20 应用监控:如何使用日志来监控应用?
你好,我是秦晓辉。
上一讲我们介绍了应用埋点监控,对于自研的软件,在一开始就建立可观测能力是非常好的选择,但是很多软件可能无法修改源代码,比如一些外采的软件,那就只能用一些外挂式的手段,比如在请求链路上插入一些代理逻辑,或者读取分析应用日志。
典型的代理方式是 Nginx,如果是 HTTP 服务,从 Nginx 的 Access 日志中可以获取很多信息,比如访问的是哪个接口,用的什么 HTTP 方法,返回的状态码是什么,耗时多久等等。这些信息对应用的监控很有帮助。
除此之外,我们也可以使用 eBPF 技术为网络包增加一些过滤分析逻辑,不过 eBPF 要求的内核版本较高。而通过日志对应用做监控,显然是相对直观和廉价的方式,这一讲我们就来看看怎么从日志中提取指标。
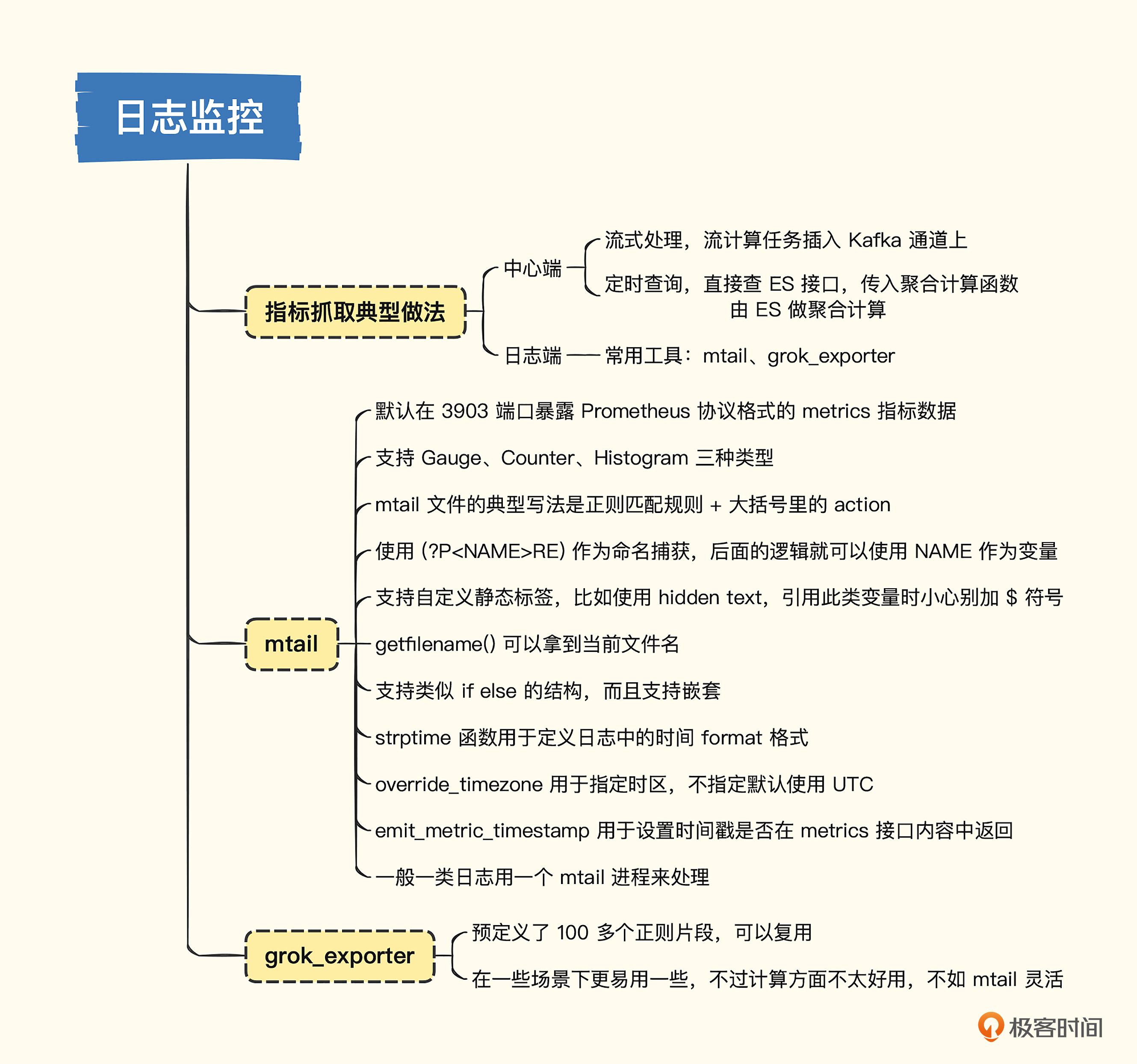
提取指标的典型做法
根据提取规则运行的位置可以分为两类做法,一个是在中心端,一个是在日志端。
中心端就是把要处理的所有机器的日志都统一传到中心,比如通过 Kafka 传输,最终落到 Elasticsearch,指标提取规则可以作为流计算任务插到 Kafka 通道上,性能和实时性都相对更好。或者直接写个定时任务,调用 Elasticsearch 的接口查询日志,同时给出聚合计算函数,让 Elasticsearch 返回指标数据,然后写入时序库,实时性会差一些,但也基本够用。
日志端处理是指提取规则直接运行在产生日志的机器上,流式读取日志,匹配正则表达式。对于命中的日志,提取其中的数字部分作为指标上报,或者不提取任何数字,只统计一下命中的日志行数有时也很有价值,比如统计一下 Error 或 Exception 关键字出现的次数,我们就知道系统是不是报错了。
中心端处理的方式,我没有找到开源解决方案,如果你知道有好用的开源方案可以在评论区留言分享。日志端处理的方式,倒是有很多开源方案,比较有名的是 mtail 和 grok_exporter,mtail 发布时间更久,3400 star,grok_exporter 发布时间晚一些,700 star,不过它们原理上是类似的,所以我们重点介绍 mtail 的用法。
快速上手mtail
你应该用过 Linux 下的 tail 命令吧?mtail、grok_exporter 等工具就像是对日志文件执行 tail -f,然后每收到一条日志,就去匹配预定义的正则表达式,如果匹配成功,就执行某些动作,否则跳过等待下一条日志。
下面我们安装一下 mtail,统计一下 /var/log/messages 中 Out of memory 关键字出现的次数,作为一个重要的监控指标上报。
mtail 最新版本是 3.0.0-rc50,虽然是 rc 版本,不过不用怕,mtail 一直在发 rc 版就是不发正式版,我在生产环境用过没遇到什么问题,我们就拿这个版本举例,下载和你的 OS 匹配的发布包,解压缩,可以看到 mtail 的二进制。
我想统计/var/log/messages 中 Out of memory 关键字出现的次数,那我得通过某种机制告诉 mtail 正则表达式是什么,提取规则是什么,这个规则文件我们叫做 program,一般命名为 xyz.mtail,我给出了一个样例,你可以看一下。
# 在 mtail 二进制同级目录下创建 progs 目录,下面放置 syslogs 子目录
# syslogs 子目录用于放置系统日志文件对应的提取规则
mkdir -p progs/syslogs
# 用于统计 Out of memory 关键字的 mtail 规则文件内容如下(我命名为
# syslogs.mtail):
counter oom_total
/Out of memory/ {
oom_total++
}
