54 理解Disruptor(上):带你体会CPU高速缓存的风驰电掣
坚持到底就是胜利,终于我们一起来到了专栏的最后一个主题。让我一起带你来看一看,CPU到底能有多快。在接下来的两讲里,我会带你一起来看一个开源项目Disruptor。看看我们怎么利用CPU和高速缓存的硬件特性,来设计一个对于性能有极限追求的系统。
不知道你还记不记得,在第37讲里,为了优化4毫秒专门铺设光纤的故事。实际上,最在意极限性能的并不是互联网公司,而是高频交易公司。我们今天讲解的Disruptor就是由一家专门做高频交易的公司LMAX开源出来的。
有意思的是,Disruptor的开发语言,并不是很多人心目中最容易做到性能极限的C/C++,而是性能受限于JVM的Java。这到底是怎么一回事呢?那通过这一讲,你就能体会到,其实只要通晓硬件层面的原理,即使是像Java这样的高级语言,也能够把CPU的性能发挥到极限。
Padding Cache Line,体验高速缓存的威力
我们先来看看Disruptor里面一段神奇的代码。这段代码里,Disruptor在RingBufferPad这个类里面定义了p1,p2一直到p7 这样7个long类型的变量。
我在看到这段代码的第一反应是,变量名取得不规范,p1-p7这样的变量名没有明确的意义啊。不过,当我深入了解了Disruptor的设计和源代码,才发现这些变量名取得恰如其分。因为这些变量就是没有实际意义,只是帮助我们进行缓存行填充(Padding Cache Line),使得我们能够尽可能地用上CPU高速缓存(CPU Cache)。那么缓存行填充这个黑科技到底是什么样的呢?我们接着往下看。
不知道你还记不记得,我们在35讲里面的这个表格。如果访问内置在CPU里的L1 Cache或者L2 Cache,访问延时是内存的1/15乃至1/100。而内存的访问速度,其实是远远慢于CPU的。想要追求极限性能,需要我们尽可能地多从CPU Cache里面拿数据,而不是从内存里面拿数据。

CPU Cache装载内存里面的数据,不是一个一个字段加载的,而是加载一整个缓存行。举个例子,如果我们定义了一个长度为64的long类型的数组。那么数据从内存加载到CPU Cache里面的时候,不是一个一个数组元素加载的,而是一次性加载固定长度的一个缓存行。
