09 为什么我们管Yarn叫作资源调度框架?
我们知道,Hadoop主要是由三部分组成,除了前面我讲过的分布式文件系统HDFS、分布式计算框架MapReduce,还有一个是分布式集群资源调度框架Yarn。但是Yarn并不是随Hadoop的推出一开始就有的,Yarn作为分布式集群的资源调度框架,它的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为一个集存储、计算、资源管理为一体的完整大数据平台,进而发展出自己的生态体系,成为大数据的代名词。
所以在我们开始聊Yarn的实现原理前,有必要看看Yarn发展的过程,这对你理解Yarn的原理以及为什么被称为资源调度框架很有帮助。
先回忆一下我们学习的MapReduce的架构,在MapReduce应用程序的启动过程中,最重要的就是要把MapReduce程序分发到大数据集群的服务器上,在Hadoop 1中,这个过程主要是通过TaskTracker和JobTracker通信来完成。
这个方案有什么缺点吗?
这种架构方案的主要缺点是,服务器集群资源调度管理和MapReduce执行过程耦合在一起,如果想在当前集群中运行其他计算任务,比如Spark或者Storm,就无法统一使用集群中的资源了。
在Hadoop早期的时候,大数据技术就只有Hadoop一家,这个缺点并不明显。但随着大数据技术的发展,各种新的计算框架不断出现,我们不可能为每一种计算框架部署一个服务器集群,而且就算能部署新集群,数据还是在原来集群的HDFS上。所以我们需要把MapReduce的资源管理和计算框架分开,这也是Hadoop 2最主要的变化,就是将Yarn从MapReduce中分离出来,成为一个独立的资源调度框架。
Yarn是“Yet Another Resource Negotiator”的缩写,字面意思就是“另一种资源调度器”。事实上,在Hadoop社区决定将资源管理从Hadoop 1中分离出来,独立开发Yarn的时候,业界已经有一些大数据资源管理产品了,比如Mesos等,所以Yarn的开发者索性管自己的产品叫“另一种资源调度器”。这种命名方法并不鲜见,曾经名噪一时的Java项目编译工具Ant就是“Another Neat Tool”的缩写,意思是“另一种整理工具”。
下图是Yarn的架构。
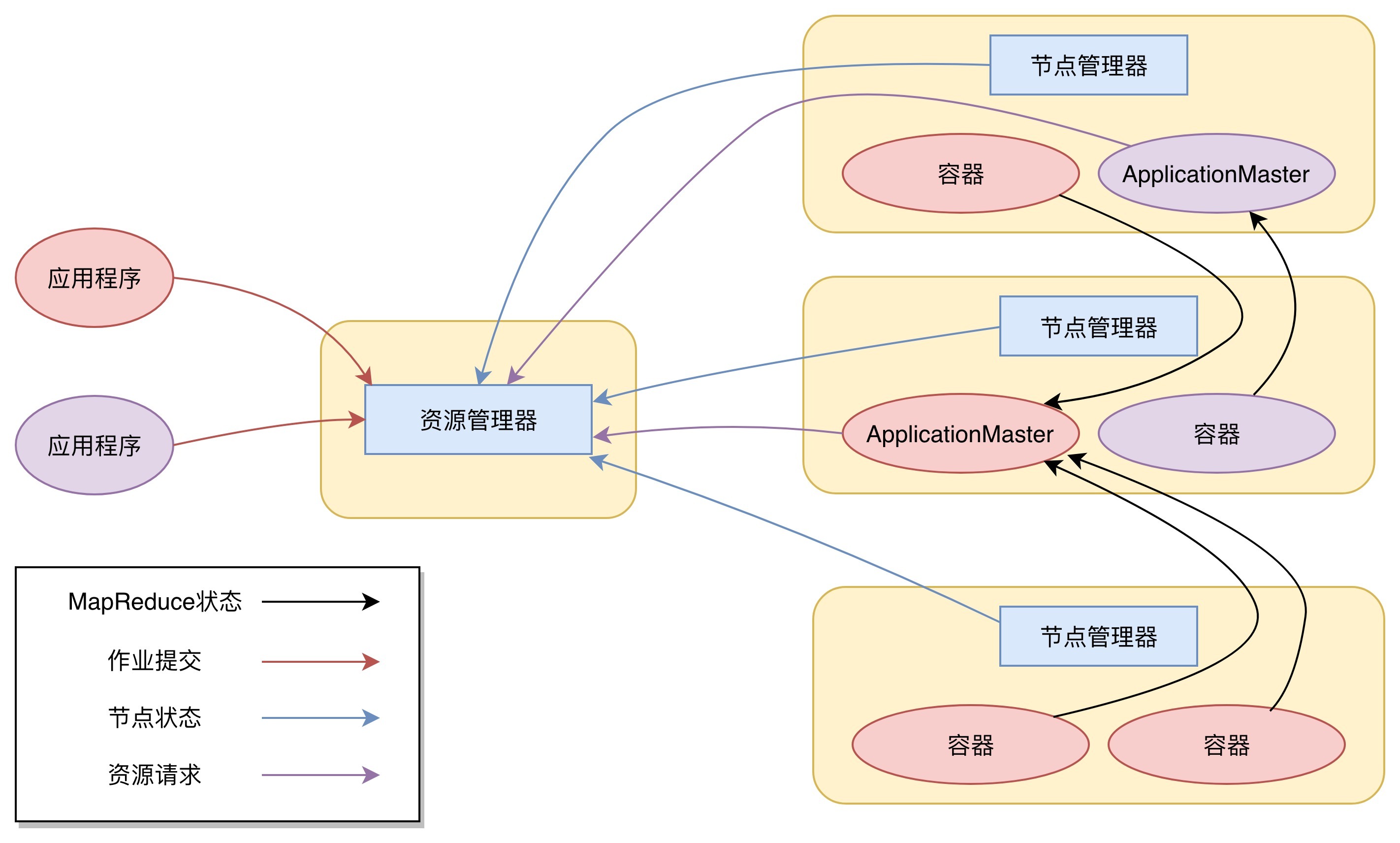
从图上看,Yarn包括两个部分:一个是资源管理器(Resource Manager),一个是节点管理器(Node Manager)。这也是Yarn的两种主要进程:ResourceManager进程负责整个集群的资源调度管理,通常部署在独立的服务器上;NodeManager进程负责具体服务器上的资源和任务管理,在集群的每一台计算服务器上都会启动,基本上跟HDFS的DataNode进程一起出现。
具体说来,资源管理器又包括两个主要组件:调度器和应用程序管理器。
