12 变更场景(二):一次简单升级竟然损失几千万
你好,我是白园。
上一节课我们分析了基础设施的变更导致的重大故障的案例,今天我们进入第二个案例分析——基础平台的变更导致的重大故障,案例来自某网约车公司。
案例回顾
2023年11月27日晚间,某网约车公司的移动应用程序遭遇了一场严重的系统故障,导致了一系列的服务中断问题。这些问题主要包括:司机无法定位到乘客、乘客等待打车的时间异常延长、用户取消已下单的行程以及地图服务长时间显示网络连接异常。这次服务故障持续了整整12个小时,成为了某网约车公司近年来所遭遇的最长时间的瘫痪事件。
故障原因
根据该网约车公司官网发布的公告,服务在28日恢复正常后,公司立即启动了内部的复盘调查程序。调查的初步结果显示,事故的根本原因是底层系统软件出现了故障,并非如网络传言所说的“遭受外部攻击”。
同时,网络上有关于Kubernetes故障的讨论。据分析,这次事故很可能是由于Kubernetes在升级过程中出现了问题,导致系统降级。
经过对网络上的传言、某网约车公司官方声明及相关技术资料的综合分析,这里我们可以得出初步结论:这家网约车公司在Kubernetes系统升级过程中,可能采取了原地升级的方式。然而,不幸的是,在升级过程中使用了与现有系统不兼容的版本,这一技术失误最终导致了服务的大规模中断。
Kubernetes架构简述
首先我简单说一下Kubernetes的架构,这样方便你后续理解。Kubernetes分为master节点和node节点。master节点就是中心控制节点,node节点就是单机控制节点。
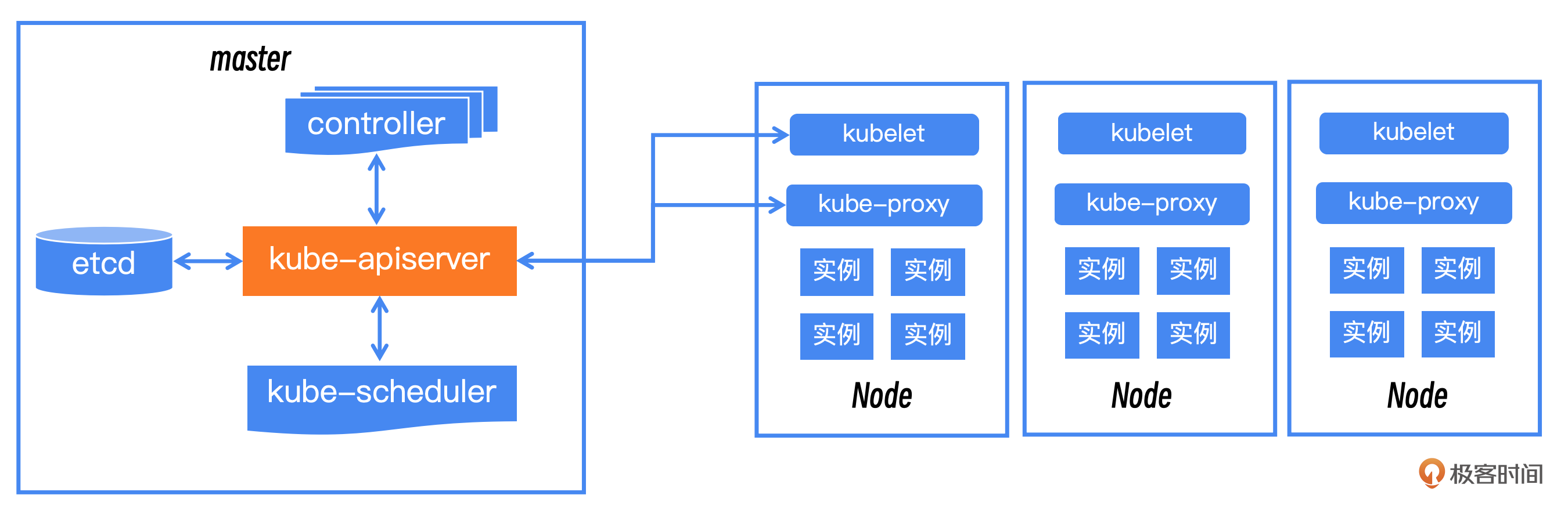
master节点包括了四个部分:etcd 负责元信息的记录和保存 ;kube-apiserver 负责对外提供 Kubernetes API 的接口和核心交互点,本次出问题的就是这个模块;kube-scheduler是负责资源调度;controller负责日常运维的交互。
