42 IPC(下):不同项目组之间抢资源,如何协调?
IPC这块的内容比较多,为了让你能够更好地理解,我分成了三节来讲。前面我们解析完了共享内存的内核机制后,今天我们来看最后一部分,信号量的内核机制。
首先,我们需要创建一个信号量,调用的是系统调用semget。代码如下:
SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops sem_ops = {
.getnew = newary,
.associate = sem_security,
.more_checks = sem_more_checks,
};
struct ipc_params sem_params;
ns = current->nsproxy->ipc_ns;
sem_params.key = key;
sem_params.flg = semflg;
sem_params.u.nsems = nsems;
return ipcget(ns, &sem_ids(ns), &sem_ops, &sem_params);
}
我们解析过了共享内存,再看信号量,就顺畅很多了。这里同样调用了抽象的ipcget,参数分别为信号量对应的sem_ids、对应的操作sem_ops以及对应的参数sem_params。
ipcget的代码我们已经解析过了。如果key设置为IPC_PRIVATE则永远创建新的;如果不是的话,就会调用ipcget_public。
在ipcget_public中,我们能会按照key,去查找struct kern_ipc_perm。如果没有找到,那就看看是否设置了IPC_CREAT。如果设置了,就创建一个新的。如果找到了,就将对应的id返回。
我们这里重点看,如何按照参数sem_ops,创建新的信号量会调用newary。
static int newary(struct ipc_namespace *ns, struct ipc_params *params)
{
int retval;
struct sem_array *sma;
key_t key = params->key;
int nsems = params->u.nsems;
int semflg = params->flg;
int i;
......
sma = sem_alloc(nsems);
......
sma->sem_perm.mode = (semflg & S_IRWXUGO);
sma->sem_perm.key = key;
sma->sem_perm.security = NULL;
......
for (i = 0; i < nsems; i++) {
INIT_LIST_HEAD(&sma->sems[i].pending_alter);
INIT_LIST_HEAD(&sma->sems[i].pending_const);
spin_lock_init(&sma->sems[i].lock);
}
sma->complex_count = 0;
sma->use_global_lock = USE_GLOBAL_LOCK_HYSTERESIS;
INIT_LIST_HEAD(&sma->pending_alter);
INIT_LIST_HEAD(&sma->pending_const);
INIT_LIST_HEAD(&sma->list_id);
sma->sem_nsems = nsems;
sma->sem_ctime = get_seconds();
retval = ipc_addid(&sem_ids(ns), &sma->sem_perm, ns->sc_semmni);
......
ns->used_sems += nsems;
......
return sma->sem_perm.id;
}
newary函数的第一步,通过kvmalloc在直接映射区分配一个struct sem_array结构。这个结构是用来描述信号量的,这个结构最开始就是上面说的struct kern_ipc_perm结构。接下来就是填充这个struct sem_array结构,例如key、权限等。
struct sem_array里有多个信号量,放在struct sem sems[]数组里面,在struct sem里面有当前的信号量的数值semval。
struct sem {
int semval; /* current value */
/*
* PID of the process that last modified the semaphore. For
* Linux, specifically these are:
* - semop
* - semctl, via SETVAL and SETALL.
* - at task exit when performing undo adjustments (see exit_sem).