调度器其实就是一个资源分配算法,根据应用程序(Client)提交的资源申请和当前服务器集群的资源状况进行资源分配。Yarn内置了几种资源调度算法,包括Fair Scheduler、Capacity Scheduler等,你也可以开发自己的资源调度算法供Yarn调用。
Yarn进行资源分配的单位是容器(Container),每个容器包含了一定量的内存、CPU等计算资源,默认配置下,每个容器包含一个CPU核心。容器由NodeManager进程启动和管理,NodeManger进程会监控本节点上容器的运行状况并向ResourceManger进程汇报。
应用程序管理器负责应用程序的提交、监控应用程序运行状态等。应用程序启动后需要在集群中运行一个ApplicationMaster,ApplicationMaster也需要运行在容器里面。每个应用程序启动后都会先启动自己的ApplicationMaster,由ApplicationMaster根据应用程序的资源需求进一步向ResourceManager进程申请容器资源,得到容器以后就会分发自己的应用程序代码到容器上启动,进而开始分布式计算。
我们以一个MapReduce程序为例,来看一下Yarn的整个工作流程。
1.我们向Yarn提交应用程序,包括MapReduce ApplicationMaster、我们的MapReduce程序,以及MapReduce Application启动命令。
2.ResourceManager进程和NodeManager进程通信,根据集群资源,为用户程序分配第一个容器,并将MapReduce ApplicationMaster分发到这个容器上面,并在容器里面启动MapReduce ApplicationMaster。
3.MapReduce ApplicationMaster启动后立即向ResourceManager进程注册,并为自己的应用程序申请容器资源。
4.MapReduce ApplicationMaster申请到需要的容器后,立即和相应的NodeManager进程通信,将用户MapReduce程序分发到NodeManager进程所在服务器,并在容器中运行,运行的就是Map或者Reduce任务。
5.Map或者Reduce任务在运行期和MapReduce ApplicationMaster通信,汇报自己的运行状态,如果运行结束,MapReduce ApplicationMaster向ResourceManager进程注销并释放所有的容器资源。
MapReduce如果想在Yarn上运行,就需要开发遵循Yarn规范的MapReduce ApplicationMaster,相应地,其他大数据计算框架也可以开发遵循Yarn规范的ApplicationMaster,这样在一个Yarn集群中就可以同时并发执行各种不同的大数据计算框架,实现资源的统一调度管理。
细心的你可能会发现,我在今天文章开头的时候提到Hadoop的三个主要组成部分的时候,管HDFS叫分布式文件系统,管MapReduce叫分布式计算框架,管Yarn叫分布式集群资源调度框架。
为什么HDFS是系统,而MapReduce和Yarn则是框架?
