网易云音乐故障猜想:如何避免迁移带来的问题?
你好,我是白园。
这两天是不是被网易云音乐的故障刷屏了?从19号下午开始,我的群消息就没有消停过,都在讨论网易云这次的故障,也有不少同学想听我分析分析。虽然完整的故障报告还没有出来,但我们可以大胆推演一下。我也希望通过这次网易云音乐的故障,可以给你带来一些新的思考。
事件回顾
8月19日下午2点半左右,大量网友反馈「网易云音乐」App无法正常使用,随后“网易云音乐崩了”词条迅速登顶微博热搜,引发了广泛关注与讨论。对于这一大面积的故障,网络上迅速出现各种猜测事故原因的传言,比如删库跑路、服务器迁移、机房起火等等。
19日下午3点,「网易云音乐」在官方微博做出回应,称因基础设施故障导致各端无法正常使用。同日下午5点左右,服务已基本恢复正常。5点半,「网易云音乐」进一步澄清,否认了“删库跑路”的传言,并公布了针对这次事故的补偿权益。19日晚,「网易云音乐」在微博回复了媒体报道,称“今天下午在业务扩容中出现了技术事故”。
原因猜想
猜想一:机房搬迁
19日晚,「网易云音乐」在微博回复了媒体报道,称“今天下午在业务扩容中出现了技术事故”。根据《凤凰网科技》独家报道,这次宕机事件或与今年二季度的机房搬迁有关。一位来自网易内部的技术人员透露,此次事故可能与网易在贵州机房的迁移有关。网易二季度刚刚完成贵州机房的迁移,新机房的投入使用评估过程中就存在较高的风险。尽管前期内部评估认为迁移顺利,但实际上结果却令人担忧,搬迁完成后不久便发生了此次事故。
猜想二:扩容或者变更导致存储系统故障
值得注意的是,在网易云音乐崩溃的同时,有网友发现,网易新闻网页端无法正常加载页面,打开网易新闻网址后会跳转至移动端首页。可能是共用了同一个云存储。在故障发生约2小时后,网易云音乐的部分服务开始陆续恢复。有媒体报道称,为了降本增效,近年来网易云音乐存在人员优化的情况。此外,由网易开发的Curve存储系统团队也曾经历过裁员。因此可能是因为云存储运维人员不熟悉底层系统配置,在操作中出现失误。
简单总结一下原因:
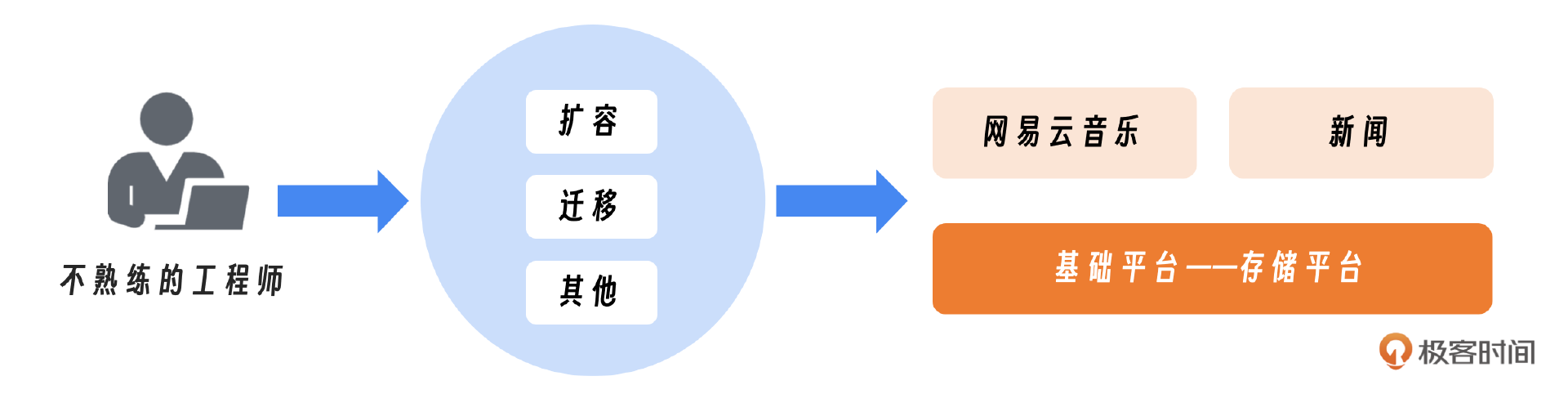
一个不熟练的工程师做了某个动作或者扩容或者迁移,导致了存储平台的故障,影响了网易旗下的多个产品,由于音乐用户最多,所以音乐的影响也最大。
根据网上的传言可能性较大的或与Curve存储系统有关。我们先看一下关于Curve相关的介绍。
