09 集群组件管理:自动化之道,轻松管理百个集群
你好,我是潘野。
通过前面的课程,我们学习了通过GitOps的方式来管理公有云里的资源,也顺利地启动了一个Kubernetes集群。
但是在真正的生产环境中,一个“光秃秃”的集群业务人员是无法使用的。比如业务需要Ingress来对外暴露流量,SRE需要集群内有Prometheus来监控整个应用的状态。所以像Ingress、Prometheus这些组件依然属于基础设施的管理范畴。也就是说,快速、可靠和可重复的管理Kubernetes集群组件也是IaC中的一环。
我们不妨试着想象一下,假如你是公司Kubernetes平台管理员,需要管理100个Kubernetes集群,而每个集群都有10个组件的时候,你应该如何来做呢?
常见的Kubernetes集群组件
我们先看看交付给业务团队使用的Kubernetes集群一般需要哪些组件。
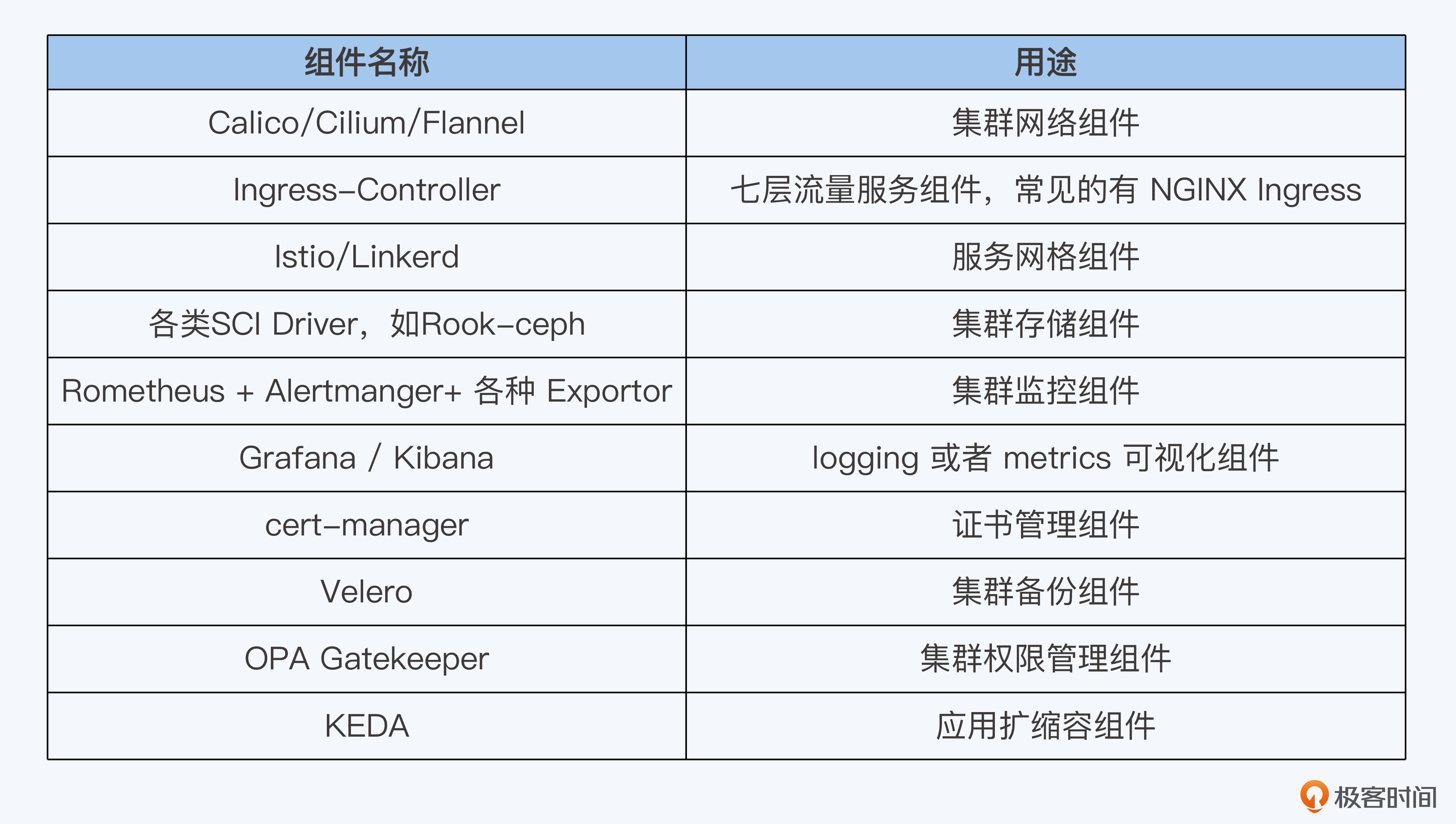
这些组件分成两类,一类是控制平面组件,一类是数据平面组件。控制平面的组件里面涉及到网络插件、安全组件等,数据平面的组件主要是以Ingress、cert-manger和Grafana这样的业务辅助组件为主。我将常用的Kubernetes集群组件用表格的形式列在下面,供你参考。
前面我们预设的场景是100个集群,每个集群10个组件,那么一共就有1000个组件。我们来分析一下有哪些通用的管理需求,主要是三类。
- 组件类型管理:因为100个集群可能因为用途不同,就需要针对性的安装不同的组件。例如给AI用的GPU集群就需要安装device-plugin这些组件,而普通集群显然不需要这样的组件。
- 组件版本管理:这100个集群的Kubernetes版本可能不一样,那么依赖的组件版本也会不一样。例如HPA的API version在1.21时候是v2beta1,但是到了1.24之后就升级到了v2,那么在1.21集群上涉及到HPA的组件可能就不能安装最新版本。
- 组件功能管理:我们还得考虑不同环境下组件配置不一样的问题。比如在测试环境的集群,我们需要开启组件的一些功能来做测试,而到了正式的生产环境,这些组件中用来测试的功能就需要关闭。