框架在架构设计上遵循一个重要的设计原则叫“依赖倒转原则”,依赖倒转原则是高层模块不能依赖低层模块,它们应该共同依赖一个抽象,这个抽象由高层模块定义,由低层模块实现。
所谓高层模块和低层模块的划分,简单说来就是在调用链上,处于前面的是高层,后面的是低层。我们以典型的Java Web应用举例,用户请求在到达服务器以后,最先处理用户请求的是Java Web容器,比如Tomcat、Jetty这些,通过监听80端口,把HTTP二进制流封装成Request对象;然后是Spring MVC框架,把Request对象里的用户参数提取出来,根据请求的URL分发给相应的Model对象处理;再然后就是我们的应用程序,负责处理用户请求,具体来看,还会分成服务层、数据持久层等。
在这个例子中,Tomcat相对于Spring MVC就是高层模块,Spring MVC相对于我们的应用程序也算是高层模块。我们看到虽然Tomcat会调用Spring MVC,因为Tomcat要把Request交给Spring MVC处理,但是Tomcat并没有依赖Spring MVC,Tomcat的代码里不可能有任何一行关于Spring MVC的代码。
那么,Tomcat如何做到不依赖Spring MVC,却可以调用Spring MVC?如果你不了解框架的一般设计方法,这里还是会感到有点小小的神奇是不是?
秘诀就是Tomcat和Spring MVC都依赖J2EE规范,Spring MVC实现了J2EE规范的HttpServlet抽象类,即DispatcherServlet,并配置在web.xml中。这样,Tomcat就可以调用DispatcherServlet处理用户发来的请求。
同样Spring MVC也不需要依赖我们写的Java代码,而是通过依赖Spring MVC的配置文件或者Annotation这样的抽象,来调用我们的Java代码。
所以,Tomcat或者Spring MVC都可以称作是框架,它们都遵循依赖倒转原则。
现在我们再回到MapReduce和Yarn。实现MapReduce编程接口、遵循MapReduce编程规范就可以被MapReduce框架调用,在分布式集群中计算大规模数据;实现了Yarn的接口规范,比如Hadoop 2的MapReduce,就可以被Yarn调度管理,统一安排服务器资源。所以说,MapReduce和Yarn都是框架。
相反地,HDFS就不是框架,使用HDFS就是直接调用HDFS提供的API接口,HDFS作为底层模块被直接依赖。
小结
Yarn作为一个大数据资源调度框架,调度的是大数据计算引擎本身。它不像MapReduce或Spark编程,每个大数据应用开发者都需要根据需求开发自己的MapReduce程序或者Spark程序。而现在主流的大数据计算引擎所使用的Yarn模块,也早已被这些计算引擎的开发者做出来供我们使用了。作为普通的大数据开发者,我们几乎没有机会编写Yarn的相关程序。但是,这是否意味着只有大数据计算引擎的开发者需要基于Yarn开发,才需要理解Yarn的实现原理呢?
恰恰相反,我认为理解Yarn的工作原理和架构,对于正确使用大数据技术,理解大数据的工作原理,是非常重要的。在云计算的时代,一切资源都是动态管理的,理解这种动态管理的原理对于理解云计算也非常重要。Yarn作为一个大数据平台的资源管理框架,简化了应用场景,对于帮助我们理解云计算的资源管理很有帮助。
思考题
Web应用程序的服务层Service和数据持久层DAO也是上下层模块关系,你设计的Service层是否按照框架的一般架构方法,遵循依赖倒转原则?
