22 AIOps变更管理:如何进行更全面地检查与更精准地阻断?
你好,我是白园。
在我们日常变更的时候需要对指标进行判断和检查,往往会面临两个问题。
第一个问题就是指标众多,数量庞大,一个核心系统的变更检查的指标包括业务指标、系统指标、基础指标,可能多达数百个,如果一个指标检查需要10s,一次检查可能需要几分钟或者几十分钟,这无疑增加了检查的复杂性,并且会大大增长变更成本和时长。
其次,工程师在分析系统性能的时候,往往难以全面顾及到上下游服务的依赖关系及其健康状况。在进行性能检查的时候,可能会忽略对下游服务的影响,很多时候都是因为忽略上下游的指标的波动而造成严重的故障。
我们既要追求发布的成本和效率,更要注重检查的全面性和准确性,单靠人的力量和精力是远远不够的。
因此,为了实现迅速而精确地分析,我们需要借助一款得力的工具。我给出了一张示意图,你可以看一下,图里展示了在分阶段发布过程中,如何迅速对各阶段的关键指标进行检测与分析,确保系统稳定性。这节课我会重点介绍一款名为智能checker的工具,这是百度为解决变更过程中对大量指标进行快速检查而首创的工具。

智能checker
我们要解决三个层面的监控指标的判断:一是变更服务本身的监控指标,比如自身的错误日志,错误码;二是调用关系的监控指标,比如请求数,延迟,P99等等;三是上下游服务的自身监控指标的检查,比如机房的变更也是需要关注业务大盘指标的变化的。
自身指标异常检测
比如服务变更出现隐患,服务A变更的时候出现CPU缓慢上涨的情况,第一时间只是观测了调用成功率,日志错误码等,并没有及时发现这个隐患,在凌晨高峰期的时候导致服务过载线上故障。
为什么没有发现呢?因为服务在变更的时候,很容易出现一些波动,比如在重启过程中内存和CPU都会有波动;有时候这种情况是正常的,有时候就是异常的。如何判断自身指标是否异常,这里采取的核心思想就是对照。
简而言之,我们需要评估一个正在经历变化的实例的指标波动是否异常。这需要通过与未发生变化的实例进行比较,以及与历史变化数据进行对比来实现。如果当前波动与这些参照标准不一致,那么可能表明存在问题。

这里我给你一个具体的思路。
- 初步判断:首先,我们评估变更组与对照组(即尚未进行变更的实例)的指标变化。如果在本次变更发布后,两组均显示出相似程度的波动,这可能意味着这波动是用户行为结果,而非异常现象。因此,这种指标变化可以被视为正常。
- 历史对比:接着,我们将变更组的指标变化与历史变更进行对比。如果变更发布后指标出现显著波动,而历史上的变更也有类似的波动趋势,我们可以推断这种波动可能是由于系统重启等常规操作引起的,属于正常的指标波动。
- 异常识别:最后,如果变更组在变更发布后出现指标异常比如突增或者突降,而对照组和历史变更数据均未显示出类似的变化。在这种情况下,我们认为变更可能引发了异常,需要考虑中止或回滚变更以防止进一步影响。
算法实现
这里我们采用T检验来实现,我简单解释一下什么是T检验,T检验又称为学生T检验,是一种统计方法,用来比较两组数据的均值是否存在显著差异。
T检验主要分为3种。
- 单样本T检验(One-Sample t-test):用于比较一组数据的均值与已知的总体均值之间是否存在显著差异。
- 独立样本T检验(Independent Samples t-test,也称为双样本T检验):用于比较两组独立样本的均值是否存在显著差异。
- 配对样本T检验(Paired Samples t-test,也称为重复测量T检验):用于比较同一组受试者在两个不同条件下的数据差异。
