19 AIOps故障发现:我们如何看到肉眼看不到的故障?
你好,我是白园。
之前我们学习了如何系统性的添加监控,以及监控在故障优化中的关键作用。现在,我们将转向那些传统方法难以解决的问题,并探讨怎么通过引入机器学习技术来克服这些挑战。这节课我会重点介绍监控与人工智能结合,会产生哪些创新性的解决方案。
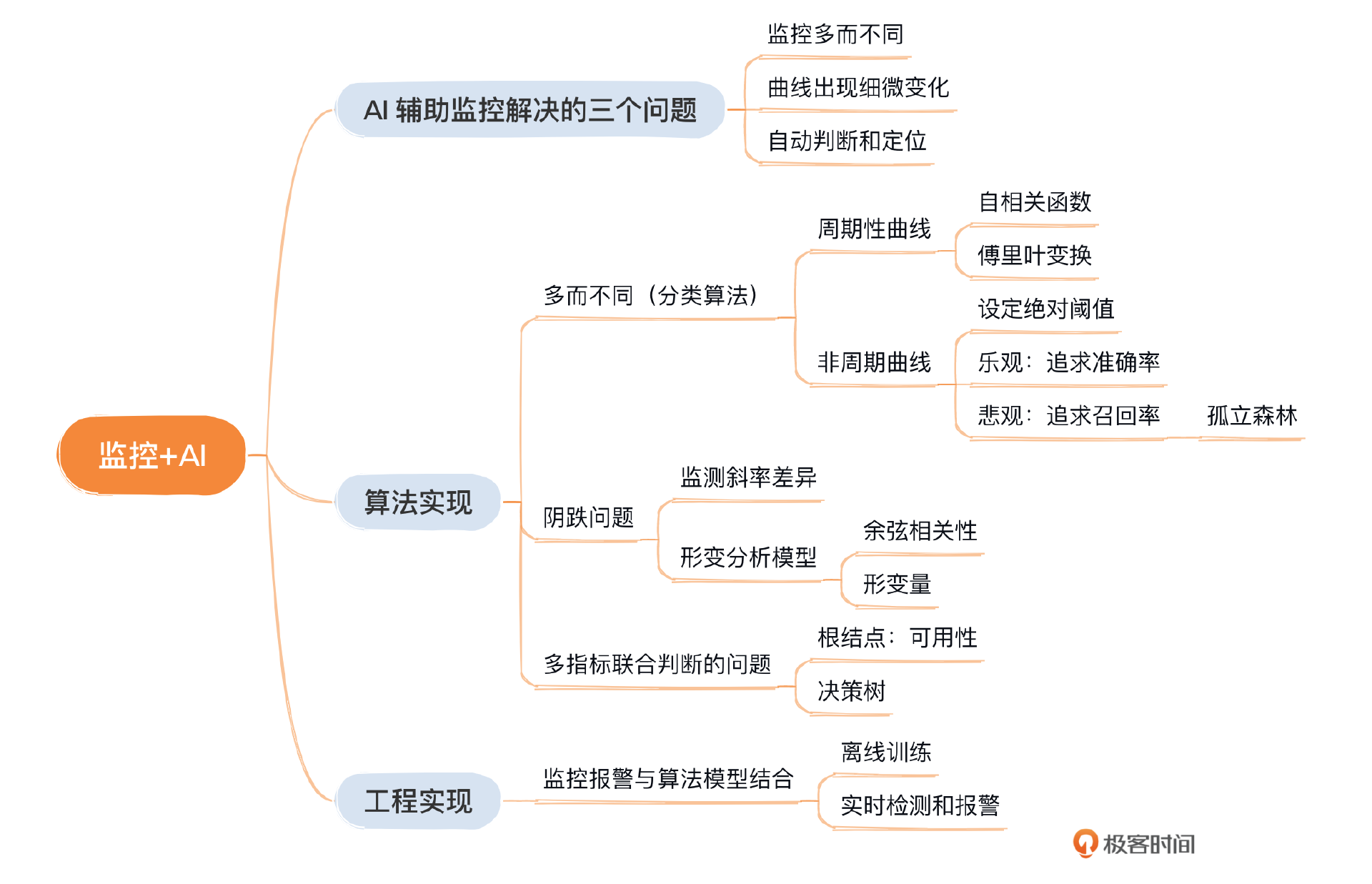
AI主要解决了监控中的三个难题
- 监控多而不同
“多而不同”指的是在监控过程中需要处理大量且各不相同的数据曲线。例如,我们可能需要对不同运营商和地区的流量数据进行细分。细分后,我们可能会看到上百条不同的数据曲线,每条曲线都需要特定的监控规则。显然,为每一条曲线单独设置监控规则不仅工作量巨大,而且从人力成本的角度来看也不切合实际。
因此,我们可以寻求AI的帮助,在不增加额外规则的情况下,有效监控这些众多的曲线。
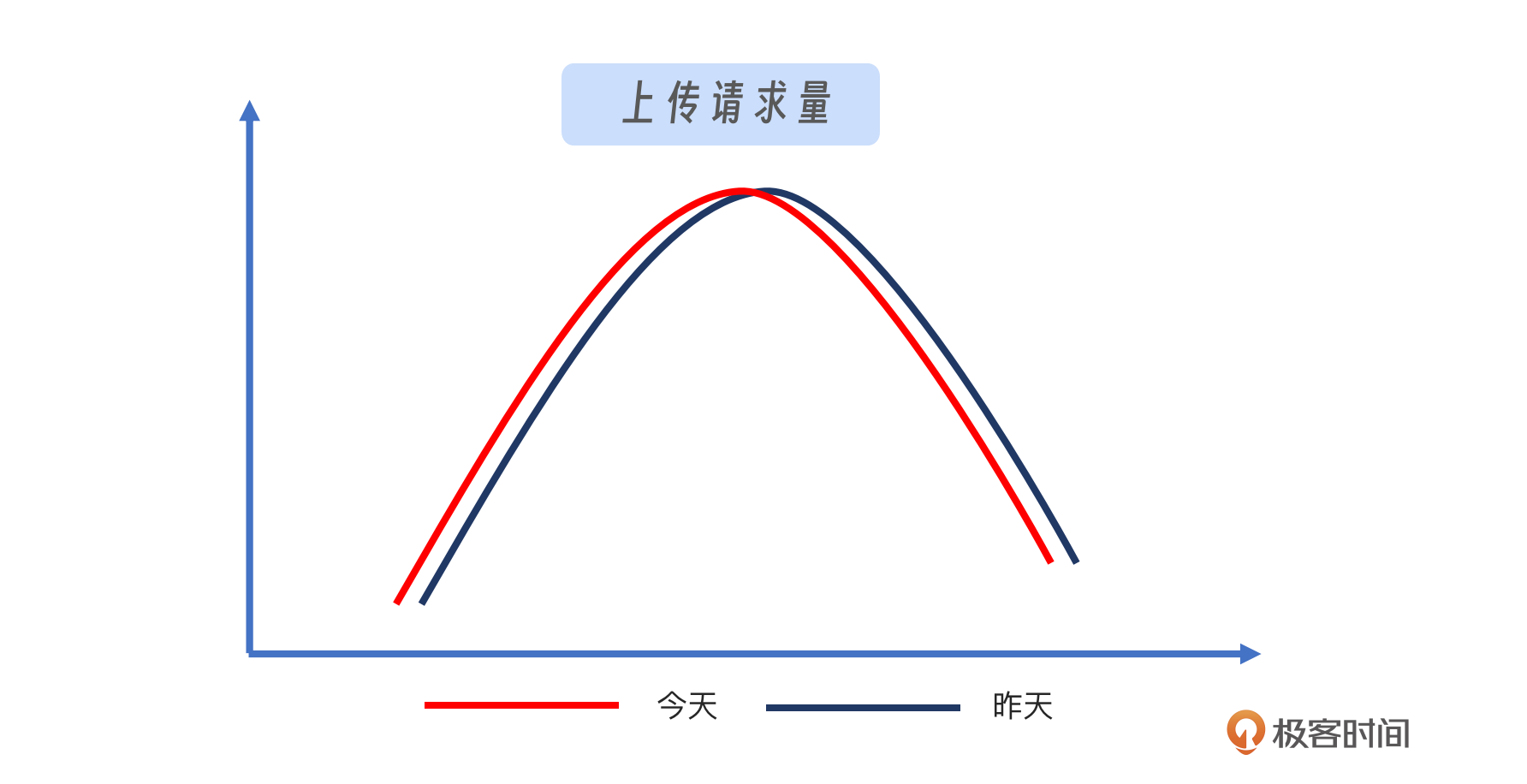
- 曲线出现细微变化
“细微变化”的问题指的是那些在特定场景下难以通过常规分析方法(如同环比)察觉到的微小变化。例如,观察下面的图片,你会发现变化非常微小。这种微小的差异很难被传统方法捕捉到。如果设置的阈值过低,可能会导致大量误报。关键在于如何设计一个既能有效识别这类问题又能够最小化误报的策略。
- 多指标联合判断
联合判断涉及在多个关键指标同时表现出异常时,如何进行综合分析,确定是否真的存在问题。这里举个例子,比如A、B两个指标同时升高,同时降低都是正常情况。只有一个升高一个降低才是异常。这个过程需要AI的协助,它能够分析这些指标之间的相互关系和影响,从而准确判断是否确实发生了异常情况。
算法实现
多而不同的问题
首先,我们需要应对的是多样化且数量众多的问题。解决这些问题的流程包括:对问题进行分类,接着针对各类问题训练相应的模型,然后将这些模型存储起来。之后,利用这些模型进行实时监测,最后根据监测结果进行反馈和必要的模型修正。
分类算法:判断是否为周期性曲线
