10 监控概论(下):监控数据的采集方式及原理
你好,我是秦晓辉。
上一讲我们介绍了监控的几个方法论,知道了哪些指标比较关键,但是具体如何采集呢?这又是一个非常重要的话题。这一讲我们就来剖析一下常见的采集数据的技术手段,了解了这些,我们就可以写自己的采集器,或者扩展很多采集器的能力了,对很多监控数据也会拥有原理层面的理解。
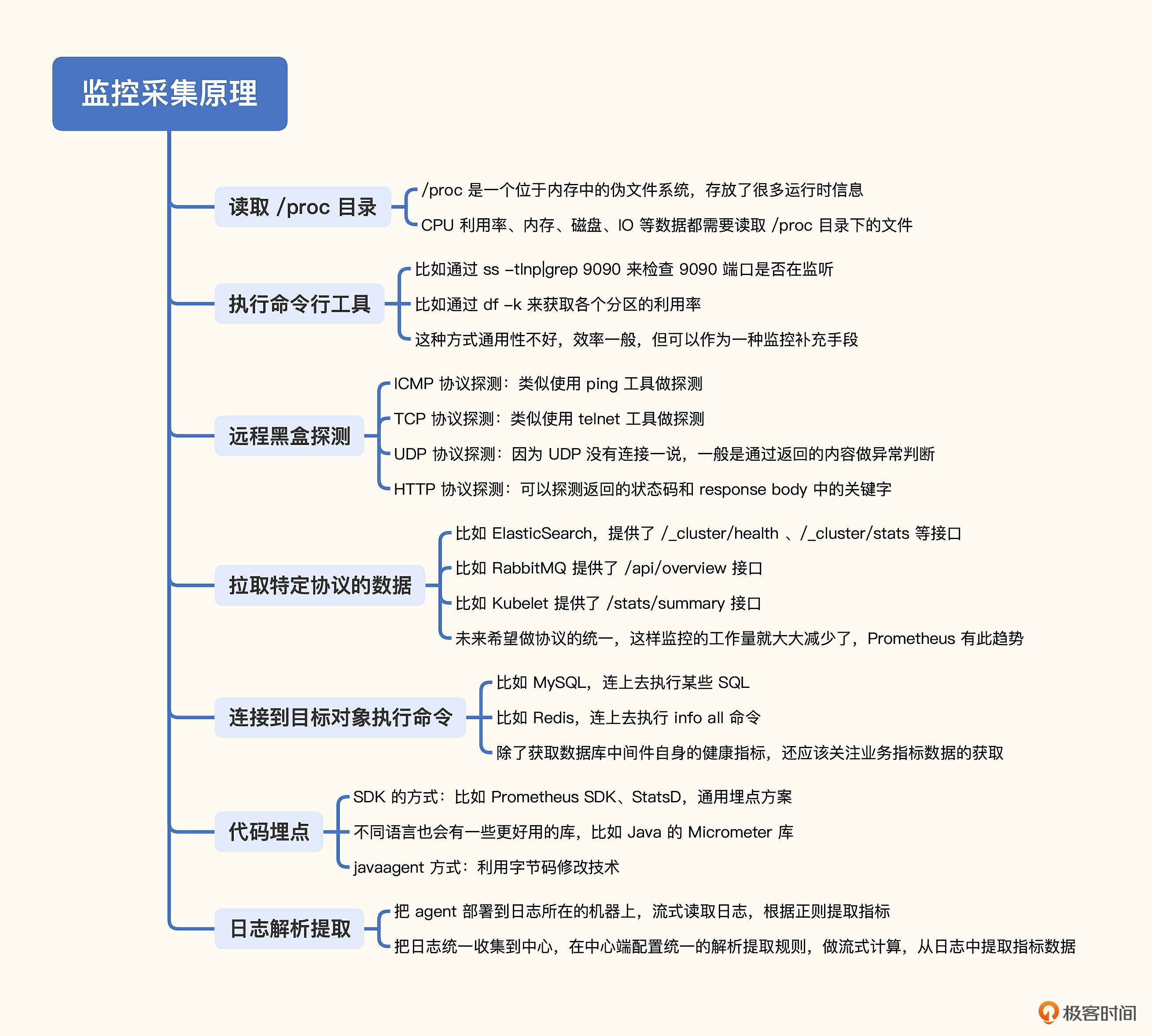
第一个版本的 Falcon-Agent 和 Categraf 都是我来主笔的,在设计的过程中,我深刻认识到采集方法的多样性,比如读取 /proc 目录、执行系统调用、执行命令行工具、远程黑盒探测、远程拉取特定协议的数据、连到目标上去执行指令获取输出、代码埋点、日志分析提取等各种各样的方法。这一讲我会从中挑选一些比较典型的手段分享给你。下面我们就按照使用频率从高到低依次看一下,先来看读取 /proc 目录的方式。
读取 /proc 目录
/proc 是一个位于内存中的伪文件系统,该目录下保存的不是真正的文件和目录,而是一些“运行时”信息,Linux操作系统层面的很多监控数据,比如内存数据、网卡流量、机器负载等,都是从 /proc 中获取的信息。
我们先来看一下内存相关的指标。
[root@dev01.nj ~]# cat /proc/meminfo
MemTotal: 7954676 kB
MemFree: 211136 kB
MemAvailable: 2486688 kB
Buffers: 115068 kB
Cached: 2309836 kB
...
