23 AIOps智能决策:给故障处理安装一个大脑
你好,我是白园。
今天,我想跟你讨论AIOps中最复杂的场景——如何决策。前面所有的场景我们都是在讨论如何去预测,包括问题发现、容量预测、故障定位,但是没有告诉你应该怎么办。今天我们就看看怎么能把预案列表和决策建议结合起来构建一个运维大脑。
之前我们讨论了如何设计和执行应急预案,但我们并没有深入探讨在哪种情况下选择执行哪个预案最为合适。目前,在面对故障的时候,我们选择执行特定预案通常需要人工进行决策和判断。这节课我们就来展示如何利用智能技术来实现这一决策过程。
为什么需要一个大脑?
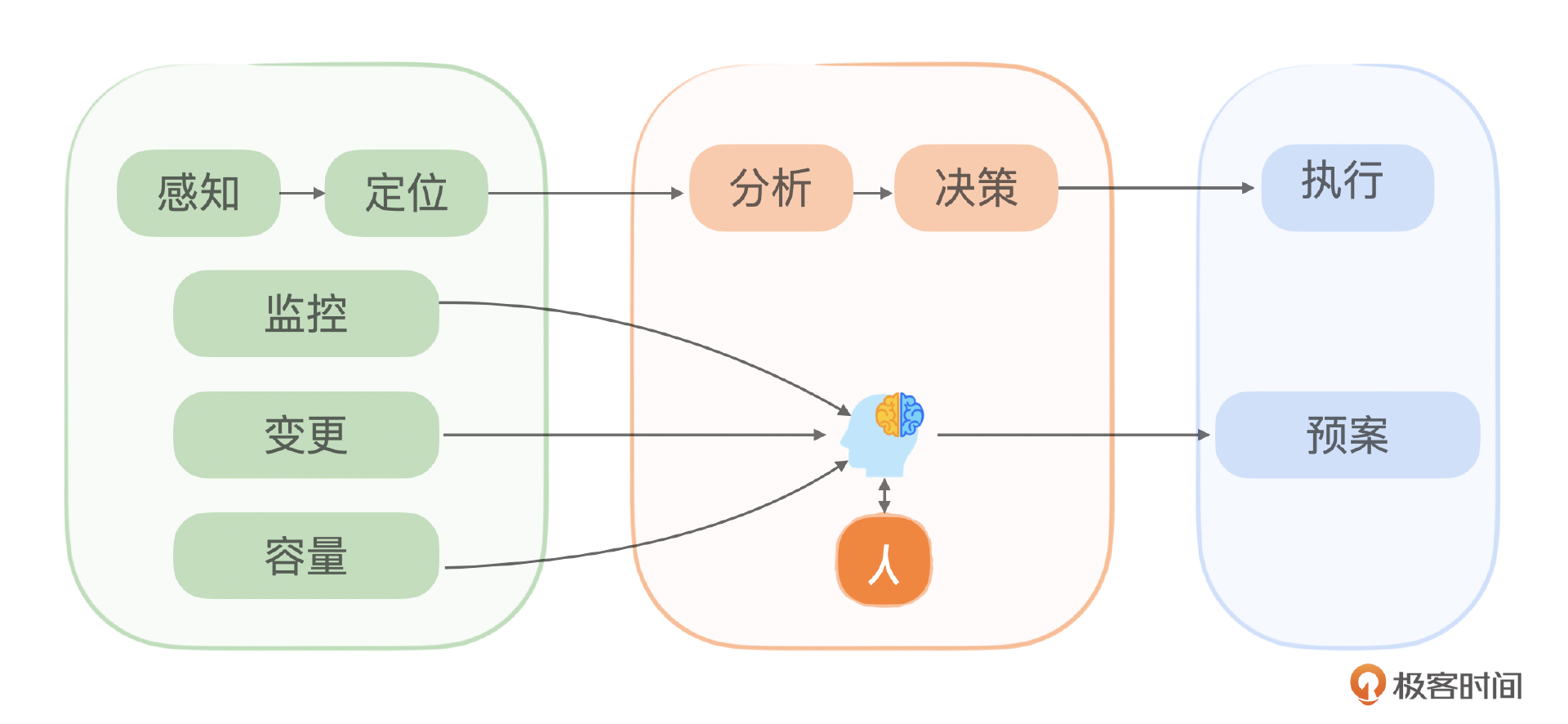
在服务可靠性领域,目前依赖人工来协调监控、容量规划、预案制定和变更管理等关键环节,个人经验直接影响故障处理的效率。这正是我们所说的运维大脑。我们可以把监控比作眼睛,发现问题;预案比作四肢,解决问题。但还需要一个中央系统来整合这些功能,进行分析和决策。
从历史的重大故障案例中我们发现,虽然重要的故障往往难以预测,但决策过程是不能缺少的。特别是在处理关键故障时,现场决策能力成为故障恢复的主要制约因素。因此一个快速而准确的决策往往能起到最终决定性的作用。
但人的经验、临场判断能力比较是有限的,因此需要AI来辅助我们做出判断和决策。你可以看一下示意图,大脑的作用在于对初步问题分析和决策,告诉人员应该执行哪个预案,什么时候执行,执行带来的后果是什么。
决策过程的演进
我们先看之前遗留的一个问题:单机房故障的时候如何做出最优化决策。我先把我之前经历的几次决策分享给你。
