20 AIOps问题定位:如何在报警风暴中找到暴风眼?
你好,我是白园。
今天我跟你分享一下AI在故障定位领域解决了哪些问题。AI与故障定位的方向基本分为三个方向:多维归因分析、因果推断、重复(相似)问题定位,我们一个个看。
多维归因定位
在一次故障中,我注意到网盘上传流量出现了阴跌。经过调查,我们发现是电信服务出现了问题。进一步分析后,我们确定故障发生在广东电信。后续我们发现这次事件凸显了一个问题:在众多指标中,如何快速准确地识别导致问题的主要因素是一个非常大的挑战。比如如何快速定位到是广东电信的问题,其中用到的方法就是多维定位。
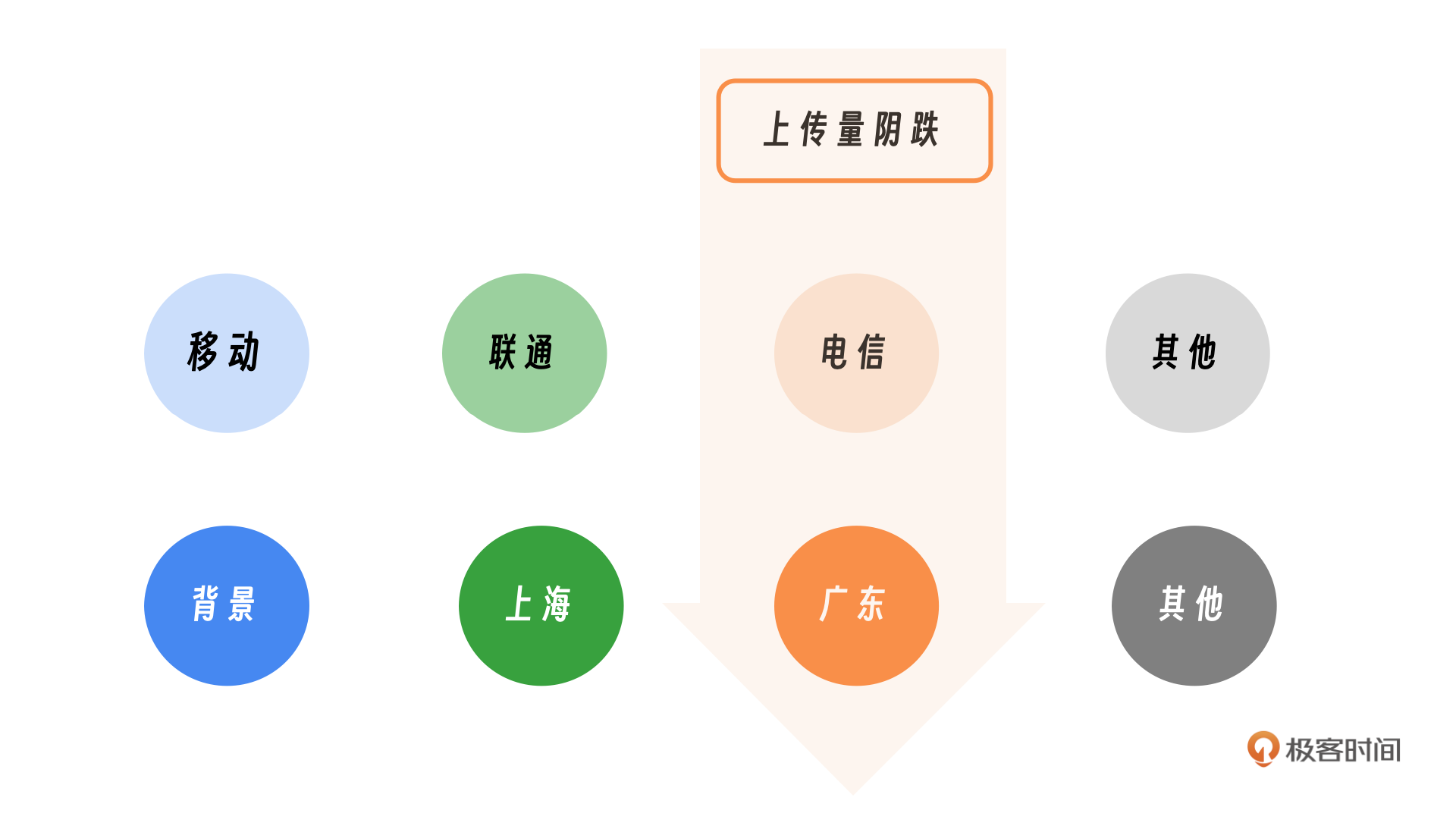
面对流量下降的问题,关键在于识别导致下降的具体维度,并进一步深入分析。首要任务是确定波动发生在哪个维度。你可以看一下示意图,在机房和年龄这两个维度下,所有子维度都显示出波动;然而,当从运营商维度进行观察的时候,只有移动运营商的流量出现了异常,其他运营商的流量则保持正常。这里我们就可以判断是运营商的问题。
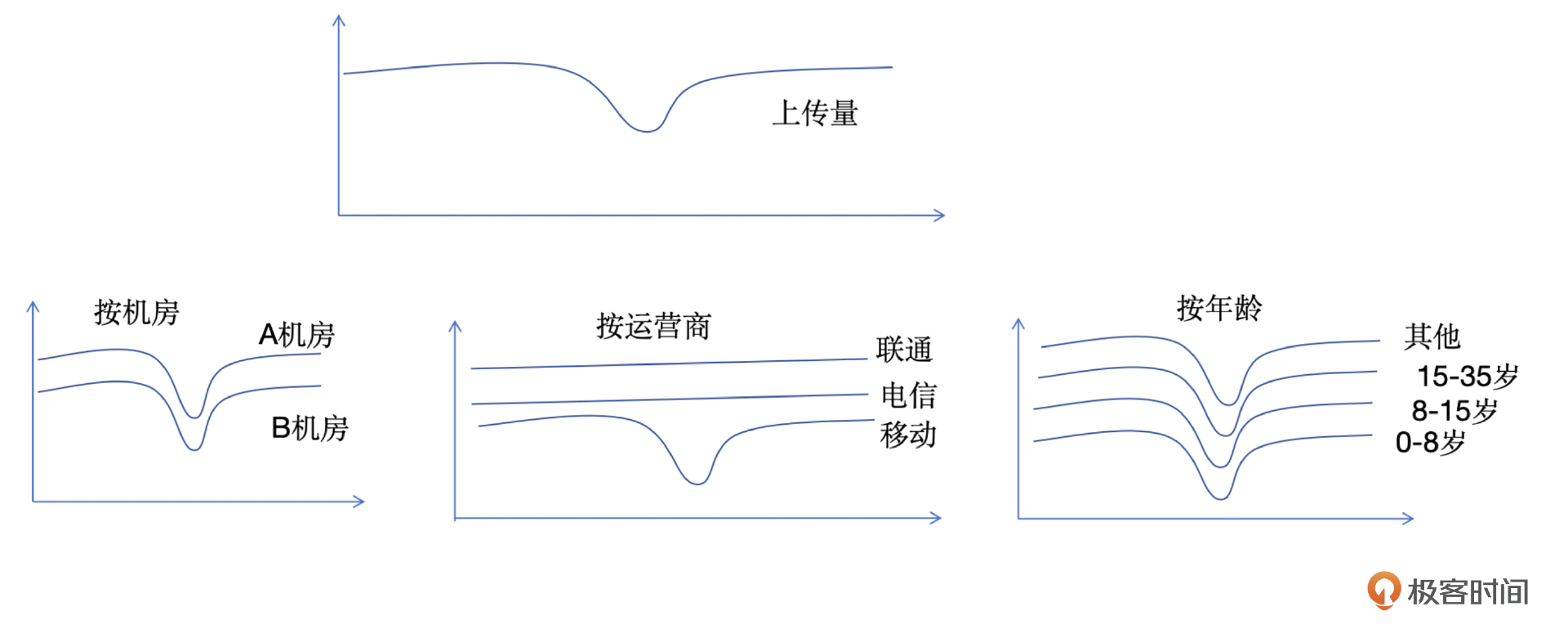
你可以看一下示意图,我们考虑上传量下降的情况。上传量同比下降了20%,我们从机房、运营商、年龄三个维度进行横向分析。如果某个维度的子维度中仅有1~2个显示有问题,那么很可能是该维度导致了整体下降。
具体来看,机房维度可以细分为A机房和B机房。如果A机房和B机房的同比下降均为20%左右,这表明机房维度并非问题所在。同样,如果所有年龄段的上传量都呈现下降趋势,那么年龄维度也可以排除。
最后,我们分析运营商维度。这里可以看到联通和电信的上传量保持正常,而移动的上传量下降了60%,且只有移动中的一个子维度出现异常,那么我们可以确定运营商是导致上传量下降的主要因素。
下面我们以运营商维度为例,来简要演示算法的应用。
第一步:总量贡献度分析:首先,需要确定整体流量的变化情况,流量同比下降了5%。然后,分析不同区域或运营商对总量变化的贡献度。如果某个运营商或区域的流量变化与整体趋势一致,这可能表明它们对整体流量变化的影响较小。
第二步:日常占比分析:查看各运营商或区域在日常流量中的占比。如果某个运营商或区域的占比与其对流量变化的贡献度相匹配,那么这个运营商或区域可能不是导致流量变化的主要原因。
