你好,我是潘野。
上一讲里,我们掌握了如何使用Kubernetes HPA这个工具,它配合Prometheus-Adapter即可实现应用的水平扩展能力。
不过,其中我们也发现了Prometheus-Adapter的一些局限性,例如依赖Prometheus,大部分情况下不能做到开箱即用,需要应用开发自定义Prometheus metrics,才能配合HPA使用。
那么有没有开箱即用型的工具,也能够配合HPA实现水平扩展呢?这就是我们今天要学习的KEDA。
KEDA的由来
在Kubernetes诞生的时候,第一个专门为 Kubernetes 设计的监控工具,叫Heapster。Heapster能够收集Node节点上的cAdvisor数据,获取pod的CPU、内存、网络和磁盘的指标,它与 Horizontal Pod Autoscaler (HPA) 等工具结合使用,即可实现自动扩缩容。
但是2016年Prometheus从CNCF毕业之后,社区转向支持Prometheus,停止了对Heapster的维护。直到2018年的10月,Prometheus-Adapter才首次发布,直到2019年4月,Prometheus-Adapter才支持了Kubernetes HPA,所以在那段时期,Kubernetes社区还没有非常成熟的自动扩缩容方案。
在这种背景下,2019 年11月微软发布了基于事件驱动型的自动扩缩容工具 KEDA。最值得我们注意的是,与Prometheus-Adapter设计方向不同,KEDA选择是事件驱动方式的扩缩容。
事件驱动
我们先理解一下什么是事件驱动。事件驱动是一种编程模型,在这种模型中,程序的执行是由事件驱动的。事件可以是任何事情,例如用户输入、网络请求或计时器超时。当事件发生时,程序会执行相应的事件处理程序。
KEDA就借鉴了事件驱动模型,根据各种事件源(例如消息队列、流平台等)的事件触发 Pod 的扩缩容。这里我举一个场景帮助你们来理解KEDA中的事件驱动模型。
很多应用都会用到像Kafka、RabbitMQ这样的消息队列中间件。消息队列里一头是生成者,不断地向队列中传递信息;另一头则是消费者,接受队列中的信息。
如果消费者的速度跟不上生产者的速度,消息队列中就会产生积压的消息,当积压的消息数量超过一定阈值,就会产生一个事件,诸如“队列中消息数量超过了X值”。这时,KEDA就会接收到这个事件,并且自动触发扩容消费者的数量,提高消费者的速度,减少队列中的消息积压,这就是KEDA基于事件驱动模型的原理。
那么上一讲里,我提到过Prometheus-Adapter的不足,比如反应慢半拍或者服务抖动问题。而KEDA就从事件驱动角度解决了这些问题,我们一起梳理一下大致的过程。
首先,当应用负载增加时,HPA 会生成一个事件并将其发布到 KEDA 事件队列,KEDA ScaledJob 控制器订阅 KEDA 事件队列,并接收 HPA 事件。
接下来,KEDA ScaledJob 控制器根据 HPA 事件中的负载信息,创建一个新的 ScaledJob。ScaledJob 会根据指定的 Pod 模板,创建新的 Pod。当新的 Pod 启动完成后,进入Ready状态,开始处理请求。
KEDA 事件驱动架构允许 KEDA 控制器在收到 HPA 事件后立即创建新的 Pod。这让应用能快速响应负载变化,不至于反应慢半拍。此外,KEDA ScaledJob 控制器可以根据负载情况平滑地扩缩容 Pod。这样应用就能避免服务抖动问题,提高其可靠性。
KEDA的架构与用法
前面,我提到事件驱动、KEDA ScaledJob等名词,接下来我们不妨结合官方提供的架构图,了解一下KEDA的组成部分和工作原理。

首先我们定义了 ScaledObject,这是KEDA的自定义资源定义(CRD),用于定义自动伸缩的规则和目标。它可以用来定义触发器类型(例如RabbitMQ、Kafka等)、触发器元数据、最小和最大副本数等参数。
接下来是事件源,也就是图片里右下角蓝色图标 External trigger source 的位置。 KEDA支持多种事件源,例如 HTTP 请求、消息队列消息、数据库连接等。当事件源产生新的事件时,KEDA会自动触发自动伸缩。
