13 同样的本质,为何Spark可以更高效?
上一期我们讨论了Spark的编程模型,这期我们聊聊Spark的架构原理。和MapReduce一样,Spark也遵循移动计算比移动数据更划算这一大数据计算基本原则。但是和MapReduce僵化的Map与Reduce分阶段计算相比,Spark的计算框架更加富有弹性和灵活性,进而有更好的运行性能。
Spark的计算阶段
我们可以对比来看。首先和MapReduce一个应用一次只运行一个map和一个reduce不同,Spark可以根据应用的复杂程度,分割成更多的计算阶段(stage),这些计算阶段组成一个有向无环图DAG,Spark任务调度器可以根据DAG的依赖关系执行计算阶段。
还记得在上一期,我举了一个比较逻辑回归机器学习性能的例子,发现Spark比MapReduce快100多倍。因为某些机器学习算法可能需要进行大量的迭代计算,产生数万个计算阶段,这些计算阶段在一个应用中处理完成,而不是像MapReduce那样需要启动数万个应用,因此极大地提高了运行效率。
所谓DAG也就是有向无环图,就是说不同阶段的依赖关系是有向的,计算过程只能沿着依赖关系方向执行,被依赖的阶段执行完成之前,依赖的阶段不能开始执行,同时,这个依赖关系不能有环形依赖,否则就成为死循环了。下面这张图描述了一个典型的Spark运行DAG的不同阶段。
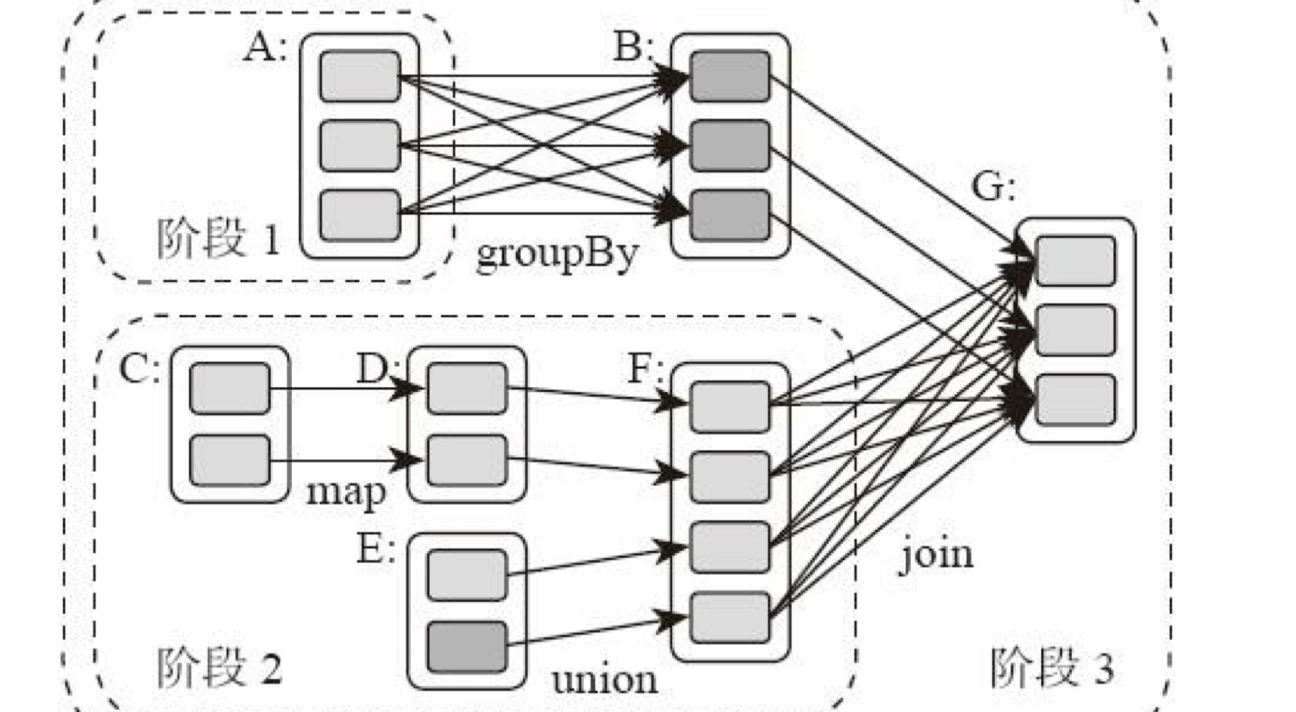