第三步:差异性分析:最后,需要分析各运营商或区域的流量变化是否存在显著差异。如果某个运营商或区域的流量变化与其他运营商或区域相比有显著不同,那么这个运营商或区域可能是导致流量变化的关键因素。
# 假设我们有以下数据:
# 昨天的流量数据(单位:百分比)
yesterday_traffic = {'联通': 40, '电信': 30, '移动': 30}
# 今天的流量数据(单位:百分比)
today_traffic = {'联通': 36, '电信': 33, '移动': 20}
# 运营商日常占比
daily_traffic_ratio = {'联通': 40, '电信': 30, '移动': 30}
# 计算流量变化和贡献度
def calculate_traffic_change(yesterday, today):
change = {}
for operator in yesterday:
change[operator] = today[operator] - yesterday[operator]
return change
# 计算差异性
def calculate_difference(yesterday_ratio, today_ratio):
difference = {}
for operator in yesterday_ratio:
difference[operator] = today_ratio[operator] - yesterday_ratio[operator]
return difference
# 计算结果
traffic_change = calculate_traffic_change(yesterday_traffic, today_traffic)
traffic_difference = calculate_difference(daily_traffic_ratio, today_traffic)
# 输出结果
print("流量变化:")
for operator, change in traffic_change.items():
print(f"{operator}: {change}%")
print("\n差异性:")
for operator, diff in traffic_difference.items():
print(f"{operator}: {diff}%")
# 根据差异性分析主要原因
def analyze_main_reason(traffic_difference):
