导学 如何构建坚不可摧的服务可靠性体系?
你好,我是白园。这节课我来带你俯瞰整个服务可靠性保障体系,让你在脑海里先有一个课程的全貌。
我们都知道,在这个数字化的时代,服务的每一次中断都可能成为企业声誉的致命伤。想象一下,当用户点击刷新,却只看到一片空白,那种失望和信任的流失是任何营销策略都难以挽回的。服务可靠性,这个看似技术性的问题,实则关乎企业的生存与发展。但如何确保服务的稳定运行,避免那些令人头疼的故障和中断呢?
这就需要我们从各个层次去建设我们的服务可靠性体系了,这里我梳理了一张服务可靠性的全景图,在后面的课程中我会分层次给你介绍每个部分的作用和建设意见。
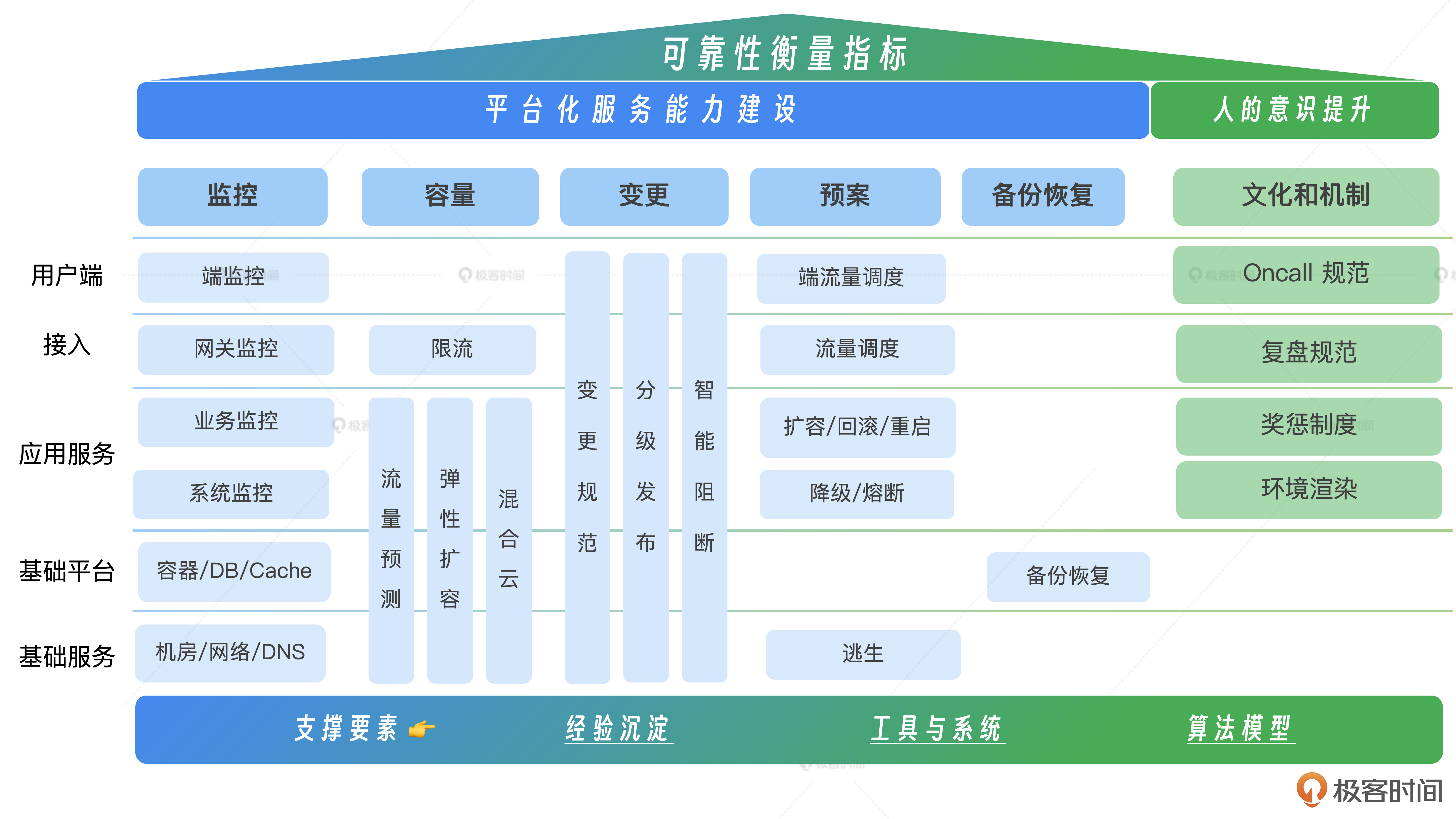
通过这张全景图可以知道想要做好服务可靠性保障建设,我们需要重点关注三个问题。
- 如何衡量服务的可靠性,指标体系是什么?
