24 AIOps数据可靠性:如何预测磁盘故障
你好,我是白园。今天我给你分享一下AIOps在数据可靠性层面的案例,其中最重要的就是磁盘的故障预测,磁盘故障预测对于数据可靠性有着非常重要的意义。
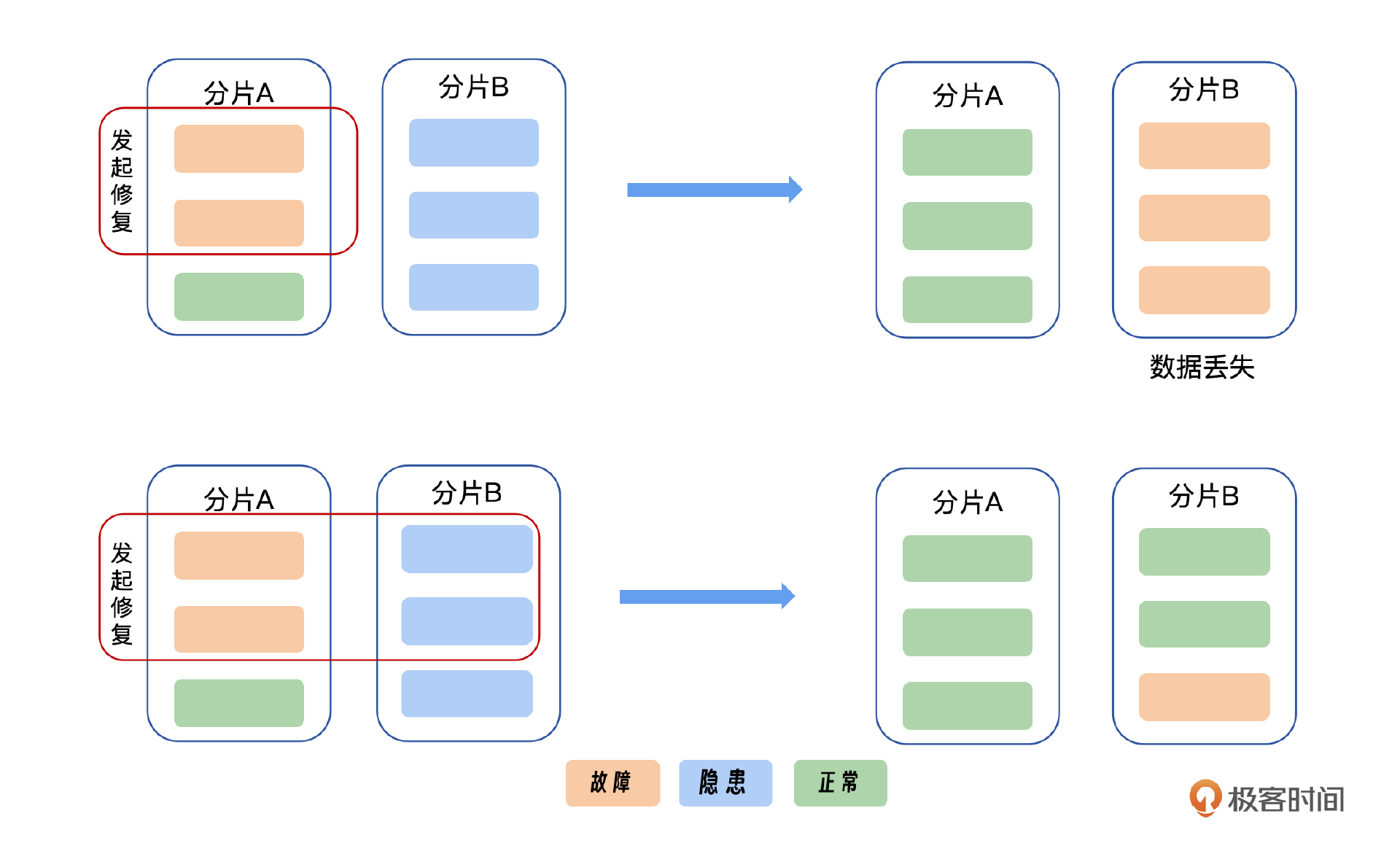
我们先来看百度网盘的一个场景,你可以看一下我给出的示意图。如果在第一时刻,分片A有两个副本出现故障,分片B有三个副本没有故障但是有隐患;如果没有磁盘故障预测的话,我们只会修复分片A的两个副本。然后第二时刻分片A完全修复,而分片B已经故障。这个时候分片B就会出现数据丢失的问题。
如果有磁盘故障预测的话,在第一时刻就会同时对分片A和分片B发起修复,然后完成修复,不会导致故障发生。所以如果能提前预测磁盘故障就会对数据可靠性有非常大的帮助。
如何实现上面的磁盘预测过程呢?我们从两个层面来看,一是算法和数据层面如何处理,二是工程层面如何处理。
算法流程
首先是算法和数据的处理,整体来说分为三个阶段。
- 数据获取:Smart信息、业务信息、其他信息
- 准备阶段:数据探索、数据规范化、数据集划分
- 决策阶段:模型创建、模型训练、模型评估
数据获取
在监测磁盘故障异常时,业界普遍采用磁盘的SMART(Self-Monitoring, Analysis, and Reporting Technology)信息来获取关键指标。然而,仅依赖SMART信息不足以全面反映业务性能。例如,即使磁盘的SMART预测显示正常,业务操作中的读写延迟已经显著增加,这种情况下,磁盘的实际表现已经受到影响,应被视为潜在故障。
为了更准确地评估磁盘状态,建议使用制造商提供的特定信息,并与业务表现数据相结合。虽然业界通常以SMART信息为主,但辅以其他数据,如业务操作中的读写延迟等,可以提供更全面的磁盘性能评估。这种综合方法有助于更准确地识别和预防潜在的磁盘问题,从而保障业务的连续性和稳定性。
准备阶段
在处理磁盘故障预测问题时,面临两个主要难点。
一是型号干扰问题:由于不同型号的磁盘具有不同的性能特性,建议在初期专注于单一型号的磁盘进行训练。这有助于减少模型在处理不同型号间差异时的复杂性。后续可以不断扩展型号来进行相关预测。
二是维度爆炸问题:磁盘的SMART信息本身就包含了数百个维度,如果再结合业务信息和其他相关数据,维度数量会急剧增加。为应对这一挑战,建议采取以下步骤:
-
初步筛选:首先,忽略多维度组合的影响,专注于单个维度的分析。通过计算故障和正常磁盘的基尼系数,识别出最有区分度的特征维度。
-
计算基尼不纯度:对于数据集中的每一个特征,计算其基尼不纯度。基尼不纯度可以通过以下公式计算:$$[ GiniImpurity(D) = 1 - \sum_{i=1}^{n} (p_i)^2 ]$$,其中 $$( D )$$ 是数据集。$$( n )$$ 是数据集中类别的数量。($$p_i )$$ 是数据集中第 ( i ) 个类别的样本比例。基尼不纯度的值介于 0 到 1 之间。值为 0 表示数据集是纯的(所有样本都属于同一个类别),值为 1 表示数据集是完全混合的(样本均匀分布在所有类别中)。
- 特征排序:将所有特征按照它们的基尼不纯度进行排序。基尼不纯度越低的特征,其排序越靠前。
- 选择特征:选择基尼不纯度最低的特征作为最有区分度的特征。这些特征可以用于后续的分类模型训练,因为它们在区分故障磁盘和正常磁盘方面最为有效。
我们来看一个示例,这个示例使用了模拟数据。
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
