52 设计大型DMP系统(上):MongoDB并不是什么灵丹妙药
如果你一讲一讲跟到现在,那首先要恭喜你,马上就看到胜利的曙光了。过去的50多讲里,我把计算机组成原理中的各个知识点,一点一点和你拆解了。对于其中的很多知识点,我也给了相应的代码示例和实际的应用案例。
不过呢,相信你和我一样,觉得只了解这样一个个零散的知识点和案例还不过瘾。那么从今天开始,我们就进入应用篇。我会通过两个应用系统的案例,串联起计算机组成原理的两大块知识点,一个是我们的整个存储器系统,另一个自然是我们的CPU和指令系统了。
我们今天就先从搭建一个大型的DMP系统开始,利用组成原理里面学到的存储器知识,来做选型判断,从而更深入地理解计算机组成原理。
DMP:数据管理平台
我们先来看一下什么是DMP系统。DMP系统的全称叫作数据管理平台(Data Management Platform),目前广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)这些领域。
通常来说,DMP系统会通过处理海量的互联网访问数据以及机器学习算法,给一个用户标注上各种各样的标签。然后,在我们做个性化推荐和广告投放的时候,再利用这些这些标签,去做实际的广告排序、推荐等工作。无论是Google的搜索广告、淘宝里千人千面的商品信息,还是抖音里面的信息流推荐,背后都会有一个DMP系统。
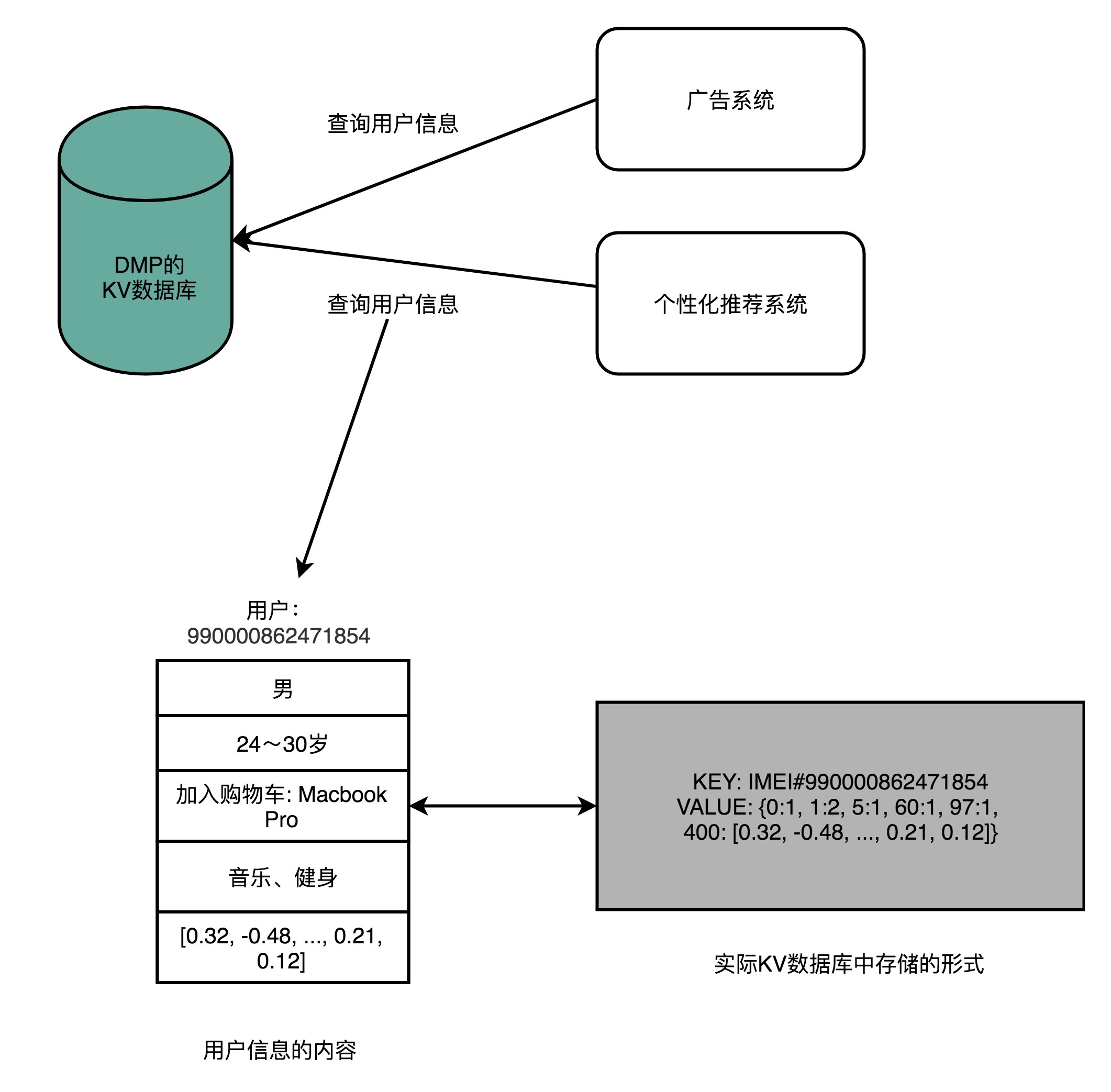
那么,一个DMP系统应该怎么搭建呢?对于外部使用DMP的系统或者用户来说,可以简单地把DMP看成是一个键-值对(Key-Value)数据库。我们的广告系统或者推荐系统,可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息。
这些信息中,有些是用户的人口属性信息(Demographic),比如性别、年龄;有些是非常具体的行为(Behavior),比如用户最近看过的商品是什么,用户的手机型号是什么;有一些是我们通过算法系统计算出来的兴趣(Interests),比如用户喜欢健身、听音乐;还有一些则是完全通过机器学习算法得出的用户向量,给后面的推荐算法或者广告算法作为数据输入。