我们现在的64位Intel CPU的计算机,缓存行通常是64个字节(Bytes)。一个long类型的数据需要8个字节,所以我们一下子会加载8个long类型的数据。也就是说,一次加载数组里面连续的8个数值。这样的加载方式使得我们遍历数组元素的时候会很快。因为后面连续7次的数据访问都会命中缓存,不需要重新从内存里面去读取数据。这个性能层面的好处,我在第37讲的第一个例子里面为你演示过,印象不深的话,可以返回去看看。
但是,在我们不使用数组,而是使用单独的变量的时候,这里就会出现问题了。在Disruptor的RingBuffer(环形缓冲区)的代码里面,定义了一个RingBufferFields类,里面有indexMask和其他几个变量,用来存放RingBuffer的内部状态信息。
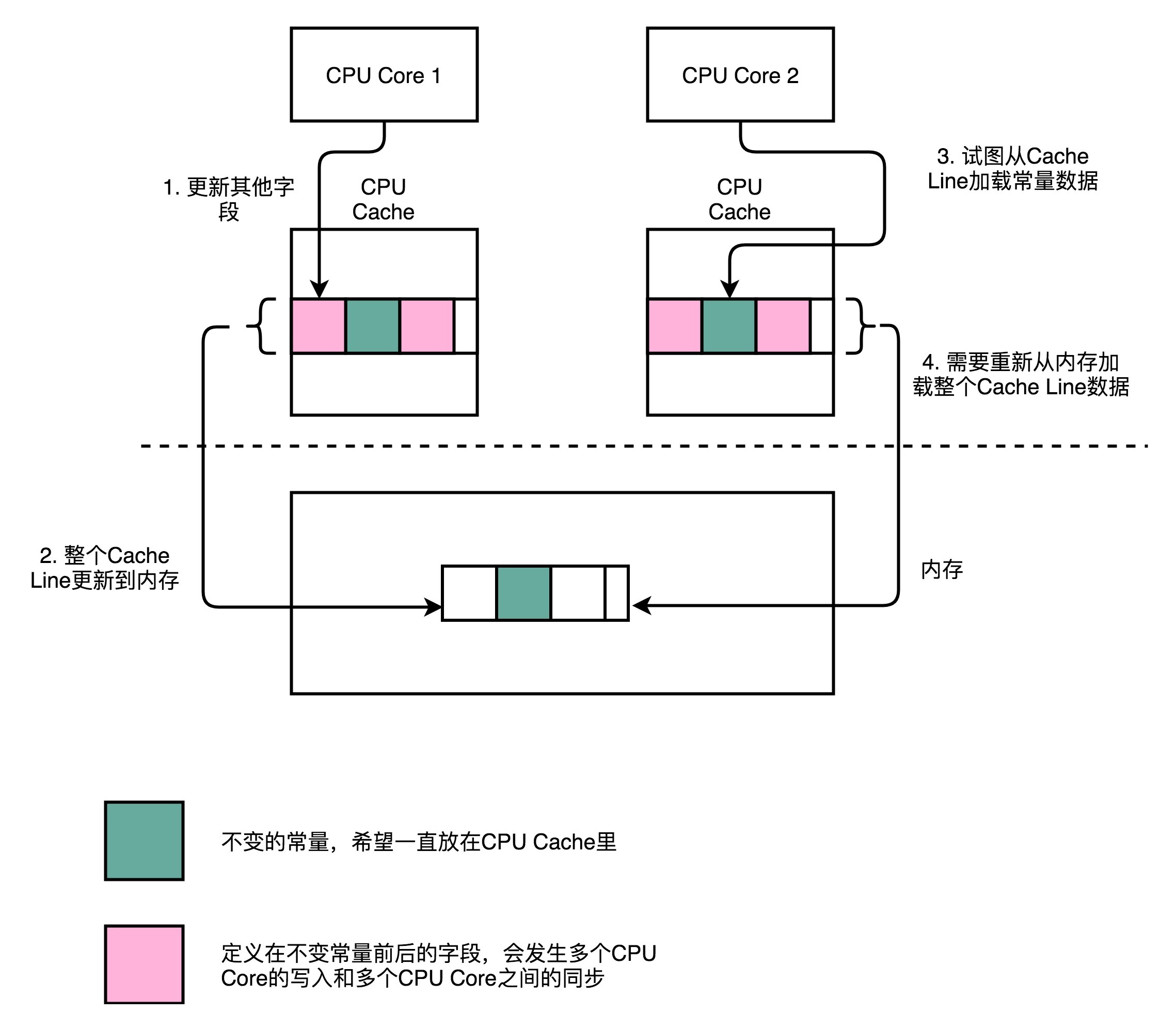
CPU在加载数据的时候,自然也会把这个数据从内存加载到高速缓存里面来。不过,这个时候,高速缓存里面除了这个数据,还会加载这个数据前后定义的其他变量。这个时候,问题就来了。Disruptor是一个多线程的服务器框架,在这个数据前后定义的其他变量,可能会被多个不同的线程去更新数据、读取数据。这些写入以及读取的请求,会来自于不同的 CPU Core。于是,为了保证数据的同步更新,我们不得不把CPU Cache里面的数据,重新写回到内存里面去或者重新从内存里面加载数据。
而我们刚刚说过,这些CPU Cache的写回和加载,都不是以一个变量作为单位的。这些动作都是以整个Cache Line作为单位的。所以,当INITIAL_CURSOR_VALUE 前后的那些变量被写回到内存的时候,这个字段自己也写回到了内存,这个常量的缓存也就失效了。当我们要再次读取这个值的时候,要再重新从内存读取。这也就意味着,读取速度大大变慢了。
......
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad
{
......
private final long indexMask;
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
......
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
......
protected long p1, p2, p3, p4, p5, p6, p7;
......
