44 Socket内核数据结构:如何成立特大项目合作部?
上一节我们讲了Socket在TCP和UDP场景下的调用流程。这一节,我们就沿着这个流程到内核里面一探究竟,看看在内核里面,都创建了哪些数据结构,做了哪些事情。
解析socket函数
我们从Socket系统调用开始。
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
......
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
......
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
......
return retval;
}
这里面的代码比较容易看懂,Socket系统调用会调用sock_create创建一个struct socket结构,然后通过sock_map_fd和文件描述符对应起来。
在创建Socket的时候,有三个参数。
一个是family,表示地址族。不是所有的Socket都要通过IP进行通信,还有其他的通信方式。例如,下面的定义中,domain sockets就是通过本地文件进行通信的,不需要IP地址。只不过,通过IP地址只是最常用的模式,所以我们这里着重分析这种模式。
第二个参数是type,也即Socket的类型。类型是比较少的。
第三个参数是protocol,是协议。协议数目是比较多的,也就是说,多个协议会属于同一种类型。
常用的Socket类型有三种,分别是SOCK_STREAM、SOCK_DGRAM和SOCK_RAW。
SOCK_STREAM是面向数据流的,协议IPPROTO_TCP属于这种类型。SOCK_DGRAM是面向数据报的,协议IPPROTO_UDP属于这种类型。如果在内核里面看的话,IPPROTO_ICMP也属于这种类型。SOCK_RAW是原始的IP包,IPPROTO_IP属于这种类型。
这一节,我们重点看SOCK_STREAM类型和IPPROTO_TCP协议。
为了管理family、type、protocol这三个分类层次,内核会创建对应的数据结构。
接下来,我们打开sock_create函数看一下。它会调用__sock_create。
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
......
sock = sock_alloc();
......
sock->type = type;
......
pf = rcu_dereference(net_families[family]);
......
err = pf->create(net, sock, protocol, kern);
......
*res = sock;
return 0;
}
这里先是分配了一个struct socket结构。接下来我们要用到family参数。这里有一个net_families数组,我们可以以family参数为下标,找到对应的struct net_proto_family。
/* Supported address families. */
#define AF_UNSPEC 0
#define AF_UNIX 1 /* Unix domain sockets */
#define AF_LOCAL 1 /* POSIX name for AF_UNIX */
#define AF_INET 2 /* Internet IP Protocol */
......
#define AF_INET6 10 /* IP version 6 */
......
#define AF_MPLS 28 /* MPLS */
......
#define AF_MAX 44 /* For now.. */
#define NPROTO AF_MAX
struct net_proto_family __rcu *net_families[NPROTO] __read_mostly;
我们可以找到net_families的定义。每一个地址族在这个数组里面都有一项,里面的内容是net_proto_family。每一种地址族都有自己的net_proto_family,IP地址族的net_proto_family定义如下,里面最重要的就是,create函数指向inet_create。
//net/ipv4/af_inet.c
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,//这个用于socket系统调用创建
......
}
我们回到函数__sock_create。接下来,在这里面,这个inet_create会被调用。
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
unsigned char answer_flags;
int try_loading_module = 0;
int err;
/* Look for the requested type/protocol pair. */
lookup_protocol:
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) {
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
......
sock->ops = answer->ops;
answer_prot = answer->prot;
answer_flags = answer->flags;
......
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
......
inet = inet_sk(sk);
inet->nodefrag = 0;
if (SOCK_RAW == sock->type) {
inet->inet_num = protocol;
if (IPPROTO_RAW == protocol)
inet->hdrincl = 1;
}
inet->inet_id = 0;
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
inet->uc_ttl = -1;
inet->mc_loop = 1;
inet->mc_ttl = 1;
inet->mc_all = 1;
inet->mc_index = 0;
inet->mc_list = NULL;
inet->rcv_tos = 0;
if (inet->inet_num) {
inet->inet_sport = htons(inet->inet_num);
/* Add to protocol hash chains. */
err = sk->sk_prot->hash(sk);
}
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
}
......