基于这三类的需要,我们怎么做才能同时实现需求定制,还有集中管理组件这两个要求呢?
如何按需定制集群组件
其实我们仔细想一想,这100个Kubernetes集群,即便是业务场景不同,但是其中部分集群组件都是一样的。
我们结合自己的经验,很容易就能找到一些共性规律。比如说,集群总需要监控吧?那么就需要采集节点状态node-exportor;再比如,应用总需要对外暴露自己服务的访问地址吧?那么ingress-controller也是必不可少的,所以这些属于必要组件。
和必要组件相对应,还有一些是可选的功能。比如说,虽然我们要对所有集群进行监控,但是查看监控数据的组件Grafana并不是每个集群都要安装,只需要安装在某一个集群即可,所以这类组件就属于可选组件。
那么我们是不是可以维护一个集合,来表述一个集群需要安装哪些组件呢?为了帮你理解这个集群组件集合如何实现,我们来看一段非常简单的yaml配置文件示例。
熟悉helm的同学,看到这里是不是觉得有点眼熟?在helm的values.yaml中,我们经常会看到 enabled: false 或者是 enabled: true 这个字段?既然在helm中我们可以使用 enabled 这个关键词来决定是否开启功能,那我们是不是也可以套用在这里呢?
这肯定是可以的。这时候我们还需要配套使用一个技巧,这个技巧来自官方文档。
The current best practice for composing a complex application from discrete parts is to create a top-level umbrella chart that exposes the global configurations, and then use the charts/ subdirectory to embed each of the components.
中文翻译过来就是:
构建复杂应用的最佳实践是创建顶层的伞状 Chart (umbrella chart),用于暴露全局配置,然后使用 charts/ 子目录嵌入每个组件。
那么如何理解顶层的umbrella chart呢?