# 创建一个模拟数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=42)
# 初始化决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X, y)
# 获取特征重要性
importances = clf.feature_importances_
# 按重要性排序特征
indices = np.argsort(importances)[::-1]
# 打印每个特征的基尼不纯度和重要性排名
print("Feature ranking (Gini Importance):")
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
# 选择最有区分度的特征维度
top_features = indices[:5] # 假设我们选择前5个最重要的特征
print("\nTop features for distinction:")
print(top_features)
在实际应用中,你需要用你的故障磁盘和正常磁盘的数据集替换X和y变量。此外,你可能需要调整 DecisionTreeClassifier 的参数,以获得更好的模型性能。
- 降维处理:去除那些对故障判断贡献较小的干扰维度,形成一个最小但有效的特征集。如果维度依然过多,建议进一步降低维度至20个以内,以减少资源消耗并避免过拟合的风险。可以使用常见的机器学习降维技术,如主成分分析(PCA)或线性判别分析(LDA),来帮助减少数据的维度。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.decomposition import PCA
from sklearn.metrics import accuracy_score
# 加载数据集到DataFrame中,名为df
df = pd.read_csv('your_dataset.csv')
# 分离特征和目标变量
X = df.drop('target', axis=1) # 假设目标变量列名为'target'
y = df['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用决策树计算特征重要性
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# 选择特征
selector = SelectFromModel(clf, prefit=True)
X_train_selected = selector.transform(X_train)
X_test_selected = selector.transform(X_test)
# 检查选择后的特征数量
print(f"Number of features after selection: {X_train_selected.shape[1]}")
# 如果特征数量仍然超过20,使用PCA进行降维
if X_train_selected.shape[1] > 20:
pca = PCA(n_components=20)
X_train_pca = pca.fit_transform(X_train_selected)
X_test_pca = pca.transform(X_test_selected)
else:
X_train_pca = X_train_selected
X_test_pca = X_test_selected
# 重新训练模型
clf.fit(X_train_pca, y_train)
# 预测和评估模型
y_pred = clf.predict(X_test_pca)
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
