26 内核态内存映射:如何找到正确的会议室?
前面讲用户态内存映射机制的时候,我们已经多次引申出了内核的映射机制,但是咱们都暂时放了放,这一节我们就来详细解析一下,让你彻底搞懂它。
首先,你要知道,内核态的内存映射机制,主要包含以下几个部分:
- 内核态内存映射函数vmalloc、kmap_atomic是如何工作的;
- 内核态页表是放在哪里的,如何工作的?swapper_pg_dir是怎么回事;
- 出现了内核态缺页异常应该怎么办?
内核页表
和用户态页表不同,在系统初始化的时候,我们就要创建内核页表了。
我们从内核页表的根swapper_pg_dir开始找线索,在arch/x86/include/asm/pgtable_64.h中就能找到它的定义。
extern pud_t level3_kernel_pgt[512];
extern pud_t level3_ident_pgt[512];
extern pmd_t level2_kernel_pgt[512];
extern pmd_t level2_fixmap_pgt[512];
extern pmd_t level2_ident_pgt[512];
extern pte_t level1_fixmap_pgt[512];
extern pgd_t init_top_pgt[];
#define swapper_pg_dir init_top_pgt
swapper_pg_dir指向内核最顶级的目录pgd,同时出现的还有几个页表目录。我们可以回忆一下,64位系统的虚拟地址空间的布局,其中XXX_ident_pgt对应的是直接映射区,XXX_kernel_pgt对应的是内核代码区,XXX_fixmap_pgt对应的是固定映射区。
它们是在哪里初始化的呢?在汇编语言的文件里面的arch\x86\kernel\head_64.S。这段代码比较难看懂,你只要明白它是干什么的就行了。
__INITDATA
NEXT_PAGE(init_top_pgt)
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_PAGE_OFFSET*8, 0
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_START_KERNEL*8, 0
/* (2^48-(2*1024*1024*1024))/(2^39) = 511 */
.quad level3_kernel_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level3_ident_pgt)
.quad level2_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.fill 511, 8, 0
NEXT_PAGE(level2_ident_pgt)
/* Since I easily can, map the first 1G.
* Don't set NX because code runs from these pages.
*/
PMDS(0, __PAGE_KERNEL_IDENT_LARGE_EXEC, PTRS_PER_PMD)
NEXT_PAGE(level3_kernel_pgt)
.fill L3_START_KERNEL,8,0
/* (2^48-(2*1024*1024*1024)-((2^39)*511))/(2^30) = 510 */
.quad level2_kernel_pgt - __START_KERNEL_map + _KERNPG_TABLE
.quad level2_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level2_kernel_pgt)
/*
* 512 MB kernel mapping. We spend a full page on this pagetable
* anyway.
*
* The kernel code+data+bss must not be bigger than that.
*
* (NOTE: at +512MB starts the module area, see MODULES_VADDR.
* If you want to increase this then increase MODULES_VADDR
* too.)
*/
PMDS(0, __PAGE_KERNEL_LARGE_EXEC,
KERNEL_IMAGE_SIZE/PMD_SIZE)
NEXT_PAGE(level2_fixmap_pgt)
.fill 506,8,0
.quad level1_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
/* 8MB reserved for vsyscalls + a 2MB hole = 4 + 1 entries */
.fill 5,8,0
NEXT_PAGE(level1_fixmap_pgt)
.fill 51
内核页表的顶级目录init_top_pgt,定义在__INITDATA里面。咱们讲过ELF的格式,也讲过虚拟内存空间的布局。它们都有代码段,还有一些初始化了的全局变量,放在.init区域。这些说的就是这个区域。可以看到,页表的根其实是全局变量,这就使得我们初始化的时候,甚至内存管理还没有初始化的时候,很容易就可以定位到。
接下来,定义init_top_pgt包含哪些项,这个汇编代码比较难懂了。你可以简单地认为,quad是声明了一项的内容,org是跳到了某个位置。
所以,init_top_pgt有三项,上来先有一项,指向的是level3_ident_pgt,也即直接映射区页表的三级目录。为什么要减去__START_KERNEL_map呢?因为level3_ident_pgt是定义在内核代码里的,写代码的时候,写的都是虚拟地址,谁写代码的时候也不知道将来加载的物理地址是多少呀,对不对?