结合我们上面示例的yaml配置文件,addons这个顶层的伞状chart,在addons这个chart里,会通过 enabled 这个字段来决定是否在集群上启用这些组件。你可以结合下图来理解原理。
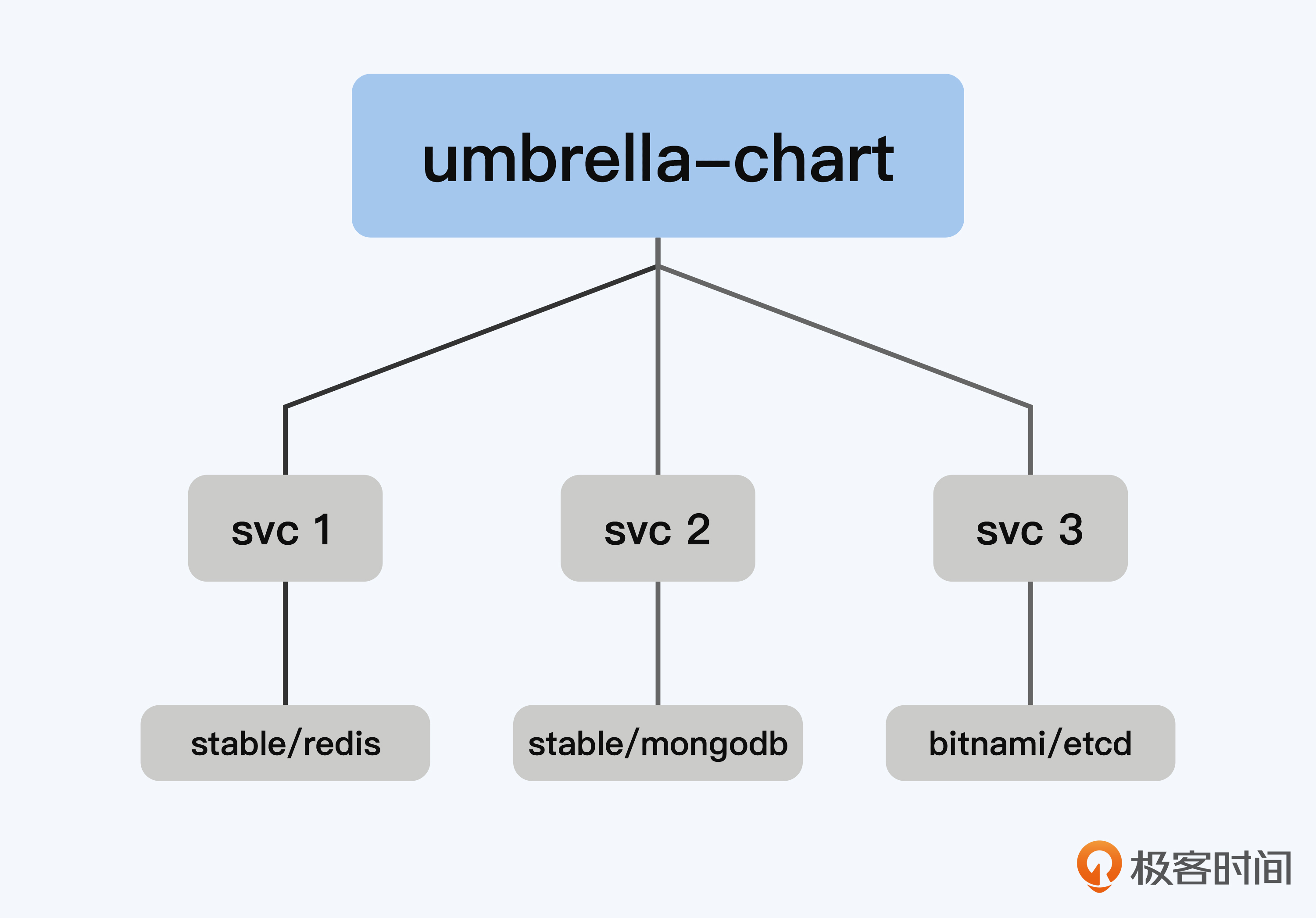
那么问题来了,在顶层的chart中包含子系统的chart,这个需求要如何实现呢?
