06 PromQL有哪些常见的使用场景?
你好,我是秦晓辉。
上一讲我们介绍了 Prometheus 中的一些关键设计,比如注重标准和生态、监控目标动态发现机制、PromQL等,其中 PromQL 是 Prometheus 的查询语言,使用起来非常灵活方便,但很多人不知道如何更好地利用它,发挥不出它的优势。所以这一讲我们就来梳理一下PromQL的典型应用场景。
PromQL主要用于时序数据的查询和二次计算场景。我们先来回顾一下时序数据,在脑子里建立起时序数据的具象视图。
时序数据
我们可以把时序数据理解成一个以时间为轴的矩阵,你可以看一下我给出的例子,例子中有三个时间序列,在时间轴上分别对应不同的值。
^
│ . . . . . . . . . . node_load1{host="host01",zone="bj"}
│ . . . . . . . . . . node_load1{host="host02",zone="sh"}
│ . . . . . . . . . . node_load1{host="host11",zone="sh"}
v
<------- 时间 ---------->
每一个点称为一个样本(sample),样本由三部分组成。
- 指标(metric):metric name和描述当前样本特征的labelsets。
- 时间戳(timestamp):一个精确到毫秒的时间戳。
- 值(value):表示该时间样本的值。
PromQL就是对这样一批样本数据做查询和计算操作。
PromQL典型的应用场景
PromQL典型的应用场景就是时序数据的查询和二次计算,这也是PromQL的两个核心价值,其中查询操作靠的就是查询选择器,下面我们就来详细地看一下。
查询选择器
随便一个公司,时序数据至少都有成千上万条,而每个监控图表的渲染或者每条告警规则的处理,都只是针对有限的几条数据,所以PromQL第一个需求就是过滤。假设我有两个需求,一是查询上海所有机器1分钟的负载,二是查询所有以host0为前缀的机器1分钟的负载。PromQL的写法是怎样的呢?你可以看一下。
大括号里写过滤条件,主要是针对标签过滤,操作符除了等于号和正则匹配之外,还有不等于 != 和正则非 !~。这个比较容易理解,不过多介绍了。需要注意的是,metric name 也是一个非常重要的过滤条件,可以写到大括号里,比如我想同时查看上海机器的 load1、load5、load15 三个指标,可以对 __name__,也就是 metric 名字做正则过滤。
上面的例子中,我给出的3条PromQL都叫做即时查询(Instant Query),返回的内容叫做即时向量( Instant Vector)。
即时查询返回的是当前的最新值,比如 10 点整发起的查询,返回的就是 10 点整这一时刻对应的数据。但是监控数据是周期性上报的,并非每时每刻都有数据上报,10 点整的时候可能恰恰没有数据进来,此时 Prometheus 就会往前看,看看9点59、9点58、9点57等时间点有没有上报数据。最多往前看多久呢?
这个数据由Prometheus的启动参数 --query.lookback-delta 控制,这个参数默认是 5 分钟。从监控的角度来看,我建议你调短一些,比如改成 1 分钟 --query.lookback-delta=1m。为什么呢?