内存总量、剩余量、可用量、Buffer、Cached等数据都可以轻易拿到。当然,/proc/meminfo 没有使用率、可用率这样的百分比指标,这类指标需要二次计算,可以在客户端采集器中完成,也可以在服务端查询时现算。
内存相关的指标都是Gauge类型的,下面我们再来看一下网卡流量相关的指标,网卡相关的数据都是Counter类型的数据。
[root@dev01.nj ~]# head -n3 /proc/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
eth0: 697407964307 2580235035 0 0 0 0 0 0 1969289573661 3137865547 0 0 0 0 0 0
我的机器上网卡比较多,所以这个文件的内容有很多行,通过head命令只查看前面几行,可以看到eth0网卡的指标值。整体上分两部分,前一部分是 Receive,表示入方向,后一部分是 Transmit,表示出方向。697407964307这个值表示eth0网卡入方向收到的byte总量,2580235035则表示eth0网卡入方向收到的packet总量。
注意了,这里所谓的总量,是指操作系统启动以来的累计值。从监控角度,通常我们不关注这个总量,而是关注最近一分钟或者最近一秒钟的流量是多少,所以在服务端看图的时候,通常要使用irate函数做二次计算。
看到这里,你可能会觉得,OS层面的监控很简单,不就是读取 /proc 目录下的内容吗?这倒也不尽然,有些数据从 /proc 下面是拿不到的,比如硬盘使用率。我们可以从 /proc/mounts 拿到机器的挂载点列表,但具体每个挂载点的使用率,就需要系统调用了。
OS内的数据采集,除了读取 /proc 目录之外,也经常会通过执行命令行工具的方式采集指标,下面我们再来看一下这种方式。
执行命令行工具
这种方式非常简单,就是调用一下系统命令,解析输出就可以了。比如我们想获取9090端口的监听状态,可以使用ss命令 ss -tln|grep 9090,想要拿到各个分区的使用率可以通过df命令 df -k。但是这个方式不太通用,性能也不好。
先说通用性问题,就拿ss命令来说吧,不是所有的机器都安装了这个命令行工具,而且不同的发行版或不同ss版本,命令输出内容格式可能不同。性能问题也容易理解,调用命令行工具是需要fork一个进程的,相比于进程内的逻辑,效率大打折扣,不过监控采集频率一般都是10秒起步,不频繁,所以这个性能问题倒不是什么大事,关键还是通用性问题。
读取本地 /proc 目录或执行命令行工具,都是在目标监控机器上进行的操作。有的时候,我们无法在目标机器上部署客户端程序,这时候就需要黑盒探测手段了。
远程黑盒探测
典型的探测手段有三类,ICMP、TCP和HTTP。有一个软件叫Blackbox Exporter,就是专门用来探测的,Categraf、Datadog-Agent等采集器也都可以做这种探测。
ICMP协议,我们可以通过Ping工具做测试,你可以看一下这个例子。
[root@dev01.nj ~]# ping -c 3 www.baidu.com
PING www.a.shifen.com (180.101.49.13) 56(84) bytes of data.
