11 变更场景(一):一条让Facebook蒸发百亿的指令
想象一下,全球数十亿人突然失去了与亲朋好友的即时联系,企业沟通中断,社交媒体一片寂静。这不是科幻电影的情节,而是2021年10月4日,Facebook及其旗下服务真实经历的一幕。
你好,我是白园。今天,我们将深入探讨这场技术界的“大地震”,它不仅让Facebook市值瞬间蒸发百亿美元,更引发了全球范围内的数字恐慌,而这一切都源于一条错误的指令。
也是从这节课开始我们进入变更部分,从基础设施、基础平台到数据和配置变更,我们将通过三个案例,剖析背后的教训,学习如何在数字世界中航行,避免触礁。这节课我们就通过Facebook的这个故障案例来学习一下基础设施的故障:网络和DNS。
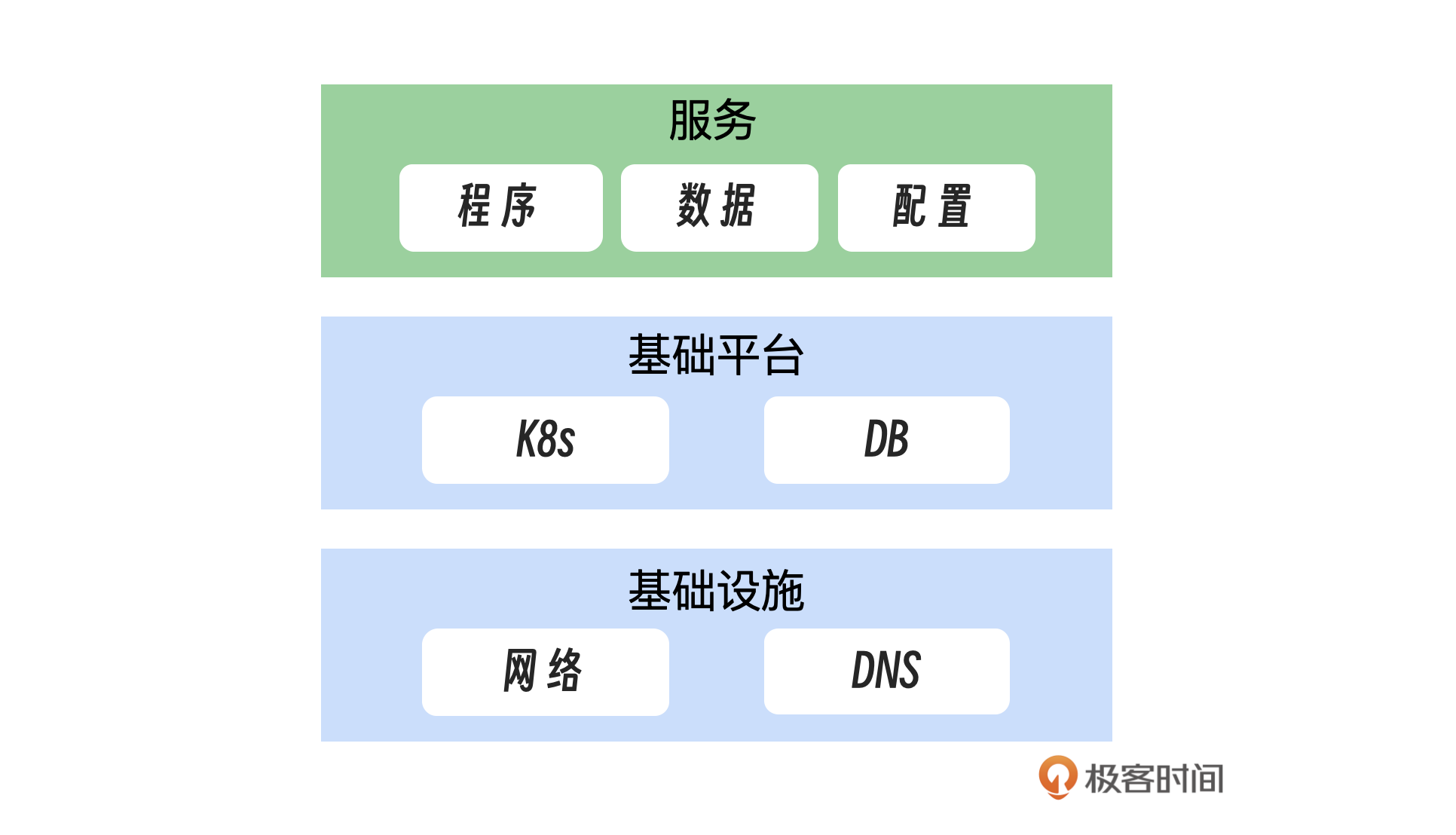
案例回顾
2021年10月4日北京时间23:39,Facebook服务全面中断,此次服务中断持续了约7个小时,是近年来罕见的长时间宕机事件。