文件内容看起来很简单,只有 4 行,第一行是声明了一个变量,类型是 counter,变量名是 oom_total,第二行是在 // 之间定义了一个正则表达式,用来匹配 Out of memory,如果匹配成功,就执行大括号里的内容,对 oom_total 变量加 1。
接下来,我们把 mtail 运行起来,看看效果如何。
启动命令:
通过 -progs 参数指定 mtail 文件所在目录,当然,指定具体的文件也可以,通过 -logs 参数指定要提取的日志文件是哪个,支持 glob 匹配,也支持传入多次 -logs 参数。mtail 启动之后会默认监听在 3903 端口,请求 3903 的 /metrics 接口就能拿到 Prometheus 协议的监控数据。
[root@fc-demo-02 qinxiaohui]# ss -tlnp|grep mtail
LISTEN 0 128 [::]:3903 [::]:* users:(("mtail",pid=18972,fd=7))
[root@fc-demo-02 qinxiaohui]# curl -s localhost:3903/metrics | grep oom_total
# HELP oom_total defined at syslogs.mtail:1:9-17
# TYPE oom_total counter
oom_total{prog="syslogs.mtail"} 0
上面的例子里,我使用 grep 命令做了过滤,只展示了 oom_total 相关的内容,实际上 mtail 会输出很多指标,你可以自己测试一下。有了这个 /metrics 接口,怎么和监控系统对接就很明显了,直接由抓取器来这个地址抓取数据就可以了。下面我们继续讲解 mtail 本身的用法。
例子里 mtail 自动加了一个 prog 标签,把 mtail 文件名作为标签加上了,对于一些 access.log 类型的日志,经常用于统计接口的吞吐、延迟等,需要把接口路径、method、statuscode 等作为标签,应该如何配置呢?这里我以 Nginx 的 access 日志作为样例来演示,你可以看一下我的 Nginx 的 logformat。
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
对应的几条样例日志如下:
# tail -n 5 /var/log/nginx/access.log
119.45.249.92 - - [17/Dec/2022:22:35:39 +0800] "GET / HTTP/1.1" 200 14849 "-" "clb-healthcheck" "-"
119.45.249.92 - - [17/Dec/2022:22:35:40 +0800] "GET / HTTP/1.1" 200 14849 "-" "clb-healthcheck" "-"
119.45.249.92 - - [17/Dec/2022:22:35:40 +0800] "GET / HTTP/1.1" 200 14849 "-" "clb-healthcheck" "-"
119.45.249.92 - - [17/Dec/2022:22:35:41 +0800] "GET / HTTP/1.1" 200 14849 "-" "clb-healthcheck" "-"
119.45.249.92 - - [17/Dec/2022:22:35:41 +0800] "GET / HTTP/1.1" 200 14849 "-" "clb-healthcheck" "-"
这个 logformat 着实简单,连响应延迟都没有打印,这是 Nginx 默认的 logformat,我们也先维持现状,统计一下请求数量以及响应体的大小,下面是具体的 mtail 文件内容。
counter request_total by method, url, code