*/
int sempid;
spinlock_t lock; /* spinlock for fine-grained semtimedop */
struct list_head pending_alter; /* pending single-sop operations that alter the semaphore */
struct list_head pending_const; /* pending single-sop operations that do not alter the semaphore*/
time_t sem_otime; /* candidate for sem_otime */
} ____cacheline_aligned_in_smp;
struct sem_array和struct sem各有一个链表struct list_head pending_alter,分别表示对于整个信号量数组的修改和对于某个信号量的修改。
newary函数的第二步,就是初始化这些链表。
newary函数的第三步,通过ipc_addid将新创建的struct sem_array结构,挂到sem_ids里面的基数树上,并返回相应的id。
信号量创建的过程到此结束,接下来我们来看,如何通过semctl对信号量数组进行初始化。
SYSCALL_DEFINE4(semctl, int, semid, int, semnum, int, cmd, unsigned long, arg)
{
int version;
struct ipc_namespace *ns;
void __user *p = (void __user *)arg;
ns = current->nsproxy->ipc_ns;
switch (cmd) {
case IPC_INFO:
case SEM_INFO:
case IPC_STAT:
case SEM_STAT:
return semctl_nolock(ns, semid, cmd, version, p);
case GETALL:
case GETVAL:
case GETPID:
case GETNCNT:
case GETZCNT:
case SETALL:
return semctl_main(ns, semid, semnum, cmd, p);
case SETVAL:
return semctl_setval(ns, semid, semnum, arg);
case IPC_RMID:
case IPC_SET:
return semctl_down(ns, semid, cmd, version, p);
default:
return -EINVAL;
}
}
这里我们重点看,SETALL操作调用的semctl_main函数,以及SETVAL操作调用的semctl_setval函数。
对于SETALL操作来讲,传进来的参数为union semun里面的unsigned short *array,会设置整个信号量集合。
static int semctl_main(struct ipc_namespace *ns, int semid, int semnum,
int cmd, void __user *p)
{
struct sem_array *sma;
struct sem *curr;
int err, nsems;
ushort fast_sem_io[SEMMSL_FAST];
ushort *sem_io = fast_sem_io;
DEFINE_WAKE_Q(wake_q);
sma = sem_obtain_object_check(ns, semid);
nsems = sma->sem_nsems;
......
switch (cmd) {
......
case SETALL:
{
int i;
struct sem_undo *un;
......
if (copy_from_user(sem_io, p, nsems*sizeof(ushort))) {
......
}
......
for (i = 0; i < nsems; i++) {
sma->sems[i].semval = sem_io[i];
sma->sems[i].sempid = task_tgid_vnr(current);
}
......
sma->sem_ctime = get_seconds();
/* maybe some queued-up processes were waiting for this */
do_smart_update(sma, NULL, 0, 0, &wake_q);
err = 0;
goto out_unlock;
}
}
......
wake_up_q(&wake_q);
......
}
在semctl_main函数中,先是通过sem_obtain_object_check,根据信号量集合的id在基数树里面找到struct sem_array对象,发现如果是SETALL操作,就将用户的参数中的unsigned short *array通过copy_from_user拷贝到内核里面的sem_io数组,然后是一个循环,对于信号量集合里面的每一个信号量,设置semval,以及修改这个信号量值的pid。
对于SETVAL操作来讲,传进来的参数union semun里面的int val,仅仅会设置某个信号量。
static int semctl_setval(struct ipc_namespace *ns, int semid, int semnum,
unsigned long arg)
{
struct sem_undo *un;
struct sem_array *sma;
struct sem *curr;
int err, val;
DEFINE_WAKE_Q(wake_q);
......
sma = sem_obtain_object_check(ns, semid);
......
curr = &sma->sems[semnum];
......
curr->semval = val;
curr->sempid = task_tgid_vnr(current);
sma->sem_ctime = get_seconds();
/* maybe some queued-up processes were waiting for this */
do_smart_update(sma, NULL, 0, 0, &wake_q);
......
wake_up_q(&wake_q);
return 0;
}
在semctl_setval函数中,我们先是通过sem_obtain_object_check,根据信号量集合的id在基数树里面找到struct sem_array对象,对于SETVAL操作,直接根据参数中的val设置semval,以及修改这个信号量值的pid。
至此,信号量数组初始化完毕。接下来我们来看P操作和V操作。无论是P操作,还是V操作都是调用semop系统调用。
SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops)
{
return sys_semtimedop(semid, tsops, nsops, NULL);
}
SYSCALL_DEFINE4(semtimedop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops, const struct timespec __user *, timeout)
{
int error = -EINVAL;
struct sem_array *sma;
struct sembuf fast_sops[SEMOPM_FAST];
struct sembuf *sops = fast_sops, *sop;
struct sem_undo *un;
int max, locknum;
bool undos = false, alter = false, dupsop = false;
struct sem_queue queue;
unsigned long dup = 0, jiffies_left = 0;
struct ipc_namespace *ns;
ns = current->nsproxy->ipc_ns;
......
if (copy_from_user(sops, tsops, nsops * sizeof(*tsops))) {
error = -EFAULT;
goto out_free;
}
if (timeout) {
struct timespec _timeout;
if (copy_from_user(&_timeout, timeout, sizeof(*timeout))) {
}
jiffies_left = timespec_to_jiffies(&_timeout);
}
......