我举个例子来说明一下,我们有个客户使用 Telegraf 做 HTTP 探测,配置了一个告警规则,说 response_code 连续 3 分钟都不等于 200 才告警。实际上只有一个数据点的 response_code 不等于200,过了3分钟还是报警了。他感觉非常困惑,就来问我为什么。
实际上,主要有两个原因,一是因为 Telegraf 的 HTTP 探测,会默认把 status code 放到标签里,这会导致标签非稳态结构(这个行为不太好,最好是把这类标签直接丢弃掉,或者使用categraf、blackbox_exporter做采集器),平时 code=200,出问题的时候 code=500,在 Prometheus 生态里,标签变了就是新的时间序列了。
第二个原因就跟 query.lookback-delta 有关了,虽然只有一个点异常,也就是说 code=500 的这个时间序列只有一个点,但是告警规则每次执行查询的时候,都是查到这个异常点,连续5分钟都是如此。所以就满足了规则里连续3分钟才告警的这个条件,触发了告警。这就是我建议你把 --query.lookback-delta 调短的原因。
除了即时查询,PromQL中还有一种查询,叫做范围查询(Range Query),返回的内容叫做 Range Vector,比如下面的 PromQL。
相比即时查询,范围查询就是多加了一个时间范围1分钟。即时查询每个指标返回一个点,范围查询会返回多个点。假设数据10秒钟采集一次,1分钟有6个点,都会返回。
Prometheus 官方文档在介绍各个函数的使用方法的时候,都会讲解函数参数,标明是 Range Vector 还是 Instant Vector,这两种查询方式是基础知识,你需要牢牢掌握。
上面说的就是PromQL第一个核心价值——筛选。接下来我们看PromQL的另一个核心价值——计算。计算部分内容比较多,有算术、比较、逻辑、聚合运算符等,下面我们来一一看下。
算术运算符
算术运算符比较简单,就是我们常用的加减乘除、取模之类的符号。这里我给出了两个例子,你可以结合这两个例子来了解它的应用场景。
# 计算内存可用率,就是内存可用量除以内存总量,又希望按照百分比呈现,所以最后乘以100
mem_available{app="clickhouse"} / mem_total{app="clickhouse"} * 100
# 计算北京区网口出向的速率,原始数据的单位是byte,网络流量单位一般用bit,所以乘以8
irate(net_sent_bytes_total{zone="beijing"}[1m]) * 8
比较运算符
比较运算符就是大于、小于、等于、不等于之类的,理解起来也比较简单,但是意义重大,告警规则的逻辑就是靠比较运算符来支撑的。这里我也举两个例子,你结合例子来理解会更容易。
mem_available{app="clickhouse"} / mem_total{app="clickhouse"} * 100 < 20
irate(net_sent_bytes_total{zone="beijing"}[1m]) * 8 / 1024 / 1024 > 700
带有比较运算符的 PromQL 就是告警规则的核心,比如内存可用率的告警,在 Prometheus 中可以这样配置。
groups:
- name: host
rules:
- alert: MemUtil
expr: mem_available{app="clickhouse"} / mem_total{app="clickhouse"} * 100 < 20
for: 1m
labels:
severity: warn
annotations:
summary: Mem available less than 20%, host:{{ $labels.ident }}
例子中的 expr 指定了查询用的 PromQL。告警引擎会根据用户的配置,周期性地执行查询。如果查不到就说明一切正常,没有机器的内存可用率低于20%。如果查到了,就说明触发了告警,查到几条就触发几条告警。当然,偶尔一次低于 20% 不是什么大事,只有连续1分钟每次查询都低于20%才会告警,这就是 for: 1m 存在的意义。
逻辑运算符
逻辑运算符有3个,and、or和unless,用于 instant-vector 之间的运算。and 是求交集,or是求并集,unless是求差集。我们来看一个 and 的使用场景。
关于磁盘的使用率问题,有的分区很大,比如16T,有的分区很小,比如50G,像这种情况如果只是用磁盘的使用率做告警就不太合理,比如 disk_used_percent{app="clickhouse"} > 70 表示磁盘使用率大于 70% 就告警。对于小盘,这个策略是合理的,但对于大盘,70%的使用率表示还有非常多的空间,就不太合理。这时我们希望给这个策略加一个限制,只有小于200G的硬盘在使用率超过70%的时候,才需要告警,这时我们就可以使用 and 运算符,你可以看一下最终 PromQL。
同理,or和unless这两个逻辑运算符也是这样,你可以自己试一试。
算术、比较、逻辑运算符,基本的使用方式比较简单,但如果运算符两侧的向量标签不统一,就会面临一些更复杂的处理逻辑,需要在 PromQL 中给出向量匹配规则,下面我们就来一起看一下。
向量匹配
向量之间的操作是想要在右侧的向量中,为左侧向量的每个条目找到一个匹配的元素,匹配行为分为:one-to-one、many-to-one、one-to-many。刚才介绍的磁盘使用率的例子,就是典型的 one-to-one 类型,左右两侧的指标,除了指标名,其余标签都是一样的,非常容易找到对应关系。但是有时候,我们希望用 and 求交集,但是两侧向量标签不同,怎么办呢?
