03 变更:为什么说变更是可靠性的第一杀手?
你好,我是白园。今天我们来聊聊可靠性领域的第三个部分——变更。
你有没有发现一个现象,无论是国内的公司还是海外的公司,在故障原因中,变更所占的比例最大。你有没有想过原因是什么?既然变更是可靠性第一杀手,那么有没有什么办法来彻底解决这个问题?
在接下来的内容中,我将带你深入探讨变更背后的原理,并分析为什么变更会成为系统稳定性的主要威胁。此外,我将分享一套有效的策略来应对变更带来的风险,帮助你提高系统的可靠性。通过这些方法,我们可以更好地控制变更过程,减少其带来的负面影响。
变更是什么?
正式开始之前,你可以先回答我一个问题,以下哪些操作属于变更?

答案是:上述列举的所有操作都属于变更。实际上,任何操作只要有可能影响到线上服务可靠性都会被视为一种变更。
为什么说变更是可靠性的第一杀手?
变更的本质就是打破稳态,在日常工作中,任何形式的变更,在变更过程中都可能让一个系统从稳定状态转变为不稳定状态。而系统处于不稳定状态的时候,正是故障最容易发生的时刻。
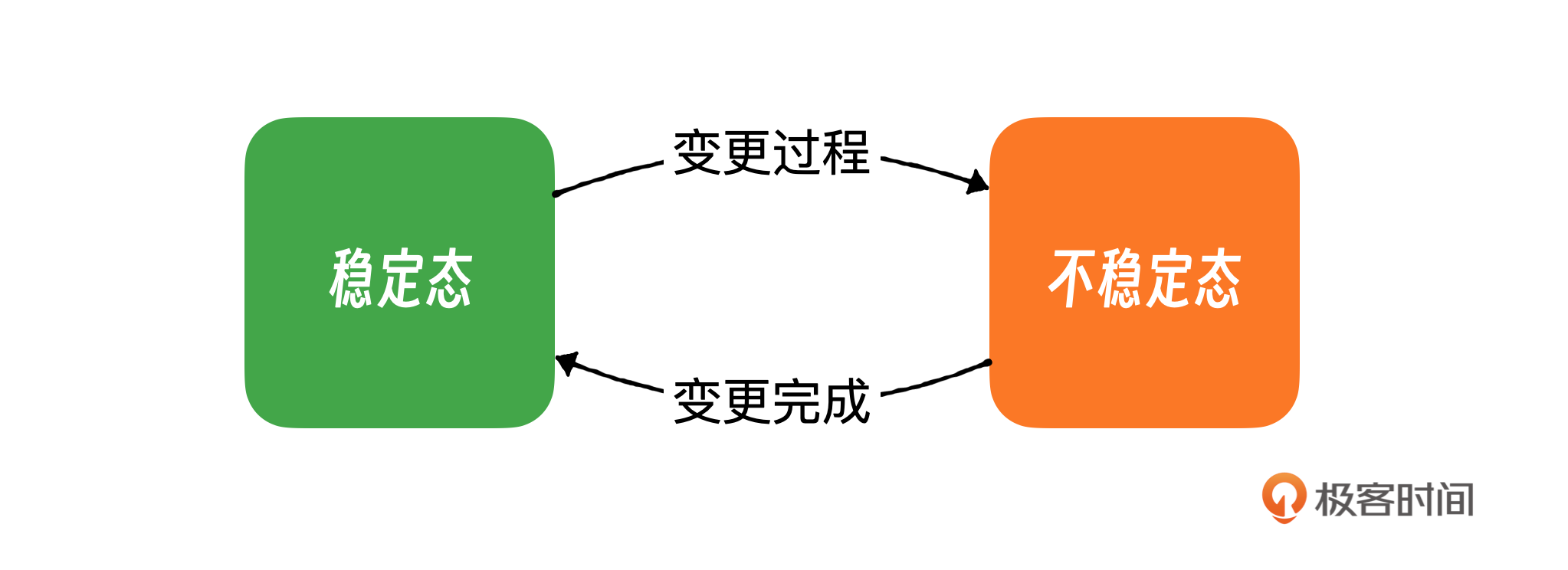
其次,变更的来源广泛,发生频率高,形式多样,涵盖软件更新、配置调整、硬件升级等类型,这些都显著增加了风险。在我负责的业务领域,变更日均超过百次,涵盖代码发布、配置调整、A/B测试等多种类型。历史上,这些类型变更都曾引发过故障。
如何应对变更带来的风险?