/* On success, find_alloc_undo takes the rcu_read_lock */
un = find_alloc_undo(ns, semid);
......
sma = sem_obtain_object_check(ns, semid);
......
queue.sops = sops;
queue.nsops = nsops;
queue.undo = un;
queue.pid = task_tgid_vnr(current);
queue.alter = alter;
queue.dupsop = dupsop;
error = perform_atomic_semop(sma, &queue);
if (error == 0) { /* non-blocking succesfull path */
DEFINE_WAKE_Q(wake_q);
......
do_smart_update(sma, sops, nsops, 1, &wake_q);
......
wake_up_q(&wake_q);
goto out_free;
}
/*
* We need to sleep on this operation, so we put the current
* task into the pending queue and go to sleep.
*/
if (nsops == 1) {
struct sem *curr;
curr = &sma->sems[sops->sem_num];
......
list_add_tail(&queue.list,
&curr->pending_alter);
......
} else {
......
list_add_tail(&queue.list, &sma->pending_alter);
......
}
do {
queue.status = -EINTR;
queue.sleeper = current;
__set_current_state(TASK_INTERRUPTIBLE);
if (timeout)
jiffies_left = schedule_timeout(jiffies_left);
else
schedule();
......
/*
* If an interrupt occurred we have to clean up the queue.
*/
if (timeout && jiffies_left == 0)
error = -EAGAIN;
} while (error == -EINTR && !signal_pending(current)); /* spurious */
......
}
semop会调用semtimedop,这是一个非常复杂的函数。
semtimedop做的第一件事情,就是将用户的参数,例如,对于信号量的操作struct sembuf,拷贝到内核里面来。另外,如果是P操作,很可能让进程进入等待状态,是否要为这个等待状态设置一个超时,timeout也是一个参数,会把它变成时钟的滴答数目。
semtimedop做的第二件事情,是通过sem_obtain_object_check,根据信号量集合的id,获得struct sem_array,然后,创建一个struct sem_queue表示当前的信号量操作。为什么叫queue呢?因为这个操作可能马上就能完成,也可能因为无法获取信号量不能完成,不能完成的话就只好排列到队列上,等待信号量满足条件的时候。semtimedop会调用perform_atomic_semop在实施信号量操作。
static int perform_atomic_semop(struct sem_array *sma, struct sem_queue *q)
{
int result, sem_op, nsops;
struct sembuf *sop;
struct sem *curr;
struct sembuf *sops;
struct sem_undo *un;
sops = q->sops;
nsops = q->nsops;
un = q->undo;
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
......
result += sem_op;
if (result < 0)
goto would_block;
......
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
.....
}
}
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
un->semadj[sop->sem_num] = undo;
}
curr->semval += sem_op;
curr->sempid = q->pid;
}
return 0;
would_block:
q->blocking = sop;
return sop->sem_flg & IPC_NOWAIT ? -EAGAIN : 1;
}
在perform_atomic_semop函数中,对于所有信号量操作都进行两次循环。在第一次循环中,如果发现计算出的result小于0,则说明必须等待,于是跳到would_block中,设置q->blocking = sop表示这个queue是block在这个操作上,然后如果需要等待,则返回1。如果第一次循环中发现无需等待,则第二个循环实施所有的信号量操作,将信号量的值设置为新的值,并且返回0。
接下来,我们回到semtimedop,来看它干的第三件事情,就是如果需要等待,应该怎么办?
