微软蓝屏事件:如何应对变更带来的问题?
你好,我是白园。
不知道你有没有被7月19日微软蓝屏事件影响到,可能国内大部分人没有,有一部分外资企业因为安装了 CrowdStrike而受到了影响,而 CrowdStrike就是这次故障的“罪魁祸首”。
这次的蓝屏事件涉及全球几千万windows用户,波及全球,银行、航空、超市等使用windows 并安装了 CrowdStrike软件的企业。
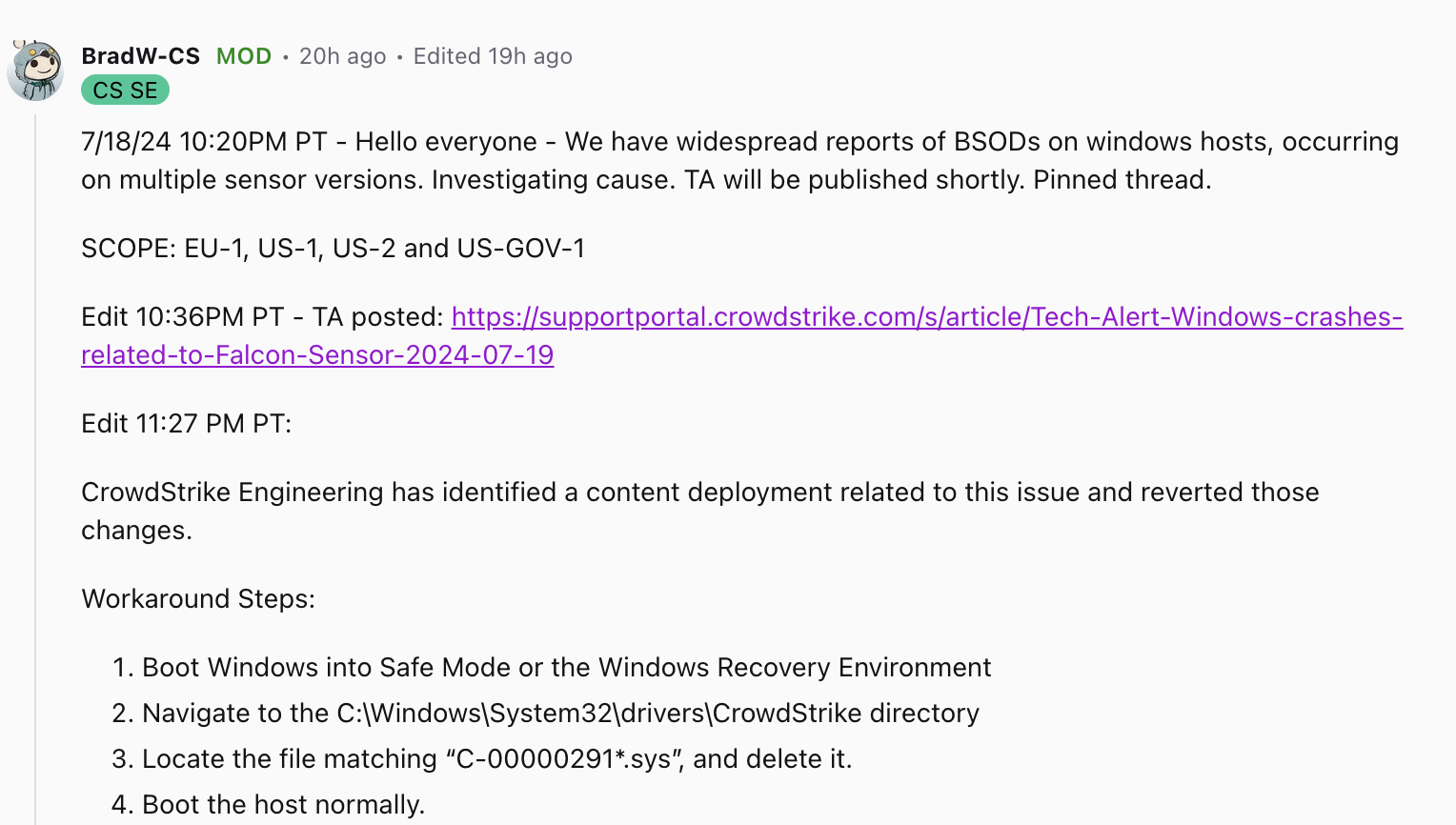
图片中的英文内容翻译如下:
7/18/24 10:20PM PT - 大家好,我们收到了关于Windows主机上出现蓝屏死机(BsOD)的广泛报告,这种情况发生在多个传感器版本上。我们正在调查原因。技术警报(TA)将很快发布。置顶帖子。 影响范围:EU-1, US-1, US-2 和 US-GOV-1 编辑 10:36PM PT - 技术警报发布:https://supportportal.crowdstrike.com/s/article/Tech-Alert-Windows-crashes-related-to-Falcon-Sensor-2024-07-19 编辑 11:27PM PT: CrowdStrike工程团队已经识别出与此问题相关的一个内容部署,并已撤销这些更改。 临时解决方案步骤: 1. 以安全模式或Windows恢复环境启动Windows。 2. 导航到 C:\windows\System32\drivers\CrowdStrike 目录。 3. 查找匹配 “C-00000291*.sys” 的文件,并将其删除。 4. 正常启动主机。
故障影响范围在 EU-1、US-1、US-2 和 US-GOV-1四个区域。据报道,7月19日,美国联邦航空管理局的状态页面显示,由于通信问题,美国航空当天宣布所有航班停飞。18日晚,由于微软服务中断,包括美国边疆航空在内的航空公司的运营受到影响。西日本旅客铁道公司(JR西日本)列车行驶位置信息因Windows系统故障导致无法获取,澳大利亚航空公司、银行、政府网络、企业、超市自动收银机等也受到影响。CrowdStrike的更新影响了大约850万台Windows设备。
