10 容量场景(三):一条让新浪工程师们通宵加班的微博
你好,我是白园。
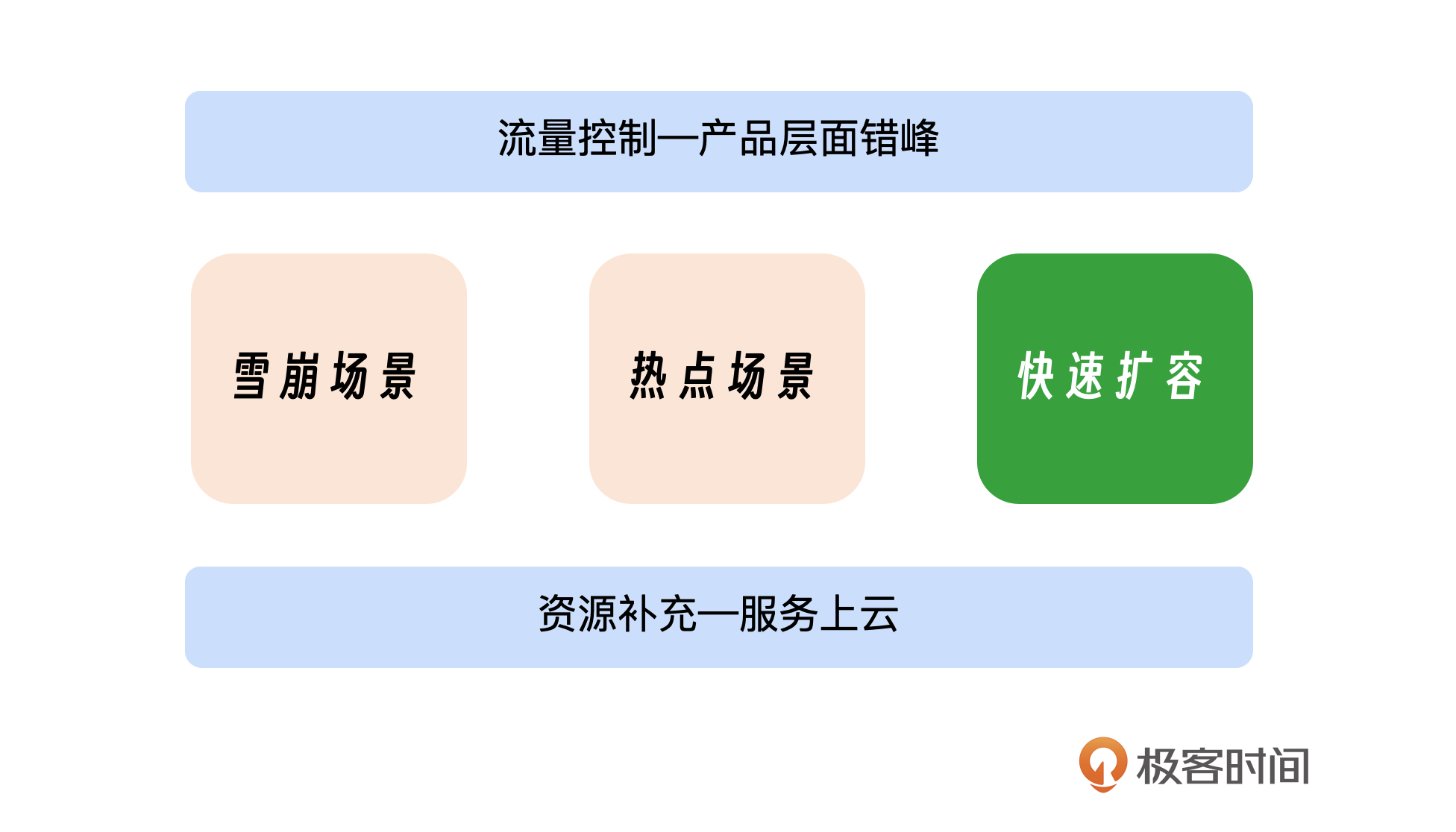
今天,我们来看容量部分的第三个案例,在之前两个案例中我跟你分享了流量控制、服务上云、雪崩、热点等场景。资源通常是有限的,因此不可能对所有服务进行扩容。我们应优先将资源扩容到那些最需要资源的关键链路。如果扩容速度不够快,未能在流量高峰到来之前完成,可能会导致系统故障或业务损失。
这节课我们就来探讨一下,在资源有限的条件下,如何做快速精准地扩容。
我们先看一个案例。时间回到2017年10月8日的这一天,也是国庆与中秋长假的尾声。在这个特别的日子里,一个事件吸引了近7000万人的目光,那就是鹿晗公开了他和关晓彤的恋情。这一消息的公布,迅速引起了公众的广泛关注,也因此导致了微博平台的短暂瘫痪。因为其访问量激增,超出了服务器的承载能力。新浪工程师们通过通宵的努力,最终才把这个问题解决。
难点分析
面对微博热点事件,最直接的应对策略是系统扩容,以适应突发的流量高峰,但是微博相关的服务扩容是非常困难的事情,扩容难点如下:
难点一:不可预测性。与抢票事件相比,微博热点事件往往伴随着许多不确定因素,因为公众人物发布新闻的时间和内容是无法控制的。
难点二:层次复杂性。系统架构中存在多个层次,包括网络入口层、四层(传输层)和七层(应用层)的网络协议处理、服务层的业务逻辑处理以及数据层的存储管理。不同系统层次的扩容难易度和维持高冗余度的成本存在显著差异。接入层维持高冗余的成本相对比较低。相比之下,服务层由于服务器规模庞大,维持高冗余度的成本比较高。