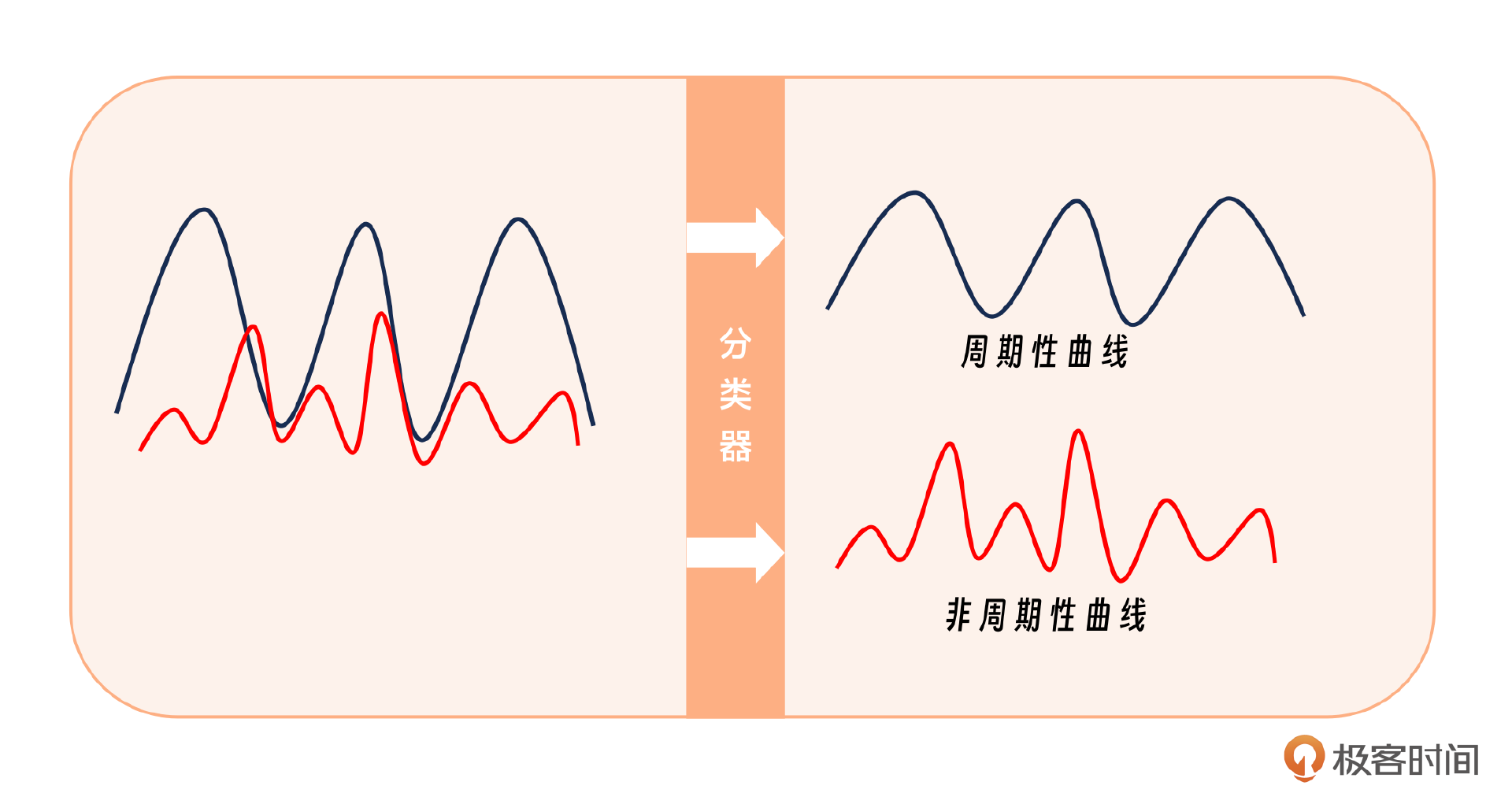
分类工作涉及将曲线数据划分为周期性和非周期性两大类。在常规监控中,我们通常以天为周期进行观察,而7天周期是最为常见的监控时段。
区分是否是周期性的曲线常见的算法有哪些呢?
- 自相关系数(Autocorrelation Function,ACF):通过计算时间序列数据的自相关系数,可以观察数据是否存在周期性。
- 傅里叶变换(Fourier Transform):傅里叶变换可以将时域的时间序列数据转换到频域,从而可以观察数据在频域上是否存在明显的周期分量。
这里我们采用自相关系数进行判断,做每分钟平均,计算不同天数据间的平均互相关系数,大于0.9才视为周期性。
代码参考:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 生成日期范围
date_rng = pd.date_range(start='2022-01-01', end='2022-01-02', freq='H')
# 生成具有强相关性的小时级别数据
np.random.seed(0)
data = np.sin(np.arange(len(date_rng)) * 2 * np.pi / 24) # 每24小时一个周期的正弦波形数据
# 创建带日期索引的Series
ts = pd.Series(data, index=date_rng)
# 绘制小时级别周期性曲线
plt.figure(figsize=(12, 6))
ts.plot()
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('Hourly Periodic Signal')
plt.show()
# 计算自相关系数
autocorr = ts.autocorr()
print(f"Autocorrelation coefficient: {autocorr}")