基于此,对于这个KV数据库,我们的期望也很清楚,那就是:低响应时间(Low Response Time)、高可用性(High Availability)、高并发(High Concurrency)、海量数据(Big Data),同时我们需要付得起对应的成本(Affordable Cost)。如果用数字来衡量这些指标,那么我们的期望就会具体化成下面这样。
- 低响应时间:一般的广告系统留给整个广告投放决策的时间也就是10ms左右,所以对于访问DMP获取用户数据,预期的响应时间都在1ms之内。
- 高可用性:DMP常常用在广告系统里面。DMP系统出问题,往往就意味着我们整个的广告收入在不可用的时间就没了,所以我们对于可用性的追求可谓是没有上限的。Google 2018年的广告收入是1160亿美元,折合到每一分钟的收入是22万美元。即使我们做到 99.99% 的可用性,也意味着每个月我们都会损失100万美元。
- 高并发:还是以广告系统为例,如果每天我们需要响应100亿次的广告请求,那么我们每秒的并发请求数就在 100亿 / (86400) ~= 12K 次左右,所以我们的DMP需要支持高并发。
- 数据量:如果我们的产品针对中国市场,那么我们需要有10亿个Key,对应的假设每个用户有500个标签,标签有对应的分数。标签和分数都用一个4字节(Bytes)的整数来表示,那么一共我们需要 10亿 x 500 x (4 + 4) Bytes = 4 TB 的数据了。
- 低成本:我们还是从广告系统的角度来考虑。广告系统的收入通常用CPM(Cost Per Mille),也就是千次曝光来统计。如果千次曝光的利润是 0.10美元,那么每天100亿次的曝光就是100万美元的利润。这个利润听起来非常高了。但是反过来算一下,你会发现,DMP每1000次的请求的成本不能超过 0.10美元。最好只有0.01美元,甚至更低,我们才能尽可能多赚到一点广告利润。