max_diff = max(traffic_difference.values())
main_reason = [operator for operator, diff in traffic_difference.items() if diff == max_diff]
return main_reason
# 执行分析
main_reason = analyze_main_reason(traffic_difference)
print("\n主要原因分析:")
for reason in main_reason:
print(f"{reason} 可能是导致流量变化的主要原因。")
上面的是一个简单的例子,这里我分享一下常见的算法。
- Attributor是一种用于多维数据分析的算法,是微软在2014年提出的,这个算法主要用于快速定位影响关键性能指标(KPI)的根因,核心思想是通过计算不同维度和元素的“惊喜度(Surprise)”和“解释力(Explanatory Power, EP)”来量化和识别可能导致KPI异常波动的因素。
- HotSpot算法使用“预测+搜索”策略,并提出了基于Ripple Effect的根因判断方法。它通过计算潜在分,来量化节点与它所有叶子节点之间满足Ripple Effect的程度。
- Divisia分解法是一种经济指标分解技术,它用于分析不同因素对总量变化的贡献。这种方法由比利时经济学家Raphaël Divisia提出,后经过多位学者的发展和完善,形成了多种变体。
因果推断
因果推断是什么意思,如果你与小王关系不和,到底是你的问题还是小王的问题。如果你与多数人的关系都紧张,很可能需要反思自己的行为;如果只是和小王关系不好,而与其他人都相处融洽。并且你发现小王与他人关系也很紧张,那问题可能出在对方身上。
因果推断包含三个层次:首先是关联性的发现,比如你与小王,难以断定何者为因,何人为果;其次是通过干预验证,例如果把小王调走,发现办公室和谐了,把你调走但是办公室氛围还是不好,那就说明小王是因,你是果。最后是反事实推理,认识到一个因素可能是另一个因素的结果,小王为什么跟人相处不好,因为他家庭关系不好,他老婆天天跟他吵架,所以他心里烦躁。
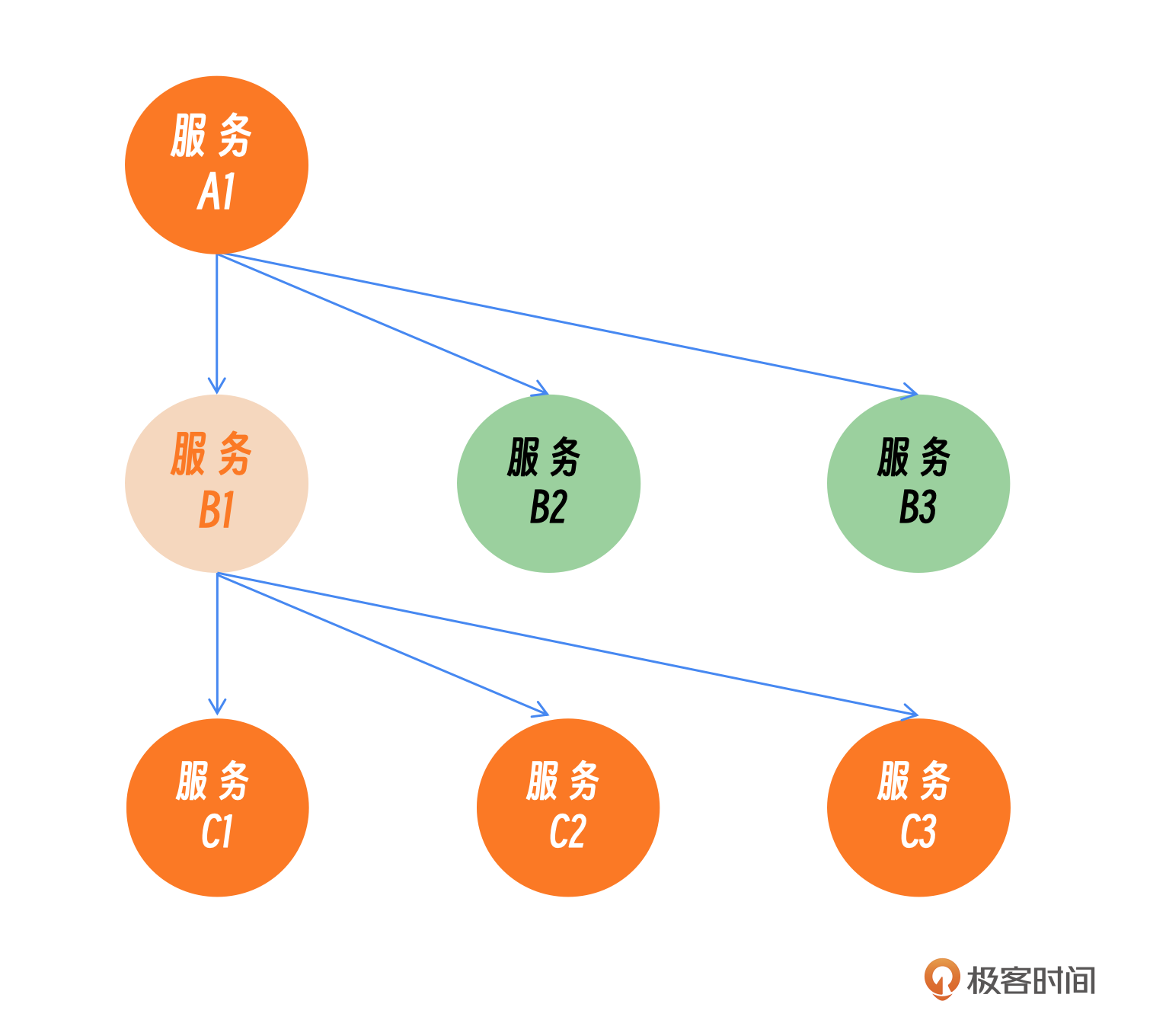
