16 集群状态观测与查看日志
你好,我是雪飞。
上节课,我带你给集群中的 Pod 容器增加了探针配置,以及资源请求和资源限额配置,从而保障我们的应用运行得更加平稳,但是,在实际项目中,我们仍然可能会遇到一些集群或者应用故障。今天我就给你介绍一些在 K8s 集群中常用的方法,来查看集群资源消耗情况、资源对象详细信息以及查看 Pod 容器和集群组件日志,帮助你快速定位和解决问题。我们先来了解一下如何统计集群资源消耗情况。
资源消耗统计
在硬件集群的日常运维过程中,我们通常需要关注各个服务器的资源使用情况,如 CPU、内存、磁盘和网络等,这些信息可以通过一些软件(例如 Prometheus)采集并展示出来,方便运维人员了解到集群的整个状态。
在 K8s 容器集群中,我们也需要关注节点和 Pod 的运行情况,所以 K8s 提供了 “kubectl top” 命令,可以查看节点和 Pod 的 CPU 和 内存消耗情况。不过在使用 “kubectl top” 命令之前,需要先安装 Metrics Server 服务。
认识 Metrics Server
Metrics Server 作为一个独立的组件部署运行在 K8s 集群中,专门负责收集和提供集群资源使用情况的相关指标(Metrics),这些指标包括对 CPU、内存使用情况的监控。它的实现原理如下图:
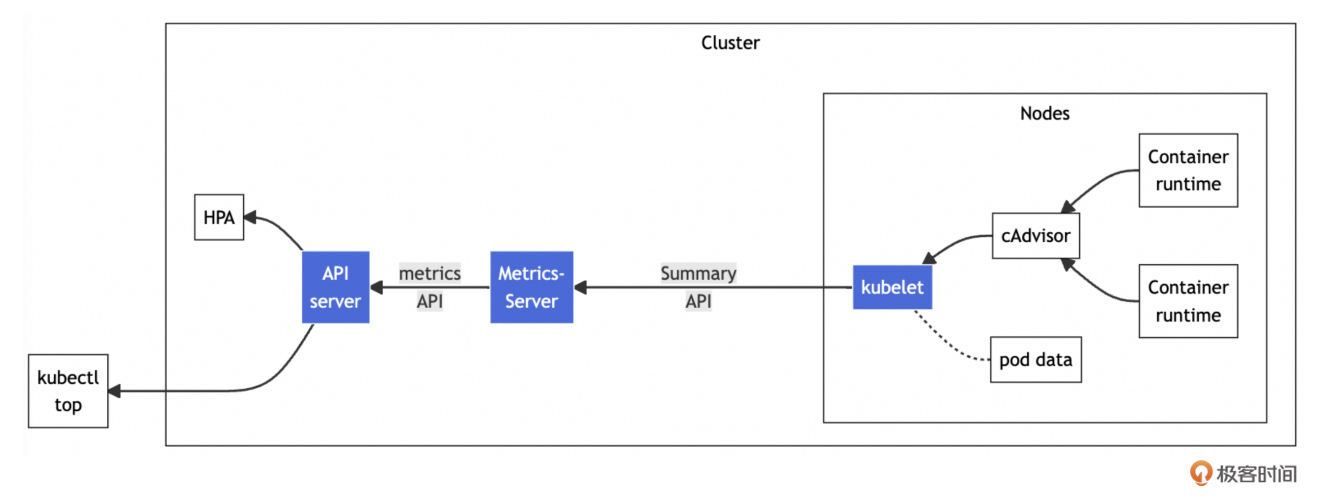
Metrics Server 在 API Server 系统组件中注册并提供自定义的 Metrics API,这样,其他集群内外组件就能够调用 Metrics API 来获取访问节点和 Pod 的 CPU 和内存使用数据。例如 K8s 的资源对象 HPA(Horizontal Pod Autoscaler,Pod 水平自动扩缩容)就是根据 Metrics Server 提供的 Pod 的资源消耗数据来自动调整 Pod 的副本数量。
Metrics Server 定期从集群各节点的 Kubelet 获取指标数据,这些数据来源于节点上的 cAdvisor 组件,K8s 安装时默认在各个节点上安装了 cAdvisor,它是一个守护应用,用于采集和聚合节点上容器的资源使用数据。这些数据存储在节点服务器内存中,没有持久化到磁盘,因此 Metrics Server 不会保持历史数据,它能保持高性能和低延迟。
安装 metrics-server
下面我们来动手安装 metrics-server 组件,你可以在 GitHub 上看到 Metrics Server 项目地址。
首先,我们要下载 metrics-server 的部署 YAML 文件,这里我使用 V0.6.2 版本。
其次,修改下载下来的 components.yaml 文件,文件中一共有 3 个地方需要修改。
- Pod 中增加属性 “hostNetwork: true”。
- 容器中增加一个运行参数 “ --kubelet-insecure-tls”(因为 Metrics Server 默认使用 TLS 协议,加这个参数可以不验证 HTTPS 证书)。
- 将镜像修改为国内可以下载的镜像。
修改具体位置参考下面的代码:
# 编辑 components.yaml 部署文件
[root@k8s-master ~]# vim components.yaml
...