可谓是让半个地球都停转了!那么我们前面说的CrowdStrike是什么呢?
Crowdstrike是美国同名软件开发商开发的面向企业和机构的终端安全软件,主要提供端点安全防护、情报威胁和网络攻击防御等服务。
当天下午晚些时候,根据Crowdstrike官方公布的信息,确定这个问题与“发版(content deployment)”有关,目前已经恢复了这些更改,建议受影响的用户将电脑启动到安全模式或恢复环境,导航至C:\Windows\System32\drivers\CrowdStrike目录,找到与“C-00000291*.sys”匹配的文件并将其删除,就可以正常启动电脑。
CrowdStrike首席执行官George Kurtz下午也在社交平台表示,这不是一起安全事件或网络攻击,相关问题已被识别、隔离,并已部署修复方案。
为什么一个普通的软件更新会引起整个操作系统的故障呢?
CrowdStrike作为一款安全软件,在内核级别运行,这意味着它拥有与操作系统管理员相同的权限等级,能够执行更高级别的安全监控和防护措施。
这次变更使Windows主机进入了自动修复死循环状态(recovery boot loop),没法开机。同时也暴露了一个问题,就是Windows操作系统在自我防护层面还是有缺失的,一旦陷入死循环,无法自我识别和隔离。
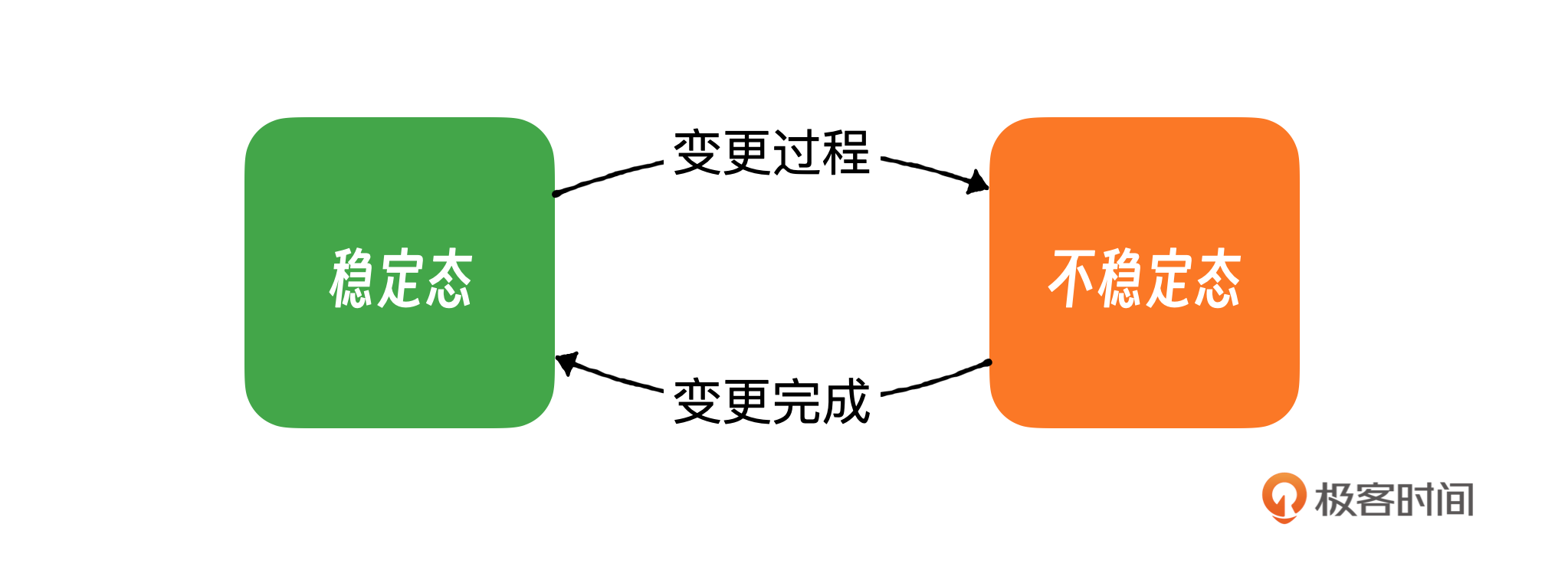
发版是一种非常常见的变更场景,我们前面也提到过,变更的本质就是打破稳态。在日常工作中,任何形式的变更,在变更过程中都可能让一个系统从稳定状态转变为不稳定状态。而系统处于不稳定状态的时候,正是故障最容易发生的时刻。其次,变更的来源广泛,发生频率高,形式多样,涵盖软件更新、配置调整、硬件升级等类型。
我们如何解决变更带来的问题呢?
这里我们从多个视角来反思一下。
应用程序视角
首先是应用程序视角,也就是CrowdStrike视角,问题的源头。 这里最重要的解决方案还是要进行分级发布。