counter body_bytes_sent_total by method, url, code
/"(?P<method>\S+) (?P<url>\S+) HTTP\/1.1" (?P<code>\d+) (?P<body_bytes_sent>\d+)/ {
request_total[$method][$url][$code]++
body_bytes_sent_total[$method][$url][$code] += $body_bytes_sent
}
这个正则看起来就复杂多了,比如获取 statuscode 的地方写的正则是 (?P<code>\d+),这个叫做命名捕获,核心的正则就是 \d+,但是后面想用这个内容,就给它设置了一个变量叫 code,而 method、url、body_bytes_sent 都是同样的道理。
匹配了正则之后,做了两个动作,request_total 变量加一,相当于在统计请求次数,body_bytes_sent_total 变量加上日志这行提取的 $body_bytes_sent 变量的值,是在统计响应总大小。
这里 request_total 和 body_bytes_sent_total 这两个指标都是带有标签的,且都是 3 个标签:method、url、code,声明之后就可以使用,通过命名捕获的方式给的变量名也可以在后面使用,非常灵活。下面是测试输出。
# 通过下面的命令加载 nginx 的 mtail,指定 nginx 的 access.log
./mtail -progs ./progs/nginx/ -logs /var/log/nginx/access.log
# 下面请求一下 /metrics 接口,看看是否采集成功
[root@fc-demo-02 qinxiaohui]# curl -s localhost:3903/metrics | grep -P 'request_total|body_bytes_sent_total'
# HELP body_bytes_sent_total defined at nginx.mtail:2:9-29
# TYPE body_bytes_sent_total counter
body_bytes_sent_total{code="200",method="GET",prog="nginx.mtail",url="/"} 1.143373e+06
# HELP request_total defined at nginx.mtail:1:9-21
# TYPE request_total counter
request_total{code="200",method="GET",prog="nginx.mtail",url="/"} 77
看起来一切正常,上面这些标签都是从日志中直接提取的,如果我想附加一些静态标签应该怎么做呢?比如把机房信息作为标签附到时序数据上,你可以看一下样例。
hidden text zone
zone = "beijing"
counter request_total by method, url, code, zone
counter body_bytes_sent_total by method, url, code, zone
/"(?P<method>\S+) (?P<url>\S+) HTTP\/1.1" (?P<code>\d+) (?P<body_bytes_sent>\d+)/ {
request_total[$method][$url][$code][zone]++
body_bytes_sent_total[$method][$url][$code][zone] += $body_bytes_sent
}
这里加了一个全局的 zone=“beijing” 的标签,写法一目了然,不过多解释。唯一需要注意的是在引用 zone 变量的时候,前面不要加 $ 符号。这里千万别写顺手了,看到其他变量都加 $ 就把 zone 也加上了,加上就识别不了了。