132 spec:
133 hostNetwork: true # 增加配置
134 containers:
135 - args:
136 - --cert-dir=/tmp
137 - --secure-port=4443
138 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
139 - --kubelet-use-node-status-port
140 - --metric-resolution=15s
141 - --kubelet-insecure-tls # 增加参数
142 # image: k8s.gcr.io/metrics-server/metrics-server:v0.6.2
143 image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.2 # 替换镜像
144 imagePullPolicy: IfNotPresent
...
然后,通过 “kubectl apply” 命令部署 YAML 文件。然后查看 metrics-server 的 Deployment 资源对象来确认部署成功。
[root@k8s-master ~]# kubectl apply -f components.yaml
serviceaccount/metrics-server unchanged
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader unchanged
clusterrole.rbac.authorization.k8s.io/system:metrics-server unchanged
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader unchanged
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator unchanged
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server unchanged
service/metrics-server unchanged
deployment.apps/metrics-server configured
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io unchanged
[root@k8s-master ~]# kubectl get deployment metrics-server -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 1/1 1 1 10d
最后,验证 Metrics Server 是否可以获取指标数据,执行以下命令,如果返回状态是 “True” 表示 Metrics Server 部署成功。
[root@k8s-master ~]# kubectl get apiservices | grep metrics # 返回状态是 True
v1beta1.metrics.k8s.io kube-system/metrics-server True 10d
使用 metrics-server
Metrics Server 部署成功后,你就可以使用 “kubectl top” 命令查看节点和 Pod 的资源消耗情况。返回结果中包含两个指标:CPU 和内存。
[root@k8s-master ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 127m 6% 2510Mi 69%
k8s-worker1 99m 4% 1288Mi 67%
k8s-worker2 117m 5% 1336Mi 70%
[root@k8s-master ~]# kubectl top pod -n kube-system
NAMESPACE NAME CPU(cores) MEMORY(bytes)
kube-system etcd-k8s-master 19m 333Mi
kube-system kube-apiserver-k8s-master 57m 434Mi
kube-system kube-controller-manager-k8s-master 8m 82Mi
kube-system kube-scheduler-k8s-master 2m 65Mi
kube-system metrics-server-7f676b86dc-9lpsb 3m 43Mi