2019年之前云音乐主要使用Ceph云盘,但Ceph在大规模场景下存在性能缺陷,且很难保证在各种异常(坏盘慢盘、存储机宕机、存储网络拥塞等)场景下云盘IO响应时延不受影响。因此网易云音乐才立项了解Curve块存储分布式存储系统。
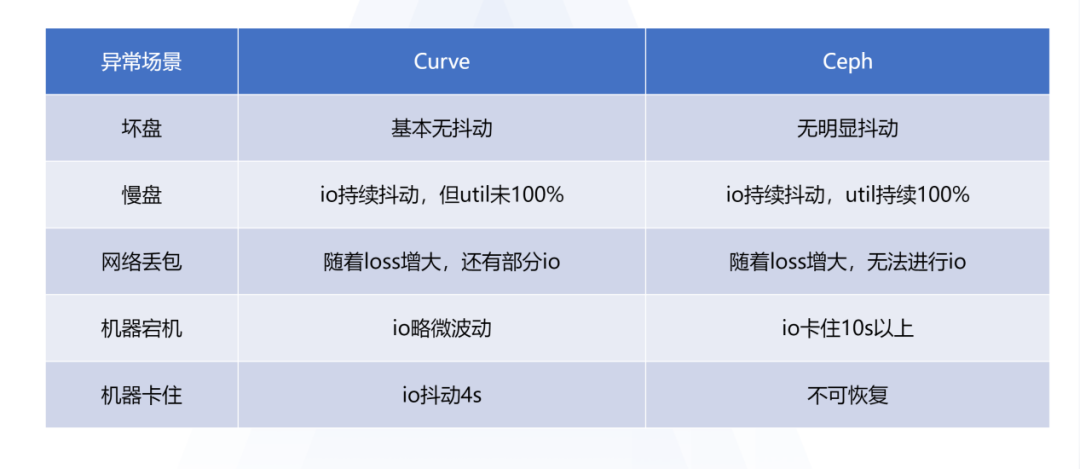 图片来自https://www.modb.pro/db/1702504020799737856
图片来自https://www.modb.pro/db/1702504020799737856
其实最终还是关于人的问题,如何解决。
角度一:老板是最终负责的人
对稳定性的重视和投入至关重要。作为老板还是需要给系统可靠性建设足够的重视和投入,如果老板都不重视那重大故障就是必然的结果。
另外作为老板也应该意识到其实系统能维持稳态才是稳定性团队最大的贡献,我们是需要投入大量的精力才能维持这个稳态,这个跟一个水电站是一样的,日常也是需要大量的投入才能维持稳定。
角度二:中层或者团队的leader该做什么
leader 需要做好衔接,去尽可能量化团队的价值,争取利益。中层领导者扮演着至关重要的角色。为团队争取合理的利益,包括但不限于资源分配、人员配置和职业发展机会。积极与上层管理层沟通,确保团队的目标与组织的整体战略一致,并获得必要的支持和资源。
- 晋升和薪资其实是关键点。如果团队长时间没有晋升是一件非常危险的事情。
- 结果达成:最终都是靠结果来说话,如果结果没有达成一切都没有意义,但是如果结果是好的,我们一定要争取积极的反馈。
- 离职和招聘:人员的离职是一个常态的事情,任何牛逼的团队都会有离职。但离职的交接要重视,不仅仅是在过程中重视,更要在平时都做好backup,任何人都不应该成为单点。
角度三:一线员工
其实作为一线员工,我们能改变的只有自己作为个人应该做什么样的准备。
- 最重要的还是不可替代性:工作上更加努力、积极、主动,老板交代的事情要及时反馈,自己领域的事情,一定要当仁不让,不可替代性是最重要的。
- 努力与细节:不亚于任何人的努力。努力要找对方向。努力思考,努力去做。一定要重视细节,做到完美。
- 坚持长期持续而孤独的投入:工作不是收入的唯一来源,不断提升自己,当有了随时想走就可以走的资本时,工作的原则和底线才能守住。
接下来我们再看下技术层面的优化和思考。
如何避免迁移带来的故障?