对于非周期性曲线,传统的同比或环比分析方法并不适用,因此我们需要设定绝对阈值来进行报警。在设定上边界和下边界时,我们可以考虑两种策略:一种是基于乐观态度,追求更高的准确率;另一种是基于悲观态度,追求更高的召回率。这两种方案可供我们选择。
基于乐观的算法比较简单:我们设定一个前提,可以分析前一周内,表现都是正常数据点。我们首先计算一周内这些数据点的峰值,然后取这些峰值的平均值,并加上一个预设的缓冲值,这样得到的结果就是我们设定的上边界。你可以参考我给出的公式。
$$avg(max(1-7天))+ x$$
基于悲观的算法这里我建议使用孤立森林。孤立森林是一种适用于连续数据的无监督异常检测方法,不需要有标记的样本来训练,但特征需要是连续的。对于如何查找哪些点是异常点,孤立森林使用了一套非常高效的策略。在孤立森林中,递归地随机分割数据集,直到所有的样本点都是孤立的。在这种随机分割的策略下,异常点通常具有较短的路径。
这里我给你一个简单的例子,帮助你理解。
from sklearn.ensemble import IsolationForest
X = [[-1.1], [0.3], [0.5], [100]]
clf = IsolationForest(random_state=0).fit(X)
clf.predict([[0.1], [0], [90],[0.8]])
对于阴跌问题
所谓的“阴跌”指的是一种缓慢而持续的下降趋势,这种趋势往往难以通过传统的同比或环比分析来察觉。为了解决这一问题,我们可以采取一种策略,即放大趋势斜率的差异。通常,天同比或周同比的变化趋势应该是相对稳定的。然而,一旦曲线出现阴跌,这种趋势的斜率差异(diff)将变得显著。通过监测这种斜率的变化,我们可以更有效地识别出阴跌现象。
这里我推荐你去读一读美团的一篇文章,标题是基于形变分析模型的异常检测系统建设与实践。核心就是利用余弦相似度来分析数据。余弦相似度是一种衡量两个向量夹角余弦值的度量,它可以用来评估两个数据集之间的相似性。在异常检测系统中,通过计算数据点的余弦相似度,可以有效地识别出与正常模式显著不同的异常行为。这种方法有助于提高检测的准确性,并减少误报。
具体如何实现呢?