我们需要结合部署集群组件的过程来找到答案。接下来,我们就分三步走,先从部署单个集群组件入手,然后升级到同时部署多个集群组件,最后再进入如何部署多个集群的组件。
ArgoCD:如何部署单个组件
我们一般会通过Helm配合ArgoCD这个工具来部署单个集群组件。这里我以部署Grafana为例,快速地讲一下ArgoCD部署单个组件的过程,一共分两步。
第一步,在ArgoCD中配好Helm的仓库。你可以通过ArgoCD的UI来添加Helm仓库,也可以通过命令行来添加仓库。这里的操作也很简单,我们先在UI中点击settings -> Repositories -> connect repo,然后选择repo的类型为helm,再填上repo的URL即可。
 当正确配置了helm repo之后,ArgoCD中就会显示successful的提示。
当正确配置了helm repo之后,ArgoCD中就会显示successful的提示。

第二步,通过UI或者Kubernetes命令行创建ArgoCD的Application,配置好相关参数即可部署。
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: grafana
namespace: argocd
spec:
destination:
namespace: addons-system
server: https://Kubernetes.default.svc
project: default
source:
chart: grafana
repoURL: https://grafana.github.io/helm-charts
targetRevision: 7.2.4
syncPolicy:
automated: {}
完成上面的步骤以后,最终我们就会看到Grafana部署在了集群中,如下图所示。
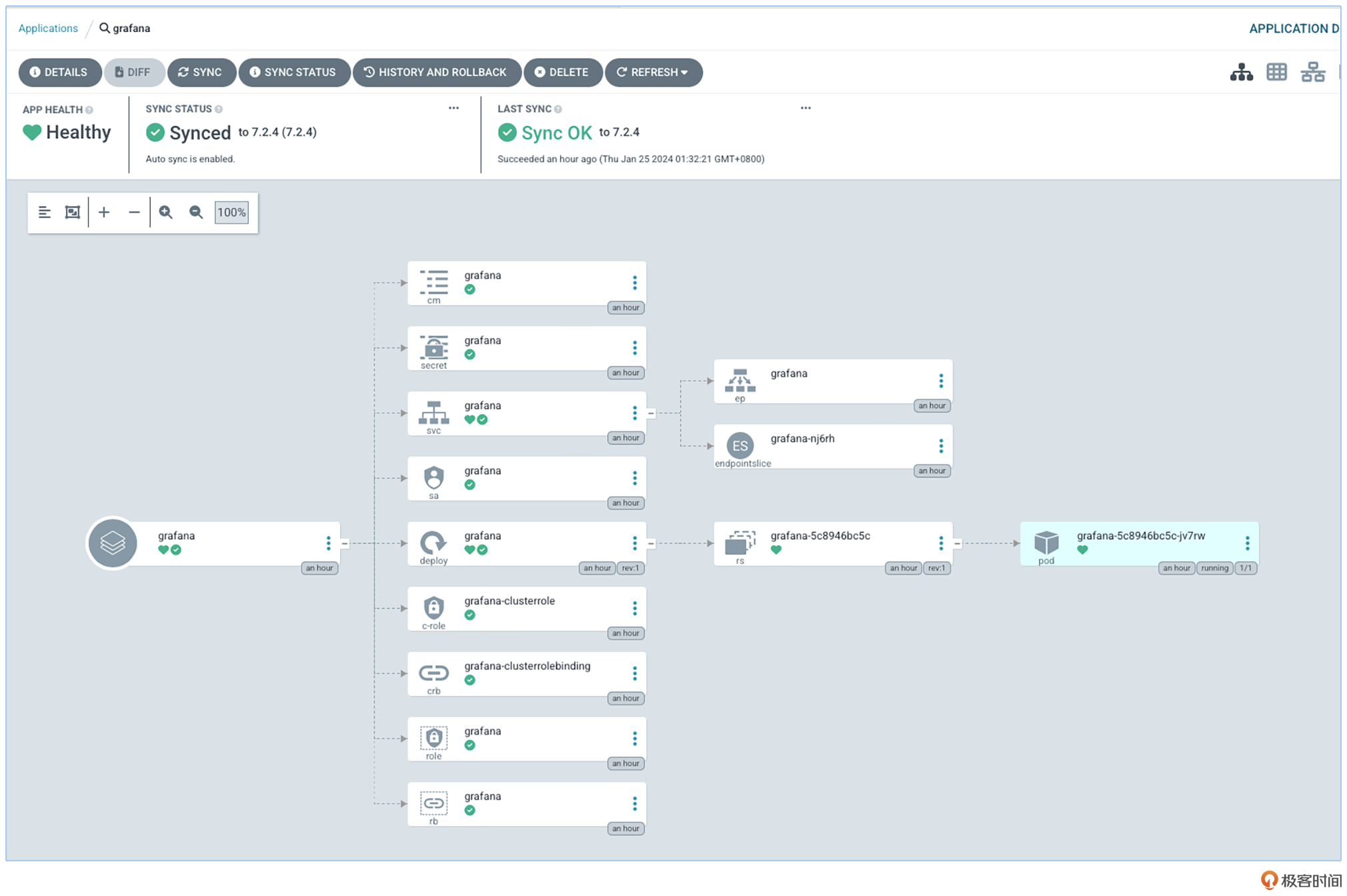
umbrella chart - 管理集群所有组件
一个组件是这样部署的,其他组件也同理,也就是说,所有的集群组件都可以通过Helm配合ArgoCD部署。而umbrella chart要做的事情,就是根据 enabled 这个字段,渲染出所需要的Application,这样不就可以解决我们的需求了吗?
