07 监控场景:为什么所有故障都有监控的因素?
你好,我是白园。从这节课开始我们就进入可靠性的第二章——场景实践篇,我会带你学习一些经典的故障案例来把理论应用到实践中。
我经历过的故障里面,绝大部分的故障都有一个优化项,就是需要优化或者补齐监控,虽然监控不是问题的根源,但总有优化的地方。这节课让我们来回顾并分析曾经发生的故障案例,深入了解各个层面的关键监控点和需要注意的事项。
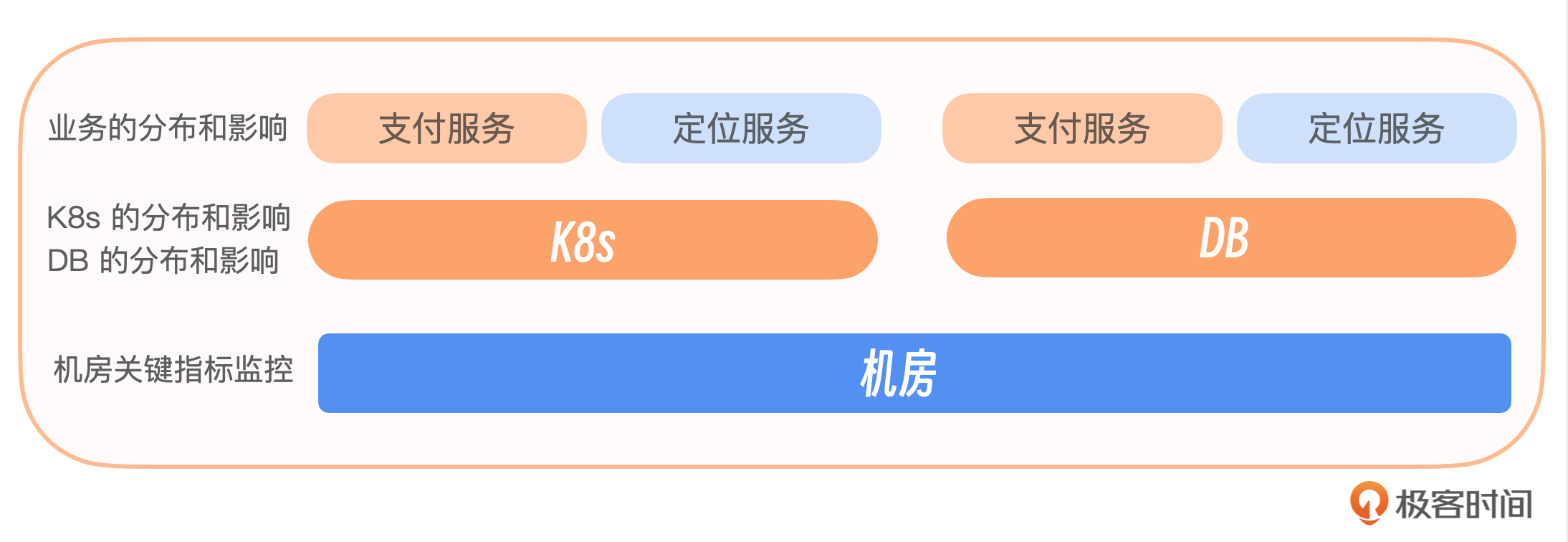
首先,我们分层分析用户请求流程,从顶层的客户端开始,一层层深入到运营商、接入层、服务层、数据层,直至机房。我们会对每一层进行详细分析,确保监控体系能够全面覆盖并有效响应潜在的故障点。
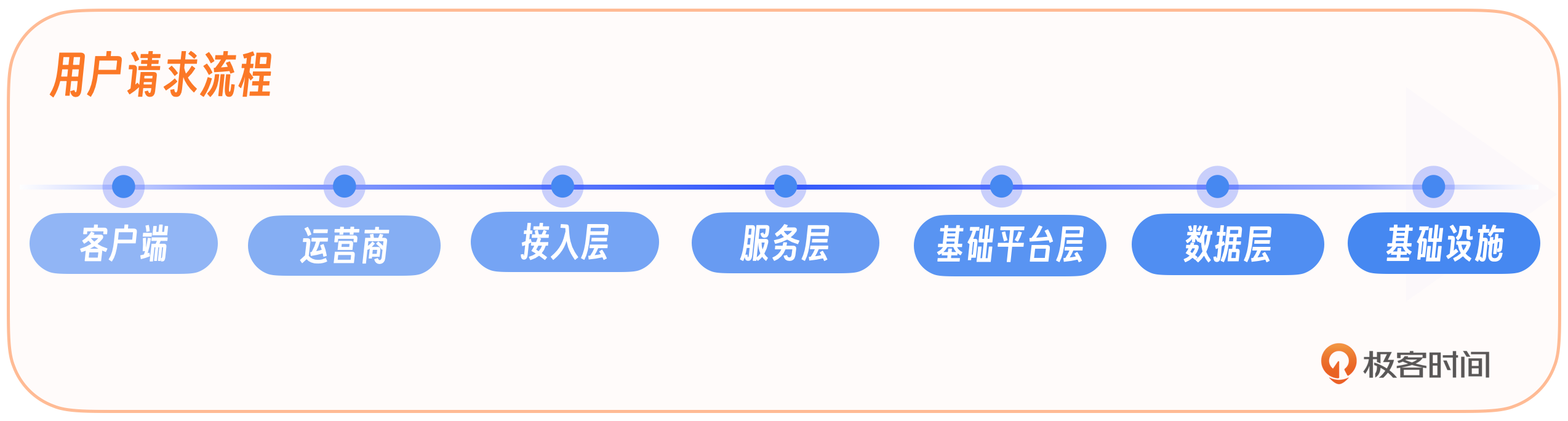
客户端监控
案例简述:2023年7月27日小红书故障
7 月 27 日凌晨,部分网友反馈小红书App出现闪退问题,官方发布第一个解决办法——卸载重装,官方“劝删”行为引起了部分用户的不满,有网友留言称不敢相信官方解决技术故障问题竟然是让删除 App 重装,也有用户表示按照方法删除重装后依然打不开App。
案例分析
故障原因:新发版的客户端存在Bug导致客户端崩溃,并且在版本发布的小流量阶段并没有及时发现这个问题,然后直接把版本推全,引起了大范围的故障和影响,这里暴露出来一个关键问题。在版本发出的阶段为什么没有及时发现?