难点三:链路多样性。系统中包含多个关键链路,如热搜功能、信息流(feed)等,它们在热点事件中的流量冲击各不相同。这要求我们对每个链路进行细致的流量分析和压力测试,以预测和应对不同的流量模式。
难点四:资源限制。面对热点事件,不能无限量地保留大量资源,因为这会导致成本过高且资源利用率低下。热点事件涉及的业务链路和技术链路非常多样,单一的防护措施无法全面保障系统的稳定运行。然而,实现所有系统和业务的全面覆盖,无论是在服务器成本还是改造的人力成本上,都是非常高昂的。
综合来看,我们要做的就是在资源有限的条件下,迅速地把现有资源扩容到那些需要资源的链路上,以迅速应对热点事件。我们把问题拆分下,首先是快速确认哪个链路需要扩容,然后去解决如何把资源快速扩容这些链路上。这里涉及到接入层、服务层、存储层的扩容和冗余。
解决方案
接下来我们重点解决这四个问题。
问题一:确认哪些链路和服务需要扩容
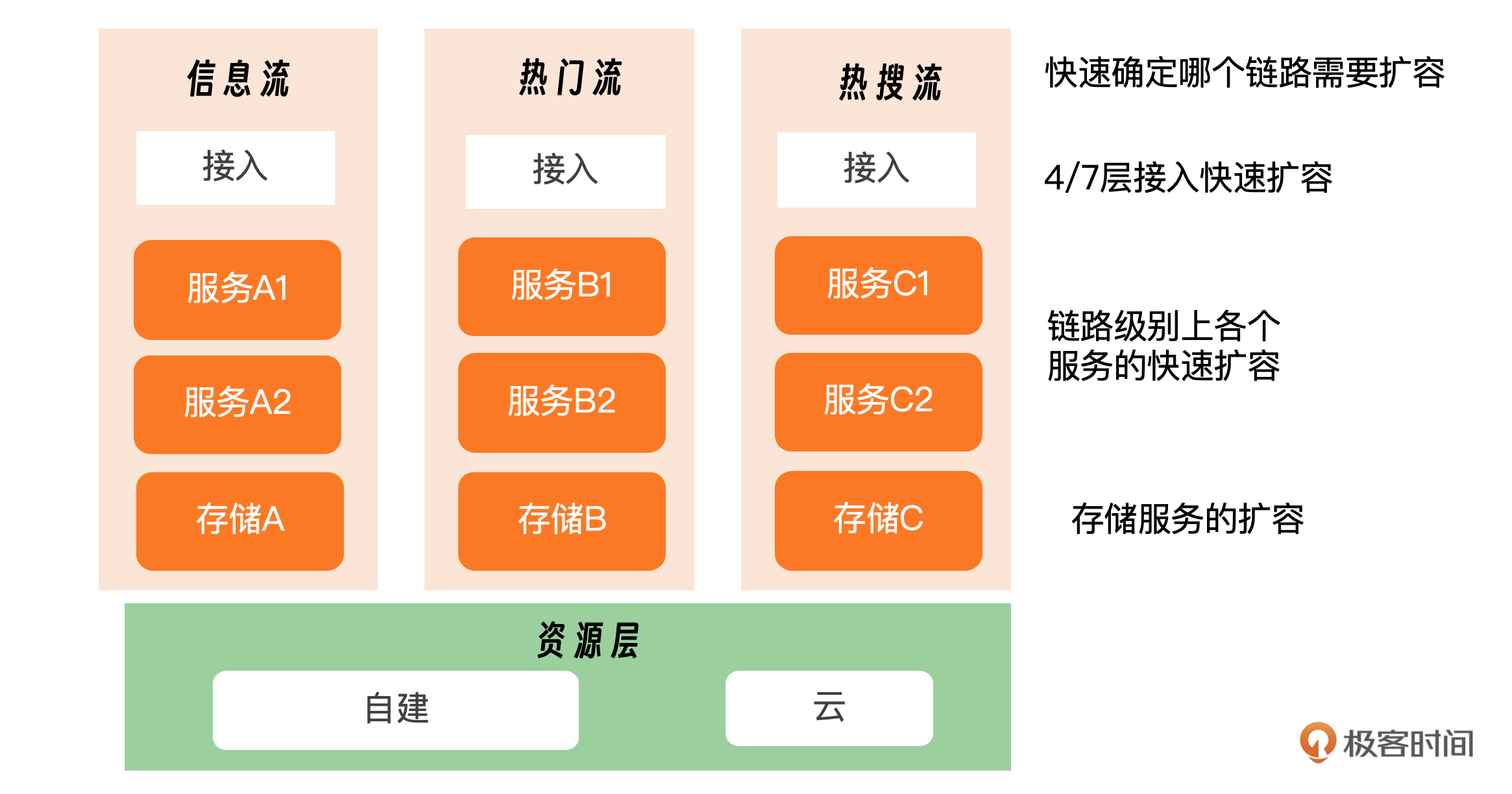
微博热点分为很多不同的类型,其中地震、游戏类的热点主要冲击 Feed 流,而明星类的热点主要冲击热搜和热门微博流。热点的访问路径不同,对应的技术链路也略有不同,但总的来说从接入层到业务层、平台层、资源层,就像现实中的洪水洪峰一样,各层都会逐步承受流量洪峰。
这里来看一下微博给出的答案——通过应急响应机制确认需要扩容的链路。面对这种不确定性,关键在于迅速感知热点并提前准备资源。当监测到服务流量达到设定的一级热度阈值时,微博的实时监测系统会自动触发一级热度警报。根据不同服务的热度等级,采取相应的响应措施。(标记2)一旦业务系统接收到警报,它们将立即按照预先规划的应急方案执行必要的操作,如扩容、功能降级等,确保平台的稳定运行,维护良好的用户体验。具体的经验如下 :
