16 备份和恢复:一次误操作中断7小时
你好,我是白园。今天我来分享数据备份的案例和背后的本质,数据可靠性如何保障和提升,我们先看两个案例。
2018年8月,腾讯云的客户“前沿数控”,遭遇了操作系统云盘故障,故障导致文件系统元数据受损。针对这个事件,腾讯云随后发布了一份技术性复盘报告,复盘结果显示,故障的起因是磁盘故障,导致数据出现了单副本,又因为数据迁移过程中两次不当操作,最终导致云盘的三副本完全丢失,最终影响了整个数据的完整性。
2023年10月23日,语雀平台发生了一次重大服务中断事件,故障时间超过7小时。经过调查,故障原因因为运维升级工具的缺陷而导致存储数据意外下线,进而引发了大规模的服务中断,比较幸运的是依靠备份的数据进行了恢复,最终没有造成数据的丢失。
从这两个案例来看,数据的备份和恢复非常重要,一旦数据丢失会造成非常大的影响和故障。那数据的备份和恢复的背后本质到底是什么呢?本质就是如何保障数据可靠性。
什么是数据可靠性?
数据可靠性是指存储数据的时候,数据能够保持完整性、可用性、一致性和持久性的能力。各个云存储都有自己的数据可靠性,比如AWS的S3数据可靠性是11个9。百度云存储的可靠性是10个9,腾讯云的是11个9,阿里云是10个9,dropbox是11个9。
这个数据可靠性到底如何衡量呢?这里有两种方法。
一种是简便的事后评估方式,计算公式为 1−丢失数据量/总数据量。这种方法容易理解和实施,但它主要依赖于已经发生的事件,因此受到随机性因素影响较大。
另一种这种方法更复杂,但提供了一个全面的可靠性评估。它基于经典的可靠性工程公式,考虑了硬件故障率和系统的平均恢复时间。通过这个公式,可以更准确地预测和衡量系统在实际操作中的可靠性水平。

这个公式里面有几个关键参数我来解释一下。
- 副本数(N),指的是数据备份的份数。直观上,副本数量越多,数据的可靠性越高,因为这样可以抵御更多的故障情况。然而,增加副本数会提升成本,因此需要在成本和可靠性之间做出平衡。
- 故障率(F),包括硬件故障率、软件故障率和人为操作故障率。这个参数反映了系统在一定时间内出现故障的可能性。特别值得注意的是,硬件故障率往往随着时间呈现出浴盆曲线(bathtub curve),即在系统生命周期的早期和晚期故障率较高,而在中期则相对稳定。