我们可以利用形变分析模型的2个公式。
归一化互相关(余弦相关性):
$$norm_corr(x,y)=\frac{\sum_{n=0}^{n-1}{x[n]\ast y[n]}}{\sqrt{{\sum_{n=0}{n-1}{{x[n]}}}}}\ast \sum_{n=0{n-1}{y[n]$$}}
形变量计算:
$$(1-余弦相关性)\times 基线变化量$$
- 第一个是分析与基线的角度差异性。
- 第二个是计算形变量,做归一化。这里我们需要同时考虑角度的变化和距离的变化。
import numpy as np
x=np.random.random(10)
y=np.random.random(10)
d1=np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y))
比如下面这张示意图:
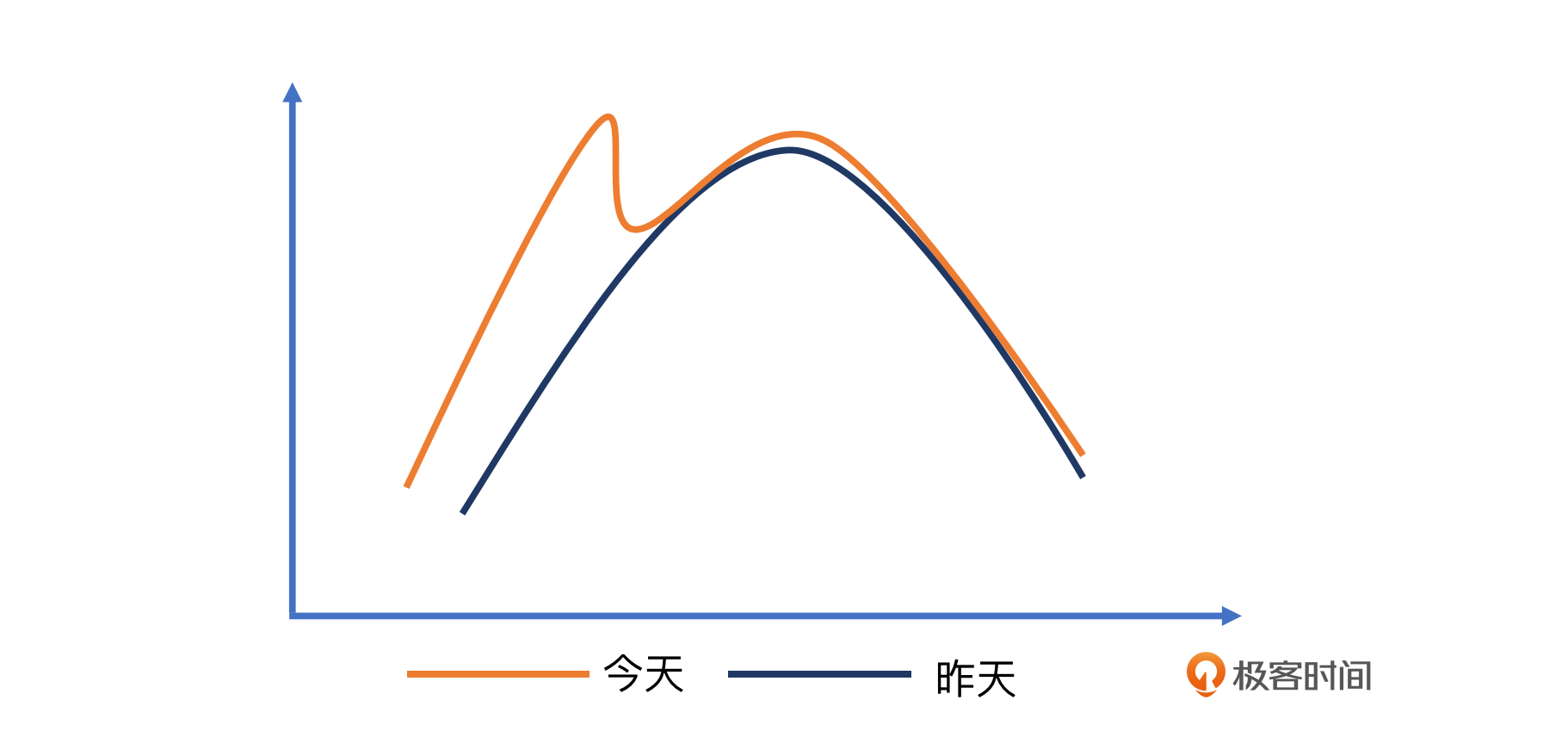
多指标联合判断的问题
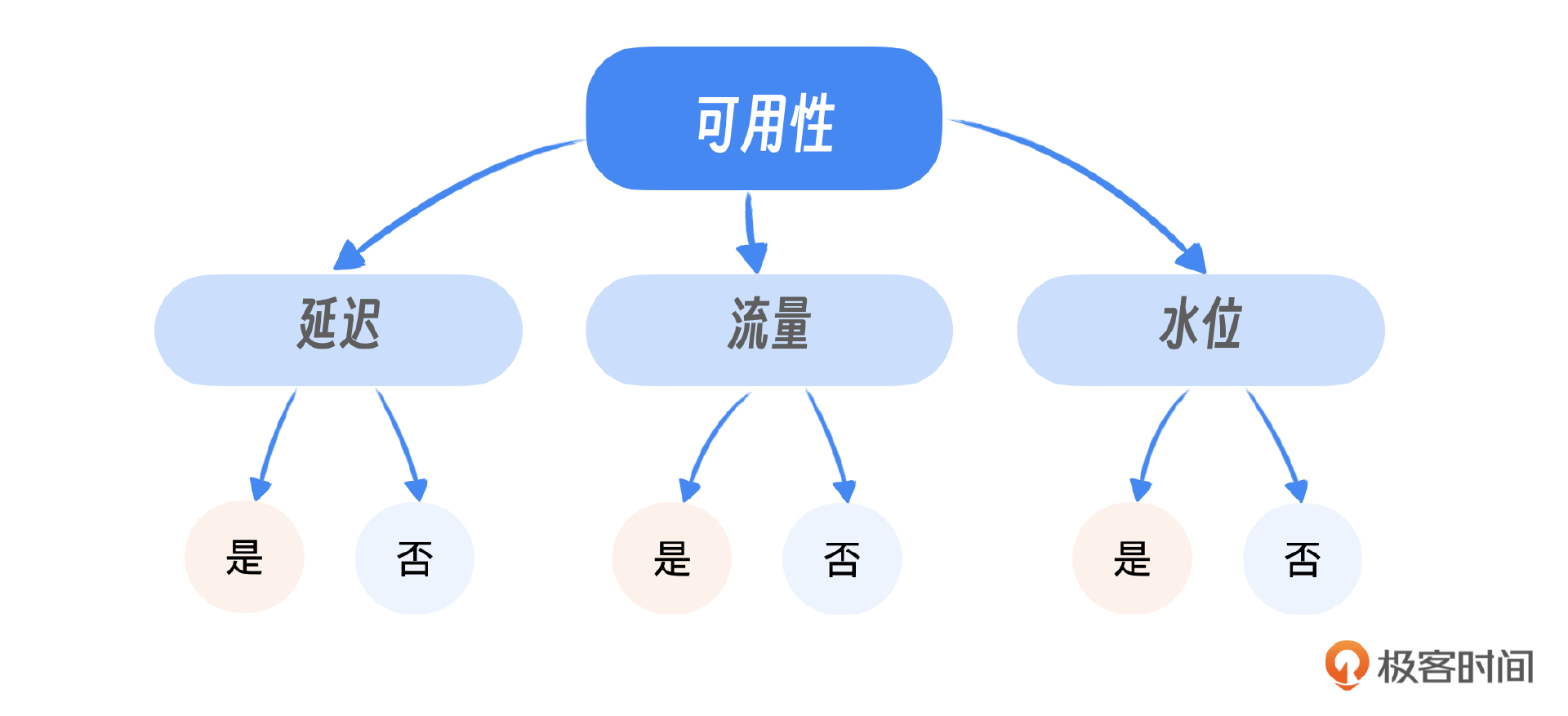
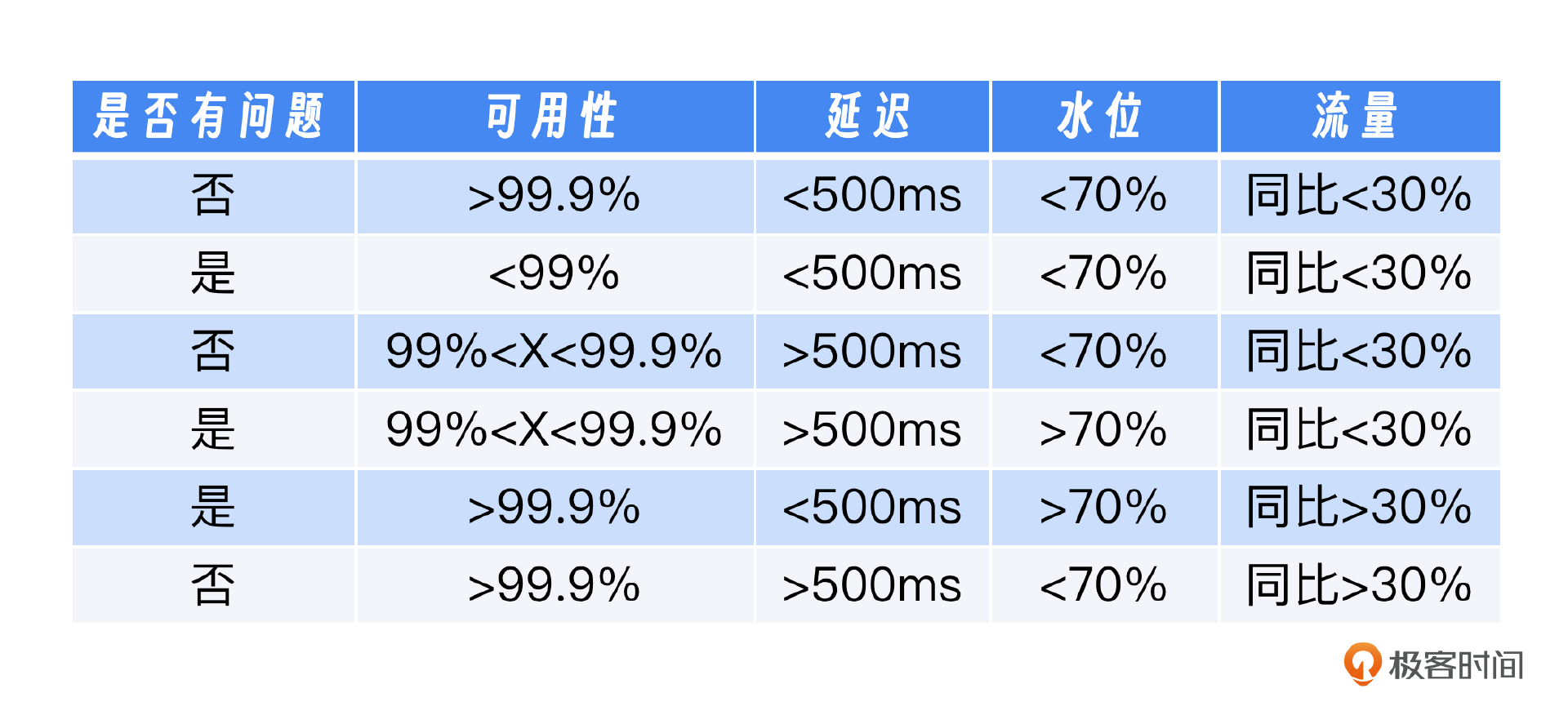
为了判断系统是否存在问题,这里我举个例子,比如我们有四个关键指标:可用性、延迟、水位和流量。这些指标的理解顺序应该是:首先识别那些能够直接明确区分正常与异常状态的指标,然后再考虑那些需要依赖其他指标来辅助判断的指标。