- 应该重点考虑并建设哪些环节?
- 支撑可靠性保障体系持续完善的几个要素是什么?
如何去衡量一个服务是否稳定?
首先我们可以思考一个问题,如何去衡量一个人是否健康。最直接的衡量标准就是看一个人是否生病,生病的严重程度,以及生病的频率。但是仅仅看生病是远远不够的,我们还需要衡量身体内的各项指标,比如血糖、血脂、血压等等。
其实这就和衡量一个系统是否有问题是一个道理;我们不仅要看结果指标,是否有故障,有异常;更要细化到每个层级去看系统指标。结果指标就是最终的影响和损失;系统指标就是内在的各个子领域的衡量维度。具体的指标我用一张图表示出来了,你可以看一下。
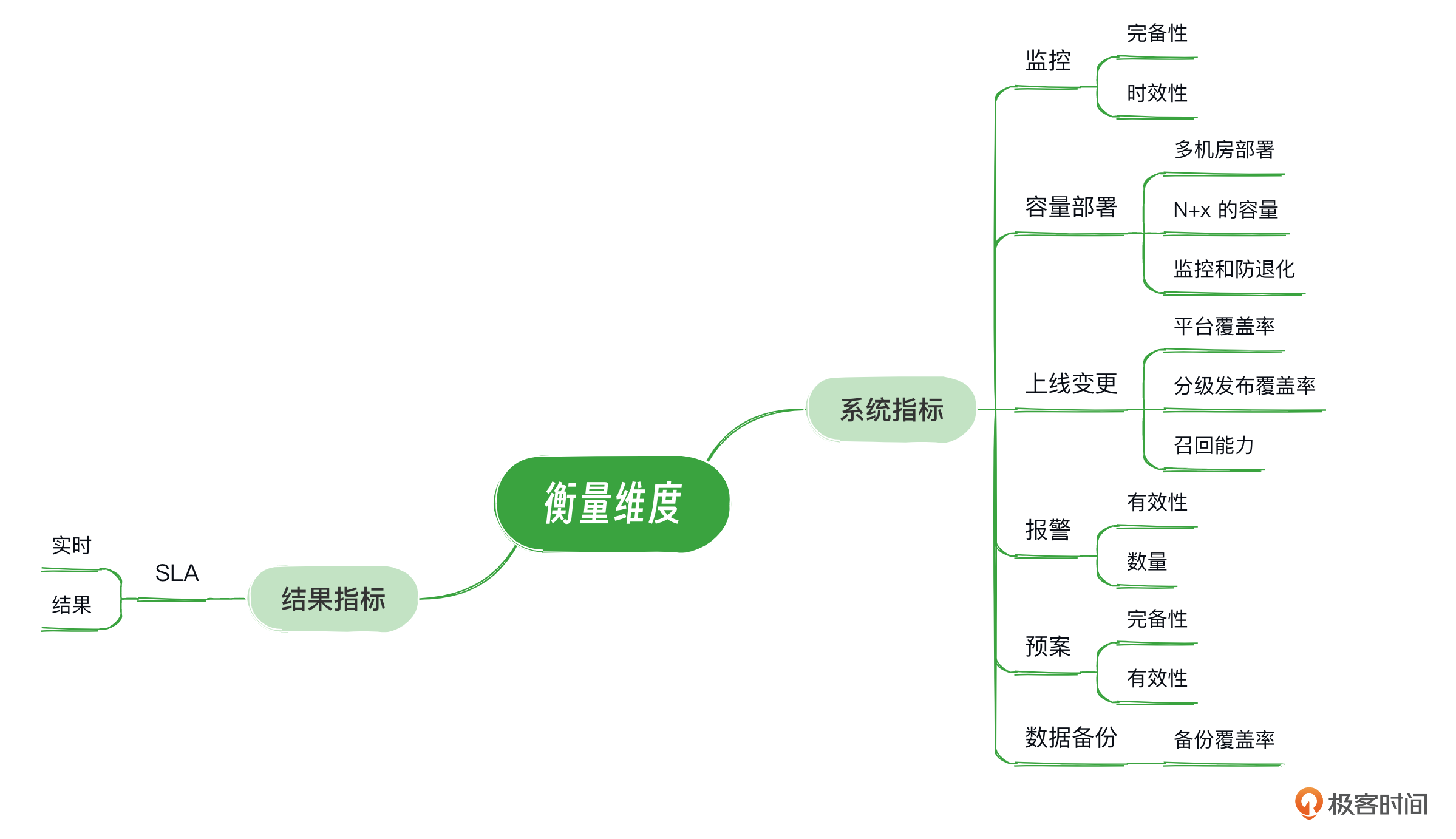
在结果指标中,一个清晰定义的SLA(Service-Level Agreement,服务级别协议)对于问题诊断和解决至关重要,而一个模糊的SLA则可能导致问题处理和优化的困难。图中我列出了两种SLA定义方式。
- 实时性SLA:这种定义侧重于服务的实时性能,通常用公式 $1-丢失pv/总pv$ 来表示。这里,我们更关注PV丢失的数量,它包括网页丢失、5xx错误等非正常返回的情况。
- 结果导向SLA:这种定义通过最终的故障影响来衡量,例如,如果一个季度内没有发生任何故障,那么SLA为100%。如果发生了一次故障,导致100PV的损失,那么可以把SLA定位为 $1-100pv/总pv$。如果第二次故障的损失为200PV,那SLA更新为 $1-100pv/总pv-200pv/总pv$。
