15 Pod探针与服务质量QoS
你好,我是雪飞。
前两节课我带你了解了集群的安全策略,K8s 通过 RBAC 权限控制有效应对了外部访问风险,并且通过网络策略控制 Pod 的出入口流量,从而应对了内部访问风险。这节课我们讨论如何保障 K8s 集群中应用的稳定性,由于应用是以 Pod 的方式部署在集群中,所以 K8s 稳定性的策略主要是针对 Pod。
我给你介绍保障 Pod 稳定性最常用的两种方式,一种是 Pod 探针,另一种是 Pod 的资源请求和限制。
Pod 探针
你一定见过心电监测设备吧,在病人身上贴上几个电极来检查心跳情况,从而了解病人的健康状况。K8s 提供的 Pod 探针也有类似的功能,只不过它的监测对象是集群中的 Pod。Pod 探针通过定期检查 Pod 容器的存活和就绪状态,从而监测 Pod 容器的健康情况。对于不健康的 Pod 容器,可以根据策略自动重启、替换,或者移出 Service 的代理列表,确保应用的稳定性和可靠性,大大减轻了运维人员的工作量。
探针种类
针对 Pod 容器启动和运行过程,K8s 提供了 3 种类型的探针。
- 启动探针(Startup Probes):启动探针用于确定容器是否已经完全启动。在容器启动期间,启动探针进行探测,如果探测失败,K8s 会认为容器启动失败,并根据重启策略进行重启。在启动探针探测成功之前,其他类型的探针都会暂时处于禁用状态。启动探针一旦检测成功,就停止了。这主要适用于容器启动时间较长的场景。
- 就绪探针(Readiness Probes):就绪探针用于确定容器是否已经准备好接收访问请求。如果就绪探针探测失败,K8s 会将该容器从 Service 负载均衡的代理列表中清除。如果探测成功,Pod 会进入 READY 状态,并被加入到 Service 的 Endpoints 终端列表中。这确保了只有完全启动并准备好对外提供服务的容器才会接收请求。
- 存活探针(Liveness Probes):存活探针用于确定容器是否正常运行。如果存活探针探测失败,K8s 会认为容器不再健康,并根据容器的重启策略来重启它。这有助于自动恢复那些进入异常状态但未崩溃的容器。
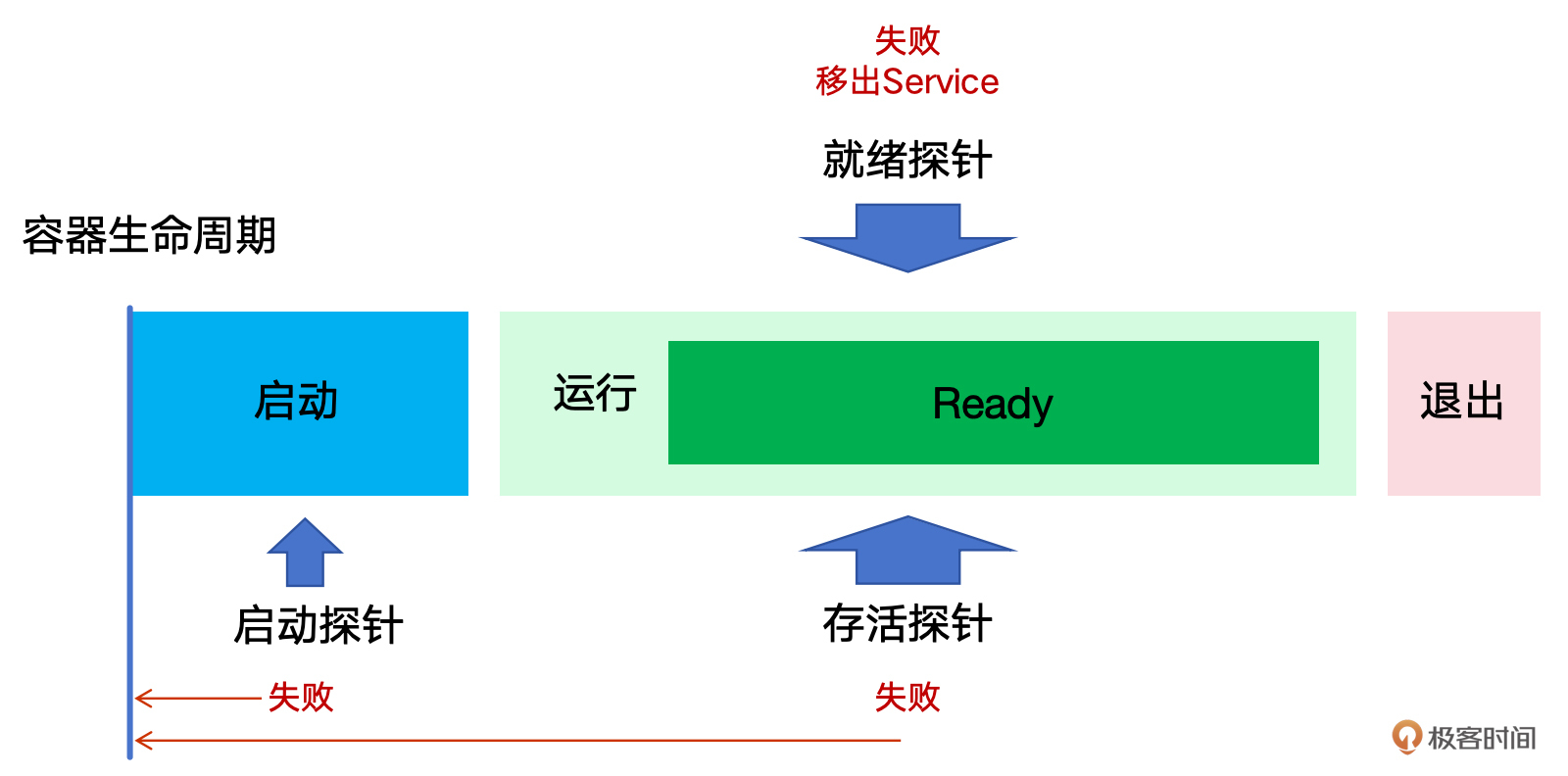
这 3 种探针分别对应 Pod 容器的不同监测场景,可以组合使用,从而提供更全面、更可靠、更精细的容器状态管理策略,满足不同的应用监测需求。
使用探针
下面我来介绍一下如何使用探针。每种探针都定义在 Pod 的 YAML 文件中,通过一组特定的属性来配置探针。其中最重要的属性是探测方式(Probe Type),它有 4 种类型,需要和探测操作(Probe Action)配合使用。
- httpGet:这种类型通过 HTTP GET 请求的方式访问容器中应用对外提供的 API 接口。如果响应的状态码大于等于 200 且小于 400,则认为诊断成功。通常,你可以在应用中专门提供一个简单的 HTTP GET 请求探测接口。
- tcpSocket:这种类型可以对容器的指定端口执行 TCP 检查。如果端口打开,则认为诊断成功。通常,我们会探测容器中应用暴露的端口,TCP 检测的配置和 HTTP 检测非常相似。
- exec:在容器内执行指定命令。如果命令退出时返回码为0,则认为诊断成功。这种方式通常更加简单,比如在运行 Nginx 的容器中检测配置文件是否可以读取成功。