}
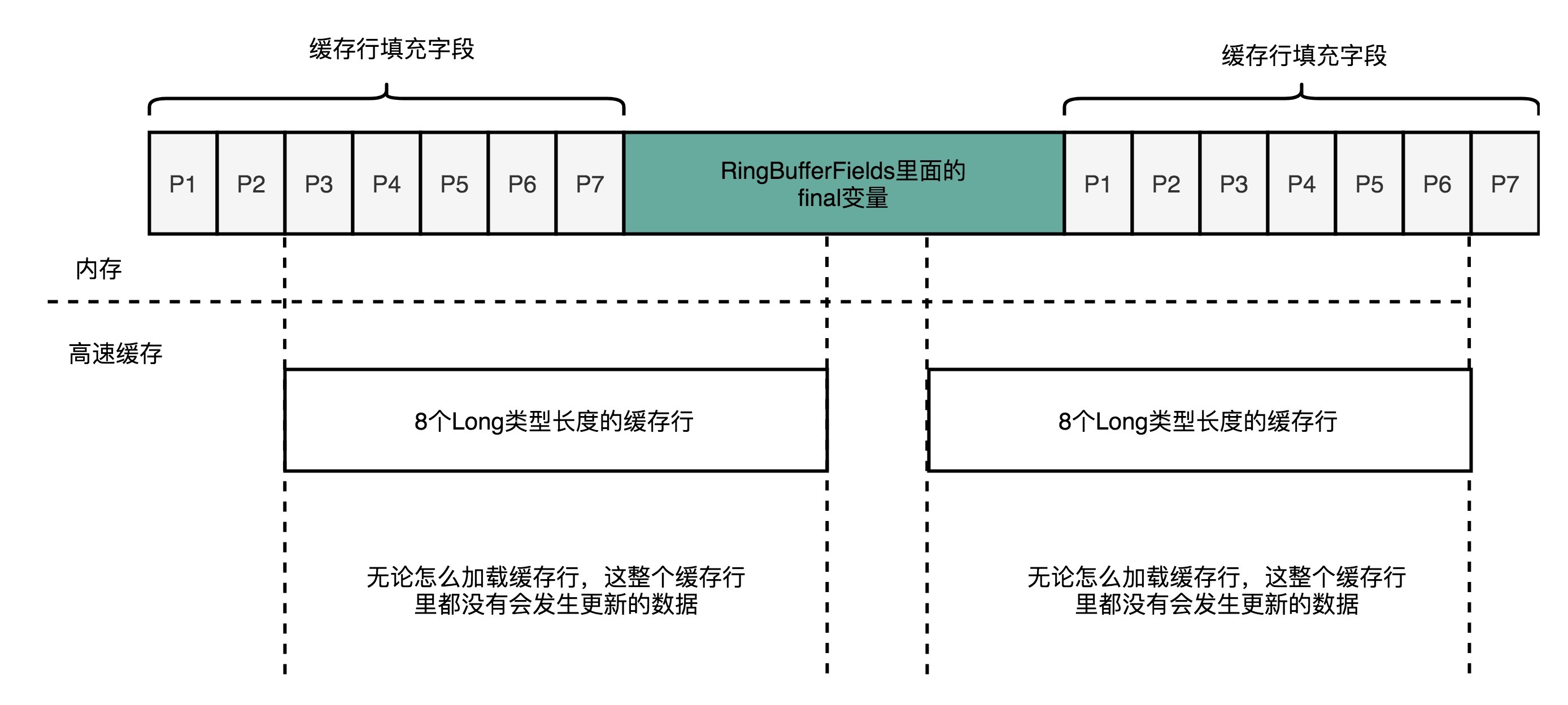
面临这样一个情况,Disruptor里发明了一个神奇的代码技巧,这个技巧就是缓存行填充。Disruptor 在 RingBufferFields里面定义的变量的前后,分别定义了7个long类型的变量。前面的7个来自继承的 RingBufferPad 类,后面的7个则是直接定义在 RingBuffer 类里面。这14个变量没有任何实际的用途。我们既不会去读他们,也不会去写他们。
而RingBufferFields里面定义的这些变量都是final的,第一次写入之后不会再进行修改。所以,一旦它被加载到CPU Cache之后,只要被频繁地读取访问,就不会再被换出Cache了。这也就意味着,对于这个值的读取速度,会是一直是CPU Cache的访问速度,而不是内存的访问速度。
使用RingBuffer,利用缓存和分支预测