接下来我们就来重点分析客户端应该如何监控和发现问题。
如何监控客户端?
客户端的问题往往对用户体验产生重大影响。在进行客户端监控时,我们需要关注两个主要方面。
- 客户端性能监控:包括监控客户端的崩溃率、启动时间等关键指标。这些指标反映了客户端的稳定性和响应速度,对于确保用户能够顺畅地使用服务至关重要。
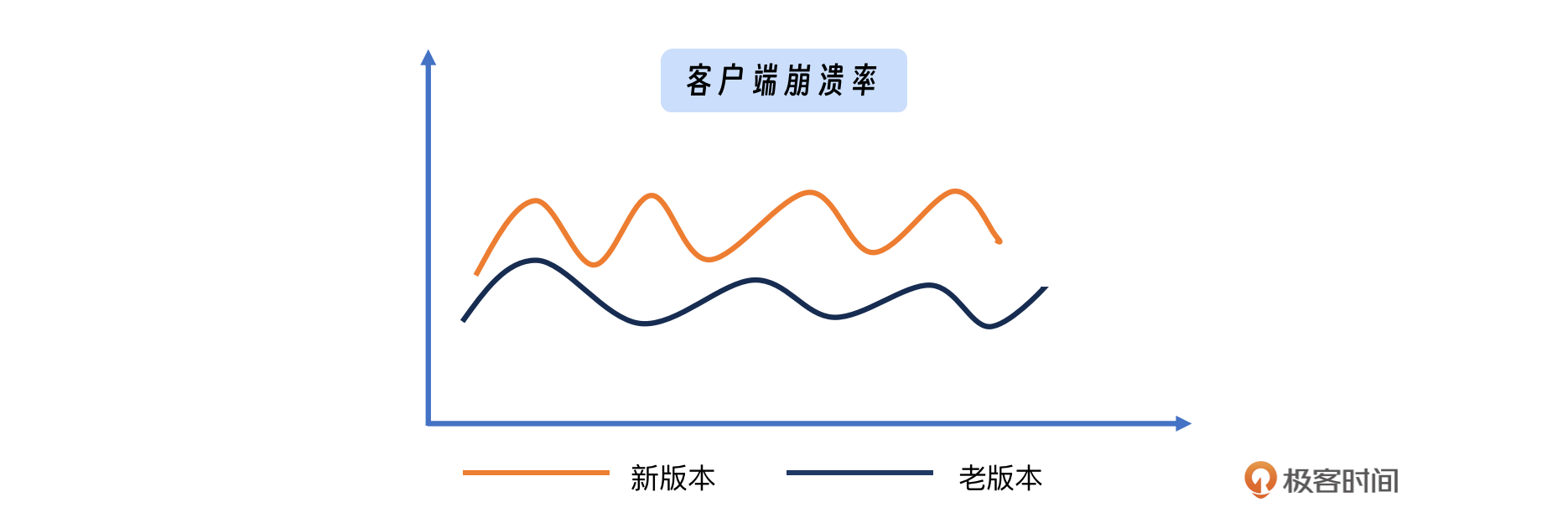
- 客户端与服务端交互监控:针对不同版本的客户端,我们需要监控其与服务端交互的性能,比如上传和下载的成功率及速度。这有助于我们识别由于客户端更新或服务端变更导致的潜在问题,确保用户功能的正常使用。
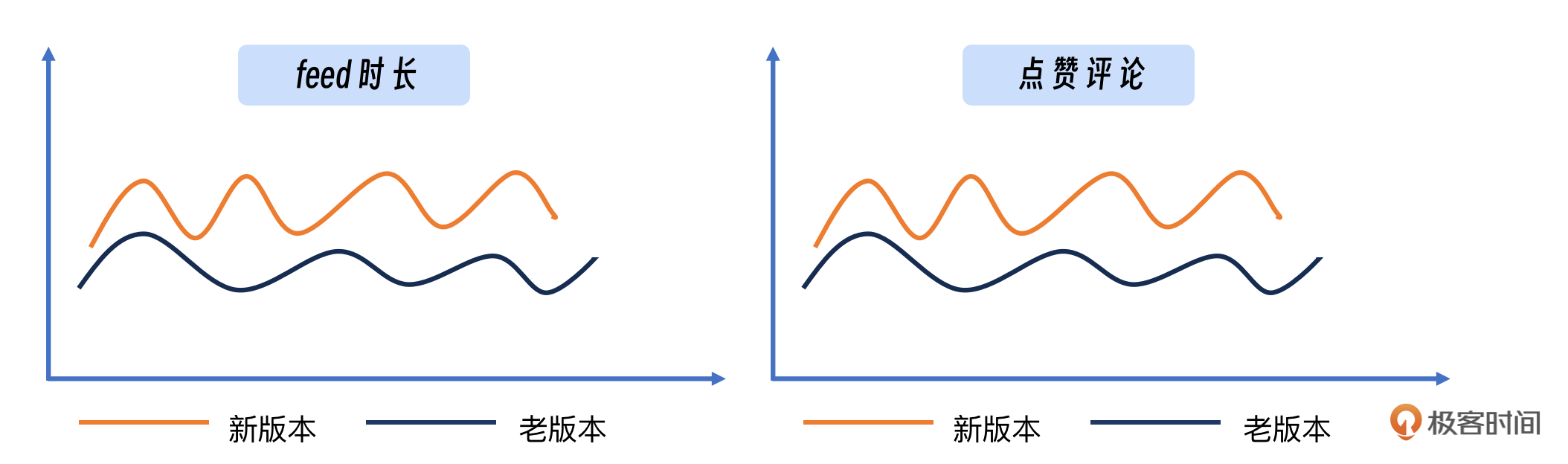
因为从历史案例的分析来看,客户端的变更可能导致两类故障:一是客户端自身的稳定性问题,如崩溃率上升;二是功能、接入点或数据处理的更新可能导致用户无法使用某些功能。因此,从这两个维度进行监控,可以帮助我们及时发现并解决这些问题,保障服务的连续性。