- grpc:使用 gRPC 执行一个远程过程调用。应用需要实现 gRPC 健康检查,这种方式比较少用。
注意:Pod 探针用于检测容器中运行的应用的健康状态。如果一个 Pod 有多个容器,每个容器都可以定义自己的探针。因此,在 YAML 文件中,探针的定义位于容器层级。
下面我们来写一个使用探针的 Pod 的 YAML 文件(my-probe-nginx-pod.yaml),了解探针如何应用。当然探针也可以用在 Deployment 等资源对象的 Pod 模板中。
# my-probe-nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-probe-nginx-pod
spec:
containers:
- name: nginx-c
image: ubuntu/nginx
startupProbe: # 启动探针
exec:
command:
- cat
- /etc/nginx/nginx.conf
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3
readinessProbe: # 就绪探针
httpGet:
path: /
port: 80
initialDelaySeconds: 15
periodSeconds: 10
timeoutSeconds: 3
livenessProbe: # 存活探针
tcpSocket:
port: 80
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
- initialDelaySeconds:指定容器启动后,需要延迟等待多少秒后才启动探针。如果定义了启动探针,则存活探针和就绪探针的延迟将在启动探针成功后才开始计算。默认值和最小值都是0。
- periodSeconds:指定每次执行探测的间隔时间(秒)。默认值 10,最小值 1。
- timeoutSeconds:指定探测超时后等待重试的时间(秒)。默认值 1,最小值 1。
- failureThreshold:指定如果探针连续失败达到多少次,K8s 将认为整体检查失败,即容器的状态为未就绪、不健康或不活跃。
注意:这里 Pod 使用 ubuntu/nginx 镜像,因此,可以进入容器执行 Linux 命令,方便查看探针效果,如果是官方的 Nginx 镜像,里面没有安装 Linux 终端命令。
我们在这个 Pod 中定义了 3 种探针,启动探针使用 exec 命令探测,执行命令查看 Nginx 配置文件;就绪探针使用 httpGet 的方式探测,通过 HTTP 请求获取 Web 服务的首页;存活探针使用 tcpSocket 方式探测,通过检测 Nginx 使用的 TCP 80 端口。
部署 Pod,使用 “kubectl describe” 命令查看 Pod 详情,可以看到 3 个探针已经被加载。
[root@k8s-master ~]# kubectl apply -f my-probe-nginx-pod.yaml
pod/my-probe-nginx-pod created
[root@k8s-master ~]# kubectl describe pod my-probe-nginx-pod
......
