47 接收网络包(上):如何搞明白合作伙伴让我们做什么?
前面两节,我们分析了发送网络包的整个过程。这一节,我们来解析接收网络包的过程。
如果说网络包的发送是从应用层开始,层层调用,一直到网卡驱动程序的话,网络包的接收过程,就是一个反过来的过程,我们不能从应用层的读取开始,而应该从网卡接收到一个网络包开始。我们用两节来解析这个过程,这一节我们从硬件网卡解析到IP层,下一节,我们从IP层解析到Socket层。
设备驱动层
网卡作为一个硬件,接收到网络包,应该怎么通知操作系统,这个网络包到达了呢?咱们学习过输入输出设备和中断。没错,我们可以触发一个中断。但是这里有个问题,就是网络包的到来,往往是很难预期的。网络吞吐量比较大的时候,网络包的到达会十分频繁。这个时候,如果非常频繁地去触发中断,想想就觉得是个灾难。
比如说,CPU正在做某个事情,一些网络包来了,触发了中断,CPU停下手里的事情,去处理这些网络包,处理完毕按照中断处理的逻辑,应该回去继续处理其他事情。这个时候,另一些网络包又来了,又触发了中断,CPU手里的事情还没捂热,又要停下来去处理网络包。能不能大家要来的一起来,把网络包好好处理一把,然后再回去集中处理其他事情呢?
网络包能不能一起来,这个我们没法儿控制,但是我们可以有一种机制,就是当一些网络包到来触发了中断,内核处理完这些网络包之后,我们可以先进入主动轮询poll网卡的方式,主动去接收到来的网络包。如果一直有,就一直处理,等处理告一段落,就返回干其他的事情。当再有下一批网络包到来的时候,再中断,再轮询poll。这样就会大大减少中断的数量,提升网络处理的效率,这种处理方式我们称为NAPI。
为了帮你了解设备驱动层的工作机制,我们还是以上一节发送网络包时的网卡drivers/net/ethernet/intel/ixgb/ixgb_main.c为例子,来进行解析。
static struct pci_driver ixgb_driver = {
.name = ixgb_driver_name,
.id_table = ixgb_pci_tbl,
.probe = ixgb_probe,
.remove = ixgb_remove,
.err_handler = &ixgb_err_handler
};
MODULE_AUTHOR("Intel Corporation, <linux.nics@intel.com>");
MODULE_DESCRIPTION("Intel(R) PRO/10GbE Network Driver");
MODULE_LICENSE("GPL");
MODULE_VERSION(DRV_VERSION);
/**
* ixgb_init_module - Driver Registration Routine
*
* ixgb_init_module is the first routine called when the driver is
* loaded. All it does is register with the PCI subsystem.
**/
static int __init
ixgb_init_module(void)
{
pr_info("%s - version %s\n", ixgb_driver_string, ixgb_driver_version);
pr_info("%s\n", ixgb_copyright);
return pci_register_driver(&ixgb_driver);
}
module_init(ixgb_init_module);
在网卡驱动程序初始化的时候,我们会调用ixgb_init_module,注册一个驱动ixgb_driver,并且调用它的probe函数ixgb_probe。
static int
ixgb_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
struct net_device *netdev = NULL;
struct ixgb_adapter *adapter;
......
netdev = alloc_etherdev(sizeof(struct ixgb_adapter));
SET_NETDEV_DEV(netdev, &pdev->dev);
pci_set_drvdata(pdev, netdev);
adapter = netdev_priv(netdev);
adapter->netdev = netdev;
adapter->pdev = pdev;
adapter->hw.back = adapter;
adapter->msg_enable = netif_msg_init(debug, DEFAULT_MSG_ENABLE);
adapter->hw.hw_addr = pci_ioremap_bar(pdev, BAR_0);
......
netdev->netdev_ops = &ixgb_netdev_ops;
ixgb_set_ethtool_ops(netdev);
netdev->watchdog_timeo = 5 * HZ;
netif_napi_add(netdev, &adapter->napi, ixgb_clean, 64);
strncpy(netdev->name, pci_name(pdev), sizeof(netdev->name) - 1);
adapter->bd_number = cards_found;
adapter->link_speed = 0;
adapter->link_duplex = 0;
......
}
在ixgb_probe中,我们会创建一个struct net_device表示这个网络设备,并且netif_napi_add函数为这个网络设备注册一个轮询poll函数ixgb_clean,将来一旦出现网络包的时候,就是要通过它来轮询了。
当一个网卡被激活的时候,我们会调用函数ixgb_open->ixgb_up,在这里面注册一个硬件的中断处理函数。
int
ixgb_up(struct ixgb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
......
err = request_irq(adapter->pdev->irq, ixgb_intr, irq_flags,
netdev->name, netdev);
......