如果需要等待,则要区分刚才的对于信号量的操作,是对一个信号量的,还是对于整个信号量集合的。如果是对于一个信号量的,那我们就将queue挂到这个信号量的pending_alter中;如果是对于整个信号量集合的,那我们就将queue挂到整个信号量集合的pending_alter中。
接下来的do-while循环,就是要开始等待了。如果等待没有时间限制,则调用schedule让出CPU;如果等待有时间限制,则调用schedule_timeout让出CPU,过一段时间还回来。当回来的时候,判断是否等待超时,如果没有等待超时则进入下一轮循环,再次等待,如果超时则退出循环,返回错误。在让出CPU的时候,设置进程的状态为TASK_INTERRUPTIBLE,并且循环的结束会通过signal_pending查看是否收到过信号,这说明这个等待信号量的进程是可以被信号中断的,也即一个等待信号量的进程是可以通过kill杀掉的。
我们再来看,semtimedop要做的第四件事情,如果不需要等待,应该怎么办?
如果不需要等待,就说明对于信号量的操作完成了,也改变了信号量的值。接下来,就是一个标准流程。我们通过DEFINE_WAKE_Q(wake_q)声明一个wake_q,调用do_smart_update,看这次对于信号量的值的改变,可以影响并可以激活等待队列中的哪些struct sem_queue,然后把它们都放在wake_q里面,调用wake_up_q唤醒这些进程。其实,所有的对于信号量的值的修改都会涉及这三个操作,如果你回过头去仔细看SETALL和SETVAL操作,在设置完毕信号量之后,也是这三个操作。
我们来看do_smart_update是如何实现的。do_smart_update会调用update_queue。
static int update_queue(struct sem_array *sma, int semnum, struct wake_q_head *wake_q)
{
struct sem_queue *q, *tmp;
struct list_head *pending_list;
int semop_completed = 0;
if (semnum == -1)
pending_list = &sma->pending_alter;
else
pending_list = &sma->sems[semnum].pending_alter;
again:
list_for_each_entry_safe(q, tmp, pending_list, list) {
int error, restart;
......
error = perform_atomic_semop(sma, q);
/* Does q->sleeper still need to sleep? */
if (error > 0)
continue;
unlink_queue(sma, q);
......
wake_up_sem_queue_prepare(q, error, wake_q);
......
}
return semop_completed;
}
static inline void wake_up_sem_queue_prepare(struct sem_queue *q, int error,
struct wake_q_head *wake_q)
{
wake_q_add(wake_q, q->sleeper);
......
}
update_queue会依次循环整个信号量集合的等待队列pending_alter,或者某个信号量的等待队列。试图在信号量的值变了的情况下,再次尝试perform_atomic_semop进行信号量操作。如果不成功,则尝试队列中的下一个;如果尝试成功,则调用unlink_queue从队列上取下来,然后调用wake_up_sem_queue_prepare,将q->sleeper加到wake_q上去。q->sleeper是一个task_struct,是等待在这个信号量操作上的进程。
接下来,wake_up_q就依次唤醒wake_q上的所有task_struct,调用的是我们在进程调度那一节学过的wake_up_process方法。
void wake_up_q(struct wake_q_head *head)
{
struct wake_q_node *node = head->first;
while (node != WAKE_Q_TAIL) {
struct task_struct *task;
task = container_of(node, struct task_struct, wake_q);
node = node->next;
task->wake_q.next = NULL;
wake_up_process(task);
put_task_struct(task);
}
}
至此,对于信号量的主流操作都解析完毕了。
其实还有一点需要强调一下,信号量是一个整个Linux可见的全局资源,而不像咱们在线程同步那一节讲过的都是某个进程独占的资源,好处是可以跨进程通信,坏处就是如果一个进程通过P操作拿到了一个信号量,但是不幸异常退出了,如果没有来得及归还这个信号量,可能所有其他的进程都阻塞了。
那怎么办呢?Linux有一种机制叫SEM_UNDO,也即每一个semop操作都会保存一个反向struct sem_undo操作,当因为某个进程异常退出的时候,这个进程做的所有的操作都会回退,从而保证其他进程可以正常工作。
如果你回头看,我们写的程序里面的semaphore_p函数和semaphore_v函数,都把sem_flg设置为SEM_UNDO,就是这个作用。
等待队列上的每一个struct sem_queue,都有一个struct sem_undo,以此来表示这次操作的反向操作。
struct sem_queue {
struct list_head list; /* queue of pending operations */
struct task_struct *sleeper; /* this process */
struct sem_undo *undo; /* undo structure */
int pid; /* process id of requesting process */
int status; /* completion status of operation */
struct sembuf *sops; /* array of pending operations */
struct sembuf *blocking; /* the operation that blocked */
int nsops; /* number of operations */
bool alter; /* does *sops alter the array? */
bool dupsop; /* sops on more than one sem_num */
};
在进程的task_struct里面对于信号量有一个成员struct sysv_sem,里面是一个struct sem_undo_list,将这个进程所有的semop所带来的undo操作都串起来。
struct task_struct {
......