运营商监控
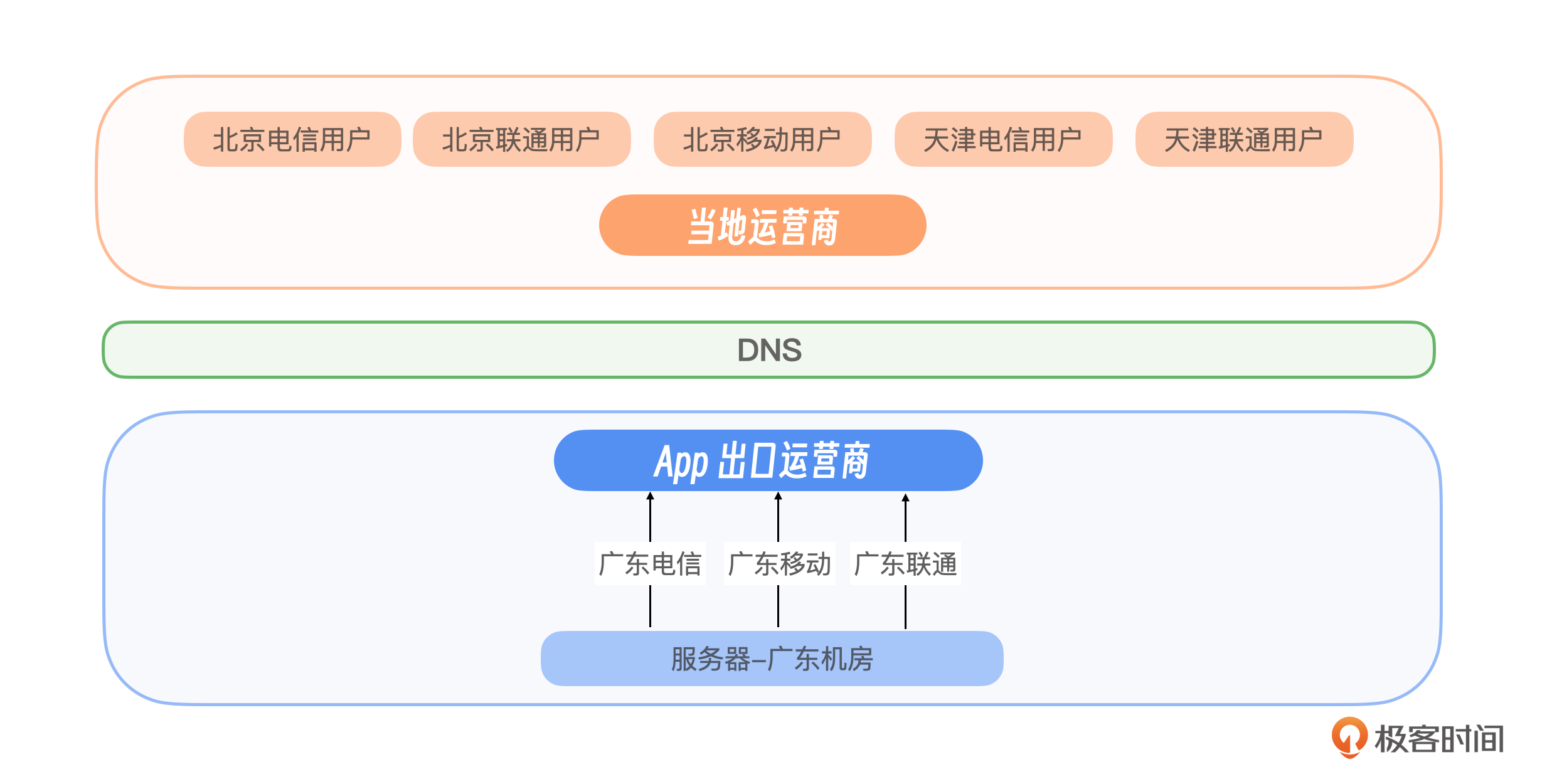
用户请求从客户端发出,之后来到当地的运营商,之后请求会从当地的运营商转发到服务提供的运营商进行交互。比如你的手机是河北联动,但是网站的IP是北京移动。因此我们从两个主要视角来分析。
- 用户所在地的运营商:这涉及到用户如何通过运营商提供的网络服务访问应用或网站。监控这一层可以帮助我们了解网络质量对用户体验的影响,例如加载速度、连接稳定性等。
- IP出口的运营商:这部分关注的是数据中心与运营商之间的连接质量。监控这一层对于确保服务的可靠性至关重要,因为它涉及到数据传输的效率和稳定性,直接影响到服务的可用性和性能。
案例简述:2023年6月8日广东电信大面积断网
2023年6月8日晚,广东电信网络罕见地出现了5小时的大面积断网事件,给亿万用户的生产和生活都带来了严重影响。此次故障的原因官方并没有说明,不过从后续网上披露来看,应该是广东电信核心网某个关键模块出现了故障。
案例分析