事件源具体触发的就是自动伸缩 Scaler。Scaler的作用是接收事件并将其转换为 Kubernetes 可以理解的格式,然后根据ScaledObject定义的规则决定是否需要进行伸缩。
KEDA内置了很多种Scaler,例如基于Kafka topic的,也有基于MySQL或者PostgreSQL数据库的。你可以课后查询官方文档了解详细内容。
最后是 Metrics Adapter,Metrics Adapter是KEDA与Kubernetes HPA(Horizontal Pod Autoscaler)之间的桥梁,用于将Scaler查询到的事件数量转化为Kubernetes HPA可以理解的度量值。
配置样例
了解了KEDA原理之后,我们还是来看看例子加深理解。官方文档中刚好有一个消息对立RabbitMQ的样例,我们来看看KEDA是如何实现中间件扩缩容的。
我们首先要部署一个RabbitMQ。注意虽然官方文档中并未提及,但RabbitMQ需要配置memory limit。你可以按照下面这个命令安装RabbitMQ。
helm install rabbitmq --set auth.username=user --set auth.password=PASSWORD --set resources.limits.memory="256Mi" bitnami/rabbitmq
接下来,我们新建一个叫rabbitmq-consumer的Deployment,这里你可以直接参考 GitHub上的代码。
然后,我们来配置KEDA的ScaledObject,对照后面的配置代码,我为你梳理一下重点。
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-consumer
namespace: default
spec:
scaleTargetRef:
name: rabbitmq-consumer
pollingInterval: 5 # Optional. Default: 30 seconds
cooldownPeriod: 30 # Optional. Default: 300 seconds
maxReplicaCount: 30 # Optional. Default: 100
triggers:
- type: rabbitmq
metadata:
queueName: hello
queueLength: "5"
authenticationRef:
name: rabbitmq-consumer-trigger
我们从第七行看起,scaleTargetRef 是指我们需要对哪一个deployment进行扩缩容。而第十一行的 maxReplicaCount 可以指定这个扩容的最大副本数。之后,我们在 triggers 中配置type为 “rabbitmq”,并填写相关参数。再来看最后两行代码,authenticationRef的作用是指定用于认证 ScaledObject 的身份验证凭据,这里就是RabbitMQ的用户名、密码和链接地址的信息。
完成配置之后,我们来验证一下效果如何。
我们来运行一个Kubernetes Job,该job的作用是向RabbitMQ中填入数据。接下来,我们get pod的时候会看到有四个rabbitmq-consumer的pod启动了,这四个Pod是消费者,正在负责接收RabbitMQ队列中的数据。
>> kubectl get pod
NAME READY STATUS RESTARTS AGE
rabbitmq-0 1/1 Running 0 7m1s
rabbitmq-consumer-778744fb5d-7s779 1/1 Running 0 19s
rabbitmq-consumer-778744fb5d-9l292 1/1 Running 0 3s
rabbitmq-consumer-778744fb5d-njbnk 1/1 Running 0 3s
rabbitmq-consumer-778744fb5d-q6x7w 1/1 Running 0 3s
此时我们可以看到,ScaledObject已经准备就绪,处在激活的状态。
❯❯❯ kubectl get scaledobjects.keda.sh rabbitmq-consumer -oyaml
...