接下来,我们将探讨如何应对变更带来的风险。首先,我们需要对变更故障进行分类。在宏观层面上,变更故障主要分为两大类:主观因素导致的故障和客观因素导致的故障。
主观因素主要涉及人为问题,包括:
- 没有按照既定流程操作:比如一个同学在封网期间,由于自信而跳过审批环节进行变更,最终引发线上故障。
- 忽略测试环节:一个同学感觉代码的变化很小就省略线下环境测试,直接在生产环境部署了新代码,最终恰恰是这个很小的变更引发了故障。
- 没有关注监控:在小流量测试阶段忽视了对关键指标的观察,未能及时发现指标变化,可能导致全面部署后故障大规模爆发。
- 变更比较随意:团队成员可以在任何时间进行变更,这不仅增加了变更的频率,而且由于变更时间的分散,难以确保所有相关人员都能及时响应,从而可能加剧了系统故障的风险。
客观因素主要涉及平台和工具的问题:
- 监控指标太多:关键指标的变化微小且不易被察觉,如内存泄露问题,通常难以通过监控发现,直到内存报警才引起注意。
- 隐藏的Bug:例如,只有特定请求触发的core dump或用户ID越界问题,这些 Bug通常只在特定条件下才导致线上服务崩溃。
- 上下游服务问题:上线新功能可能导致下游服务调用量激增,如果没有及时监控下游服务的容量,可能会在高峰时段引发故障。
整体应对方案
为了有效应对变更带来的风险,我们双管齐下,一方面解决主观层面的问题,另一方面解决客观层面的问题。我们的应对措施贯穿变更的全过程,包括变更前、变更中和变更后三个阶段。此外,我们还可以依赖平台、工具和人工智能技术的支持,提高风险管理的效率和效果。
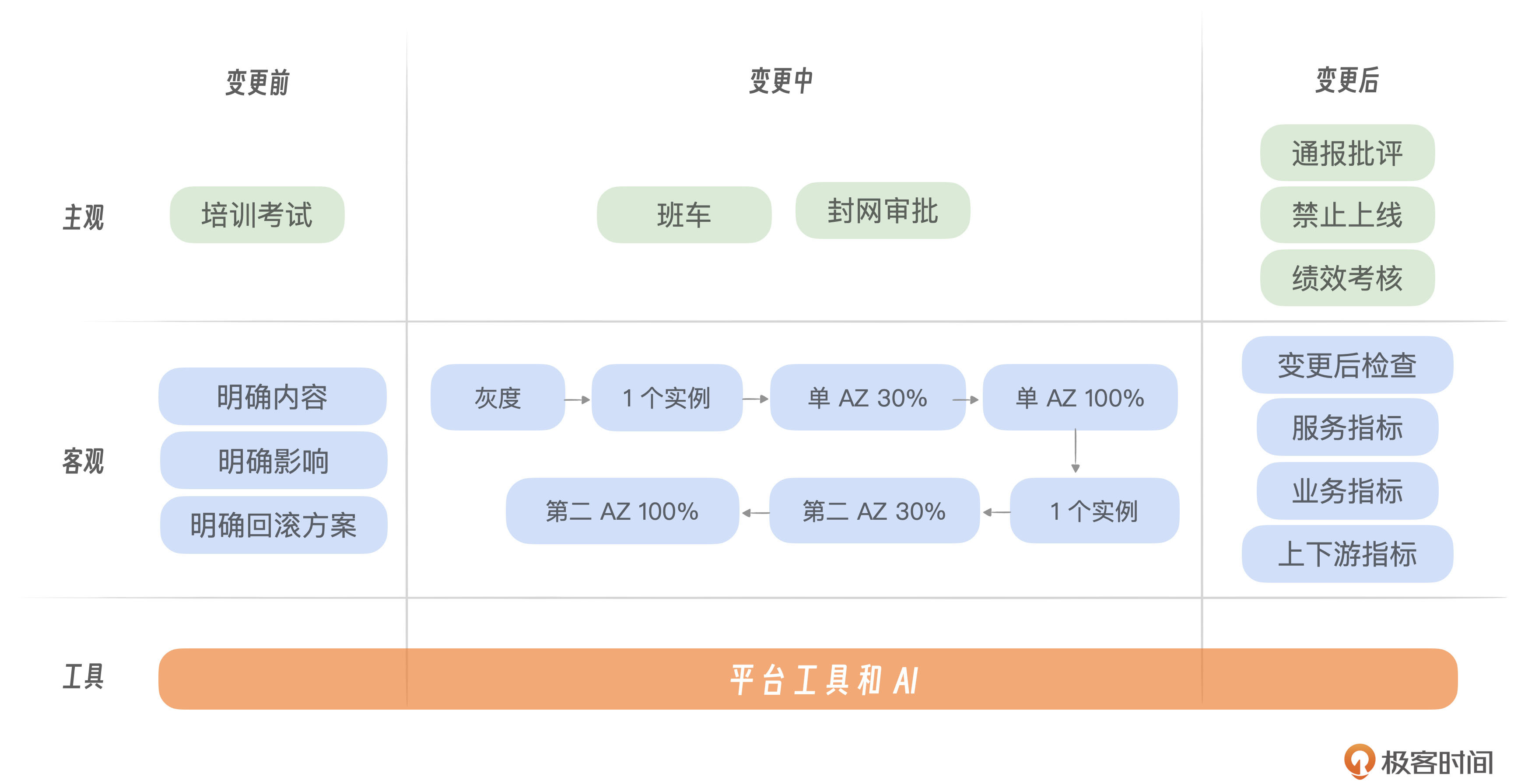
主观层面上
首要任务是提升团队成员对变更管理的重视。许多团队成员可能对变更流程和规范不够了解,因此必须明确传达相关的操作流程和标准。为确保线上变更的安全性,所有成员在进行变更操作前必须通过相应的流程和规范考核。原则上,只有考核合格者才有资格执行线上变更操作,这是保障变更安全的基本前提。

建立明确的奖惩制度,尤其要强调惩罚措施的重要性。
- 通报批评:对于未遵守变更规范而引发故障的行为,应在适当的范围内公开批评相关人员及其直接上级。若故障影响较大,应相应扩大通报的级别和范围。