node节点上,kube-proxy负责实现集群内部的网络代理和负载均衡功能;kubelet负责维护和管理单个节点上的容器。
升级方案
替换升级方案:两个 Kubernetes 集群,1.12 和 1.20,直接搭建一套新的 1.20 master 和周边组件。新集群中创建和老集群等量的业务负载集群,通过上游的流量管控应用决定流量分布,一开始流量都在老集群上,然后一步步切流到新的集群。有问题的时候可以快速回切流量。
原地升级方案:只有一个 Kubernetes 集群,把 master 和周边组件直接从 1.12 升级到 1.20,然后一步步把集群中的 node,从老版本升级到新版本。不做任何业务负载相关的操作,随着 node 升级,流量就慢慢从老版本切到新版本了。有问题的时候,需要部分回滚 node,当出现全局性风险的时候,需要全量回滚 master 和周边组件。
最终他们选择的是原地升级的方案。正常的流程是升级master,然后再升级node,而这次应该是把已经升级的集群做了误操作。把kube-apiserver从新版本降级到老版本,而node继续运行在新版本,这个时候master版本低,而node版本高,就会出现不兼容的情况,进而引发一系列的连锁反应。
从网络上的讨论中我们可以知道,当时应该是出现了三个现象。首先,大量服务重新启动;其次,etcd服务发生了故障并触发了雪崩效应;最后,自动重启失败,最终依靠人工干预才得以恢复。
我们无法看到官方给出的具体解释,所以就不深入探讨背后的具体的技术原因,下面我们重点讨论一下如何避免这种类似的问题发生。
如何避免类似的故障?
这次的问题现在看来也是一次非常简单的故障,就是有人把版本号选错了,但越是简单的故障往往越是需要重视。结合基础变更篇中的内容,我整理了整体的变更思路和规范,你可以在变更前、变更中、变更后三个阶段作出反应。

变更前
实施双人审核机制:为防止版本兼容性问题,关键系统升级任务必须经过两名专业审核员的双重审批和核实,确保升级流程的精确性和安全性。其实双人审核是我接触过的既简单又实用的方式,能避免大量人工失误导致的故障。