用户通过运营商接入网络时,可能会遇到域名劫持、DNS故障等问题。运营商故障的案例是我们经常遇到的故障,对于一个网站,或者一个App来说,最重要的就是能及时的识别出来是哪些地区出现了故障,是运营商本身的故障还是DNS劫持。
如何监控用户所在地的运营商?
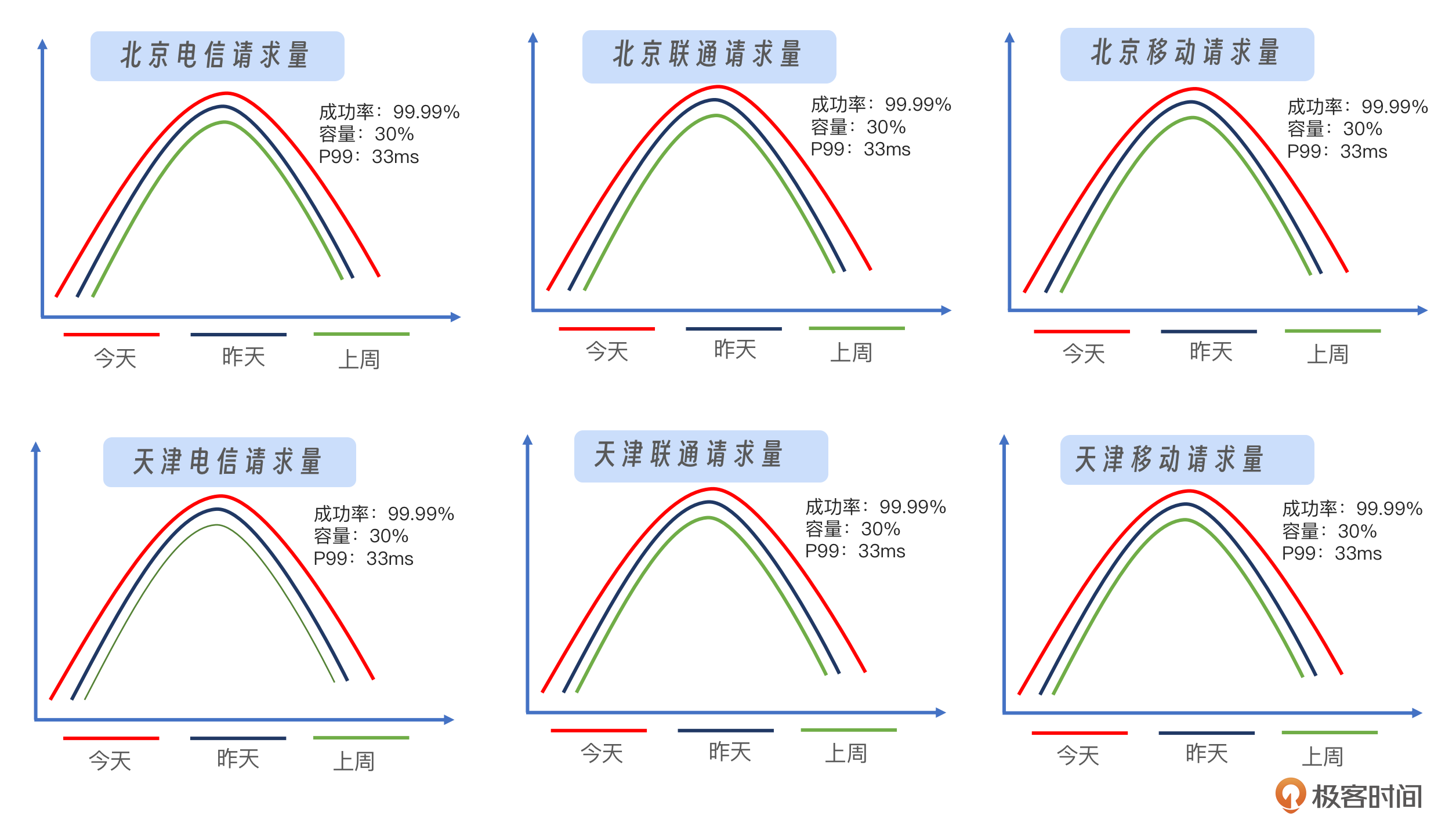
我们需要细化和拆分监控数据。我们可以根据用户的IP来源,将监控数据按地区和运营商进行分类和汇总。面对众多的监控曲线(例如,地区与运营商的组合可能达到150条),我们采取两种策略来设置报警。
- 流量较大的地区,由于流量模式相对规律,可以通过同比和环比的监控来设置报警。
- 流量较小的地区,流量模式可能没有明显规律,因此可以通过设置绝对阈值来进行监控。
针对这两种情况的监控和处理策略有所不同:对于用户当地运营商的故障,我们需要督促运营商快速恢复;而对于域名劫持或DNS故障,可以采用HTTPS或HTTPDNS等技术手段来解决。
如何对服务IP所在运营商进行监控?