不仅Facebook本身,它旗下所有相关应用和服务全面崩溃,包括但不限于Instagram、WhatsApp、Messenger等主要社交平台,以及虚拟现实平台Oculus、部分企业服务、内部工作系统。Facebook的股价在当天下跌近5%,创下了全年最大的单日跌幅,市值瞬间蒸发百亿美元。
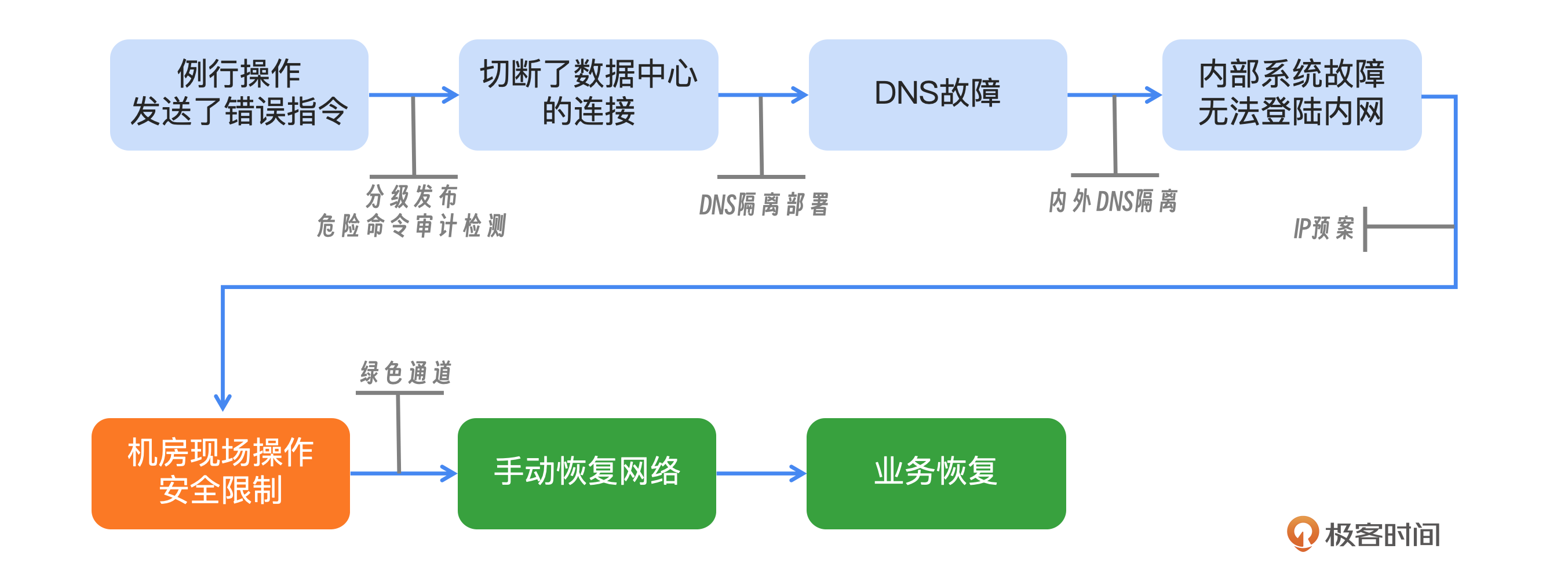
你可以参考示意图来理解Facebook内网故障时的处理方式。在发生故障的时候,Facebook主动撤销了其域名在权威DNS服务器上的解析记录。这导致用户无法通过DNS查询到正确的IP地址,从而无法访问Facebook提供的服务。
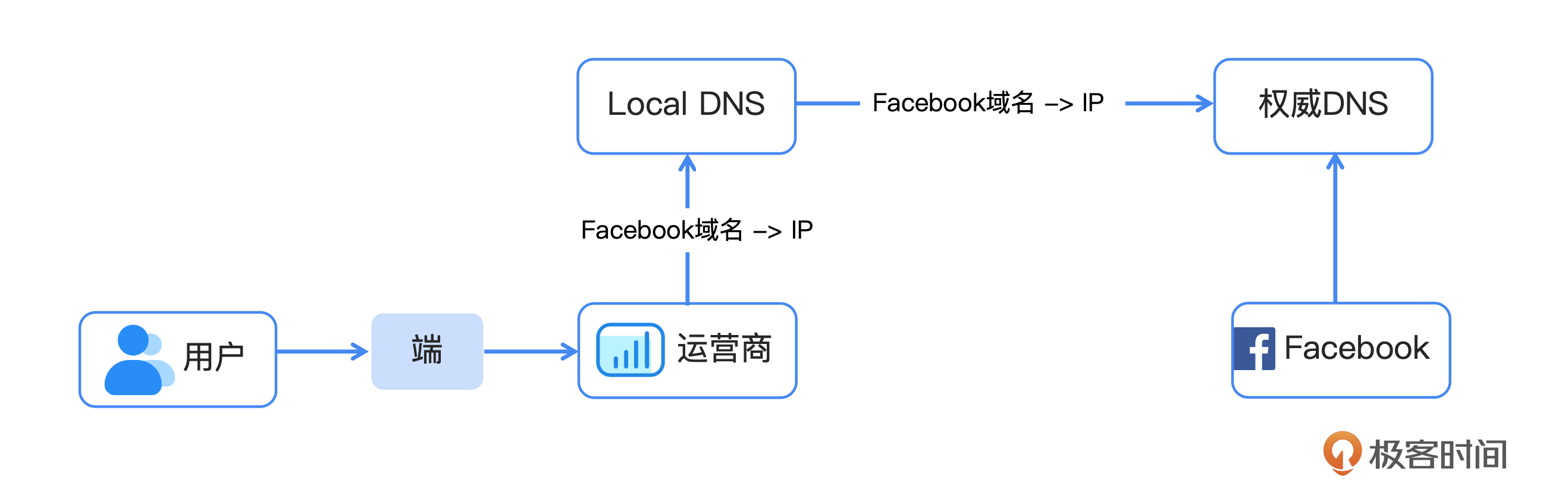
原因分析
在日常维护过程中,工程师在评估全球骨干网容量时不慎发出了错误指令。这条错误命令意外地切断了Facebook全球数据中心之间的所有网络连接。