其实这个利用CPU Cache的性能的思路,贯穿了整个Disruptor。Disruptor整个框架,其实就是一个高速的生产者-消费者模型(Producer-Consumer)下的队列。生产者不停地往队列里面生产新的需要处理的任务,而消费者不停地从队列里面处理掉这些任务。
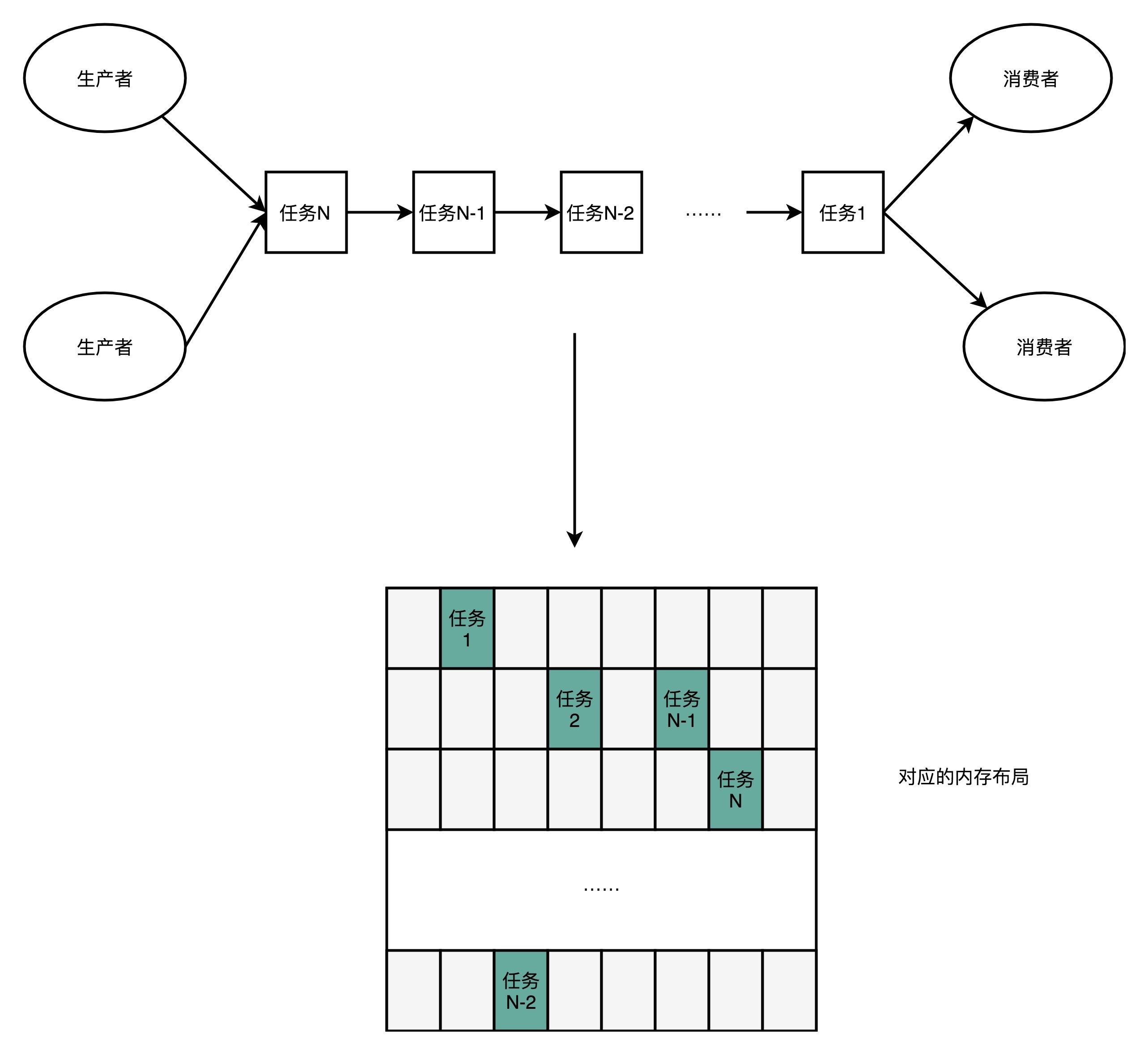
如果你熟悉算法和数据结构,那你应该非常清楚,如果要实现一个队列,最合适的数据结构应该是链表。我们只要维护好链表的头和尾,就能很容易实现一个队列。生产者只要不断地往链表的尾部不断插入新的节点,而消费者只需要不断从头部取出最老的节点进行处理就好了。我们可以很容易实现生产者-消费者模型。实际上,Java自己的基础库里面就有LinkedBlockingQueue这样的队列库,可以直接用在生产者-消费者模式上。
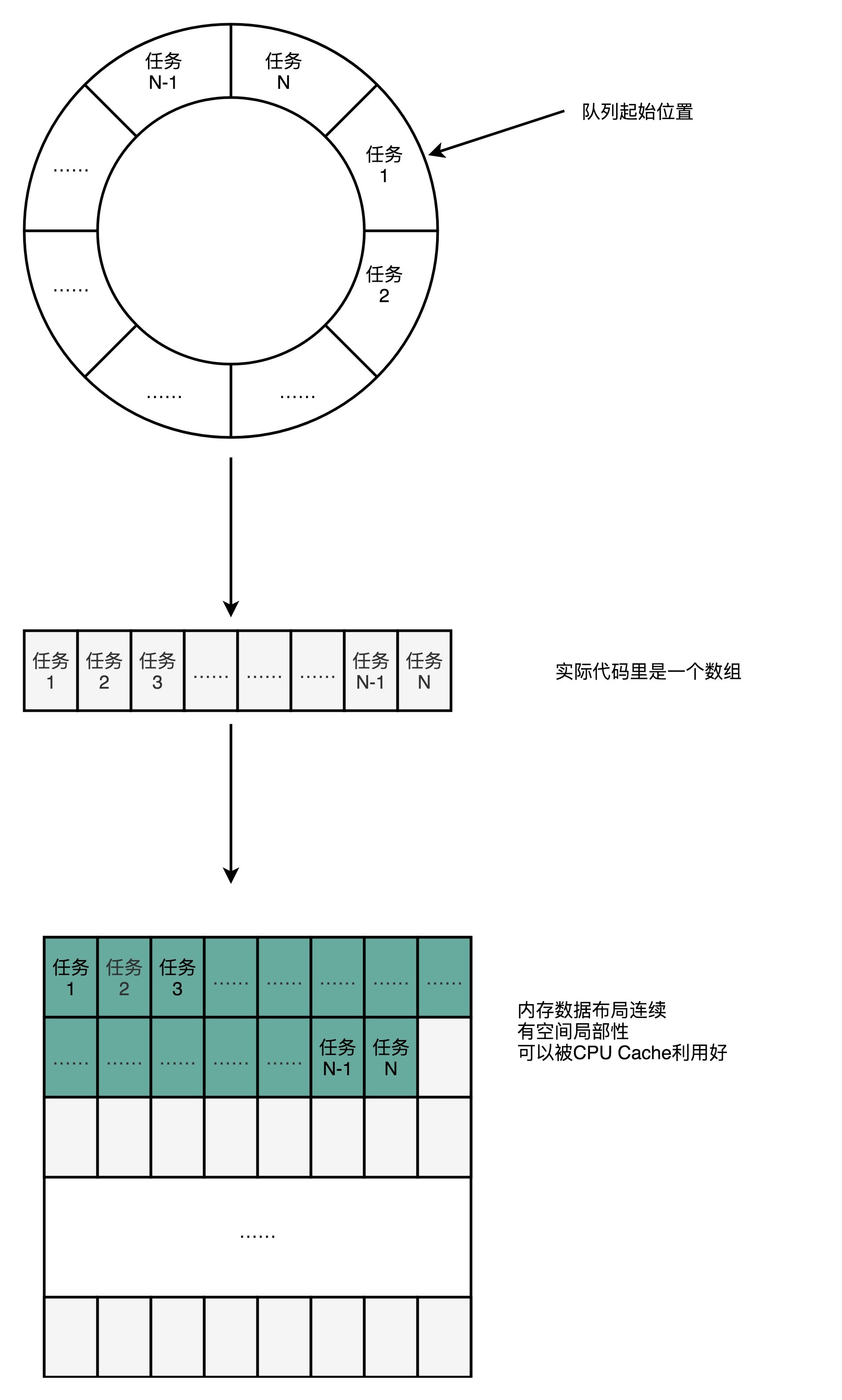
不过,Disruptor里面并没有用LinkedBlockingQueue,而是使用了一个RingBuffer这样的数据结构,这个RingBuffer的底层实现则是一个固定长度的数组。比起链表形式的实现,数组的数据在内存里面会存在空间局部性。
就像上面我们看到的,数组的连续多个元素会一并加载到CPU Cache里面来,所以访问遍历的速度会更快。而链表里面各个节点的数据,多半不会出现在相邻的内存空间,自然也就享受不到整个Cache Line加载后数据连续从高速缓存里面被访问到的优势。
除此之外,数据的遍历访问还有一个很大的优势,就是CPU层面的分支预测会很准确。这可以使得我们更有效地利用了CPU里面的多级流水线,我们的程序就会跑得更快。这一部分的原理如果你已经不太记得了,可以回过头去复习一下第25讲关于分支预测的内容。
总结延伸
好了,不知道讲完这些,你有没有体会到Disruptor这个框架的神奇之处呢?
