17 可靠性意识:可靠性Oncall十大原则
你好,我是白园。
Oncall作为可靠性的第一道防线尤其重要。今天我以Oncall为例子,结合我自己的职业生涯的重大的转折和收获,以及周围影响巨大的事件、故障,总结抽象成10条原则分享给你,帮助你养成可靠性意识。
原则一:态度决定命运,我们需要保持积极的心态
我一开始入职百度的时候由于刚从学校毕业一切都不太适应,而可靠性工作、运维工作是一项非常琐碎的工作,也容易让人反感、抵触。Oncall的时候心态也是悲观、抗拒的。最终在第一次绩效也是收获了第四档(差的一档),晋升也没有通过,这个也是我工作中第一次低谷。
当时想离职或者内部转岗,不过我最终还是思考了一下,下定决心从哪里跌倒必须从哪里站起来。首先就是从心态做起,Oncall的时候不再抱怨和抗拒,转而变成了抱着争口气的心态,做好每件事情。而坚持下来的结果也是好的,后续得到了快速的晋升,也完成了一次自我的蜕变。
这次事件也是我人生道路上从学校进入社会之后学到的第一堂课。很多事情并不是看起来那么难,在任何事情面前都需要保持一个积极的心态。什么是积极的心态,乐观、热情、皮实/耐挫。稻盛和夫提出一个理念:人生工作的结果=思维方式热情能力,热情是一切的源动力。埃隆·马斯克说过一句话,宁可要错误的乐观,也不要正确的悲观。董宇辉在多次演讲也反复提到要有一个皮实的心态。
人与人之间的差异,归根结底在于心态二字。一开始我也认为这是一句鸡汤。直到一些事情真实发生在自己的身边,并且这些事情直接决定了个人不同职业生涯的发展。
原则二:补位意识
当我在低谷期的时期其实还有一件事情对我的影响挺大,那段时间总感觉做什么都是错的。直到有一次轮到我Oncall的时候,发生了一次重大故障。在处理故障的时候其实是另一个团队的问题,也不是我们团队的事情,如果我当时什么事情也不做其实也可以,最终不会追责到我头上。但我还是选择先积极推动问题解决,在得到对方的解决方案之后亲自动手解决了问题。
这次的事情之后,我也得到了部门领导的肯定,当时给我的反馈的意见就是补位意识很好,这对一个刚毕业而且处于一个低谷期的应届毕业生来说无疑是一剂强心针。在我后续的职业生涯中起到了非常关键的作用。在次年的晋升、年终绩效、调薪都取得不错的反馈。
补位意识对于Oncall人员来说至关重要。它要求我们在发现问题时,无论是否属于自己直接负责的范畴,都应采取行动,及时通知相关人员,并尽可能协助处理,以保障整个系统的稳定运行。这种意识不仅能减少故障带来的影响,也能在团队中树立起专业可靠的形象,对个人职业发展大有裨益。
原则三:用户为先意识
在处理问题时,用户意识的培养至关重要。这也是我在百度学到的第三课。
百度的“魏则西事件”就是一个典型的缺乏用户意识的严重案例。这个案例当时这样处理,公关在对处理用户的态度上非常冷淡,百度的第一时间回应是摘除关系,“对于则西生前通过电视媒体报道和百度搜索选择的武警北京总队第二医院,我们第一时间进行了搜索结果审查,该医院是一家公立三甲医院,资质齐全”,虽然客观上来说的也是事实,但是并没有从用户的角度来思考问题,导致了后续的一系列严重的事件,损失至少几十上百亿元,造成了非常恶劣的影响。
这个案例教会我们,作为服务提供者,我们应该始终将用户的利益放在首位,通过有效沟通建立信任,减少不确定性带来的恐慌和不满。
原则四:Oncall前做好准备
在Oncall之前我们要做好详细的准备,否则一旦出现问题,你又无法正确处理,对于故障来说反而会起到相反的效果。要做哪些准备呢?
