06 K8s节点管理与Pod调度
你好,我是雪飞。
上一讲我介绍了 K8s 中的核心资源对象——Pod,它是 K8s 中的最小部署单元,Pod 中包含了一个或者多个容器,这些容器中运行着满足各种业务需求的应用镜像。我们可以使用 kubectl 命令和 YAML 文件来部署 Pod,当 K8s 接到一个 Pod 资源对象的部署任务,它的 Scheduler 组件就会根据调度策略来决定这个 Pod 应该运行在哪些节点上,然后这些节点上的 kubelet 组件就会和容器运行时组件协同工作,将 Pod 中的容器运行在节点上。这节课我们就来深入了解一下 K8s 的节点管理和调度策略。
管理节点
节点是加入到 K8s 集群中的物理机、虚拟主机或者云服务器,它们组成了 K8s 集群的硬件基础设施,它也是 Pod 中容器运行的载体。节点分为管理节点和工作节点,分别运行着不同的 K8s 组件。通常 K8s 集群至少由两台以上的节点组成,这样才是真正意义上的集群,从而实现业务应用的高可用。
K8s 把节点也作为一种资源对象,从而纳入到 Controller Manager 组件的管理中。下面我们就来讲讲节点在 K8s 中的相关操作。
加入新节点
如果我们要新增加一个节点,需要先保证这个节点和现有 K8s 集群的节点在同一内网环境,能够相互访问。然后配置好新节点的系统环境,安装容器相关软件,安装 kubeadm 和 kubelet 组件,最后在新节点上执行 “kubeadm join” 命令来加入集群。具体过程可以参考集群搭建里介绍的步骤。
查看节点
使用 “kubectl get node” 命令可以查看节点列表信息,由于 Node 的缩写是 no,也可以在命令中使用 no 代替 node。命令后面可以增加 “-o wide” 参数看到集群节点的详细信息,例如节点的 IP 地址、操作系统、容器运行时等等。
[root@k8s-master ~]# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master Ready control-plane 30h v1.28.0 192.168.1.11 <none> CentOS Linux 7 (Core) 3.10.0-1160.108.1.el7.x86_64 docker://26.1.4
k8s-worker1 Ready <none> 30h v1.28.0 192.168.1.12 <none> CentOS Linux 7 (Core) 3.10.0-1160.108.1.el7.x86_64 docker://26.1.4
k8s-worker2 Ready <none> 30h v1.28.0 192.168.1.13 <none> CentOS Linux 7 (Core) 3.10.0-1160.108.1.el7.x86_64 docker://26.1.4
使用 “kubectl describe node” 命令可以查看节点的详细信息。节点不支持用命名空间分组,所以节点相关命令没有 -n 参数。
我们会在命令返回结果(返回信息太多,我用“…”做了省略)中看到,节点详细信息里包含了节点基础信息、状态信息、网络信息、节点上运行的 Pod 信息、分配的资源信息、事件信息等等,以帮助我们快速了解节点详情和状态。
[root@k8s-master ~]# kubectl describe node k8s-master
Name: k8s-master
Roles: control-plane
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
......
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Thu, 13 Jun 2024 17:37:46 +0800 Thu, 13 Jun 2024 17:37:46 +0800 CalicoIsUp Calico is running on this node
......
Non-terminated Pods: (8 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
calico-apiserver calico-apiserver-547c4c48b-bjbdb 0 (0%) 0 (0%) 0 (0%) 0 (0%) 23h
......
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 650m (32%) 0 (0%)
memory 100Mi (2%) 0 (0%)
......