# 打印选择的特征
selected_features = X.columns[selector.get_support()]
print("Selected features:", selected_features)
your_dataset.csv
feature1,feature2,feature3,feature4,...,target
100,200,300,400,...,0
150,250,350,450,...,1
120,220,320,420,...,0
130,230,330,430,...,1
90,190,290,390,...,0
...,...,...,...,...,...
在进行数据分类时,我们需关注几个关键指标来评估分类模型的性能。首先,我们区分两种极端情况:所有实例都被分类为正类(全正)或所有实例都被分类为负类(全负)。然后,我们对比正类和负类的分类结果。对于一个二分类问题,存在四种结果。
- 真正类(True Positive, TP):实例实际属于正类,并且被模型正确预测为正类。
- 假正类(False Positive, FP):实例实际属于负类,但被模型错误地预测为正类。
- 真负类(True Negative, TN):实例实际属于负类,并且被模型正确预测为负类。
- 假负类(False Negative, FN):实例实际属于正类,但被模型错误地预测为负类。
决策阶段
在磁盘故障预测领域,多种算法已被成功应用,包括逻辑回归(LR)、随机森林、决策树等传统机器学习方法。此外,随着人工智能技术的发展,深度学习算法也逐渐被引入,以利用其在处理复杂模式识别方面的强大能力。这里我们选择随机森林算法进行模型构建,因其在处理大量特征和捕捉非线性关系方面表现出色。所使用的数据集基于S.M.A.R.T.指标,这是一种广泛认可的硬盘健康指标集合。当然你可以根据具体业务需求和数据可用性,进一步扩充数据集,以增强模型的泛化能力和预测精度。
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler
# 假设有一个包含SSD SMART属性的数据集
# 特征:[擦写次数, 读取错误率, 平均温度, ...]
# 标签:是否发生故障(0表示正常,1表示故障)
data = [
[high, normal, warm, ..., 0], # 正常
[very_high, high, hot, ..., 1], # 故障
# ... 更多数据
]
# 提取特征和标签
X = np.array([item[:-1] for item in data]) # 特征集
y = np.array([item[-1] for item in data]) # 标签集
# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建随机森林分类器实例
clf = RandomForestClassifier(n_estimators=100)
# 训练模型
clf.fit(X_train, y_train)
# 进行预测
y_pred = clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy}")
print(classification_report(y_test, y_pred))
# 使用模型进行实时预测
# 假设有一个新的SSD SMART数据点
new_ssd_smart_data = [some_wear_count, some_read_error_rate, some_temperature, ...]