通过 Metrics Server 你可以随时掌握集群中节点和 Pod 的资源消耗情况,及时发现占用资源过大的节点和 Pod,分析资源消耗原因,从而合理调整资源分配与调度策略,确保 Pod 中应用的流畅运行。一般来说,集群节点 CPU 和内存使用率超过了80%,你就需要排查一下具体原因,检测资源消耗量大的 Pod 或者增加节点硬件配置和数量来降低集群压力。
查看资源对象信息
有时,当你部署完资源对象,你会发现资源对象并没有正常生效,这种情况就需要查看一下资源对象的状态和相关信息。
查看资源对象的命令,我们在之前的课程中已经用到过很多次,查看列表和查看详情这两条命令十分常用,遇到任何问题你可以先用这两条命令查看一下资源对象,返回结果中包括名称、创建时间、状态、配置信息、事件等,可以帮助你全面了解各种信息,这样就能快速找到问题。
这里,我再带你回顾一下这两条命令的用法。
# 查看资源对象列表
kubectl get <资源对象类型> [-n <namespace 名称>] [-A] [-o wide] [--show-labels]
# 查看资源对象详情
kubectl describe <资源对象类型> <资源对象名称> [-n <namespace 名称>]
- -n :表示资源对象所在的命名空间,不加这个参数使用默认命名空间 default。
- -A:查看所有命名空间下的资源对象。
- -o wide:查看更详细的信息。
- –show-labels:显示资源对象的标签 Label。
查看 Pod 容器日志
有时,你会发现资源对象的状态都是正常的,但是应用还是一直崩溃或者出现错误,这种情况就需要使用 K8s 提供的容器日志功能来查找应用的问题了。
在 K8s 集群中,日志信息的采集与查看对于保障集群的稳定性、可靠性以及定位问题至关重要。日志作为记录集群组件和应用运行状况的第一手资料,能够帮助你快速找到问题、分析故障原因,从而提高问题解决效率。
工作原理
K8s 可以从正在运行的 Pod 中捕捉每个容器的日志。容器运行时(Container Runtime)组件负责处理和转发容器中应用的 stdout 和 stderr 流的所有输出信息。不同的容器运行时组件都提供了标准的 CRI 集成接口,kubelet 使用 CRI 接口将日志配置信息发送到容器运行时,而容器运行时按照配置要求将容器的日志保存到指定的目录中。
logrotate 是 Linux 系统上的日志管理工具,用于自动管理日志文件的大小和生命周期。它可以定期地重命名、压缩、删除旧的日志文件,并创建新的日志文件,以避免日志文件无限制地增长导致磁盘空间不足。
K8s 组件与 logrotate 工具共同协作,负责容器日志的管理和轮换。在容器化环境中,由于容器可能会被重启或重建,使用 logrotate 来管理日志文件尤为重要。这确保了即使容器生命周期结束,日志数据也不会丢失。
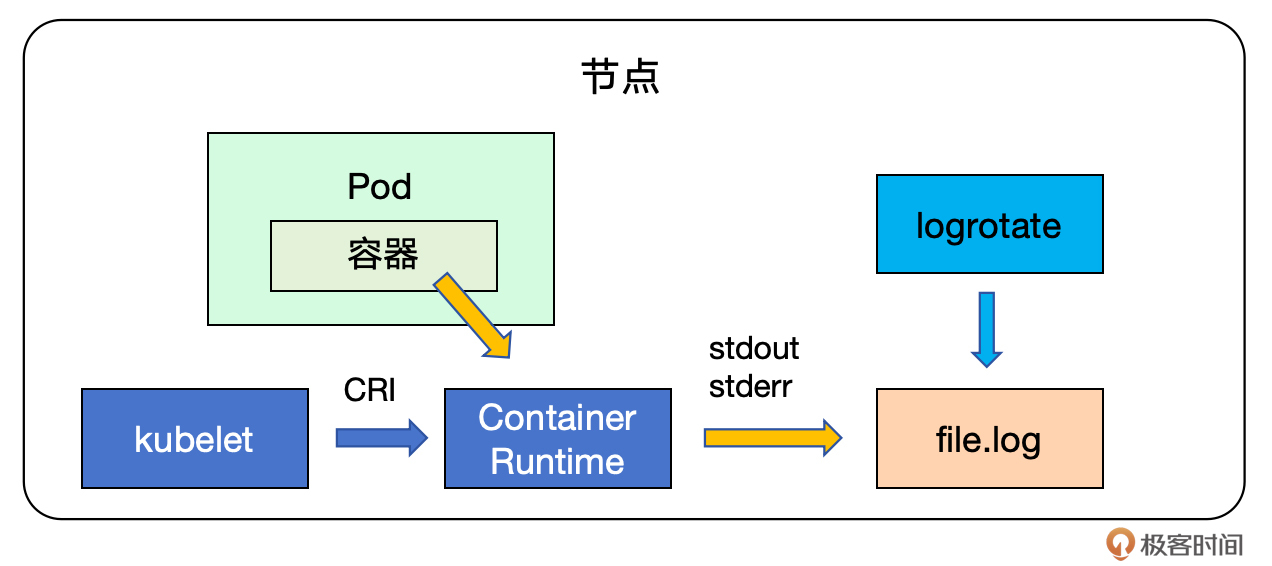
查看 Pod 容器日志
了解了获取容器日志的过程,我们现在就来尝试一下两种查看日志的方式:一种是使用 “kubectl logs” 命令,另一种是直接查看日志文件。
注意:由于 K8s 的系统组件也是通过静态 Pod 部署在集群中,所以查看容器日志也可以查看到这些组件的输出日志,例如集群的 Scheduler 调度器、API Server 组件、Controller Manager 组件等。
1. 使用 “kubectl logs” 命令
使用 “kubectl logs” 命令时,节点上的 kubelet 会处理请求,并直接从日志文件中读取日志内容返回。
kubectl logs [-f] <Pod名称> [-c <容器名称>] [-n <命名空间>]
kubectl logs --tail <查看行数> <Pod名称>
kubectl logs -l <key=value>
- -f:表示实时跟随日志输出,可以使用 Ctrl + C 键盘快捷键来终止命令。
- -c:表示如果 Pod 中有多个容器,需要通过 -c 指定容器。
- –tail:表示查看多少行日志,后面行数是一个整数,例如 --tail 200。
- -l:表示查看标签为“ key:value” 的所有 Pod 的合并日志。
我们动手部署一个 Pod 来测试容器日志功能,该 Pod 中包含一个 busybox 容器,每 5 秒输出一条打印语句。Pod 的 YAML 文件(my-count-log-pod.yaml)如下:
# my-count-log-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-count-log-pod
spec:
containers:
- name: count-c
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 5; done']