我们先来了解系统架构。当时的业务采用双可用区(AZ)设计。考虑到成本,常规运行时的峰值容量只设定为120%,这意味着单个可用区只能承载60%的峰值流量。在流量低谷的时候,能够进行全量流量切换。然而,在高峰时段,只能根据当时的容量进行流量切换,并需要立即进行扩容。扩容过程大约需要20分钟,完成后才能继续进行下一步的切量工作。
我们来看一下最终决策分支情况。
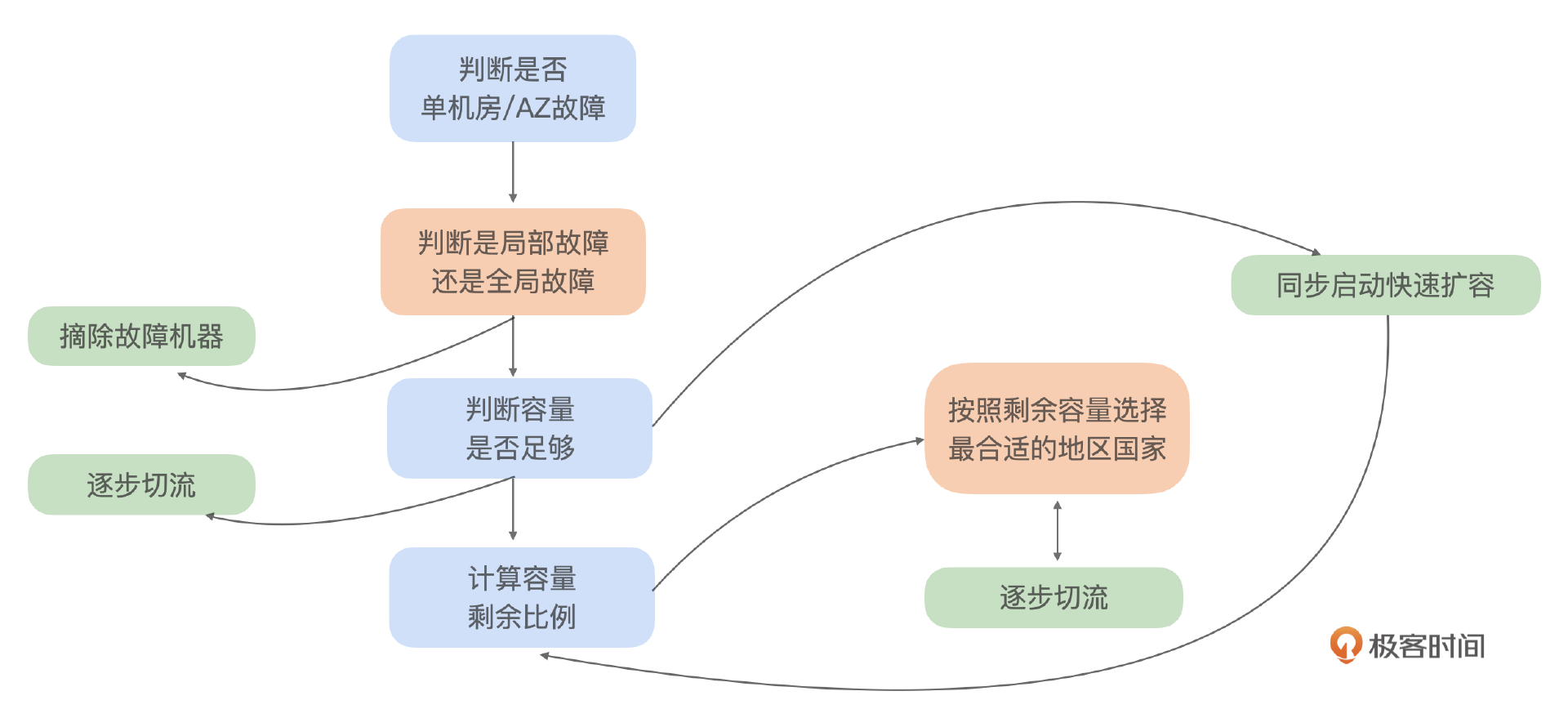
乍一看这个决策过程是非常复杂的,那么我想解释一下这个决策过程是如何形成的。 这里我们要遵循两个原则。
- 原则一:从业务视角出发来选择最优解决方案。
- 原则二:从实际案例出发,从已经发生的案例来分析,不去想当然。
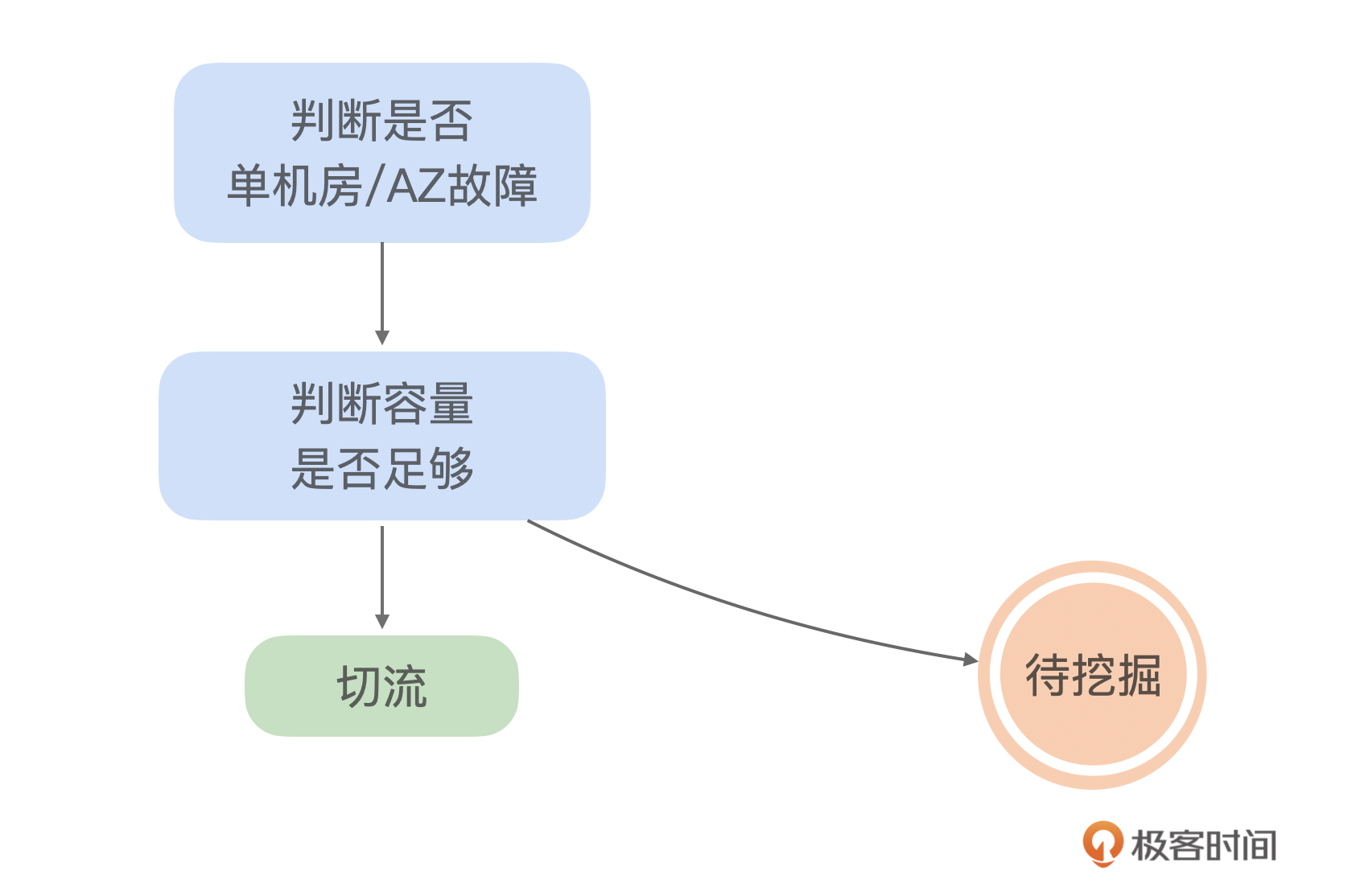
有一天,某个可用区的流量下降,失败率大量报警。这个时候我们先做了一个判断,是否只有一个可用区异常,另一个可用区是否正常。因为这个关系到是否能切流。后来发现确实只有一个可用区异常,这个时候需要做二次判断。判断容量第二个可用区的容量是否足够,幸运的是故障发生在流量低峰期,容量足够,所以我们很快通过切流来进行止损。 这次的决策和操作时间非常快,大概花了5分钟时间。
我们从这个案例里可以看到最简单的就是决策是否,也就是一个分类问题。
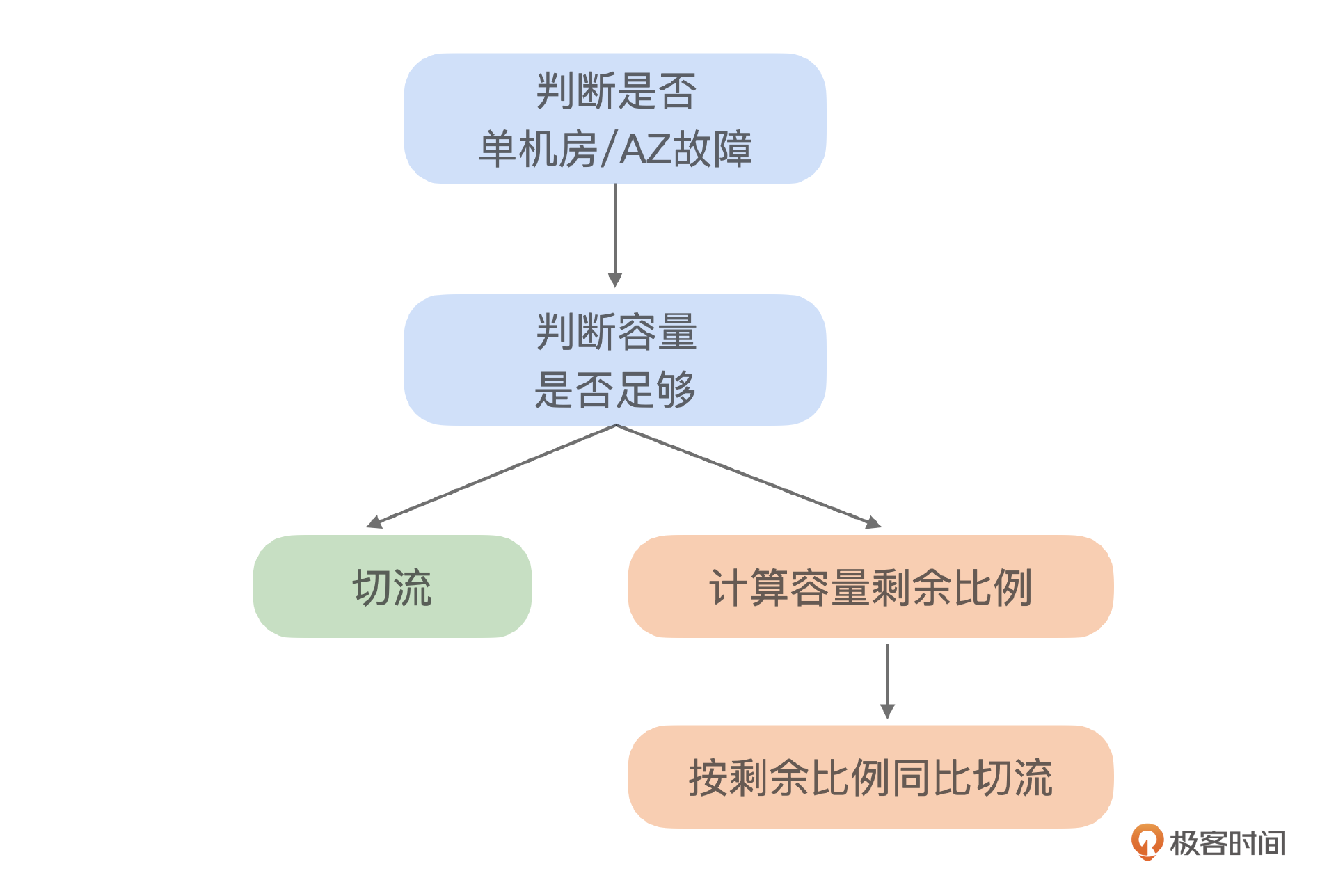
后来随着时间的推移,我们再次遇到了类似的问题,但这次是在流量高峰期。由于容量限制,我们只能把流量部分转移到另一个可用区。剩余流量需要等待系统扩容后才能继续切流。在这一过程中,决策过程耗时约10分钟,主要因为需要现场评估并计算可以转移多少流量,这增加了决策的复杂性和时间。这个时候决策问题从是否变成了多少。从分类问题变成了回归问题。