我们这就来看看具体实现思路,我们先为ArgoCD的Application这类资源自定义一个helm chart包,将变化的参数转变成可配置的value。你可以先看看下面的配置示例 ,再听我分析。
在template中grafana.yaml中,我们用 addon.enabled 来控制helm是否渲染出这个配置文件,如果enabled是true,那么接下来会根据values.yaml里面的值生成真正的ArgoCD的配置文件。下面是grafana argocd application的样例代码:
{{- $addon := .Values.addons.grafana }}
{{- if $addon.enabled }}
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: {{ $addon.names.app }}
namespace: argocd
spec:
destination:
namespace: {{ $addon.namespace | default "addons-system" }}
server: https://Kubernetes.default.svc
project: default
source:
chart: {{ $addon.names.chart }}
helm:
valueFiles:
- values.yaml
repoURL: {{ $addon.repoURL}}
targetRevision: {{ $addon.targetVersion }}
syncPolicy:
automated: {}
{{- end }}
基于上面的样例代码,我们发现在helm中的value定义无非就是这么几个参数,分别用来说明是否在集群中启用,chart的仓库地址,还有需要在集群中安装哪个版本等等信息。你可以参考后面这个例子看一下。
grafana:
enabled: false
names:
app: grafana
chart: grafana
repoURL: https://grafana.github.io/helm-charts
targetVersion: 7.2.4
如何集中化管理集群组件
前面,我们解决了集群组件定制的需求,那么我们如何通过一份代码来管理100个集群的组件呢?
Helm里的values.yaml是可以采用层层递进式覆盖的。你可以结合后面这个配置案例来理解。
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: addons
namespace: argocd
spec:
destination:
namespace: addons-system
server: https://Kubernetes.default.svc
project: default
source:
chart: addonsmgr
helm:
valueFiles:
- values.yaml
- values/aks/infra.yaml