}
在inet_create中,我们先会看到一个循环list_for_each_entry_rcu。在这里,第二个参数type开始起作用。因为循环查看的是inetsw[sock->type]。
这里的inetsw也是一个数组,type作为下标,里面的内容是struct inet_protosw,是协议,也即inetsw数组对于每个类型有一项,这一项里面是属于这个类型的协议。
static struct list_head inetsw[SOCK_MAX];
static int __init inet_init(void)
{
......
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
......
}
inetsw数组是在系统初始化的时候初始化的,就像下面代码里面实现的一样。
首先,一个循环会将inetsw数组的每一项,都初始化为一个链表。咱们前面说了,一个type类型会包含多个protocol,因而我们需要一个链表。接下来一个循环,是将inetsw_array注册到inetsw数组里面去。inetsw_array的定义如下,这个数组里面的内容很重要,后面会用到它们。
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
}
我们回到inet_create的list_for_each_entry_rcu循环中。到这里就好理解了,这是在inetsw数组中,根据type找到属于这个类型的列表,然后依次比较列表中的struct inet_protosw的protocol是不是用户指定的protocol;如果是,就得到了符合用户指定的family->type->protocol的struct inet_protosw *answer对象。
接下来,struct socket *sock的ops成员变量,被赋值为answer的ops。对于TCP来讲,就是inet_stream_ops。后面任何用户对于这个socket的操作,都是通过inet_stream_ops进行的。
接下来,我们创建一个struct sock *sk对象。这里比较让人困惑。socket和sock看起来几乎一样,容易让人混淆,这里需要说明一下,socket是用于负责对上给用户提供接口,并且和文件系统关联。而sock,负责向下对接内核网络协议栈。
在sk_alloc函数中,struct inet_protosw *answer结构的tcp_prot赋值给了struct sock *sk的sk_prot成员。tcp_prot的定义如下,里面定义了很多的函数,都是sock之下内核协议栈的动作。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.get_port = inet_csk_get_port,
......
}
在inet_create函数中,接下来创建一个struct inet_sock结构,这个结构一开始就是struct sock,然后扩展了一些其他的信息,剩下的代码就填充这些信息。这一幕我们会经常看到,将一个结构放在另一个结构的开始位置,然后扩展一些成员,通过对于指针的强制类型转换,来访问这些成员。
socket的创建至此结束。
解析bind函数
接下来,我们来看bind。
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (err >= 0) {
err = sock->ops->bind(sock,
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
在bind中,sockfd_lookup_light会根据fd文件描述符,找到struct socket结构。然后将sockaddr从用户态拷贝到内核态,然后调用struct socket结构里面ops的bind函数。根据前面创建socket的时候的设定,调用的是inet_stream_ops的bind函数,也即调用inet_bind。
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
unsigned short snum;
......
snum = ntohs(addr->sin_port);
......
inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr;
/* Make sure we are allowed to bind here. */
if ((snum || !inet->bind_address_no_port) &&
sk->sk_prot->get_port(sk, snum)) {
......
}
inet->inet_sport = htons(inet->inet_num);
inet->inet_daddr = 0;
inet->inet_dport = 0;
sk_dst_reset(sk);
}
bind里面会调用sk_prot的get_port函数,也即inet_csk_get_port来检查端口是否冲突,是否可以绑定。如果允许,则会设置struct inet_sock的本方的地址inet_saddr和本方的端口inet_sport,对方的地址inet_daddr和对方的端口inet_dport都初始化为0。
bind的逻辑相对比较简单,就到这里了。
解析listen函数
接下来我们来看listen。
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
在listen中,我们还是通过sockfd_lookup_light,根据fd文件描述符,找到struct socket结构。接着,我们调用struct socket结构里面ops的listen函数。根据前面创建socket的时候的设定,调用的是inet_stream_ops的listen函数,也即调用inet_listen。
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
int err;
old_state = sk->sk_state;
/* Really, if the socket is already in listen state
* we can only allow the backlog to be adjusted.
*/
if (old_state != TCP_LISTEN) {
err = inet_csk_listen_start(sk, backlog);
}
sk->sk_max_ack_backlog = backlog;
}
如果这个socket还不在TCP_LISTEN状态,会调用inet_csk_listen_start进入监听状态。
int inet_csk_listen_start(struct sock *sk, int backlog)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_max_ack_backlog = backlog;
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
sk_state_store(sk, TCP_LISTEN);
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
......