struct sysv_sem sysvsem;
......
}
struct sysv_sem {
struct sem_undo_list *undo_list;
};
struct sem_undo {
struct list_head list_proc; /* per-process list: *
* all undos from one process
* rcu protected */
struct rcu_head rcu; /* rcu struct for sem_undo */
struct sem_undo_list *ulp; /* back ptr to sem_undo_list */
struct list_head list_id; /* per semaphore array list:
* all undos for one array */
int semid; /* semaphore set identifier */
short *semadj; /* array of adjustments */
/* one per semaphore */
};
struct sem_undo_list {
atomic_t refcnt;
spinlock_t lock;
struct list_head list_proc;
};
为了让你更清楚地理解struct sem_undo的原理,我们这里举一个例子。
假设我们创建了两个信号量集合。一个叫semaphore1,它包含三个信号量,初始化值为3,另一个叫semaphore2,它包含4个信号量,初始化值都为4。初始化时候的信号量以及undo结构里面的值如图中(1)标号所示。
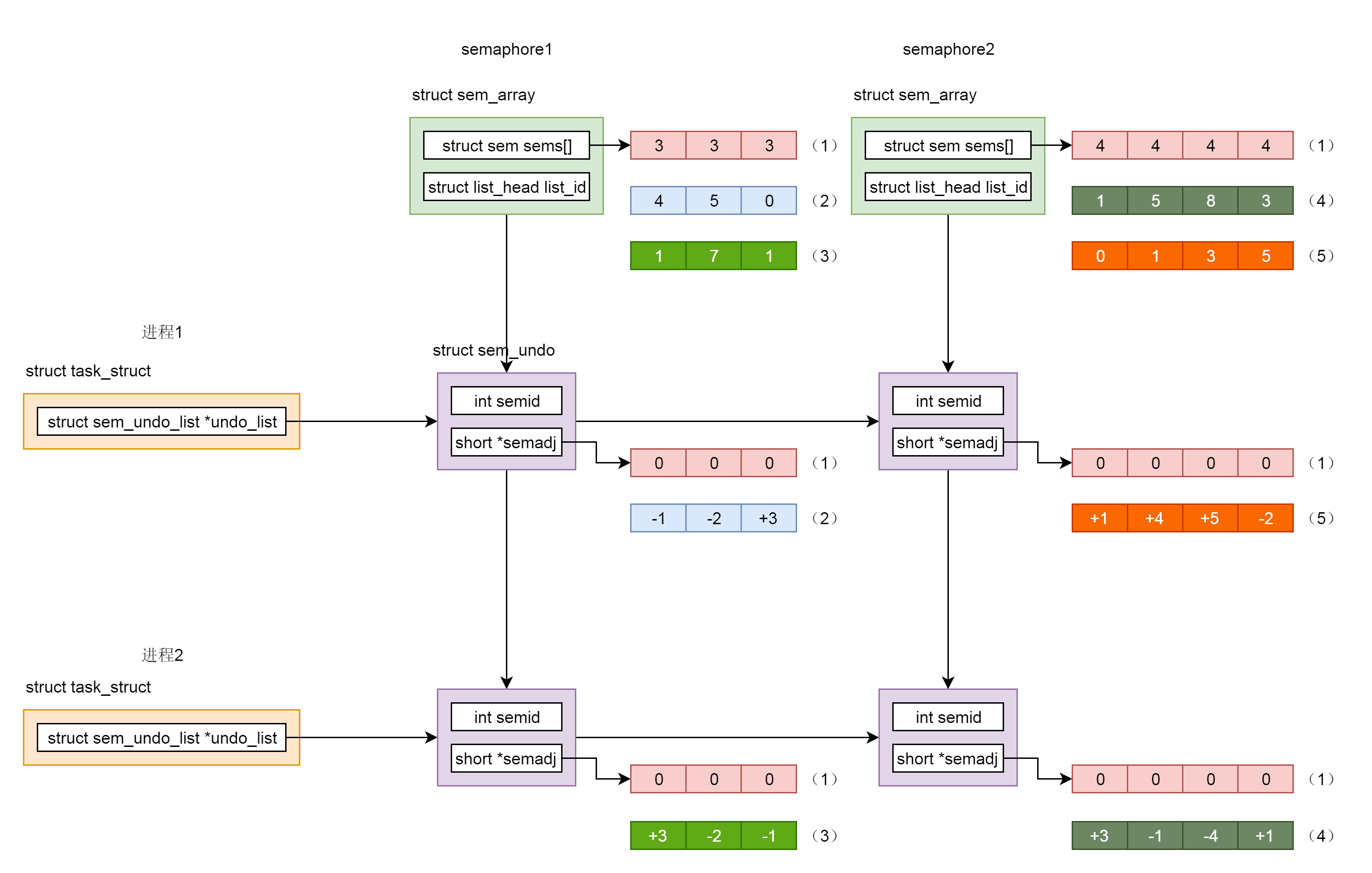
首先,我们来看进程1。我们调用semop,将semaphore1的三个信号量的值,分别加1、加2和减3,从而信号量的值变为4,5,0。于是在semaphore1和进程1链表交汇的undo结构里面,填写-1,-2,+3,是semop操作的反向操作,如图中(2)标号所示。
然后,我们来看进程2。我们调用semop,将semaphore1的三个信号量的值,分别减3、加2和加1,从而信号量的值变为1、7、1。于是在semaphore1和进程2链表交汇的undo结构里面,填写+3、-2、-1,是semop操作的反向操作,如图中(3)标号所示。
然后,我们接着看进程2。我们调用semop,将semaphore2的四个信号量的值,分别减3、加1、加4和减1,从而信号量的值变为1、5、8、3。于是,在semaphore2和进程2链表交汇的undo结构里面,填写+3、-1、-4、+1,是semop操作的反向操作,如图中(4)标号所示。
然后,我们再来看进程1。我们调用semop,将semaphore2的四个信号量的值,分别减1、减4、减5和加2,从而信号量的值变为0、1、3、5。于是在semaphore2和进程1链表交汇的undo结构里面,填写+1、+4、+5、-2,是semop操作的反向操作,如图中(5)标号所示。
从这个例子可以看出,无论哪个进程异常退出,只要将undo结构里面的值加回当前信号量的值,就能够得到正确的信号量的值,不会因为一个进程退出,导致信号量的值处于不一致的状态。
总结时刻
信号量的机制也很复杂,我们对着下面这个图总结一下。
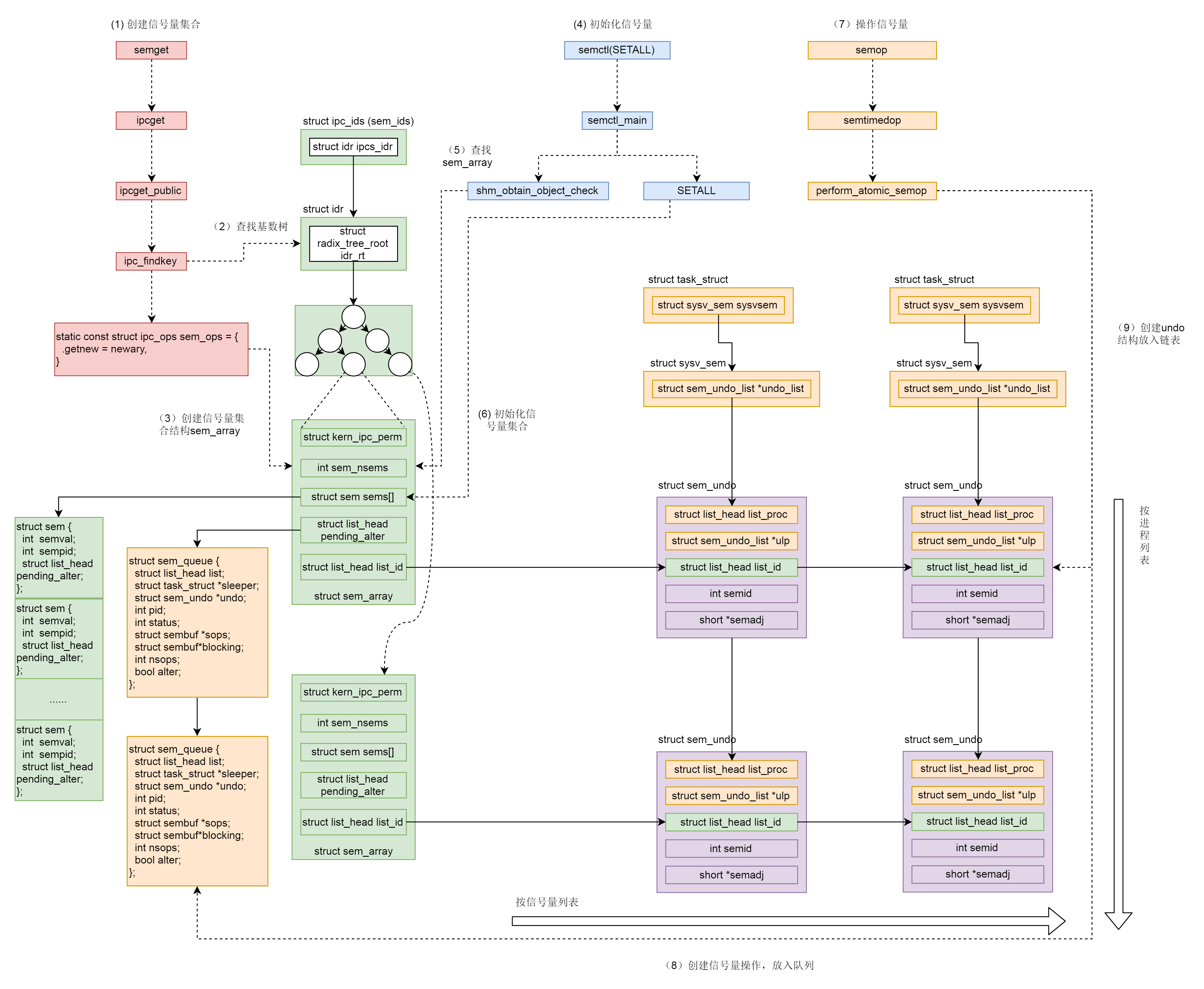