这两种定义方式并没有绝对的优劣之分,因为它们适用于不同的业务场景。例如,对于网盘服务的上传和下载,实时性SLA可能更适用,因为它以操作次数为衡量标准。而对于短视频平台如快手和抖音,实时性SLA可能不适用,因为即使出现故障,用户仍然可以看到视频,只是推荐的视频可能用户不感兴趣。在这种情况下,事后的结果导向SLA可能更加合适。
但仅仅依赖结果指标来评估系统稳定性是不够的。这种做法可能会导致我们陷入一个误区:如果一个系统在一段时间内没有进行任何变更,业务流量也保持平稳,表面上看似稳定,实际上可能隐藏着许多隐患。这样的系统可能无法承受一次新的上线或流量的突然增加。关键问题可能无法被及时发现,从而导致潜在的风险和故障。接下来我们看一下如何定义和选择系统指标。
- 监控指标:关注召回率和时效性,确保能够迅速准确地识别问题。
- 报警系统:重视报警的准确率和数量,避免误报和漏报,同时控制报警的频率,以免造成警报疲劳。
- 变更管理:实施分级发布策略,提高覆盖率,确保变更的平滑过渡和风险控制。
- 容量规划:评估系统的容量水位能力,确保在高负载下仍能保持性能。
- 应急预案:提高预案的有效率,并通过定期演练来验证其有效性,确保在紧急情况下能够迅速响应。
- 数据备份:确保备份的覆盖率,保障数据的安全性和可恢复性。
通过这些多维度的指标,我们可以更全面地理解和管理系统的健康状况,及时发现并解决潜在问题。指标定义清楚之后,我们就需要按照定义的指标进行相关的建设,接下来来看从哪些环节和领域去进行重点建设。
我们应该重点建设哪些环节?