例如,可用性低于99%是一个明确的异常信号,因为它直接反映了服务的稳定性。此外,我们也不能仅凭流量的变化判断系统是否存在问题,还需要结合其他指标,如水位和延迟,来进行综合分析。水位指标反映了系统的负载情况,而延迟指标则显示了服务响应的速度。这些指标相互依赖,共同构成了对系统健康状况的全面评估。
在实际应用中,我们应该首先检查可用性,将其作为判断的起点或“根节点”。如果可用性指标正常,那么我们可以进一步分析其他指标;如果可用性指标异常,这通常意味着需要立即采取行动。通过这样的层次化分析,我们可以更有效地识别和处理潜在的问题。
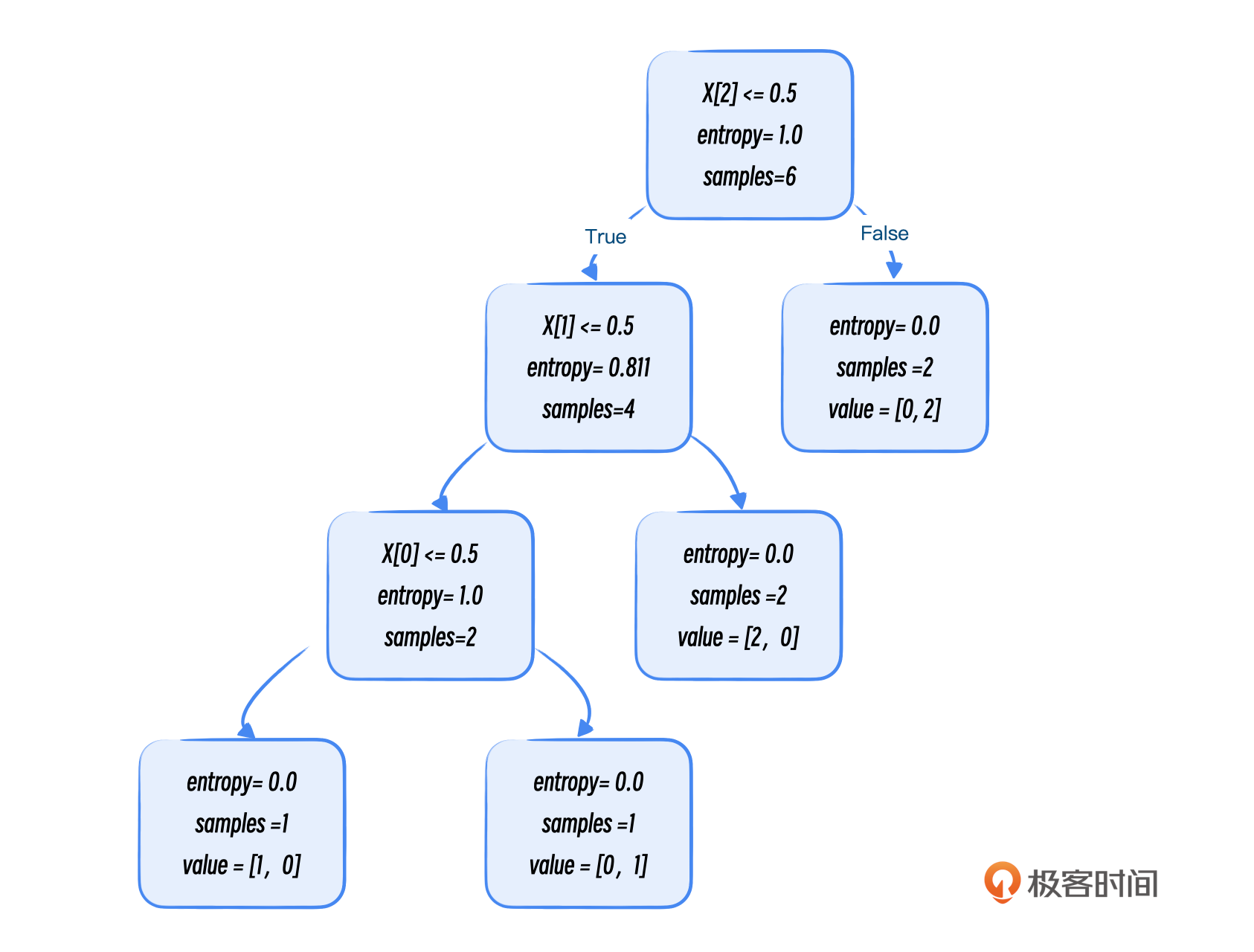
下面我们使用决策树分类器作为示例,展示如何从原始数据中提取特征,训练模型进行预测,并通过可视化工具理解模型的决策过程。
第一步:处理数据
第二步:训练模型
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
# 数据加载
train_data = pd.read_csv('./sla.csv')
features = ['sla','latency','waterlevel','follow']
print(train_data.head())
train_features = train_data[features]
train_labels = train_data['state']
# 构造 ID3 决策树
clf = DecisionTreeClassifier(criterion='entropy')