Containers:
nginx-c:
......
Liveness: tcp-socket :80 delay=15s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:80/ delay=15s timeout=3s period=10s #success=1 #failure=3
Startup: exec [cat /etc/nginx/aaa.conf] delay=5s timeout=1s period=5s #success=1 #failure=3
......
验证探针
目前这个 Pod 运行正常,探针也在正常工作。我们来修改探针的配置,制造一个探针探测失败的情况,再来观察 Pod 的运行情况。
这里我们修改 Pod 中的启动探针,改成检测一个 Nginx 应用中不存在的文件名,再重新部署一下,查看 Pod 详情。
...
startupProbe: # 启动探针
exec:
command:
- cat
- /etc/nginx/aaa.conf # 不存在的配置文件
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3
...
通过 Pod 详情中的 Events 事件可以看出,启动探针检测失败,三次重试之后,Pod 重启。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 9m23s default-scheduler Successfully assigned default/my-probe-nginx-pod to k8s-worker2
Normal Pulled 8m59s kubelet Successfully pulled image "ubuntu/nginx" in 21.994s (21.994s including waiting)
Normal Pulled 8m27s kubelet Successfully pulled image "ubuntu/nginx" in 15.434s (15.434s including waiting)
Normal Created 7m57s (x3 over 8m59s) kubelet Created container nginx-c
Normal Started 7m57s (x3 over 8m59s) kubelet Started container nginx-c
Normal Pulled 7m57s kubelet Successfully pulled image "ubuntu/nginx" in 15.453s (15.453s including waiting)
Normal Pulling 7m42s (x4 over 9m21s) kubelet Pulling image "ubuntu/nginx"
Warning Unhealthy 7m42s (x9 over 8m52s) kubelet Startup probe failed: cat: /etc/nginx/aaa.conf: No such file or directory
Normal Killing 7m42s (x3 over 8m42s) kubelet Container nginx-c failed startup probe, will be restarted
对于剩余两种探针,httpGet 方式的就绪探针和 tcpSocket 方式的存活探针,就不再演示探测失败的情况。你可以通过类似的方法自行修改 YAML 文件中的探针配置来尝试一下。
使用 Pod 探针是增强应用稳定性的最佳实践之一,它们为容器化应用提供了内置的自我修复机制,确保应用的稳定性和高可用性。接下来,我将带你了解另一种针对 Pod 的配置,以保障集群稳定。
Pod 的资源请求和资源限额
在 K8s 集群中,可以通过为 Pod 中的容器设置资源请求(Requests)和资源限额(Limits),确保 Pod 获得足够的 CPU 和内存资源运行,同时又避免 Pod 消耗过多节点资源从而影响集群中的其他组件。