repoURL: https://cloudnative-automation.github.io/addon-manager/repo
targetRevision: 0.1.*
syncPolicy:
automated: {}
可以看到,我们只要为每个集群单独配置一个values.yaml,就能控制集群可以安装哪些组件。这是因为valueFiles会默认读取chart包中的values.yaml,并覆盖掉默认的values。
例如,我们在 values/aks/infra.yaml 中定义了Grafana开启,而ingressNginx则没有开启,这样就能精细地控制这个集群可以安装哪些组件。
---
clusterURL: infra-dev.hcp.japaneast.azmk8s.io
addons:
grafana:
enabled: true
ingressNginx:
enabled: false
效果图
让我们来看下这样做的效果如何。
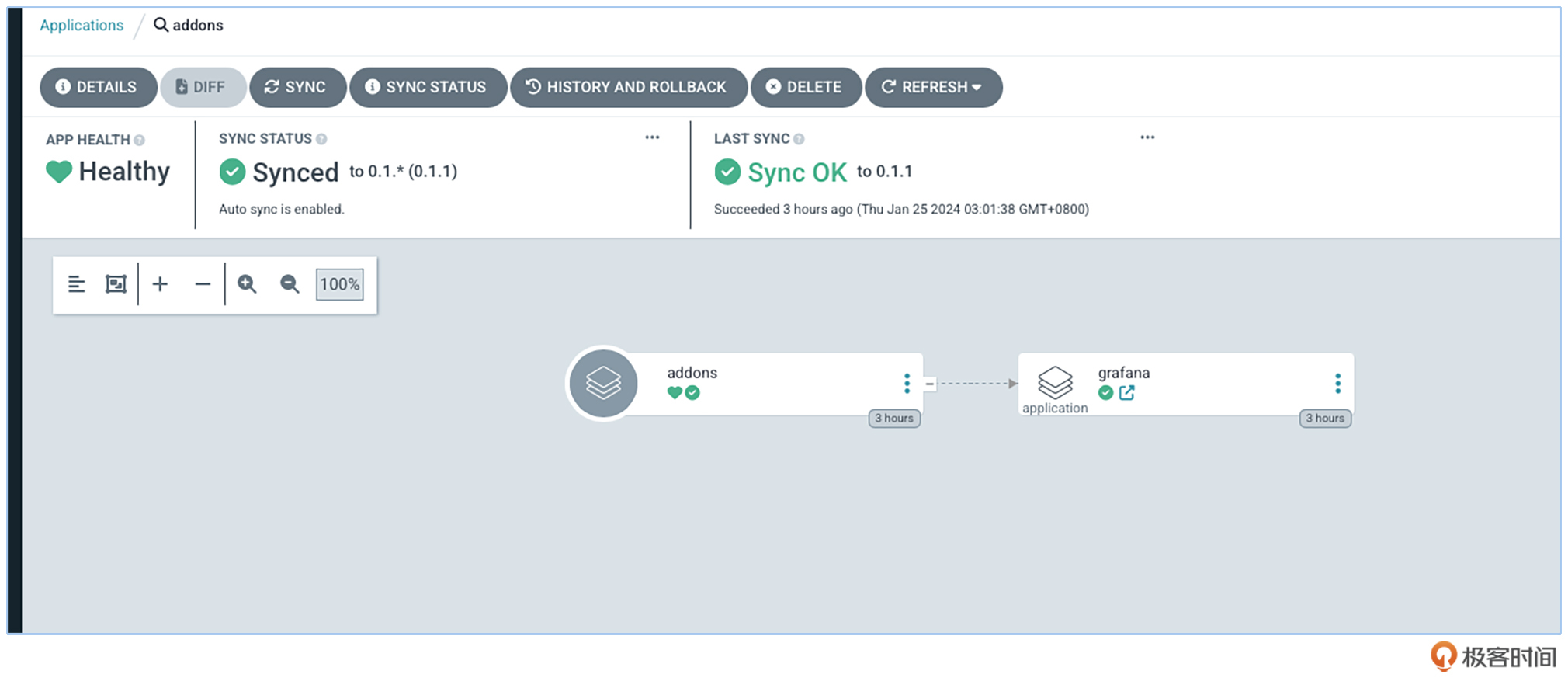
对照截图可以看到,addons是顶层的umbrella chart,在这个集群中,Grafana是它的子chart。详细代码我已经放在 GitHub 上,你可以结合我前面的讲述来深入理解。
看到这里,有同学可能会问,想要建立100个集群,岂不是要执行100次创建命令了么?
这一点其实你无需担心。在工作中,我们同时建立的集群一般不超过10个。我们只是在集群初始化时,才会去创建这个addons的application,部署addons这个顶层chart。之后,ArgoCD将会通过 targetRevision: 0.1.* 这样的方式来监听Helm仓库的变化,一旦有新的版本出现,便会自己同步过来,进行更新。
如何维护helm chart的仓库地址
除了创建命令执行的自动化,对于helm char的仓库地址的维护,我们也可以自动化实现。
我们可以看到,每个子chart都有一个repoURL的配置,常用的管理方式有两种方式。
第一种是自己维护一个chart repo,将所有需要安装的chart包导入自己维护的repo中,同学们可以参考课程 GitHub仓库中关于自建chart仓库的说明。
第二种是依然使用原始chart的仓库地址,这里需要保证集群环境网络对外的连通性。
无论是哪一种管理方式,都需要提前将Chart的Repositories导入ArgoCD。这一讲里我已经写了如何在ArgoCD中导入仓库的方法,这步动作也是在集群初始化的时候先完成,你可以把后面这段代码放在Terraform的代码中。
resource "repo_resource" "add helm repos" {
provisioner "local-exec" {
command = <<EOF
argocd repo add https://charts.jetstack.io --username devops;
EOF
environment = {
AWS_REGION = var.region
}
}
GitOps维护
讲到这里,我们已经完成了所有的工作。
如果我们想在某个集群里打开一个组件,应该如何操作呢?