- 热度等级划分:通过实时监测服务流量,微博能够评估事件的热度,并将其分为不同的等级。
- 烈度等级划分:除了热度,微博还对事件的烈度进行评估,以便更精确地理解事件对系统的具体影响。这里的烈度指的是大家对事件反应的激烈程度。
- 热点联动动员:微博还会动员内部资源和人员,确保在热点事件发生时,能够快速有效地进行处理。
我们已经识别出了需要扩容的关键链路。下一步是分析这些链路上所涉及的应用和服务。为此,我们需要两个关键工具:动态服务架构图和追踪(trace)工具。我们需要一个能够从接口追踪到链路,再到服务列表的追踪工具和平台,以便根据流量热点链路迅速确定相关服务。此外,我们还需要明确标注服务之间的依赖关系,区分它们的重要性和依赖强度。
问题二:接入层如何快速扩容?
这里我给你两个建议,一是提前扩容保持足够的冗余;二是工具和演练。
4层、7层的网络接入层扩容通常需要一定时间,这主要是因为在进行流量接入前,需要完成一些必要的配置工作,而接入层的资源配置往往耗时较长。因此,我建议采取提前扩容的策略,并预留一定的冗余空间。这样做的好处在于操作简便,且能有效应对突发流量。
4层、7层网络扩容,必须加强演练。由于涉及网络设计、接入和业务配置等多个团队的协作,缺乏日常演练可能导致问题频发。例如,B站的故障案例揭示了由于缺乏日常演练,导致人员在应对故障时配合不够熟练,从而耗费了较长时间才得以恢复。
问题三:服务层如何快速扩容?