- 禁止上线权限:对于造成故障的个人,可以暂时撤销其上线和变更的权限,例如禁止期限为两周,直至其重新学习并通过考核后,才能恢复权限。这类似于驾驶违章的积分处罚制度。
- 绩效考核影响:对于造成严重后果的故障,应在绩效考核中予以明确体现,确保责任与后果相匹配。
实施严格的变更机制,提高变更的审慎性,并有效降低变更的频率。比如班车制度就是一种有效的方法,它允许将多个变更集中到单一的部署过程中。这样做的优势在于显著减少了变更次数,并在出现问题时便于执行回滚操作。
此外,我们还应当设定变更时间窗口期,避免在团队休息时段进行变更。推荐上午10点到中午12点,以及下午2点到5点之间进行变更操作,确保在变更过程中有足够的团队成员可以支持和应对可能出现的问题。当然你可以根据自己的业务场景设置合理的变更窗口期。
客观层面上
整体分为变更前、变更中、变更后三个阶段,我们看一下每一个阶段应该做哪些事情。
变更前:充分评估、准备
首先我们应该详细记录每次变更的具体内容,包括更新了哪些代码模块、变更执行者的身份,还有是否已经完成了QA测试。如果测试被跳过,必须说明原因。然后在变更前,需要评估变更可能对哪些功能造成影响,还有是否会增加资源的使用量,这些评估应当尽可能准确。最后是制定详细的回滚计划,来应对变更后可能出现的问题。计划中应该包括怎么回滚配置、代码或数据,还有如果涉及数据变更,应该提前进行备份的步骤。
变更时:分级发布
分级发布是一种非常有效的应对变更风险的策略,目的是将变更可能引起的风险最小化。在实施线上变更时,将整个变更过程细化为若干阶段,每个阶段针对特定的服务实例或可用区进行操作。理想状态下,变更应按照服务单元的逻辑顺序逐步展开。这种分阶段的方法允许我们在早期发现问题时及时采取措施,为后续的故障控制提供了更大的灵活性,有效降低了整体风险。
分级发布的三要素
- 变更顺序:按可用区依次进行,这里的可用区,可以是分组或者机房,这个就按照具体的业务情况来定。可用区之间要严格按照顺序进行,不要并行。这样的好处是,当一个可用区有问题的时候可以快速切流到另一个,不至于两个都挂掉。在可用区内也要按照一定比例的顺序进行。
- 变更检查:在每个阶段之间要进行严格的变更检测。比如可用性、延迟、资源消耗等等。一旦有问题就需要进行变更干预。