}
/**
* ixgb_intr - Interrupt Handler
* @irq: interrupt number
* @data: pointer to a network interface device structure
**/
static irqreturn_t
ixgb_intr(int irq, void *data)
{
struct net_device *netdev = data;
struct ixgb_adapter *adapter = netdev_priv(netdev);
struct ixgb_hw *hw = &adapter->hw;
......
if (napi_schedule_prep(&adapter->napi)) {
IXGB_WRITE_REG(&adapter->hw, IMC, ~0);
__napi_schedule(&adapter->napi);
}
return IRQ_HANDLED;
}
如果一个网络包到来,触发了硬件中断,就会调用ixgb_intr,这里面会调用__napi_schedule。
/**
* __napi_schedule - schedule for receive
* @n: entry to schedule
*
* The entry's receive function will be scheduled to run.
* Consider using __napi_schedule_irqoff() if hard irqs are masked.
*/
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
____napi_schedule(this_cpu_ptr(&softnet_data), n);
local_irq_restore(flags);
}
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
__napi_schedule是处于中断处理的关键部分,在他被调用的时候,中断是暂时关闭的,但是处理网络包是个复杂的过程,需要到延迟处理部分,所以____napi_schedule将当前设备放到struct softnet_data结构的poll_list里面,说明在延迟处理部分可以接着处理这个poll_list里面的网络设备。
然后____napi_schedule触发一个软中断NET_RX_SOFTIRQ,通过软中断触发中断处理的延迟处理部分,也是常用的手段。
上一节,我们知道,软中断NET_RX_SOFTIRQ对应的中断处理函数是net_rx_action。
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
LIST_HEAD(list);
list_splice_init(&sd->poll_list, &list);
......
for (;;) {
struct napi_struct *n;
......
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
}
......
}
在net_rx_action中,会得到struct softnet_data结构,这个结构在发送的时候我们也遇到过。当时它的output_queue用于网络包的发送,这里的poll_list用于网络包的接收。
struct softnet_data {
struct list_head poll_list;
......
struct Qdisc *output_queue;
struct Qdisc **output_queue_tailp;
......
}
在net_rx_action中,接下来是一个循环,在poll_list里面取出网络包到达的设备,然后调用napi_poll来轮询这些设备,napi_poll会调用最初设备初始化的时候,注册的poll函数,对于ixgb_driver,对应的函数是ixgb_clean。
ixgb_clean会调用ixgb_clean_rx_irq。
static bool
ixgb_clean_rx_irq(struct ixgb_adapter *adapter, int *work_done, int work_to_do)
{
struct ixgb_desc_ring *rx_ring = &adapter->rx_ring;
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
struct ixgb_rx_desc *rx_desc, *next_rxd;
struct ixgb_buffer *buffer_info, *next_buffer, *next2_buffer;
u32 length;
unsigned int i, j;
int cleaned_count = 0;
bool cleaned = false;
i = rx_ring->next_to_clean;
rx_desc = IXGB_RX_DESC(*rx_ring, i);
buffer_info = &rx_ring->buffer_info[i];
while (rx_desc->status & IXGB_RX_DESC_STATUS_DD) {
struct sk_buff *skb;
u8 status;
status = rx_desc->status;
skb = buffer_info->skb;
buffer_info->skb = NULL;
prefetch(skb->data - NET_IP_ALIGN);
if (++i == rx_ring->count)
i = 0;
next_rxd = IXGB_RX_DESC(*rx_ring, i);
prefetch(next_rxd);
j = i + 1;
if (j == rx_ring->count)
j = 0;
next2_buffer = &rx_ring->buffer_info[j];
prefetch(next2_buffer);
next_buffer = &rx_ring->buffer_info[i];
......
length = le16_to_cpu(rx_desc->length);
rx_desc->length = 0;
......
ixgb_check_copybreak(&adapter->napi, buffer_info, length, &skb);
/* Good Receive */
skb_put(skb, length);
/* Receive Checksum Offload */
ixgb_rx_checksum(adapter, rx_desc, skb);
skb->protocol = eth_type_trans(skb, netdev);
netif_receive_skb(skb);
......
/* use prefetched values */
rx_desc = next_rxd;
buffer_info = next_buffer;
}
rx_ring->next_to_clean = i;
......