T检验分为5个步骤。
- 假设设定:零假设(H0)通常是指两组数据的均值没有差异,备择假设(H1)则是指存在差异。
- 计算T统计量:根据样本数据计算T值,该值反映了样本均值与假设均值之间的差异程度。
- 确定自由度(df):通常为较小样本量的减1。
- 查找T分布表或使用统计软件确定P值:P值用于判断统计结果的显著性。
- 结果解释:如果P值小于预定的显著性水平(如0.05),则拒绝零假设,认为两组数据的均值存在显著差异。
你可以看一下我给出的代码。代码中首先生成了三组模拟数据:变更组、对照组和历史数据。然后,我们使用T检验来比较变更组和对照组的数据,并根据P值来判断两组数据是否存在显著差异。最后,根据数据变化情况和P值,我们进一步判断,来确定变更是否正常或异常。
import numpy as np
from scipy.stats import ttest_ind
# 生成模拟数据
np.random.seed(0) # 为了可重复性设置随机种子
group1_change = np.random.normal(loc=100, scale=10, size=30) # 变更组数据,模拟变更后上升
group2_control = np.random.normal(loc=95, scale=10, size=30) # 对照组数据,模拟轻微上升
historical_data = np.random.normal(loc=90, scale=10, size=30) # 历史数据,模拟变更后下降
# 进行t检验
t_statistic, p_value = ttest_ind(group1_change, group2_control)
# 打印t检验结果
print(f"t-statistic: {t_statistic}, p-value: {p_value}")
# 根据p值和数据变化进行判断
alpha = 0.05 # 显著性水平
if p_value < alpha:
print("变更组和对照组之间存在显著差异")
# 进一步分析数据变化情况
if np.mean(group1_change) > np.mean(group2_control):
print("变更组数据上升,但对照组也上升,可能是时间因素导致。")
else:
print("变更组数据下降,但历史数据显示通常也会下降,可能是进程重启导致。")
else:
print("变更组和对照组之间没有显著差异")
# 检查变更组是否突增,而对照组和历史数据没有变化
if np.mean(group1_change) - np.mean(group2_control) > 2 * np.std(group1_change):
print("变更组数据突增,但对照组和历史数据没有明显变化,指标异常。")
请注意,这只是一个简化的示例,实际应用中可能需要更复杂的数据分析和判断逻辑。
上下游指标分析
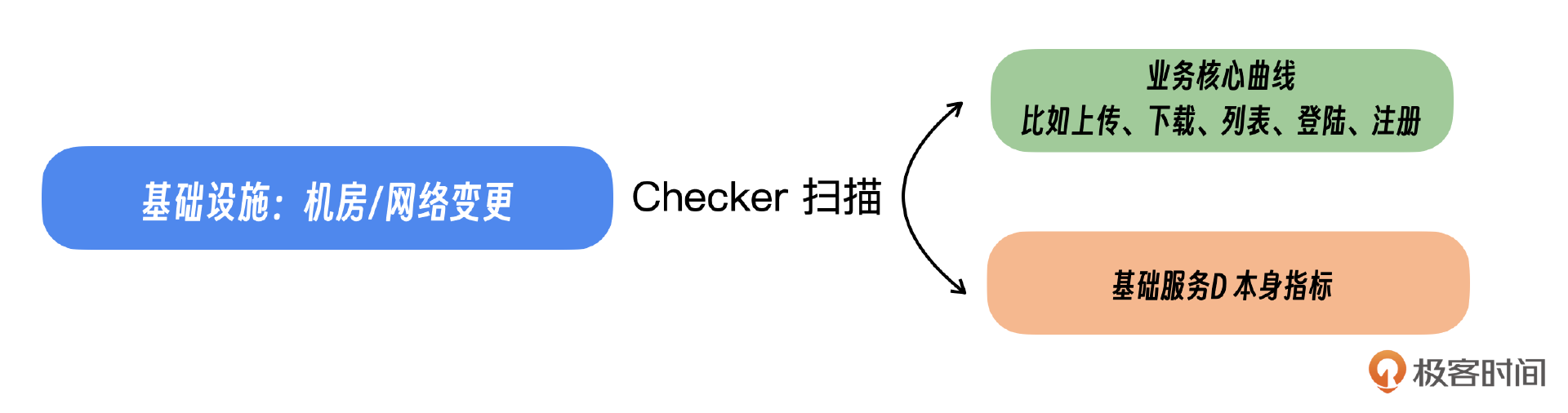
上下游关系这里分为两种情况,一种是有直接调用关系的。一种是没有直接调用关系,比如基础设施、基础平台。
比如服务变更导致下游出现问题,服务A在变更的时候更改了调用逻辑,对下游服务B2的请求量翻了一倍还多,在变更的时候观测了A本身的所有指标都正常。由于不是服务B2的Owner,所以它并没有关注到下游的情况,在凌晨高峰期的时候服务B2容量过载导致线上故障。为什么没有发现呢?因为下游的服务很多,而且owner也不是自己所以没有观察到。