在一次故障排查中,我们发现服务调用链出现了广泛的异常(一片红),这表明多个服务在报错。这次故障是由一个新上线的服务引起的。在这种情况下,定位问题根源非常耗时,因为我们需要确定是服务A导致了服务B的故障,还是服务B首先出现问题影响了服务A。通过仔细分析,我们发现服务B1的变更是导致整个调用链出现问题的原因。这就是一个典型的因果推断场景。
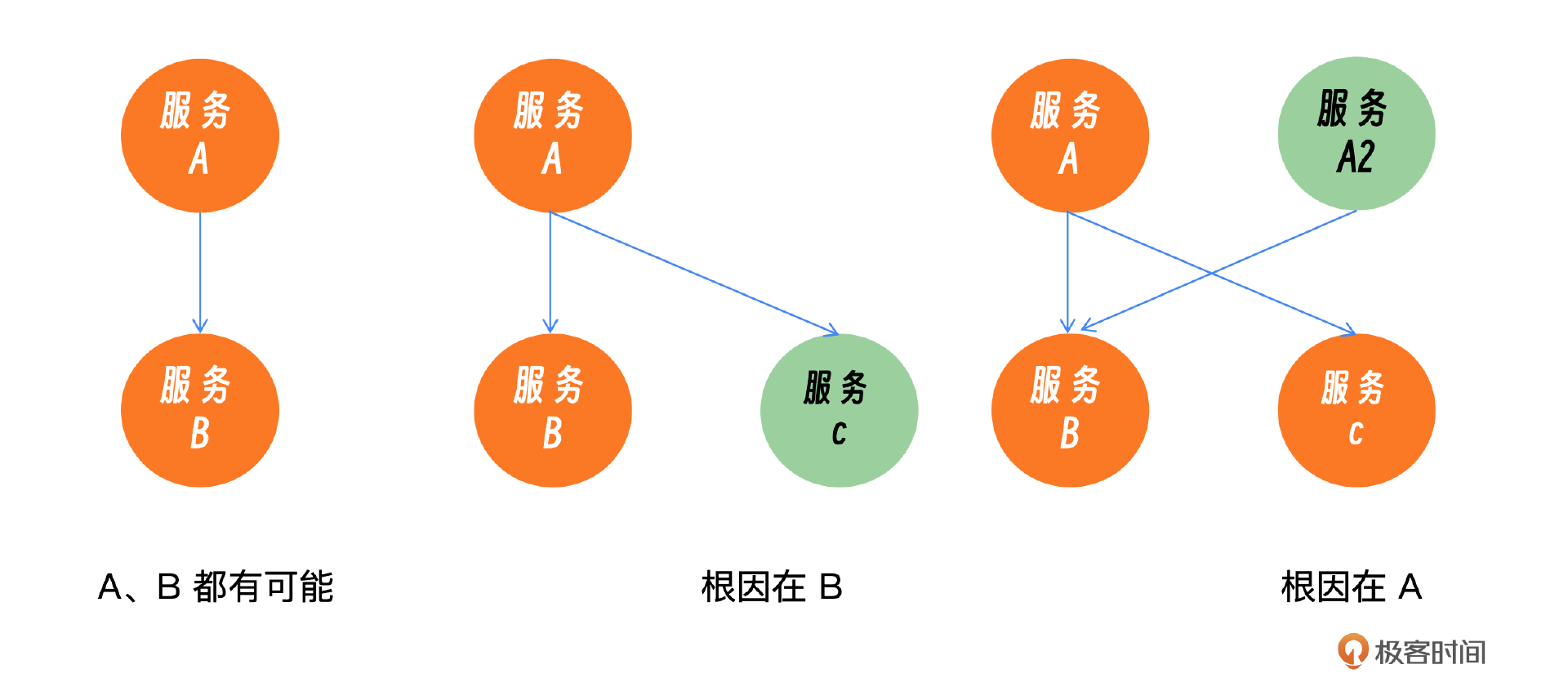
面对A服务请求B服务时出现的故障,我们需要判断A或B谁是原因。如果A服务对C服务的请求同样出现问题,那么问题很可能出在A服务;反之,如果A到C的请求正常,那么故障可能源自B服务。为了深入诊断,我们还需考虑B服务的下游服务是否存在问题,并继续采用之前提到的方法进行递归排查。
下面是具体的代码实现:
import random
def call_service(caller, callee):
"""
模拟服务调用,返回成功或失败。
实际应用中,这里可以是API调用或其他形式的服务请求。
"""
# 假设服务调用有50%的几率失败
return "success" if random.random() > 0.5 else "failure"
def check_fault(caller, callee, downstream_services=None):
"""
检查调用者调用被调用者的故障,并递归检查下游服务。
:param caller: 调用者服务
:param callee: 被调用者服务
:param downstream_services: 下游服务字典,键为服务名称,值为其下游服务列表
:return: 故障所在的服务
"""
if not downstream_services:
downstream_services = {}
# 检查调用者调用被调用者的结果
result = call_service(caller, callee)
if result == "failure":
# 如果调用失败,检查调用者是否对其他服务也有问题
for service in downstream_services.get(caller, []):
if call_service(caller, service) == "failure":
return f"问题在 {caller}"
# 如果调用者对其他服务没有问题,问题可能在被调用者
return f"问题在 {callee}"
else:
# 如果调用成功,进一步递归检查被调用者的下游服务
return check_downstream(callee, downstream_services)
def check_downstream(service, downstream_services):
"""
递归检查服务的下游服务。
:param service: 当前服务
:param downstream_services: 下游服务字典
:return: 故障所在的服务或确认当前服务正常
"""
if service in downstream_services:
# 获取当前服务的下游服务列表
downstream_list = downstream_services[service]
for downstream in downstream_list:
# 对每个下游服务进行递归检查
result = check_fault(service, downstream, downstream_services)
if result.startswith("问题在"):
return result
# 如果下游服务都正常,返回当前服务正常
return f"{service} 正常,需要进一步检查"
else:
# 如果没有下游服务,返回当前服务正常
return f"{service} 正常"
# 定义服务及其下游服务关系
downstream_services = {
"服务A": ["服务B", "服务C"],
"服务B": ["服务D"],
"服务C": [],
"服务D": []
}
# 开始故障排查
result = check_fault("服务A", "服务B", downstream_services)
print(result) # 输出排查结果
还有一些常见的因果推断算法,我们可以了解下。
- 倾向得分匹配(Propensity Score Matching):通过计算每个个体接受处理的概率(倾向得分),将处理组和对照组中相似的个体进行匹配,以减少选择性偏倚。
- 双重差分法(Difference-in-Differences, DiD):通过比较处理组和对照组在干预前后的变化差异,来估计干预的因果效应。
- 工具变量法(Instrumental Variable, IV):使用与处理变量相关但与误差项不相关的工具变量来解决因果关系的识别问题。
重复问题定位
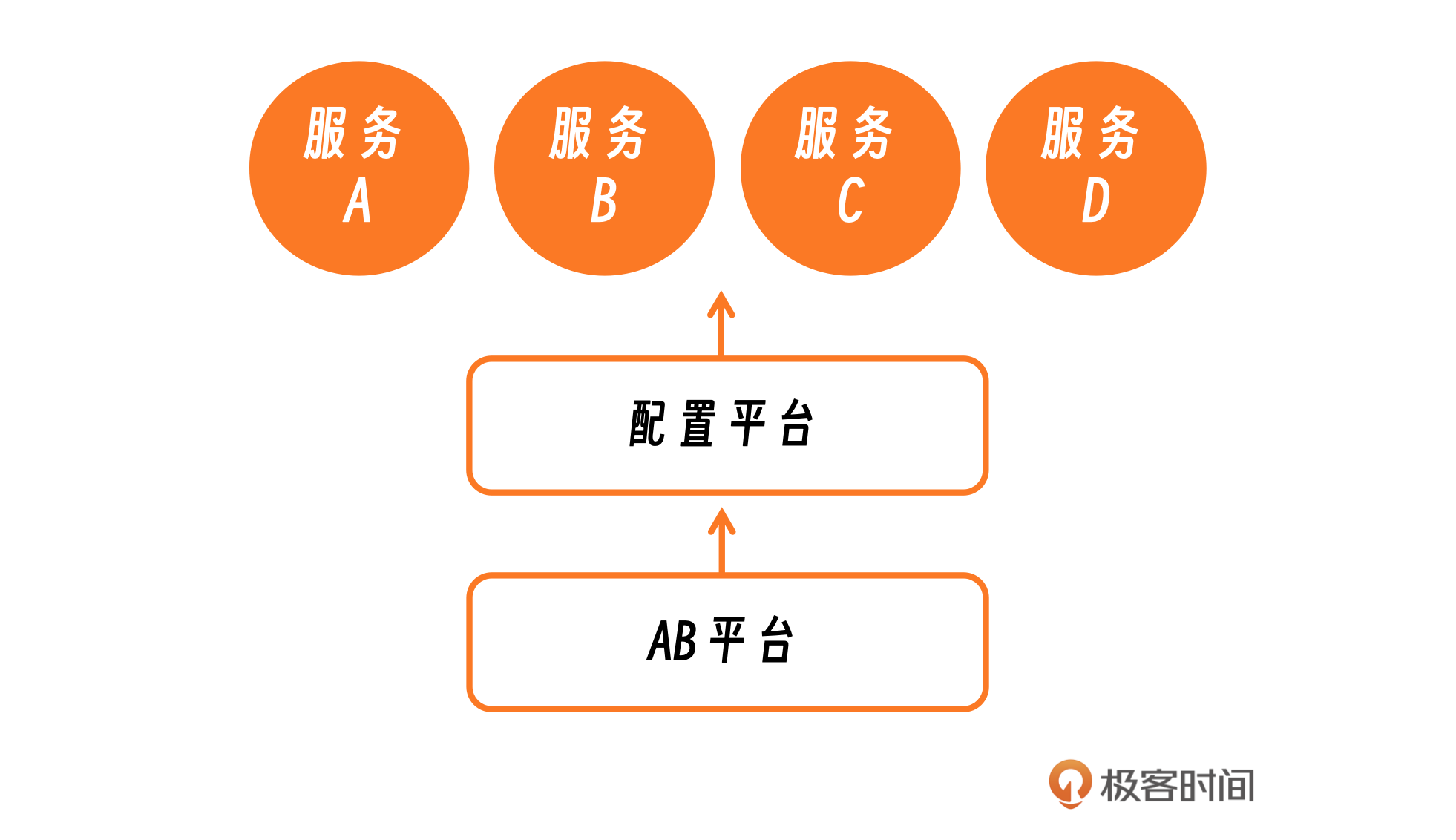