- 调用semget创建信号量集合。
- ipc_findkey会在基数树中,根据key查找信号量集合sem_array对象。如果已经被创建,就会被查询出来。例如producer被创建过,在consumer中就会查询出来。
- 如果信号量集合没有被创建过,则调用sem_ops的newary方法,创建一个信号量集合对象sem_array。例如,在producer中就会新建。
- 调用semctl(SETALL)初始化信号量。
- sem_obtain_object_check先从基数树里面找到sem_array对象。
- 根据用户指定的信号量数组,初始化信号量集合,也即初始化sem_array对象的struct sem sems[]成员。
- 调用semop操作信号量。
- 创建信号量操作结构sem_queue,放入队列。
- 创建undo结构,放入链表。
课堂练习
现在,我们的共享内存、信号量、消息队列都讲完了,你是不是觉得,它们的API非常相似。为了方便记忆,你可以自己整理一个表格,列一下这三种进程间通信机制、行为创建xxxget、使用、控制xxxctl、对应的API和系统调用。
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
- 免费的人 👍(4) 💬(3)
消息队列的内核实现好像没讲过?
2019-07-03 - Geek_835e66 👍(2) 💬(2)
请问消息队列的内容在哪里?
2019-07-16 - 一只特立独行的猪 👍(1) 💬(1)
我们来看进程 2。我们调用 semop,将 semaphore1 的三个信号量的值,分别减 3、加 2 和加 1,从而信号量的值变为 1、7、1 ???