2024年1月11日晚,多位网友表示包括《英雄联盟》《王者荣耀》在内的多款腾讯旗下游戏出现服务器崩溃、掉线的问题。“腾讯游戏全部断开”甚至登上热搜,这个就是因为腾讯游戏服务接入的运营商出现了故障,针对这种故障应该如何监控呢?
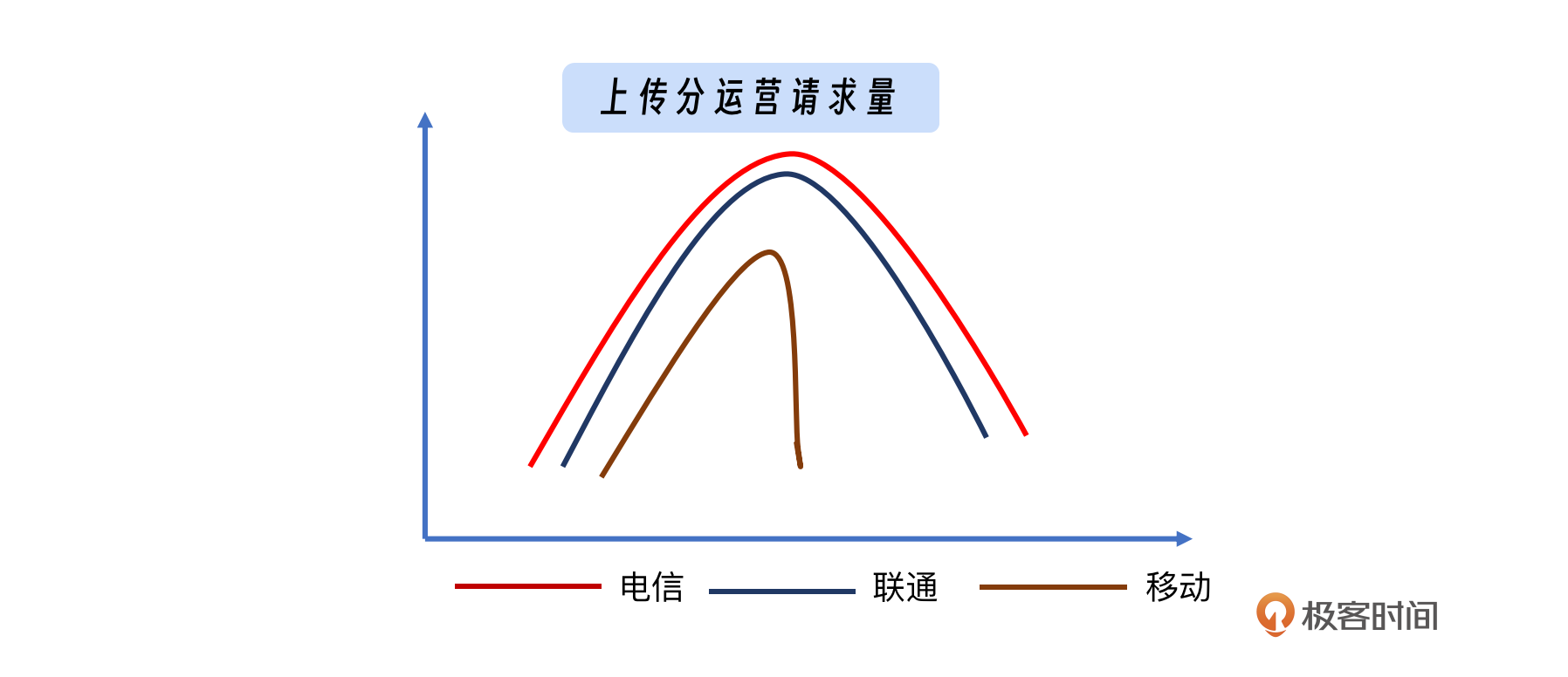
首先是对关键域名进行监控,对于关键域名监控,我们建议按运营商进行细分,例如针对中国移动、中国电信、中国联通等。此外,如果你的服务依赖于云服务提供商,建议使用2~3个不同的云运营商,以增加冗余和可靠性。比如我给出的这张示意图,当移动的趋势表现跟联动和电信不一致的时候,明显就是移动的运营商出现了问题,需要及时介入。很多时候某一个运营商的流量占比很小,如果不做拆分的话就非常容易被淹没。
这里你可能会问,每个功能都需要加吗?其实不需要,针对核心的功能添加就可以了。
接入层监控
用户请求从运营商层出来之后,进入接入层,这个时候请求已经进入了生产环境。
案例:2021 年 7 月 13 日 B 站故障
2021年7月13日晚,用户反馈B站无法使用,SRE收到大量服务和域名的接入层不可用报警,同时内部同学也反馈B站无法打开,甚至App首页也无法打开。最后确认是接入层的Bug导致。详细的解析我们会在后面课程中分享,这里我重点说一下接入层监控应该注意的点。
如何监控接入层?