平台管控策略:在升级过程中,我们可以设计一个变更的原则,就是绝对不允许出现master版本低于node版本的操作。这一点可以放到变更自动检查里面。如果发现就自动停止操作。
回滚方案:必须事先制定一个清晰且可执行的回滚方案。在实施任何变更之前,都应该确保存在足够的资源,便于迅速恢复到变更前的状态,从而有效应对可能出现的问题。根据刚刚的故障分析,很明显现有的回滚方案是不够健全的。比如该故障中,原地升级回滚的方案会相对复杂,而且周期很长。这个就需要在事前进行多次演练,确保尽可能安全、快速。
变更中
变更中最需要关注的点就是分级、仔细观察、快速隔离和处置,尽可能在前期去屏蔽故障。
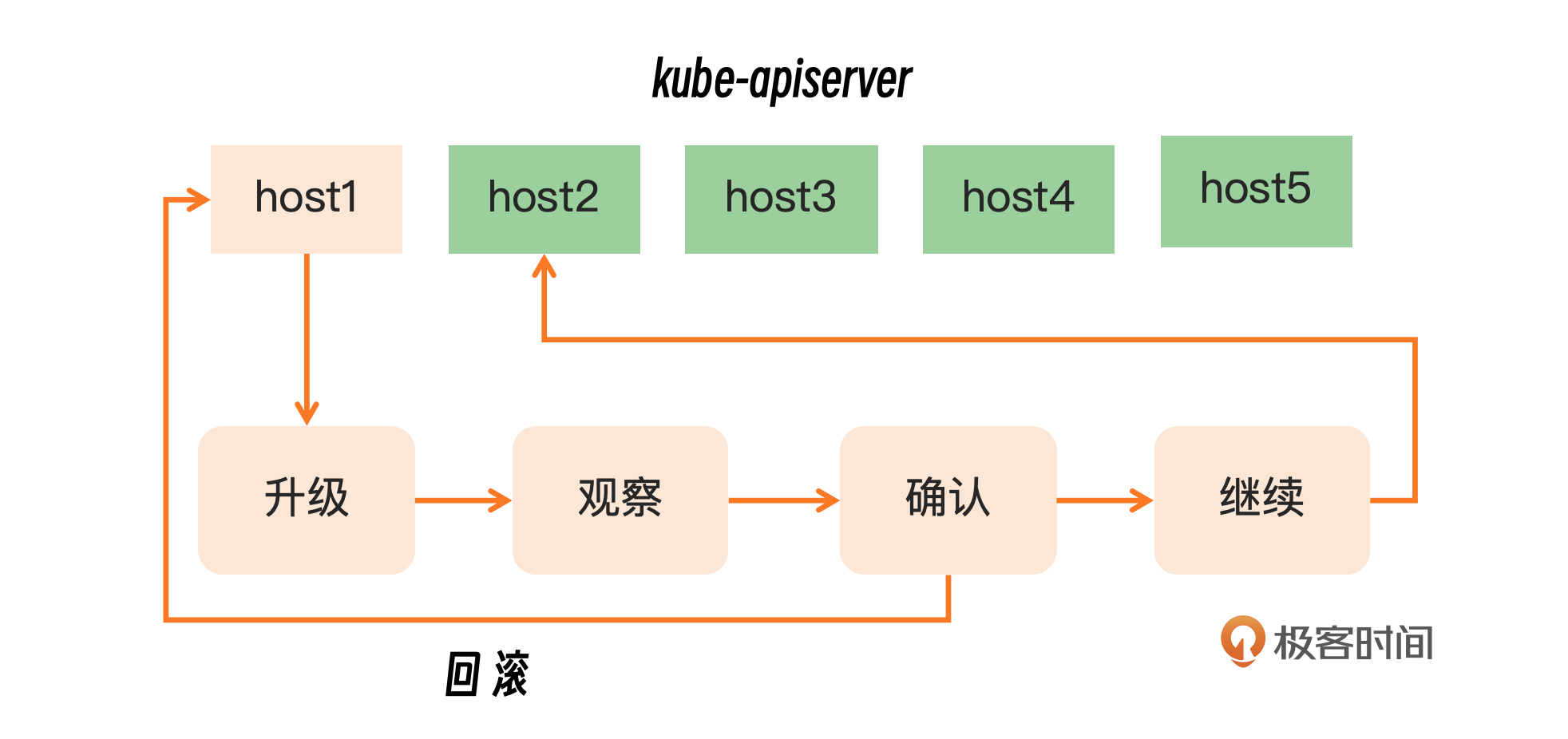
首先实施分级发布流程,当需要对API服务器进行升级的时候,如果采用滚动升级的策略。这意味着升级过程是逐步进行的,所以这里要求必须一次只升级一个master节点,并且保持足够长的时间。这种逐步升级的方法有助于最小化升级对服务可用性的影响,并需要实时监控升级的效果。
如果在升级过程中发现任何问题,就必须迅速采取措施,对出现问题的master节点进行隔离,并执行必要的回滚操作。通过这种谨慎的升级流程,可以最大限度地减少升级带来的风险,同时保持服务的高可用性。
然后需要仔细观察我们关注的指标,比如升级一台master节点,升级完成后进行观察的指标除了master本身的指标,还需要包括整个集群的node和业务实例。更需要特别关注业务指标,观察是否存在大量重启的情况,以及业务指标是否产生波动。一旦发现异常,就应该马上停止升级,并采取屏蔽措施。如果没有问题可以继续,我们可以看到这次Kubernetes的升级过程中可能存在观察时间不够或者观察指标不全的问题。
如果能在上线第一台master节点时候,仔细观察,其实是可以发现问题的,这个时候你一定能够发现有大量服务做了重启或者挂掉,就应该及时停下来。
如何控制影响?
