01 发展历程:IaC过去、现在与未来展望
你好,我是潘野。
从今天开始,我们将会学习云原生基础架构的重要理论和发展脉络,为之后我们实践全自动化的基础架构管理打好基础。
作为课程的第一讲,我想先和你聊聊“基础设施即代码(Infrastructure as code)”。说起这个话题,你可能觉得是老生常谈,毕竟我们很容易就能在网上搜到很多相关内容。不过,这些内容往往很零散、不够系统,结合实践案例深入探讨的更是凤毛麟角。
今天,我就带你系统梳理一下基础设施即代码(Infrastructure as code)的来龙去脉。
场景模拟
让我们从一个小场景开始聊起。假如你是基础架构部门的技术总监。最近,公司要上线一个新业务。开发部门估算后,向你提出需要300台服务器来支持,100台做缓存系统,100台给中间件使用,50台给数据库使用,为了应对意外情况,还有50台做冗余。
那么接下来,从采购到业务真正上线都会经历哪些过程呢?
过去的IaC:面向配置工具管理
在公有云普及之前,一般来说情况是这样。
- 基础架构部门先采购300台服务器,数据中心工程师负责将机器推上机架,加电开机。
- 网络组同学会为这批新机器分配Vlan、Subnet等资源。
- 系统运维同学根据需求分配机器,然后安装操作系统,运行配置管理工具,完成后,再交付给负责应用发布的同学。
- 负责应用发布的同学发布应用,最终完成整个业务上线。
其中第三步是最耗费时间的,系统运维的同学不仅要安装操作系统,还要对这个300台的服务器做配置管理。这300台服务器的用途不同,所以系统配置肯定也不相同,这时就需要借助配置管理工具来帮忙。那这个配置管理工具背后是怎么运行的?它是如何保证300台机器能被正确管理的呢?
就拿我们比较熟悉的工具——Puppet举例,这是一个Client-Server模型的配置管理工具。它的原理是这样的:每台机器上的Puppet agent每30分钟去Puppet master上拉取一次本机对应的配置,然后与本机上的配置做比对,发现不一致就会更改成Puppet Master里存储的配置。
既然300台机器各有各的用途,怎么使用配置管理工具来区分它们的用途,以便推送相对应的配置呢?
Puppet内置了一个节点角色定义的功能,早期叫ENC,Puppet 3之后改成Hiera,假设我们在Puppet节点定义文件中声明了50台数据库服务器,前几台数据库服务器的核心定义如下:
node 'redis01' {
include redis
}
node 'db01' {
include mysql
}
node 'db02' {
class {'mysql':
type => slave
default_master = "db01"
}
}
...
结合代码可以看到,redis01这个节点里要应用Redis这个模块,db01和db02要应用MySQL这个模块,db02里的参数表示它是db01的slave节点。Puppet agent会根据节点定义拉取对应的配置,然后应用到主机上。
为了方便团队协作,一般运维团队会将Puppet的配置文件放在公司内的git上,通过一些代码控制流程来管理代码的变更历史,这就是我们常说的Infrastructure as Code,简称IaC。
基于配置管理的IaC方式,尽管具体选哪种工具可能有所不同,比如我们还可以选择Saltstack或者是Ansible工具,但是思路和流程大体应该差不多。
这种管理方式相比自己写脚本的传统管理方式,具有三个重要的标准。
- 快速:一旦节点的角色定义好了之后,Puppet agent会自动拉取配置完成配置变更。
- 可靠:通过工具自动定期对比配置,防止有人手动做了更改,确保实际配置与定义配置保持一致。
- 可重复:无论是配置数据库服务器,还是设置冗余服务器,运维只需要定义好服务器角色,设置一次应用配置,Puppet就能搞定所有的配置工作,省去了手工重复配置数百台机器的烦恼。
好,我们稍微总结一下什么是IaC。IaC是一种自动化基础设施管理的方法,通过代码描述和配置基础设施资源,实现快速、可靠和可重复的部署和管理过程。
现在的IaC:面向API与资源管理
你有没有发现,我们前面例子里,从采购、配置300台服务器到业务上线的流程效率其实并不高?