网易云计划进行迁移的主要原因是为了降低成本,特别是考虑到贵州机房的低成本优势。然而,确保迁移过程中的系统稳定性是一项极具挑战性的任务。为此,我们必须在整个迁移周期内严格实施故障管理策略,任何疏忽都可能导致严重故障。
迁移本身是一种重大的系统变更,而变更管理的关键在于采用成熟的解决方案来处理变更。我们需要确保迁移策略不仅能实现成本效益,同时也能保证服务的连续性和可靠性。这里的关键还是严格按照变更规范。你可以参考我之前的文章 03|变更:为什么说变更是可靠性的第一杀手?
熟悉流程和机制:在迁移过程中需要制定严格的审批流程和机制,比如定制时间窗口低峰期操作,如果这次网易云在夜间凌晨操作影响应该不会那么大。 还有一个技巧就是关键系统升级的任务必须经过两名专业审核员的双重审批和核实,确保升级流程的精确性和安全性。其实双人审核是我接触过的既简单又实用的方式,能避免大量人工失误导致的故障。
回滚方案:迁移必须事先制定一个清晰且可执行的回滚方案。一旦迁移过程中出现问题要能及时回滚。在实施任何变更之前,都应该确保存在足够的资源,便于迅速恢复到迁移的状态,从而有效应对可能出现的问题。另外就是要注意方案的验证和演练。
迁移中最需要关注的点就是分级、仔细观察、快速隔离和处置,尽可能在前期去屏蔽故障。
分布和分级迁移策略:需要对非核心的业务或者集群进行迁移。然后才是核心的业务或者集群,迁移过程中要仔细地观测相关指标。并且保持足够长的时间。这种逐步迁移的方法有助于最小化迁移对服务可用性的影响,并需要实时监控升级的效果。
如果在迁移过程中发现任何问题,就必须迅速采取措施,如果是对master等核心节点进行迁移的话,最好是能提前做好相关的备份,或者搭建两套热备集群,通过逐步切流的方式进行,千万不要线上直接进行扩缩容操作来完成。因为扩缩操作是非常难回滚的操作。
迁移后注意观察各种系统指标,比如流量、成功率、延迟等等。另外不仅要观测平台指标,也要观测业务指标,比如网易云音乐的关键指标。
如何控制影响?
首先看技术角度,核心的原则就是故障域的控制和细分,把一个超级大集群可以划分成多个小集群,来避免一个集群对整个业务的核心业务都有影响。
面对重大故障,必须迅速启动一套全面的对外应急响应机制,核心内容包括:
- 用户安抚:迅速采取措施安抚受影响的用户,通过清晰、透明地沟通,向用户说明故障情况、正在采取的措施以及预计的恢复时间。比如网易云这个对外的信息就比较及时。
- 专业团队介入:由专业的公关团队负责对外沟通,包括社交媒体、新闻发布等,以维护公司形象和用户信任。同时,还需要协调公关(Public Relations, PR)和政府关系(Government Relations, GR)两个层面的工作,确保所有外部沟通都是一致的,并且符合法律法规和政策要求。
- 沟通策略:制定明确的沟通策略,确保所有信息发布都经过严格审核,避免造成误解或恐慌。
- 后续跟进:在故障处理结束后,继续与用户保持沟通,提供恢复情况的更新,并在适当时候发布详细的故障报告和改进措施。
如何快速恢复?
在故障恢复阶段,单靠平台去做恢复是远远不够的,也需要业务层做容灾和逃生。 其实从各种重大故障来看多活建设和逃生是应对极端故障的第一选择。所以一定要做好多活的建设和日常逃生演练。一旦在迁移过程中发现有损失,及时进行逃生和切流,第一时间完成止损。
在平台层面,也需要做好日常故障的演练,比如故障快速重建,一键重启。当平台无法自动重启的时候有工具和预案进行一键启动,这样也可以加速恢复的速度。
小结
2024年已经走完一多半,这大半年有不少大公司出现了这样那样的故障,上次就连微软也没能幸免,希望我们都能从这些故障中吸取教训,观彼律己,修补漏洞,让自己的服务可靠性体系更加坚不可摧,给用户更好的体验。
- 若水清菡 👍(1) 💬(1)
其实就是猜想二,什么情况下连官网静态的服务都挂掉。肯定是依赖的共享存储挂掉导致的整体容器平台服务不可用。 降本增笑裁员后后面人照着操作文档搞的时候某些技术文字理解上有差异导致后端出现大规模某种事件。哈哈
2024-08-22 - 夜空中最亮的星 👍(3) 💬(0)
坚持长期持续而孤独的投入:工作不是收入的唯一来源,不断提升自己,当有了随时想走就可以走的资本时,工作的原则和底线才能守住。--- 这个说的很有共鸣
2024-08-21