例如我们在集群中打开cert- manager这个组件,只需要提交一个PR,经过代码的审核,然后merge进代码主干。
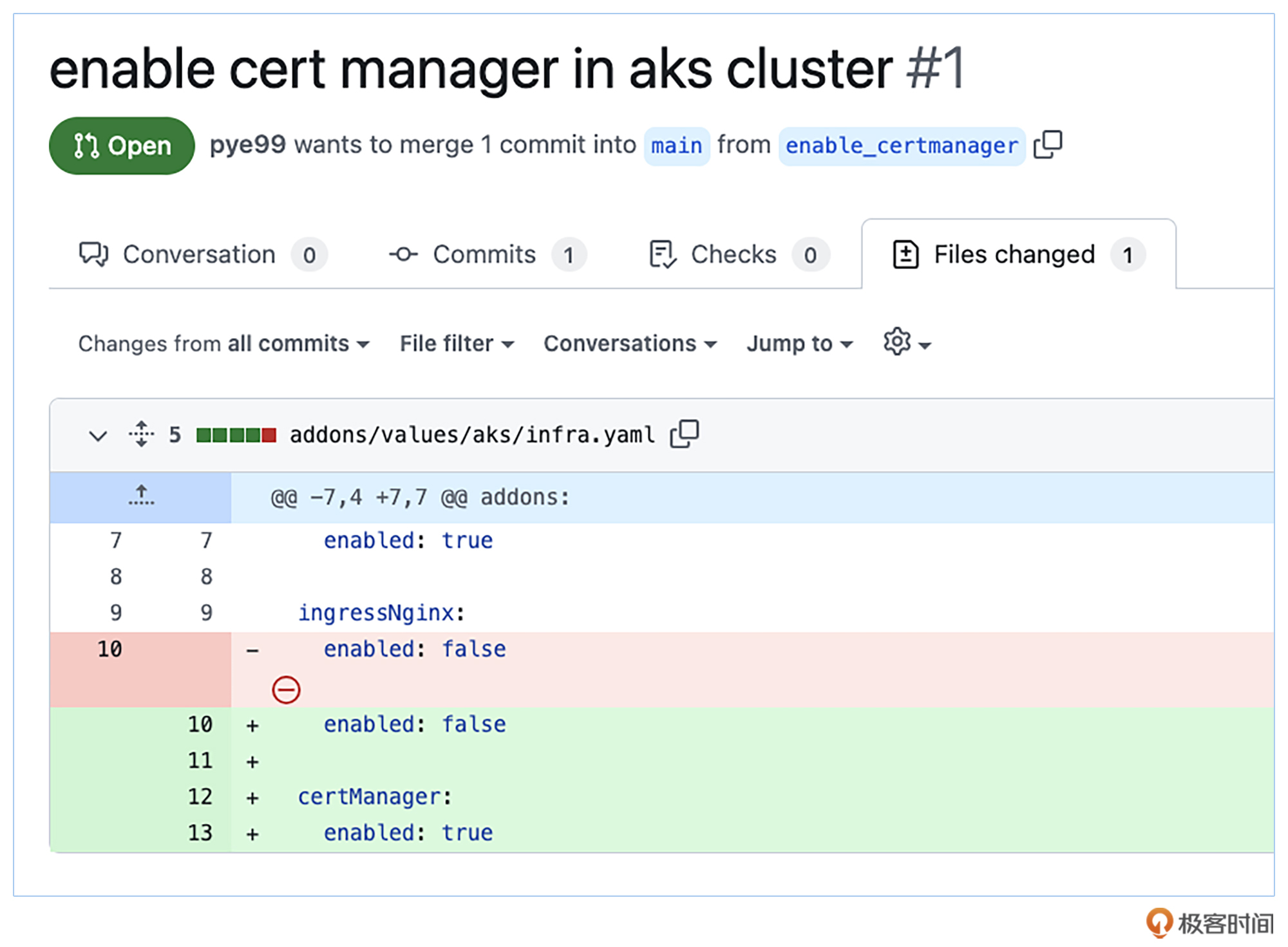
这样就能触发GitHub Action的流水线,将我们的Chart自动打包并上传到镜像仓库,ArgoCD监测到chart版本变化之后开始更改集群组件配置。
如果我们需要回滚某个配置,只需要重新提交一个git revert的PR,之后GitHub Action的流水线以及ArgoCD会遵循同样的方法部署出去。
进行到这里,我们实践了如何用GitOps方式来管理Kubernetes集群配置。在这个仓库里,你可以看到整个集群的配置更改历史,都显示在Git的commit中,而且使用了Git作为唯一真实数据源的运维模式。
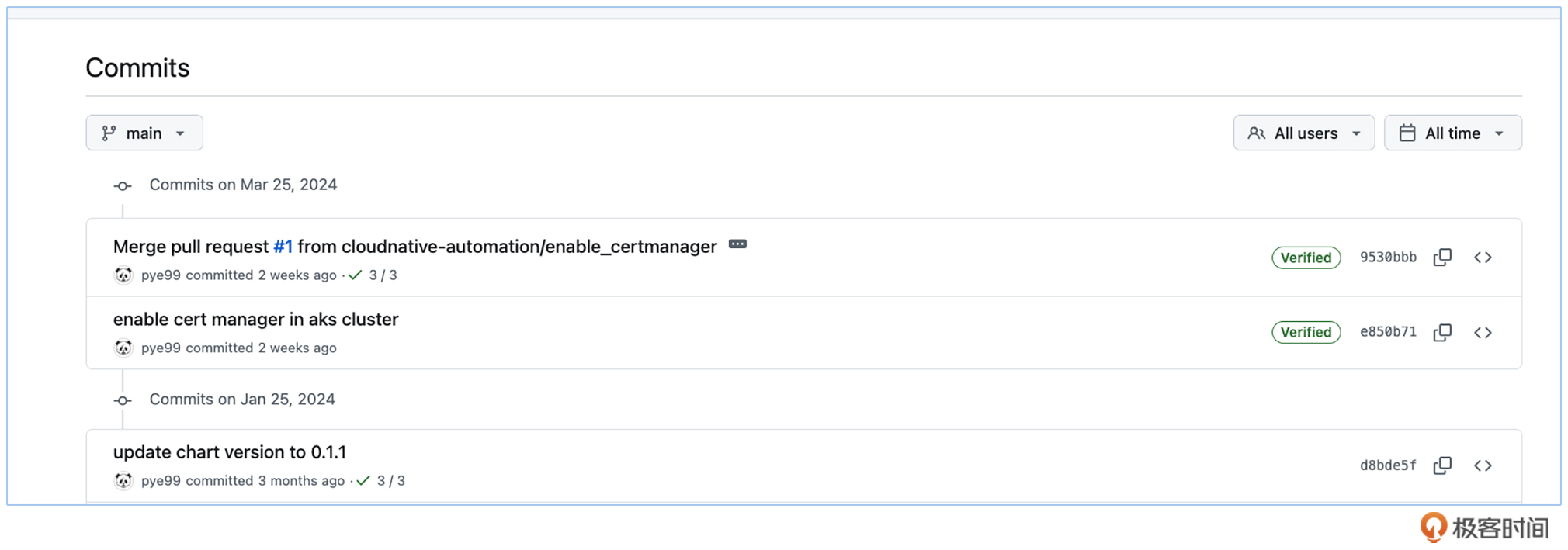 这种方式提供了版本控制、审计日志以及回滚等功能,完整地实现了我们在课程最初提出来的快速、可靠和可重复的部署和管理过程。
这种方式提供了版本控制、审计日志以及回滚等功能,完整地实现了我们在课程最初提出来的快速、可靠和可重复的部署和管理过程。
总结
今天这一讲是基础架构自动化管理中相当重要的一节课。
我们的目标是让Kubernetes基础组件既可以按需求定制,又能够集中管理。为此,我们从我们umbrella chart切入为你做了详细演示。
我们先从部署单个集群组件入手,然后升级到同时部署多个集群组件,最后再进入如何部署多个集群的组件。
由此,我们就解决了基础设施自动化管理的最后一公里 ,也就是Kubernetes集群交付。同时也遵循了我们在课程最初提出的快速、可靠和可重复的部署和管理过程。
到今天为止,我们完成了基础设施即代码环节,但是目前我们仅仅完成了交付给业务使用的环节。在此基础上,我们如何保证交付的基础设施的可用性与稳定性呢?这些问题后面我们再继续讨论,敬请期待。