此时我们可以使用关键字 on 和 ignoring 来限制用于做匹配的标签集。
这个PromQL想表达的意思是如果这个MySQL实例是个slave(master_server_id>0),就检查其slave_sql_running的值,如果slave_sql_running==0,就表示slave sql线程没有在运行。
但mysql_slave_status_slave_sql_running和mysql_slave_status_master_server_id这两个metric的标签,可能并非完全一致。不过好在二者都有个instance标签,且相同的instance标签的数据从语义上来看就表示一个实例的多个指标数据,那我们就可以用关键字on来指定只使用instance标签做匹配,忽略其他标签。
与on相反的是关键字ignoring,顾名思义,ignoring是忽略掉某些标签,用剩下的标签来做匹配。我们拿 Prometheus 文档中的例子来说明。
## example series
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
## promql
method_code:http_errors:rate5m{code="500"}
/ ignoring(code)
method:http_requests:rate5m
## result
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
例子里都是 one-to-one 的对应关系,这个好理解。难理解的是 one-to-many 和 many-to-one,这种情况下,做指标运算时就要借助关键字 group_left 和 group_right 了。left、right 指向高基数那一侧的向量。还是用上面method_code:http_errors:rate5m和method:http_requests:rate5m 这两个指标来举例,你可以看一下使用 group_left 的PromQL和输出的结果。
## promql
method_code:http_errors:rate5m
/ ignoring(code) group_left
method:http_requests:rate5m
## result
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
比如针对 method="get" 的条目,右侧的向量中只有一个记录,但是左侧的向量中有两个记录,所以高基数的一侧是左侧,故而使用 group_left。
这里我再举一个例子,来说明 group_left、group_right 的一个常见用法。比如我们使用 kube-state-metrics 来采集 Kubernetes 各个对象的指标数据,其中针对 pod 有个指标是 kube_pod_labels,该指标会把 pod 的一些信息放到标签里,指标值是1,相当于一个元信息。
kube_pod_labels{
[...]
label_name="frontdoor",
label_version="1.0.1",
label_team="blue"
namespace="default",
pod="frontdoor-xxxxxxxxx-xxxxxx",
} = 1
假设某个 Pod 是接入层的,统计了很多 HTTP 请求相关的指标,我们想统计 5xx 的请求数量,希望能按 Pod 的 version 画一个饼图。这里有个难点:接入层的请求类指标没有 version 标签,version 信息只出现在 kube_pod_labels 里,那怎么让二者联动呢?
上答案!
sum(
rate(http_request_count{code=~"^(?:5..)$"}[5m])) by (pod)
*
on (pod) group_left(label_version) kube_pod_labels
我们把这个 PromQL掰开揉碎,看一下具体的意思,乘号前面的部分,是一个统计每秒 5xx 数量的典型语法,按照 pod 维度做分组统计。
然后我们乘以 kube_pod_labels,这个值是1。任何值乘以1都是原来的值,所以对整体数值没有影响,而 kube_pod_labels 有多个标签,而且和 sum 语句的结果向量的标签不一致,所以通过 on(pod) 语法来指定只按照 pod 标签来建立对应关系。
最后,利用 group_left(label_version),把 label_version 附加到了结果向量里,高基数的部分显然是 sum 的部分,所以使用 group_left 而非 group_right。
聚合运算
除了前面我们说的查询需求外,针对单个指标的多个 series,还会有一些聚合需求。比如说,我想查看100台机器的平均内存可用率,或者想要排个序,取数值最小的10台。这种需求可以使用 PromQL 内置的聚合函数来实现。
# 求取 clickhouse 的机器的平均内存可用率
avg(mem_available_percent{app="clickhouse"})
# 把 clickhouse 的机器的内存可用率排个序,取最小的两条记录
bottomk(2, mem_available_percent{app="clickhouse"})
另外,我们有时会有分组统计的需求,比如我想分别统计 clickhouse 和 canal 的机器内存可用率,可以使用关键字 by 指定分组统计的维度(与 by 相反的是 without)。
注意:这些聚合运算,可以理解为纵向拟合。你可以想象一下,100 台机器的内存可用率,在折线图上有100条线,如果我们想要把这100条线拟合成一条线,就相当于把每个时刻的100个点拟合成1个点。那怎么让100个点变成1个点呢?求个平均值或最大值之类的,就可以实现,所以就有了这些聚合运算符。
还有一类聚合运算函数,可以看作是横向拟合,也就是 <aggregation>_over_time 类的函数。这些函数接收范围向量,因为范围向量是一个时段内有多个值,<aggregation> 就是对这多个值做运算。
target_up 指标后面加了 [2m],指的就是获取这个指标最近 2 分钟的所有数据点,如果15秒采集一个点,2分钟就是8个点,max_over_time就是对这8个点求最大值,相当于对各个时间序列做横向拟合。
容易误解的函数
除了上面我们说的这些常用的聚合函数外,Prometheus还内置了很多其他函数,其中用得最广并且最容易被人误解的是 increase 和 rate 函数,我们讲一讲这两个函数。
先来看 increase 函数,字面意思上表示求取一个增量,接收一个 range-vector,range-vector 显然是会返回多个 value+timestamp 的组合。我们直观地理解就是,直接把时间范围内的最后一个值减去第一个值,不就可以得到增量了吗?非也!