根据我开头给出的服务可靠性全景图,我们可以从一纵一横两个维度进行思考。
纵向维度:我们先回顾一下2023年的经典故障分布。故障主要分布在客户端、接入层、业务服务、基础服务、基础平台/服务、基础设施各个层级。比如基础设施层唯品会和腾讯的机房故障、广东电信的网络故障。这些层级是需要我们特别关注的。

横向维度:依次是监控、容量、变更、预案、备份、机制,这是我结合多年工作经验和实际案例划分出来的。为什么要这么划分呢?
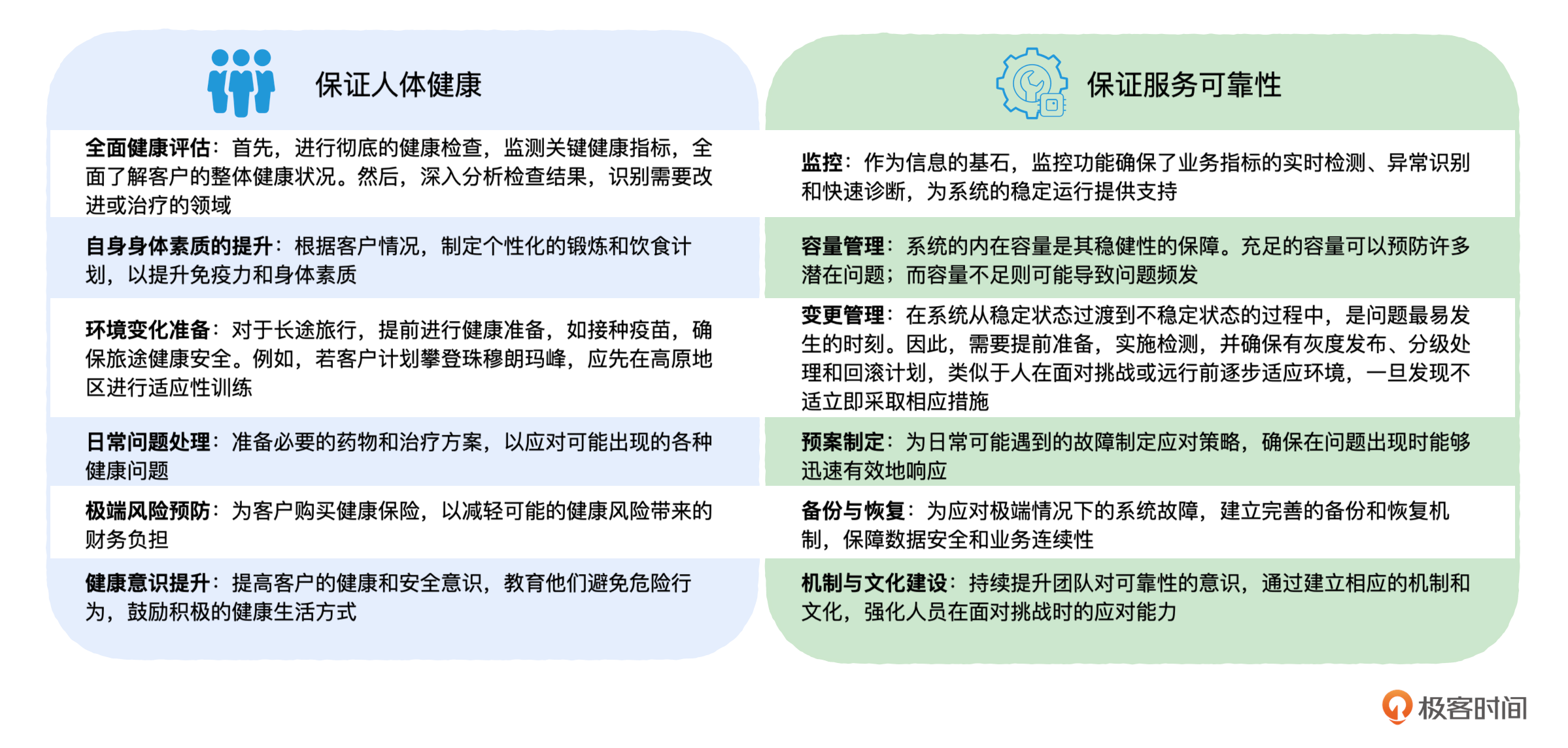
就像之前说的,我们可以把服务的可靠性比作人体健康的维护,那么监控(全面检查)、容量管理(日常锻炼)、变更管理(应对环境变化)、制定预案(常见问题处理)、备份与恢复(预防极端风险),还有机制与文化建设(健康意识)都必不可少。
如何让可靠性体系持续完善?