我们再来看一个基础服务变更导致多个服务故障的例子。基础服务D是一个配置平台类的服务,是一个非常底层的服务,很多服务都依赖它,在一次做变更的时候修改了其中一个字段,上游的业务都不兼容这个字段,导致全员出core。服务B1、B2、B3全部core,引发了非常严重的故障。因为上游使用方非常多,而且灰度的时候自己的服务本身没有问题,有问题的是上游服务。
这里的解决方案也分为两种。
- 在变更过程中,如果调用关系能够清晰地表现出来,我们应当重点监测上游服务的关键性能指标。这包括但不限于实例的数量、调用的频率以及核心资源的使用情况等,确保服务的稳定性和性能不受影响。
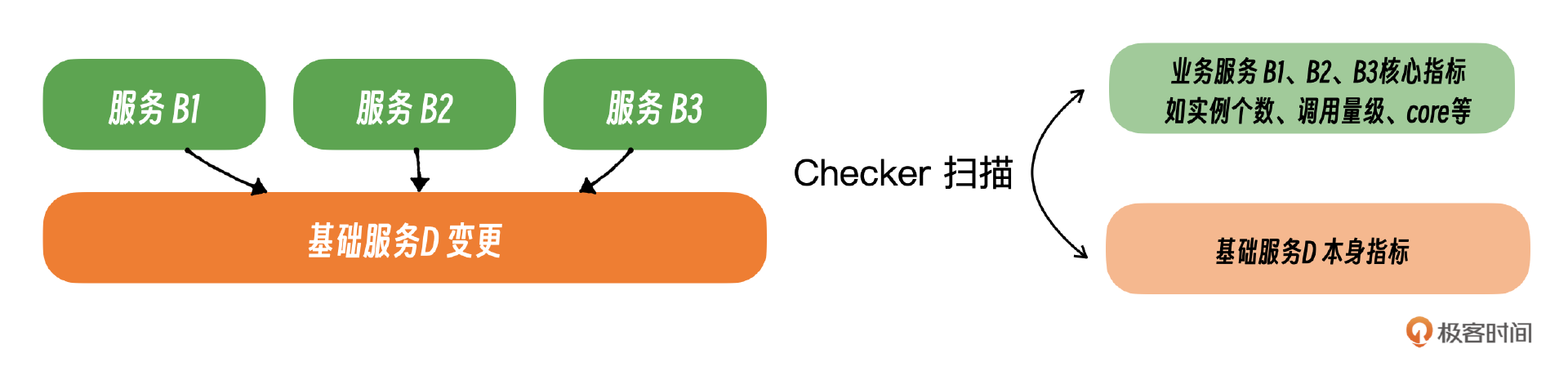
- 对于无法直接通过调用关系显现的变更,例如基础设施的调整,我们需要迅速检查业务核心指标的健康状况。这是因为关键故障往往会在业务指标上有所体现,从而影响整体服务表现。
下面是具体的实现例子:
import numpy as np
import pandas as pd
def generate_mock_data(num_days=100, num_metrics=3, mean=100, std=10):
"""生成模拟数据"""
np.random.seed(42) # 为了可重复性设置随机种子
dates = pd.date_range(start='2024-01-01', periods=num_days, freq='D')
metrics_data = np.random.normal(loc=mean, scale=std, size=(num_days, num_metrics))
return pd.DataFrame(metrics_data, index=dates, columns=[f'Metric{i+1}' for i in range(num_metrics)])
def calculate_annual_change(df, periods=7):
"""计算同比变化率"""
return (df - df.shift(periods)) / df.shift(periods)
def detect_anomalies(df, threshold_day, threshold_week):
"""异常检测函数"""
anomalies = []
for column in df.columns:
day_change = calculate_annual_change(df[column], 1) # 天同比
week_change = calculate_annual_change(df[column], 7) # 周同比
# 过滤掉NaN值,并检查异常
for i, (day_chg, week_chg) in enumerate(zip(day_change, week_change)):
if pd.isna(day_chg) or pd.isna(week_chg):
continue
if abs(day_chg) > threshold_day or abs(week_chg) > threshold_week:
anomalies.append({
'Metric': column,
'Date': df.index[i],
'Value': df[column][i],
'Day_Change': day_chg,
'Week_Change': week_chg
})
return anomalies