status:
conditions:
- message: ScaledObject is defined correctly and is ready for scaling
reason: ScaledObjectReady
status: "True"
type: Ready
- message: Scaling is performed because triggers are active
reason: ScalerActive
status: "True"
type: Active
看完刚刚的例子,估计你也发现了,相比Prometheus-Adapter来说,KEDA的配置过程方便了很多。
KEDA的优势
除了配置方便之外,我们来讨论一下KEDA都有哪些优势,我认为可以从三个角度去看。
1. 更灵活的扩缩容策略
KEDA 可以根据应用的实际负载进行扩缩容,而不是依赖于 CPU 或内存等资源指标。KEDA还可以根据负载的阶梯变化来扩缩容 Pod。例如,当负载增加 10% 时,KEDA 可以扩容 1 个 Pod。当负载增加 20% 时,KEDA 可以再扩容 2 个 Pod。
虽然Prometheus-Adapter也可以实现这样的自动扩容方式,但是需要将消息队列的metrics导入进Prometheus,需要维护的组件包括Prometheus、Prometheus-Adapter,消息队列的exporter等,相对来说对外部组件的依赖较多,维护成本较高。
2. 更快的扩缩容速度
与基于指标驱动的Prometheus-Adapter不同,KEDA 无需等待指标收集就能立即响应事件,从而快速扩缩容 Pod,这可以进一步缩短扩缩容的响应时间。而 Prometheus-Adapter 需要等待Prometheus定期收集指标数据,然后才能根据指标数据触发 Pod 的扩缩容,这意味着 KEDA 可以更快地应对突发负载,避免服务中断。
3. 更高的资源利用率
KEDA 利用了 Predictkube 这个AI-Base的Kubernetes扩容插件。 PredictKube 插件可以使用 Prometheus 历史数据来预测未来的负载,并提前扩容 Pod,以确保应用始终有足够的资源来处理负载,避免资源浪费或不足。
我们结合一个KEDA 预扩容的示例配置感受一下。在这个示例中,KEDA 将根据过去 7天的历史数据预测未来2小时的负载。如果预测的http_requests_total超过2000的时候,KEDA 将扩容 Pod。
triggers:
- type: predictkube
metadata:
# Required fields:
predictHorizon: "2h"
historyTimeWindow: "7d"
prometheusAddress: http://<prometheus-host>:9090
query: sum(irate(http_requests_total{pod=~"example-app-.*"}[2m]))
