14 预案场景(一):B站最为深刻的一次自我剖析
你好,我是白园。
今天我们开始进入预案场景故障的分析。这节课我们就来分析一下 B 站 2021 年 7 月 13 日的故障这也是我见过的公司对自身故障剖析得最详细的一次,我们来看看能从中学习到什么内容。
故障回顾
7月13日23时许,B站客户端和网页端均出现访问故障,无法打开,页面提示“正在玩命加载数据”。不久后,“B站崩了”话题也迅速登上微博热搜。14日凌晨B站网页端和App才恢复正常。
22:52是故障开始的时间,SRE团队接到了关于服务和域名接入层不可用的多起警报。与此同时,客服部门接到了大量用户反映B站无法访问的反馈,公司内部员工也报告了相同的问题,包括App首页加载失败。根据报警信息,SRE团队迅速把注意力集中在可能的基础设施故障上,包括数据中心、网络连接、四层负载均衡器(L4 LB)和七层负载均衡器(L7 SLB)。为了迅速应对,SRE团队立即启动了紧急语音会议,并召集了所有相关团队的成员进行紧急处理。

故障原因:7 层接入 SLB 代码 Bug
B站在2019年9月份,迁移到了OpenResty,通过服务在注册中心的权重变更,来实现SLB的动态调权,从而实现更精细的灰度能力。在某种发布模式中,应用的实例权重会短暂地调整为0,这个时候注册中心返回给SLB的权重是字符串类型的0。这个时候由于lua语言的特性并不会强制转化字符串的0为数字0,程序就会陷入到死循环进而把worker打死。
根因分析

Lua 是动态类型语言,常用习惯里变量不需要定义类型,只需要为变量赋值即可。 Lua在对一个数字字符串进行算术操作时,会尝试将这个数字字符串转成一个数字。 在 Lua 语言中,如果执行数学运算 n % 0,则结果会变为 nan(Not A Number)。 _gcd函数对入参没有做类型校验,允许参数b传入:“0”。同时因为"0" != 0,所以此函数第一次执行后返回是 _gcd(“0”,nan)。如果传入的是int 0,则会触发[ if b == 0 ]分支逻辑判断,不会死循环。 _gcd(“0”,nan)函数再次执行时返回值是 _gcd(nan,nan),然后Nginx worker开始陷入死循环,进程 CPU 100%。
这里的根因分析你了解就可以了,如果你有兴趣可以直接看当时 B 站发布的报告。而我们这节课的重点是发现这个案例中的问题,并讨论优化策略。接下来我们先分析一下这次故障里的几个关键点。
故障分析
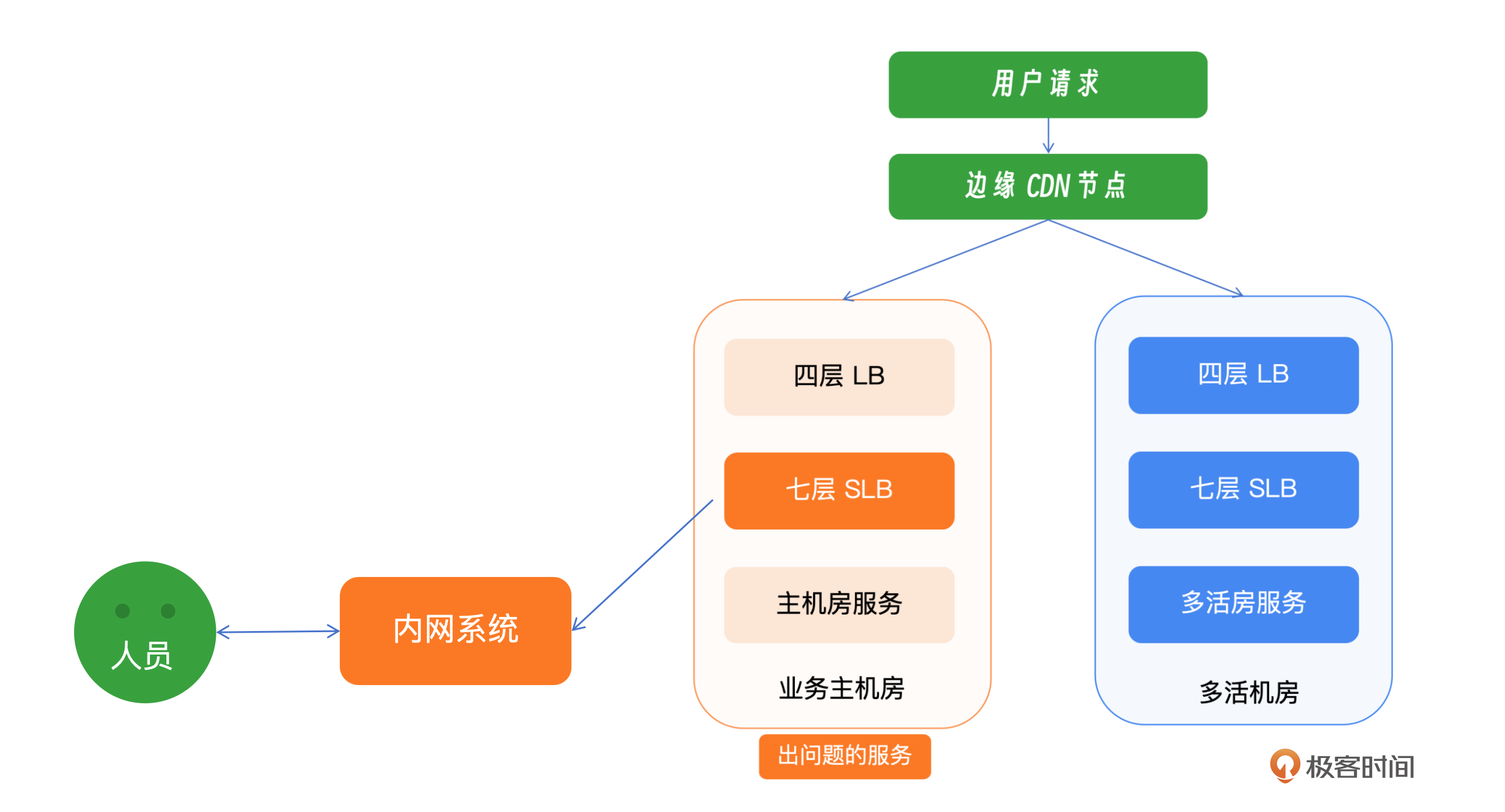 首先是响应时间,用了3分钟,还是非常快的。那是否可以再加加速呢?理论上来说比较难,这里就不再重点讨论。