64 bytes from 180.101.49.13 (180.101.49.13): icmp_seq=1 ttl=251 time=1.41 ms
64 bytes from 180.101.49.13 (180.101.49.13): icmp_seq=2 ttl=251 time=1.39 ms
64 bytes from 180.101.49.13 (180.101.49.13): icmp_seq=3 ttl=251 time=1.38 ms
--- www.a.shifen.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 1.382/1.393/1.405/0.009 ms
这里我们使用Ping工具向Baidu发了3个数据包,得到了多个指标数据。
- 丢包率:0%
- min rtt:1.382
- avg rtt:1.393
- max rtt:1.405
- ttl:251
监控采集器和手工Ping测试的原理是一样的,也是发几个包做统计。不过有些机器是禁Ping的,这时候我们就可以通过TCP或HTTP来探测。对于Linux机器,一般是会开放sshd的22端口,那我们就可以用类似telnet的方式探测机器的22端口,如果成功就认为机器存活。
对于HTTP协议的探测,除了基本的连通性测试,还可以检查协议内容,比如要求返回的status code必须是200,返回的response body必须包含success字符串,如果任何一个条件没有满足,从监控的角度就认为是异常的。
有黑盒监控,自然就有白盒监控。黑盒监控是把监控对象当成一个黑盒子,不去了解其内部运行机理,只是通过几种协议做简单探测。白盒监控与之相反,它要收集能够反映监控对象内部运行健康度的指标。但是监控对象的内部指标,从外部其实是无法拿到的,所以白盒监控的指标,需要监控对象自身想办法暴露出来。最典型的暴露方式,就是提供一个HTTP接口,在response body中返回监控指标的数据。下面我们就来看一下这种采集方式。
拉取特定协议的数据
有很多组件都通过HTTP接口的方式,暴露了自身的监控指标。这里我给你举几个例子,让你有个感性的认识,比如Elasticsearch的 /_cluster/health 接口。
[root@dev01.nj ~]# curl -uelastic:Pass1223 http://10.206.0.7:9200/_cluster/health -s | jq .
{
"cluster_name": "elasticsearch-cluster",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 430,
"active_shards": 430,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 430,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}
我们可以看到,返回的内容大多是指标数值,转换成监控服务端要求的数据格式,传上去即可。除了 /_cluster/health ,还可以测试一下 /_cluster/stats,也能帮你了解这种获取指标的方式。
除了Elasticsearch,还有很多其他组件也是用这种方式来暴露指标的,比如RabbitMQ,访问 /api/overview 可以拿到Message数量、Connection数量等概要信息。再比如 Kubelet,访问 /stats/summary 可以拿到Node和Pod等很多概要信息。
不同的接口返回的内容虽然都是指标数据,但是要推给监控服务端,还是要做一次格式转换,比如统一转换为 Prometheus 的文本格式。要是这些组件都直接暴露 Prometheus 的协议数据就好了,使用统一的解析器,就能大大简化监控采集逻辑。所幸这个趋势正在发生,上一讲我们也提到了,像etcd、CoreDNS、新版ZooKeeper、新版RabbitMQ、nginx-vts等,都内置暴露了 Prometheus 协议数据,可谓行业幸事。
这种拉取监控数据的方式虽然需要做一些数据格式的转换,但并不复杂。因为目标对象会把需要监控的数据直接通过接口暴露出来,监控采集器把数据拉到本地做格式转换即可。更复杂的方式是需要我们连接到目标对象上执行指令,MySQL、Redis、MongoDB等都是这种方式,下面我们就来一起看一下这种采集方式的工作原理。
连接到目标对象执行命令
目前最常用的数据库就是MySQL和Redis了,我们就拿这两个组件来举例。先说MySQL,我们经常需要获取一些连接相关的指标数据,比如当前有多少连接,总共拒绝了多少连接,总共接收过多少连接,登录MySQL命令行,使用下面的命令可以获取。
mysql> show global status like '%onn%';
+-----------------------------------------------+---------------------+
| Variable_name | Value |
+-----------------------------------------------+---------------------+
| Aborted_connects | 3212 |
| Connection_errors_accept | 0 |