2020-06-14 - 王之刚 👍(0) 💬(1)
请问一下老师,在应用程序开发中,像信号量 共享内存这些内核资源怎么样防止泄漏呢?比如有进程a和b用共享内存共享数据,共享内存资源由教程a申请和维护,但由于异常情况导致教程异常退出导致共享内存资源没有释放,导致了申请的共享内存没有释放。这种情况一般怎么处理呢?Linux内核是否有相关资源保护吗?谢谢了
2019-07-06 - 欢乐小熊 👍(16) 💬(0)
终于把共享内存和信号量集合的知识串联在一起了, 其中的操作的确有些复杂 共享内存若想实现进程之间的同步读写, 则需要配合信号量共同使用 - **共享内存** - **共享内存的创建** - 开辟共享内存区域, 使用 shmid_kernel 描述 - 通过 kvmalloc 在内核的直接映射区分配一个 shmid_kernel 结构体 - 将内存映射到文件 - 这个文件并非磁盘文件, **而是通过内存文件系统 shmem 创建的内存文件** - 这么做的原因是因为**文件可以跨进程共享** - 将这个 shmid_kernel 挂载到共享内存基树上, 返回对应的 id - **共享内存的映射** - 通过 id 在共享内存基树上找到对应的共享内存描述 shmid_kernel - 创建一个 shm_file_data 指向共享内存的内存文件 - 创建一个 file 指向 shm_file_data - 在用户空间找一块内存区域, 将这个 file 映射到用户地址空间 - 通过文件映射之后, 便可以在用户空间操作这块内存了 - **信号量集合** - 信号量集合的创建 - 创建 sem_array 结构体, 用于描述信号量 - 将这个 sem_array 信号量添加到基树上, 返回对应的 id - 信号量集合的初始化 - SETALL: 为所有信号量集合赋值 - SETVAL: 为指定信号量赋值 - 操作信号量集合 - 调用 **perform_atomic_semop** 尝试从操作队列中读取执行 - 若执行成功, 则说明无需等待 - 调用 do_smart_update, 看看这次操作能够激活等待队列中的哪些进程 - 调用 **wake_up_q** 唤醒因为信号量阻塞的进程 - 若需要等待 - 根据是操作信号量还是信号集合, 将其挂载到对应的 pending_alter 中 - 执行 looper 等待, 直到 timeout 或者被 wake_up_q 唤醒 - 若未设置 timeout, 则让出 CPU 资源
2019-07-03 - Helios 👍(11) 💬(1)
思考问题总结了个图: https://user-images.githubusercontent.com/12036324/67062221-431e6f80-f195-11e9-9dd1-4353ebbc730c.png https://github.com/helios741/myblog/issues/60
2019-10-18 - 酷酷的嵩 👍(1) 💬(0)
在 perform_atomic_semop 函数中,对于计算和修改是如何确保原子性的?
2022-08-31 - 莫名 👍(1) 💬(1)
老师,有没有打算讲一下POSIX IPC呢?
2019-07-04 - Run 👍(0) 💬(2)
第一次看到这个的时候月薪8k
2021-12-23 - geek 👍(0) 💬(1)
一个进程已经等待在心信号量上时,如果另一个进程释放了此信号量,原先等待的进程如何知道该提前退出了?按文中的代码,是要一直等到超时,如果没超时,就会一直等下去。
2021-04-26 - 小怪盗kid 👍(0) 💬(0)
老师有两个问题:1.共享内存的创建,是不是只要创建就是在内存中存在,与创建共享内存的进程无关吧,即使该进程异常退出,也不会影响创建好的共享内存?2.某个进程获取信号量,但是这个进程也是异常退出了,信号量没有释放,这个恢复工作由内核完成,还是其他进程需要判断undo结构进行恢复?
2021-03-12 - 安排 👍(0) 💬(2)
schedule_timeout调用完后,会让出cpu,过一段时间还会回来。这个过一段时间是多长时间啊?是说超时之后返回来吗,还是被其它信号打断睡眠之后回来?
2019-07-04