因为level3_ident_pgt是在虚拟地址的内核代码段里的,而__START_KERNEL_map正是虚拟地址空间的内核代码段的起始地址,这在讲64位虚拟地址空间的时候都讲过了,要是想不起来就赶紧去回顾一下。这样,level3_ident_pgt减去__START_KERNEL_map才是物理地址。
第一项定义完了以后,接下来我们跳到PGD_PAGE_OFFSET的位置,再定义一项。从定义可以看出,这一项就应该是__PAGE_OFFSET_BASE对应的。__PAGE_OFFSET_BASE是虚拟地址空间里面内核的起始地址。第二项也指向level3_ident_pgt,直接映射区。
PGD_PAGE_OFFSET = pgd_index(__PAGE_OFFSET_BASE)
PGD_START_KERNEL = pgd_index(__START_KERNEL_map)
L3_START_KERNEL = pud_index(__START_KERNEL_map)
第二项定义完了以后,接下来跳到PGD_START_KERNEL的位置,再定义一项。从定义可以看出,这一项应该是__START_KERNEL_map对应的项,__START_KERNEL_map是虚拟地址空间里面内核代码段的起始地址。第三项指向level3_kernel_pgt,内核代码区。
接下来的代码就很类似了,就是初始化个表项,然后指向下一级目录,最终形成下面这张图。
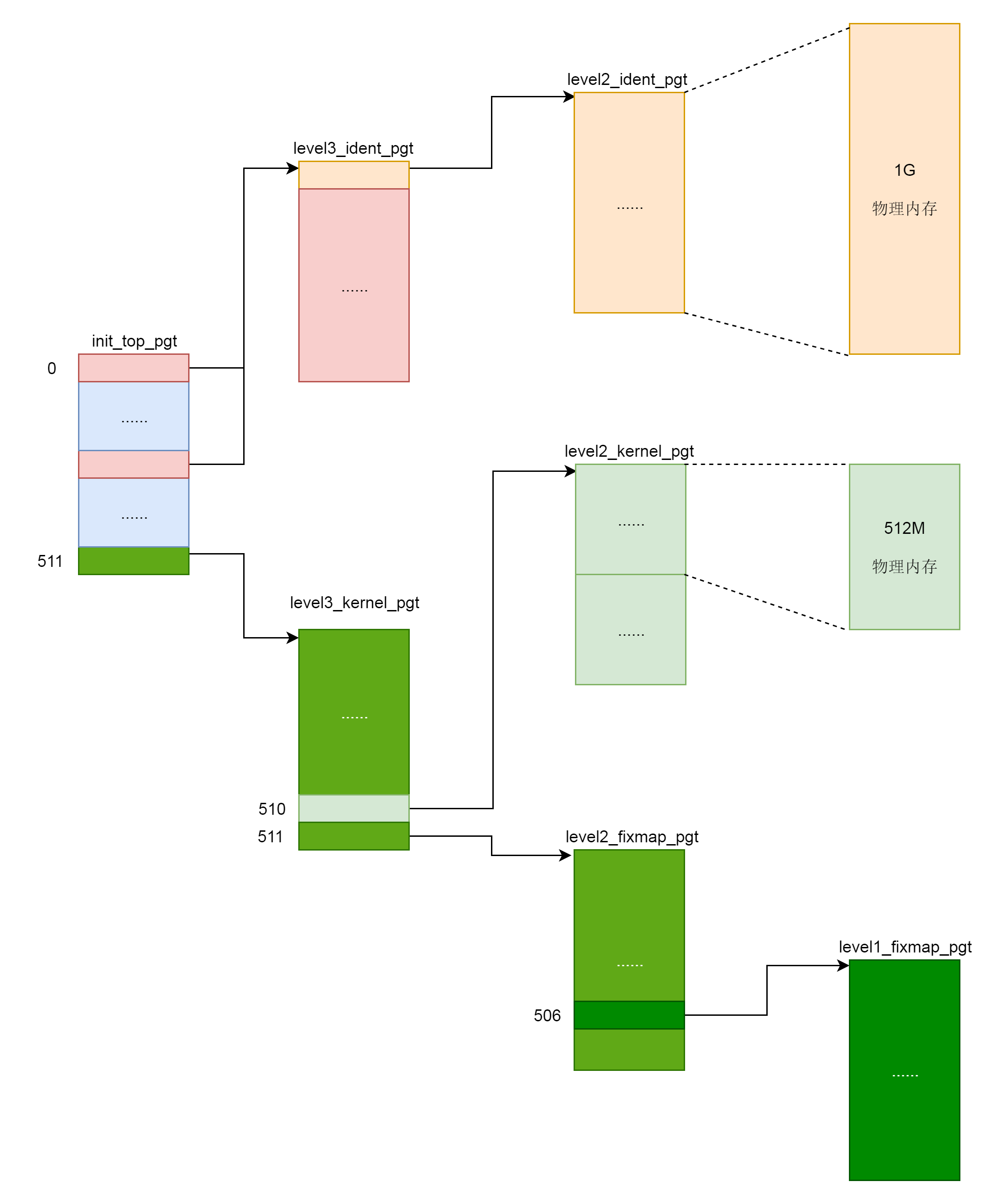
内核页表定义完了,一开始这里面的页表能够覆盖的内存范围比较小。例如,内核代码区512M,直接映射区1G。这个时候,其实只要能够映射基本的内核代码和数据结构就可以了。可以看出,里面还空着很多项,可以用于将来映射巨大的内核虚拟地址空间,等用到的时候再进行映射。
如果是用户态进程页表,会有mm_struct指向进程顶级目录pgd,对于内核来讲,也定义了一个mm_struct,指向swapper_pg_dir。
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
定义完了内核页表,接下来是初始化内核页表,在系统启动的时候start_kernel会调用setup_arch。
void __init setup_arch(char **cmdline_p)
{
/*
* copy kernel address range established so far and switch
* to the proper swapper page table
*/
clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY,
initial_page_table + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
load_cr3(swapper_pg_dir);
__flush_tlb_all();
......
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
init_mm.brk = _brk_end;
......
init_mem_mapping();
......
}
在setup_arch中,load_cr3(swapper_pg_dir)说明内核页表要开始起作用了,并且刷新了TLB,初始化init_mm的成员变量,最重要的就是init_mem_mapping。最终它会调用kernel_physical_mapping_init。
/*