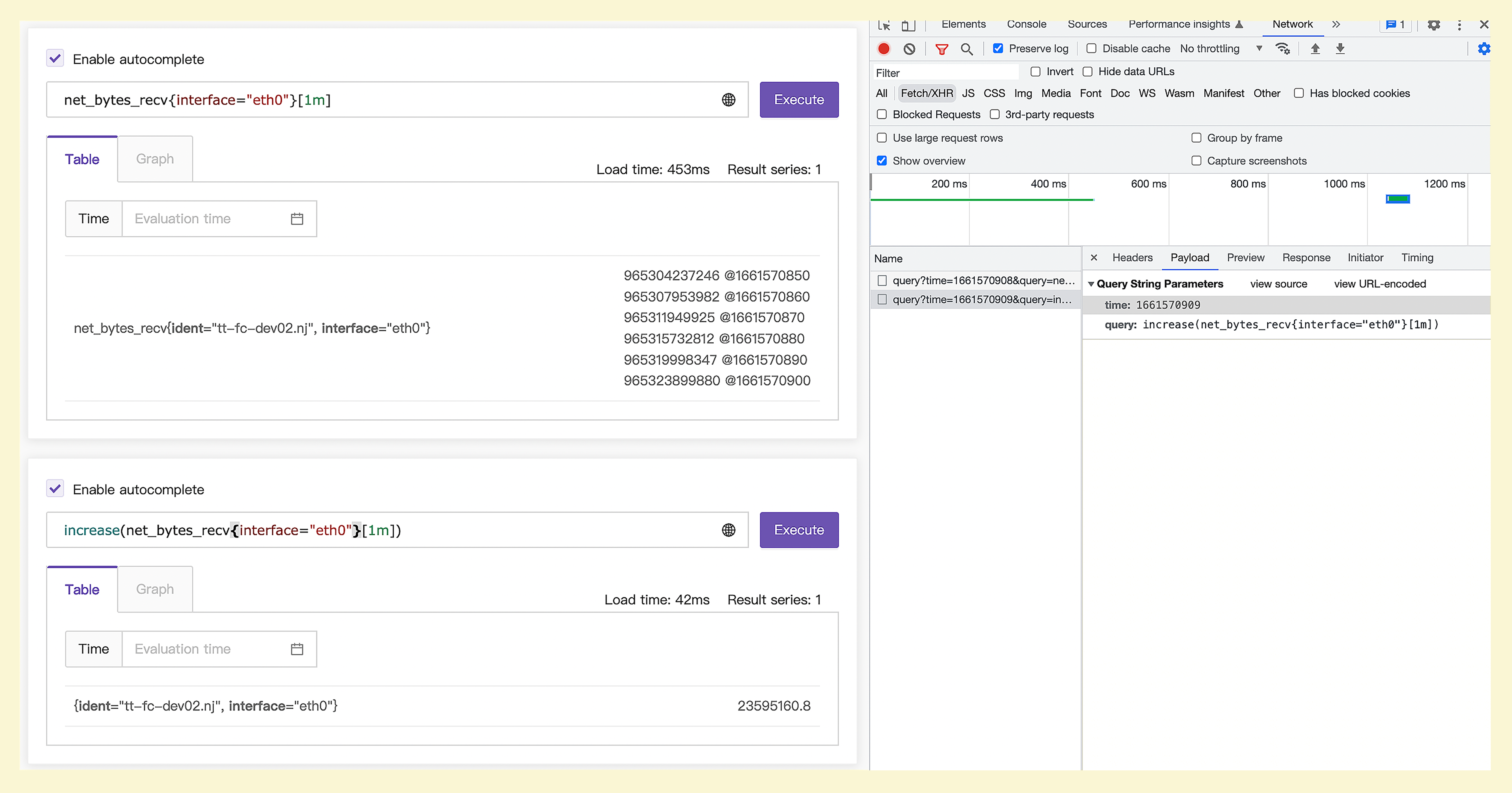
你可以看一下这张图,图里的一些关键信息,我摘录成了文本,你可以看一下。
promql: net_bytes_recv{interface="eth0"}[1m] @ 1661570908
965304237246 @1661570850
965307953982 @1661570860
965311949925 @1661570870
965315732812 @1661570880
965319998347 @1661570890
965323899880 @1661570900
promql: increase(net_bytes_recv{interface="eth0"}[1m]) @1661570909
23595160.8
监控数据是10秒上报一次,所以虽然两次 PromQL 查询时间不同,一次是 1661570908,一次是 1661570909,但是所查询的原始数据内容是一样的,就是 1661570850~1661570900 这几个时间点对应的数据。
直观上理解,在这几个时间点对应的数据上求取 increase,无非就是最后一个值减去第一个值,即965323899880-965304237246=19662634。不过很遗憾,实际结果是23595160.8,差别有点大,显然这个直观理解的算法是错的。
实际上,increase 这个 PromQL 发起请求的时间是1661570909,时间范围是[1m],相当于告诉Prometheus,我要查询1661570849(由1661570909-60得出)~1661570909之间的 increase 数值。但是原始监控数据并没有 1661570849、1661570909 这两个时刻的数值,怎么办呢?