}
......
}
这里面建立了一个新的结构inet_connection_sock,这个结构一开始是struct inet_sock,inet_csk其实做了一次强制类型转换,扩大了结构,看到了吧,又是这个套路。
struct inet_connection_sock结构比较复杂。如果打开它,你能看到处于各种状态的队列,各种超时时间、拥塞控制等字眼。我们说TCP是面向连接的,就是客户端和服务端都是有一个结构维护连接的状态,就是指这个结构。我们这里先不详细分析里面的变量,因为太多了,后面我们遇到一个分析一个。
首先,我们遇到的是icsk_accept_queue。它是干什么的呢?
在TCP的状态里面,有一个listen状态,当调用listen函数之后,就会进入这个状态,虽然我们写程序的时候,一般要等待服务端调用accept后,等待在哪里的时候,让客户端就发起连接。其实服务端一旦处于listen状态,不用accept,客户端也能发起连接。其实TCP的状态中,没有一个是否被accept的状态,那accept函数的作用是什么呢?
在内核中,为每个Socket维护两个队列。一个是已经建立了连接的队列,这时候连接三次握手已经完毕,处于established状态;一个是还没有完全建立连接的队列,这个时候三次握手还没完成,处于syn_rcvd的状态。
服务端调用accept函数,其实是在第一个队列中拿出一个已经完成的连接进行处理。如果还没有完成就阻塞等待。这里的icsk_accept_queue就是第一个队列。
初始化完之后,将TCP的状态设置为TCP_LISTEN,再次调用get_port判断端口是否冲突。
至此,listen的逻辑就结束了。
解析accept函数
接下来,我们解析服务端调用accept。
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen)
{
return sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0);
}
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len, newfd, fput_needed;
struct sockaddr_storage address;
......
sock = sockfd_lookup_light(fd, &err, &fput_needed);
newsock = sock_alloc();
newsock->type = sock->type;
newsock->ops = sock->ops;
newfd = get_unused_fd_flags(flags);
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
err = sock->ops->accept(sock, newsock, sock->file->f_flags, false);
if (upeer_sockaddr) {
if (newsock->ops->getname(newsock, (struct sockaddr *)&address, &len, 2) < 0) {
}
err = move_addr_to_user(&address,
len, upeer_sockaddr, upeer_addrlen);
}
fd_install(newfd, newfile);
......
}
accept函数的实现,印证了socket的原理中说的那样,原来的socket是监听socket,这里我们会找到原来的struct socket,并基于它去创建一个新的newsock。这才是连接socket。除此之外,我们还会创建一个新的struct file和fd,并关联到socket。
这里面还会调用struct socket的sock->ops->accept,也即会调用inet_stream_ops的accept函数,也即inet_accept。
int inet_accept(struct socket *sock, struct socket *newsock, int flags, bool kern)
{
struct sock *sk1 = sock->sk;
int err = -EINVAL;
struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err, kern);
sock_rps_record_flow(sk2);
sock_graft(sk2, newsock);
newsock->state = SS_CONNECTED;
}
inet_accept会调用struct sock的sk1->sk_prot->accept,也即tcp_prot的accept函数,inet_csk_accept函数。
/*
* This will accept the next outstanding connection.
*/
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
error = inet_csk_wait_for_connect(sk, timeo);
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
......
}
/*
* Wait for an incoming connection, avoid race conditions. This must be called
* with the socket locked.