在回顾先前案例的时候,我们发现单纯按比例进行流量切换并不是最佳策略。业务需要优先保障特定地区用户的需求。具体来说,我们有三个关键地区:A、B和C,其中A地区的用户需求最为紧迫,其次是B和C。因此,我们的决策不再是简单地决定切换流量的数量,而是需要优化选择,确定哪些地区的用户应优先获得服务。这就把问题切流比例转变为一个更为复杂的最优化问题,需要综合考虑各地区的重要性来选择。
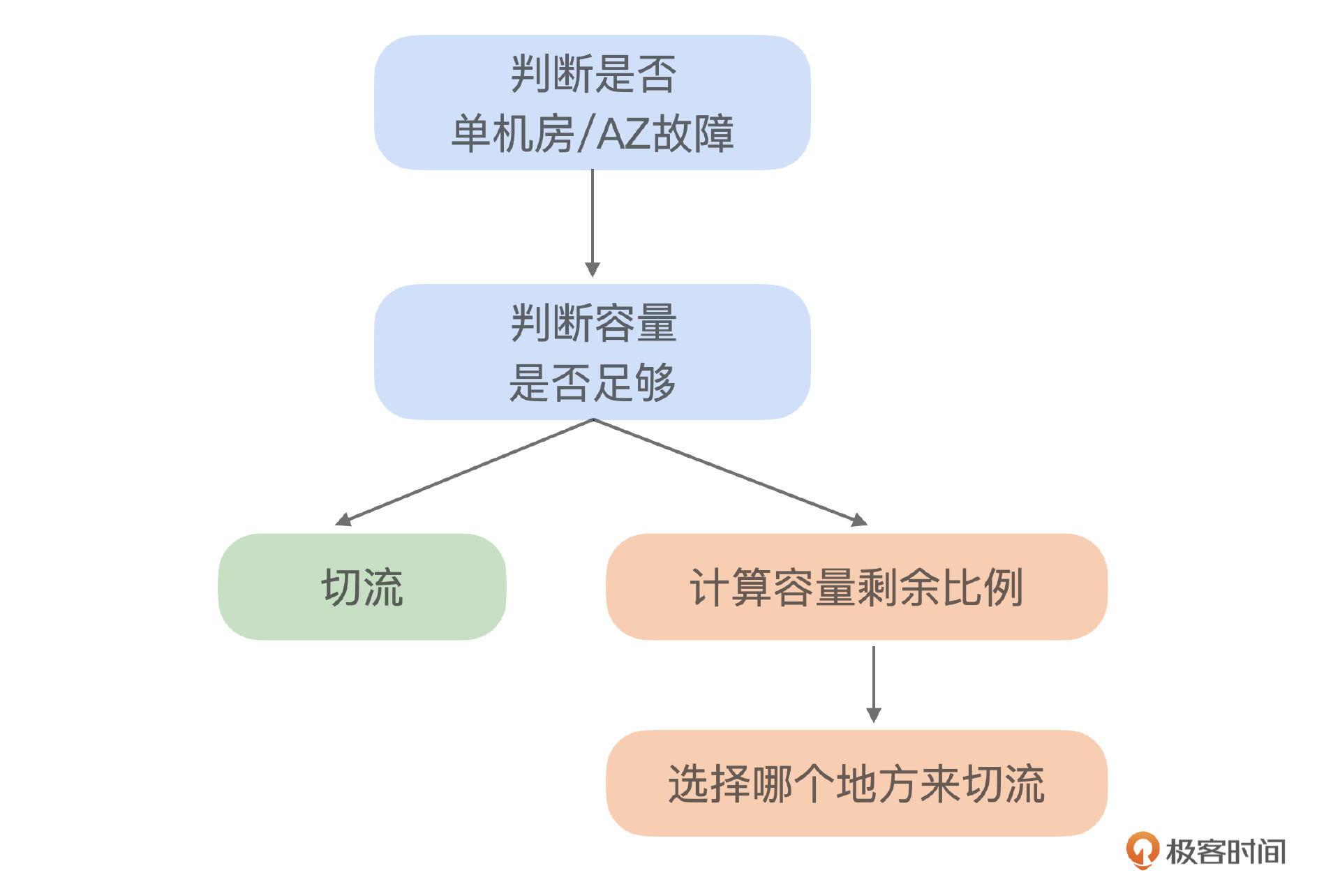
在进一步的优化过程中,我们发现如果流量切换过快,而系统扩容速度跟不上,可能会导致服务过载,甚至引发连锁反应,造成服务雪崩。为了避免这种情况,我们采取了分阶段的流量切换策略。在扩容的同时逐步进行流量切换,这个问题升级为一个多阶段的决策问题。
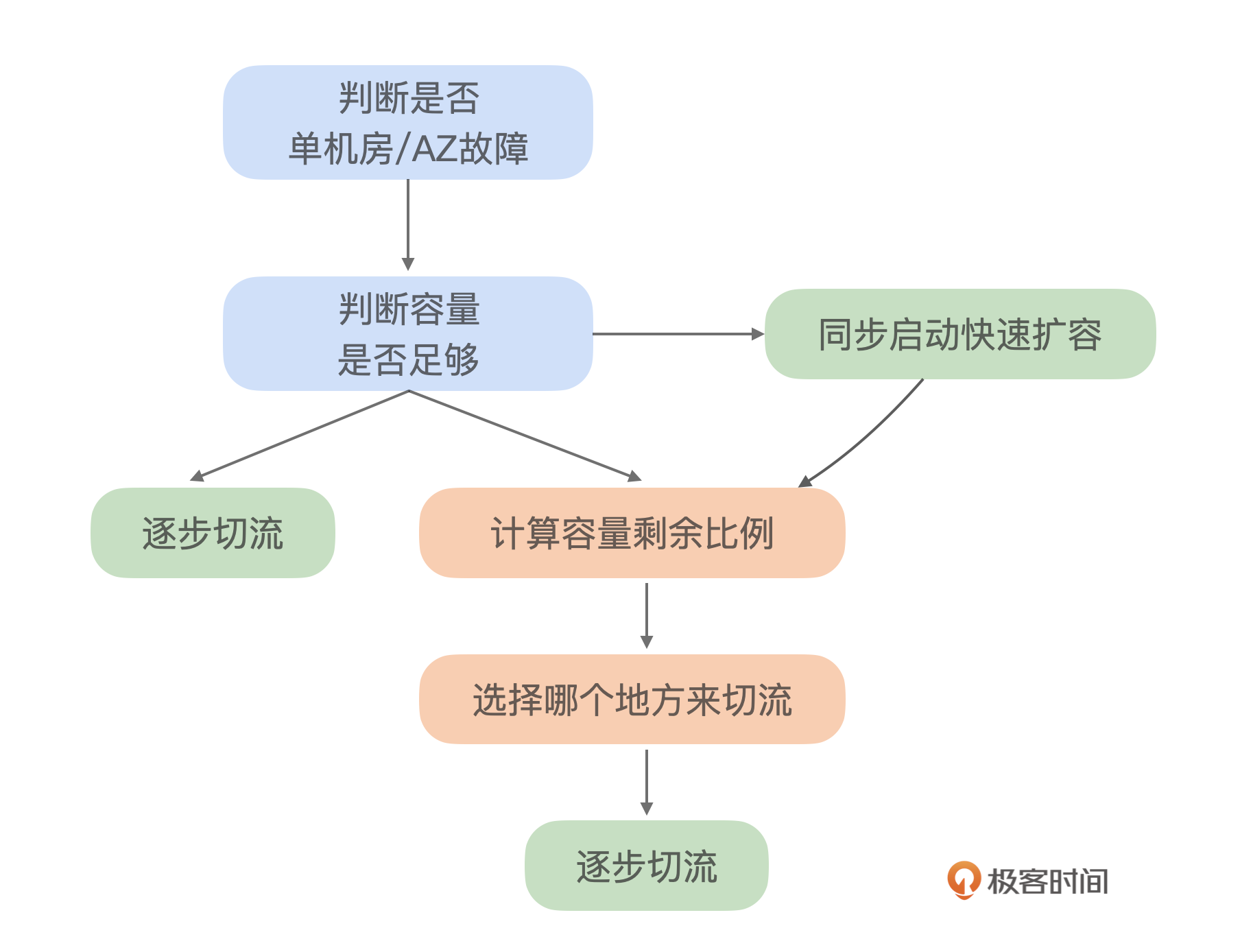
后来我们再次遇到问题,这次故障只影响到了部分机器,但这些机器位于系统的关键节点,影响几乎等同于全机房故障。面对这种情况,最合理的应对措施是迅速把这些故障机器从系统中摘除。这样就可以避免了因流量切换引发的容量紧张问题,同时能最大可能保证用户体验。因此,决策的核心问题转变为如何快速定位故障机器、分析其影响,并做出摘除决策。这个就演变成了定位、分析和决策三者融合的综合问题。
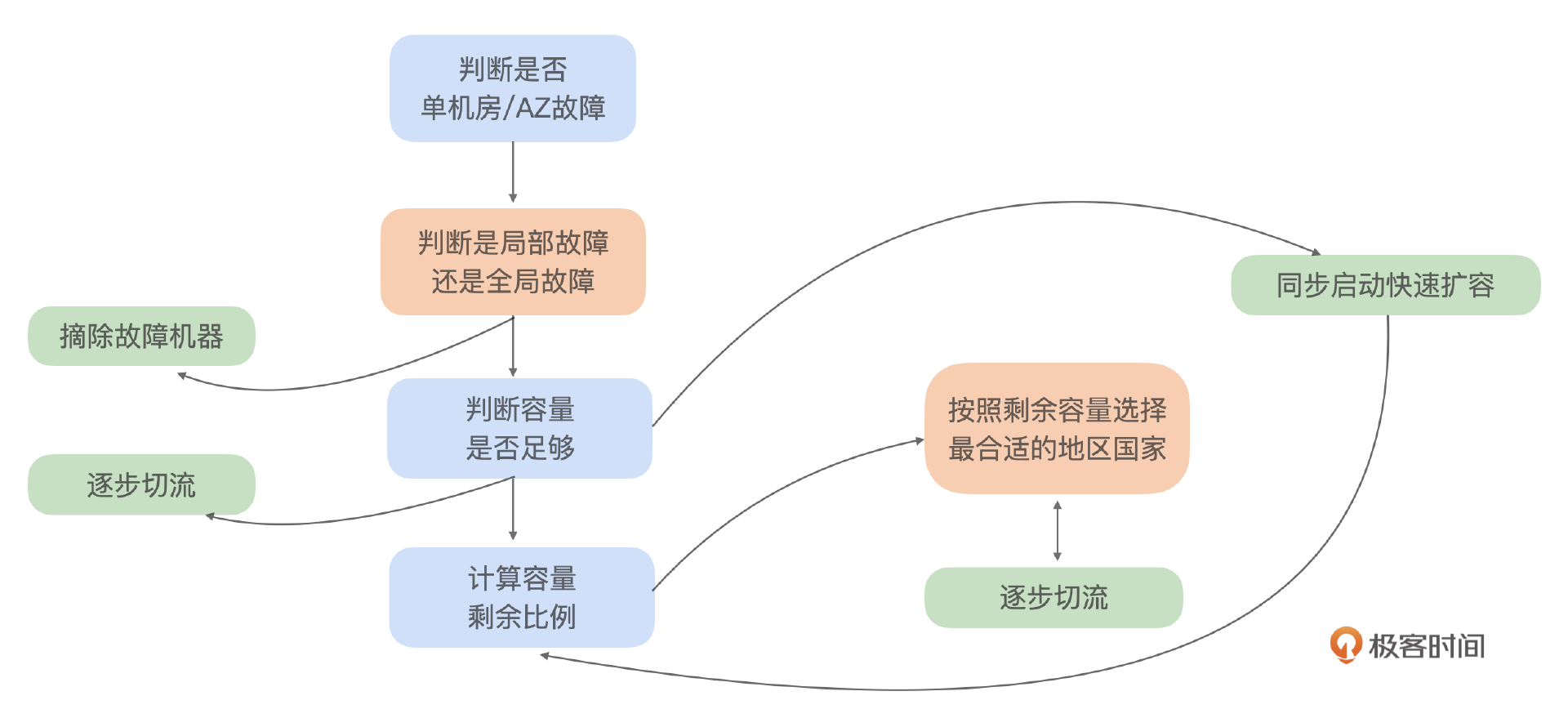
我们可以看到决策从易到难依次是:是否切流->切流多少->切流哪个国家->什么时候开始启动切流->先定位后分析再决策。所以我们的决策整体思路就是尽可能把复杂的问题变成简单的,拆分成几个简单的问题再进行判断。