- 变更干预和处置:一旦发现异常就要快速阻断当前的变更,一般我们可以根据具体的情况采取不同的方式处理。如果是1个实例有问题,这个时候可以采用单实例摘除的方式进行;如果一个可用区全量后发现问题就可以进行快速切流;如果所有服务都完成上线了,这个时候就只能回滚了。

变更后:检查
变更后的检查环节常常被忽视,但它对于确保变更成功至关重要。在进行变更后的检查时,应关注几个关键指标。
- 自身服务状态指标:这些通常是最容易监控的指标,包括调用成功率、响应延迟和CPU等待时间等,它们直接反映了服务的健康状况。
- 业务核心指标:有时服务变更可能在内部运行正常,但却影响到其他依赖服务。例如,一个接口的数据格式变更,可能导致依赖该接口的服务出现问题,从而引发整体业务指标的波动。曾有一个案例,服务端返回格式的错误导致客户端服务崩溃,造成了严重故障。
- 上下游关键指标:包括调用频率、延迟以及核心功能的性能指标。上游服务的变更可能会增加下游服务的流量,有可能导致下游服务超载。比如曾经有新增功能未及时通知下游服务,导致流量激增4到5倍的事情发生。由于变更是在低峰期进行的,下游服务未能立即察觉到变化,结果在晚高峰时段出现了容量不足的问题。
工具和平台层面
如果想要更全面地防范变更引发的故障,我们还需要借助一些工具,比如自动阻断和智能checker。
自动阻断
自动阻断系统的设计旨在实时监控发布过程,并在检测到异常时自动暂停操作。这种方法能够在问题发生的早期阶段进行干预,有效降低了生产环境中大规模故障发生的风险。自动阻断常见的就是对通用性能指标进行监控,一旦这些指标出现异常,系统便会自动触发暂停变更的机制。这些指标包括但不限于调用失败率、CPU使用率、P99延迟、实例存活数以及core文件的数量等。
不过自动阻断只能应对通用指标的监控需求,但对于特定指标的监控显得力不从心了。这时候就需要用到智能checker了。
智能checker
智能checker可以处理大规模且具有个性化特征的指标检测问题,是自动阻断系统的补充。
例如,在网盘服务中,有的服务侧重于上传性能的监控,而另一些则关注下载性能。对于上下游服务的监控也同样如此,每个服务的依赖关系和业务模式都不相同,通用的监控策略不太合适,这样我们需要检查的指标就很多了,可能会涉及几百上千个。