Events: <none>
排空节点
如果你想要对一个节点进行升级、故障修复,或者安全地删除一个节点,你需要先“排空”该节点上的 Pod。这意味着你需要将该节点上的所有 Pod 迁移到其他节点上。以下是安全排空节点的步骤。
第一步:标记节点“不可调度”
使用 “kubectl cordon” 命令来标记节点为“不可调度”,这样新的 Pod 就不会被调度到这个节点上。
第二步:排空节点
使用 “kubectl drain” 命令来安全地清除节点上的所有 Pod,将它们迁移到其他可用的节点上,K8s 会自动重新调度这些 Pod 到其他节点。之后,就可以对节点进行运维操作。
- –ignore-daemonsets:告诉 K8s 忽略 DaemonSet 管理的 Pod,因为 DaemonSet 确保它们的 Pod 只运行在可用的节点上。
- –delete-emptydir-data:告诉 K8s 可以删除 Pod 存储在本地的临时数据。
注意:在执行 “kubectl cordon” 和 “kubectl drain” 命令之前,请确保你有足够的资源来处理迁移的 Pod。
等节点升级或者修复完成,可以使用 “kubectl uncordon” 命令重新设置节点为“可调度”状态,这样 K8s 又可以把新的 Pod 调度到该节点了。
删除节点
如果不再使用该节点,排空节点后,你也可以使用 “kubectl delete” 命令从集群中安全地删除节点。
了解完节点的相关命令。现在我再来给你讲一下 Pod 调度到节点上的过程。
Pod 调度过程
在 K8s 里,调度 Pod 的过程就像是住酒店安排房间。当你通过 kubectl 运行部署 Pod 的命令,就像是给“大堂经理”(API server)说要给这个“新客人”(Pod)安排一个房间。
“大堂经理”会把这个要求记录在“账本”(etcd)里。然后“酒店前台”(Scheduler)看到“账本”中记录的需求,就开始在“酒店”(K8s 集群)中寻找有没有合适安置“新客人”的“房间”(节点 Node)。“酒店前台”会考虑很多因素,比如这个“新客人”需要住多大的“空间”(Pod 的资源需求),还要看他有没有特别的要求,比如要住在哪一个“楼层”(命名空间)。
一旦“酒店前台”找到个合适的好“房间”,就会通知“房间管理员”(kubelet),“房间管理员”就开始按照“新客人”的要求,准备“相关物品”(容器镜像),然后“新客人”就可以在“房间”里安顿下来了。
最后,“房间管理员”会把“客人”的情况报告给“大堂经理”记录在“账本”里。这个安排“房间”的过程就结束了。你只需要把这些角色换成 K8s 的对应组件,就能清楚地理解 Pod 的完整调度过程。
Pod 的调度过程完全是自动化的,非常省心省力。但是如果 Pod 对要部署到的节点有一些特殊需求,我们就要采取一定的调度策略,通常有两种方式可以手动配置调度策略:nodeSelector、污点和容忍度。我们先来讲一下 nodeSelector 这种方式。
nodeSelector
在 K8s 中,标签(Label)是一种强大的对资源对象进行分组的功能,它通常是一组键值对(key: value),标签值可以为空。我们给 K8s 的资源对象加上标签,用于对资源对象进行分类和选择。
nodeSelector 调度方式就是通过在 Pod 的 YAML 文件中增加 nodeSelector 属性,用来指定要部署的节点的标签,从而调度器会将 Pod 调度到具有这个标签的节点上。我还是用住酒店安排房间的例子给你描述一下,节点的标签就类似酒店房间的等级,比如普通房、高级房、豪华房,nodeSelector 就相当于 Pod 这个客人指定要住在豪华房,所以“酒店前台”就会把他安排到豪华房中的一间。
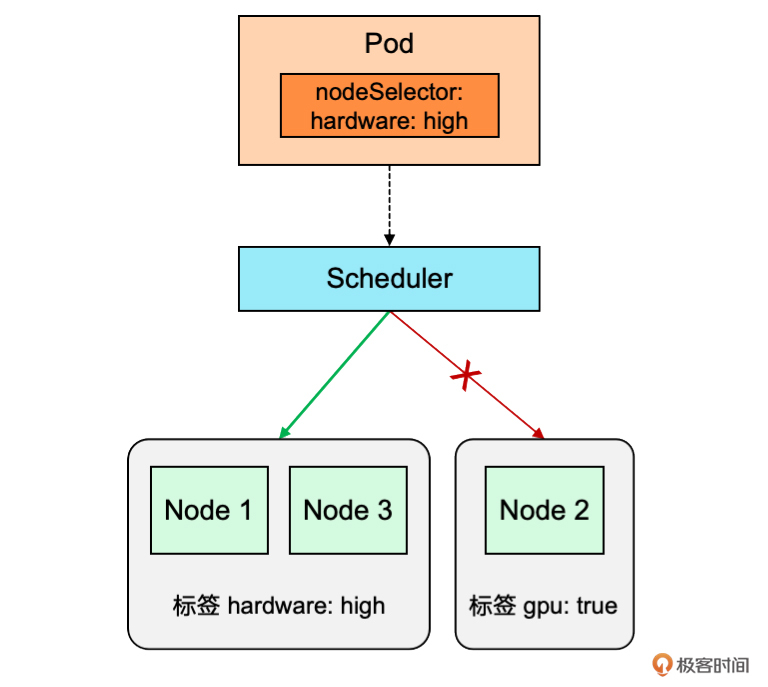
我们通过一个实际例子来演示一下,如何把 Pod 调度到具有高配置硬件的节点上。在演示之前,我先给你列出了节点设置标签的相关命令。你可以通过 “kubectl label node” 命令来管理节点标签。
添加节点标签:kubectl label node <node名称> key=value
查看节点标签:kubectl get node --show-labels
编辑节点标签:kubectl label node <node名称> key=newvalue --overwrite
删除节点标签:kubectl label node <node名称> key-
第一步:定义节点标签
首先,你需要确保目标节点要具有相应的标签。集群中节点的硬件配置不一定相同,我们可以给高配置的 k8s-worker1 节点打上 “hardware=high” 标签。
第二步:配置 Pod 的 nodeSelector
要把 Pod 调度到高配置的节点上,你需要在 Pod 的 YAML 文件(nginx-nodeselector.yaml)中,添加一个 “nodeSelector” 属性,用来指定与目标节点标签匹配的键值对。
# nginx-nodeselector.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-node
spec:
nodeSelector:
hardware: high # 这里是你的节点标签
containers:
- name: nginx
image: nginx
在这个文件中,nodeSelector 指定了 “hardware=high” 标签。由于我们已经给高配置节点打了这个标签,所以这意味着 Pod 将只会被调度到这些高配置的节点上。
第三步:部署 Pod
使用 “kubectl apply” 命令部署 Pod 的 YAML 文件。
第四步:验证调度结果
使用 “kubectl get pod -o wide” 命令可以查看 Pod 所在的节点。可以看到 Pod 确实被调度到了具有 “hardware=high” 标签的 k8s-worker1 节点上。
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-node 1/1 Running 0 155m 10.244.194.68 k8s-worker1 <none> <none>
通过使用 nodeSelector 方式,可以有效地确保 Pod 运行在具有特定标签的节点上,从而优化资源利用率、满足 Pod 性能要求。nodeSelector 是一种正向选择,我们再来看一下污点和容忍度的方式,这是一种反向选择的调度策略。
污点和容忍度
在 K8s 中,节点除了可以打上标签,还有另一种标记方式,就是污点(Taints)。污点也是一组键值对(key: value),值可以为空。一旦节点被标记有污点之后,Pod 就不能够被调度到这些有污点的节点上,所以污点是一种反向调度策略。
那么有没有办法让 Pod 可以调度到这些有污点的节点上呢?答案是肯定的,K8s 也给 Pod 提供了容忍度(Tolerations)这个属性,Pod 通过配置对污点的容忍度,从而可以调度到有污点的节点。
我继续用住酒店安排房间的例子给你描述一下,节点的污点就类似酒店房间的缺点,比如有的房间没有空调或者没有热水,所以正常的 Pod 客人是不会去住这种有缺点的房间,但是有些 Pod 配置了容忍度,可以忍受没有空调的房间,那这种情况下,“酒店前台”也就可以把他安排到没有空调的房间,也就是 Pod 被调度到了有污点的节点。
下面我们通过一个实际例子来演示一下,如何通过给节点设置污点来阻止正常 Pod 调度到节点上,以及通过给 Pod 设置容忍度又可以把 Pod 调度到有污点的节点上。
第一步:给节点添加上污点
在K8s中,使用 “kubectl taint node” 命令为节点添加污点。我们给节点 k8s-worker1 添加一个污点 “ready=no”。
在污点 “ready=no” 后面还有一个 “:NoSchedule”,它是用来表示污点的效果类型。有三种类型:
- NoSchedule:表示只能调度配置了该污点的容忍度的 Pod 到该节点上。常用这种类型。
- PreferNoSchedule:表示如果 Pod 没有配置该污点的容忍度,通常是不会调度到该节点上,但如果这个 Pod 没有其他节点可选,那也能勉强调度到该节点。
- NoExecute:表示如果 Pod 没有配置该污点的容忍度,不仅不能被调度到该节点上,而且如果节点上已经存在这样的 Pod,它们将被驱逐。
第二步:部署正常的 Pod
我们先试一下不加容忍度的 Pod,编写 Pod 的 YAML 文件(nginx-no-toleration.yaml)。
# nginx-no-toleration.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-no-toleration
spec:
containers:
- name: nginx
image: nginx
使用 “kubectl apply” 命令部署 Pod 的 YAML 文件。
使用 “kubectl get pod -o wide” 命令可以查看 Pod 部署所在的节点。可以看到 Pod 被调度到了没有污点的 k8s-worker2 节点上。
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-no-toleration 1/1 Running 0 38s 10.244.126.5 k8s-worker2 <none> <none>
第三步:配置 Pod 的容忍度
我们再编写一个新的 Pod 的 YAML文件(nginx-toleration.yaml)中,添加一个 “tolerations” 属性,用来配置 Pod 的容忍度,匹配节点上的污点。
# nginx-toleration.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-toleration
spec:
tolerations:
- key: "ready"
operator: "Equal"
value: "no"
effect: "NoSchedule"
containers:
- name: nginx
image: nginx