首先,网络组的同学要为这批新机器分配vlan、subnet等网络资源,往往这个过程中还要涉及到一些开防火墙规则。其次,运维同学要等待网络组同学完成网络配置后,才能安装操作系统,并交付配置管理。
这种一环套一环的基础架构管理方式效率并不高,这几百台服务器从上架到交付使用,整个过程没有十天半个月,是不可能完成的。
这些基础设施的维护工作在业务运行里占据了很大比重,但效率低下。这显然无法跟上行业里不断变化的市场需求,拖慢了业务团队持续交付、早日上线的步伐。
为解决传统基础架构中低效工作的部分,云计算逐渐占据了基础架构中主流地位。我们不再需要自己维护一个机房,也不再需要专门采购服务器了,而是通过公有云上的API或者SDK来申请计算存储网络的资源。
那为什么公有云可以快速满足业务对基础设施资源的需求呢?在公有云上申请计算、存储和网络资源具体又是如何操作的呢?
让我们结合例子来解读,后面的命令创建了一个EC2虚拟机实例。这条命令背后其实是调用AWS的API来创建EC2虚拟机实例。
aws ec2 run-instances --image-id ami-xxxxxxxx --count 1 --instance-type t2.micro --key-name MyKeyPair --security-group-ids sg-903004f8 --subnet-id subnet-6e7f829e
我将参数的含义整理了一张表,供你参考。
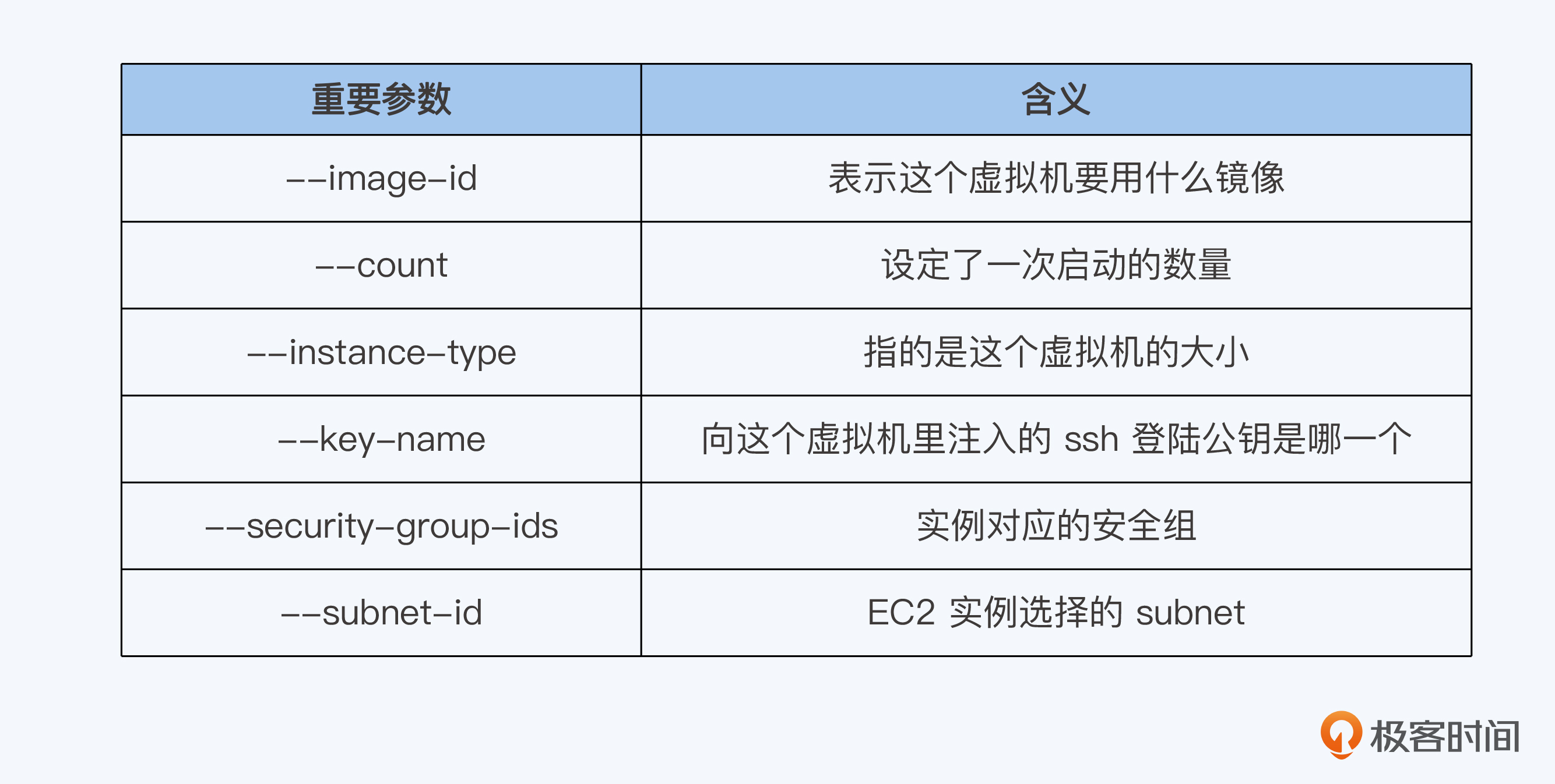
当这一条命令敲下去之后,只需要1分钟你就能获得一台可以立刻进行应用部署的虚拟机。其他网络资源、存储资源获取的方式也类似,对照AWS的文档就能轻松搞定。
可以看到在公有云上,基础架构的资源管理有了质的飞跃。
- 部署和上线时间方面,从原有的天级别压缩到分钟级别。
- 计算、网络、存储资源都可以通过API形式获得。
- 资源可以按需配置,随用随取。
在这种背景下,基础设施的配置管理就要转变成面向云上资源管理,也就是对计算、网络、存储做全方位的管理,而不是再面向机器配置管理。然而,基于Puppet这类配置管理工具的IaC方式显然无法匹配新的情况,因为它们的能力仅限于主机上的配置管理。
那么面向资源管理具体怎么实现呢?
我们主要会通过命令式和声明式两种方式来管理资源。我继续沿用这个业务上线的例子,来帮你理解命令式与声明式。
此时需求会变成这样:
应用需要30台虚拟机部署中间件,30台虚拟机部署缓存系统,这两类机器启用云上自动扩展功能,根据CPU使用率对机器数量进行扩容。
前端需要一个负载均衡器,对外暴露的端口是8082。
10个云数据库实例用来存储用户信息,用户的图片数据存储在对象存储中,对象存储的大小为1T。
这时运维同学就可以根据上述需求,将AWS的命令组合成一个shell的脚本。脚本中会组合地创建EC2实例、RDS数据库实例、创建ELB还有创建S3的命令。然后执行这个脚本即可轻松获取到相对应的资源,这种管理方式叫命令式方法。
命令式方法的问题在于配置程度低,一旦应用多起来,就会带来更多的手工工作。
于是,一种新的资源管理方式就出现了。AWS 为了帮助用户简化工作,快速复制基础设施,推出了CloudFormation这个功能。CloudFormation使用结构化的文本,通过模板方式组合来创建一组资源。这些资源能一起合作,共同创建一个应用程序或解决方案。
这种方式叫做声明式方法。声明式方法定义了系统的预期状态,包括所需的资源以及它们应具有的属性,声明式方法的IaC工具执行时可能会中断或出错,但是这类工具可以不断重试,直到最终的实际状态与预期状态一致。
我们来看一个CloudFormation的例子,直观比较一下声明式方法和之前的命令式方法有什么不同。
Resources:
Ec2Instance:
Type: 'AWS::EC2::Instance'
Properties:
SecurityGroups:
- !Ref InstanceSecurityGroup
KeyName: mykey
ImageId: 'ami-xxxx'
InstanceSecurityGroup:
Type: 'AWS::EC2::SecurityGroup'
Properties:
GroupDescription: Enable SSH access via port 22
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 22
ToPort: 22
CidrIp: 0.0.0.0/0
在这个配置中,我们定义了这个EC2的镜像、安全组、ssh登陆公钥等信息,将命令转化成了声明式的配置。之后再结合模版的方式,就能达到IaC管理快速、可靠、可重复的标准。
但CloudFormation是AWS的产品,只支持AWS的API。如果我们选择其他的云厂商或者是自己搭建私有云时,又该怎么办呢?有没有什么工具可以支持所有的API?