Prometheus只能基于现有的数据做外推,也就是使用最后一个点的数值减去第一个点的数值,得到的结果除以时间差,再乘以60。
$$(965323899880.0-965304237246.0)\div(1661570900.0-1661570850.0)\times60=23595160.8$$
这样最终就得到了1分钟的 increase 值,是个小数。趁热打铁,我们再说一下 rate 函数,increase 函数是求取的时间段内的增量,而且有数据外推,rate 函数则求取的是每秒变化率,也有数据外推的逻辑,increase 的结果除以 range-vector 的时间段的大小,就是 rate 的值。我们用下面的 PromQL 验证一下。
rate(net_bytes_recv{interface="eth0"}[1m])
== bool
increase(net_bytes_recv{interface="eth0"}[1m])/60.0
这里 == 后面跟了一个 bool 修饰符,表示希望返回一个 bool 值,如果是 True 就会返回 1,如果是 False 就返回 0。我们观察结果后发现,这个表达式永远都会返回 1,即等号前后的两个 PromQL 语义上是相同的。
rate 函数求取的变化率,相对平滑。因为是拿时间范围内的最后一个值和第一个值做数据外推,一些毛刺现象就会被平滑掉。如果想要得到更敏感的数据,我们可以使用 irate 函数。irate 是拿时间范围内的最后两个值来做计算,变化就会更剧烈,我们拿网卡入向流量这个指标来做个对比。