部署 Pod,然后查看 Pod 日志,可以看出日志中每隔 5s 输出一条打印语句,这说明了 K8s 的Pod 容器日志获取到了应用中的打印输出语句。
[root@k8s-master ~]# kubectl apply -f my-count-log-pod.yaml
pod/my-count-log-pod created
[root@k8s-master ~]# kubectl logs -f my-count-log-pod
0: Tue Jul 2 13:45:00 UTC 2024
1: Tue Jul 2 13:45:05 UTC 2024
2: Tue Jul 2 13:45:10 UTC 2024
3: Tue Jul 2 13:45:15 UTC 2024
2. 直接在节点上查看日志文件
我们也可以在节点上查看日志文件,先查看 Pod 部署所在的节点。
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-count-log-pod 1/1 Running 0 4m20s 10.244.194.88 k8s-worker1 <none> <none>
然后,我们远程连接 Pod 所在的 k8s-worker1 节点,并在 “/var/log/pods/” 目录下找到相应的 Pod,从而使用 “tail” 命令查看其日志。
[root@k8s-worker1 ~]# cd /var/log/pods/
# 进入更深的目录层级,可以看到日志文件 0.log
[root@k8s-worker1 count-c]# tail -n 5 0.log
{"log":"103: Tue Jul 2 13:53:35 UTC 2024\n","stream":"stdout","time":"2024-07-02T13:53:35.562096124Z"}
{"log":"104: Tue Jul 2 13:53:40 UTC 2024\n","stream":"stdout","time":"2024-07-02T13:53:40.562869416Z"}
{"log":"105: Tue Jul 2 13:53:45 UTC 2024\n","stream":"stdout","time":"2024-07-02T13:53:45.56417172Z"}
{"log":"106: Tue Jul 2 13:53:50 UTC 2024\n","stream":"stdout","time":"2024-07-02T13:53:50.564846585Z"}
{"log":"107: Tue Jul 2 13:53:55 UTC 2024\n","stream":"stdout","time":"2024-07-02T13:53:55.566009871Z"}
集群级日志方案
虽然 K8s 提供了查看容器日志的方式,但是毕竟日志文件都还在各个节点上,比较分散,而且使用命令查看大量日志,体验并不友好,也无法实现快速检索。所以出现了很多开源的日志解决方案,我比较常用的是 Loki,它是一种轻量级的日志聚合系统,可以处理大规模容器日志数据。
Loki 是由 Grafana 实验室开发,非常适合与 K8s 环境集成,能够收集容器和集群的日志信息,将日志数据存储在远程的、可扩展的存储系统中,同时提供了强大的查询语言 LogQL,允许你进行复杂的日志查询和聚合操作,而且它与 Grafana 紧密集成,提供日志数据的可视化和分析工具。这里我就不再展开讲了,有兴趣可以查看网上资料部署一套 Loki 日志系统。
查看 kubelet 日志
最后,如果集群某个节点无法运行,你就要查看一下节点上 kubelet 组件的日志。
kubelet 直接安装在集群的所有节点上,是 K8s 在各个节点上的“管理员”。因此,查看每个节点上的 kubelet 服务日志非常重要。由于 kubelet 并不像其他组件一样通过静态 Pod 运行在集群中,所以我们不能通过查看 Pod 容器日志的方式查看 kubelet 组件日志,而是使用 “journalctl” 命令查看 kubelet 日志。
journalctl 是一个 Linux 系统上用来查看系统应用服务日志的命令,它需要在查看日志的节点上执行。
# 在节点上执行命令,来查看该节点的kubelet日志
[root@k8s-master ~]# journalctl -u kubelet
-- Logs begin at Sat 2024-06-15 15:48:31 CST, end at Tue 2024-07-02 19:29:45 CST. --
Jun 15 16:48:24 k8s-master systemd[1]: Started kubelet: The Kubernetes Node Agent.