首先是响应时间,用了3分钟,还是非常快的。那是否可以再加加速呢?理论上来说比较难,这里就不再重点讨论。
其次是准备时间,用时22分钟,这段时间我们看到 B 站做的最重要的操作就是了解如何通过绿色通道登录内网系统。这段时间暴露了两个问题,第一个是内网鉴权系统和接入层的循环依赖,第二个是如何通过绿色通道登录机器,就是日常紧急情况的演练和覆盖的缺失。
故障恢复过程历时110分钟,从00:00开始至01:50结束。在这段时间内,SLB新集群的搭建工作耗时60分钟,包括集群的搭建、初始化、负载均衡配置以及公网IP的分配。随后的50分钟内,团队开始逐步切换流量至新集群。
在多活业务的恢复方面,SLB运维团队发现多活机房的SLB存在大量请求超时的问题,但幸运的是,CPU并未出现过载的情况。因此,团队决定先重启多活机房的SLB,以尝试控制问题的扩散。在重启操作进行时,内部群组中的同学报告称主站服务已经恢复。进一步观察多活机房SLB的监控数据,发现请求超时的数量显著减少,业务成功率回升至50%以上。随着这些措施的实施,多活业务的核心功能,包括App推荐、播放、评论与弹幕拉取、动态更新、追番以及影视观看等,已基本恢复正常。

这里我们可以回顾一下B站几个有效的止损动作。全程时间178分钟,一是登录内网用时 22分钟。二是无效尝试重启用时30分钟。三是服务搭建用时60分钟。四是服务切流用时50分钟。
故障优化
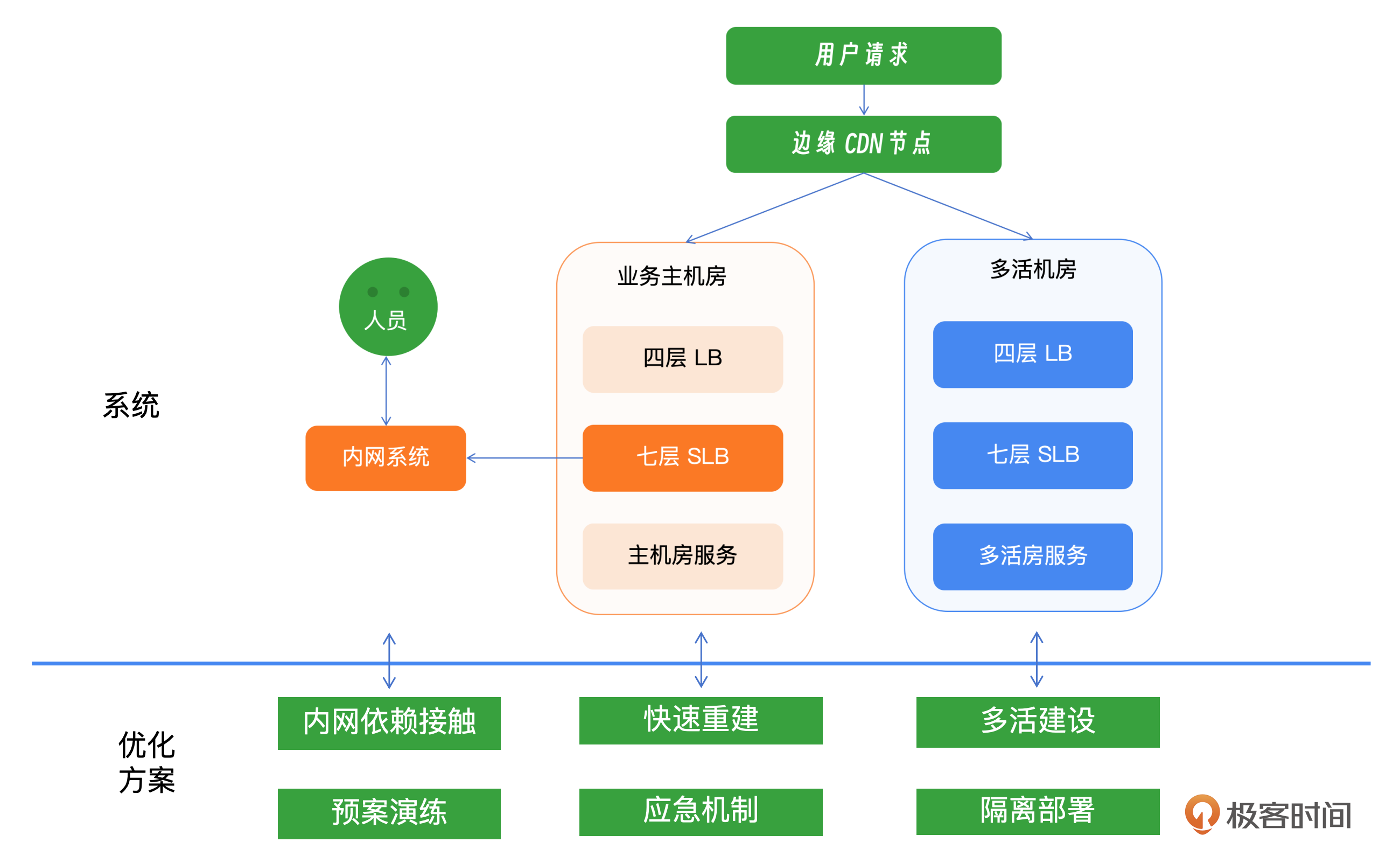
核心点一:双活与切流
在本次故障中,实现业务快速恢复的关键策略是双活部署和流量切换。如果所有业务能够在故障发生后立即执行流量切换,理论上所有业务可以在23:23分恢复。所以当面对极端故障的时候双活和切流是最为重要的手段,一定要严格地进行双活建设和服务逃生。通过有效的切换措施,故障时间从178分钟显著缩短至31分钟。
但是还有很多服务没有恢复,这其中也暴露了一些问题,这些问题也是在多活建设中很常见的。
- 机房和业务混乱:机房与业务的多活定位关系不明确,CDN多机房流量调度不支持固定路由和分片,业务多活架构在写入功能上存在缺陷,导致当时未能完全恢复。
- 元信息管理缺失:缺乏一个统一的平台来管理哪些业务实现了多活,以及它们是采用同城双活还是异地单元化的策略。此外,也不清楚哪些URL规则支持多活,以及当前的多活流量调度策略是什么,这些信息目前只能通过文档临时维护。
- 切流缓慢:多活切操作高度依赖CDN团队执行,其他人员没有操作权限,导致效率低下。缺少切量管理平台,使整个切量过程缺乏透明度。接入层和存储层的切量操作分离,无法实现有效编排。由于缺乏业务多活元信息,切量的准确性和容灾效果受到影响。