new_ssd_smart_data_scaled = scaler.transform([new_ssd_smart_data])
predicted_fault = clf.predict(new_ssd_smart_data_scaled)
print(f"预测结果: {'故障' if predicted_fault[0] == 1 else '正常'}")
请注意,这个示例代码是一个简化的版本,实际应用中需要收集真实的SMART数据,并根据数据的特性选择合适的特征和模型参数。此外,模型的评估和优化需要更复杂的技术,如特征重要性分析、模型调参和集成学习等。
工程实现
这里我分享一下关于磁盘故障预测及数据修复部署的综合策略。只依赖于磁盘故障预测是不足以确保数据安全的。在实际应用中,如果预测模型识别出大量潜在故障的磁盘,而同时触发大规模的数据修复操作,这可能会导致资源过载,从而增加数据丢失的风险,并可能引发更广泛的系统性问题。
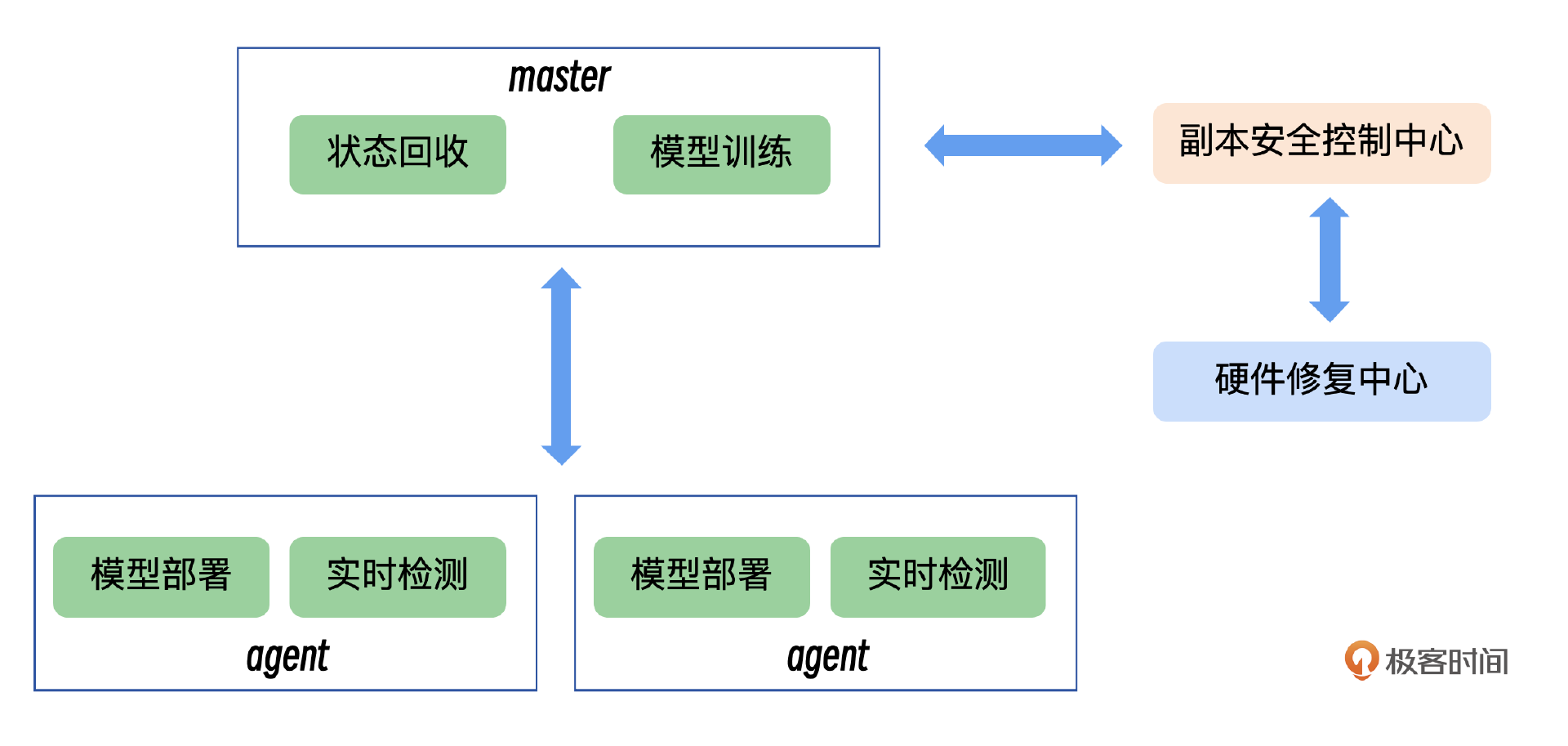
因此我把磁盘故障预测与数据修复的联动机制分为三个关键部分:磁盘故障预测中心、副本安全控制中心、数据修复决策。通过这三个部分的协同工作,可以有效地预测和应对磁盘故障,确保数据的安全性和业务的连续性。
磁盘故障预测中心:该中心的核心任务是分析和预测即将发生故障的磁盘。通过对磁盘性能数据的实时监控和分析,该中心能够提前识别出潜在的故障风险。也就是这节课的重点部分。