*/
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
release_sock(sk);
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
sched_annotate_sleep();
lock_sock(sk);
err = 0;
if (!reqsk_queue_empty(&icsk->icsk_accept_queue))
break;
err = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
break;
err = sock_intr_errno(timeo);
if (signal_pending(current))
break;
err = -EAGAIN;
if (!timeo)
break;
}
finish_wait(sk_sleep(sk), &wait);
return err;
}
inet_csk_accept的实现,印证了上面我们讲的两个队列的逻辑。如果icsk_accept_queue为空,则调用inet_csk_wait_for_connect进行等待;等待的时候,调用schedule_timeout,让出CPU,并且将进程状态设置为TASK_INTERRUPTIBLE。
如果再次CPU醒来,我们会接着判断icsk_accept_queue是否为空,同时也会调用signal_pending看有没有信号可以处理。一旦icsk_accept_queue不为空,就从inet_csk_wait_for_connect中返回,在队列中取出一个struct sock对象赋值给newsk。
解析connect函数
什么情况下,icsk_accept_queue才不为空呢?当然是三次握手结束才可以。接下来我们来分析三次握手的过程。
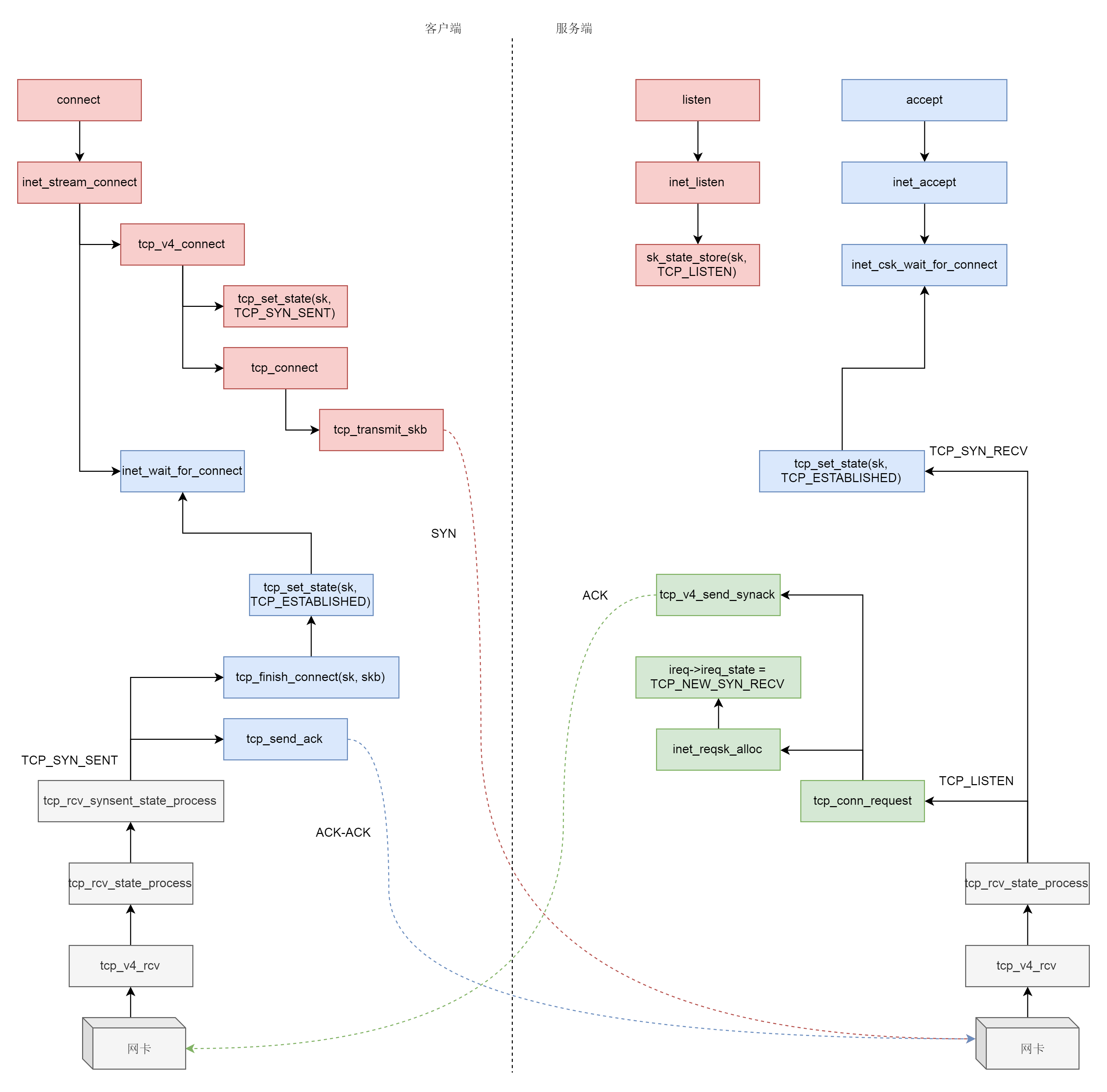
三次握手一般是由客户端调用connect发起。
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
err = move_addr_to_kernel(uservaddr, addrlen, &address);
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags);
}
connect函数的实现一开始你应该很眼熟,还是通过sockfd_lookup_light,根据fd文件描述符,找到struct socket结构。接着,我们会调用struct socket结构里面ops的connect函数,根据前面创建socket的时候的设定,调用inet_stream_ops的connect函数,也即调用inet_stream_connect。
/*
* Connect to a remote host. There is regrettably still a little
* TCP 'magic' in here.