关于如何做双活和逃生,我们会在下一讲中介绍。
核心点二:故障演练
B站在做重建的时候还是非常慢的,主要原因在于多个团队操作,日常缺乏演练,必然会导致各种各样的问题。SLB的预案中只演练过SLB机器初始化、配置初始化,但和四层LB公网IP配置、CDN之间的协作并没有做过全链路演练,元信息在平台之间也没有联动,比如四层LB的Real Server信息提供、公网运营商线路、CDN回源IP的更新等。所以一次完整的新建源站耗时非常久。
每个团队分工不同,这里我们先不考虑平台化的事情,我们先考虑人是否可以通过配合来加速。多个团队相互配合的快速重建的演练,重要性不言而喻。只有通过反复练习,才能有效提升速度。
核心点三:隔离和解耦
B站在复盘的时候发现,用户在登录内网鉴权系统时,鉴权系统会跳转到多个域名下,其中一个域名是由故障的SLB代理的,受SLB故障影响,当时此域名无法处理请求,导致用户登录失败。
循环依赖在系统架构中是一个普遍存在的问题,一旦出现故障,可能会导致整个系统无法正常运作。因此,在制定日常的预案演练时,必须特别关注循环依赖的问题,并采取措施进行解耦。我们来了解几个常见的解耦策略。
- 内网与外网接入的解耦:在故障发生前,单一的SLB可能会成为故障域隔离的瓶颈。为了避免这种情况,建议将SLB按业务部门进行拆分,为每个核心业务部门配置独立的SLB集群和公网IP地址,以实现更有效的故障隔离和管理。
- 预案与基础服务的解耦:预案平台和基础服务之间不应存在循环依赖。例如,数据库切换操作如果依赖于预案平台,而预案平台又依赖于数据库来存储预案信息,这将形成一个恶性循环。我们应该设计一种机制,使预案平台和数据库之间能够独立运作,而不是相互依赖。
- 建立绿色通道:在系统设计中应包含绿色通道机制,以便在紧急情况下快速恢复关键服务,如用户登录等。
- 机房外部的带外系统:除了机房内部的处理系统外,还应该建立一个带外系统,即独立于主系统之外的备用管理系统,用于在主系统不可用时进行故障处理和恢复操作。
核心点四:应对故障恢复之后的流量
在故障期间,多活SLB面临了极大的压力,主要由于CDN流量的回源重试以及用户端的频繁重试行为,这导致流量剧烈增加,超过了正常水平的四倍。同时,连接数激增到1000万的量级,最终引起了SLB的过载。
尽管如此,随着流量的自然回落和SLB的及时重启,服务开始逐步恢复到正常状态。在常规的晚高峰时段,这个SLB集群的CPU使用率一般维持在30%左右,并且拥有接近两倍的额外处理能力。这表明,如果多活SLB具备足够的容量,理论上它能够应对流量的突增,从而迅速恢复多活业务。这一情况也凸显了在面临极端故障时,流量管理的重要性以及确保容量充足的必要性。
