26 互联网产品 + 大数据产品 = 大数据平台
从今天开始,我们进入专栏的“大数据平台与系统集成”模块。
前面我讲了各种大数据技术的原理与架构,大数据计算通过将可执行的代码分发到大规模的服务器集群上进行分布式计算,以处理大规模的数据,即所谓的移动计算比移动数据更划算。但是在分布式系统中分发执行代码并启动执行,这样的计算方式必然不会很快,即使在一个规模不太大的数据集上进行一次简单计算,MapReduce也可能需要几分钟,Spark快一点,也至少需要数秒的时间。
而互联网产品处理用户请求,需要毫秒级的响应,也就是说,要在1秒内完成计算,因此大数据计算必然不能实现这样的响应要求。但是互联网应用又需要使用大数据,实现统计分析、数据挖掘、关联推荐、用户画像等一系列功能。
那么如何才能弥补这互联网和大数据系统之间的差异呢?解决方案就是将面向用户的互联网产品和后台的大数据系统整合起来,也就是今天我要讲的构建一个大数据平台。
大数据平台,顾名思义就是整合网站应用和大数据系统之间的差异,将应用程序产生的数据导入到大数据系统,经过处理计算后再导出给应用程序使用。
下图是一个典型的互联网大数据平台的架构。

在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使用开源大数据产品或者自己开发相关大数据组件。
你可以看到,大数据平台由上到下,可分为三个部分:数据采集、数据处理、数据输出与展示。
数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。数据库同步通常用Sqoop,日志同步可以选择Flume,打点采集的数据经过格式化转换后通过Kafka等消息队列进行传递。
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以使用了,而日志和爬虫产生的数据就需要进行大量的清洗、转化处理才能有效使用。
数据处理
这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在HDFS。MapReduce、Hive、Spark等计算任务读取HDFS上的数据进行计算,再将计算结果写入HDFS。
MapReduce、Hive、Spark等进行的计算处理被称作是离线计算,HDFS存储的数据被称为离线数据。在大数据系统上进行的离线计算通常针对(某一方面的)全体数据,比如针对历史上所有订单进行商品的关联性挖掘,这时候数据规模非常大,需要较长的运行时间,这类计算就是离线计算。
除了离线计算,还有一些场景,数据规模也比较大,但是要求处理的时间却比较短。比如淘宝要统计每秒产生的订单数,以便进行监控和宣传。这种场景被称为大数据流式计算,通常用Storm、Spark Steaming等流式大数据引擎来完成,可以在秒级甚至毫秒级时间内完成计算。
数据输出与展示
前面我说过,大数据计算产生的数据还是写入到HDFS中,但应用程序不可能到HDFS中读取数据,所以必须要将HDFS中的数据导出到数据库中。数据同步导出相对比较容易,计算产生的数据都比较规范,稍作处理就可以用Sqoop之类的系统导出到数据库。
这时,应用程序就可以直接访问数据库中的数据,实时展示给用户,比如展示给用户关联推荐的商品。淘宝卖家的量子魔方之类的产品,其数据都来自大数据计算产生。
除了给用户访问提供数据,大数据还需要给运营和决策层提供各种统计报告,这些数据也写入数据库,被相应的后台系统访问。很多运营和管理人员,每天一上班,就是登录后台数据系统,查看前一天的数据报表,看业务是否正常。如果数据正常甚至上升,就可以稍微轻松一点;如果数据下跌,焦躁而忙碌的一天马上就要开始了。
将上面三个部分整合起来的是任务调度管理系统,不同的数据何时开始同步,各种MapReduce、Spark任务如何合理调度才能使资源利用最合理、等待的时间又不至于太久,同时临时的重要任务还能够尽快执行,这些都需要任务调度管理系统来完成。
有时候,对分析师和工程师开放的作业提交、进度跟踪、数据查看等功能也集成在这个任务调度管理系统中。
简单的大数据平台任务调度管理系统其实就是一个类似Crontab的定时任务系统,按预设时间启动不同的大数据作业脚本。复杂的大数据平台任务调度还要考虑不同作业之间的依赖关系,根据依赖关系的DAG图进行作业调度,形成一种类似工作流的调度方式。
对于每个公司的大数据团队,最核心开发、维护的也就是这个系统,大数据平台上的其他系统一般都有成熟的开源软件可以选择,但是作业调度管理会涉及很多个性化的需求,通常需要团队自己开发。开源的大数据调度系统有Oozie,也可以在此基础进行扩展。