}
在网络设备的驱动层,有一个用于接收网络包的rx_ring。它是一个环,从网卡硬件接收的包会放在这个环里面。这个环里面的buffer_info[]是一个数组,存放的是网络包的内容。i和j是这个数组的下标,在ixgb_clean_rx_irq里面的while循环中,依次处理环里面的数据。在这里面,我们看到了i和j加一之后,如果超过了数组的大小,就跳回下标0,就说明这是一个环。
ixgb_check_copybreak函数将buffer_info里面的内容,拷贝到struct sk_buff *skb,从而可以作为一个网络包进行后续的处理,然后调用netif_receive_skb。
网络协议栈的二层逻辑
从netif_receive_skb函数开始,我们就进入了内核的网络协议栈。
接下来的调用链为:netif_receive_skb->netif_receive_skb_internal->__netif_receive_skb->__netif_receive_skb_core。
在__netif_receive_skb_core中,我们先是处理了二层的一些逻辑。例如,对于VLAN的处理,接下来要想办法交给第三层。
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
struct packet_type *ptype, *pt_prev;
......
type = skb->protocol;
......
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&orig_dev->ptype_specific);
if (pt_prev) {
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
......
}
static inline void deliver_ptype_list_skb(struct sk_buff *skb,
struct packet_type **pt,
struct net_device *orig_dev,
__be16 type,
struct list_head *ptype_list)
{
struct packet_type *ptype, *pt_prev = *pt;
list_for_each_entry_rcu(ptype, ptype_list, list) {
if (ptype->type != type)
continue;
if (pt_prev)
deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
*pt = pt_prev;
}
在网络包struct sk_buff里面,二层的头里面有一个protocol,表示里面一层,也即三层是什么协议。deliver_ptype_list_skb在一个协议列表中逐个匹配。如果能够匹配到,就返回。
这些协议的注册在网络协议栈初始化的时候, inet_init函数调用dev_add_pack(&ip_packet_type),添加IP协议。协议被放在一个链表里面。
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
list_add_rcu(&pt->list, head);
}
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific : &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
假设这个时候的网络包是一个IP包,则在这个链表里面一定能够找到ip_packet_type,在__netif_receive_skb_core中会调用ip_packet_type的func函数。
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
从上面的定义我们可以看出,接下来,ip_rcv会被调用。
网络协议栈的IP层
从ip_rcv函数开始,我们的处理逻辑就从二层到了三层,IP层。
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
const struct iphdr *iph;
struct net *net;
u32 len;
......
net = dev_net(dev);
......
iph = ip_hdr(skb);
len = ntohs(iph->tot_len);
skb->transport_header = skb->network_header + iph->ihl*4;
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
......
}
在ip_rcv中,得到IP头,然后又遇到了我们见过多次的NF_HOOK,这次因为是接收网络包,第一个hook点是NF_INET_PRE_ROUTING,也就是iptables的PREROUTING链。如果里面有规则,则执行规则,然后调用ip_rcv_finish。
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct net_device *dev = skb->dev;
struct rtable *rt;
int err;
......
rt = skb_rtable(skb);
.....
return dst_input(skb);
}
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
ip_rcv_finish得到网络包对应的路由表,然后调用dst_input,在dst_input中,调用的是struct rtable的成员的dst的input函数。在rt_dst_alloc中,我们可以看到,input函数指向的是ip_local_deliver。
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
在ip_local_deliver函数中,如果IP层进行了分段,则进行重新的组合。接下来就是我们熟悉的NF_HOOK。hook点在NF_INET_LOCAL_IN,对应iptables里面的INPUT链。在经过iptables规则处理完毕后,我们调用ip_local_deliver_finish。
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
__skb_pull(skb, skb_network_header_len(skb));
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
int ret;
ret = ipprot->handler(skb);
......
}
......
}
在IP头中,有一个字段protocol用于指定里面一层的协议,在这里应该是TCP协议。于是,从inet_protos数组中,找出TCP协议对应的处理函数。这个数组的定义如下,里面的内容是struct net_protocol。
struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS] __read_mostly;
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol)
{
......
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
NULL, prot) ? 0 : -1;
}
static int __init inet_init(void)
{
......
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
......