由于数据中心间的网络连通性至关重要,一旦连通性出现问题,DNS服务会撤销BGP路由,导致包括公网和内部网络在内的所有DNS服务撤销路由。DNS服务的异常进一步影响了内部多个系统,包括网络排查工具和网络/服务器登录系统,使得远程操作变得不可能。
面对远程操作的失败,Facebook团队决定前往数据中心进行现场业务恢复。到达数据中心后,由于安全级别的限制,即便在现场进行了直接管理,服务器和网络设备的配置变更依然困难,后端认证系统的故障进一步增加了现场操作的难度。
经过努力,数据中心间的网络连通性最终得以恢复。随着数据中心连通性的恢复,DNS服务逐步恢复正常,相关服务也随之陆续恢复。Facebook的后端系统在凌晨5点左右的业务高峰期间表现出色,没有出现异常。最终,在10月5日大约05:00,所有业务恢复正常。
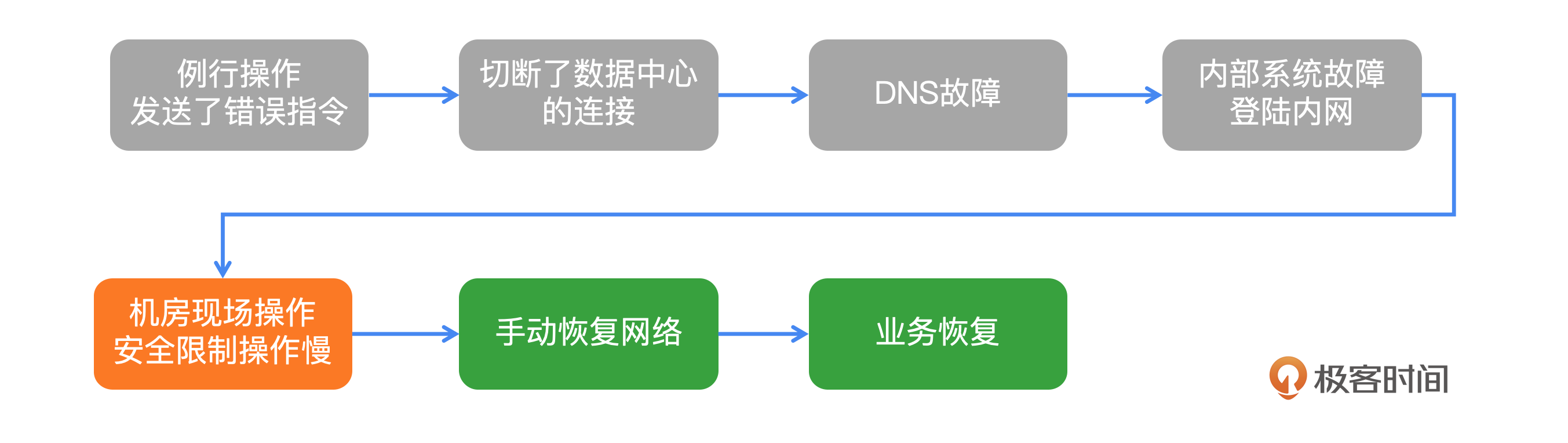
案例分析