并非所有服务都需要进行扩容,而是针对特定的几条链路。在这种情况下,我们需要深入分析这些链路上具体包含哪些服务,以及这些服务各自需要扩容的比例。接下来,我将讨论一种较为复杂的场景:链路之间的交叉调用。例如,链路A1上的服务同时调用了A2和B2服务,而B1服务也调用了B2服务,但B2只需要对来自A1的请求进行扩容。为了更直观地理解,可以参考我提供的示意图。
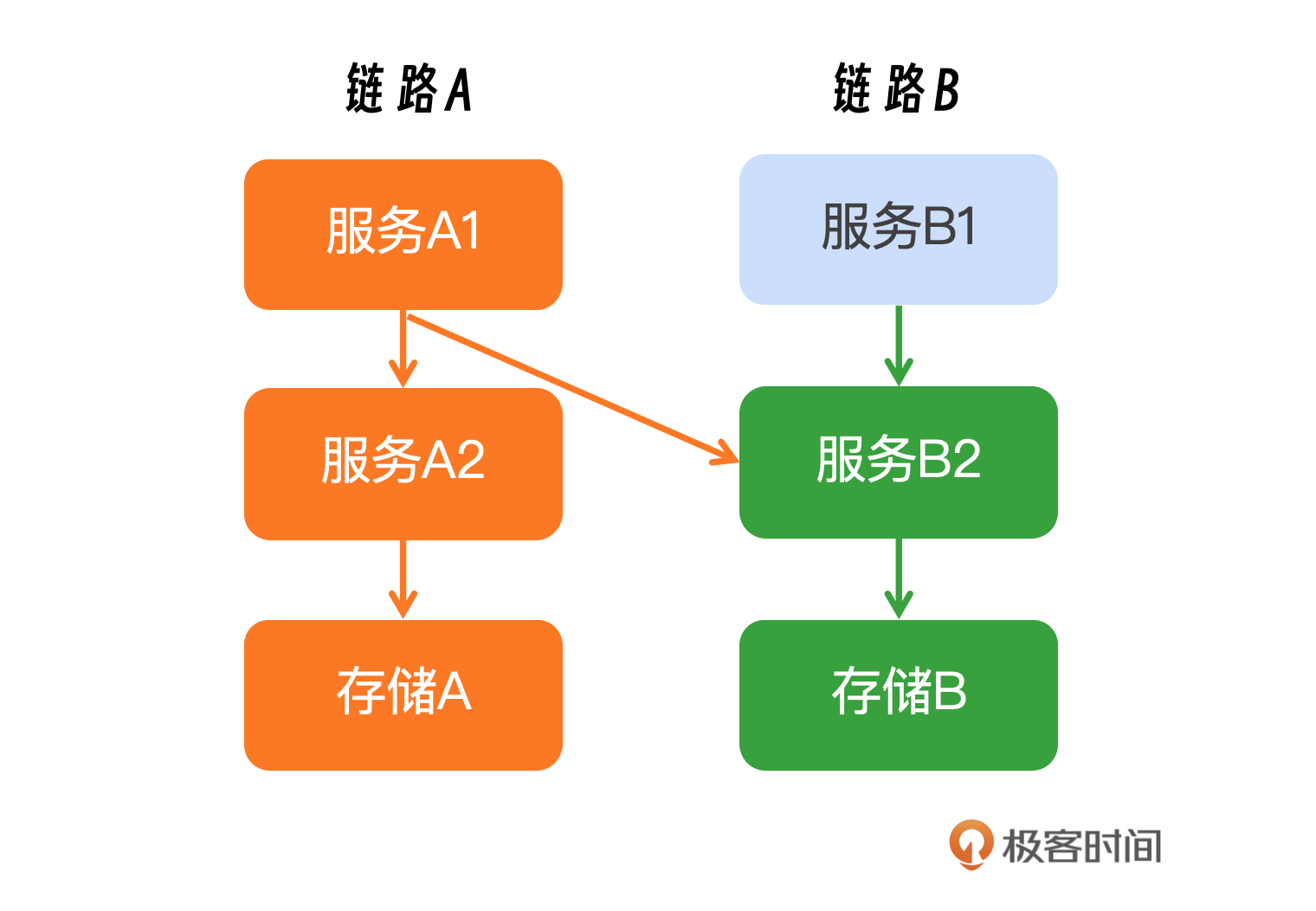
在进行服务链路管理和扩容规划时,首先要全面识别出链路上所有涉及的服务,这包括直接依赖和间接依赖的服务。其次进行细致的流量分析,以确定不同服务间的交互模式。如果服务B2同时向服务B1和A1提供服务,需要分析这些服务之间的流量分布,并据此计算出各个服务应扩容的比例。
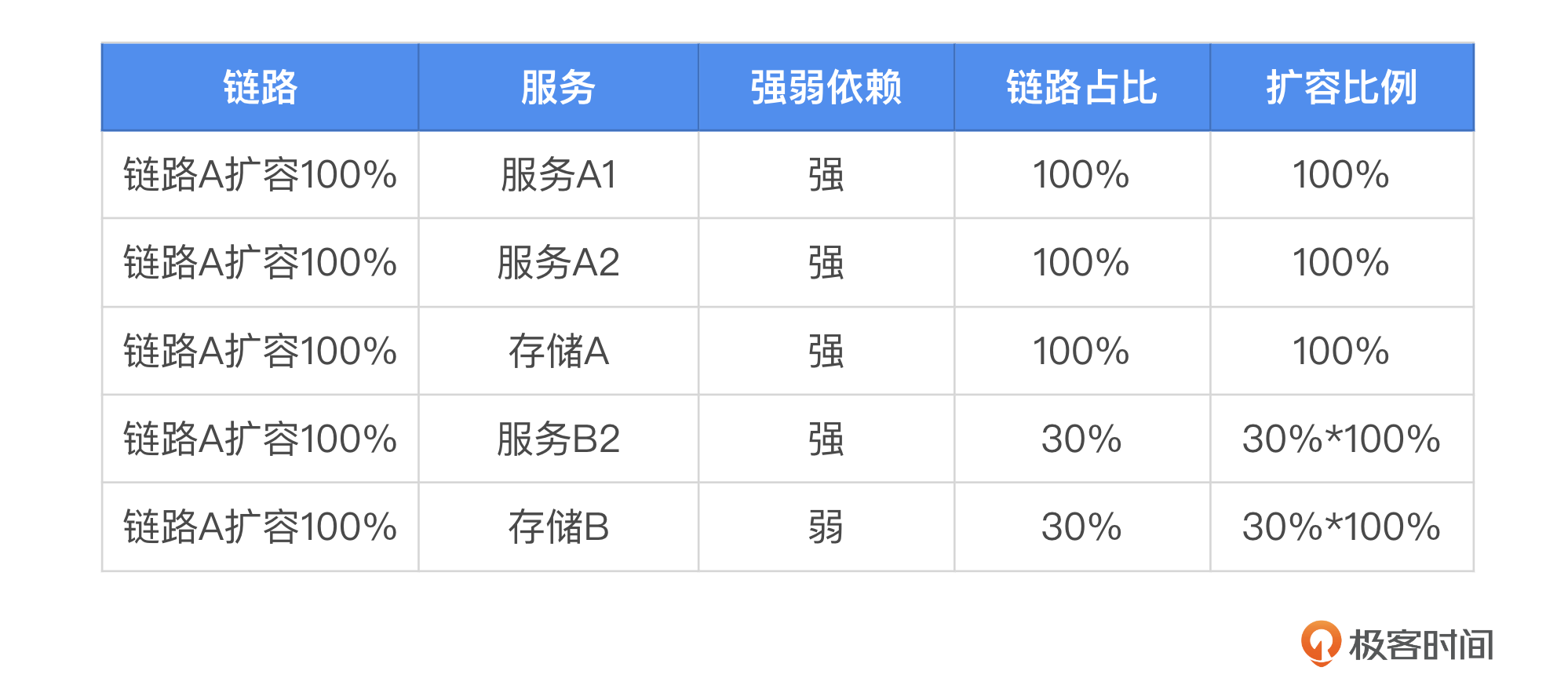
为了更直观地展示这一过程,我提供了一张表格作为参考,帮助你进一步理解如何根据链路特性和流量模式来确定扩容策略。这里如果A入口流量增长1倍,那么B2需要在原有基础上扩容多少呢?原来B2的上游流量占比 A1为30%,B1为70%;现在就变成了30%*2+70%=130%,等比资源就需要之前的基础上扩容30%。
此外还有一些扩容手段,我们一起了解下。
首先,将根据预先计算的比例进行全面扩容。这一步的重点是优先扩容那些强依赖的服务。如果资源充足,也会考虑扩容那些弱依赖的服务。