在接入层的监控中,我们需要特别关注两个关键部分。
- 接入层性能监控:包括对CPU利用率、连接数和系统健康状态的实时监控。B站这个例子就是Bug导致资源迅速耗尽,最终CPU利用率飙升至100%,引发了服务故障。这类监控有助于我们及时发现并解决资源过载的问题。
- 第二是接入层与链接后端服务的状态监控对比:我们需要对比接入层观察到的下游服务状态与下游服务自身观察到的状态,包括接入层观察到的下游服务的实例数、存活数据、权重等等,是否与真实的下游服务的状态一致。很多情况下因为接入层的Bug把正常的服务实例踢出造成了故障。
基础平台监控
用户请求从接入层进入服务层,这个时候的服务其实大部分已经部署在了平台上,比如Kubernetes。像K8s这样的基础平台我们应该如何监控呢?
案例:2023年11月27日某网约车服务异常
11月27日晚,某网约车因系统故障导致App服务异常,这次故障的主要原因是更新了Kubernetes。
如何监控基础平台?
在基础平台进行变更时,我们经常面临一个挑战:变更可能会影响上层业务,但平台本身的监控指标却未能及时捕捉到这些影响。为了解决这个问题,基础平台的监控需要更加主动和全面。以Kubernetes为例,除了对Kubernetes自身的监控之外,还有两个关键的监控领域常常被忽视。
- 服务健康状态监控:我们需要监控运行在Kubernetes平台上的服务的健康状态。有时Kubernetes的变更可能不会直接影响其自身,但可能会导致运行在它上面的应用服务出现故障或重启。在这种情况下,监控服务的数量和关键服务的健康实例数变得尤为重要。一旦发现服务实例数有显著下降,就应该立即处理,比如停止当前的变更,进行回滚,并及时处理已经受到影响的服务。
- 上层业务监控:基础平台监控也应关注上层业务的关键指标。在进行平台变更时,如果平台状态、服务状态和业务指标都保持正常,那么可以认为变更是成功的。在某网约车公司的这次变更中就遇到了服务和业务指标大规模异常的问题。如果在变更的早期阶段能发现这些问题,就可以避免更严重的后果。比如Kubernetes上面部署了网盘、搜索等业务,在平台变更的时候至少要关注1~2条核心指标是否有波动。
因此,为了保证平台变更不会对业务造成负面影响,我们需要在变更前后都进行细致的监控,确保所有层面的指标都在正常范围内。
数据层监控
用户请求现在从服务层,进入到了数据层,比如DB。
案例:2023年10月23日语雀重大服务故障
2023年10 月 23 日语雀出现重大服务故障,持续 7 个多小时才完全恢复,给用户使用造成极大不便,我们一起来看一下此次故障的原因、修复过程和改进措施。
10 月 23 日下午,语雀的数据存储运维团队在进行升级操作时,由于新的运维升级工具 Bug,导致华东地区生产环境存储服务器被误下线。受其影响,语雀数据服务发生严重故障,造成大面积的服务中断。
案例分析
语雀这个故障相对来说要特殊一些,这个故障是数据类型的故障,涉及到了数据的误删、数据校验和数据的恢复,导致恢复时间会比较长。所以针对数量类型的服务,我们应该尽可能在初期就发现问题并及时解决,而不是等到故障大面积爆发的时候才开始处理。另外对于语雀来说也是相对幸运的,因为数据最终还是恢复了。
如何监控数据层?