完全依靠人工检查这些指标显然是不现实的,因此必须借助智能checker技术。然而,智能checker也有局限性,它需要大量的计算资源和复杂的服务模型来支持。如何在这两者之间找到平衡点,以及如何进行资源的合理分配和优化,你可以先想一想,我们后面会在具体的案例中继续讨论。
小结
这节课,我们详细探讨了如何进行变更管理,特别是变更可能引发的线上问题及其成因。变更故障产生的原因主要有主观和客观两个层面。针对这两种不同层面的问题,我们提出了相应的解决策略:对于主观层面的问题,我们通过建立有效的机制进行管理;而对于客观层面的问题,则通过优化发布流程、采用合适的工具和平台来解决。
我把这些内容总结成了一张表格,你可以通过这个表格来对照和评估你的变更策略,确保变更过程顺利进行。
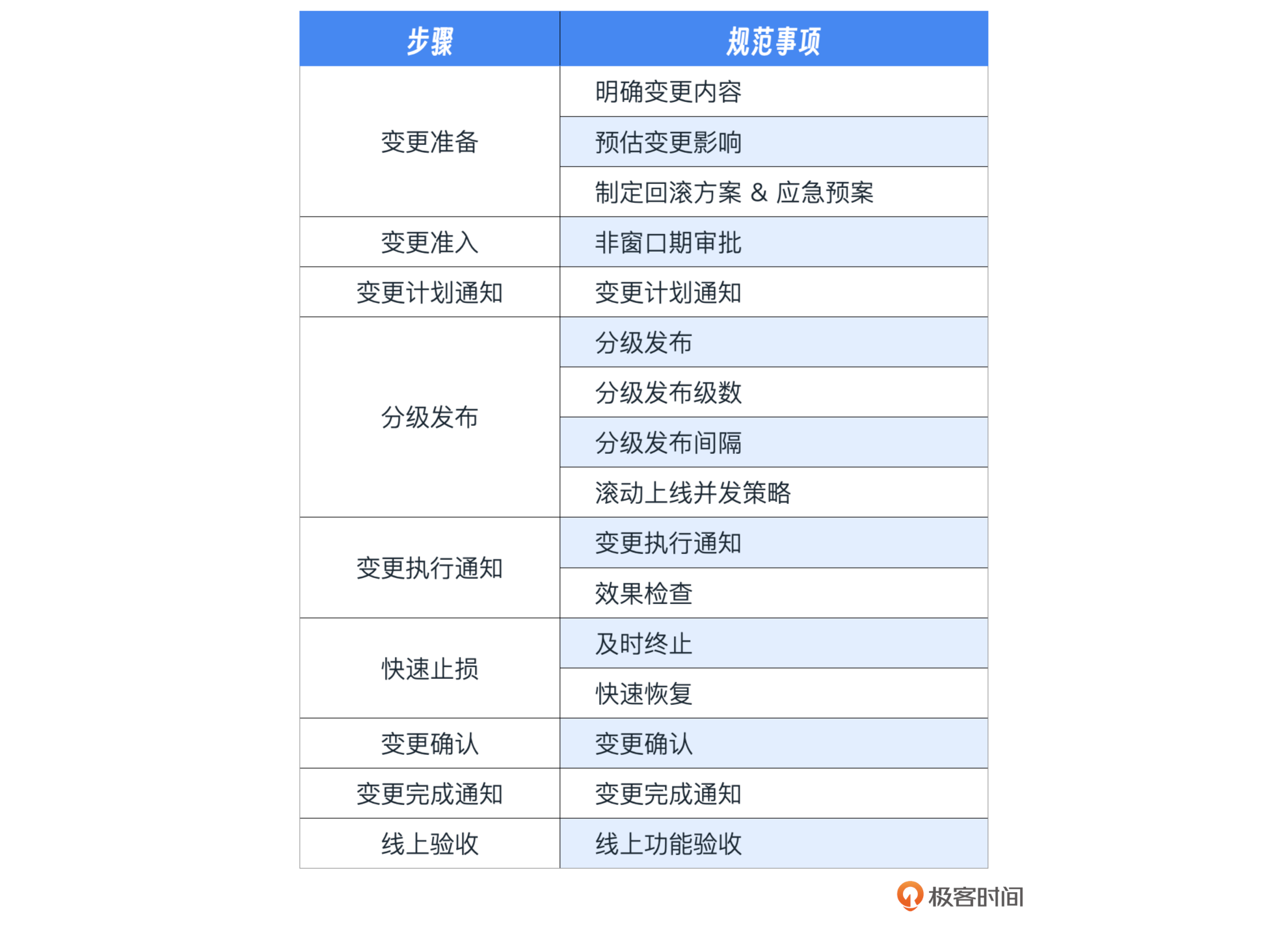
至于怎么把这些变更策略应用到实践中,后面的场景篇中我会结合具体的案例来深入探讨。这里有一些业界比较好的变更方案,有兴趣的话你可以点进去看看。
思考题
如果在上线的过程中,你的系统出现了故障,这个时候是优先切流止损还是优先选择回滚呢? 欢迎你把你的想法分享到评论区,和我一起讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
- takumi 👍(2) 💬(0)
先止损,把影响降到最低,然后在回滚,至少保证服务可用性不会中断太久
2024-07-30 - 枕畔雪 👍(1) 💬(0)
哪个手段生效快用哪个。一般情况故障发现后这两个手段一起上。
2024-07-23 - 会飞~的猪 👍(0) 💬(0)
根源上解决问题---灰度策略。先上灰度环境,没问题了再进行正式与灰度切换
2025-01-18 - 花花大脸猫 👍(0) 💬(0)
针对思考题,我理解需要针对业务特性来判断,在发版时,我们一般会控制新老版本的服务流量,保留一部分老服务,先将流量切给新服务,如果新服务业务处理异常,如果是面向客户是toC端会立即会立即切流回滚到老服务,如果是toB端的,会新老服务并行,控制新服务的转发流量,用于验证分析问题,基于问题解决的复杂度,确定是否需要回滚处理
2025-01-14 - 书豪 👍(0) 💬(0)
单实例阶段回滚,单机房阶段切流,全流量阶段回滚
2024-08-01