* Create page table mapping for the physical memory for specific physical
* addresses. The virtual and physical addresses have to be aligned on PMD level
* down. It returns the last physical address mapped.
*/
unsigned long __meminit
kernel_physical_mapping_init(unsigned long paddr_start,
unsigned long paddr_end,
unsigned long page_size_mask)
{
unsigned long vaddr, vaddr_start, vaddr_end, vaddr_next, paddr_last;
paddr_last = paddr_end;
vaddr = (unsigned long)__va(paddr_start);
vaddr_end = (unsigned long)__va(paddr_end);
vaddr_start = vaddr;
for (; vaddr < vaddr_end; vaddr = vaddr_next) {
pgd_t *pgd = pgd_offset_k(vaddr);
p4d_t *p4d;
vaddr_next = (vaddr & PGDIR_MASK) + PGDIR_SIZE;
if (pgd_val(*pgd)) {
p4d = (p4d_t *)pgd_page_vaddr(*pgd);
paddr_last = phys_p4d_init(p4d, __pa(vaddr),
__pa(vaddr_end),
page_size_mask);
continue;
}
p4d = alloc_low_page();
paddr_last = phys_p4d_init(p4d, __pa(vaddr), __pa(vaddr_end),
page_size_mask);
p4d_populate(&init_mm, p4d_offset(pgd, vaddr), (pud_t *) p4d);
}
__flush_tlb_all();
return paddr_l
在kernel_physical_mapping_init里,我们先通过__va将物理地址转换为虚拟地址,然后再创建虚拟地址和物理地址的映射页表。
你可能会问,怎么这么麻烦啊?既然对于内核来讲,我们可以用__va和__pa直接在虚拟地址和物理地址之间直接转来转去,为啥还要辛辛苦苦建立页表呢?因为这是CPU和内存的硬件的需求,也就是说,CPU在保护模式下访问虚拟地址的时候,就会用CR3这个寄存器,这个寄存器是CPU定义的,作为操作系统,我们是软件,只能按照硬件的要求来。
你可能又会问了,按照咱们讲初始化的时候的过程,系统早早就进入了保护模式,到了setup_arch里面才load_cr3,如果使用cr3是硬件的要求,那之前是怎么办的呢?如果你仔细去看arch\x86\kernel\head_64.S,这里面除了初始化内核页表之外,在这之前,还有另一个页表early_top_pgt。看到关键字early了嘛?这个页表就是专门用在真正的内核页表初始化之前,为了遵循硬件的要求而设置的。早期页表不是我们这节的重点,这里我就不展开多说了。
vmalloc和kmap_atomic原理