| Connection_errors_internal | 0 |
| Connection_errors_max_connections | 0 |
| Connection_errors_peer_address | 0 |
| Connection_errors_select | 0 |
| Connection_errors_tcpwrap | 0 |
| Connections | 3281 |
| Locked_connects | 0 |
| Max_used_connections | 13 |
| Max_used_connections_time | 2022-10-30 16:41:35 |
| Performance_schema_session_connect_attrs_lost | 0 |
| Ssl_client_connects | 0 |
| Ssl_connect_renegotiates | 0 |
| Ssl_finished_connects | 0 |
| Threads_connected | 1 |
+-----------------------------------------------+---------------------+
16 rows in set (0.01 sec)
Threads_connected 表示当前有多少连接,Max_used_connections 表示曾经最多有多少连接,Connections表示总计接收过多少连接。当然,除了连接数相关的指标,通过 show global status 还可以获取很多其他的指标,这些指标用于表示MySQL的运行状态,随着实例运行,这些数据会动态变化。
还有另一个命令 show global variables 可以获取一些全局变量信息,比如使用下面的命令可以获取MySQL最大连接数。
mysql> show global variables like '%onn%';
+-----------------------------------------------+-----------------+
| Variable_name | Value |
+-----------------------------------------------+-----------------+
| character_set_connection | utf8 |
| collation_connection | utf8_general_ci |
| connect_timeout | 10 |
| disconnect_on_expired_password | ON |
| init_connect | |
| max_connect_errors | 100 |
| max_connections | 5000 |
| max_user_connections | 0 |
| performance_schema_session_connect_attrs_size | 512 |
+-----------------------------------------------+-----------------+
9 rows in set (0.01 sec)
其中 max_connections 就是最大连接数,这个数值默认是151。在很多生产环境下,都应该调大,所以我们要把这个指标作为一个告警规则监控起来,如果发现这个数值太小要及时告警。
当然,除了刚才介绍的两个命令,我们还可以执行其他命令获取其他数据库指标,比如 show slave status 可以获取Slave节点的信息。总的来看,MySQL监控的原理就是,连上MySQL后执行各种SQL语句,解析结果,转换为监控时序数据。
上面例子中的SQL语句都是用来获取MySQL实例运行状态的。实际上,既然可以执行SQL语句,我们就可以自定义一些SQL来查询业务数据,获取业务指标。上一讲我们也提到过,业务指标数据是整个监控体系中价值最大的,我们要好好利用这个能力。
比如有个 orders 表存储了订单数据,那我们就可以使用下面的语句获取订单总量。
把 order_total 这个返回值作为最终的监控数据上报即可。这种方式对于一些比较简单的单表场景还是挺好用的。但如果业务侧有分库分表,就需要用一些更复杂的手段来解决了。
Redis也是类似的,比如我们通过 redis-cli 登录到命令行,执行 info memory 命令,就可以看到很多内存相关的指标。
127.0.0.1:6379> info memory
# Memory
used_memory:1345568
used_memory_human:1.28M
used_memory_rss:3653632
used_memory_rss_human:3.48M
used_memory_peak:1504640
used_memory_peak_human:1.43M
used_memory_peak_perc:89.43%
used_memory_overhead:1103288
used_memory_startup:1095648
used_memory_dataset:242280
used_memory_dataset_perc:96.94%
...