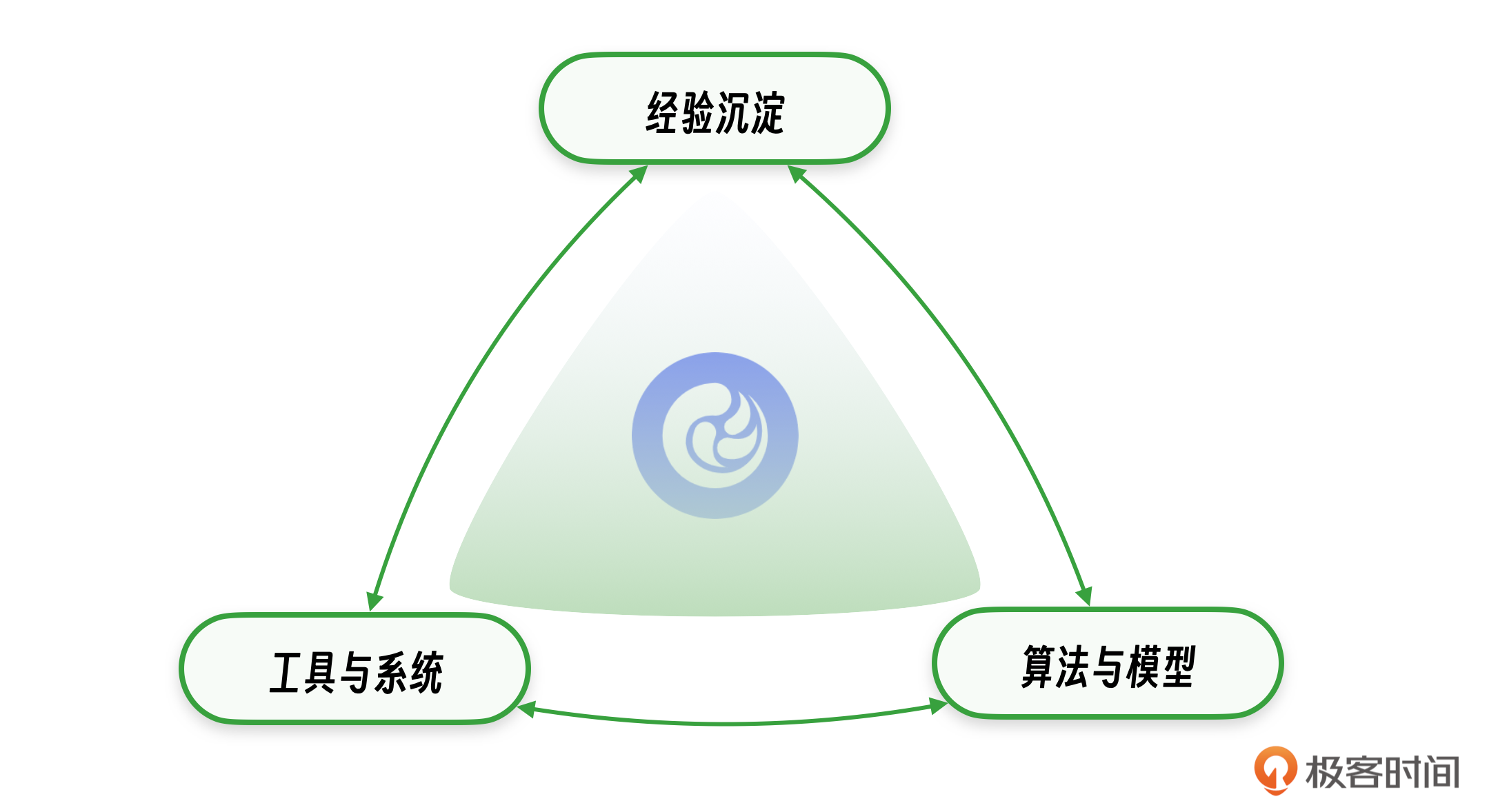
首先,我们应当重视经验的积累与传承。在不同的业务领域、系统架构和应用场景中,定位逻辑往往存在显著差异。资深工程师与新手工程师在问题解决能力上的差异尤为明显。因此,我们的主要目标是将这些宝贵的经验沉淀下来。以系统监控为例,我们需要明确监控的设置方法,深入考虑监控的关键维度,确保监控系统能够全面、有效地反映系统运行状态。
其次,我们需要关注工具和系统的重要性。工欲善其事,必先利其器,要提升系统的可靠性和保障能力,就必须依靠先进的工具和系统作为支撑。以系统监控为例,不同的监控工具在数据可视化、展示方式、数据丰富度以及操作便捷性等方面存在显著差异。一个优秀的监控系统能够显著提高故障检测的效率,从而快速响应并解决问题,确保业务的连续性和稳定性。
第三,我们应重视数据和模型在服务可靠性中的核心作用。在人工智能技术日益普及的今天,服务的可靠性越来越依赖于算法和模型的支持。我们需要将传统的被动人工判断和决策转变为主动的机器判断和决策。通过持续地将经验转化为算法模型,我们可以使模型更加智能和强大,从而减少因个人经验差异导致的效率和准确性的差异,实现服务的高效和稳定。
小结