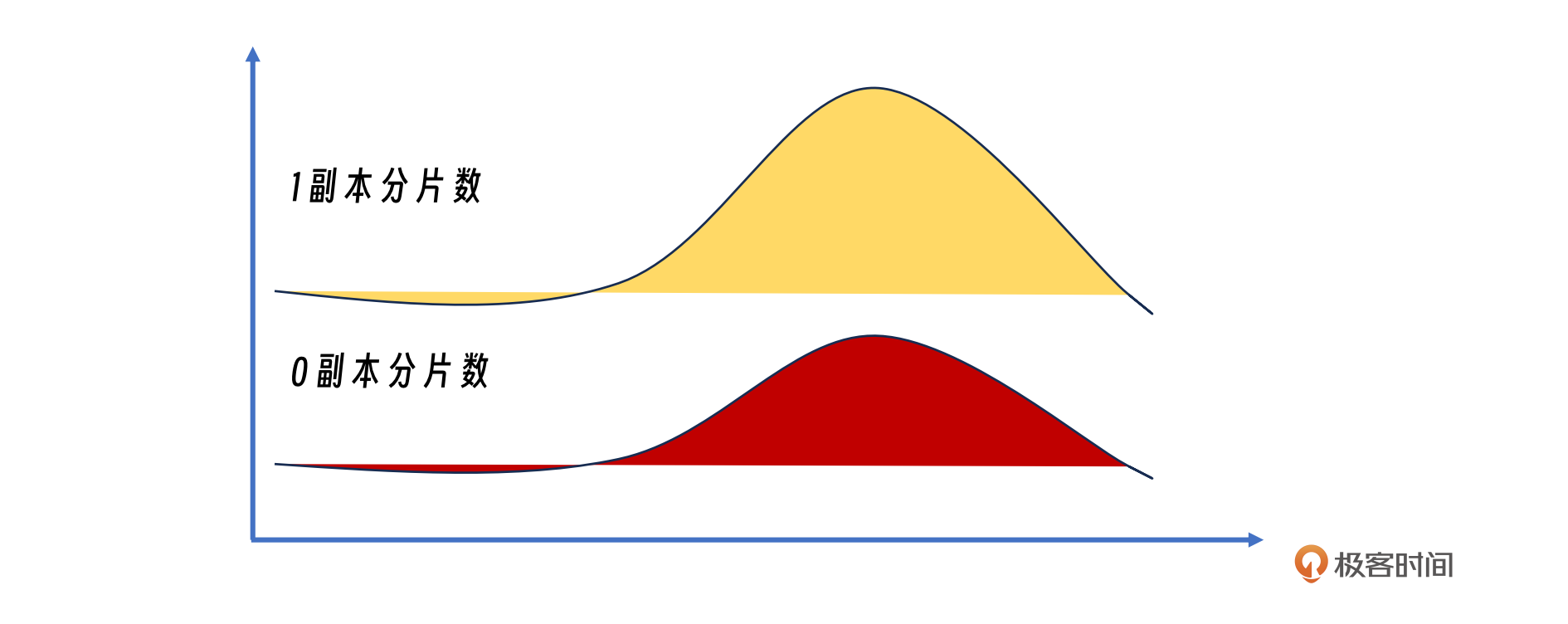
存储服务和计算服务很不一样,存储服务需要特别关注数据的可靠性。最直接的可靠性指标包括零副本、单副本和双副本的分片数量。大多数存储系统采用三副本策略来确保数据的冗余和持久性。在正常情况下,即使有两台机器发生故障,系统也能自动修复数据,因为至少还有一台机器保持运行。然而,如果故障发生的速度超过了系统的修复能力,就可能出现单副本甚至零副本的情况,这会造成严重的数据流失。
- 不完整副本数的监控:这些副本的数量对于维护存储服务的稳定性至关重要,以语雀这次的故障为例,能直接发现问题的地方就是这个监控在运维变更的时候,如果可以及时发现副本数量的变化就能及时止损。常见的分布为3副本,那我们就需要对0副本和1副本的分片格外重视。
- 对备份成功率的监控:还有一个容易遗漏的就是备份频率和完整性的监控,语雀能成功地恢复得益于它做了完整的备份,如果数据永久性地丢失,影响会更大。对于备份是否成功是需要有监控的,这里可以通过数据校验来判断。
基础设施层监控—机房
用户请求从数据层出发来到了最底层,也就是基础设施层,这里我们重点介绍机房。
案例:2023年3月29日唯品会机房宕机
2023年03月29日 00:14~12:01 唯品会机房宕机近12小时,故障的主要原因是南沙 IDC 冷冻系统故障,导致机房设备温度快速升高宕机,线上商城因此停止服务。
案例分析
机房故障其实是最严重的一种故障,影响范围之广,影响的业务之大,让人无法不重视。这里我重点说一下监控可能遗漏的点。机房故障其实分两种,一种是突然故障,不给人任何缓冲时间;第二种是断电、温度等故障,第二种故障其实还是有30分钟左右的时间,这30分钟非常宝贵,我们如果能利用好这段时间把流量切走,那么是可以完全避免重大故障的出现。但很多时候因为监控有盲点,所以就把这宝贵的30分钟忽视了,直到最终故障。
接下来我们就来看看如何避免监控盲点,利用好这宝贵的30分钟,及早发现故障。
基础设施层如何监控?