从图上看,整个应用被切分成3个阶段,阶段3需要依赖阶段1和阶段2,阶段1和阶段2互不依赖。Spark在执行调度的时候,先执行阶段1和阶段2,完成以后,再执行阶段3。如果有更多的阶段,Spark的策略也是一样的。只要根据程序初始化好DAG,就建立了依赖关系,然后根据依赖关系顺序执行各个计算阶段,Spark大数据应用的计算就完成了。
上图这个DAG对应的Spark程序伪代码如下。
所以,你可以看到Spark作业调度执行的核心是DAG,有了DAG,整个应用就被切分成哪些阶段,每个阶段的依赖关系也就清楚了。之后再根据每个阶段要处理的数据量生成相应的任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark就实现了大数据的分布式计算。
具体来看的话,负责Spark应用DAG生成和管理的组件是DAGScheduler,DAGScheduler根据程序代码生成DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。
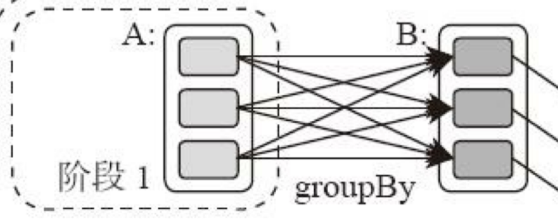
那么Spark划分计算阶段的依据是什么呢?显然并不是RDD上的每个转换函数都会生成一个计算阶段,比如上面的例子有4个转换函数,但是只有3个阶段。
你可以再观察一下上面的DAG图,关于计算阶段的划分从图上就能看出规律,当RDD之间的转换连接线呈现多对多交叉连接的时候,就会产生新的阶段。一个RDD代表一个数据集,图中每个RDD里面都包含多个小块,每个小块代表RDD的一个分片。