变更前充分评估、准备:包括充分的测试,影响评估,以及回滚方案的制定。这次可以明显看到测试不充分的问题,这种严重的Bug在测试阶段一定是能发现的。
变更时分级发布:分级发布是一种非常有效的应对变更风险的策略,目的是将变更可能引起的风险最小化。
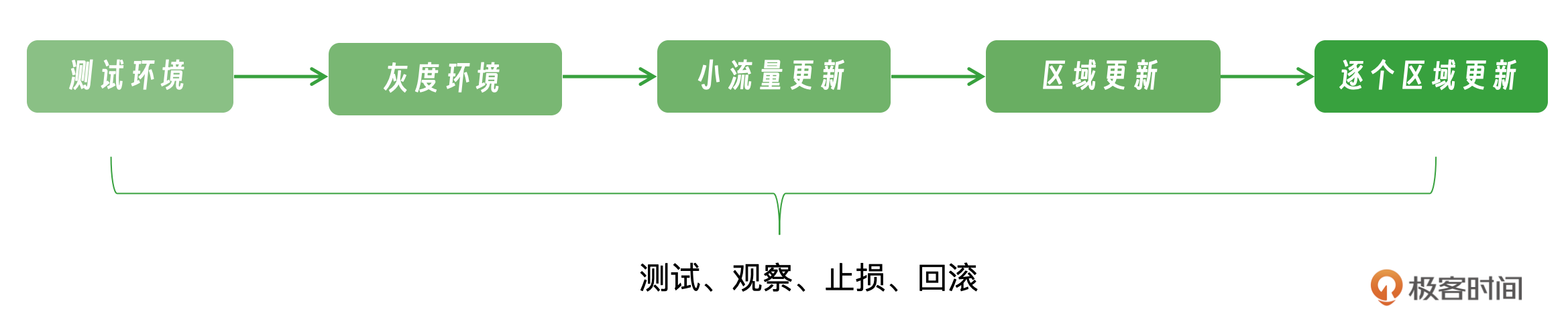
在实施线上变更时,将整个变更过程细化为若干阶段,每个阶段针对特定的服务实例或可用区进行操作。比如这次发布可以按照灰度环境(比如内部用户)->小流量用户->某个地区->逐个地区这样的顺序来更新。
每个阶段之间要进行严格的变更检测。比如用户反馈,是否存活,可用性、延迟、资源消耗等等。一旦有问题就需要进行变更干预,快速阻断当前的变更,并且回滚操作,但是这次故障我们可以看到程序是不能回滚的。这次故障我们看到它只能升级,没法回滚,不仅自己挂了,而且影响到了其他程序。这就要求应用程序自己必须能进行热更新和热回滚。也就是保证其中最根本的主进程无论如何都不能挂。
操作系统视角
操作系统作为计算机架构的核心基础,其稳定性至关重要。为确保操作系统的健壮性,必须实施几个关键措施。
- 资源隔离与限制:必须对每个程序实施资源使用限制,确保它们不会长时间占用CPU等关键资源。除非用户明确允许,否则系统应具备自动终止资源滥用程序的能力,以保障系统资源不被单一应用程序所独占。
- 关键程序保护:所有应用程序都应设计为不能干扰系统的核心功能,包括开机和启动过程。一旦发现任何应用程序影响这些基础操作,系统应立即终止该程序,以维护系统的基本运行。
- 异常检测与自我保护:操作系统需要具备自我检测功能,能够识别并立即终止异常程序。此外,应建立一个安全模型,该模型在安全模式下仅运行最基本的服务和程序,确保系统在面对潜在威胁时仍能稳定运行。
比如在本次的案例中,操作系统已经陷入了自动修复死循环状态,这个时候操作系统是应该及时把相关的应用程序进行降级和隔离。比如找出CrowdStrike相关的程序及时跳过或者终止,把最大的影响局限在这个程序无法启动和运行,而不是让系统直接崩溃。这一点也是Windows在健壮性和容错性上的缺失。