在用户态可以通过malloc函数分配内存,当然malloc在分配比较大的内存的时候,底层调用的是mmap,当然也可以直接通过mmap做内存映射,在内核里面也有相应的函数。
在虚拟地址空间里面,有个vmalloc区域,从VMALLOC_START开始到VMALLOC_END,可以用于映射一段物理内存。
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL);
}
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, 0, node, caller);
}
我们再来看内核的临时映射函数kmap_atomic的实现。从下面的代码我们可以看出,如果是32位有高端地址的,就需要调用set_pte通过内核页表进行临时映射;如果是64位没有高端地址的,就调用page_address,里面会调用lowmem_page_address。其实低端内存的映射,会直接使用__va进行临时映射。
void *kmap_atomic_prot(struct page *page, pgprot_t prot)
{
......
if (!PageHighMem(page))
return page_address(page);
......
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, prot));
......
return (void *)vaddr;
}
void *kmap_atomic(struct page *page)
{
return kmap_atomic_prot(page, kmap_prot);
}
static __always_inline void *lowmem_page_address(const struct page *page)
{
return page_to_virt(page);
}
#define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)
内核态缺页异常
可以看出,kmap_atomic和vmalloc不同。kmap_atomic发现,没有页表的时候,就直接创建页表进行映射了。而vmalloc没有,它只分配了内核的虚拟地址。所以,访问它的时候,会产生缺页异常。
内核态的缺页异常还是会调用do_page_fault,但是会走到咱们上面用户态缺页异常中没有解析的那部分vmalloc_fault。这个函数并不复杂,主要用于关联内核页表项。
/*
* 32-bit:
*
* Handle a fault on the vmalloc or module mapping area
*/
static noinline int vmalloc_fault(unsigned long address)
{
unsigned long pgd_paddr;
pmd_t *pmd_k;
pte_t *pte_k;
/* Make sure we are in vmalloc area: */
if (!(address >= VMALLOC_START && address < VMALLOC_END))
return -1;
/*
* Synchronize this task's top level page-table
* with the 'reference' page table.
*
* Do _not_ use "current" here. We might be inside
* an interrupt in the middle of a task switch..