决策中常见的算法
算法一:构建一棵你自己的决策树
我想强调的是,决策树是一个广泛的概念,它不局限于机器学习中的特定算法,如ID3或C4.5。实际上,任何形式的逻辑树,包括基本的if-else语句,都可以视为决策树的一种形式。最关键的是找到能够准确、高效解决实际问题的方法。
对于机器学习中的决策树,它们依赖于大量的数据来进行训练和模型拟合。这种方法能够从数据中学习并做出泛化的决策,适用于处理复杂的模式识别任务。相比之下,使用if-else逻辑构建的决策树通常基于程序员预先定义的规则。这种方法在处理已知情况时表现良好,但可能无法适应未预见的情况,因为它缺乏从数据中学习的能力。
我的建议是在项目的初期阶段,可以使用if-else逻辑来快速构建和测试解决方案。随着项目的发展,当积累了足够的数据和案例后,可以考虑利用机器学习算法的能力来进行更深入地训练和模式抽象。这种方法可以帮助我们将决策逻辑从具体的代码中抽象出来,提高模型的适应性和可扩展性。
算法二:回归预测
这里最基本的线性回归其实就可以解决大部分的问题。比如我们要计算当前的容量水位,和可以迁移多少的流量过来,就可以利用线性回归的算法。这里你可以参考AIOps容量部分。
算法三:线性规划
线性规划也是一个在运筹学和凸优化中非常常见的算法,但实现的成本会非常高。一般我们会采取折中的算法,比如贪心算法来代替。比如在刚刚案例中,有A、B、C三个地区都需要止损和切流,虽然在战略上A地区要高于B,然后高于C。但是实际来说是A地区核心功能>B地区核心功能>A地区的非核心功能>B地区和非核心功能,这里功能可能有十几个,每个排序都不一样。