企业视角
对于政府、医院、航空航天等关键企业,我们必须制定周全的应急计划,确保在技术系统发生故障时,能够迅速切换到原始的人工操作模式。这种预案至关重要,它保障了即便在系统崩溃的情况下,关键业务流程仍能持续运作,从而避免造成整个组织的停摆。如果企业这方面内容做得好,那么Windows出现故障的时候,就不至于完全瘫痪了。
- 建立冗余系统:确保关键功能有备份系统支持,实现无缝切换。当然这对于一些关键企业是非常重要的,我们需要一个基本的备份系统。比如除了Widows之外是否有mac/Linux等系统。
- 培训员工和演练:定期对员工进行培训,使其熟悉系统故障时的手动操作流程。通过模拟故障情况,定期测试应急预案的有效性,确保在真实情况下能够迅速响应。
- 数据和恢复:确保所有关键数据都有备份,以防止数据丢失对业务造成的影响。建立快速恢复流程,一旦系统恢复,能够立即重新同步数据和操作。
在这次7月19日的微软蓝屏事件中,CrowdStrike的软件更新无疑成为了一个重要的教训。它提醒我们,无论是软件开发商还是企业用户,都需要对软件更新和系统变更持有更加谨慎的态度。通过这次事件,我们学到了以下几点:
- 变更管理的重要性:任何软件或系统的更新都应经过严格的测试和评估,以确保其稳定性和安全性。
- 分级发布策略:通过逐步推出更新,可以最小化潜在的风险,并在问题发生时快速响应。
- 系统健壮性:操作系统和应用程序都需要设计有自我检测和异常处理的能力,以抵御可能的故障。
- 应急预案:企业和组织应该制定详尽的应急计划,包括数据备份、员工培训和冗余系统建设,确保在技术故障发生时能够快速恢复业务。
随着技术的不断进步,我们依赖的系统越来越复杂,这就需要我们在享受技术带来的便利的同时,也要准备好应对可能的挑战。这次事件虽然给全球许多企业和个人带来了不便,但它也是一个宝贵的学习机会,让我们在未来能够更好地管理技术风险,保障业务的连续性和稳定性。
最后,让我们以这次事件为鉴,不断提高我们的技术管理水平,加强风险意识,共同构建一个更加安全、可靠的数字世界。只有这样,我们才能确保技术进步真正成为推动社会发展的积极力量。