欢迎你写下自己的思考或疑问,与我和其他同学一起讨论。
- 落叶飞逝的恋 👍(90) 💬(1)
实际项目开发中,要做到依赖倒置的方法,一般就是抽象出相应的接口的方法,不依赖具体。面向接口编程。
2018-11-17 - hua168 👍(29) 💬(1)
看完几期感觉没有什么能难得住大神你的,回答问题在您那里感觉都很简单……我一般学习是先找视频看一下,照着截图,练习,然后去官网看一下说明文档,看更新了哪些知识。照视频学习又要截图,感觉很慢,很费时,看官方文档又很难深入,能否请教一下自学如果能深入,是我方法不对吗?有很多问题官网都没答案的啊,google不少也搜索不出来……运维类学的东西很多,精通感觉比较难……把原理东西,理解好,慢慢锻炼能不能达到您一半的水平呢?😂
2018-11-17 - 小千 👍(25) 💬(2)
sql语言是不是也是依赖倒转原则?不同的数据库都要支持sql语言规范,(很多)sql语句语句都可以在不同的数据库执行。
2018-11-22 - 生活在别处 👍(23) 💬(1)
老师,资源调度和计算调度的区别是什么?
2019-02-19 - 老男孩 👍(22) 💬(1)
突然明白了,这么多年都是错误的观点。我之前的所谓分层展现层,服务层,持久层其实都是上层依赖下层的抽象,不是依赖倒置。
2018-11-19 - 纯洁的憎恶 👍(17) 💬(1)
MapReduce框架遵循把程序发送到数据存储位置运行的原则。而资源调度框架的任务是动态调配计算资源(内存+cpu),那么就很有可能出现本地数据需要发送到其他节点计算的情况,于是就会有网络传输大量数据的现象,这是否与程序在数据存储节点运行的初衷相悖呢?我这么理解对么?
2018-11-18 - 席席 👍(16) 💬(1)
李老师。框架:指的是能兼容一类底层问题的技术,这么理解可以嘛?Spring 的依赖注入指的是框架嘛?
2020-05-18 - Jowin 👍(10) 💬(2)
请教老师,关于mapreduce和yarn的结合,是不是mapreduce ApplicationMaster 向资源管理器申请计算资源时可以指定目标节点(数据分片所在节点),而如果系统资源能够满足,就会把mapreduce计算任务分发到指定的服务器上。如果资源不允许,比如目标节点非常繁忙,这时部分mapreduce计算任务可能会分配另外的服务器(数据分片不在本地)?也就是说,yarn对资源调度是尽力而为,不保值一定满足ApplicationMaster的要求,这个理解正确么?
2018-12-01 - Li Shunduo 👍(10) 💬(1)
请问Yarn里的容器和docker这一类容器有什么关系吗?
2018-11-17 - 涤生 👍(8) 💬(1)
有没有可能存在一种情况就是,在分布式集群中,DataNode存了10G的数据,但是该节点服务器计算资源很少了(假设系统中已经有其他大数据应用在跑),其他DataNode也是存了10G数据,但是其他阶段计算资源都很充足,那最后是不是就导致了整个reduce操作都要等当前的map操作结束了才能执行,大大降低了整个程序的计算效率。
2019-11-03 - 李二木 👍(7) 💬(1)
强烈建议老师加餐一篇你对架构设计理解的文章。^^
2018-11-19 - 蜡笔小新 👍(6) 💬(1)
老师请教一下,MapReduce ApplicationMaster怎么计算出需要多少资源的呢?
2018-11-24 - 星凡 👍(5) 💬(1)
您好,请问一下,Yarn的工作流程中(以MapReduce为例)只会向ResourceManager申请两次容器资源吗,一次用来运行ApplicationMaster,一次用来运行MapReduce程序
2019-10-05 - hunterlodge 👍(5) 💬(1)
老师前面说"每个应用程序启动后都会先启动自己的 ApplicationMaster",后面具体mapReduce例子里又是先启动ApplicationMaster的,这不矛盾吗?
2018-11-19 - Mcnulty 👍(4) 💬(1)
前文中写道 3.JobTacker 根据作业调度策略创建 JobInProcess 树,每个作业都会有一个自己的 JobInProcess 树。 6. 如果 TaskTracker 有空闲的计算资源(有空闲 CPU 核心),JobTracker 就会给它分配任务。 可以理解为jobtracker 在服务器A上,负责整个job的调度,包括subjob的生成与分发。tasktracker在服务器B C D上,负责subjob的执行mapreduce。 本文中写道: 这种架构方案的主要缺点是,服务器集群资源调度管理和 MapReduce 执行过程耦合在一起,如果想在当前集群中运行其他计算任务,比如 Spark 或者 Storm,就无法统一使用集群中的资源了。 这里说的 服务器集群资源调度与mapreduce执行过程耦合,在前文中具体是怎么体现的呢?不太理解
2018-11-19