CPU从内存加载数据到CPU Cache里面的时候,不是一个变量一个变量加载的,而是加载固定长度的Cache Line。如果是加载数组里面的数据,那么CPU就会加载到数组里面连续的多个数据。所以,数组的遍历很容易享受到CPU Cache那风驰电掣的速度带来的红利。
对于类里面定义的单独的变量,就不容易享受到CPU Cache红利了。因为这些字段虽然在内存层面会分配到一起,但是实际应用的时候往往没有什么关联。于是,就会出现多个CPU Core访问的情况下,数据频繁在CPU Cache和内存里面来来回回的情况。而Disruptor很取巧地在需要频繁高速访问的变量,也就是RingBufferFields里面的indexMask这些字段前后,各定义了7个没有任何作用和读写请求的long类型的变量。
这样,无论在内存的什么位置上,这些变量所在的Cache Line都不会有任何写更新的请求。我们就可以始终在Cache Line里面读到它的值,而不需要从内存里面去读取数据,也就大大加速了Disruptor的性能。
这样的思路,其实渗透在Disruptor这个开源框架的方方面面。作为一个生产者-消费者模型,Disruptor并没有选择使用链表来实现一个队列,而是使用了RingBuffer。RingBuffer底层的数据结构则是一个固定长度的数组。这个数组不仅让我们更容易用好CPU Cache,对CPU执行过程中的分支预测也非常有利。更准确的分支预测,可以使得我们更好地利用好CPU的流水线,让代码跑得更快。
推荐阅读
今天讲的是Disruptor,推荐的阅读内容自然是Disruptor的官方文档。作为一个开源项目,Disruptor在自己GitHub上有很详细的设计文档,推荐你好好阅读一下。
这里面不仅包含了怎么用好Disruptor,也包含了整个Disruptor框架的设计思路,是一份很好的阅读学习材料。另外,Disruptor的官方文档里,还有很多文章、演讲,详细介绍了这个框架,很值得深入去看一看。Disruptor的源代码其实并不复杂,很适合用来学习怎么阅读开源框架代码。
课后思考
今天我们讲解了缓存行填充,你可以试试修改Disruptor的代码,看看在没有缓存行填充和有缓存行填充的情况下的性能差异。你也可以尝试直接修改Disruptor的源码和性能测试代码,看看运行的结果是什么样的。
欢迎你把你的测试结果写在留言区,和大家一起讨论、分享。如果有收获,你也可以把这篇文章分享给你的朋友。
- 小海海 👍(48) 💬(4)
老师,有个疑惑的地方:文中讲了RingBuffer类利用缓存行填充来解决INITIAL_CURSOR_VALUE伪共享的问题,但是我记得Java对象内存布局是:实例变量放在堆区,静态变量属于类,放在方法区,而堆区和方法区在内存里肯定是隔离开的,但是RingBuffer的前后填充字段都是实例字段,而INITIAL_CURSOR_VALUE是静态常量,所以实际运行中他们肯定不是紧密排列在一起的,那么就解决不了伪共享的问题了,况且RingBuffer的子类RingBufferFields还有其他实例字段,如:indexMask、entries、bufferSize、sequencer,这些字段都是final修饰的,即对象构建后不会再修改,所以我理解前后的缓存行填充守护的应该是这几个字段,而且从子类RingBufferFields的命名也可以看出前面那几个字段才是想要缓存的字段。希望得到老师的回复,另外课程快结束了,一路跟下来收获很大,我准备这段时间二刷来巩固下^_^
2019-09-09 - 山间竹 👍(39) 💬(1)
在java8中,jvm团队搞出了@Contended注解来进行支持,在你需要避免“false sharing”的字段上标记注解,这可以暗示虚拟机“这个字段可以分离到不同的cache line中”,这是JEP 142的目标。
2020-01-06 - D 👍(24) 💬(2)
这个是不是和前面讲的msei有一定关系啊,请徐老师点拨
2019-09-06 - -_-||| 👍(20) 💬(5)
“而 Disruptor 很取巧地在需要频繁高速访问的变量,也就是 RingBufferFields 里面的 indexMask 这些字段前后,各定义了 7 个没有任何作用和读写请求的 long 类型的变量。”为什么前后各7个,cache line 就没有写的请求,就是因为8个long正好64byte吗,为什么没有写的呢?