*/
pgd_paddr = read_cr3_pa();
pmd_k = vmalloc_sync_one(__va(pgd_paddr), address);
if (!pmd_k)
return -1;
pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
return -1;
return 0
总结时刻
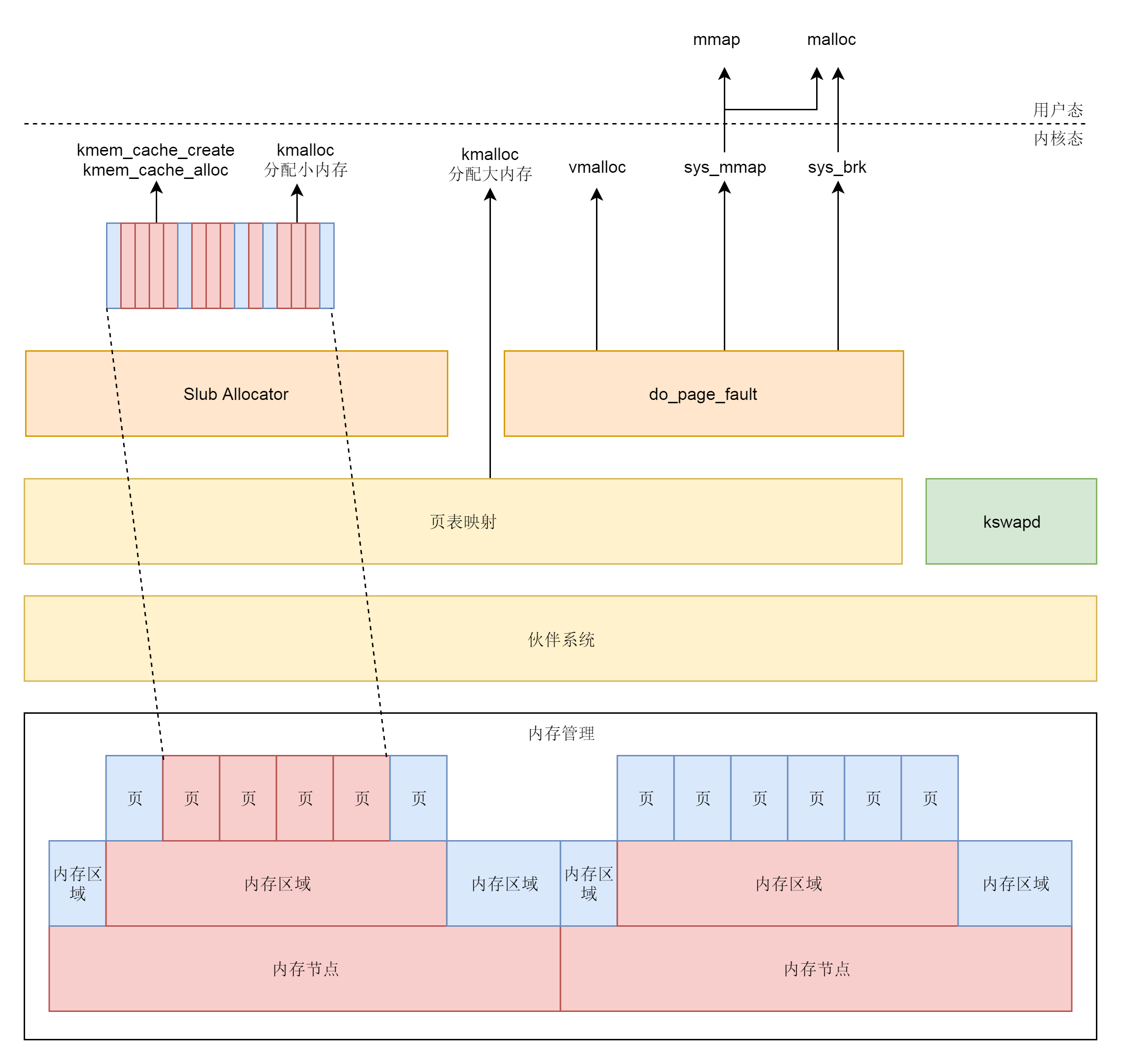
至此,内核态的内存映射也讲完了。这下,我们可以将整个内存管理的体系串起来了。
物理内存根据NUMA架构分节点。每个节点里面再分区域。每个区域里面再分页。
物理页面通过伙伴系统进行分配。分配的物理页面要变成虚拟地址让上层可以访问,kswapd可以根据物理页面的使用情况对页面进行换入换出。
对于内存的分配需求,可能来自内核态,也可能来自用户态。
对于内核态,kmalloc在分配大内存的时候,以及vmalloc分配不连续物理页的时候,直接使用伙伴系统,分配后转换为虚拟地址,访问的时候需要通过内核页表进行映射。
对于kmem_cache以及kmalloc分配小内存,则使用slub分配器,将伙伴系统分配出来的大块内存切成一小块一小块进行分配。
kmem_cache和kmalloc的部分不会被换出,因为用这两个函数分配的内存多用于保持内核关键的数据结构。内核态中vmalloc分配的部分会被换出,因而当访问的时候,发现不在,就会调用do_page_fault。
对于用户态的内存分配,或者直接调用mmap系统调用分配,或者调用malloc。调用malloc的时候,如果分配小的内存,就用sys_brk系统调用;如果分配大的内存,还是用sys_mmap系统调用。正常情况下,用户态的内存都是可以换出的,因而一旦发现内存中不存在,就会调用do_page_fault。
课堂练习
伙伴系统分配好了物理页面之后,如何转换成为虚拟地址呢?请研究一下page_address函数的实现。
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。

- 没心没肺 👍(18) 💬(2)
好恐怖,看到这里,是硬看了
2019-07-05 - ezra.xu 👍(16) 💬(2)
内核能用c语言编写,是不是意味着用c可以直接操作物理内存,另外linux上的c语言编译器是用什么语言开发的,c语言实现了自举吗,c语言跨平台底层原理是什么,请老师答疑解惑。
2019-05-27 - 莫名 👍(7) 💬(1)
👍看起来很有感觉,先讲用户态、内核态虚拟内存的管理,然后讲物理内存的管理,最后讲用户态、内核态虚拟内存与物理内存如何建立关联。
2019-07-18 - LDxy 👍(3) 💬(1)
操作系统是如何知道计算机上有多少物理内存的呢?
2019-06-02 - 活的潇洒 👍(3) 💬(1)
坚持完整的学到底,坚持完整的笔记到底 day26 学习笔记:https://www.cnblogs.com/luoahong/p/10931320.html
2019-05-27 - Mhy 👍(1) 💬(1)
老师,看到这里我是不是可以认为在用户态使用mmap和内核态使用mmap是两码事,我们一般应用场景比如将图片内存直接映射到用户空间上访问避免多次拷贝从而提高图片加载速度,那么这个场景是发生在用户态上面,期间不需要通过内核态吗?调用系统函数触发的mmap是发生在内核态吗,比如strace ls -l
2020-05-08 - Bing 👍(1) 💬(1)