- 恢复时间(T),指的是系统在发生故障后恢复正常运行所需的时间。故障恢复时间对可靠性至关重要,因为快速的故障发现和恢复可以显著提高系统的稳定性。通常,恢复时间与数据恢复成功率呈负指数关系,即恢复时间越短,恢复成功率越高。
- 故障类型(i):涉及故障的多样性。系统遇到的故障类型越少,数据越可靠。不同类型的故障可能需要不同的应对策略,因此了解故障类型对于制定有效的风险管理计划至关重要。
如何进行数据的可靠性建设?
通过上面的公式,我们可以看到影响可靠性的因素有四个,副本数、故障率、恢复时间、故障类型。 所以对应的解决方法就是增加副本数、降低故障率、提升恢复时间(提升发现效率和提升修复效率)、减少故障次数。我们一个一个来看。
增加副本
提升数据可靠性的首要策略是增加副本数。这可以通过下面几种常见的方式来实现,不过每种方法都有优势和局限性,选择合适的策略需要综合考虑数据的价值、存储成本以及业务需求。
直接增加副本是最直接的方法,通过在不同的存储介质或服务器上复制数据,来提高数据的冗余度。直接增加副本会导致成本的增加,这个时候你可以选择重要的数据增加副本。
使用纠删码(Erasure Coding,简称EC)是一种更高效的数据保护方式,通过计算额外的校验块和数据块,可以在减少存储开销的同时提供高容错性。
数据备份是一种成本效益高且有效的策略,通过将数据复制到不同的物理位置或云存储提供商来实现。这种方法不仅提高了数据的可恢复性,而且通常实现起来成本较低。但是实效性会差些。我们可以选择核心的数据进行备份。
降低故障率
为了减少硬件故障,我需要定期把数据从过保服务器,迁移到新的服务器上。因为随着时间的推移,磁盘等硬件设备会经历浴盆曲线,也就是说,故障率在设备使用初期和接近寿命末期的时候会比较高。因此,及时的数据迁移,可以有效避免在故障高峰期出现问题数据丢失。此外,利用磁盘故障预测技术,尤其是对于有写入次数限制的SSD,可以提前识别潜在故障并进行更换,从而进一步提高数据的可靠性。关于磁盘故障预测,我会在AIOps篇介绍。
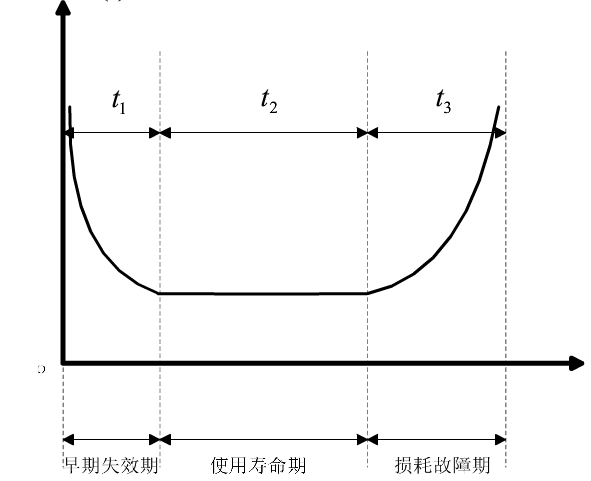
提升发现效率:数据校验
故障修复的时间越短,修复的成功率越高,如下图所示,在早期能发现的话数据恢复的概率是非常高的,越到后面恢复的概率越低。所以这里的关键在于能否快速发现,快速恢复。
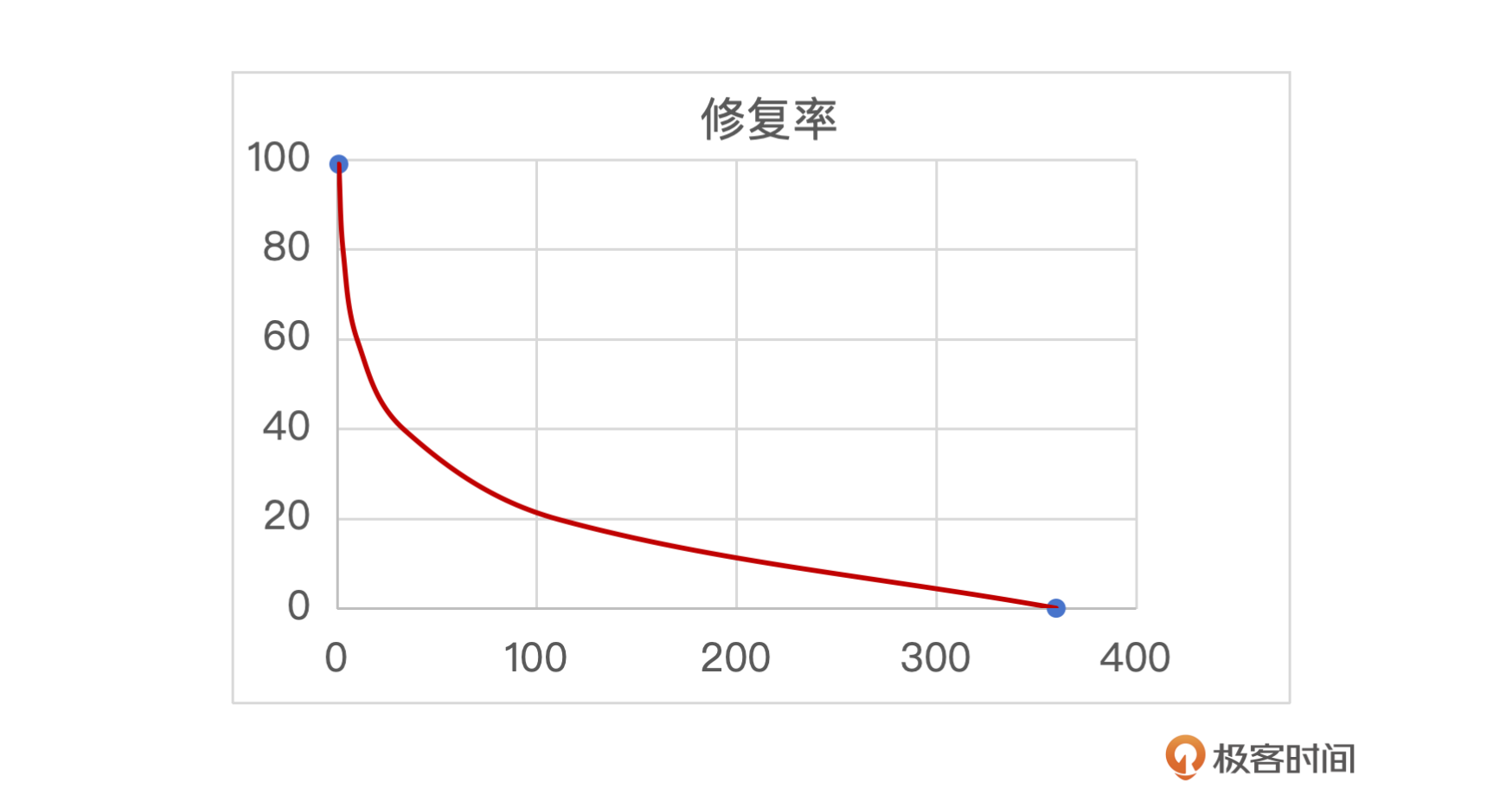