2020-01-31 - leslie 👍(18) 💬(2)
老师今天说的这个东西其实就是MQ:只不过现在的MQ基本上是在充分利用内存/缓存,而disruptor其实是在利用CPU cache。刘超老师有一点确实没有说错“计算机组成原理和操作系统相辅相成”:学到今天去相互结合确实发现这种收益远比单独学习好。 扩展的问老师一个问题:现在所谓的智能芯片或者说前端时间提出的智能芯片,会对后续产生革命性影响么?毕竟硬件的i5到现在差不多十多年了其实进步不大,这十余年最大的变化莫过于内存容量的暴涨造就了nosql、MQ的兴起,如果说将来cache的变化是吧同样可能早就类似于老师今天所说的Disruptor这种基于CPU Cache技术的兴起。 今年华为的AI CPU、老美那边的云计算CPU似乎实验室测试已经通过了:毕竟从奔腾4之后到现在近20年了,老师今天所说的又刚好符合现在关键硬件CPU的革新时期?老师对此是如何看待?希望老师能提点。
2019-09-06 - Scott 👍(14) 💬(1)
最好说明一下,这种填充cache line的手法是为了防止False Sharing
2019-09-06 - 易儿易 👍(7) 💬(1)
经典的东西总是容易被频繁引用,disruptor记得没错应该是在java并发实战专栏里被王宝令老师讲过,今天又一次学习,加深了印象……拍个双响马屁:两位老师都有很高的水准,深入浅出!
2019-09-08 - -_-||| 👍(2) 💬(1)
“我们现在的 64 位 Intel CPU 的计算机,缓存行通常是 64 个字节(Bytes)”,64位为什么不是64bit而是设计成64Byte的缓存行,感觉应该叫64比特intel CPU的计算机。
2020-01-31 - 许童童 👍(2) 💬(1)
老师讲得实在是太好了。
2019-09-07 - 等风来 👍(3) 💬(3)
老师, 我对于前后7个long有点疑惑, 我大概知道是为了防止被换出, 但就是不知道为什么可以😂, 可以举例说明一下吗
2019-10-10 - jssfy 👍(2) 💬(0)
这一系列文章太赞了,这几天一有空就看,完全停不下来!真实场景代码配合原理,特别是各个文末推荐的阅读,真所谓授之以渔。
2021-10-28 - 余巍 👍(2) 💬(0)
注意一下类是abstract。父子类属性原理。pad父类填充属性在前,field父类的属性被保护在中间,ringbuffer子类填充属性在最后。这样就杜绝被其他cache line影响。
2020-11-06 - InvisibleDes 👍(2) 💬(0)
对分支预测的执行很有利,这一点没有看懂
2020-10-17 - Geek_e9a05e 👍(1) 💬(1)
请教一下大家,老师文中说了数组形式的数据进行遍历访问时,会增加分支预测的准确性,我不太理解,为什么呢?
2022-07-19 - 曾经瘦过 👍(1) 💬(0)
赞,之前还以 计算机组成原理主要是架构师 选择技术 硬件 的时候使用的,原来在代码层面也可以这样使用。不过虽然能看懂他代码的意思,但是还不不太理解他是如何实现的,怎么写可以做到这样的,需要进一步的研究一下
2019-11-01