上面两个例子演示的都是 Counter 类型的变量,其实 mtail 还支持 Gauge 和 Histogram 类型,并且在仓库的 examples 目录下提供了很多样例,可以直接拿来使用,注意 Histogram 类型在定义的时候要给出 Bucket 的分布范围,要不然 mtail 不知道如何放置统计数据,这个应该也容易理解,如果有疑问可以返回前面第 2 讲,再回顾一下 Histogram 类型的讲解。
下面我们来看一个生产级的例子,用于分析 lighttpd 的访问日志,我们从中可以学到更多生产级的写法。
# Copyright 2010 Google Inc. All Rights Reserved.
# This file is available under the Apache license.
# mtail module for a lighttpd server
counter request by status
counter time_taken by status
counter bytes_out by subtotal, status
counter bytes_in by status
counter requests by proxy_cache
const ACCESSLOG_RE // +
/(?P<proxied_for>\S+) (?P<request_ip>\S+) (?P<authuser>\S+)/ +
/ \[(?P<access_time>[^\]]+)\] "(?P<http_method>\S+) (?P<url>.+?) / +
/(?P<protocol>\S+)" (?P<status>\d+) (?P<bytes_body>\d+) (?P<bytes_in>\d+)/ +
/ (?P<bytes_out>\d+) (?P<time_taken>\d+) "(?P<referer>[^"]+)" / +
/"(?P<agent>[^"]+)"/
# /var/log/lighttpd/access.log
getfilename() =~ /lighttpd.access.log/ {
// + ACCESSLOG_RE {
# Parse an accesslog entry.
$url == "/healthz" {
# nothing
}
otherwise {
strptime($access_time, "02/Jan/2006:15:04:05 -0700")
request[$status]++
time_taken[$status] += $time_taken
bytes_out["resp_body", $status] += $bytes_body
bytes_out["resp_header", $status] += $bytes_out - $bytes_body
bytes_in[$status] += $bytes_in
$proxied_for != "-" {
requests[$request_ip]++
}
}
}
}
这个 program 一开始,定义了很多 counter 类型的变量,这里没有什么新知识,略过。然后定义了一个常量 ACCESSLOG_RE,这个正则很复杂,对于这类复杂的正则,可以拆成很多个小的部分,相互之间用 + 连接,这种做法既容易阅读,又容易为每个片段增加注释,便于后期维护,后面介绍的 grok_exporter 则更进一步,把这些正则片段直接做成 pattern 单独维护了。