用malloc申请的内存,进程退出时,操作系统是否会释放
2019-08-15 - 栋能 👍(0) 💬(1)
没太看懂kmalloc又是从哪里来的,是写错了么?(这个我还特意往前找了下,以为是kmmap,用于内存映射区的呢)
2019-07-25 - why 👍(23) 💬(0)
- 涉及三块内容: - 内存映射函数 vmalloc, kmap_atomic - 内核态页表存放位置和工作流程 - 内核态缺页异常处理 - 内核态页表, 系统初始化时就创建 - swapper_pg_dir 指向内核顶级页目录 pgd - xxx_ident/kernel/fixmap_pgt 分别是直接映射/内核代码/固定映射的 xxx 级页表目录 - 创建内核态页表 - swapper_pg_dir 指向 init_top_pgt, 是 ELF 文件的全局变量, 因此再内存管理初始化之间就存在 - init_top_pgt 先初始化了三项 - 第一项指向 level3_ident_pgt (内核代码段的某个虚拟地址) 减去 __START_KERNEL_MAP (内核代码起始虚拟地址) 得到实际物理地址 - 第二项也是指向 level3_ident_pgt - 第三项指向 level3_kernel_pgt 内核代码区 - 初始化各页表项, 指向下一集目录 - 页表覆盖范围较小, 内核代码 512MB, 直接映射区 1GB - 内核态也定义 mm_struct 指向 swapper_pg_dir - 初始化内核态页表, start_kernel→ setup_arch - load_cr3(swapper_pg_dir) 并刷新 TLB - 调用 init_mem_mapping→kernel_physical_mapping_init, 用 __va 将物理地址映射到虚拟地址, 再创建映射页表项 - CPU 在保护模式下访问虚拟地址都必须通过 cr3, 系统只能照做 - 在 load_cr3 之前, 通过 early_top_pgt 完成映射 - vmalloc 和 kmap_atomic - 内核的虚拟地址空间 vmalloc 区域用于映射 - kmap_atomic 临时映射 - 32 位, 调用 set_pte 通过内核页表临时映射 - 64 位, 调用 page_address→lowmem_page_address 进行映射 - 内核态缺页异常 - kmap_atomic 直接创建页表进行映射 - vmalloc 只分配内核虚拟地址, 访问时触发缺页中断, 调用 do_page_fault→vmalloc_fault 用于关联内核页表项 - kmem_cache 和 kmalloc 用于保存内核数据结构, 不会被换出; 而内核 vmalloc 会被换出
2019-05-27 - 活的潇洒 👍(20) 💬(2)
决心从头把计算机所有的基础课程全部补上,夯实基础,一定要坚持到最后 day26笔记:https://www.cnblogs.com/luoahong/p/10931320.html
2019-05-29 - czh 👍(10) 💬(0)
整个内存的讲解(这个专栏内容如果一下看不懂直接跳总结部分,甚至每章的最后,现有个整体认识,再返回去看细节,会容易很多)
2019-11-25 - garlic 👍(4) 💬(0)
