是平面几何(二维几何)里的n=2,立体几何(三维几何)里的n=3,而机器学习需要面对的每个数据都可能有n维的维度,即每个数据有n个特征值。但是不管特征值n是多少,两个数据之间的空间距离的计算公式还是这个欧氏计算公式。大多数机器学习算法都需要计算数据之间的距离,因此掌握数据的距离计算公式是掌握机器学习算法的基础。
欧氏距离是最常用的数据计算公式,但是在文本数据以及用户评价数据的机器学习中,更常用的距离计算方法是余弦相似度。
$$cos(\theta)=\frac{\sum_{k=1}{n}{x_{ik}x_{jk}}}{\sqrt{\sum_{k=1}}{x_{ik{2}}}\sqrt{\sum_{k=1}$$}{x_{jk}^{2}}}
余弦相似度的值越接近1表示其越相似,越接近0表示其差异越大,使用余弦相似度可以消除数据的某些冗余信息,某些情况下更贴近数据的本质。我举个简单的例子,比如两篇文章的特征值都是:“大数据”“机器学习”和“极客时间”,A文章的特征向量为(3, 3, 3),即这三个词出现次数都是3;B文章的特征向量为(6, 6, 6),即这三个词出现次数都是6。如果光看特征向量,这两个向量差别很大,如果用欧氏距离计算确实也很大,但是这两篇文章其实非常相似,只是篇幅不同而已,它们的余弦相似度为1,表示非常相似。
余弦相似度其实是计算向量的夹角,而欧氏距离公式是计算空间距离。余弦相似度更关注数据的相似性,比如两个用户给两件商品的打分分别是(3, 3)和(4, 4),那么两个用户对两件商品的喜好是相似的,这种情况下,余弦相似度比欧氏距离更合理。
文本的特征值
我们知道了机器学习的算法需要计算距离,而计算距离还需要知道数据的特征向量,因此提取数据的特征向量是机器学习工程师们的重要工作,有时候甚至是最重要的工作。不同的数据以及不同的应用场景需要提取不同的特征值,我们以比较常见的文本数据为例,看看如何提取文本特征向量。
文本数据的特征值就是提取文本关键词,TF-IDF算法是比较常用且直观的一种文本关键词提取算法。这种算法是由TF和IDF两部分构成。
TF是词频(Term Frequency),表示某个单词在文档中出现的频率,一个单词在一个文档中出现得越频繁,TF值越高。
词频: $$ TF=\frac{某个词在文档中出现的次数}{文档总词数}$$
IDF是逆文档频率(Inverse Document Frequency),表示这个单词在所有文档中的稀缺程度,越少文档出现这个词,IDF值越高。
逆文档频率:$$IDF=log(\frac{所有的文档总数}{出现该词的文档数})$$
TF与IDF的乘积就是TF-IDF。
$$TF-IDF=TF\times IDF$$
所以如果一个词在某一个文档中频繁出现,但在所有文档中却很少出现,那么这个词很可能就是这个文档的关键词。比如一篇关于原子能的技术文章,“核裂变”“放射性”“半衰期”等词汇会在这篇文档中频繁出现,即TF很高;但是在所有文档中出现的频率却比较低,即IDF也比较高。因此这几个词的TF-IDF值就会很高,就可能是这篇文档的关键词。如果这是一篇关于中国原子能的文章,也许“中国”这个词也会频繁出现,即TF也很高,但是“中国”也在很多文档中出现,那么IDF就会比较低,最后“中国”这个词的TF-IDF就很低,不会成为这个文档的关键词。
提取出关键词以后,就可以利用关键词的词频构造特征向量,比如上面例子关于原子能的文章,“核裂变”“放射性”“半衰期”这三个词是特征值,分别出现次数为12、9、4。那么这篇文章的特征向量就是(12, 9, 4),再利用前面提到的空间距离计算公式计算与其他文档的距离,结合KNN算法就可以实现文档的自动分类。
贝叶斯分类
贝叶斯公式是一种基于条件概率的分类算法,如果我们已经知道A和B的发生概率,并且知道了B发生情况下A发生的概率,可以用贝叶斯公式计算A发生的情况下B发生的概率。事实上,我们可以根据A的情况,即输入数据,判断B的概率,即B的可能性,进而进行分类。
举个例子:假设一所学校里男生占60%,女生占40%。男生总是穿长裤,女生则一半穿长裤一半穿裙子。假设你走在校园中,迎面走来一个穿长裤的学生,你能够推断出这个穿长裤学生是男生的概率是多少吗?