在这个文件中,tolerations 属性指定了 Pod 可以容忍的污点键 “ready”、关系 “Equal”、值 “no” 和效应 “NoSchedule”,这意味着 Pod 可以被调度到具有这些污点的节点上。
第四步:部署设置了容忍度的 Pod
使用 “kubectl apply” 命令部署新的 Pod 的 YAML 文件。
第五步:验证调度结果
使用 “kubectl get pod -o wide” 命令可以查看 Pod 所在的节点。可以看到 Pod 被调度到了有污点的 k8s-worker1 节点上。
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-toleration 1/1 Running 0 43s 10.244.194.69 k8s-worker1 <none> <none>
实验完成,最后通过 “kubectl taint” 命令清除一下 k8s-worker1 节点上的污点。
[root@k8s-master ~]# kubectl taint nodes k8s-worker1 ready=no:NoSchedule-
node/k8s-worker1 untainted
通过使用节点的污点和 Pod 的容忍度,你可以更精细地控制集群中 Pod 的调度行为,确保 Pod 运行在符合特定要求的节点上,同时避免不兼容的 Pod 被调度到不适当的节点。
小结
今天,我首先介绍了 K8s 中的节点(Node),节点是加入到 K8s 集群中的物理机、虚拟主机或者云服务器,它们组成了 K8s 集群的硬件基础设施,它也是 Pod 中容器运行的载体。节点分为管理节点(Master Node)和工作节点(Worker Node),分别运行着不同的 K8s 组件。
接着,我通过一个住酒店安排房间的例子,给你讲解了 Pod 被调度到节点的过程。部署 Pod 的请求会先发送到 API server,并被记录到 etcd 中存储,然后 Scheduler 会根据集群中各个节点的资源占用情况和调度策略来自动选择要运行 Pod 的节点,之后 Scheduler 会通知节点上的 kubelet,再由 kubelet 和容器运行时来共同运行起 Pod 中的容器,最后返回 Pod 状态更新到 etcd 中。
最后,我给你介绍了两种手动影响调度策略的方式。第一个是 nodeSelector,它是给节点打上标签 Label,然后在部署 Pod 的时候通过 nodeSelector 属性来指定 Pod 要调度的节点。第二个是污点和容忍度,通过给节点添加污点(Taints)来阻止正常 Pod 调度到节点上,但是如果 Pod 设置了可以容忍该污点的容忍度(Tolerations)属性,就可以继续调度到这个有污点的节点上。这两种方式可以帮助你精准地控制 Pod 的调度,从而满足一些特殊的调度需求。
今天讲了很多节点相关的 kubectl 命令,这里给你做了总结。
查看节点列表:kubectl get node [-o wide]
查看节点详细信息:kubectl describe node <node名称>
标记节点为不可调度状态:kubectl cordon <node名称>
排空节点上的Pod:kubectl drain <node名称> [--ignore-daemonsets]
节点添加标签:kubectl label node <node名称> <key=value>
节点删除标签:kubectl label node <node名称> <key->
查看节点标签:kubectl get node --show-labels
节点添加污点:kubectl taint node <node名称> <key=value:NoSchedule>
节点删除污点:kubectl taint node <node名称> <key=value:NoSchedule->
思考题
这就是今天的全部内容,最后留一道思考题给你。
Pod 通常会被调度到工作节点上,但是管理节点上也运行着工作节点上的全部组件,那么 Pod 是否可以调度到管理节点上呢?如果可以,那怎么能把 Pod 调度到管理节点?
你可以在自己的集群中测试一下,欢迎你把答案写到留言区。相信经过思考和实践,会让你对知识的理解更加深刻。
- 抱紧我的小鲤鱼 👍(5) 💬(1)
三种方法,对应本文的三个方法 1. 移除节点上的污点, kubectl taint nodes master-node node-role.kubernetes.io/master- 2. 添加容忍 spec: tolerations: - key: "node-role.kubernetes.io/master" operator: "Equal" value: "" effect: "NoSchedule" 3. 直接指定节点名称 spec: nodeName: master-node
2024-07-15 - 高志强 👍(0) 💬(0)
奇怪了,我部署设置了容忍度的pod,并没有跑到节点1上,节点1我加了污点和效果类型都按老师步骤来的
2025-02-14