最基本的就是要保证Oncall的时候能快速感知到问题。电话畅通,保证手机的震动,以及检查是否有运营商配置的黑名单屏蔽,否则一个关键的报警很容易被屏蔽掉。电脑和网络,时刻保证电脑在身边,并且网络畅通,提前把VPN的权限申请好。内部系统的各种权限需要提前申请好,确保能第一时间感知到问题。
其次是能找到合适的人处理问题,提前熟悉有哪些监控和报警,报警出现的时候应该采取什么级别去处理。了解上下游的协同响应机制,一旦出现多团队配合的故障,需要第一时间找到相关人员。此外,之前处理问题的SOP也非常关键,最好是能自己实践一下,确保对文档理解的准确性和熟练度。
最后就是能掌控处理的方案和节奏,这个就是需要深入业务、架构、基建,去了解清楚。当有问题的时候,可以独立判断和思考,并独立处理。

原则五:严格地规范Oncall过程
Oncall主要分为两种状态,一是有故障或者异常的状态;二是无故障或者无异常的状态。大部分时间都处于无故障的时候,这个时候Oncall需要做好三件事情:定期巡检,来发现那些可能潜在的隐患, 比如流量的增长或者下降、资源是否足够等;每天的日报总结和沉淀,比如今天的流量、日活、峰值、问题的处理、上线情况等等;快速响应,关注群消息,做好及时的反馈和处理。
如果遇到紧急情况如何处理呢? 首先作为Oncall最重要的事情就是明确发生了什么,具体是什么影响,影响到了谁。其次是通报,让更多人知道发生了什么,让应该处理的人去处理,而不是一出现问题马上就埋头去处理,不做任何的通报,这样很可能走弯路浪费时间。如果需要自己去操作,那可以请求别人去做故障协助,自己再去处理。
简而言之就是一确认,二通报,三操作。

原则六:Oncall后认真复盘和总结
我记得在一次严重的系统故障中,我们团队陷入了一片混乱,不知所措。正当大家焦急寻找解决方案时,一位同事勇敢地站了出来,当时他不仅迅速定位了问题所在,还及时采取措施,有效控制了损失,将影响降到了最低。
不过他并不是故障服务负责人,他之所以能够做出关键判断,就是得益于他在前年的一次故障中进行了深入分析和总结。他不仅找到了问题的关键日志,还制定了相应的处理方案。这次成功的应对不仅赢得了领导的高度赞扬,也为他日后的晋升奠定了坚实的基础。所以深入的复盘分析,避免在同样的问题上重蹈覆辙,不仅可以快速解决新问题,对个人而言更重要的是能够抓住职业机遇。记住,机遇总是青睐那些做好准备的人。
原则七:避免同时处理多个重要任务
同时进行两项重要的变更或任务可能会分散你的注意力,从而影响对细节的关注和处理质量。之前,我遇到过一个case,就是一个同学在一次Oncall过程中,由于同时进行了两项重要的变更,没能对监控系统进行充分地检查,导致了监控疏漏,最终引发了严重的故障。