答案是75%,具体算法是:
$$穿长裤是男生的概率 = \frac{男生穿长裤的概率 \times 是男生的概率}{学生穿长裤的概率}$$
这个算法就利用了贝叶斯公式,贝叶斯公式的写法是:
$$P(B|A)= \frac{P(A|B)*P(B)}{P(A)}$$
意思是A发生的条件下B发生的概率,等于B发生的条件下A发生的概率,乘以B发生的概率,除以A发生的概率。还是上面这个例子,如果我问你迎面走来穿裙子的学生是女生的概率是多少。同样带入贝叶斯公式,可以计算出是女生的概率为100%。其实这个结果我们根据常识也能推断出来,但是很多时候,常识受各种因素的干扰,会出现偏差。比如有人看到一篇博士生给初中学历老板打工的新闻,就感叹读书无用。事实上,只是少见多怪,样本量太少而已。而大量数据的统计规律则能准确反映事物的分类概率。
贝叶斯分类的一个典型的应用场合是垃圾邮件分类,通过对样本邮件的统计,我们知道每个词在邮件中出现的概率$P(A_{i})$,我们也知道正常邮件概率$P(B_{0})$和垃圾邮件的概率$P(B_{1})$,还可以统计出垃圾邮件中各个词的出现概率$P(A_{i}|B_{1})$,那么现在一封新邮件到来,我们就可以根据邮件中出现的词,计算$P(B_{1}|A_{i})$,即得到这些词出现情况下,邮件为垃圾邮件的概率,进而判断邮件是否为垃圾邮件。
现实中,贝叶斯公式等号右边的概率,我们可以通过对大数据的统计获得,当有新的数据到来的时候,我们就可以带入上面的贝叶斯公式计算其概率。而如果我们设定概率超过某个值就认为其会发生,那么我们就对这个数据进行了分类和预测,具体过程如下图所示。
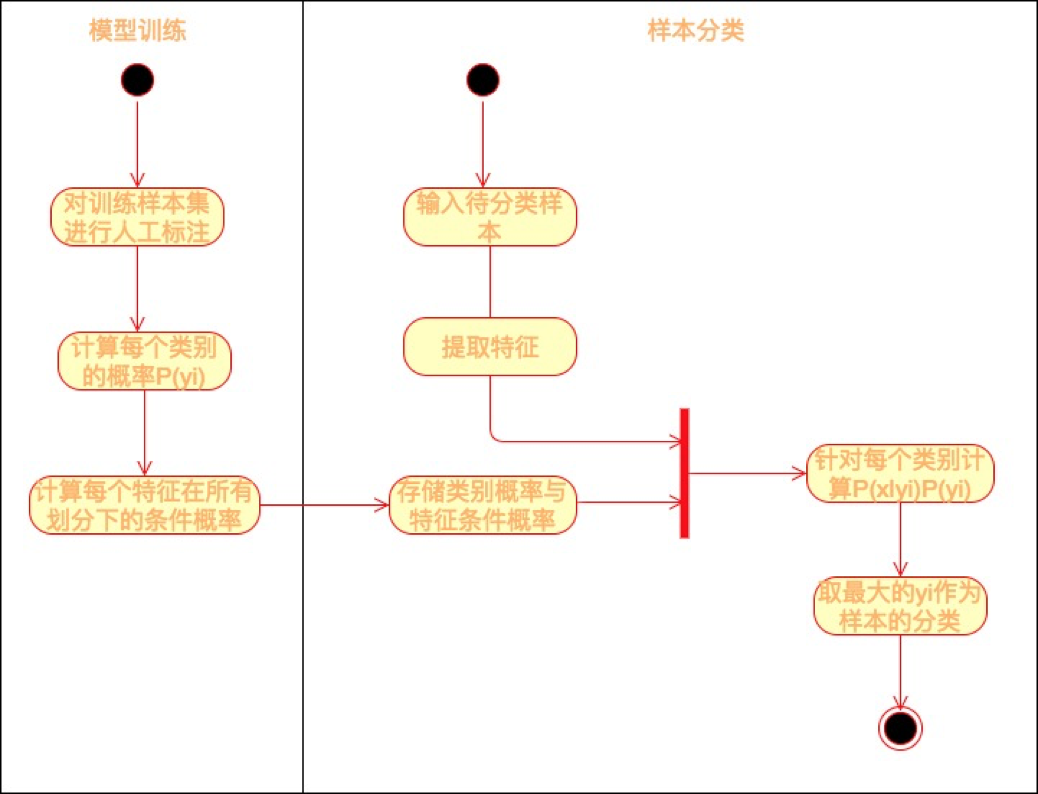
训练样本就是我们的原始数据,有时候原始数据并不包含我们想要计算的维度数据,比如我们想用贝叶斯公式自动分类垃圾邮件,那么首先要对原始邮件进行标注,需要标注哪些邮件是正常邮件、哪些邮件是垃圾邮件。这一类需要对数据进行标注才能进行的机器学习训练也叫作有监督的机器学习。
小结
分类是机器学习非常重要的一类算法,很多场景都需要用到分类,很多AI其实都是分类算法在起作用。比如AI围棋算法AlphaGo本质就是一个分类算法,围棋棋盘有361个交叉点,可以认为有361个分类选项,AlphaGo只要每次选择一个有最大赢面的分类选项输出即可,具体我们在神经网络一期再来讨论。
思考题
KNN算法的简单实现只需要几十行代码,请用你熟悉的编程语言实现KNN。
欢迎你点击“请朋友读”,把今天的文章分享给好友。也欢迎你写下自己的思考或疑问,与我和其他同学一起讨论。
- leadluge 👍(0) 💬(1)
KNN的那个例子(3,3,3)和(6,6,6)的余弦相似度按照公式=(3*6+3*6+3*6)/((根号27)*(根号216))不是1吧,值应该是1/(根号2),是老师笔误还是我理解错了^_^
2019-01-24 - 老陈 👍(43) 💬(1)
精辟! 跟随老师一路走来,学到很多,您这个专栏特点是理论知识阐述的非常清楚,不像技术书籍那样子晦涩,同时专栏也夹杂大量的工作方法和技巧,而这些方法和技巧不是技术书籍里能够看到的。
2019-01-22 - 杰之7 👍(8) 💬(0)
跟着老师进入了最后一个模块的学习,也是这两年最火的名称,机器学习和AI。 在这一节中,老师讲述了AI的定义,数据统计出来的规律,自动化的数据处理,使其表现出某种智能的特征。我的理解是人工智能依然是统计学的范畴,只不过将海量的统计规律用在计算机来自动处理学习,达到智能的效果。 在数据统计方法中,老师介绍了分类算法KNN,关键点是通过提取向量,对特征向量进行距离或者余弦计算,然后通过KNN的处理步骤,得到分类的结果。 另一种分类是条件分类贝叶斯,老师介绍了贝叶斯在邮件分类的处理。 结合这一节的学习和生活中的现象,分类已经在各行各业中应用成熟。网购的购买标签分类之后推荐相似产品,头条系的定制推荐,现在的定制化制作,都在属于分类算法。
2019-01-23 - Python 👍(5) 💬(0)
谁能用python实现看看
2019-01-22 - 你为啥那么牛 👍(3) 💬(0)