如果要实现这个问题的最优化,就是把它看作一个在线规划的问题。这里我们在工程上通常简化为A地区>B地区,直接用贪心算法来实现,也就是优先切A,尽可能完成A的止损再切B,然后是C。
运维大脑落地实践
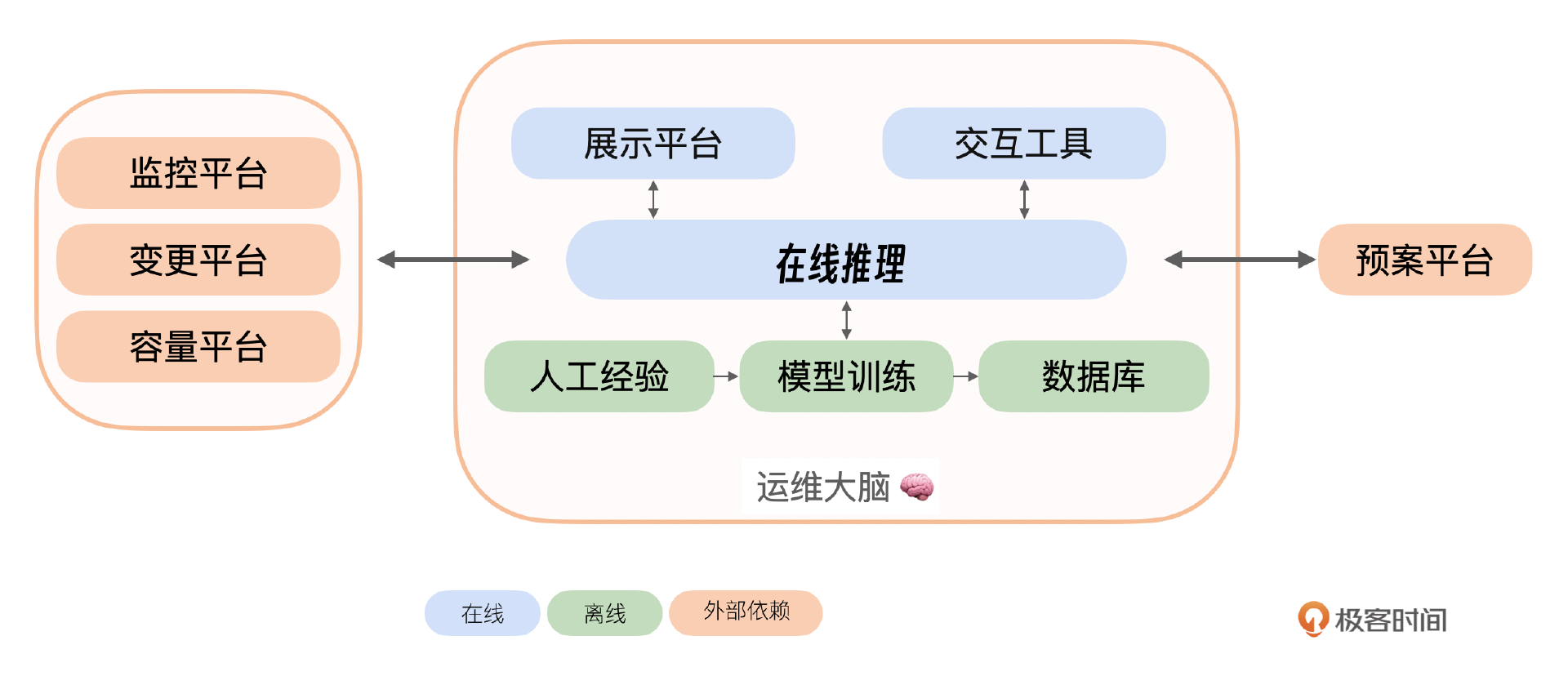 这里可以把运维大脑分为在线部分和离线部分两大部分。在线部分包括展示平台、交互工具、推理部分。离线部分包括把数据和人工经验训练成模型并保存到数据库中。
这里可以把运维大脑分为在线部分和离线部分两大部分。在线部分包括展示平台、交互工具、推理部分。离线部分包括把数据和人工经验训练成模型并保存到数据库中。
展示平台
首先是展示部分,这个跟监控最大的区别就是结论和分析部分展示处理。
我们来回溯一下之前第19讲留下的第二个问题。为了提升业务监控的效率和效果,我们可以在传统的业务监控曲线展示之外,引入一个智能模型。这个模型的职责是对监控和报警数据进行深入分析和总结,并将分析结果以结论的形式反馈到监控界面。这样一来,当我们查看监控时,不仅能看到各种数据曲线和报警信息,还能直接获得关键的分析结论,这会大大地提高我们对系统状态的理解和响应速度。
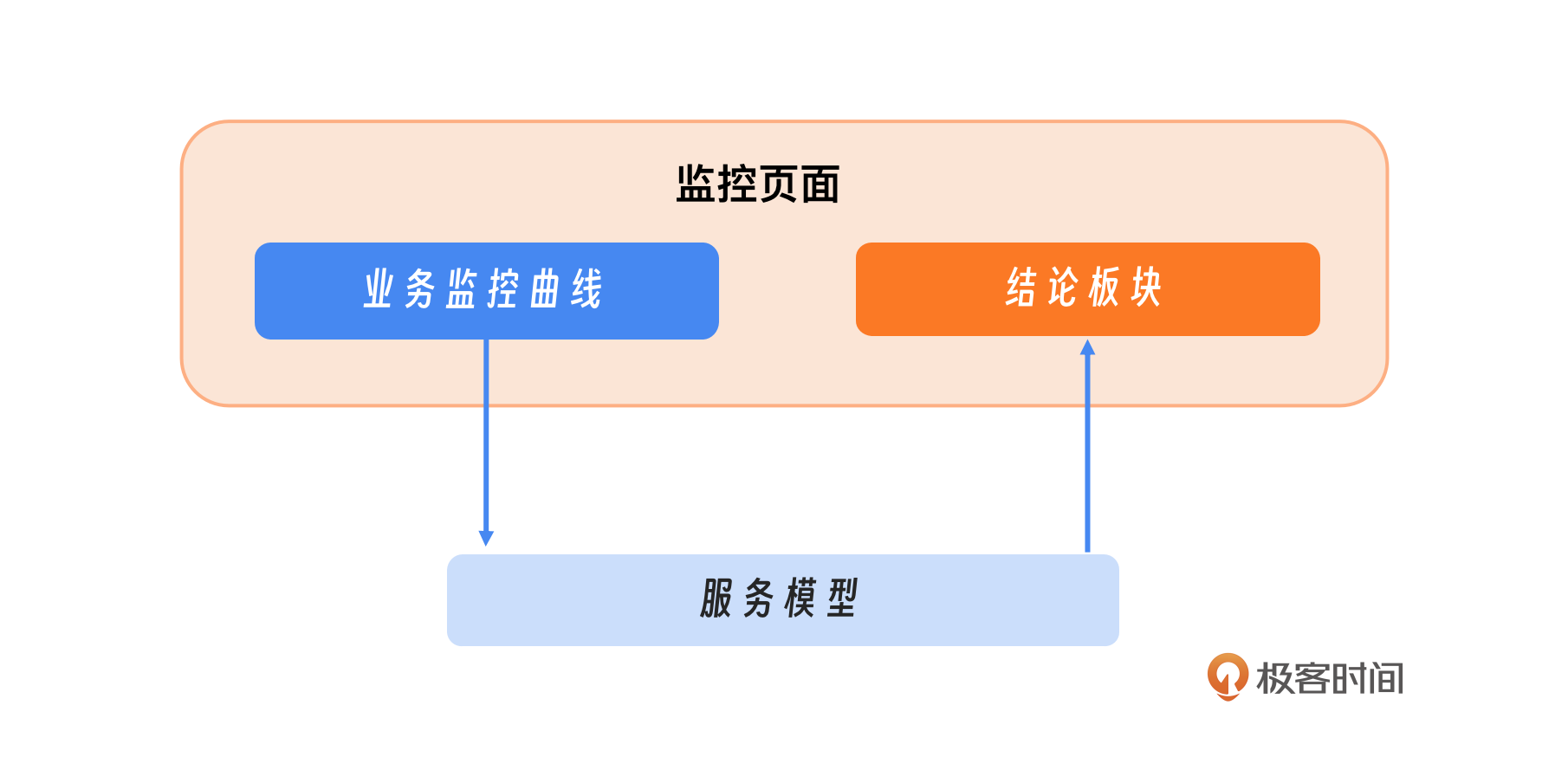
想想为什么需要这样一个结论板块呢?就是为了加速整个决策过程。接下来我们看看如何实现,这个板块展示哪些信息呢?首先要做的是影响面的分析,其次定位到具体哪个服务,再定位具体的事件和范围,最后根据实际情况给出推荐的预案。
我们来看一下机房规模的故障结论板块:规模判断,1024台机器发生故障,机房占比60%,故障规模属于机房级别。