*/
int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags, int is_sendmsg)
{
struct sock *sk = sock->sk;
int err;
long timeo;
switch (sock->state) {
......
case SS_UNCONNECTED:
err = -EISCONN;
if (sk->sk_state != TCP_CLOSE)
goto out;
err = sk->sk_prot->connect(sk, uaddr, addr_len);
sock->state = SS_CONNECTING;
break;
}
timeo = sock_sndtimeo(sk, flags & O_NONBLOCK);
if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) {
......
if (!timeo || !inet_wait_for_connect(sk, timeo, writebias))
goto out;
err = sock_intr_errno(timeo);
if (signal_pending(current))
goto out;
}
sock->state = SS_CONNECTED;
}
在__inet_stream_connect里面,我们发现,如果socket处于SS_UNCONNECTED状态,那就调用struct sock的sk->sk_prot->connect,也即tcp_prot的connect函数——tcp_v4_connect函数。
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
......
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
......
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
if (likely(!tp->repair)) {
if (!tp->write_seq)
tp->write_seq = secure_tcp_seq(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port);
tp->tsoffset = secure_tcp_ts_off(sock_net(sk),
inet->inet_saddr,
inet->inet_daddr);
}
rt = NULL;
......
err = tcp_connect(sk);
......
}
在tcp_v4_connect函数中,ip_route_connect其实是做一个路由的选择。为什么呢?因为三次握手马上就要发送一个SYN包了,这就要凑齐源地址、源端口、目标地址、目标端口。目标地址和目标端口是服务端的,已经知道源端口是客户端随机分配的,源地址应该用哪一个呢?这时候要选择一条路由,看从哪个网卡出去,就应该填写哪个网卡的IP地址。
接下来,在发送SYN之前,我们先将客户端socket的状态设置为TCP_SYN_SENT。然后初始化TCP的seq num,也即write_seq,然后调用tcp_connect进行发送。
/* Build a SYN and send it off. */
int tcp_connect(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *buff;
int err;
......
tcp_connect_init(sk);
......
buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true);
......
tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);
tcp_mstamp_refresh(tp);
tp->retrans_stamp = tcp_time_stamp(tp);
tcp_connect_queue_skb(sk, buff);
tcp_ecn_send_syn(sk, buff);
/* Send off SYN; include data in Fast Open. */
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
......
tp->snd_nxt = tp->write_seq;
tp->pushed_seq = tp->write_seq;
buff = tcp_send_head(sk);
if (unlikely(buff)) {
tp->snd_nxt = TCP_SKB_CB(buff)->seq;
tp->pushed_seq = TCP_SKB_CB(buff)->seq;
}
......
/* Timer for repeating the SYN until an answer. */
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
return 0;
}
在tcp_connect中,有一个新的结构struct tcp_sock,如果打开他,你会发现他是struct inet_connection_sock的一个扩展,struct inet_connection_sock在struct tcp_sock开头的位置,通过强制类型转换访问,故伎重演又一次。
struct tcp_sock里面维护了更多的TCP的状态,咱们同样是遇到了再分析。
接下来tcp_init_nondata_skb初始化一个SYN包,tcp_transmit_skb将SYN包发送出去,inet_csk_reset_xmit_timer设置了一个timer,如果SYN发送不成功,则再次发送。
发送网络包的过程,我们放到下一节讲解。这里我们姑且认为SYN已经发送出去了。
我们回到__inet_stream_connect函数,在调用sk->sk_prot->connect之后,inet_wait_for_connect会一直等待客户端收到服务端的ACK。而我们知道,服务端在accept之后,也是在等待中。
网络包是如何接收的呢?对于解析的详细过程,我们会在下下节讲解,这里为了解析三次握手,我们简单的看网络包接收到TCP层做的部分事情。
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
}
我们通过struct net_protocol结构中的handler进行接收,调用的函数是tcp_v4_rcv。接下来的调用链为tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process。tcp_rcv_state_process,顾名思义,是用来处理接收一个网络包后引起状态变化的。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
......
case TCP_LISTEN:
......
if (th->syn) {
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
......