}
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
static struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.early_demux_handler = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
在系统初始化的时候,网络协议栈的初始化调用的是inet_init,它会调用inet_add_protocol,将TCP协议对应的处理函数tcp_protocol、UDP协议对应的处理函数udp_protocol,放到inet_protos数组中。
在上面的网络包的接收过程中,会取出TCP协议对应的处理函数tcp_protocol,然后调用handler函数,也即tcp_v4_rcv函数。
总结时刻
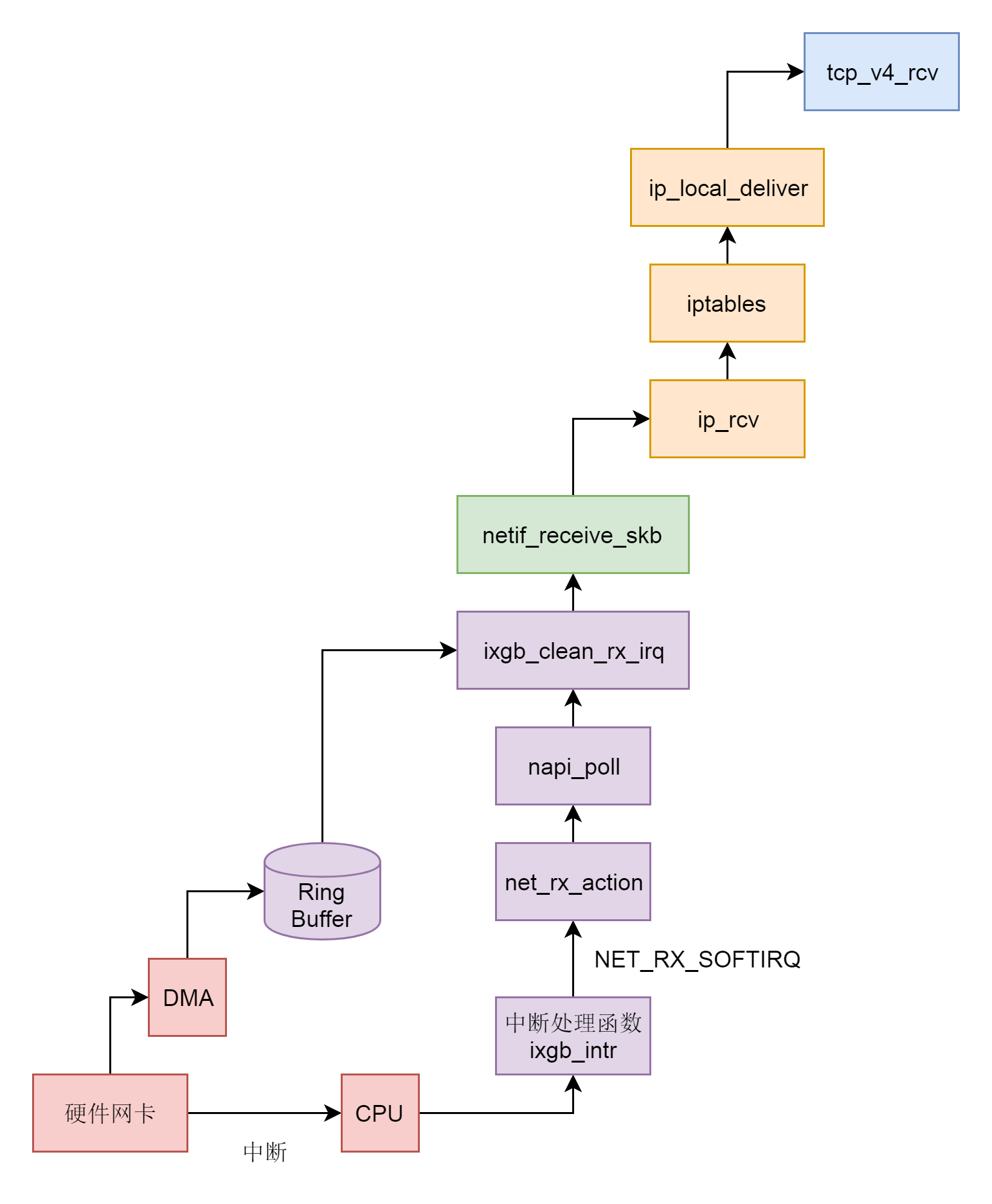
这一节我们讲了接收网络包的上半部分,分以下几个层次。
- 硬件网卡接收到网络包之后,通过DMA技术,将网络包放入Ring Buffer。
- 硬件网卡通过中断通知CPU新的网络包的到来。
- 网卡驱动程序会注册中断处理函数ixgb_intr。
- 中断处理函数处理完需要暂时屏蔽中断的核心流程之后,通过软中断NET_RX_SOFTIRQ触发接下来的处理过程。
- NET_RX_SOFTIRQ软中断处理函数net_rx_action,net_rx_action会调用napi_poll,进而调用ixgb_clean_rx_irq,从Ring Buffer中读取数据到内核struct sk_buff。
- 调用netif_receive_skb进入内核网络协议栈,进行一些关于VLAN的二层逻辑处理后,调用ip_rcv进入三层IP层。
- 在IP层,会处理iptables规则,然后调用ip_local_deliver,交给更上层TCP层。
- 在TCP层调用tcp_v4_rcv。
课堂练习
我们没有仔细分析对于二层VLAN的处理,请你研究一下VLAN的原理,然后在代码中看一下对于VLAN的处理过程,这是一项重要的网络基础知识。
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

- likun 👍(8) 💬(3)
老师 一直有个疑问 网络报数据从进入内存后在cpu的参与下进行了几次内存拷贝呢? 目前我的理解是两次:DMA将数据从网卡接收到内存的网卡环形缓冲区后,cpu进行第一次的内存数据拷贝,生成sk_buff, 内核处理完成后交给应用层,cpu又会经过一次拷贝,获取到用户空间表示的数据。同理,发送的时候,cpu将用户空间数据拷贝到内核空间分配sk_buff,后续设备驱动层cpu将sk_buff的数据拷贝到网卡的环形发送缓冲区,然后发起dma传输指令,dma将数据从内存发送到网卡。不知道这个过程我理解的对不对,请老师指正。以前总是理解为一次的用户空间和内核空间的数据拷贝,后续cpu发起d ma传输指令,dma直接将sk_buff的数据发送到网卡,现在根据老师讲解,这样似乎有问题。
2020-05-17 - 羊仔爸比 👍(1) 💬(1)
老师我想问一下,因为我看网络发送和接收两章iptables规则都是在内核中IP层生效的,像配置和端口相关的iptables规则是在哪里生效的?
2019-09-10 - Geek_ae11ce 👍(0) 💬(1)
网络包的接收过程,写成结束了。一个小的笔误。