为了提高系统在类似情况下的韧性,我们可以进行更细致的容量规划,确保在极端情况下,SLB能够处理预期之外的流量激增。然后实施有效的流量控制机制,限流同时保持足够的冗余等等,减轻对SLB的压力。此外还可以改进系统设计,优化CDN和用户端的重试策略,减少不必要的流量和连接数。最后也要加强实时监控系统,以便在流量异常增加时,能够及时发出预警,并采取相应的措施。
核心点五:基础服务要做严格的测试
对于许多公司的基础服务而言,专业的测试人员并不常见。基础测试往往难度较大,而且执行频率较低,这导致招聘专业测试人员的性价比不高。因此,我建议引入一个专门负责基础组件测试的团队,对SLB(Server Load Balancer)这样的服务进行全面的异常测试。
如果无法引入这样的专业测试团队,开发和运维人员就需要学习并掌握必要的测试流程。此外,还应该确保单元测试的覆盖率达到标准。
核心点六:应急响应
B站目前还没有建立一个专门的技术支持团队来应对紧急事故。在紧急事故发生时,SRE工程师不仅要负责故障处理,还要承担故障响应、通报和协同工作。这种做法在处理普通事故时或许可行,但在面对重大事故时,信息同步的速度往往跟不上需求。
这里阐述一下我的见解,拥有一个专门的团队无疑是理想的,但如果缺乏这样的支持,那么培养SRE人员的组织协调能力至关重要。同时,构建一个既完善又简洁的运作机制也非常重要。这包括迅速通报情况,及时召集相关人员;确保关键人员能够迅速了解情况,比如团队领导、对外运营、公关或政府关系人员等等;快速同步目前事件的影响范围和具体情况。
小结
B站的故障其实非常典型,其中有非常多的问题值得我们去思考和探索。这里面最关键的双活建设、故障演练、隔离和解耦、严格的测试和发布流程,以及应急响应,都是值得我们去思考和学习的。我这里整理出了一张示意图,你可以结合示意图来复习。
思考题
你有什么办法在不影响线上服务的同时进行大规模的故障演练,同时能讲清楚收益获得老板的支持?欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- 奔跑的阿飞 👍(2) 💬(2)
大规模的故障演练,肯定得来自老板的支持,否则给自己挖坑。 说服老板主要有以下方面 1.故障演练可以发现生产环境的架构缺陷,可以有针对性的制定应对措施和应急手册。 2.后续万一真发生故障,可以参考应急响应手册,进行快速排查定位,将故障中断时间缩短。 关于不影响线上业务做演练 1.选择业务的低峰时间及有冗余的服务进行演练。 2.演练前,制定演练计划及措施,以防发生异常情况进行处置。 3.演练后,进行总结覆盖,形成改善计划。
2024-08-14