采用集中式训练方法,将训练完成的模型部署到各个单机上。这样,每个单机都能够利用该模型进行本地的磁盘故障预测。这个策略的优势在于:集中训练可以充分利用所有可用数据,提高模型的泛化能力。通过在单机上进行预测,可以分散计算负载,避免对集中式系统的过度依赖。
通过这种部署方式,我们能够实现高效的资源利用和快速的故障响应。
- Master:使用历史数据进行模型训练。同时负责整个流程的协调和管理。模型的更新和部署,系统将处理后的数据或模型结果进行存储,供后续分析或使用。
- client:把训练出来的模型部署到了每台机器上进行磁盘故障的预测,模型对实时磁盘的进行检测或分析。
副本安全控制中心:一旦磁盘故障预测中心检测到潜在故障,副本安全控制中心将立即介入。该中心负责评估故障磁盘对当前副本数量的影响,并制定相应的数据修复策略。它将综合考虑以下因素:
- 磁盘故障对副本数量的潜在影响;
- 需要采取的修复措施的优先级和力度;
- 回收和维修过程中的资源分配和调度。
数据修复决策:在磁盘故障发生后,数据修复决策部分将迅速启动。它负责决策哪些数据需要优先修复,并快速启动修复流程。这包括:
- 确定故障磁盘上的数据重要性和紧急程度;
- 选择最合适的修复方法和工具;
- 监控修复进度,确保数据的完整性和可用性。
小结
本次课程中,我们重点讲解了磁盘故障预测技术,这一技术对于存储系统的稳定性和数据可靠性至关重要。它通过结合硬件数据与业务数据,增强了数据的安全性和可靠性。