于是,Terraform这种多云基础设施编排工具就应运而生了!和CloudFormation一样,Terraform也是声明式方法,但是它没有使用结构化文本,而是Terraform自己的语法,这里我贴一个小样例。
module "ec2_instance" {
source = "terraform-aws-modules/ec2-instance/aws"
name = "single-instance"
instance_type = "t2.micro"
key_name = "user1"
monitoring = true
vpc_security_group_ids = ["sg-12345678"]
subnet_id = "subnet-eddcdzz4"
tags = {
Terraform = "true"
Environment = "dev"
}
}
可以看到,这个例子中导入了terraform-aws-modules,因此能够支持Google Cloud,Azure Cloud等其他云的模块。下一讲我还会跟你继续探讨Terraform的原理和应用,这里你先对它有个印象就行。
未来的IaC:面向应用管理
早期IaC是为系统管理员服务,通过Puppet这样的工具帮助系统管理员自动化配置server;现在的IaC是面向资源,通过Terraform这样的工具将计算网络存储的管理整合在一起。这两种管理方式的共性是,先由应用申请资源,再由我们为应用准备资源。
但是还有没有更快更好的方法呢?
我们再回顾下前面模拟场景里的需求,开发团队上线应用程序之前,需要等待基础设施团队通过云的API准备资源。那么开发团队为什么不能直接调用云的API呢?
但是,哪怕开发团队自学了Terraform的文档,搞定了冗长的资源配置管理操作,再应用到云上,整个过程其实是开发团队被动完成了基础设施团队的工作,本质上并没有让效率变得更高。
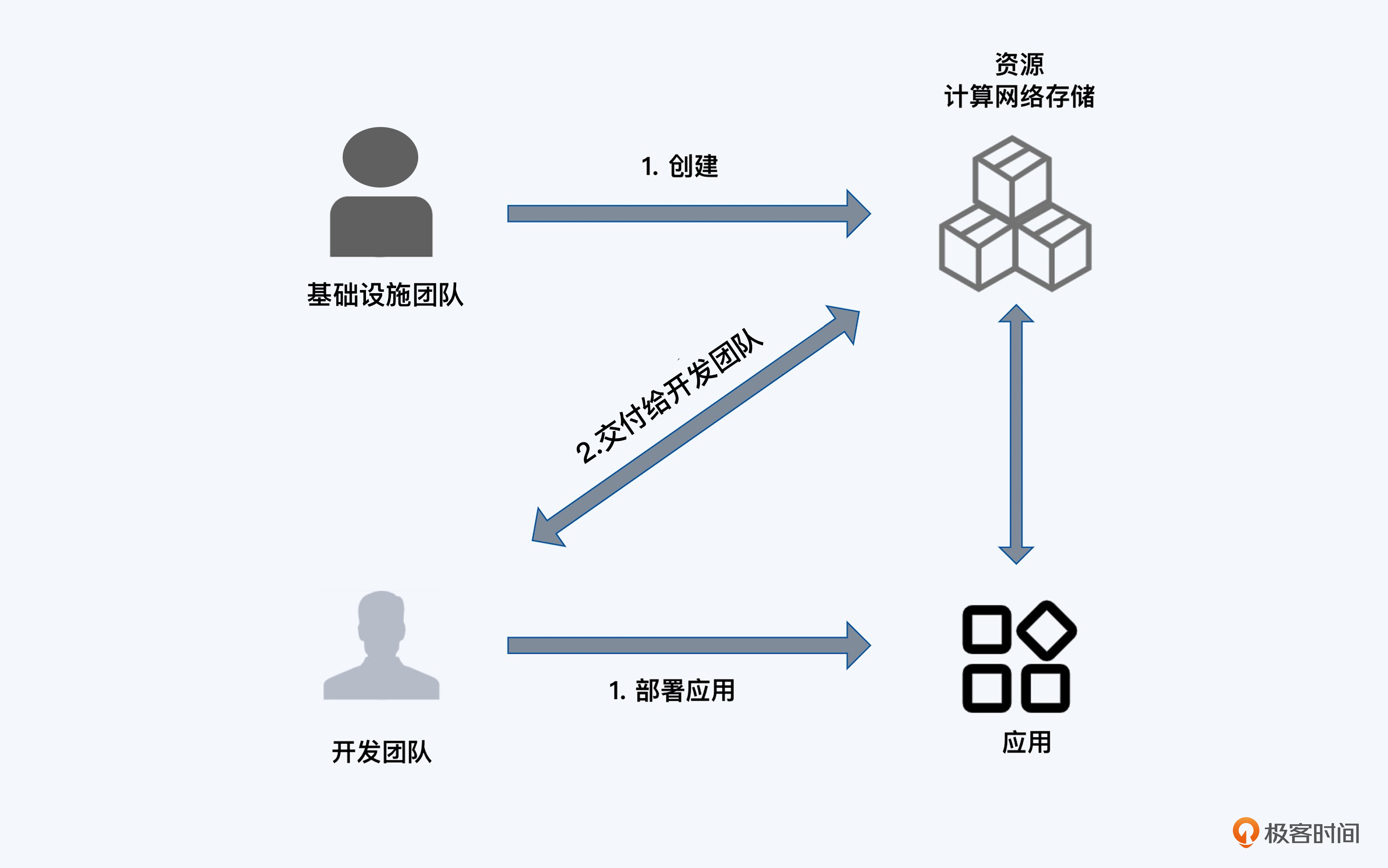
所以这种交付方式依赖的其实是某个人或者某个岗位,只有准备好资源,才能分配给应用资源使用。
一旦有很多应用程序需要调用资源,这种“按需下单,等候分配”的过程就会更加漫长、复杂。那么能不能把准备资源这个过程,交由应用程序本身来触发,通过自动化程序来管理应用程序的整个生命周期呢?
这不就是Kubernetes最重要的特性吗?Kubernetes实际上将基础设施转化成了它的配置对象,让业务在大部分场景中不需要去考虑底层基础架构的形态。
这样一来,开发团队在完成程序开发之后,不需要找到系统管理员或者云管理员,只要在Kubernetes配置文件里,声明所需要CPU、内存和磁盘的大小以及对外暴露服务需要的网关等信息,通过Kubernetes API便可调用各类资源。当应用生命周期结束的时候,再通过Kubernetes配置文件删除应用并释放资源,做到资源的有借有还。