我之前经历过一次严重的故障事件。AB平台进行了一次变更,这次变更通过配置平台实施,影响了基于AB平台SDK等多个服务。由于这次变更,SDK出现了不兼容问题,导致大量服务崩溃(出core)。由于中间有一层配置平台的介入,且没有直接的调用关系,使问题定位变得极其困难。错误日志显示问题出在配置上。这次故障的定位非常具有挑战性,影响也非常广泛。
幸运的是,一位同事迅速地定位到了问题。我询问他是如何做到的,他解释说,由于之前遇到过类似的故障,他知道如果出现某个关键日志,基本上就可以确定是AB平台的问题。这个经验教训提醒我们,在面对复杂故障时,历史数据和日志记录的重要性。
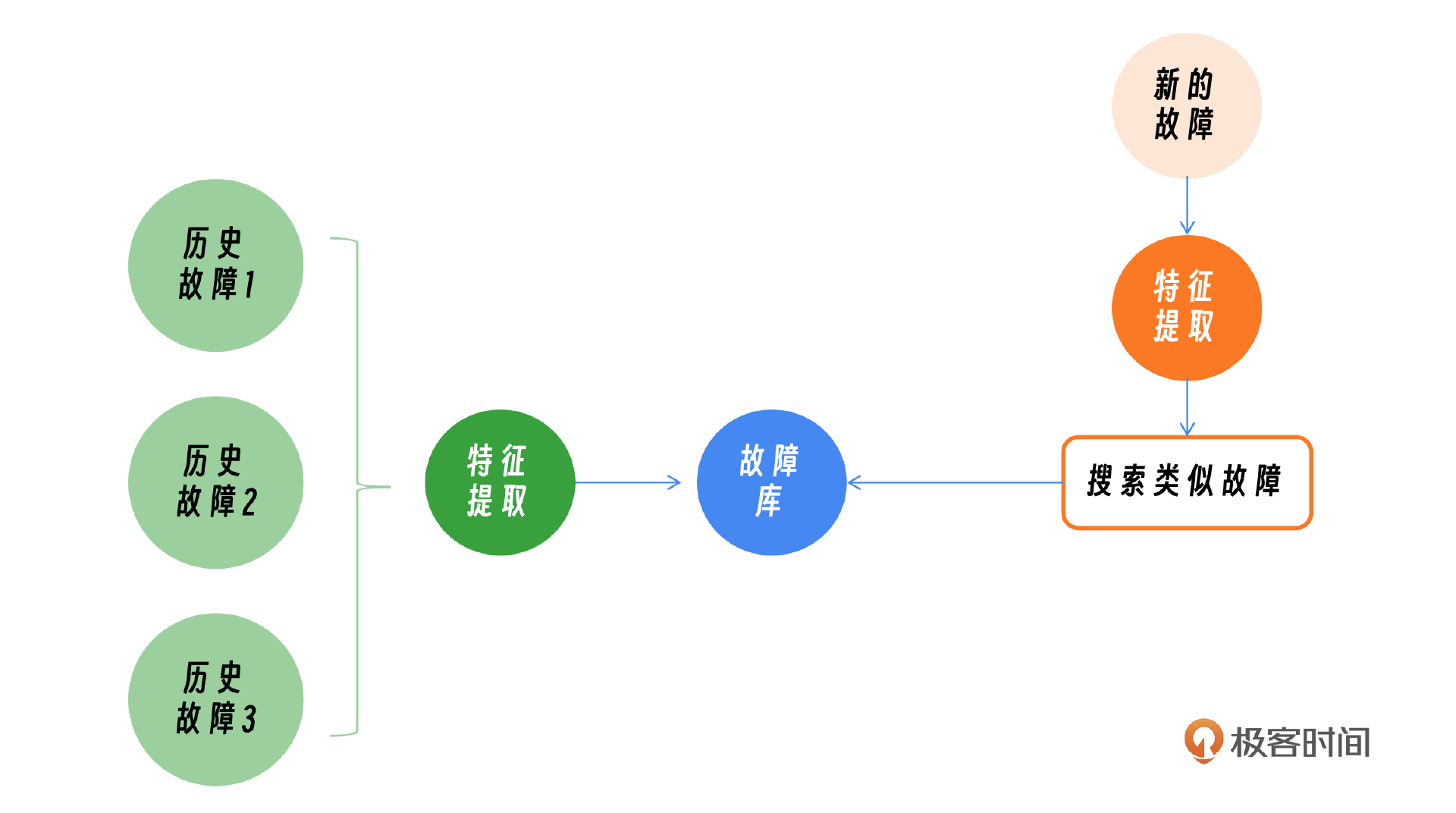
在处理重复类型故障时,相似度检查是定位问题的关键。这通常涉及到对故障特征的提取和比较,以便快速识别和解决类似问题。这里最简单的办法就是特征提取,然后在故障库里面搜索。就拿刚刚这个案例来说,观察到具体的日志里面的具体内容,然后在故障库里面搜索,发现2021年发生过一次类似的故障,是AB平台的变更导致。
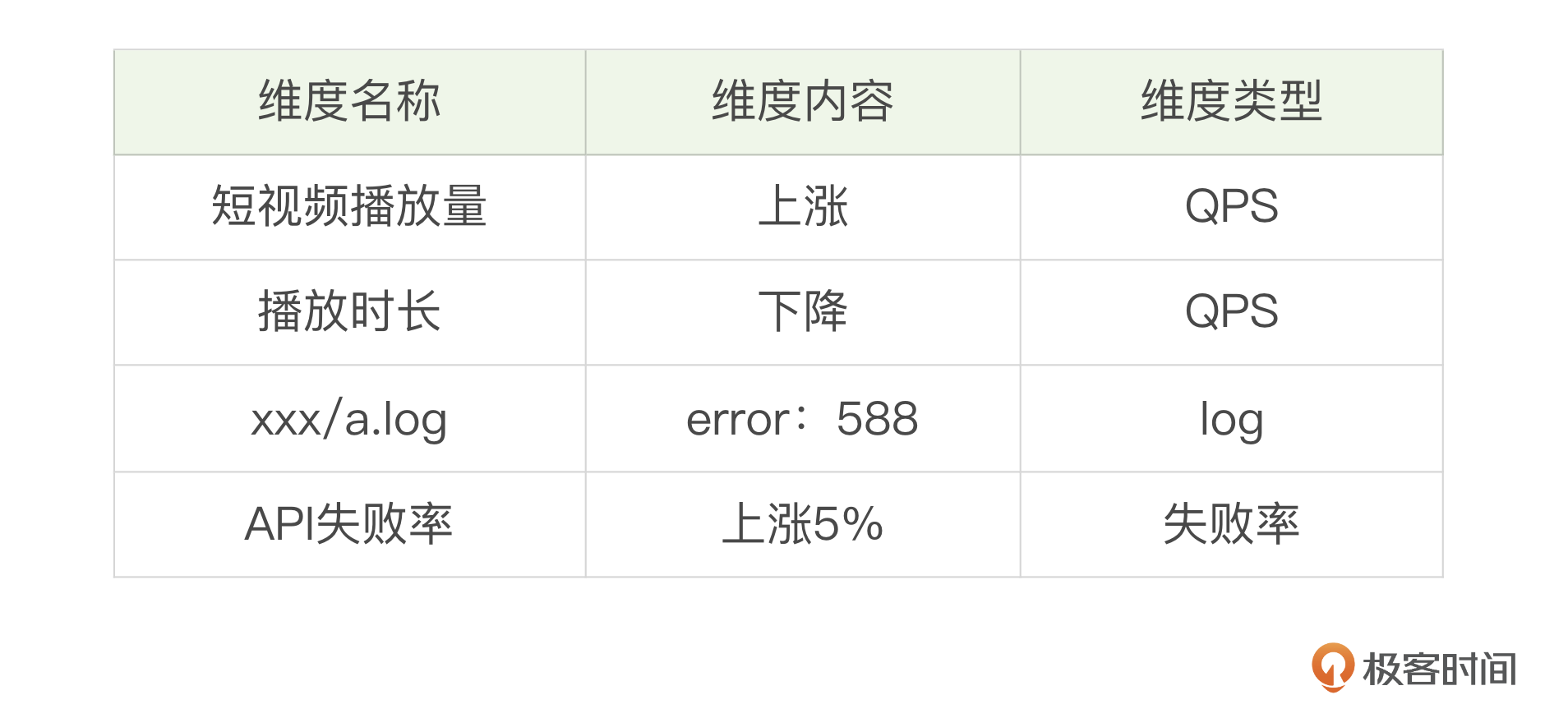
当出现新的故障时,首先需要从故障中提取关键特征。这些特征可能包括但不限于:
- 流量数据:网络流量的变化,如流量突增或下降;
- 日志信息:系统日志、错误日志等,用于分析故障发生时的系统状态;
- 性能指标:CPU使用率、内存使用情况、磁盘I/O等;
- 时间戳:故障发生的时间,可能与特定时间段的系统负载有关;
- 用户反馈:用户报告的问题描述,可以提供故障的直观信息。
这里我给一个简单的demo供你参考。
- 历史故障库构建:在系统初始化阶段,构建一个历史故障库。历史故障库中应包含以往故障的特征以及相关的诊断信息。
- 搜索类似故障:使用提取的故障特征,在历史故障库中搜索类似的故障案例。可以采用关键词匹配、相似度计算等方法来找到最相似的故障案例。
- 故障诊断:根据搜索到的类似故障案例,进行故障诊断。如果找到高度相似的案例,就可以借鉴之前的解决方案。
- 知识库更新:将新的故障案例及其解决方案添加到历史故障库中,以便未来参考。
# 示例:故障库
fault_database = {
'error_404': {
'description': 'Page not found',