}
目前服务端是处于TCP_LISTEN状态的,而且发过来的包是SYN,因而就有了上面的代码,调用icsk->icsk_af_ops->conn_request函数。struct inet_connection_sock对应的操作是inet_connection_sock_af_ops,按照下面的定义,其实调用的是tcp_v4_conn_request。
const struct inet_connection_sock_af_ops ipv4_specific = {
.queue_xmit = ip_queue_xmit,
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
.conn_request = tcp_v4_conn_request,
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
.setsockopt = ip_setsockopt,
.getsockopt = ip_getsockopt,
.addr2sockaddr = inet_csk_addr2sockaddr,
.sockaddr_len = sizeof(struct sockaddr_in),
.mtu_reduced = tcp_v4_mtu_reduced,
};
tcp_v4_conn_request会调用tcp_conn_request,这个函数也比较长,里面调用了send_synack,但实际调用的是tcp_v4_send_synack。具体发送的过程我们不去管它,看注释我们能知道,这是收到了SYN后,回复一个SYN-ACK,回复完毕后,服务端处于TCP_SYN_RECV。
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
......
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE);
......
}
/*
* Send a SYN-ACK after having received a SYN.
*/
static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst,
struct flowi *fl,
struct request_sock *req,
struct tcp_fastopen_cookie *foc,
enum tcp_synack_type synack_type)
{......}
这个时候,轮到客户端接收网络包了。都是TCP协议栈,所以过程和服务端没有太多区别,还是会走到tcp_rcv_state_process函数的,只不过由于客户端目前处于TCP_SYN_SENT状态,就进入了下面的代码分支。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
......
case TCP_SYN_SENT:
tp->rx_opt.saw_tstamp = 0;
tcp_mstamp_refresh(tp);
queued = tcp_rcv_synsent_state_process(sk, skb, th);
if (queued >= 0)
return queued;
/* Do step6 onward by hand. */
tcp_urg(sk, skb, th);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return 0;
}
......
}
tcp_rcv_synsent_state_process会调用tcp_send_ack,发送一个ACK-ACK,发送后客户端处于TCP_ESTABLISHED状态。
又轮到服务端接收网络包了,我们还是归tcp_rcv_state_process函数处理。由于服务端目前处于状态TCP_SYN_RECV状态,因而又走了另外的分支。当收到这个网络包的时候,服务端也处于TCP_ESTABLISHED状态,三次握手结束。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
......
switch (sk->sk_state) {
case TCP_SYN_RECV:
if (req) {
inet_csk(sk)->icsk_retransmits = 0;
reqsk_fastopen_remove(sk, req, false);
} else {
/* Make sure socket is routed, for correct metrics. */
icsk->icsk_af_ops->rebuild_header(sk);
tcp_call_bpf(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB);
tcp_init_congestion_control(sk);
tcp_mtup_init(sk);
tp->copied_seq = tp->rcv_nxt;
tcp_init_buffer_space(sk);
}
smp_mb();
tcp_set_state(sk, TCP_ESTABLISHED);
sk->sk_state_change(sk);
if (sk->sk_socket)
sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT);
tp->snd_una = TCP_SKB_CB(skb)->ack_seq;
tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale;
tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
break;
......