李老师,之前做过一个通过算法,分辨农机田地作业轨迹与道路轨迹的业务,也不了解这些算法,自己就通过数据特征琢磨,也涉及到距离计算、方向计算等等,实现就是不理想。看了几天的文章,貌似有点领悟了。 在我公号里有这么一篇文章,如果有时间,能大概分享下你的思路吗? 原文链接:https://mp.weixin.qq.com/s/cNWQHT_ERk73lYqVW6K5RA
2021-03-15 - 任鹏斌 👍(3) 💬(0)
老师讲的通俗易懂竟然一下就看懂了,不错,希望能学到更多
2019-01-22 - 纯洁的憎恶 👍(2) 💬(0)
机器分类KNN。 首先要定义和提取特征向量,然后将其数字化。通过标记、计算样本的特征向量,给予机器指引。采用欧式距离、余弦相似度、TF-IDF、贝叶斯公式等方法,计算待分类对象与样本数据的特征向量差异,找到最近似的分类。
2019-01-22 - 伊森 👍(1) 💬(0)
很好
2019-01-22 - twintel 👍(0) 💬(0)
import java.util.*; public class KNNUsingJava { public static class Point { double x; double y; //可以设置多维数据 String label; public double getDistance(double dataX, double dataY) { return (x - dataX)*(x-dataX) + (y-dataY)(y-dataY); } } public String getLabel(final double x, final double y, List<Point> existingDataSet, int k) { PriorityQueue<Point> queue = new PriorityQueue<>((p1,p2)->{ return Double.compare(p1.getDistance(x,y), p2.getDistance(x,y)); }); for (Point point : existingDataSet) queue.offer(point); Map<String, Integer> map = new HashMap<>(); while (k > 0) { Point point = queue.remove(); Integer count = map.getOrDefault(point.label, 0); map.put(point.label, count+1); k--; } int maxUsed = 0; String selectdLabel = ""; for (Map.Entry<String, Integer> entry : map.entrySet()) { if (entry.value() > maxUsed) { maxUsed = entry.getValue(); selectdLabel = entry.getKey(); } } return selectdLabel; } }
2025-01-12 - 1043 👍(0) 💬(0)
十几年前,我在大连市一个比较有名的财经类院校附近刚吃完饭,走出饭店门口,见到一位美丽动人,楚楚可怜,穿着裙子,喷着香水,擦着胭脂水粉,然而ta有喉结,说话是男声……我一脸懵的看了看这个“美人”,ta不耐烦的警告我说:“看什么看,老娘是男的。”我都没算出来ta到底是男是女,贝叶斯算法能算出ta是女生的概率为100%?那我告诉你这个贝叶斯算法算错了!
2022-05-20 - 亚林 👍(0) 💬(0)
有点像数学建模竞赛
2021-08-30 - 钱 👍(0) 💬(0)
阅过留痕 现在火热的机器学习本质上说就是统计学习,对事物分类是认识事物的第一步,因为事物的粒度已经粗或复杂到我们一下子理解不了,所以,需要分类。人工智能算法的关键也是一样,首先,要分门别类的识别出各种事物,不同的事物用不同的方式对待。
2020-02-11 - 徐同学 👍(0) 💬(0)
作为一名back-end业务开发,跟随智慧老师一步步走来,感觉学到了很多。谢谢老师。
2020-01-18 - 上善若水 👍(0) 💬(0)
提取关键字
2019-11-30 - 上善若水 👍(0) 💬(0)
去冗余
2019-11-30