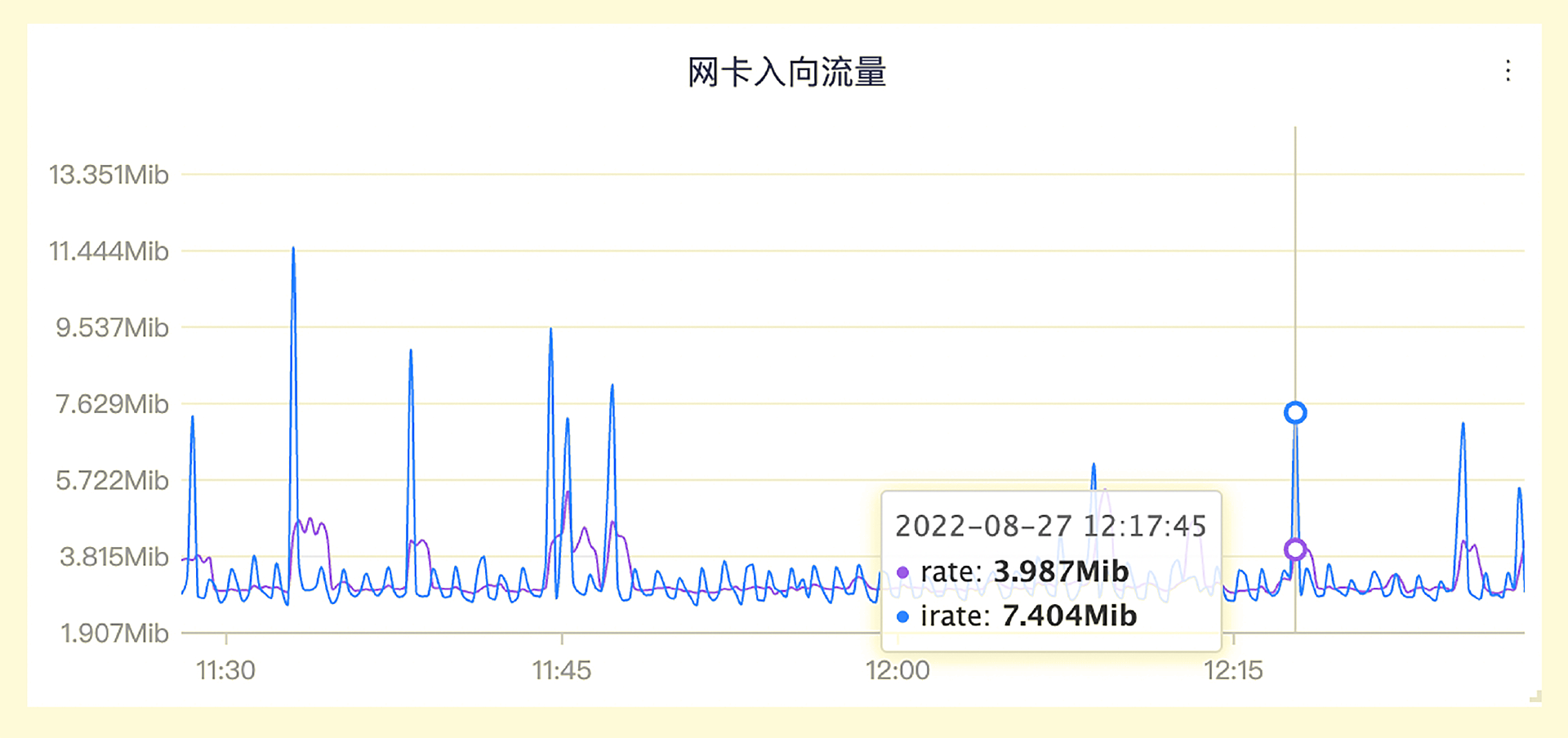
蓝色的变化得更剧烈的线是用 irate 函数计算得到的,而紫色的相对平滑的线是用 rate 函数计算得到的,对比还是很强烈的。
小结
这一讲我们以实际场景为出发点,介绍了不同场景下如何使用 PromQL。为了让你更好地理解,我们回顾了时序数据的内容,你需要在脑海里建立一个时序数据的二维图像,方便你之后理解和使用 PromQL。
我们还重点讲解了PromQL的两个核心价值,一个是筛选,一个是计算。筛选是靠查询选择器,查询分为即时查询和范围查询。计算部分内容较多,有算术、比较、逻辑、聚合运算符,还有向量匹配逻辑,特别是 group_left 和 group_right,比较难理解,需要你仔细推敲。
函数部分比较重要的是 increase 和 rate,其实 histogram_quantile 也很常用而且比较难理解,不过我们在前面的第2讲中已经介绍过 histogram_quantile 的计算逻辑了,这里就不再重复。
互动时刻
Prometheus 中提供了一个函数叫 absent,用于做数据缺失告警,使用得也很广泛,但是坑也挺大。这里我留给你一个问题:如果我想对 100 台机器的 node_load1 做数据缺失告警,应该如何配置?这个需求用 absent 解决合适吗?你能否给出 absent 的最佳使用场景?
欢迎留言讨论,也欢迎你把今天的内容分享给你身边的朋友,邀他一起学习。我们下一讲再见!
- peter 👍(4) 💬(1)
请问:注册用户100万的网站,适合用Prometheus吗?