一个数据集中的多个数据分片需要进行分区传输,写入到另一个数据集的不同分片中,这种数据分区交叉传输的操作,我们在MapReduce的运行过程中也看到过。
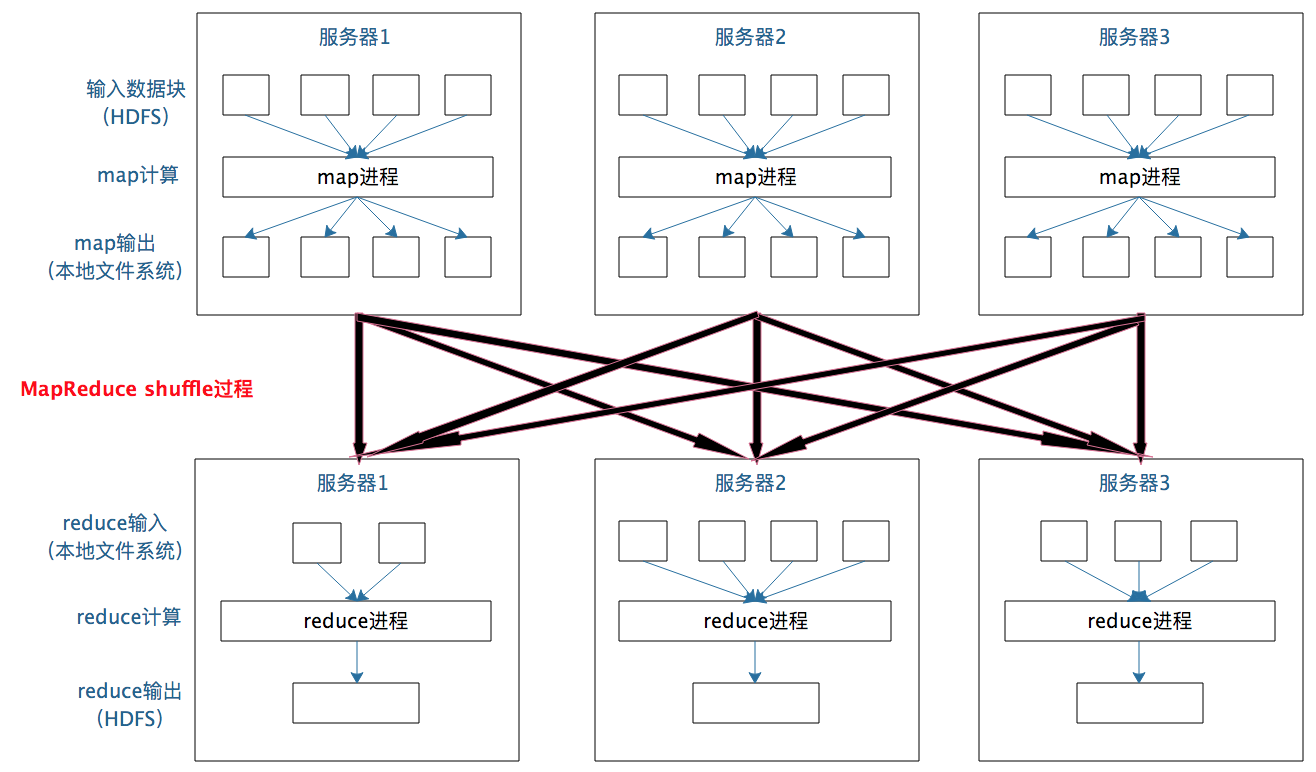
是的,这就是shuffle过程,Spark也需要通过shuffle将数据进行重新组合,相同Key的数据放在一起,进行聚合、关联等操作,因而每次shuffle都产生新的计算阶段。这也是为什么计算阶段会有依赖关系,它需要的数据来源于前面一个或多个计算阶段产生的数据,必须等待前面的阶段执行完毕才能进行shuffle,并得到数据。
这里需要你特别注意的是,计算阶段划分的依据是shuffle,不是转换函数的类型,有的函数有时候有shuffle,有时候没有。比如上图例子中RDD B和RDD F进行join,得到RDD G,这里的RDD F需要进行shuffle,RDD B就不需要。
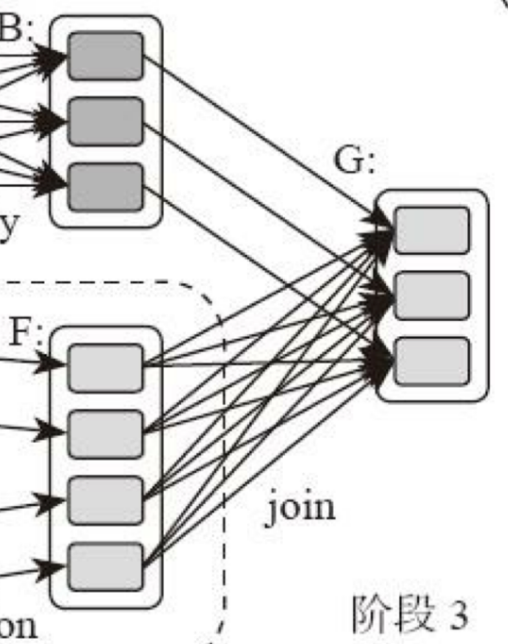
因为RDD B在前面一个阶段,阶段1的shuffle过程中,已经进行了数据分区。分区数目和分区Key不变,就不需要再进行shuffle。
这种不需要进行shuffle的依赖,在Spark里被称作窄依赖;相反的,需要进行shuffle的依赖,被称作宽依赖。跟MapReduce一样,shuffle也是Spark最重要的一个环节,只有通过shuffle,相关数据才能互相计算,构建起复杂的应用逻辑。
在你熟悉Spark里的shuffle机制后我们回到今天文章的标题,同样都要经过shuffle,为什么Spark可以更高效呢?