思考题
请你根据代码仓库里提供的样例,来完成其他集群组件的部署。
---
clusterURL: 127.0.0.1
addons:
namespaces:
default: addons-system
grafana:
enabled: false
names:
app: grafana
chart: grafana
repoURL: https://grafana.github.io/helm-charts
targetVersion: 7.2.4
ingressNginx:
enabled: false
names:
app: ingress-nginx
chart: ingress-nginx/ingress-nginx
repoURL: https://kubernetes.github.io/ingress-nginx
targetVersion: 4.9.0
欢迎在评论区与我讨论。如果这一讲对你有启发,也欢迎分享给身边更多朋友。
- cfanbo 👍(1) 💬(1)
上一节介绍了tekton,为什么这节才用了argoCD,是因为什么原因?生态?
2024-04-15 - cfanbo 👍(0) 💬(1)
它与argoCD比较有哪些优缺点?
2024-04-15 - Geek_45a572 👍(0) 💬(1)
老师您好,如何完整的拉起一套系统呢?像云服务的rds等其他saas服务如何集成到terraform? 数据库的参数是否需要terraform管理呢?
2024-04-15 - 咸蛋超人 👍(0) 💬(1)
潘老师,能否分享一下再eBay这种公司是怎么样来管理和运维这么多的大规模K8S集群?是否有文章或者资料可以分享下?
2024-04-12 - kissyoudyb 👍(0) 💬(0)
太有用了,舒服,真是开了眼界
2024-08-07