2023-01-21 - Ppppppp 👍(2) 💬(2)
关于标签问题,之前写代码踩过很多坑,一查promql一大堆 T.T 后来自己总结的就是所有很难发生变化的数据写标签,但是别什么乱七八糟的都加进去,只写和业务有关的;变化频繁的值写到measurement。
2023-03-05 - Goal 👍(2) 💬(1)
absent(node_load1{instance=~".*"}) absent_over_time(node_load1{job="node-exporter"}[5m]) 传递给absent的任意一个时间序列有值,那么整体 absent() 就是为空; 至于答案,还没有想到好的解决方案
2023-01-28 - 金尚 👍(1) 💬(1)
老师我一次性想查询多个指标怎么做。例如:服务器的带宽,上下行速率,丢包数等。
2023-06-30 - 那时刻 👍(1) 💬(1)
思考题:通过参考了下absent文档,我的答案如下,烦请老师指正 如果我想对 100 台机器的 node_load1 做数据缺失告警,应该如何配置? count(node_load1 offset 1h) by (instance) unless count(node_load1} ) by (instance) absent不适合这个场景,因为absent表示指标的有无(存在与否)。
2023-02-01 - lei 👍(1) 💬(1)
大年初一来过,祝大家新年快乐!
2023-01-22 - hshopeful 👍(1) 💬(1)
另外由思考题想到一个场景:在 prometheus 体系下怎么做监控和配置告警来监控服务器挂掉的场景,希望老师能提供几种思路并说说每种思路的优缺点
2023-01-20 - hshopeful 👍(1) 💬(1)
思考题中:在没有其他 label 的情况下,直接在 prometheus 里面查询 absent(node_load1{}),得到的是 empty query result。在外面在封一层 absent 函数 absent(absent(node_load1{})),可以得到指标 {} 的值为 0,这种场景下面,即使在告警中配置 {} 值 为 0 的告警真的触发了,也不确定到底是哪个指标无数据触发的,所以感觉这个需求使用 absent 并不合适;那么我认为适合使用 absent 的场景是指标拥有的 labelsets 集合能够代表指标的时候。不知道说的对不对,麻烦老师指正下,谢谢!
2023-01-20 - Geek_51809f 👍(0) 💬(1)
老师你好, 文中提到 irate 是拿时间范围内的最后两个值来做计算,这个怎么理解的?方便举例说明一下吗
2023-03-21 - Geek_51809f 👍(0) 💬(1)
老师你好!问一下 rate 是计算的每秒变化率? 还是每秒变化数量? 举例 :sum(rate(http_server_requests_seconds_count{application="$application", instance="$instance"}[1m])) 这个是表示 每秒http请求增长数量?还是每秒http请求增长率?
2023-03-20 - penng 👍(0) 💬(1)
PromQL查询能够限制时间戳吗?比如我有些指标是1个月前的,在查询时会把他查出来,我现在不想查询它。结果为空就好
2023-02-14 - hello 👍(0) 💬(2)
老师您好,我们的业务指标用的prometheus + grafana,是这样的我们每天都有一个活跃uv统计,使用 counter 类型记入prometheus指标,我一直在寻找怎么看过去一周每天的uv总数,如果我使用1d的位移,grafana默认取每天8点的 value,而我想取的是每天最后一刻的值,直到我看到您这篇文章 我改成了 max_over_time(total_uv[1d]) , 但是又引入了一个新的问题,每个横坐标日期展示的是前一天的指标值,不知道我是否有描述清楚,您是否有遇到这样的问题,有没有解决方案? 总结一下,就是每天一个counter,取每天末最大的counter 绘图
2023-02-07 - 那时刻 👍(0) 💬(1)
思考题:如果我想对 100 台机器的 node_load1 做数据缺失告警,应该如何配置。 count( group( last_over_time(node_label1[10m]) ) by (instance) ) < 100 对于node label最近10分钟的数据按照 instance进行 group计数,如果数量小于 100,则报警。当然这个10分钟可以按需调节。
2023-02-02 - Dowen Liu 👍(4) 💬(0)
能不能提供下 prometheus 的 tsdb snapshot 啊。可以本地导入做下实验,有问题也可以以统一的数据基础反馈提问。
2023-01-28 - lei 👍(1) 💬(0)
可不可以讲下prometheus 如何做动态扩展,保证高可用?如果需要数据可迁移,是不是就要搭建两个实例,然后这两个实例需要互通吗?谢谢
2023-01-22