其实从本质上看,Spark可以算作是一种MapReduce计算模型的不同实现。Hadoop MapReduce简单粗暴地根据shuffle将大数据计算分成Map和Reduce两个阶段,然后就算完事了。而Spark更细腻一点,将前一个的Reduce和后一个的Map连接起来,当作一个阶段持续计算,形成一个更加优雅、高效的计算模型,虽然其本质依然是Map和Reduce。但是这种多个计算阶段依赖执行的方案可以有效减少对HDFS的访问,减少作业的调度执行次数,因此执行速度也更快。
并且和Hadoop MapReduce主要使用磁盘存储shuffle过程中的数据不同,Spark优先使用内存进行数据存储,包括RDD数据。除非是内存不够用了,否则是尽可能使用内存, 这也是Spark性能比Hadoop高的另一个原因。
Spark的作业管理
我在专栏上一期提到,Spark里面的RDD函数有两种,一种是转换函数,调用以后得到的还是一个RDD,RDD的计算逻辑主要通过转换函数完成。
另一种是action函数,调用以后不再返回RDD。比如count()函数,返回RDD中数据的元素个数;saveAsTextFile(path),将RDD数据存储到path路径下。Spark的DAGScheduler在遇到shuffle的时候,会生成一个计算阶段,在遇到action函数的时候,会生成一个作业(job)。
RDD里面的每个数据分片,Spark都会创建一个计算任务去处理,所以一个计算阶段会包含很多个计算任务(task)。
关于作业、计算阶段、任务的依赖和时间先后关系你可以通过下图看到。

图中横轴方向是时间,纵轴方向是任务。两条粗黑线之间是一个作业,两条细线之间是一个计算阶段。一个作业至少包含一个计算阶段。水平方向红色的线是任务,每个阶段由很多个任务组成,这些任务组成一个任务集合。
DAGScheduler根据代码生成DAG图以后,Spark的任务调度就以任务为单位进行分配,将任务分配到分布式集群的不同机器上执行。
Spark的执行过程
Spark支持Standalone、Yarn、Mesos、Kubernetes等多种部署方案,几种部署方案原理也都一样,只是不同组件角色命名不同,但是核心功能和运行流程都差不多。

上面这张图是Spark的运行流程,我们一步一步来看。
首先,Spark应用程序启动在自己的JVM进程里,即Driver进程,启动后调用SparkContext初始化执行配置和输入数据。SparkContext启动DAGScheduler构造执行的DAG图,切分成最小的执行单位也就是计算任务。
然后Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。Cluster Manager收到请求以后,将Driver的主机地址等信息通知给集群的所有计算节点Worker。
Worker收到信息以后,根据Driver的主机地址,跟Driver通信并注册,然后根据自己的空闲资源向Driver通报自己可以领用的任务数。Driver根据DAG图开始向注册的Worker分配任务。
Worker收到任务后,启动Executor进程开始执行任务。Executor先检查自己是否有Driver的执行代码,如果没有,从Driver下载执行代码,通过Java反射加载后开始执行。
小结
总结来说,Spark有三个主要特性:RDD的编程模型更简单,DAG切分的多阶段计算过程更快速,使用内存存储中间计算结果更高效。这三个特性使得Spark相对Hadoop MapReduce可以有更快的执行速度,以及更简单的编程实现。
Spark的出现和流行其实也有某种必然性,是天时、地利、人和的共同作用。首先,Spark在2012年左右开始流行,那时内存的容量提升和成本降低已经比MapReduce出现的十年前强了一个数量级,Spark优先使用内存的条件已经成熟;其次,使用大数据进行机器学习的需求越来越强烈,不再是早先年那种数据分析的简单计算需求。而机器学习的算法大多需要很多轮迭代,Spark的stage划分相比Map和Reduce的简单划分,有更加友好的编程体验和更高效的执行效率。于是Spark成为大数据计算新的王者也就不足为奇了。
思考题
Spark的流行离不开它成功的开源运作,开源并不是把源代码丢到GitHub上公开就万事大吉了,一个成功的开源项目需要吸引大量高质量开发者参与其中,还需要很多用户使用才能形成影响力。
Spark开发团队为Spark开源运作进行了大量的商业和非商业活动,你了解这些活动有哪些吗?假如你所在的公司想要开源自己的软件,用于提升自己公司的技术竞争力和影响力,如果是你负责人,你应该如何运作?
欢迎你写下自己的思考或疑问,与我和其他同学一起讨论。
- vivi 👍(71) 💬(1)
懂了原理,实战其实很简单,不用急着学部署啊,操作,原理懂了,才能用好,我觉得讲得很好
2018-12-25 - 纯洁的憎恶 👍(12) 💬(4)
这两天的内容对我来说有些复杂,很多知识点没有理解透。针对“而 Spark 更细腻一点,将前一个的 Reduce 和后一个的 Map 连接起来,当作一个阶段持续计算,形成一个更加优雅、高效地计算模型”。这句话中“将前一个的 Reduce 和后一个的 Map 连接起来”在细节上该如何理解,这也是明显的串行过程,感觉不会比传统的MapReduce快?是因为不同阶段之间有可能并行么?
2018-11-27 - ming 👍(9) 💬(1)
老师,有一句话我不太理解,请老师指导。“DAGScheduler 根据代码和数据分布生成 DAG 图”。根据代码生产DAG图我理解,但是为什么生成DAG图还要根据数据分布生成,数据分布不同,生成的DAG图也会不同吗?