仅依靠初步扩容可能不足以应对所有情况。因为在实际运行中,某些服务可能存在性能误差,或者有些服务的实际需求没有被准确识别。因此,在初步扩容的基础上,我们需要引入弹性伸缩策略,这依赖于实时监控系统。一旦监测到CPU使用率超过预设的阈值,系统就会自动触发扩容流程。这种策略与初步的统一扩容形成互补:初步扩容是基于流量预测进行的,而弹性伸缩则是根据实时数据进行的动态调整。
最后,通过压力测试来模拟真实流量。在压测过程中,如果发现某些服务的CPU使用率不足,将利用弹性扩容功能,进一步增加资源,以确保服务的稳定性和响应速度。
在完成压力测试并确认系统稳定通过测试之后,将实施统一的限流策略。这一策略旨在确保系统的流量处于可控范围内。对于超出设定限流阈值的流量,将采取丢弃处理,从而避免过载情况的发生,保障核心服务的正常运行。
通过这种分阶段、有计划的扩容策略,能够更加灵活和高效地应对不同服务的资源需求,同时确保整个系统的稳定性和性能。
问题四:存储层如何处置?
数据库(DB)扩容是一个耗时的过程,特别是在紧急情况下,很难迅速完成,因为扩容涉及到数据的同步操作,必须在同步完成后才能进行。通常情况下,只能对读分片(从分片)进行扩容,而对写分片(主分片)的扩容则相对复杂且具有挑战性。
- 缓存:在数据层应对热点最好的方案就是多级缓存,比如用CDN来缓存一些静态图片和视频,比如利用Redis/Memcached来缓解一些热点查询压力。因为有些扩容不一定能解决问题,比如读写热点集中在局部存储的时候,扩容可能来不及。
- 提前规划保持足够的冗余:针对写分片,应提前进行扩容,以避免在流量高峰时措手不及。针对核心集群的吞吐日常就需要有足够的冗余。比如微博需要保留3到4倍的冗余,当不满足时,便需要扩容。因为热点总是不期而来,扩容缓存往往并没有那么及时,这时候保证足够的冗余,有助于预防DB被打挂。