print(clf)
# 决策树训练
clf.fit(train_features, train_labels)
# 数据导出
with open("jueceshu.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file = f)
# 测试数据加载
test_data = pd.read_csv('./test_sla.csv')
test_features = test_data[features]
test_labels=test_data['state']
# 预测
pred_labels = clf.predict(test_features)
# 准确率验证
acc_decision_tree = round(clf.score(test_features, test_labels), 6)
print(u'score 准确率为 %.4lf' % acc_decision_tree)
结果:
第三步:可视化
执行命令可以导出PDF。
工程实现
基于决策树的基本思路
刚刚我们简述了三个算法的实现过程,下面我们看一个 AI 跟监控如何结合的工程实现的案例,下面这张图展示了目前监控报警与算法模型结合的基本流程和思路,整体分为两条线:一是离线训练;二个是实时检测和报警。
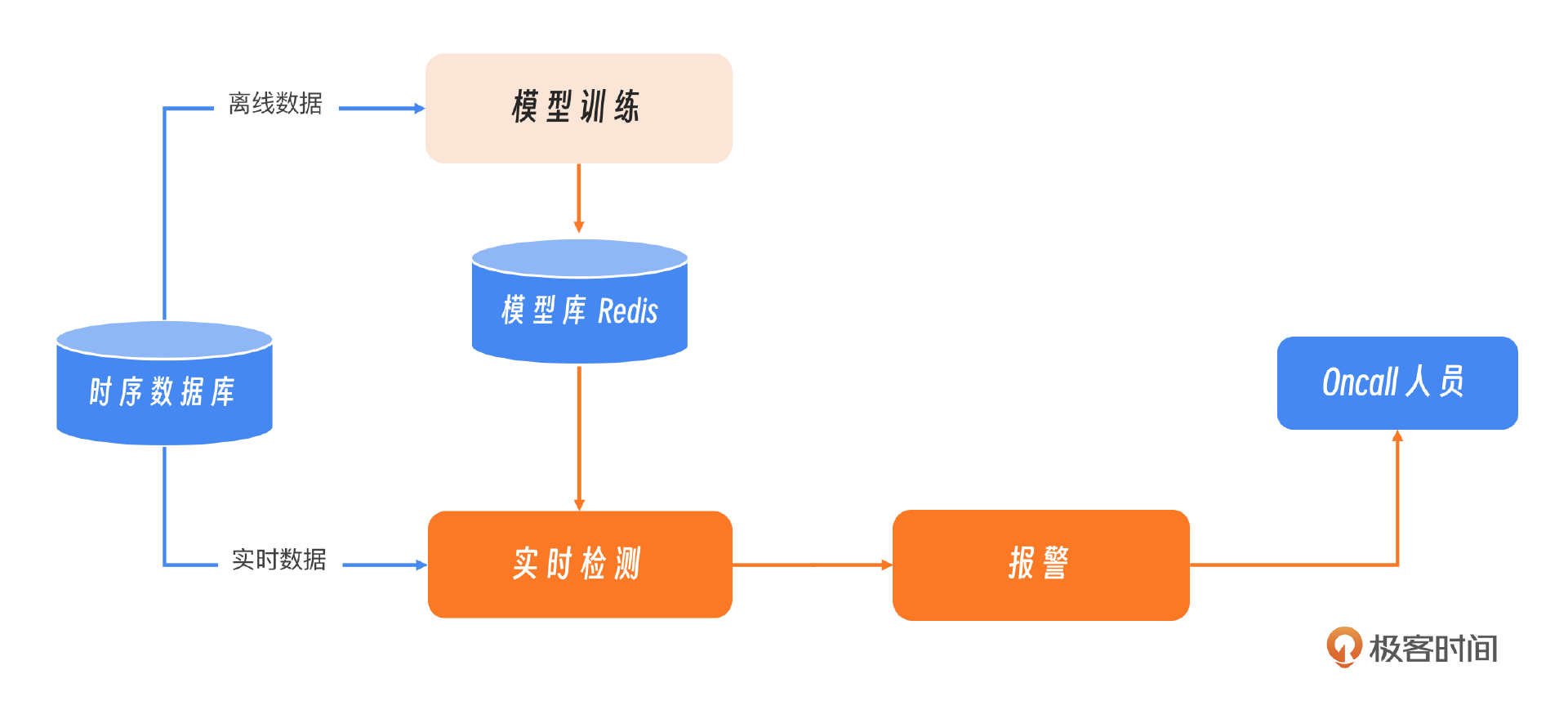