Jun 15 16:48:24 k8s-master kubelet[16953]: Flag --container-runtime-endpoint has been deprecated, This parameter should be set via the
Jun 15 16:48:24 k8s-master kubelet[16953]: Flag --pod-infra-container-image has been deprecated, will be removed in a future release.
Jun 15 16:48:24 k8s-master kubelet[16953]: I0615 16:48:24.055239 16953 server.go:203] "--pod-infra-container-image will not be prune
Jun 15 16:48:24 k8s-master kubelet[16953]: I0615 16:48:24.268231 16953 server.go:467] "Kubelet version" kubeletVersion="v1.28.0"
......
# 倒序排列日志
[root@k8s-master ~]# journalctl -u kubelet -r
-- Logs begin at Sat 2024-06-15 15:48:31 CST, end at Tue 2024-07-02 19:29:45 CST. --
Jun 15 16:48:24 k8s-master systemd[1]: Started kubelet: The Kubernetes Node Agent.
Jun 15 16:48:24 k8s-master kubelet[16953]: Flag --container-runtime-endpoint has been deprecated, This parameter should be set via the
Jun 15 16:48:24 k8s-master kubelet[16953]: Flag --pod-infra-container-image has been deprecated, will be removed in a future release.
Jun 15 16:48:24 k8s-master kubelet[16953]: I0615 16:48:24.055239 16953 server.go:203] "--pod-infra-container-image will not be prune
Jun 15 16:48:24 k8s-master kubelet[16953]: I0615 16:48:24.268231 16953 server.go:467] "Kubelet version" kubeletVersion="v1.28.0"
......
如果发现 kubelet 出现错误,可以通过 systemctl 命令查看 kubelet 状态并重启 kubelet 组件。
# 查看 kubelet 状态
[root@k8s-master ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Thu 2024-07-04 13:57:34 CST; 21h ago
Docs: https://kubernetes.io/docs/
......
# 重启 kubelet
[root@k8s-master ~]# systemctl restart kubelet
小结
今天,我给你介绍了几个在 K8s 集群中查看集群资源消耗状态、查看资源对象以及查看容器及组件日志的方法,帮助你初步判断和快速解决集群使用过程中遇到的各种问题。
首先,了解了用于集群资源消耗统计的 Metrics Server 服务,它可以采集集群中节点和 Pod 的资源使用指标数据,主要是 CPU 和内存数据,这样你就可以及时发现占用资源过大的节点和 Pod,分析资源消耗原因,从而确保应用 Pod 的流畅运行。我们动手安装了 metrics-server ,然后使用 “kubectl top” 命令来查看节点和 Pod 的资源消耗情况。
其次,我带你回顾了 “kubectl get” 和 “kubectl describe” 命令,这两个命令非常常用,可以查看资源对象列表和详情,帮助你全面了解各种信息,这样就能快速找到问题。
最后,我给你介绍了查看集群中两种日志的方法,对于容器日志,不管是自己部署的应用 Pod,还是 K8s 的系统组件 Pod,都可以使用 kubectl logs 命令来查看容器日志。对于直接安装在节点上的 kubelet 组件,则需要使用 journalctl 命令查看系统服务日志,如果发现 kubelet 组件出错,可以使用 “systemctl restart kubelet” 命令来直接重启 kubelet。
思考题
这就是今天的全部内容,在 CKA 中也会考到相关的知识点。我给你留一道练习题。
创建三个 Nginx 镜像的 Pod,设置为 “app=web” 标签,然后再通过 top 命令找到这三个 Pod 中使用 CPU 最高的 Pod。
相信经过动手实践,会让你对知识的理解更加深刻。