我们可以采取数据校验的方式,核心目标是确保数据的实时性和完整性。然而,这两个目标在实际操作中往往存在一定的冲突,如果检验频率太高,扫描力度太大就会影响到正常的线上服务,因为会使用大量的资源,如果校验太粗,频率太低又无法及时发现问题。
此外数据校验有抽样校验与全量校验两种方式,抽样校验可以快速识别潜在的数据问题,而全量校验能够确保数据的全面准确性。二者结合使用,可以在保证系统性能的同时,不遗漏任何数据问题。
如果是抽样校验的方式,注意不同时间的数据要控制抽样比,新的数据抽样比可以高一些,老的数据抽样比可以低一些。对最近写入的文件执行读写操作。这种检测通常以千分之一或百分之一的比例进行,既不会对系统性能造成过大负担,又能高效地发现潜在问题。由于系统问题往往具有全局性,一旦发生,抽样检测能够迅速揭示问题所在。
如果是全量校验的话,我们就可以采取分层处理、数据聚合和交叉验证几种方式来辅助。
- 分层处理:目的在于将不同的问题分配给专门的系统层次来解决。通过这种方式,每个层次可以专注于它设计的任务,从而提高整体系统的效率和针对性。
- 数据合并:相同数据层的数据进行合并降低IO的压力,比如在写入数据的时候可以整体记录这个数据块的md5,在后续校验的时候先进行块级别的校验,一旦发现校验不通过再进行单条校验,来发现有问题的key。
- 交叉验证(互证):通过比较不同数据源或备份之间的信息,可以验证数据的一致性。
下面我以网盘为例来介绍一下。
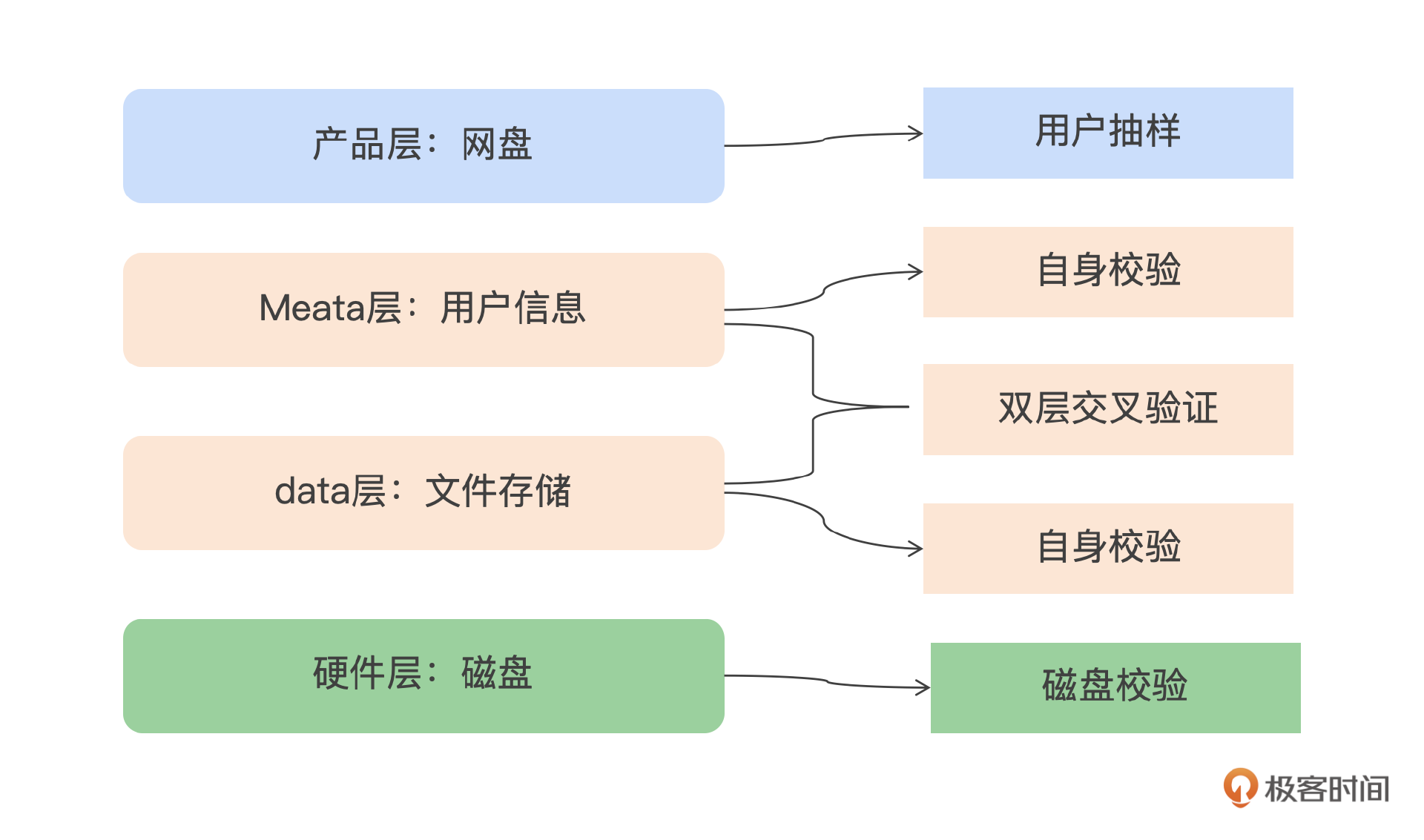
业务层关注用户操作的直观体验,比如网盘服务中上传与下载文件的一致性。确保用户交互层面的数据展现无误;平台层验证存储一致性,监控存储平台的副本完整性,包括副本的数量是否符合预期,以及不同副本间的数据是否保持一致;硬件层关注数据完整性,检查硬件层面的数据是否遭受损坏,例如检测是否有位翻转(bit flip)等硬件故障的迹象。
通过两层互验的方式来检验元信息一致性,确保不同层级之间的元数据保持一致,通过交叉校验来强化数据的完整性。为了确认存储的数据是否完整,需要对元数据进行校验,包括在数据存储层额外存储一份元数据副本。利用存储层的元数据副本与元数据存储层的信息进行对比,确保数据的完整性和一致性。
提升修复效率:数据恢复
故障自动修复在确保数据可靠性中扮演着至关重要的角色,我们利用分布式存储平台的内置修复功能,再辅以人工干预来补充平台的限制,就能达到不错的效果。