queryStep: "2m"
threshold: '2000'
有小伙伴要问了,Prometheus-Adapter中可以做到预扩容吗?
虽然在Prometheus-Adapter中无法直接做到预扩容,但是我们可以使用Prometheus的预测规则 predict_linear() 间接实现有限度的预测扩容。
我们来看后面这个例子,这里使用了Prometheus 预测规则。
在这个示例中, my_metric 指标用于衡量负载。预测规则会计算 my_metric 指标的平均值和变化率。然后,它会使用线性回归预测未来 10 分钟的平均值。如果预测的平均值超过 100,则会触发 HighLoad 警报。
那么显然Prometheus的predict_linear函数与和KEDA的预扩容机制相比,还不够完善。
Prometheus-Adapter 与 KEDA 对比
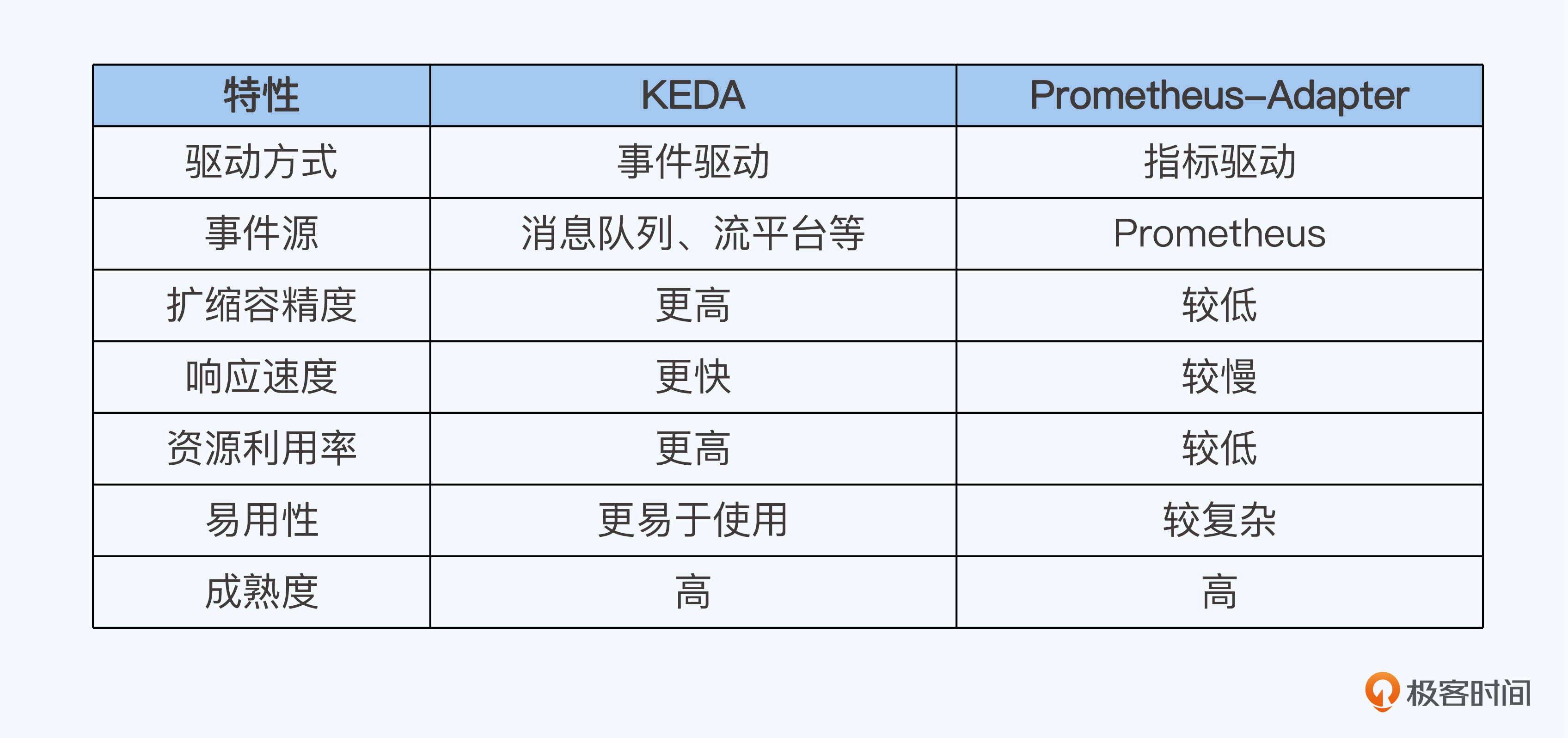
Prometheus-Adapter 与 KEDA 均可用于将监控数据与 Kubernetes 集成,但侧重点不同。Prometheus-Adapter基于指标驱动,根据Prometheus中的指标触发扩缩。而KEDA基于事件驱动,根据各种事件触发扩缩容。
选择 KEDA 还是 Prometheus-Adapter,取决于我们的具体需求。
- 如果你的应用是事件驱动的,则 KEDA 是更好的选择。
- 如果你的应用是指标驱动的,则 Prometheus-Adapter 是更好的选择。
- 如果你需要更精准的扩缩容和更快的响应速度,则 KEDA 是更好的选择。
最后为了方便你直观对比,我用表格梳理了KEDA 和 Prometheus-Adapter 的主要区别,供你参考。
总结
今天这一讲,我们学习了基于事件驱动的自动扩缩容工具KEDA,了解了KEDA的架构,还结合配置案例了解了它的使用方法。
和基于指标驱动的Prometheus-Adapter扩缩容方式相比,基于事件驱动的KEDA具有以下优势。
- 更灵活:事件驱动可以根据应用程序的具体事件进行扩缩容,而指标驱动只能根据预定义的指标进行扩缩容。
- 更快速:事件驱动可以更快地响应应用程序负载的变化,而指标驱动可能需要一段时间才能收集到足够的指标数据。
- 更准确:事件驱动可以更准确地反映应用程序的实际负载情况,而指标驱动可能受到指标收集频率和准确性的影响。
当然,我们使用KEDA也要面对一些挑战,例如需要定义合适的事件类型和事件处理逻辑。但总体而言,KEDA是一种更为灵活、快速和准确的扩缩容策略。
思考题
你觉得 KEDA 在哪些场景下可以发挥最大价值?
欢迎在评论区里给我留言。如果这一讲对你有启发,别忘了分享给身边更多朋友。
- 橙汁 👍(2) 💬(0)
keda 用是可以用 但要看你集群规模 和应用的架构,我觉得kubernetrs应用基本都是这样,只有规模足够大使用效果更好,你说你就5个页面几个后端,上集群可能就大材小用了
2024-04-22