上面我讲的这种大数据平台架构也叫Lambda架构,是构建大数据平台的一种常规架构原型方案。Lambda架构原型请看下面的图。
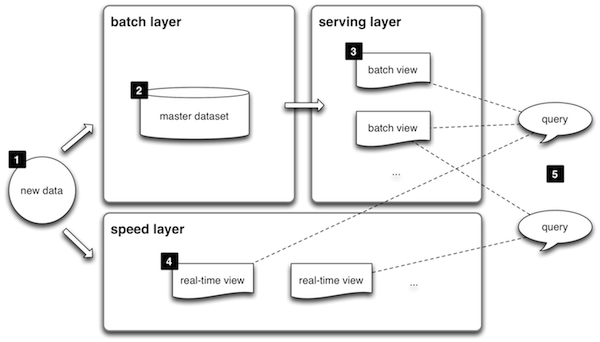
1.数据(new data)同时写入到批处理大数据层(batch layer)和流处理大数据层(speed layer)。
2.批处理大数据层是数据主要存储与计算的地方,所有的数据最终都会存储到批处理大数据层,并在这里被定期计算处理。
3.批处理大数据层的计算结果输出到服务层(serving layer),供应用使用者查询访问。
4.由于批处理的计算速度比较慢,数据只能被定期处理计算(比如每天),因此延迟也比较长(只能查询到截止前一天的数据,即数据输出需要T+1)。所以对于实时性要求比较高的查询,会交给流处理大数据层(speed layer),在这里进行即时计算,快速得到结果。
5.流处理计算速度快,但是得到的只是最近一段时间的数据计算结果(比如当天的);批处理会有延迟,但是有全部的数据计算结果。所以查询访问会将批处理计算的结果和流处理计算的结果合并起来,作为最终的数据视图呈现。
小结
我们看下一个典型的互联网企业的数据流转。用户通过App等互联网产品使用企业提供的服务,这些请求实时不停地产生数据,由系统进行实时在线计算,并把结果数据实时返回用户,这个过程被称作在线业务处理,涉及的数据主要是用户自己一次请求产生和计算得到的数据。单个用户产生的数据规模非常小,通常内存中一个线程上下文就可以处理。但是大量用户并发同时请求系统,对系统而言产生的数据量就非常可观了,比如天猫“双十一”,开始的时候一分钟就有数千万用户同时访问天猫的系统。
在线数据完成和用户的交互后,会以数据库或日志的方式存储在系统的后端存储设备中,大量的用户日积月累产生的数据量非常庞大,同时这些数据中蕴藏着大量有价值的信息需要计算。但是我们没有办法直接在数据库以及磁盘日志中对这些数据进行计算,前面我们也一再讨论过大规模数据计算的挑战,所以需要将这些数据同步到大数据存储和计算系统中进行处理。
但是这些数据并不会立即被数据同步系统导入到大数据系统,而是需要隔一段时间再同步,通常是隔天,比如每天零点后开始同步昨天24小时在线产生的数据到大数据平台。因为数据已经距其产生间隔了一段时间,所以这些数据被称作离线数据。
离线数据被存储到HDFS,进一步由Spark、Hive这些离线大数据处理系统计算后,再写入到HDFS中,由数据同步系统同步到在线业务的数据库中,这样用户请求就可以实时使用这些由大数据平台计算得到的数据了。
离线计算可以处理的数据规模非常庞大,可以对全量历史数据进行计算,但是对于一些重要的数据,需要实时就能够进行查看和计算,而不是等一天,所以又会用到大数据流式计算,对于当天的数据实时进行计算,这样全量历史数据和实时数据就都被处理了。
我的专栏前面三个模块都是关于大数据产品的,但是在绝大多数情况下,我们都不需要自己开发大数据产品,我们仅仅需要用好这些大数据产品,也就是如何将大数据产品应用到自己的企业中,将大数据产品和企业当前的系统集成起来。
大数据平台听起来高大上,事实上它充当的是一个粘合剂的作用,将互联网线上产生的数据和大数据产品打通,它的主要组成就是数据导入、作业调度、数据导出三个部分,因此开发一个大数据平台的技术难度并不高。前面也有同学提问说,怎样可以转型做大数据相关业务,我觉得转型去做大数据平台开发也许是一个不错的机会。
思考题
如果你所在的公司安排你去领导开发公司的大数据平台,你该如何开展工作?建议从资源申请、团队组织、跨部门协调、架构设计、开发进度、推广实施多个维度思考。
欢迎你点击“请朋友读”,把今天的文章分享给好友。也欢迎你写下自己的思考或疑问,与我和其他同学一起讨论。
- Jack 👍(5) 💬(2)
请问老师 采用cdh来搭建大数据平台是否一个好的选择
2018-12-28 - 君侯 👍(4) 💬(1)
如何定义或者区别所谓在线业务,离线业务,实时业务
2020-06-11 - 西瓜 👍(23) 💬(0)
一楼那位兄弟,你应该是把资源调度和任务调度的概念弄混了
2018-12-27 - 纯洁的憎恶 👍(12) 💬(0)