理想情况下,如果平台能够自主感知到损坏的数据块并及时完成修复,这就是最高效的解决方案。在进行数据修复时,还需要考虑硬件故障对整个系统的影响,来选择磁盘的修复顺序。优先修复那些剩余副本数少的磁盘,防止数据丢失。
在许多情况下,平台可能无法感知到所有故障,或者感知到故障但需要人工介入处理。这时,需要使用专业工具来解决平台无法自动修复的问题。例如,当磁盘发生故障导致部分数据无法读取,且磁盘检查工具已经识别出问题,但因为用户正在访问数据,平台未能感知到数据损坏。在这种情况下,需要人工触发修复流程。
减少故障类型:人为故障
就像语雀的故障,因为新引入的运维工具存在缺陷,导致正在运行的服务器意外下线,就属于人为故障。这类故障我们应该尽量避免。为了降低人为故障的发生概率,我们需要重点关注运维工具的使用和管理,因为它们是导致服务器意外下线的主要原因。
对于任何可能影响服务器正常运行的运维工具,尤其是那些涉及服务器下线操作的工具,必须进行严格的风险评估,并且任何关键操作都应该要求人工审查和确认,避免误操作。此外,在执行机器下线之前,必须确保该机器上的所有服务已经完全摘除。这是防止数据丢失和简化恢复过程的重要前提。
在开发和使用运维工具的时候,必须遵循严格的流程和规范,确保工具的稳定性和安全性。此外,任何运维操作都应明确限制它的影响范围,比如限制在特定的区域或可用区(AZ)。语雀这次的事件暴露出来的,就是他们有可能没有充分实施多AZ的故障隔离措施。
小结
这节课我们讨论了对数据可靠性的影响,以及应对方式。重点从四个方面来提升数据可靠性:利用系统功能、EC、备份来提升关键数据的副本;利用数据迁移、磁盘预测降低软硬件的故障率;提升数据校验和数据恢复的整体恢复时间;同时通过严格的流程、工具和平台来避免人为因素导致的故障。
推荐一篇文章
dropbox的校验思路:https://dropbox.tech/infrastructure/pocket-watch 可靠性计算公式:Next Generation Scalable and Efficient Data Protection
思考题
数据备份和程序备份有什么区别,哪些方向需要考虑程序的备份呢? 欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- cx 👍(0) 💬(1)
请教下,这里提到的数据校验,是开发在程序层面做呢,还是运维备份的时候去对备份数据做校验呢?
2024-09-24