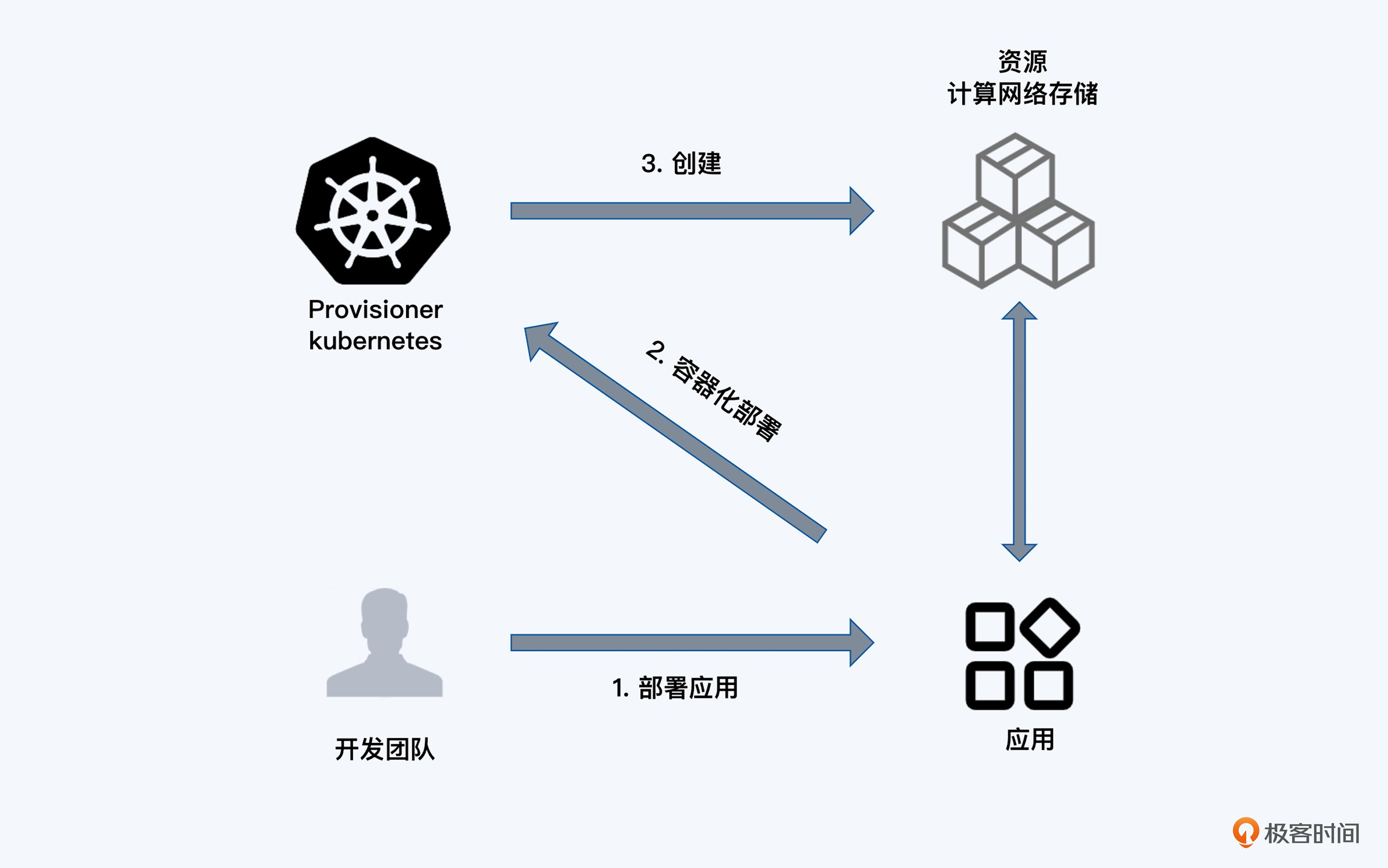
今天Kubernetes已经是事实上的云计算的标准接口。Kubernetes通过对计算、网络、存储的高度抽象,屏蔽了云上和云下的差异。我们在云上和云下机房里分别启动Kubernetes的集群,应用程序几乎不用更改,就可以很快地从云下迁移到云上,或者从云上迁移到云下。
在我看来,在云原生技术的帮助下,未来的基础架构管理中应用与基础设施之间将不再脱节。Kubernetes一方面会为应用提供接口,快速获得相应的计算、网络与存储资源,另一方面又能对接云厂商的API,实现根据应用需求动态扩展资源的能力。
所以,未来Kubernetes的集群管理将会变成IaC的主体。而对于基础设施团队,可以把更多的关注点更多放在集群组件管理、集群监控、成本分析、资源优化等进阶工作上。
总结
今天我和你分享了我对基础设施即代码的经验和理解。
我们用一句话来总结一下IaC的概念,IaC是一种自动化基础设施管理的方法,通过代码描述和配置基础设施资源,实现快速、可靠和可重复的部署和管理过程。
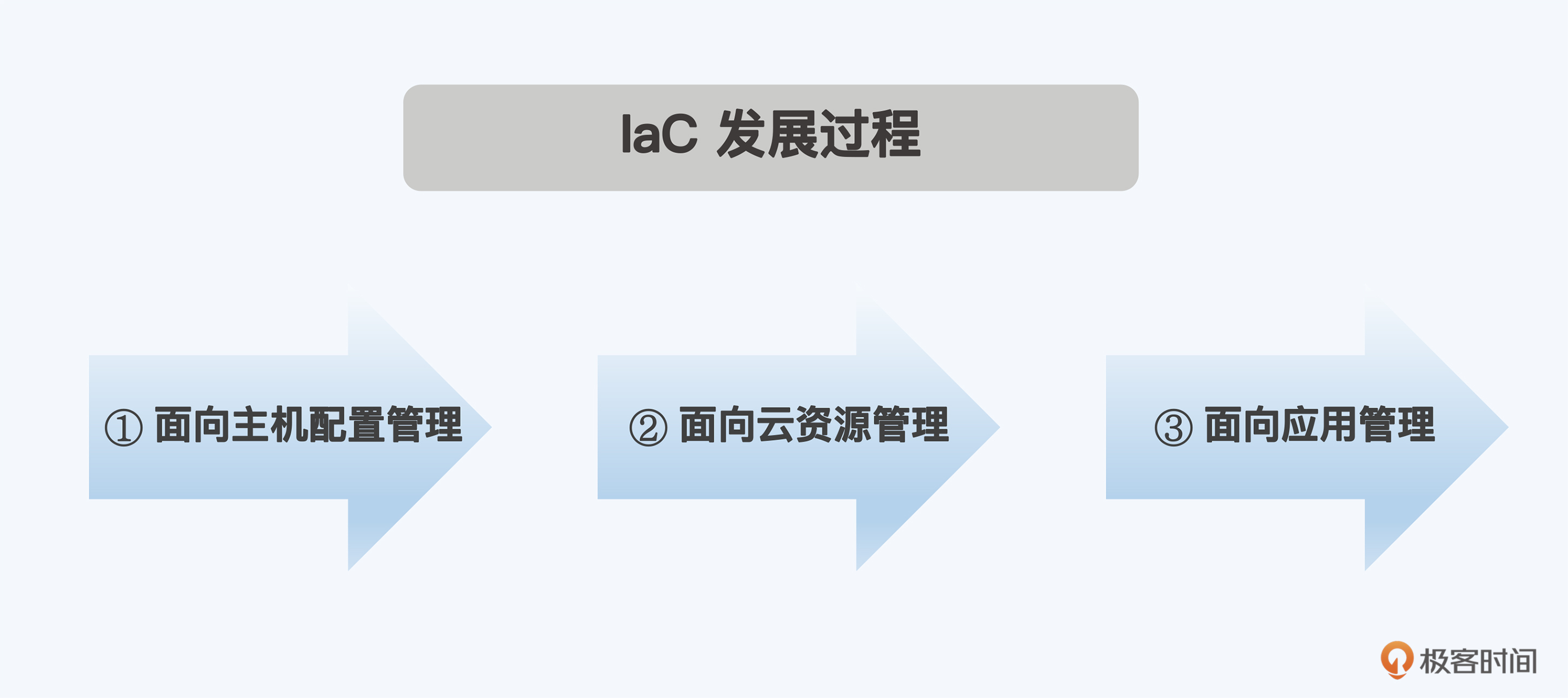