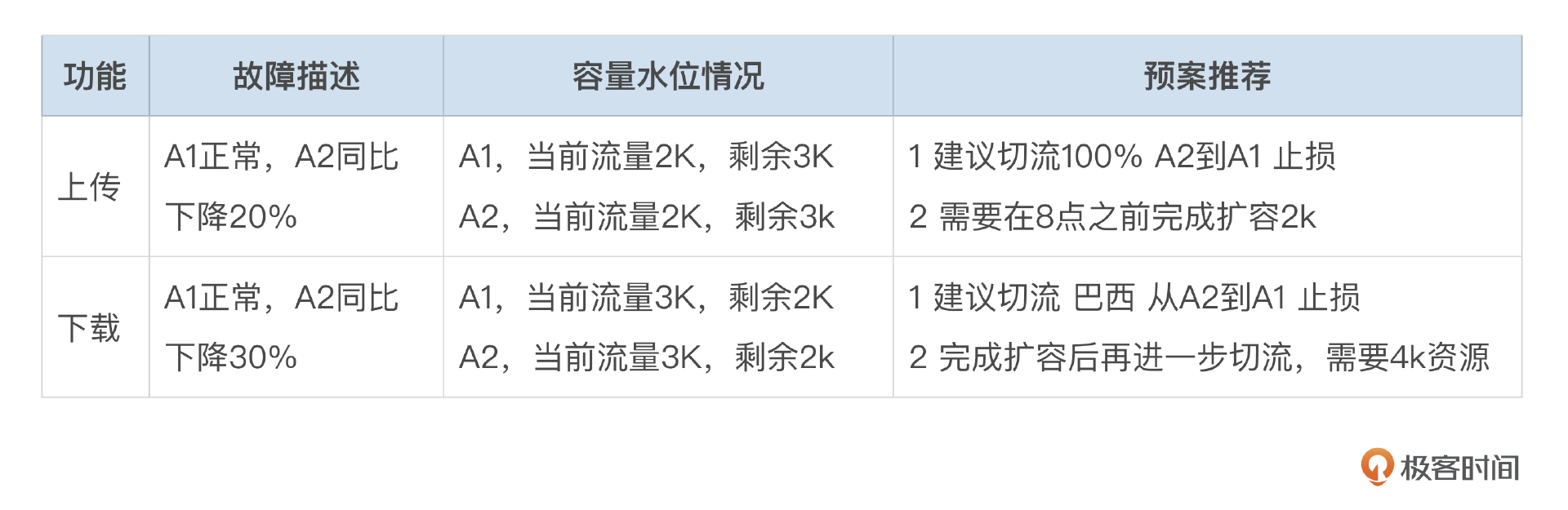
我们再来看一下局部规模的板块结论:规模判断,10台机器发生故障,机房占比1%,故障为局部级别故障。
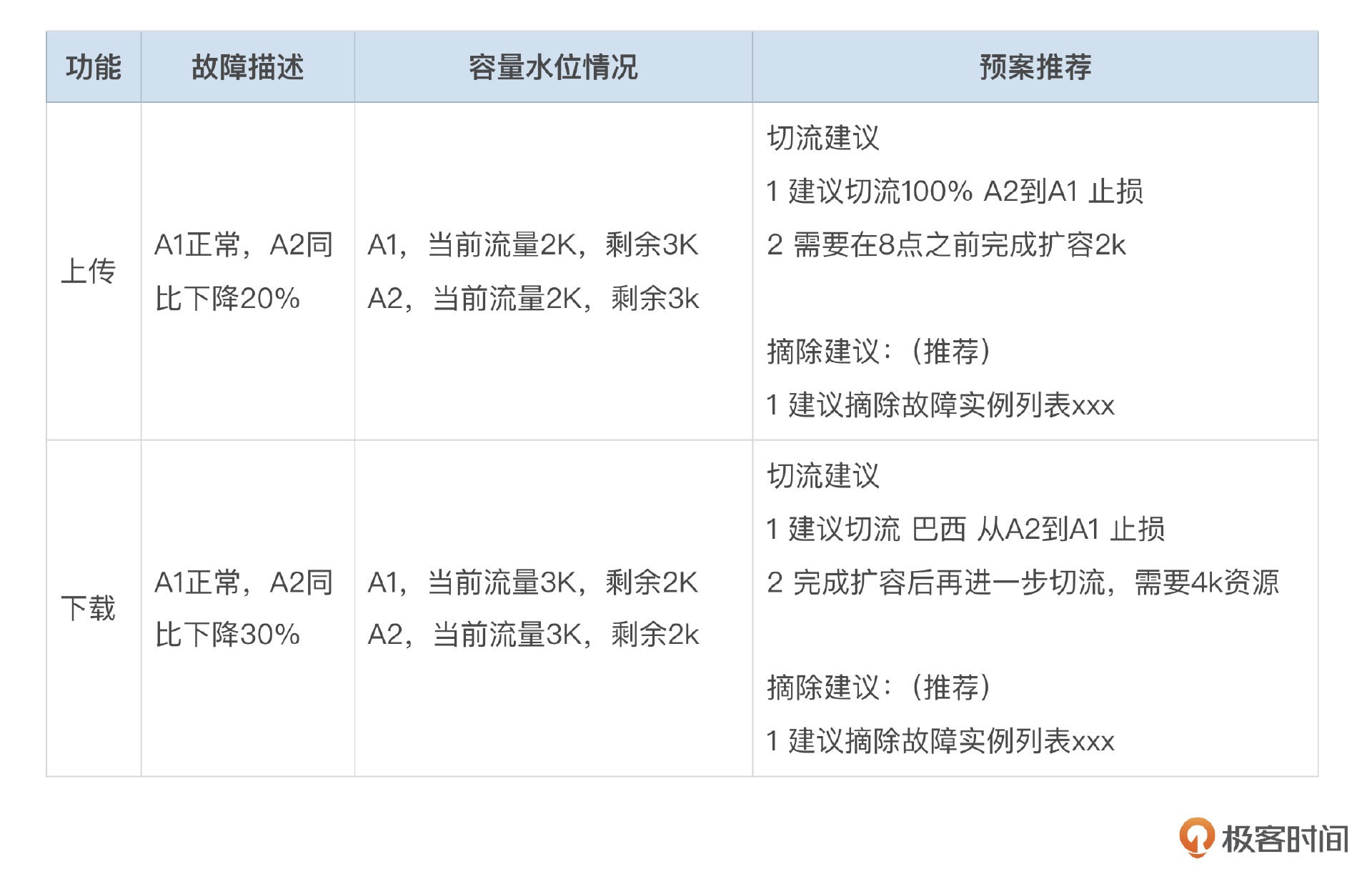
结论:从功能视角给出建议
交互工具
只有展示平台是不够的,因为展示平台只能读,却无法进行反馈和交互。这里就需要一个交互工具。这里就是我们常见的小助手工具。比如运维小助手,我们可以定义语义去进行交互和反馈。比如可以在群里 @运维小工具 执行相关的动作。如果是展示、分析、定位、辅助决策比监控平台会更加高效。
在线推理
- 权限验证策略:必须实施细致的权限验证机制,确保不同用户根据其角色获得相应的控制权限,包括数据查看权限和操作权限等级别。
- 语义分析处理:对系统中的决策制定、信息展示和用户反馈等各个环节进行深入的语义分析,确保信息的准确性和相关性。
- 结果数据展示:实时计算和展示,实时计算决策的结论。结合当前的容量状态、关键指标水位,并综合考虑故障情况。同时结合历史决策模型,动态输出分析结果,以提供决策支持。
离线训练
离线训练就是需要把上面的决策过程沉淀出来一个决策模型,并存储起来。我们需要对历史上的故障都沉淀出来相应的决策模型。并通过综合的判断,不断扩展不同的情况。这个就像是神经元的扩展和激活的过程。不断扩大和健壮自己的大脑。这里我提供一段伪代码供你参考。
class FaultHandler:
def __init__(self):
self.capacity = 100 # 初始容量设置为100