我们继续上面的决策树模型,如何把训练出来的模型进行保存呢?这里常见的做法就是把曲线的ID作为key进行保存,比如这个ID是99。离线模型训练的部分就结束了。
# 将模型序列化为字节流
model_bytes = pickle.dumps(clf)
# 将模型保存到Redis
r = redis.Redis(host='localhost', port=6379, db=0)
r.set('99', model_bytes)
接下来是实时监测部分,实时检测其实是把模型读取出来,然后对当前的数据进行预测。
# 读取模型
r = redis.Redis(host='99', port=6379, db=0)
model_bytes = r.get('decision_tree_model')
# 反序列化模型
clf_loaded = pickle.loads(model_bytes)
把当前的实时数据转化为DataFrame。
data = {
'sla': [1],
'latency': [1],
'waterlevel': [0],
'follow':[0]
}
df = pd.DataFrame(data)
# 预测
pred_labels = clf.predict(df)
print("---结果判断----")
print(pred_labels)
最后的结果:
传统监控+智能模型
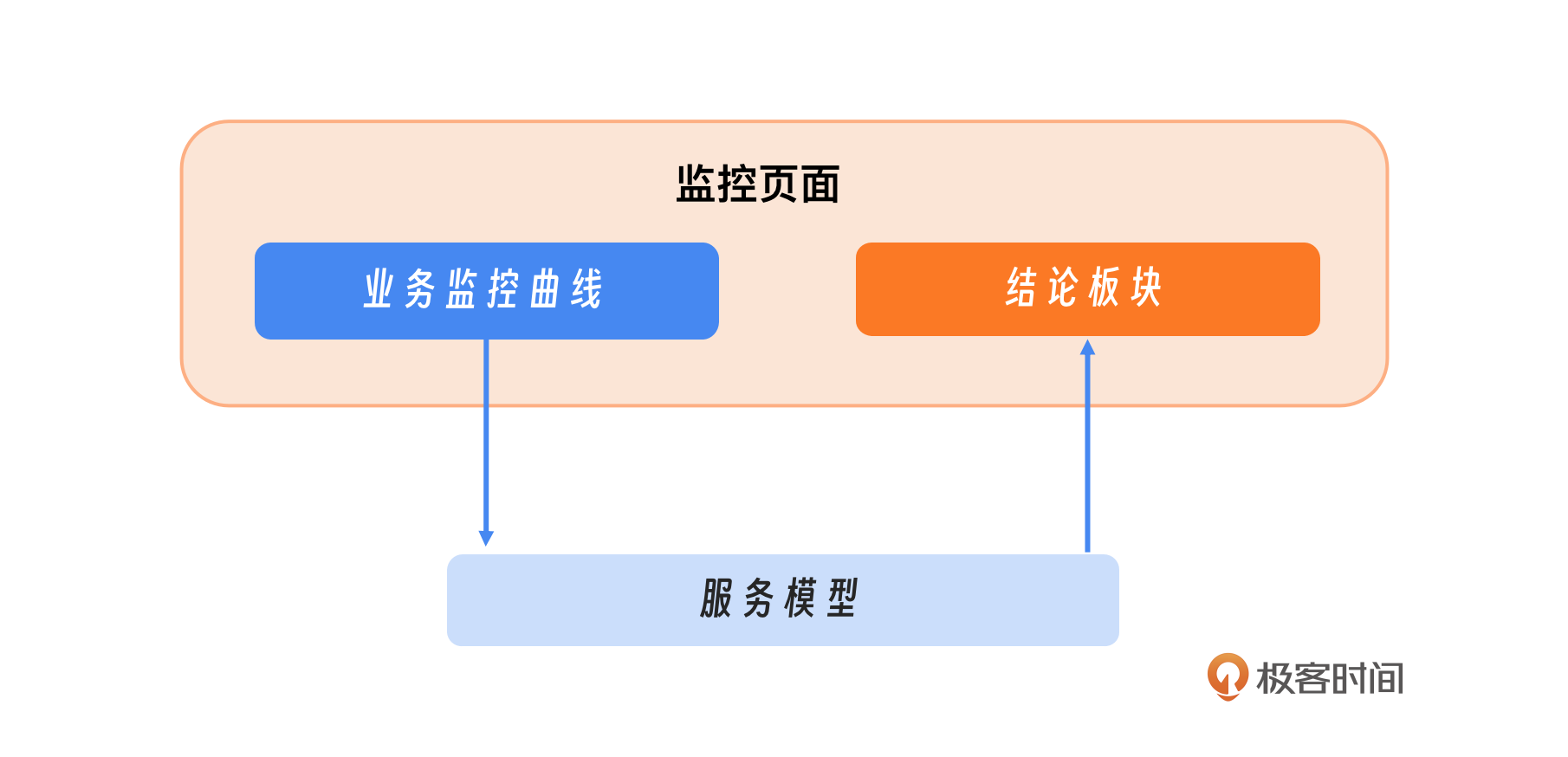