2024-06-18 - 莫名 👍(0) 💬(1)
流程图很赞
2019-08-11 - 追风筝的人 👍(0) 💬(3)
好复杂呀 头疼
2019-08-05 - 许童童 👍(0) 💬(1)
VLAN 的原理有些忘了,希望老师可以在答疑中给我们答疑一下。
2019-07-15 - Cyril 👍(13) 💬(0)
老师能否详细写一点关于 smp 相关的知识,比如多 cpu 如何处理网卡过来的中断,多 cpu 如何进程调度,多 cpu 又是如何解决共享变量访问冲突的问题,对这一部分知识点一直比较模糊
2019-07-15 - 奔跑的码仔 👍(8) 💬(0)
https://baijiahao.baidu.com/s?id=1628398215665219628&wfr=spider&for=pc该文章很好的讲解了VLAN的基本原理和各种使用方式,推荐给大家。
2019-10-18 - 啦啦啦 👍(5) 💬(1)
我好像听到了错了重新读,哈哈,这么逗比的吗
2019-09-27 - 安排 👍(2) 💬(0)
牛
2019-07-15 - Penn 👍(1) 💬(0)
和Cyril提到的问题一样,老师能否介绍下smp,网卡多队列的收包后,进入内核的处理流程
2019-07-15 - ABC 👍(0) 💬(0)
原文:“ixgb_check_copybreak 函数将 buffer_info 里面的内容,拷贝到 struct sk_buff *skb,从而可以作为一个网络包进行后续的处理,然后调用 netif_receive_skb。” 我看了下3.10.14版本的内核,总觉得这里有些奇怪。从函数看,这里长度大于256的直接返回,无需执行下面的copy啊。按照原文来说,从网卡队列DMA到内存环形队列,然后再copy一份,这等于内存里有两份报文数据了,不合常理吧。 static void ixgb_check_copybreak(struct net_device *netdev, struct ixgb_buffer *buffer_info, u32 length, struct sk_buff **skb) { struct sk_buff *new_skb; if (length > copybreak)这里长度大于256的直接返回,无需执行下面的copy return; new_skb = netdev_alloc_skb_ip_align(netdev, length); if (!new_skb) return; skb_copy_to_linear_data_offset(new_skb, -NET_IP_ALIGN, (*skb)->data - NET_IP_ALIGN, length + NET_IP_ALIGN); /* save the skb in buffer_info as good */ buffer_info->skb = *skb; *skb = new_skb; }
2021-06-30 - Geek_29c23f 👍(0) 💬(0)
napi方式接收网络数据包时,关闭中断一直轮询,假如这个时候又有中断进来,不是没法响应了?
2021-03-16 - 程序水果宝 👍(0) 💬(0)
tcp_protocol和udp_protocol这两个结构体中为啥只有收包的函数没有对应的发包函数
2020-02-02 - 奔跑的码仔 👍(0) 💬(0)
ixgb_probe函数的调用时机是,设备也就是网卡和驱动程序匹配之后,才会调用的吧。
2019-10-18