资源请求指明了 Pod 运行所需的最小资源量,有助于 K8s 的调度器选择合适的节点进行调度。而资源限额定义了 Pod 可以使用的最大资源量,如果超出这些限制,Pod 可能会被系统终止,以保护集群的稳定性。在 K8s 中,你在提交 Pod 时,可以声明一个相对较小的资源请求值供调度器使用,而 K8s 实际为容器分配的 CPU 和内存,则是相对较大的资源限额值。因此,调度时资源请求比较重要,而运行时资源限额比较重要。
使用资源请求和资源限额
我们来动手给一个 Pod 容器配置资源请求和资源限额,资源请求和资源限额也是通过属性定义在 Pod 的 YAML 文件(my-nginx-resources.yaml)中。
# my-nginx-resources-limit.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-nginx-resources-limit
spec:
containers:
- name: nginx-c
image: nginx
resources:
requests:
memory: "256Mi"
cpu: "100m"
limits:
memory: "512Mi"
cpu: "500m"
- cpu:CPU 资源分配的细粒度是通过使用毫核(millicores)来实现的,其中1000 毫核相当于 1 个 CPU 核。例如,100m =100毫核= 0.1个 CPU 核。因此,在一个拥有 4 核 CPU 的节点上,可分配的 CPU 资源总量为4000毫核。
- memory:内存资源通常以字节为单位,如 Ki、Mi 和 Gi。注意, MiB ≠ MB,MB 是十进制单位,即 1MB=1000KB;而 MiB 是二进制,即 1MiB=1024KiB。
注意:Pod 资源请求和资源限额都是针对容器的配置。如果一个 Pod 有多个容器,每个容器都可以定义自己的资源请求和资源限额。因此,在 YAML 文件中,它们也是位于容器层级。
如果没有设置资源限额,Pod 可以使用节点上所有可用的空闲资源。如果设置了资源限额而没有设置资源请求时,K8s 默认会将资源请求值等于资源限额值。
部署 Pod 资源,查看 Pod 详情,可以看到资源请求和资源限额。
[root@k8s-master ~]# kubectl apply -f my-nginx-resources-limit.yaml
pod/my-nginx-resources-limit created
[root@k8s-master ~]# kubectl describe pod my-nginx-resources-limit
......
Containers:
nginx-c:
......
Limits:
cpu: 500m
memory: 512Mi
Requests:
cpu: 100m
memory: 256Mi
......
Pod 服务质量 Qos
配置好 Pod 的资源请求和资源限额,我们考虑一个问题:当节点上资源不够时,K8s 会触发机制来驱逐 Pod。这时,节点如何选择驱逐哪个 Pod 呢?Pod 之间有优先级吗?
这就要讲到 K8s 的服务质量 QoS(Quality of Service)机制。K8s 根据 Pod 的资源请求和资源限额,将 Pod 分为不同的 QoS 类别,当节点资源不足时,K8s 基于这些类别决定哪些 Pod 会被优先驱逐。
服务质量类别分为三种:Guaranteed、Burstable 和 BestEffort。K8s 基于每个 Pod 的资源请求和资源限额为 Pod 设置 QoS 类别,分类规则如下:
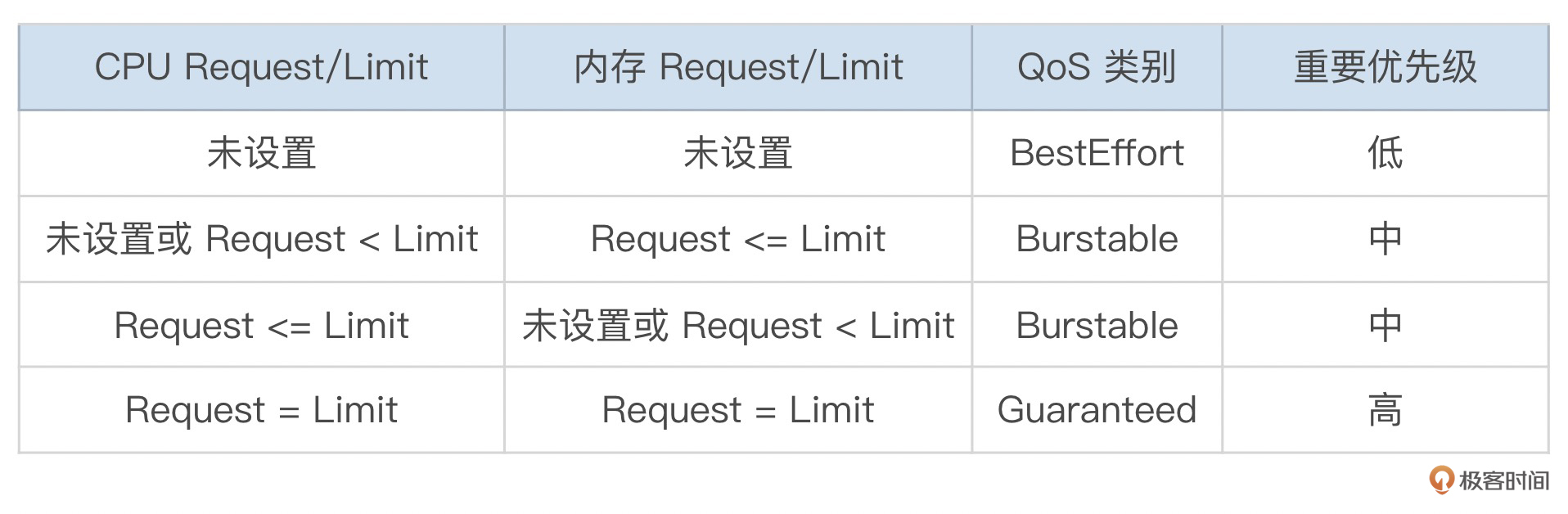
当节点资源耗尽时,K8s 将首先驱逐 BestEffort 类别的 Pod,其次是 Burstable 类别的 Pod,最后才是 Guaranteed 类别 Pod。K8s 会保障只有当 Guaranteed 类别的 Pod 的资源使用量超过了其资源限额的限制,或者宿主机面临内存不足时,才会终止这类 Pod。
通过 QoS 类别,K8s 能够实现 Pod 资源的优先级分配,优化节点的 CPU 和内存利用率,从而确保关键应用的稳定性和性能,帮助集群在面临资源有限时做出合理的调度决策。
小结
今天,我跟你讨论了 K8s 集群中应用稳定性的保障机制。