这节课我带你学习了如何衡量一个系统是否稳定,通过一纵一横来解释背后的逻辑,纵向来看包括客户端、接入层、服务层、基础服务和平台层、基础设施层。横向来看包括监控、容量、变更、预案、备份、机制六个维度。接下来的课程我们以横向视角重点介绍这六个维度。
此外,你要知道可靠性保障不局限于特定领域,它是工程师职业生涯中的一项核心技能,对SRE、研发、测试、算法等各个领域的工程师都至关重要。它要求我们不仅要关注技术细节,还要具备全局视野和前瞻性思维,而这节课就是为了让你具备可靠性保障的全局视角而设置的,你可以自己梳理一下所负责的业务,画一张服务可靠性的全景图出来,后面我们再一点一点地完善它。
思考题
可靠性全貌其实远不止这些,你还有哪些好的经验,欢迎分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
分享几条可靠性保障关键法则

- 熊 👍(2) 💬(1)
感觉还缺少故障演练部分,演练是对预案部分是否有效的闭环监测
2024-08-15 - 刺猬 👍(0) 💬(2)
什么是PV
2024-07-20 - 小猪猪猪蛋 👍(0) 💬(0)
做实事、有价值的事、长期的事
2024-10-02 - 不会爬树的熊 👍(0) 💬(0)
果然精品!期待永久更新
2024-07-19 - 八渡 👍(0) 💬(0)
做实事、有价值的事、长期的事
2024-07-18