def is_single_az_fault(self):
# 模拟判断是否单AZ故障
# 这里需要根据实际情况实现具体的逻辑
return True
def is_partial_fault(self):
# 模拟判断是否局部故障
# 这里需要根据实际情况实现具体的逻辑
return False
def remove_faulty_machine(self):
print("故障机器已被摘除。")
def quick_scale_up(self):
print("正在同步启动快速扩容。")
def gradually_cut_flow(self):
print("正在逐步切流。")
def is_capacity_sufficient(self):
# 模拟判断容量是否足够
# 这里需要根据实际情况实现具体的逻辑
return self.capacity > 50
def calculate_remaining_capacity(self):
# 模拟计算剩余容量比例
return self.capacity / 100
def choose_best_location(self, remaining_capacity_ratio):
print(f"根据剩余容量比例 {remaining_capacity_ratio} 选择最合适的地区或国家。")
def handle_global_fault(self):
print("正在处理全局故障。")
def handle_fault_process(self):
if self.is_single_az_fault():
self.remove_faulty_machine()
self.quick_scale_up()
elif self.is_partial_fault():
self.gradually_cut_flow()
if self.is_capacity_sufficient():
self.gradually_cut_flow()
remaining_capacity_ratio = self.calculate_remaining_capacity()
self.choose_best_location(remaining_capacity_ratio)
else:
self.handle_global_fault()
# 创建故障处理对象
fault_handler = FaultHandler()
# 调用故障处理流程
fault_handler.handle_fault_process()
小结
这节课我们详细阐述了决策大脑的构建要素:为了实现更高效的决策和深入的分析。决策大脑将监控、容量管理、变更控制与应急预案等功能紧密整合,形成一个协调一致的系统。决策过程应基于实际情境触发,通过每次故障响应来构建并持续优化自身的决策模型。整个运维大脑由展示层、交互工具、在线推理模块、离线训练机制以及相关数据库构成。
运维大脑代表了SRE的理想发展形态。SRE的终极目标应是将业务理解、故障处理和AI算法等关键要素抽象化,并构建成模型。这些模型如同大脑中的神经元,通过持续激活和优化,逐步增强其功能和效能。
思考题
还有哪些场景可以抽象为一个具体的模型,并沉淀起来呢?你可以思考一下,欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!