伙伴系统分配好了物理页面到虚拟地址:有两种情况 1. 申请时转换, 直接使用伙伴系统申请页,通过page_address进行地址转换,如kmalloc申请大于2个页面时 通过SLAB从伙伴系统申请页,创建new slab时通过page_address进行地址转换, 如vmalloc, VMA结构体申请时 2. 有虚拟地址挂载页面 有指定虚拟地址范围,再通过伙伴系统申请空间,申请释放时统一进行更新页表项, 如vmalloc 课堂学习笔记: https://garlicspace.com/2020/08/12/%e4%bc%99%e4%bc%b4%e7%b3%bb%e7%bb%9f%e5%88%86%e9%85%8d%e7%89%a9%e7%90%86%e9%a1%b5%e5%90%8e%e5%a6%82%e4%bd%95%e8%bd%ac%e6%8d%a2%e6%88%90%e4%b8%ba%e8%99%9a%e6%8b%9f%e5%9c%b0%e5%9d%80/
2020-08-12 - dll 👍(3) 💬(0)
真的反复看了几遍,没理解init_top_pgt里的三项指的是什么,我觉得有时候文章还是有点写的词不达意,代码有点缺失,真的看起来好幸苦
2022-03-25 - 奔跑的码仔 👍(2) 💬(0)
page_address的实现如下:
- 如果不是高端内存,物理地址和虚拟地址之间的转换相对比较简单,直接使用lowmme_page_address进行转换,前面提到过这个函数; - 对于非高端内存页,通过page_slot计算出pas,pas保存在由pagez作为key的hash表page_address_htable中; - 遍历pas->lh双向链表,链表的节点保存有page的地址和page所对应的虚拟地址,通过page,可以确定page对应的虚拟地址。2019-09-03/** * page_address - get the mapped virtual address of a page * @page: &struct page to get the virtual address of * * Returns the page's virtual address. */ void *page_address(const struct page *page) { unsigned long flags; void *ret; struct page_address_slot *pas; if (!PageHighMem(page)) return lowmem_page_address(page); pas = page_slot(page); ret = NULL; spin_lock_irqsave(&pas->lock, flags); if (!list_empty(&pas->lh)) { struct page_address_map *pam; list_for_each_entry(pam, &pas->lh, list) { if (pam->page == page) { ret = pam->virtual; goto done; } } } done: spin_unlock_irqrestore(&pas->lock, flags); return ret; } - geek 👍(1) 💬(0)
page_address_map结构体中保存了page和对应虚拟地址的映射关系。 每个page对象保存在page_address_htable中,映射到相同slot的pages会形成一个链表。page_address方法就是根据page找到slot,遍历对应slot的链表,找到page相同的那项,返回其对应的虚拟地址。
2021-04-04