Facebook在这次的故障发生和处置上其实犯了很多错误。首先就是故障发生,这是一个典型的人为故障,并不是客观不可避免的,在操作的流程和规范上犯了严重的错误。其次就是在影响控制上,网络故障触发了DNS服务的连锁反应,而Facebook在影响隔离和保护措施上的不足,引发了更大的问题。第三,故障处理过程中的混乱,暴露了应急响应机制上的不足。不仅需要人工去现场重启,而且权限还被隔离了。
接下来,我们将从这三个关键层面进行深入分析:如何避免人为错误,如何有效控制故障影响,以及如何加速故障恢复。
如何避免人为因素导致的重大故障?
首先需要考虑的是错误命令的早期识别问题。通过改进检查机制及增强监控系统,可以提前发现并纠正错误的命令。这不仅要求我们采用更先进的技术手段,还要求工作人员具备高度的警觉性和专业能力。通过定期的培训和实践,可以确保团队在面对潜在的错误命令时能够迅速且有效地作出反应。
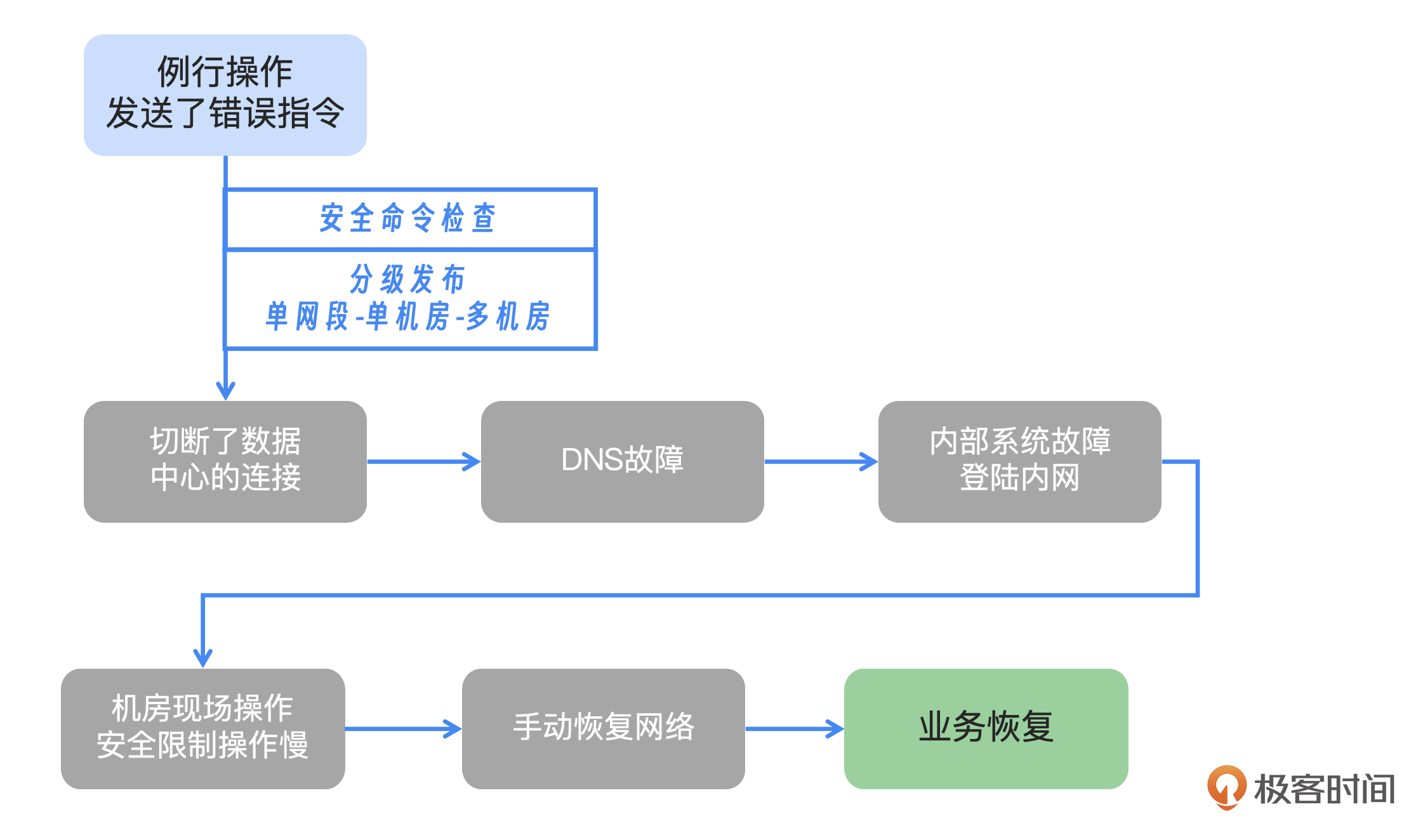
为了确保线上环境的安全,避免执行可能带来风险的命令,我们可以采取以下两种高效的预防措施:
实施严格的人工审批流程。通过建立一个详尽的审批和审查机制,可以有效地减少人为失误。在这一流程中,所有即将部署到线上环境的命令都需要经过专业人员的仔细检查与批准。这样的双重检查不仅能够确保命令的准确性,还能防止潜在的危险命令对系统造成损害。
利用平台的自动监测功能。由于查询命令和执行命令在性质上存在差异,通过平台的自动监测系统可以提前识别并阻止任何可能带来风险的操作命令。例如,Facebook等社交平台可能由于缺乏相应的检测机制,导致有害命令得以直接执行并影响线上环境。通过引入自动化工具和算法,可以有效地筛选和过滤掉这些不安全的命令,从而保障线上环境的安全与稳定。
严格遵守分级发布
- 从一个小网络段开始,以便控制影响范围并快速解决问题,同时密切监控系统性能。
- 逐步扩展到单个房间。持续观察和监控。
- 发布到单个机房进行持续监控,确保问题及时发现。
- 最后才是对所有机房进行发布。发布完成后,继续监控以确保系统稳定运行。
如何控制故障影响?