继续往下看,getfilename() 是个内置函数,获取日志文件的路径,对这个内容做了一个正则判断,如果匹配才去走核心逻辑,这里是不是有些多此一举了呢?我猜测,这个写法的初衷是觉得这段内容可能会和其他的提取规则混在一起,同时提取多个日志文件时,为了避免这段逻辑跑在一些无关的日志上,就加了这么一句判断,考虑得很周全。不过,如果我们在使用的时候,可以保证这段逻辑只用于处理 lighttpd 的访问日志,这个判断就是可以去掉的。
getfilename() 的判断通过之后,就开始校验主正则了。主正则匹配就开始判断请求的 url 是不是 /healthz,如果是就什么都不干(空逻辑),因为这个是健康检查的接口,没必要提取指标。否则进行主逻辑处理,“否则”的关键词是 otherwise,相当于 else。主逻辑部分你应该一眼就能明白是什么意思,核心点是这个 strptime 函数,它其实是在告诉 mtail 用什么时间格式来转换时间戳,第二个参数是 Go 写法的 format pattern,这些其实都好理解,比较容易掉坑里的是时区问题。
如果日志里的时间戳没有打印时区信息,mtail 在处理的时候会把它们统一当做 UTC 时间来对待,这在其他时区的场景显然是错误的,这个时候我们就要手工指定时区,比如通过 -override_timezone=Asia/Shanghai 启动参数可以让 mtail 使用东八区。
当然,如果我们压根就不在 /metrics 接口中暴露时间戳信息,那抓取器抓取数据的时候只能使用抓取的时间,时区这个参数有没有都无所谓了,但如果我们在 /metrics 接口中返回时间戳信息,就一定要在启动参数中控制时区,是否在 /metrics 接口中返回时间戳信息,也是通过一个启动参数来控制的,emit_metric_timestamp 设置为 true 的时候才会返回时间戳。
最后说一下 mtail 的部署,如果一个机器上有 5 个应用程序都要用 mtail 来提取指标,各个应用的日志格式又不一样,建议启动 5 个 mtail 进程分别来处理。虽然管理起来麻烦,但是性能好,相互之间没有影响。
如果把所有提取规则都放到一个目录下,然后通过多次 -logs 参数的方式同时指定这多个应用的日志路径,一个 mtail 进程也能处理,但是对于每一行日志,mtail 要把所有提取规则都跑一遍,十分浪费性能,而且正则提取,速度本来就不快。另外有些指标可能是所有应用都可以复用的,如果放在一起处理,还容易相互干扰,导致统计数据不准。从这两点来看,尽量还是要拆开分别处理,虽然管理起来麻烦一些,但也是值得的。
在容器场景中就没有这个问题,容器场景直接使用 sidecar 部署就好了,每个 Pod 必然只有一个应用,伴生的 mtail 就专注去处理这个应用的日志就好了。
💡 延伸讨论:物理机大概率会有混部 5 个甚至 50 个服务的场景,容器又必然是一个服务一个 Pod,那虚拟机呢?做成大规格的好,还是小规格的好呢?是有混部好还是没有混部好呢?欢迎留言分享你的见解。
mtail 基本用法我们就介绍这么多,不知道你有没有感受到,得写这么多正则,太麻烦了。有没有一些工具可以复用这些正则表达式呢?毕竟有很多相同的正则需求,没必要重复造轮子。的确有,除了刚才介绍的 mtail 自带的 examples 之外,grok_exporter 把每个正则都拆散了,复用性更好,下面我们看一下 grok_exporter 是如何使用的。
快速上手grok_exporter
grok_exporter 的核心逻辑和 mtail 一样,就是通过正则从日志中提取指标,我们之前已经介绍过 mtail 的核心逻辑了,所以关于grok_exporter 的介绍会相对简明一些。
grok_exporter 显然是用到了 Grok,Grok 在 logstash 中被重度使用,内置了 100 多个预定义的正则(叫做 pattern),在 grok_exporter 的代码仓库里直接作为 submodule 的方式引用了 logstash-patterns-core,预定义的正则放在了 patterns 目录下,你可以点击查阅。