IaC的发展过程可以分为三个阶段。最初,我们主要关注的是面向主机的配置管理,这包括安装和配置服务器、数据库等基础设施组件。随着云计算的发展,我们的关注点转向了面向云资源的管理,这包括创建和管理虚拟机、存储、网络等云资源。在未来,我们预计将进一步前进,关注面向应用资源的管理,这将包括部署和管理微服务、容器、函数等应用级别的资源。
下一讲,我会带你梳理现在流行的IaC的工具,帮你选择适合自己业务的IaC工具。
思考题
请你对照IaC方式的三大标准,看看自己公司里现在所实施的IaC存在哪些不足?
欢迎你在留言区和我交流互动。如果今天的内容对你有启发,也推荐你分享给身边更多朋友。
- yayiyaya 👍(1) 💬(3)
老师, 我有些地方不明白,声明需要CPU、内存和磁盘。 可以通过定义的resource 资源和storageclass来解决;如果是节点的资源不足 ,也可以通过云平台k8s管理, 动态的扩缩容节点。 但是,何时进行扩缩容?是通过什么做判断的? 某些服务申请的声明资源比实际使用要大的多,这些又该怎么办呢?
2024-03-26 - xueerfei007 👍(0) 💬(1)
但是对于云服务提供者来说,给外部提供k8s这样的api,方便用户创建使用资源,但是他们自己的工作依然很复杂,还是要自己处理物理集群
2024-04-22 - kaizen 👍(0) 💬(2)
应用所需要的DB,消息队列等,应该还得靠terraform来拉起来吧
2024-03-25