在数据处理层面,我们采用了硬件与业务数据的复合模型,以确保全面性。在算法选择上,我们有多种预测算法可供实施,以适应不同的应用场景和需求。
在工程实施方面,我们采取了集中式训练和单机检测的模型架构。此外,为了进一步提升数据保护的安全性,我们的系统还需要与副本安全控制中心和数据修复决策中心紧密协作,从而为数据安全提供多层次的保障措施。
在选择模型时,可以考虑以下因素:
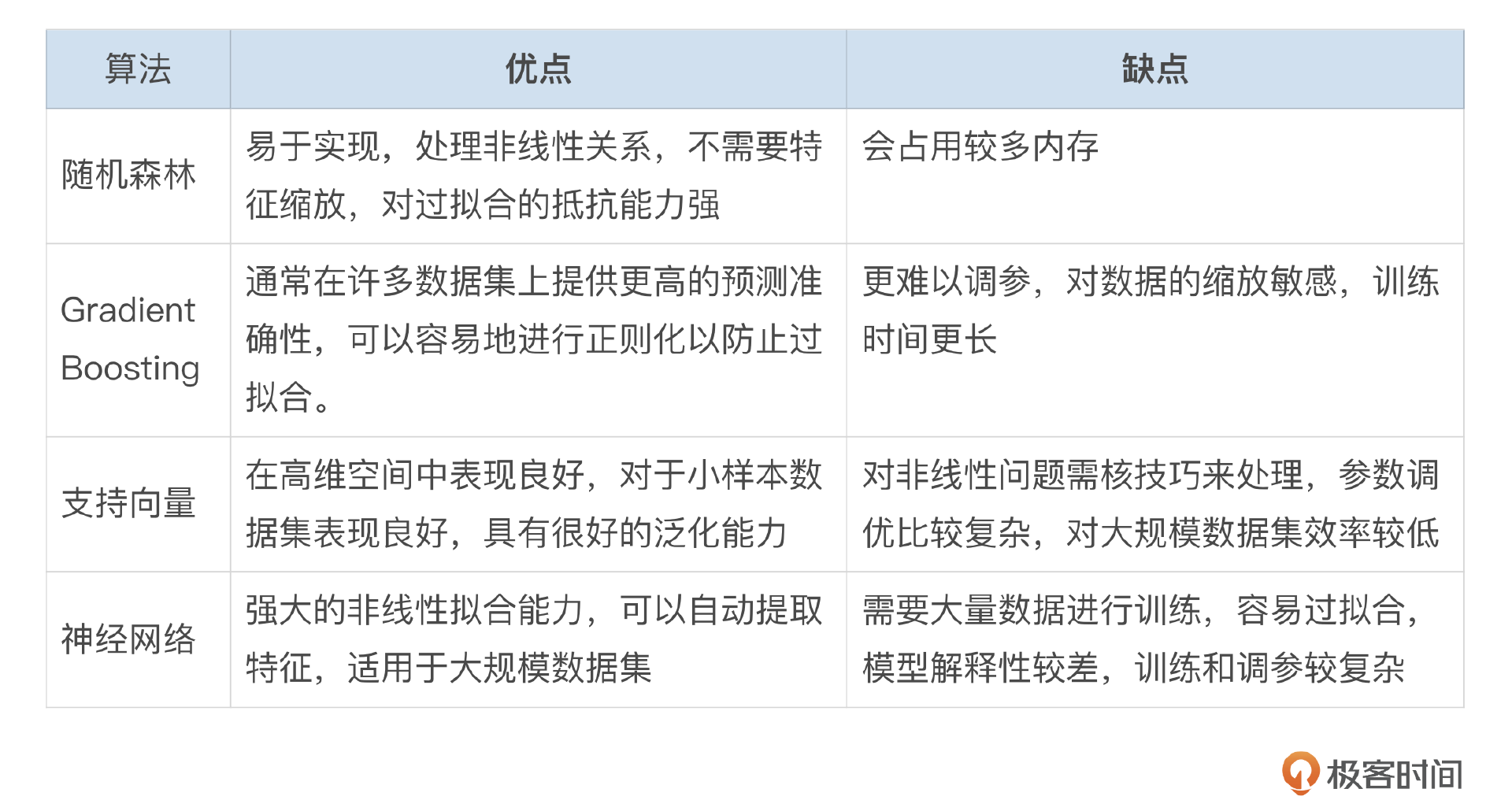
- 数据规模:数据量小的情况下,不需要复杂的模型。
- 特征类型:线性特征更适合逻辑回归或SVM,非线性特征更适合树模型或神经网络。
- 模型解释性:如果需要模型的决策过程易于理解,更推荐你使用决策树或随机森林。
- 训练和预测时间:对于需要快速预测的应用,选择训练和预测速度快的模型。
- 模型复杂度:简单模型通常更容易维护和更新,但在预测准确性上有所妥协。
通常,建议在实际应用中尝试多种模型,并通过交叉验证来评估它们的性能,选择在特定数据集上表现最好的模型。此外,模型选择也应考虑实际业务需求和资源限制。
思考题
其实SSD和HDD的磁盘故障预测还是有明显不同的,你可以想一想不同的地方在哪里,以及为什么。欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!