为了提升业务监控的效率和效果,我们可以在传统的业务监控曲线展示之外,引入一个智能模型,这个模型实现会在后续的课程中介绍。这个模型的职责是对监控和报警数据进行深入分析和总结,并将分析结果以结论的形式反馈到监控界面。这样一来,当我们查看监控时,不仅能看到各种数据曲线和报警信息,还能直接获得关键的分析结论,这会大大地提高我们对系统状态的理解和响应速度。
小结
这节课我们看到了目前AI与监控的结合能解决的三个问题:多而不同、细微变化、多指标综合判断。我们采用了四个算法:孤立森林、决策树、相关系数、形变分析,来提升业务监控的效率。最后我们基于决策树的思路,设计了一个监控+AI的工程实现。
目前针对异常检测,业界有非常多的优秀的案例和解决方案,比如这节课我们聊的美团在针对阴跌等场景的形变分析,百度用来解决频繁抖动和毛刺问题的基于概率的恒定阈值算法,还有清华基于VAE的异常检测Bagel,都是非常好的检测模型,你可以根据你的业务场景进行选择和组合。
思考题
你在工作中还遇到过哪些问题是传统的同环比无法解决,需要靠AI才能得到解决的案例和算法?欢迎你分享在评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 奔跑的阿飞 👍(0) 💬(1)
看完以后专业术语还是不少的,对于中小企业来说,对AIops做下了解即可,用好相关的云平台的AIops相关工具和平台即可。
2024-08-26 - InfoQ_4d14d6a85fb0 👍(0) 💬(0)
有理论有实践,的确是很干的干货
2024-09-22