- 限流和降级:对于一个高可用的服务,很重要的一个设计就是降级开关,其目的是抛弃非重要服务,保障主要或核心业务能够正常提供服务。对于后端资源,包括MySQL、MC、Redis、队列等而言,并不能保证时时刻刻都是可用的,一旦出现问题,降级策略就能派上用场。
- 扩容:包括水平扩容和垂直扩容。选择水平扩容还是垂直扩容,需要根据实际业务需求、成本预算、系统架构和未来扩容计划来综合考虑。通常,水平扩容更适合于大规模、高并发、需要高可用性的业务场景,而垂直扩容则适用于业务规模较小、成本敏感或者短期内性能需求增长有限的情况。在实际操作中,两种扩容策略也可以结合使用,例如,先通过垂直扩容提升单个服务器的性能,再通过水平扩容来实现更大规模的扩容和负载均衡。
小结
这节课我们深入探讨了微博面对热点事件的应对策略,核心在于利用有限的资源以最快的速度进行扩容,应对流量高峰。我根据几种不同情况提出了一些理解和建议,我把问题分解成了四个具体问题,并给出了解决方案,如果你遇到类似问题时可以参考。

相关资料: https://www.sohu.com/a/214165308_355135 https://cloud.tencent.com/developer/news/818595
思考题
如果资源有限,但是需要扩容的链路很多,应该如何做出决策,哪些服务扩容,哪些服务降级,才能保障收益最优?欢迎你把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- Ferris 👍(0) 💬(0)
是2016年吧
2024-09-04