}
总结时刻
这一节除了网络包的接收和发送,其他的系统调用我们都分析到了。可以看出来,它们有一个统一的数据结构和流程。具体如下图所示:
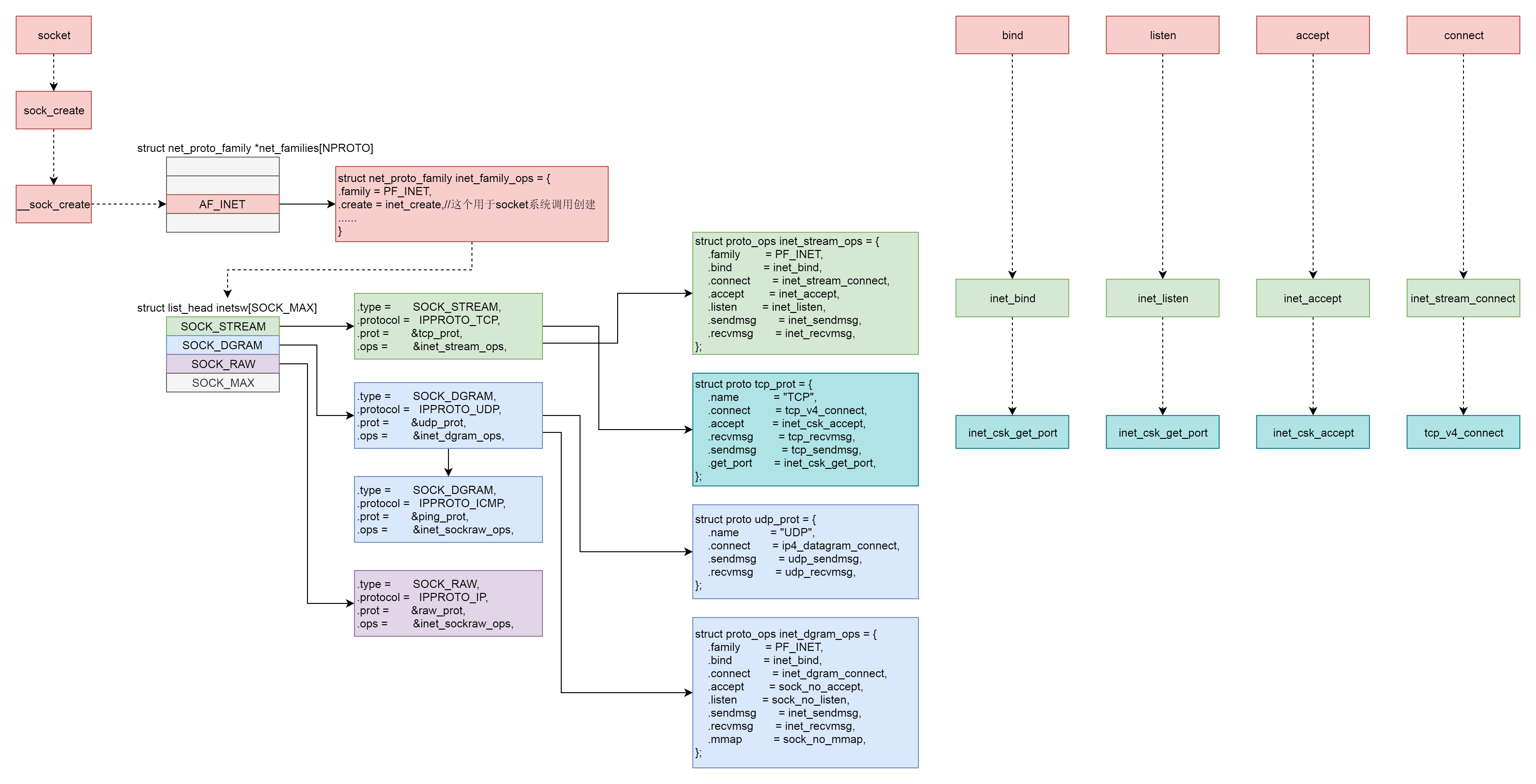
首先,Socket系统调用会有三级参数family、type、protocal,通过这三级参数,分别在net_proto_family表中找到type链表,在type链表中找到protocal对应的操作。这个操作分为两层,对于TCP协议来讲,第一层是inet_stream_ops层,第二层是tcp_prot层。
于是,接下来的系统调用规律就都一样了:
- bind第一层调用inet_stream_ops的inet_bind函数,第二层调用tcp_prot的inet_csk_get_port函数;
- listen第一层调用inet_stream_ops的inet_listen函数,第二层调用tcp_prot的inet_csk_get_port函数;
- accept第一层调用inet_stream_ops的inet_accept函数,第二层调用tcp_prot的inet_csk_accept函数;
- connect第一层调用inet_stream_ops的inet_stream_connect函数,第二层调用tcp_prot的tcp_v4_connect函数。
课堂练习
TCP的三次握手协议非常重要,请你务必跟着代码走读一遍。另外我们这里重点关注了TCP的场景,请走读代码的时候,也看一下UDP是如何实现各层的函数的。
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
- 莫名 👍(13) 💬(1)
看了一遍,然后花了一天把源码又过了一遍,很有收货,对socket的理解不再浮于表面。
2019-08-09 - kkxue 👍(5) 💬(1)
原来得先看总结图,再看内容。。
2019-07-14 - W.jyao 👍(3) 💬(1)
老师,能解释下listenfd和acceptfd的端口为什么一样吗?