从 grok_exporter 的 releases 页面下载发布包,解压缩,直接运行就可以。
grok_exporter 默认监听在 9144 端口,我们看下访问测试效果。
[flashcat@fc-demo-02 ~]$ curl -s 10.100.0.7:9144/metrics | head -n 6
# HELP exim_rejected_rcpt_total Total number of rejected recipients, partitioned by error message.
# TYPE exim_rejected_rcpt_total counter
exim_rejected_rcpt_total{error_message="Sender verify failed",logfile="exim-rejected-RCPT-examples.log"} 2000
exim_rejected_rcpt_total{error_message="Unrouteable address",logfile="exim-rejected-RCPT-examples.log"} 32
exim_rejected_rcpt_total{error_message="relay not permitted",logfile="exim-rejected-RCPT-examples.log"} 165
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
通过代码,我们可以看到grok_exporter可以正常拿到监控数据了。下面我们搞一下测试数据,把它放到 example 目录下,保存为 login.log。
12.12.2022 04:33:03 10.1.2.1 user=Ulric message="logged in"
12.12.2022 06:47:03 10.1.2.2 user=Qin message="logged failed"
12.12.2022 06:55:03 10.1.2.2 user=Qin message="logged in"
12.12.2022 07:03:03 10.1.2.3 user=Sofia message="logged in"
12.12.2022 07:37:03 10.1.2.1 user=Ulric message="logged out"
12.12.2022 08:47:03 10.1.2.2 user=Qin message="logged out"
12.12.2022 14:34:03 10.1.2.3 user=Sofia message="logged out"
之后修改 config.yml 来解析login.log。
global:
config_version: 3
input:
type: file
path: ./example/login.log
readall: true # Read from the beginning of the file? False means we start at the end of the file and read only new lines.
imports:
- type: grok_patterns
dir: ./patterns
metrics:
- type: counter
name: user_activity
help: Counter metric example with labels.
match: '%{DATE} %{TIME} %{HOSTNAME:instance} user=%{USER:user} message="%{GREEDYDATA:data}"'
labels:
user: '{{.user}}'
logfile: '{{base .logfile}}'
server:
protocol: http
port: 9144
使用这个新的配置文件做个测试,下面是返回内容。
[flashcat@fc-demo-02 ~]$ curl -s 10.100.0.7:9144/metrics | grep user_activity
grok_exporter_line_processing_errors_total{metric="user_activity"} 0
grok_exporter_lines_matching_total{metric="user_activity"} 7
grok_exporter_lines_processing_time_microseconds_total{metric="user_activity"} 106
# HELP user_activity Counter metric example with labels.
# TYPE user_activity counter
user_activity{logfile="login.log",user="Qin"} 3
user_activity{logfile="login.log",user="Sofia"} 2
user_activity{logfile="login.log",user="Ulric"} 2
看起来 grok_exporter 要比 mtail 的方式更易用,不过和 mtail 一样,如果要对多个应用程序分别进行日志分析处理,就要启动多个 grok_exporter 实例,这点还是不太方便。当然,在运算方面,grok_exporter 没有 mtail 这种类语言式的处理来得灵活方便。至于选用哪个,尺有所短寸有所长,都学会,具体使用场景具体决策。这一讲我就给你介绍这么多,下面我们做一个总结。
小结
我们这一讲介绍的手段,从标题上来看是服务于应用监控,不过实际上也可以用于操作系统、中间件、数据库等其他监控场景,而应用监控本身,反倒不推荐日志监控方式,而是更推荐上一讲介绍的埋点监控方式。这一点,请你一定要注意,毕竟相比埋点方式,日志方式链路又长、性能又差,算是一个不得已而为之的方式。
指标提取的几种方式,总体上来看就是中心端和日志端两种,由于中心端的处理方式多见于商业软件,没有看到开源解决方案,所以我们重点介绍的是日志端的处理方式,日志端的处理核心逻辑都是一样的,通过类似 tail -f 的方式不断读取日志内容,然后对每行日志做正则匹配提取,由于日志格式不固定,很难有结构化的处理手段,所以这些工具都是选择使用正则的方式来提取过滤指标。
mtail 和 grok_exporter 是日志端处理工具的佼佼者,mtail 直接写正则,虽然可阅读性上稍微差了点儿,但是胜在逻辑处理能力,可以对提取的变量做运算,就像一门小语言,所以 mtail 把这些提取规则的文件叫做 program。grok_exporter 可以使用预定义的 pattern 名称配置匹配规则,更易读、易维护,运算方面则显得稍弱。
互动时刻
由于 mtail 和 grok_exporter 都是通过正则提取的方式来处理非结构化的日志数据的,性能是个比较关键的问题,如果日志量很大,可能会侵蚀较多的机器算力,甚至影响上面运行的服务。有没有什么实践方式可以提升性能呢?欢迎在留言区分享你的想法,也欢迎你把今天的内容分享给你身边的朋友,邀他一起学习。我们下一讲再见!