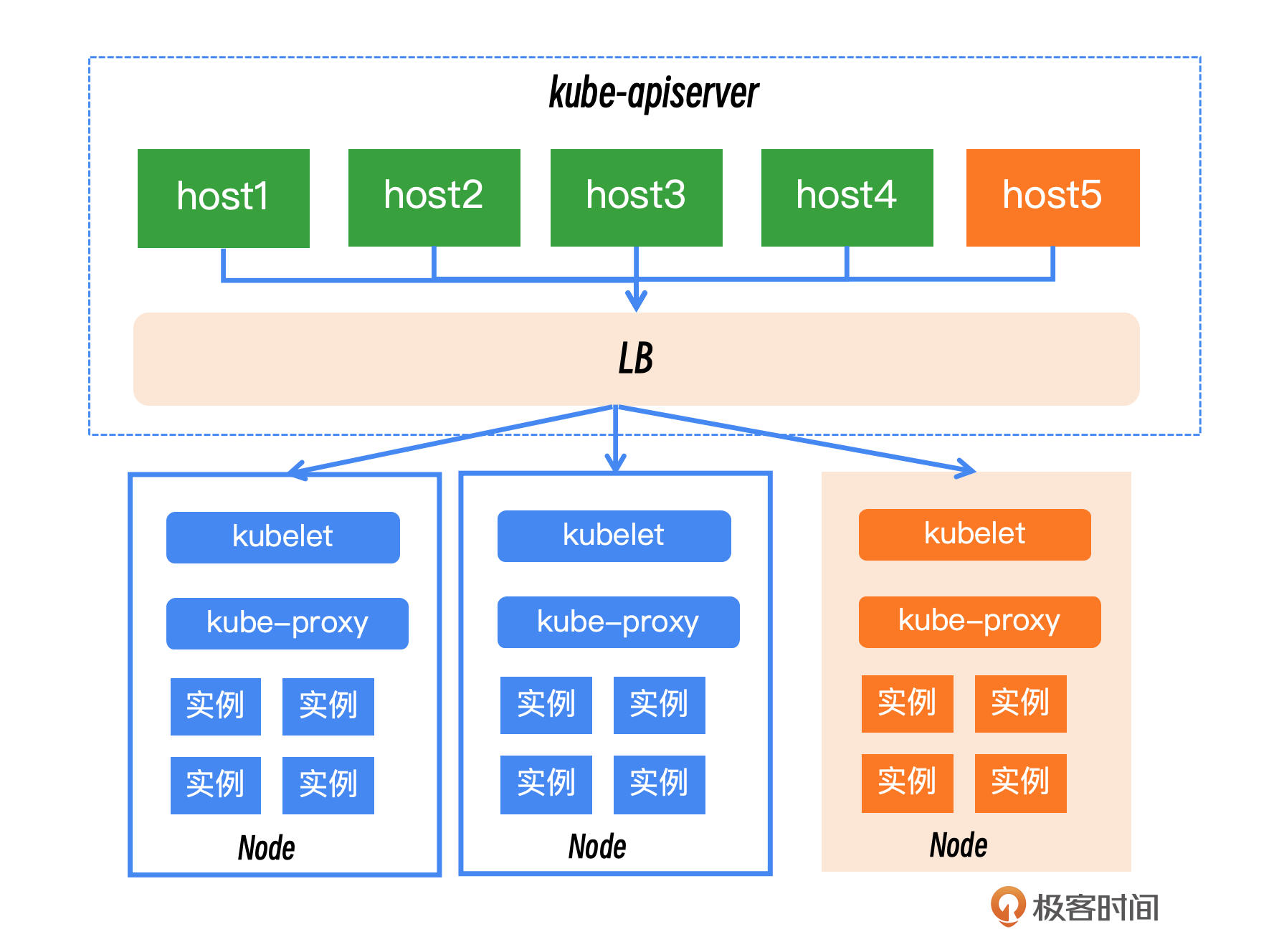
这里我们从技术角度和公关角度来看。 首先看技术角度,核心的原则就是,故障域的控制和细分,把master控制的一个超级大集群可以划分成多个小集群,来避免一个master故障之后对整个业务的核心业务都有影响。
在升级过程中,应该对master的不同节点执行严格的隔离措施。例如,对正在升级的节点进行操作范围的限制。比如将负载均衡算法设置为hash模式,可以简化隔离过程。你可以根据你的基础平台能力,制定相应的隔离策略,以确保单台机器的升级不会波及整个集群。
此外我们还可以跟业务联动,可以让核心业务提前把流量切走,升级完成后再切回来。当然这个会受限于容量情况需要业务的配合的支持,需要根据自己实际情况来定。
应急响应机制:面对重大故障,必须迅速启动一套全面的对外应急响应机制,其核心内容包括:
- 用户安抚:迅速采取措施安抚受影响的用户,通过清晰、透明地沟通,向用户说明故障情况、正在采取的措施以及预计的恢复时间。
- 服务降级:在必要时,果断执行服务降级策略,优先保证关键功能和服务的可用性,以最小化故障对用户体验的影响。
- 专业团队介入:由专业的公关团队负责对外沟通,包括社交媒体、新闻发布等,以维护公司形象和用户信任。同时,还需要协调公关(Public Relations, PR)和政府关系(Government Relations, GR)两个层面的工作,确保所有外部沟通都是一致的,并且符合法律法规和政策要求。
- 沟通策略:制定明确的沟通策略,确保所有信息发布都经过严格审核,避免造成误解或恐慌。
- 后续跟进:在故障处理结束后,继续与用户保持沟通,提供恢复情况的更新,并在适当时候发布详细的故障报告和改进措施。
如何快速恢复?