机房监控涉及众多指标,如环境、电力、水冷系统等。但从业务角度出发,我们需要关注以下几个关键监控点。
- 温度监控:历史数据显示,空调或制冷系统故障是导致机房故障的常见原因。温度的升高通常是一个缓慢的过程,通常有大约15分钟的时间窗口供业务团队开展应对措施及切换系统。因此,监控机房温度对于预防硬件故障和保障业务连续性至关重要。
- 服务器与业务关联监控:在机房发生故障时,快速判断受影响的范围至关重要。首先需要确定哪些服务器出现了故障,这些故障又影响了哪些服务,以及进一步影响了哪些业务,我们才能迅速做出判断并采取有效行动。
小结
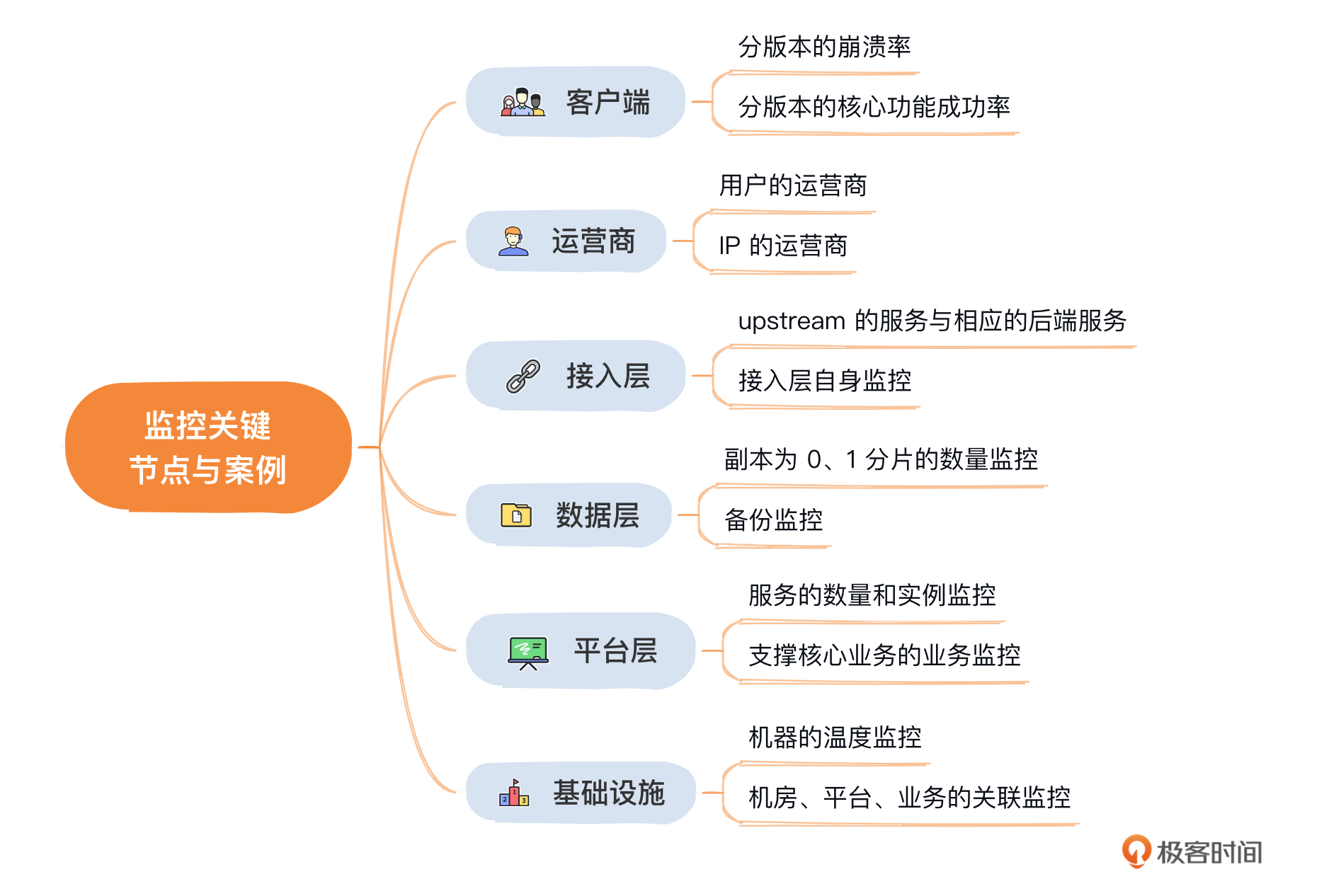
今天我们从用户请求流程出发,梳理了几个重要的监控节点,通过我给出的近几年几个重要故障案例来看,这些节点都是非常容易出现故障的环节,从客户端、运营商、再到接入层、数据层和平台层,以及最底层的基础设施层,哪个环节出现问题都有可能引发重大故障,给业务造成巨大损失,需要我们特别关注。具体哪一层应该监控哪些指标,我就不一一列举了,你可以通过我总结出的思维导图来回顾。
思考题
其实除了我们今天说的这几个层次之外,还有一点就是服务层的故障和监控,你有没有遇到过相关的故障,你又是如何处理的?欢迎你把你曾经遇到的故障以及故障的原因分享出来,我们一起交流、讨论,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
- 可乐 👍(0) 💬(0)
感觉以上说的,更适合专门搞Sre的同学,具体搞业务的,还是比较关注业务上的监控
2024-09-20 - 若水清菡 👍(0) 💬(0)
基本上全部遇到过,这些故障的频次特别低,一年有时候都出不了一次,机房互备这个成本太高小公司做不了,日常工作中遇到比较多的故障集中在变更上。
2024-08-09