为了提高效率,减少风险,我们应该一次专注于完成一项重要任务,并确保有足够的时间和资源来仔细检查和验证每一步。确保每个变更都经过了充分的测试和评估,避免潜在的问题和故障。专注于单一任务,直到完成,然后再转向下一个,是提高工作质量和保障系统稳定性的有效策略。
原则八:杜绝侥幸心态
最近,我们经历了一次机房电路检修,情况十分严峻:双路市电同时中断,仅靠柴油发电机供电。这时候任何故障都可能导致严重后果。为此,我们全力以赴,制定了详尽的应急预案,并提前了12小时启动系统进行设备监测。幸运的是,我们的努力得到了回报,最终实现了零事故。
然而,几天后,我们使用的云服务提供商也遇到了类似情况,但他们没有制定任何预案,而且只在停电前两小时启动了柴油发电机。结果,系统很快就出现了故障,而此时市电已经中断,引发了一次非常严重的故障。这一经历再次提醒我们,面对潜在风险,绝不能掉以轻心。充分的准备和预防措施是避免灾难性后果的关键。
原则九:不要轻易放过任何一个异常
在处理问题的时候,我们不能忽视任何细微的波动。我曾遇到一个案例,当时的情况是这样的,kwaipro的上传、播放、评论等多个流量都有略微地下降,后来排查时候发现当地有活动;经过历史上对比发现有活动的时候往往会有流量的下降,但都是播放、评论在下降,而上传却是上涨的。
初步感觉是上传的表现是异常的,后来我把这个问题和现象也反馈给了相关团队,而这个团队的Oncall同学当时却无心进行深入排查,最终给出了错误的反馈。等到第二天活动结束了,播放、评论的流量恢复了正常,而上传的流量依然没有恢复,终于又做了一轮更加详细的定位,发现了异常,但这个时候已经演变成严重的故障,损失可想而知。最终这个案例也被当成了后续大家学习的典型案例。
原则十:不要隐瞒
这里要说的案例也是我接触过的一次事故,一个工程师因为一次错误的操作导致大量服务内核夯死,引发线上重大故障。最重要的是他因为害怕承担责任,没有第一时间说出自己做了什么操作。之后也故意隐瞒,最后在证据面前才不得不承认。耽误了大家时间同时也影响了线上的恢复,严重触犯了红线。如果第一时间能选择坦诚,那么影响范围将会小得多,解决起来也会更加高效。
所以在紧急情况下,及时、准确地分享信息非常关键。当问题发生时,迅速通报并采取透明的态度,不仅有助于快速定位问题,还能减少由于隐瞒或延迟造成的不必要损失。因此,培养一种开放、坦诚的沟通文化,以及鼓励团队成员在遇到问题时勇于承担责任,对于提高团队的响应能力和整体效率至关重要。
小结
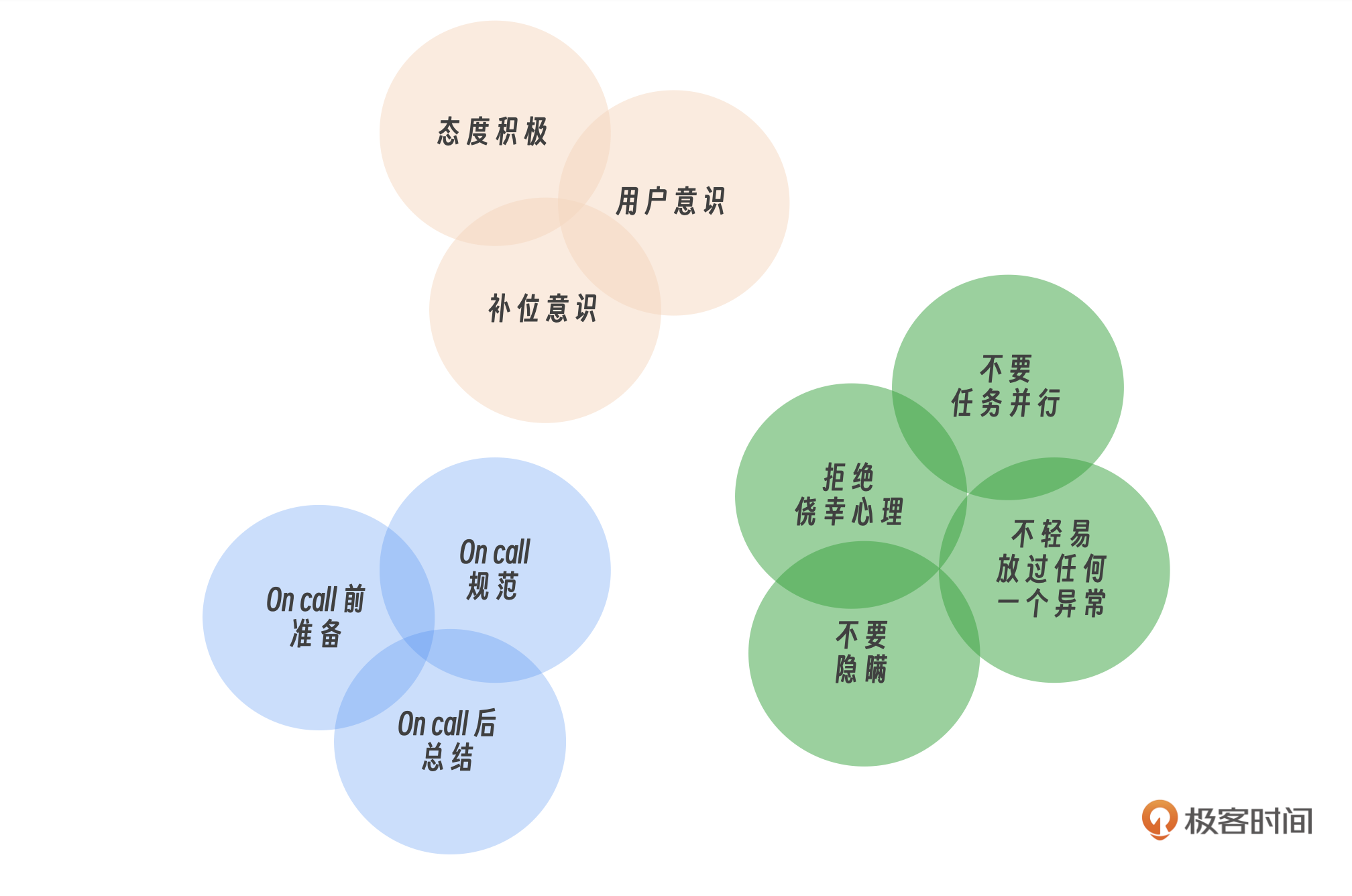
这节课我们归纳了Oncall工作的十大核心原则,旨在提升值班效率和系统稳定性。具体包括:
- 一个核心态度:保持积极主动,面对问题和挑战时展现出解决问题的决心和热情。
- 两个基本意识:补位意识,在团队中相互支持,主动填补可能出现的职责空缺。用户为先意识,始终将用户的利益放在首位,确保服务的连续性和质量。
- 三个行动准则:事前准备,在Oncall前进行全面的准备工作,包括熟悉系统和工具。事中规范,在Oncall期间,严格遵循既定的操作规范和流程。事后总结,值班结束后进行详细的总结,包括问题解决和经验教训。
- 四个禁忌:避免多任务处理,不同时进行两项重要任务,以保持专注和效率。杜绝侥幸心理,不忽视任何小概率事件,始终保持警惕。重视异常,不放过任何异常情况,及时调查和处理。不要故意隐瞒犯下的失误。
思考题
如果晚上你突然收到一个报警电话,需要做紧急上线,这个时候你发现没有人审批流程应该是选择跳过流程还是继续打电话找人呢?欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
可靠性意识遍布各行各业
历史上曾经发生过一次非常严重的技术灾难——切尔诺贝利核电站泄漏事故,1986年4月26日凌晨,切尔诺贝利核电站接到基辅电网的通知,准备进行停堆测试。但由于班次更换和交接工作存在的疏漏,新接班的操作员对测试程序并不熟悉。在副总工程师的命令下,尽管缺乏充分培训,这名操作员还是在压力下开始了操作。副总工程师为了达成业绩指标,忽略了安全建议,甚至以解雇相威胁,逼迫操作员继续操作,这一系列决策最终导致灾难发生。
- 若水清菡 👍(3) 💬(1)
如果晚上你突然收到一个报警电话,需要做紧急上线,这个时候你发现没有人审批流程应该是选择跳过流程还是继续打电话找人呢? 这个问题要两方面区分,一是能明确定位到原因,必须上线才能解决,这种联系不到审批人的情况下需要当机立断,先解决线上问题(公司服务运维应急响应流程应该有这种特殊情况的规定) 二是持怀疑可能性的,这种需要上线加一些排查日志的log来帮助定位的,需要联系到审批人再进行上线操作。要学会保护自己,完全遵守审批流程是最好的方式。
2024-08-22 - includestdio.h 👍(0) 💬(1)
我们现在公司技术团队基本就是我一个运维+一整个开发团队,除了明确的代码问题,比如 panic 等,绝大多数问题都由我来响应(因为故障问题领导只找我,他也不确定是哪个团队应该处理这个问题),由我来推进,领导一直在 push 我提供各种进度,但是这种补位导致的结果就是,代码的问题虽然我什么都干不了几乎,但是压力仍然在我,最终问题的复盘也是我,开发同学反而成了辅助,甚至从领导角度,“锅”也在我,有点吃力不讨好的无力感,现在已经属于是习惯了...
2024-09-29