# 生成模拟数据
data = generate_mock_data()
# 设置同比阈值
threshold_day = 0.5 # 天同比变化的阈值,例如50%
threshold_week = 0.3 # 周同比变化的阈值,例如30%
# 执行异常检测
anomalies = detect_anomalies(data, threshold_day, threshold_week)
# 打印异常结果
for anomaly in anomalies:
print(anomaly)
# 可选:将异常结果保存到CSV文件
# anomalies_df = pd.DataFrame(anomalies)
# anomalies_df.to_csv('anomalies.csv', index=False)
generate_mock_data:生成模拟的时间序列数据。calculate_annual_change:计算给定周期的同比变化率。detect_anomalies:执行异常检测,使用calculate_annual_change函数来计算同比变化率,并根据设定的阈值判断是否存在异常。
工程实现
最后我们看一下工程实现。
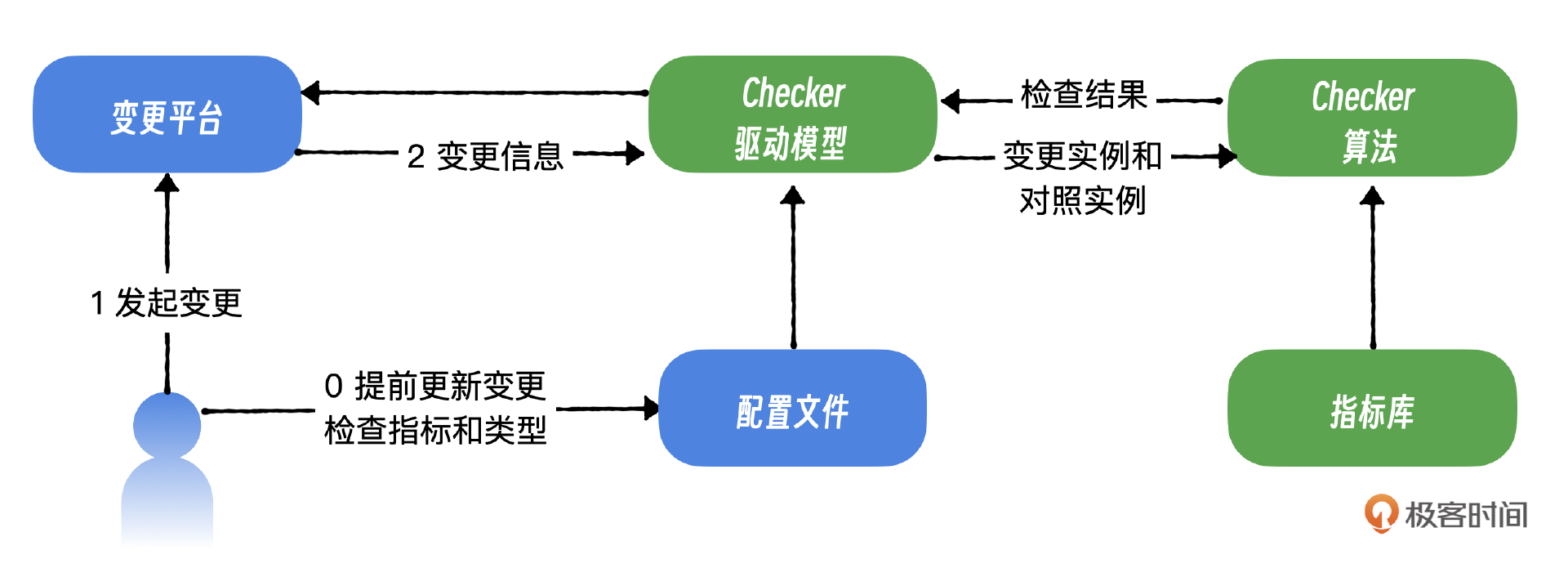
首先是Checker驱动模型,接收并筛选变更信息。例如,当检测到一个容器云服务的变更单时,它将提取关键信息,包括变更类型、服务名称、单号,以及相关的实例组和对照组,并将这些信息传递给Checker算法模块进行进一步处理。
第二个组件是算法模型,它的核心功能是进行实时计算和快速判断。这个模型接收来自驱动模块的信息,并在指标库中检索相关指标。随后,它应用上述算法对这些指标进行迅速地异常检测分析。
第三个组件是指标库,它负责把不同类型或不同服务的检查需求和相应的指标相对应,确保检查过程的准确性和针对性。
第四个组件是配置文件,它要求操作人员预先设定服务类型、检查指标等关键参数,以便算法模型可以准确地执行其功能。
小结
这节课我简要介绍了智能checker的概念及其实现方法。你可以根据自己面临的具体变更场景,进行深入探索和实践应用。智能checker的目的是解决在变更过程中对众多指标进行快速检查的难题。
通过分析服务间的依赖和调用关系,智能checker可以识别出潜在的影响范围和关键组件。通过比较变更前后的指标数据,智能checker能够快速识别出性能退化或其他问题。智能checker通过高效地处理大量数据,快速完成对关键指标的检查,从而加速问题发现过程。
智能Checker虽然属于异常检测领域,但和传统的报警支持型异常检测有两个主要的区别。报警支持型异常检测持续监控少量关键指标,而智能Checker则在特定时间点对大量指标进行检测。这个时候就需要利用大规模异常检测来快速实现。报警支持型异常检测能够及时捕捉到指标的突变并判断为异常。相比之下,智能Checker无法直接通过指标突变判断异常,因为产品上线变更等预期因素可能导致指标出现大幅波动。这个时候就需要利用对照的思路进行判断,比如T检测等算法。
思考题
之前我还遇到过一个案例,一次网络的变更,出现了网络报文被修改的请求。从网络侧自身的监控来看并没有发现这个问题,但是从业务的调用和大盘指标来看出现了明显的波动。一开始业务侧根本不知道网络做了哪些变更,网络侧也以为没有问题,导致整体的故障时间非常长。这个问题如何解决?欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!