从这个案例中我们可以看到内网的故障影响到了监控,监控失败误以为是DNS故障,进而DNS主动撤销了自己的权威信息。这里我们需要解决三个问题,首先要保证网络的故障不影响DNS;监控误报不引发错误决策;内网故障不要影响外网。

数据中心链路的独立性:为了确保数据中心链路的稳定性,我们需要设计一个更加健壮的网络架构,使单个链路的问题不会影响到DNS服务。这可以通过冗余设计、负载均衡和智能路由等技术实现,确保关键服务的高可用性。
多路径探测机制:DNS探活通常依赖于跨机房的网络连接。为了减少单点故障的风险,可以设计一个多路径探测机制,通过多个网络路径进行探活,这样即使某一条链路出现问题,其他链路仍然可以保持探活功能的正常运行。
DNS撤销保护机制:为了防止在链路中断期间误撤销正常的DNS记录,可以引入一个安全阈值。当撤销操作超过这个阈值时,系统会自动停止撤销操作。这样可以避免在网络不稳定时误判服务器状态,导致DNS中断。
内外网DNS独立部署:将内网和外网的DNS服务进行独立部署,可以有效地隔离两者之间的影响。内网DNS服务器专门服务于内部网络的域名解析,而外网DNS服务器则处理来自互联网的请求。这样,即使外网DNS发生故障,内网系统仍然可以正常运行。
IP地址兜底机制:在DNS服务不可用的情况下,可以通过IP地址兜底机制来确保内网系统的可访问性。这意味着在DNS解析失败时,系统可以回退到直接使用IP地址进行通信。为此,可以在内网系统中配置备用的IP地址,或者在用户端提供一种机制HTTPDNS,当在DNS解析出现问题时,用户可以直接输入备用的IP地址来访问服务。此外,还可以通过配置静态路由或修改本地hosts文件等方式,将域名映射到特定的IP地址,从而实现在DNS故障时的无缝切换。
如何加速恢复?
带外管理系统(Out-of-Band Management, OOBM)是一种独立的网络管理解决方案,它与主要的生产网络相隔离,但能够提供对关键网络设备和服务器的远程管理能力。
独立的管理网络:构建一个与生产网络逻辑上或物理上独立的管理网络。这个网络专门用于管理和监控目的,即使生产网络发生故障,管理网络仍然可以正常运行,保证管理人员可以远程访问关键设备。
应急影响机制:为了提高紧急情况下的故障修复速度,我们需要建立一个快速响应机制,允许授权人员在必要时绕过常规的审批和确认流程。这种机制应当确保在不牺牲安全性的前提下,提高处理速度和效率。
预授权机制:为紧急响应团队成员提供预授权的高级权限。这些权限应当在严格的安全框架下授予,确保仅在紧急情况下使用,并且有明确的使用准则和记录。
紧急通道:建立一个紧急通道,允许授权人员在必要时快速访问系统资源和执行必要的操作。这个通道应当设计为绕过常规的审批流程,以便快速响应。
定期培训和演练:定期对紧急响应团队进行培训和模拟演练,确保他们熟悉快速响应流程和工具,提高他们在真实紧急情况下的应对能力。
值得借鉴的地方
Facebook在服务恢复后成功应对了凌晨5点的业务高峰期,这一点值得业界学习。这表明,在故障恢复过程中,除了关注服务的及时恢复外,还应特别注重系统在恢复后的稳定性和弹性。Facebook的这次经验对我们来说具有重要的借鉴意义,提醒我们在设计和维护系统时,要综合考虑即时恢复与长期稳定性,以及在面对不可预见的流量激增时的应对策略。
小结
通过Facebook的故障案例,我们可以看到,即使是一个微小的操作失误也可能引发灾难性的后果。这也告诫我们在执行任何系统变更或发布时,必须遵循严格的操作步骤和流程。并且要确保有一套详尽的变更管理程序,以降低人为错误的风险,确保所有变更都经过了充分的测试和审查。
此外,为了提高系统的可靠性和弹性,基础设施的设计应当包含足够的冗余。这意味着关键组件和系统应设计为可以承受部分故障而不影响整体服务的连续性。下面是我整理一个全局优化图,供你参考。
相关材料参考: https://engineering.fb.com/2021/10/04/networking-traffic/outage/ https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/
思考题
如果你的业务的DNS故障了,你有什么好的办法来应对。欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- xd 👍(0) 💬(1)
节点不多的话,dns 写入 hosts,,
2024-09-11 - E 👍(0) 💬(2)
dns服务撤销bgp路由?
2024-08-08