在工业上,很多大数据计算的结果,要应用到互联网产品中。然而前者的计算时长难以保证实时性,后者又有很高的响应及时性要求。于是需要找到一个途径,整合前后两端的差异,这就是大数据平台的使命。它从前端应用程序获取数据,倒入后台的大数据系统计算,再将结果返还给应用程序。由此大数据平台自上而下分为数据采集、数据处理、数据展示三个部分。 数据采集。数据采集的来源可能有数据库、日志、网络爬虫,不同来源的数据质量各异,日志与爬虫数据在导入前需要预处理(清洗、转化)。 数据处理。倒入大数据系统的数据被存储在分布式文件系统中(如HDFS),大数据批处理和产品离线计算保存在分布式文件系统中的被倒入数据,并将结果也写入分布式文件系统。大数据流处理产品计算输入数据并直接输出。 数据展示。大数据离线处理的计算结果存储在分布式文件系统中,无法被应用程序直接调用,需要同步后导出到数据库。 当然还需要一个任务调度系统将上述三部分组织起来。简单的调度策略按先后次序,复杂的要依据依赖关系(DAG图)。
2018-12-30 - kwang 👍(5) 💬(2)
1,日志同步可以理解为在app或web浏览器中部署埋点sdk,将埋点数据上报给应用服务器,应用服务器上的日志在经过 flume 接入到 HDFS。想问一下老师“打点采集”一般是在什么场景下会涉及到呢?又有什么方式实现“打点采集”? 2,我接触到的大数据平台中,有这样一种实现方式:日志同步通过 flume-agent 接入,然后打到 kafka,kafka 的数据同时供离线和实时计算消费,个人感觉这种方式的实时效果不一定会很好,请问老师怎么看待这种方式? 3,比较奇怪的是老师在资源调度系统里为啥没有提到 yarn,个人认为 crontab 只是决定任务的启动方式和时间,而真正做资源调度的应该主要是 yarn。
2018-12-27 - special 👍(4) 💬(0)
学习大数据将近一年,对Hadoop各种工具的特点、原理以及编程使用有较为全面的总结,大数据小白入门的好帮手。 欢迎关注公众号: 程序员的修身养性 一起交流学习!
2018-12-28 - 达子不一般 👍(3) 💬(0)
lamda给我的印象应该是java的lamda表达式,这个lamda架构貌似看不出来跟lamda本意有啥关联?
2019-10-11 - 哥们,走起!! 👍(3) 💬(0)
老师,请问您是去哪找论文看的
2018-12-31 - 草裡菌 👍(1) 💬(0)
深入浅出,简洁明了,谢谢大佬。
2020-04-14 - 杰之7 👍(1) 💬(0)
通过这一节的学习,理解了互联网产品加大数据产品等于大数据平台。 整个大数据平台的流程图老师已经给我们展示,我理解的是通过用户对App或者是网页的使用产生的数据,通过服务器传输到数据库中,这样就有了数据的获取。接着通过数据同步系统将获取的数据导入大数据产品中进行计算处理。计算处理主要分两类,批处理和流式计算,两者结合可以将过去到此刻的数据处理完成。最后将处理好的数据导出到数据库中给用户或者相关人员使用。 在上述的整个过程中,任务调度管理系统进行调度的优先级和执行顺序。 基础薄弱甚至没有计算机科班基础,依然可以学习数据技术,执着的相信有一天是一名真正的数据人。
2019-01-01 - helloWorld 👍(1) 💬(2)
老师,我昨天看了腾讯TEG团队的一篇文章,他们做了一个流计算平台,其中提到了在Web页面通过画板构建一个流计算应用,想请教一下这样的功能实现的思路是什么
2018-12-27 - 臣馟飞扬 👍(0) 💬(1)
而互联网产品处理用户请求,需要毫秒级的响应,也就是说,要在 1 秒内完成计算,因此大数据计算必然不能实现这样的响应要求。但是互联网应用又需要使用大数据,实现统计分析、数据挖掘、关联推荐、用户画像等一系列功能。 那么如何才能弥补这互联网和大数据系统之间的差异呢?解决方案就是将面向用户的互联网产品和后台的大数据系统整合起来,也就是今天我要讲的构建一个大数据平台。大数据平台,顾名思义就是整合网站应用和大数据系统之间的差异,将应用程序产生的数据导入到大数据系统,经过处理计算后再导出给应用程序使用。 大数据平台还是利用大数据系统进行计算啊,无非就是做些数据的导入导出,没看出来从哪里能把计算速度提高到满足互联网应用的要求上啊,我理解的哪里有问题?
2020-02-29 - 钱 👍(0) 💬(0)
阅过留痕 计算机界最核心的就是数据,她是各种变幻的基础资料。大数据,把大字放在第一位以示强调数据量大这个特点,不过根本上还是围绕数据的采集加工挖掘在使劲。
2020-02-10 - Zend 👍(0) 💬(0)
看了这篇感触,能跟我们现在做的系统架构能对应的上。请问一下老师HBase现在在大数据平台里面处于什么位置,应用前景如何。
2019-11-15 - vailau 👍(0) 💬(0)
这一章受益良多~给我们一个全面清晰的大数据平台的架构,核心还是在于数据。 不管是互联网产品还是大数据产品,本质都是数据的采集、处理、展示过程,就方法及技术要求不一样。 会对个人/公司搭建自己的大数据平台有很直观的指导作用
2019-03-04