- 那时刻 👍(1) 💬(1)
讨论:物理机大概率会有混部 5 个甚至 50 个服务的场景,容器又必然是一个服务一个 Pod,那虚拟机呢?做成大规格的好,还是小规格的好呢?是有混部好还是没有混部好呢? 我觉得对于虚拟机,大规格适合混部,小规格适合单独部署。大规格混部的话,可以最大化利用资源。不过,从监控角度来说,混部会对于数据监控带来干扰因素,因为混部破坏了隔离性。 思考题:由于 mtail 和 grok_exporter 都是通过正则提取的方式来处理非结构化的日志数据的,性能是个比较关键的问题,如果日志量很大,可能会侵蚀较多的机器算力,甚至影响上面运行的服务 我没有过多的使用经验,谈谈我的想法。对于日志量大,可以考虑分段处理,可以先把日志切分成多段,然后每段分别处理,减少一次处理的数据量。另外,为了控制mtail 和 grok_exporter侵蚀较多的算力,可以通过cgroup的方式来控制max cpu使用率。 问题:请问老师 Telegraf的 plugin logparser 和 tail可以读取log文件, 同时也有 prometheus_client,实际工作中有应用么?
2023-03-01 - 金龟 👍(0) 💬(2)
老师,请教下,我们有个大盘需要查看 某种类型任务数或者任务的失败数(瞬时的数据),这类数据都是存在业务的数据库里面,所以有2个问题: 1. 用户看的数据是瞬时的快照数据,且想用饼状图看,不用时序图看,这类数据适合踩在prom里面吗? 2. 同时要通过这类统计数据点击跳转到详细列表(业务的详细列表,查看失败任务数明细),这个应该怎么实现好,是在 展示图的标签上都配置个跳转连接? 我们的系统都自研哈
2024-04-28 - Geek_be4f4d 👍(0) 💬(1)
老师您好,应用监控本身,推荐埋点方式实现,请问php有什么好用的sdk来实现埋点监控吗?
2023-06-07 - 勇敢黄瓜 👍(0) 💬(2)
请教下老师,文中说的中心端监控日志方案没有开源,EFK或者loki算吗
2023-06-07 - Kevin 👍(0) 💬(1)
看了下目录,这是指标搜集的最后一章了。想问下,categraf没有做etcd的指标采集吗?看conf目录下没有input.etcd目录
2023-02-24 - peter 👍(0) 💬(1)
请教老师几个问题: Q1:应用保存日志还有用吗? 既然对于应用的监控推荐使用埋点方式,不推荐使用日志方式。那么,对于应用,还有必要打印、保存日志吗?尤其是线上环境。 Q2:用云服务的话,一般是虚拟机,categraf怎么部署到机器上?机器是虚拟的,是不确定的实体,怎么把categraf部署到特定的机器上啊。 Q3:注册用户100万的网站,适合用什么监控? 通过前面的学习,感觉Prometheus适合比较大的规模的网站。那么,对于注册用户100万的网站,是不是有更合适的监控方案?(注1:对于网站规模大小,我不很清楚;100万用户的规模,算大还是小,不清楚,只是个人臆测; 注2: 也许Prometheus也适合小规模的网站)
2023-02-22 - 刘涛 👍(3) 💬(0)
中心处理,filebeat kafka flink
2023-02-23 - 不经意间 👍(0) 💬(0)
关于互动问题,有方法可以对日志内容去反吗,对于看是否有错误日志的情况。 对于counter应该就不行了,它得计数。
2023-08-09 - 林龍 👍(0) 💬(0)
由于项目中已经搭建了opentraceing链路,把数据加载到prometheus,请问这种方案有没有什么缺点
2023-02-22 - Tangzen 👍(0) 💬(0)
同类产品有loki+grafana,sls
2023-02-22