在故障恢复阶段,单靠平台去做恢复是远远不够的,也需要业务层做容灾和逃生。
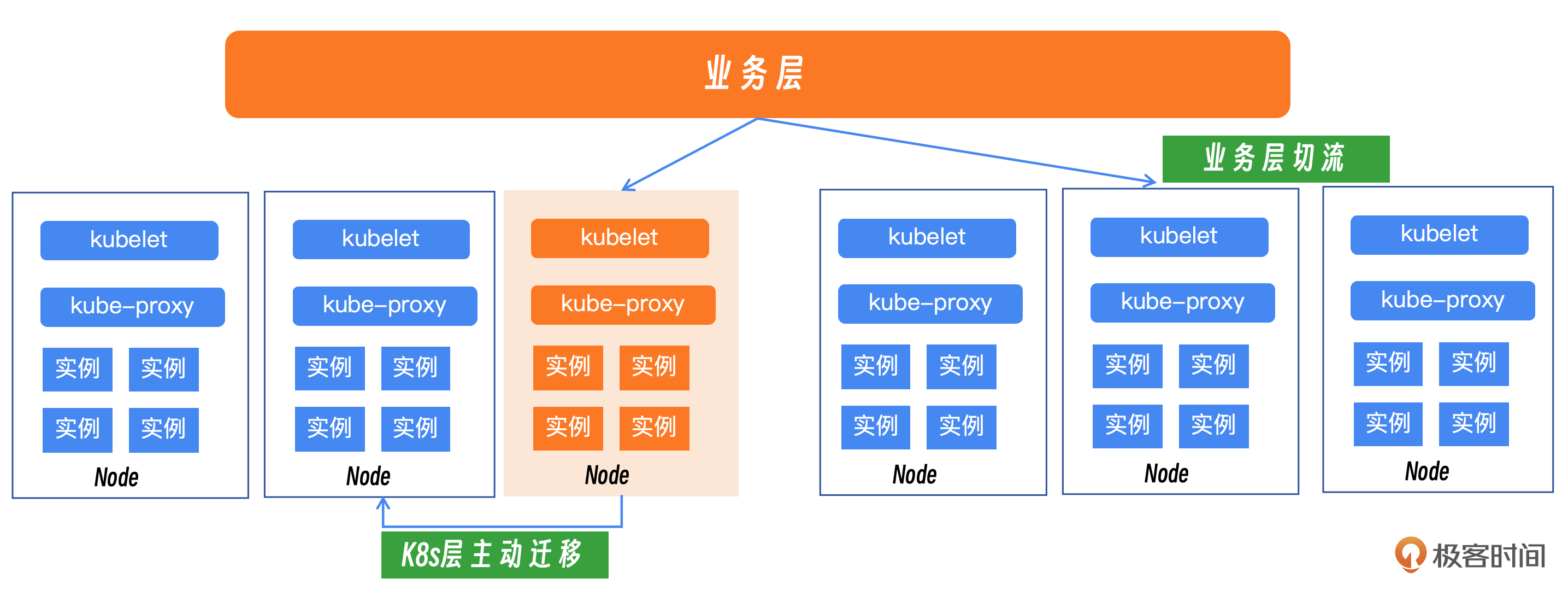
在业务层面,可以实施流量切换策略,将当前受影响的流量从一个受影响的地域转移到另一个正常的地域,以减少故障对用户的影响。启用逃生机制,通过智能路由或负载均衡策略,自动将请求导向稳定可靠的服务实例,从而提高系统的可用性和弹性。
在Kubernetes层面,可以主动执行服务迁移操作,将受影响的服务从故障区域迁移到健康区域,以恢复服务的正常运行。对于受到影响的Pod或服务实例,快速进行迁移,确保它们在健康的节点上重新启动并提供服务。
服务快速重启的能力建设,当平台无法自动重启的时候有工具和预案进行一键启动,这样也可以加速恢复的速度。
小结
基础服务的变更影响巨大,因此我们需要做好充分的准备,主要包括变更前的充分检测、严格执行分级发布,还有可靠的升级方案、集群拆分以及快速止损方案,具体的操作我整理在表格里了,你可以参考。

思考题
针对Kubernetes的升级,除了刚刚我们说的措施,你还有什么手段保障不出现问题,或者说当出现问题的时候如何快速做出相关的止损动作。欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- E 👍(0) 💬(1)
这里我们从技术角度和公关角度来看。 ———这里的“公关角度”没讲啊
2024-08-09