2019-07-08 - 无心之福 👍(1) 💬(2)
开头的那个代码的 逗号加的不对吧?
2019-08-19 - book尾汁 👍(0) 💬(2)
调用accept的时候,会新建一个socket,以及其对应的struct file,然后会从icsk_accept_queue 取出一个req,将其sk赋值给新建的socket->sk,这样就可以读取到请求的数据了,不理解的是后面讲到接收数据包时tcp层有三个队列,会根据内核低延时 高吞吐量的等策略以及socket当时的状态来决定放入哪个队列,这里的socket是怎么选出来的啊,数据包是先发送到处于监听队列的socket然后由其将数据分发到其通过accept生成的sokcet上吗,如果是直接由通过accept生成的socket来处理,怎么分辨出来到底该给哪个socket呢,根据数据包的源地址与端口吗?
2020-05-03 - 飞翔 👍(0) 💬(3)
syn到底是个什么东西呀?是个integer还是char类型
2019-07-08 - 二星球 👍(0) 💬(2)
老师好,同一个TCP链接上先后发送2次rpc请求,后发送的请求其结果先返回,先发送的请求结果后返回,这样有没有问题呢,系统能区分各自的返回结果么,靠什么机制保证的呢?一直没有想明白
2019-07-08 - 奔跑的码仔 👍(16) 💬(0)
struct tcp_sock继承自struct inet_connection_sock inet_conn,inet_connection_sock继承自struct inet_sock,struct inet_sock继承自struct sock; 1.上述四个结构的关系具有十足的面向对象的特征,struct是基类,通过层层继承,实现了类的复用; 2.内核中网络相关的很多函数,参数往往都是struct sock,函数内部依照不同的业务逻辑,将struct sock转换为不同的业务结构; 这样做的好处: 1.简化接口的设计复杂度; 2.使用基类作为参数,十分类似于面向对象中的多态特性,能够有效的增强接口的稳定性、提升扩展性。
2019-10-11 - 谛听 👍(6) 💬(0)
socket: 根据参数创建相应socket bind: 绑定IP、端口 listen: 建立两个队列,改变状态为TCP_LISTEN accept: 从完成三次握手的队列中取出一个socket,没有的话让出cpu connect: 三次握手
2019-11-24 - Geek_ty 👍(1) 💬(0)
老师您好,我在认真阅读了文章和代码后还是存在一个疑惑:icsk_accept_queue是全连接队列当然没有问题,但是服务端LISTEN状态下,调用tcp_v4_conn_request()时inet_csk_reqsk_queue_hash_add()函数也是增加了该队列的长度。但是实际上应该修改的时半连接队列才对。我反复看了几遍源码,没有发现在什么地方有保存syn队列,也没有syn队列的相关操作,都是对icsk_accept_queue的操作,这让我十分困惑,还请老师帮忙解答。
2020-08-08 - Spring 👍(1) 💬(0)
老师,请问服务端维护的未完全建立链接队列的元素sock是什么时候创建的呢?是每次收到客户端的SYN包后创建?还是listen时会初始化几个sock?
2019-10-02 - Geek_ae11ce 👍(0) 💬(0)
一篇过于简单了,可能是函数较多的原因。实际更好的是一个函数或两个函数放在一章中
2024-05-31 - Geek_a9a743 👍(0) 💬(0)
太复杂了……
2023-11-26