2018-12-08 - 张飞 👍(7) 💬(1)
1.“而 Spark 更细腻一点,将前一个的 Reduce 和后一个的 Map 连接起来,当作一个阶段持续计算,形成一个更加优雅、高效地计算模型”,stage之间是串行的,即便前一个的reduce和后一个的map连接起来,也是要从前一个stage的计算节点的磁盘上拉取数据的,这跟mapreduce的计算是一样的,老师所说的高效在这里是怎么提现的呢? 2. spark的内存计算主要体现在shuffle过程,下一个stage拉取上一个stage的数据的时候更多的使用内存,在这里区分出与mapreduce计算的不同,别的还有什么阶段比mapreduce更依赖内存的吗? 3.我是不是可以这样理解,如果只有map阶段的话,即便计算量很大,mapreduce与spark的计算速度上也没有太大的区别? 可能问题问的不够清晰,希望老师解答一下。
2019-03-01 - weiruan85 👍(5) 💬(1)
1.完备的技术说明文档是必须的,比如使用场景,常见问题,环境搭建,核心技术的原理等。 2.输出真实等使用案例,以及给解决实际问题带来等好处,比如如果没有我们的开源方案是怎么实现的,有了这个方案是怎么实现的,差异是什么 3.商业推广,找业界有名的公司站台,或者有名的技术大牛做宣传(头羊效应) 4.归根结底,还是得有开创性的技术,能解决现实中的某一类问题。
2019-07-31 - 白鸽 👍(5) 💬(1)
Executor 从 Diver 下载执行代码,是整个程序 jar包?还是仅 Executor 计算任务对应的一段计算程序(经SparkSession初始化后的)?
2018-11-30 - 追梦小乐 👍(5) 💬(2)
老师,我想请教几个问题: 1、“根据每个阶段要处理的数据量生成相应的任务集合(TaskSet),每个任务都分配一个任务进程去处理”,是一个任务集合TaskSet启动一个进程,taskSet里面的任务是用线程计算吗?还是每个TaskSet里面的任务启动一个进程? 2、task-time 图中红色密集的表示什么? 3、Spark 的执行过程 的图中 Executor 中的 Cache 是表示内存吗?task和Executor不是在内存中的吗?
2018-11-27 - yang 👍(4) 💬(1)
啊、老师现在的提问都好大,我现在是老虎吃天无从下爪啊 ^_^
2018-11-27 - Yezhiwei 👍(3) 💬(1)
这里是学习过程中做的一些总结 https://mp.weixin.qq.com/s/OyPRXAu9hR1KWIbvc20y1g
2019-01-14 - 蓬蒿 👍(3) 💬(1)
“DAGScheduler 根据程序代码生成 DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。” 针对这一段话,我想多请教老师一些,我理解的DAGScheduler 根据程序代码生成 DAG,类似于关系型数据库优化器根据SQL生成执行计划,然后spark计算引擎根据这些计划去做计算,我的疑惑的是:DAG已经是根据代码生成的了,那Worker 还要从 Driver 下载执行代码去执行,我无法想象worker是如何执行代码的,能否帮忙解疑一下?
2018-12-14 - 星凡 👍(2) 💬(1)
老师您好,请问一下,对于复杂的多阶段计算,Hadoop MapReduce是需要进行多次map reduce 过程吗,而且每次map和reduce之间一定会进行shuffle(主要使用磁盘进行存储),所以相比Spark才更加低效,不知道我理解的正确嘛,请指教
2019-10-06 - 冰ྂ镇ྂ可ྂ乐ྂ 👍(2) 💬(1)
之前讲mr时候也有提到生成dag,spark这里也是dag,二者的差异是mr中,map reduce为一组操作(可能没有reduce)的一个job job之间是依赖关系,而spark并非简单依照m r划分而是针对数据的处理情况,如果r后到下一个m是窄依赖,则属于同一个stage,属于一个流程,这样理解对吗?
2019-04-30 - 尼糯米 👍(2) 💬(1)
1、DAGScheduler根据应用构造执行的DAG:是不是一个应用便构造一个DAG 2、DAG划分出计算阶段 3、每个计算阶段,根据要处理的数据量,为每个数据分片生成一个对应的任务,这些任务组成一个任务集合 4、每个任务分配一个进程 5、分布式计算:某个计算阶段,其某个任务的进程在集群某处执行计算 6、执行action函数便生成作业:依据DAG计算,是不是便可以生成多个作业 我这么理解可以吗?
2019-01-08 - 足迹 👍(2) 💬(1)
老师,根据大数据技术,程序移动,数据不动的原理。是不是应该在每个DataNode节点上面安装Spark呢?
2018-12-09 - sunlight001 👍(2) 💬(1)
老师,多出几本书吧,我保证全买☺,这个专栏真值!
2018-11-27