'solution': 'Check the URL and server routing'
},
'error_500': {
'description': 'Internal server error',
'solution': 'Check server logs for detailed error information'
},
# 可以添加更多故障案例
}
# 故障特征提取函数
def extract_fault_features(fault_log):
# 这里只是一个简单的模拟,实际情况可能需要复杂的日志分析
features = fault_log.split(': ')
return {'error_code': features[0], 'message': features[1]}
# 搜索相似故障函数
def search_similar_faults(features, fault_database):
similar_faults = {}
# 简单的关键字匹配,实际情况可能需要更复杂的相似度计算
for fault_key, details in fault_database.items():
if fault_key in features['error_code']:
similar_faults[fault_key] = details
return similar_faults
# 故障诊断函数
def diagnose_fault(fault_log, fault_database):
features = extract_fault_features(fault_log)
similar_faults = search_similar_faults(features, fault_database)
if similar_faults:
for fault_key, details in similar_faults.items():
print(f"Similar fault found: {fault_key}")
print(f"Description: {details['description']}")
print(f"Suggested Solution: {details['solution']}")
else:
print("No similar faults found in the database. Manual investigation required.")
# 模拟新的故障日志
new_fault_log = "error_404: Page not found"
# 故障诊断
diagnose_fault(new_fault_log, fault_database)
最后分享一个DejaVu系统,实现面向重复类型故障的可操作故障定位,通过自动化、可执行且可解释的方式,对在线服务系统中的重复故障进行定位。你可以参考原始论文。
小结
这节课我们探讨了人工智能在故障定位领域的应用,涵盖了三个关键方向:多维归因分析、因果推断和重复问题定位。
多维归因分析适用于存在外部因素导致的原因,比如节假日、运营商等因子。因果推断适用微服务多层链路调用的情况和定位。重复问题定位适用无直接调用的情况。这些方法可以显著提升故障诊断的速度和准确性,帮助我们从海量数据中迅速识别问题的根源。
我们在课程中还提供的算法示例和代码实现,进一步展示了如何将这些理论应用到实际问题中,提高了故障定位的自动化和智能化水平。你可以自己试着运行一下。
思考题
如果有一天你发现业务的流量突然下降了,这个时候你的定位思路和步骤是什么?怎么做才能够以最快的速度定位到原因?欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 面包 👍(0) 💬(1)
论文链接《面向在线服务系统中重复类型故障的可操作故障定位方法》:https://arxiv.org/abs/2207.09021
2024-10-22 - 若水清菡 👍(0) 💬(1)
如果有一天你发现业务的流量突然下降了,这个时候你的定位思路和步骤是什么?怎么做才能够以最快的速度定位到原因? 1.查看接入层的统计,对比其他业务流量变化趋势,如果发现只有这个业务流量明显下降了,可以确定是这个业务的问题,和接入层无关;用第三方拨测平台在全网对业务接口进行一下测试,排查一下网络运营商侧情况。 2.查看业务层的服务指标统计,对比现在和昨天同时间段的吞吐、响应时间等。排查是不是业务代码这边出的问题,同时回溯最近两天的服务代码、配置文件和基础组件的变更历史。 3.如果上面排查都没问题,和产品和运营同学确认业务是否有季节性周期属性,例如受学生寒暑假影响就会流量低;确认app是否进行过发版,排查app端的打点日志,排查是否因为app发的新版引起的故障。 4.所有的都做完了也没任何发现,翻看一下故障历史记录,可能能找到灵感。
2024-08-28