虽然我把输出截断了,但也很容易看出所以然,输出的指标是Key:Value的格式,Value部分有的带着单位,解析的时候需要注意一下,做一个格式转换。
有些业务数据可能是存在Redis里的,所以监控Redis不只是获取Redis自身的指标,还应该支持自定义命令,获取一些业务数据,比如下面的命令,用于获取订单总量。
这个例子是假设业务程序会自动更新 Redis Key:/orders/total,用这个Key来存放订单总量。

讲到这里,我们就把常见的OS和中间件的监控讲完了,按照上一讲的监控分层架构图,接下来就是应用监控和业务监控,应用监控和业务监控有两种典型的采集手段,一个是埋点,一个是日志解析。
代码埋点
所谓的代码埋点方式,是指应用程序内嵌一些监控相关的SDK,在请求的关键链路上调用SDK的方法,告诉SDK当前是个什么请求、耗时多少、是否成功之类的,SDK汇总这些数据并二次计算,最终推给监控服务端。
比如一个用Go写的Web程序,提供了10个HTTP接口,我们想获取这10个接口的成功率和延迟数据,那就要写程序实现这些逻辑,包括数据采集、统计、转发给服务端等。这些监控相关的逻辑是典型的横向需求,这个Web程序有需求,其他的程序也有这个需求,所以就把这部分代码抽象成一个统一的Lib,即上面提到的这个SDK,每个需要监控逻辑的程序都可以复用这个SDK,提升效率。
但是每个项目都要调用这个SDK的方法仍然显得很冗余,是否有更简单的办法呢?有!每个公司可以建立统一的框架开发团队,开发统一的HTTP框架,在框架里使用AOP的编程方式,内置采集这些监控数据。这样一来,只要某个团队用了这个统一的HTTP框架,就自动具备了监控埋点能力。同理,我们也可以构建统一的RPC调用框架,统一的MySQL调用框架,这样就逐步构建了统一且完备的应用监控数据收集体系。
这种方式需要内嵌SDK,对代码有侵入性,是否有更简单的办法呢?有!对于Java这种字节码语言,我们可以使用 JavaAgent 技术,动态修改字节码,自动获取监控数据,到Google上通过关键词“javaagent monitoring”可以找到很多资料。
当然,现在也开始流行 eBPF 技术,有些厂商在尝试,你也可以关注下。不过在生产实践中,我观察大部分厂商还是在用埋点的方式采集监控数据,后面第19讲我会专门给你演示如何做埋点。
对于自研的程序,代码埋点是没问题的,但是很多程序可能是外采的,我们没法修改它的源代码,这时候就要使用日志解析的方式了。一般程序都会打印日志,我们可以写日志解析程序,从日志中提取一些关键信息,比如从业务日志中很容易拿到Exception关键字出现的次数,从接入层日志中很容易就能拿到某个接口的访问次数。这部分内容我们会在第20讲详细演示,这里就不过多介绍了。
小结
今天我们介绍了多种监控数据的采集方式,帮助我们从原理的角度来理解监控数据采集这部分内容,后面再遇到监控指标获取不到的问题,我们也可以从原理上做一些排查。
总的来看,OS层面的监控需要把Agent部署到机器里,读取一些本地的特殊文件,执行一些命令来获取监控数据;数据库、中间件的监控,大都是远程采集,只是协议各异,需要做一定的适配;应用监控的话,典型的采集方式有两种,一个是代码埋点,一个是日志解析。最后我把这一讲的内容总结成了一张脑图,帮你理解和记忆。
互动时刻
学完这一讲的内容,是不是感觉监控是个非常驳杂的领域?确实是这样,我们这一讲只介绍了一些常见的监控数据采集方法,实际上还有一些其他的方法没有介绍,你还知道哪些方法,欢迎在评论区留言,我们一起讨论,也欢迎你把今天的内容分享给你身边的朋友,邀他一起学习。我们下一讲再见!
- MrPolo 👍(3) 💬(1)
請教老師會介紹到 open telemetry 這塊嗎,最近看到這似乎把 log,trace,metric 都包進去了?
2023-01-30 - hshopeful 👍(3) 💬(1)
在我的认知范围内,关于监控数据的采集方式,老师已经讲得很全面的,还有一种方式其实跟上面的类似: 很多年之前有些开源软件会将自身计算好的指标维护在本地日志中,agent 读取日志,不需要做正则匹配,直接获取指标;当然这种方式随着 prometheus 的流行,这些开源软件都会将计算好的指标通过接口提供出去。 还有哪些方式,希望老师能讲一下,谢谢!
2023-01-30 - Geek_986cad 👍(1) 💬(1)
思考题: 有些监控信息并不能直接采集,也不能通过监控软件已有的函数等功能计算得出。 比如我们如果关心 mysql 数据库 24h 之内的主从切换次数的信息, 如果想采集这类信息,就需要在被采集端编写监控程序,最后再把数据“推”,“拉”到监控服务器。
2023-02-03 - peter 👍(1) 💬(1)
请教老师两个问题: Q1:MySQL的max_connections是同时最大连接数吗? 文中有这一句:“max_connections 就是最大连接数,这个数值默认是 151”。max_connections是累计连接数吗?还是同时最大连接数? 如果是同时连接数,设置为5000是不是太大了? Q2:统一框架是否有开源的实现?
2023-01-30 - 奕 👍(0) 💬(1)
Prometheus 协议数据 是 Prometheus 定义好的规范吗? 其他中间件按照这个协议实现,Prometheus 就可以直接解析
2023-01-30 - 隆哥 👍(0) 💬(1)
老师,后面会说k8s内部署promethes和如何配置告警规则啥的嘛,这块是刚需呢!!!
2023-01-30