首先是 Pod 探针,K8s 提供了 3 种探针类型(启动探针、就绪探针、存活探针),如果定义了启动探针,它会首先被执行,启动探针用于判断容器是否已经启动并准备接受请求。当启动探针成功或者未定义时,就绪探针将开始执行,就绪探针用于检查容器是否已经准备好接收外部请求。最后执行的是存活探针,存活探针用于检查容器是否还在运行。如果存活探针检查失败,K8s 会杀死容器并尝试重启它。这些探针通过不同的监测方式,可以定时监测容器的启动、就绪、存活状态,从而自动进行容器的重启、替换、移出服务列表等操作,确保应用的稳定性。
其次,我们讲了 Pod 资源请求和资源限额,通过为 Pod 配置 CPU 和内存的资源请求(Requests)和资源限额(Limits),可以保证 Pod 获得必要的节点资源运行,同时防止资源被过度消耗。Pod 按照不同资源请求和资源限额配置,可以定义为不同的服务质量(QoS)类别。K8s 有三种服务质量类别(Guaranteed、Burstable、BestEffort),当节点资源耗尽时,K8s 将首先驱逐 BestEffort 类别的 Pod, 其次是 Burstable 类别的 Pod,最后才是 Guaranteed 类别的 Pod。
注意,Pod 探针和 Pod 资源请求和资源限额的配置都是针对 Pod 中的容器,如果 Pod 有多个容器,每个容器都可以配置自己的探针、资源请求和资源限额,在编写 YAML 文件时需要注意层级关系。
思考题
这就是今天的全部内容,最后给你留一道练习题。
请你部署一个镜像为 Busybox 的 Pod,定义启动探针来检查容器中 “/data/config.txt” 文件是否创建,查看一下 Pod 的运行状态。
然后再来修改 Pod,在运行容器时执行 “touch /data/config.txt” 命令来创建这个配置文件,再观察一下 Pod 的运行情况。
相信经过动手实践,会让你对知识的理解更加深刻。
- Y 👍(0) 💬(1)
1.设置启动探针 # my-pod-probe.yaml apiVersion: v1 kind: Pod metadata: name: my-pod-probe spec: containers: - name: nginx-c-probe image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nginx:1.26.1-alpine startupProbe: exec: command: - cat - /root/config.txt initialDelaySeconds: 5 periodSeconds: 5 successThreshold: 1 failureThreshold: 3 2.然后再来修改 Pod,在运行容器时执行 “touch /data/config.txt” 命令来创建这个配置文件,再观察一下 Pod 的运行情况 这个试了半天都没成功。不知道哪里出问题了。请老师帮看一下。 # my-pod-probe.yaml apiVersion: v1 kind: Pod metadata: name: my-pod-probe spec: containers: - name: nginx-c-probe image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nginx:1.26.1-alpine command: ["/bin/sh", "-c"] args: ["touch /root/config.txt"] startupProbe: exec: command: - cat - /root/config.txt initialDelaySeconds: 5 periodSeconds: 5 successThreshold: 1 failureThreshold: 3
2024-08-21 - 抱紧我的小鲤鱼 👍(0) 💬(1)
readinessProbe: exec: command: - cat - /data/config.txt initialDelaySeconds: 5 periodSeconds: 5 successThreshold: 1 failureThreshold: 3
2024-07-27