这五个因素一结合,听起来是不是就不那么简单了?不过,更复杂的还在后面呢。
虽然从外部看起来,DMP特别简单,就是一个KV数据库,但是生成这个数据库需要做的事情更多。我们下面一起来看一看。
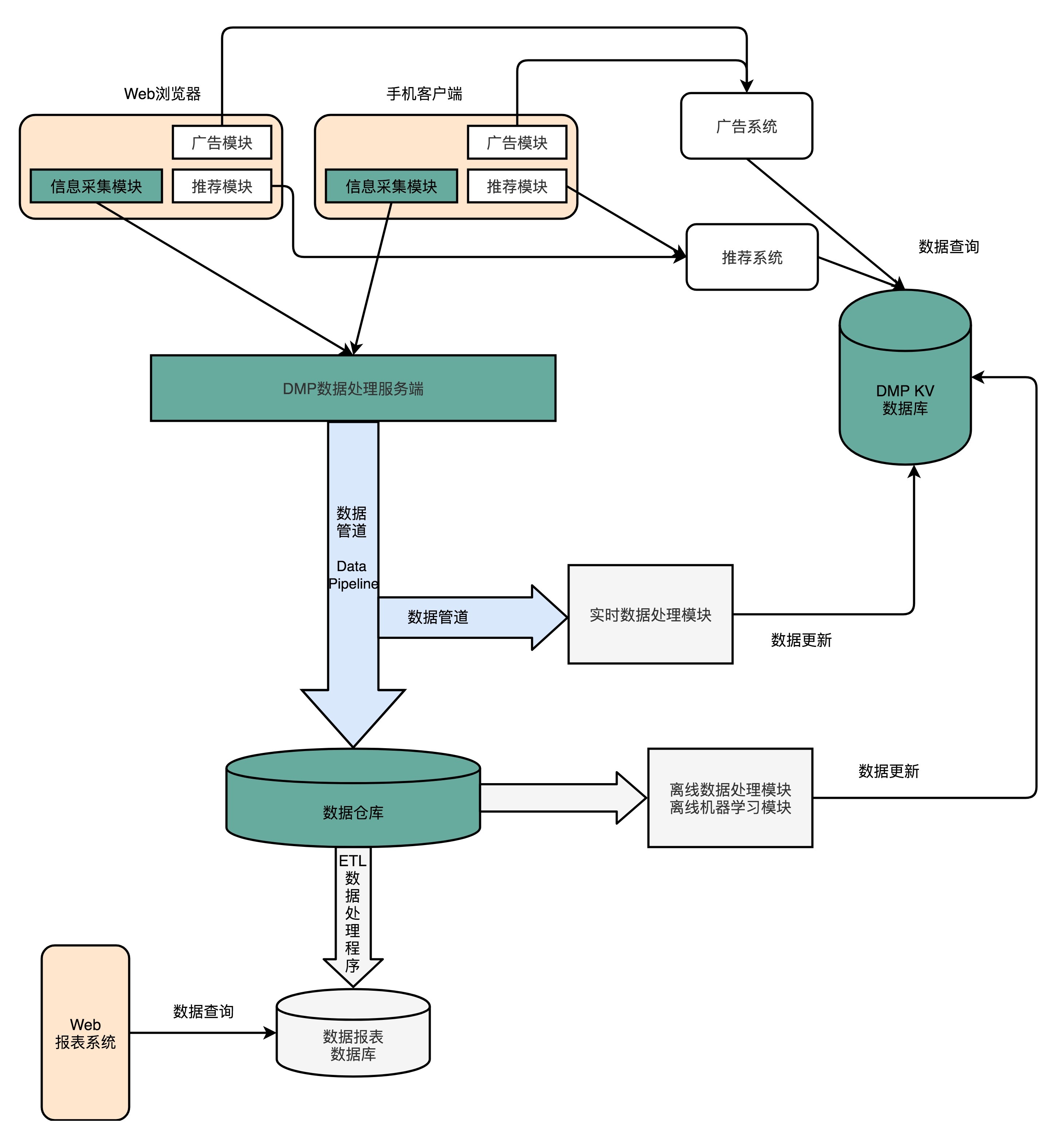
在这个系统中,我们关心的是蓝色的数据管道、绿色的数据仓库和KV数据库
为了能够生成这个KV数据库,我们需要有一个在客户端或者Web端的数据采集模块,不断采集用户的行为,向后端的服务器发送数据。服务器端接收到数据,就要把这份数据放到一个数据管道(Data Pipeline)里面。数据管道的下游,需要实际将数据落地到数据仓库(Data Warehouse),把所有的这些数据结构化地存储起来。后续,我们就可以通过程序去分析这部分日志,生成报表或者或者利用数据运行各种机器学习算法。
除了这个数据仓库之外,我们还会有一个实时数据处理模块(Realtime Data Processing),也放在数据管道的下游。它同样会读取数据管道里面的数据,去进行各种实时计算,然后把需要的结果写入到DMP的KV数据库里面去。
MongoDB真的万能吗?
面对这里的KV数据库、数据管道以及数据仓库,这三个不同的数据存储的需求,最合理的技术方案是什么呢?你可以先自己思考一下,我这里先卖个关子。
我共事过的不少不错的Web程序员,面对这个问题的时候,常常会说:“这有什么难的,用MongoDB就好了呀!”如果你也选择了MongoDB,那最终的结果一定是一场灾难。我为什么这么说呢?
MongoDB的设计听起来特别厉害,不需要预先数据Schema,访问速度很快,还能够无限水平扩展。作为KV数据库,我们可以把MongoDB当作DMP里面的KV数据库;除此之外,MongoDB还能水平扩展、跑MQL,我们可以把它当作数据仓库来用。至于数据管道,只要我们能够不断往MongoDB里面,插入新的数据就好了。从运维的角度来说,我们只需要维护一种数据库,技术栈也变得简单了。看起来,MongoDB这个选择真是相当完美!
但是,作为一个老程序员,第一次听到MongoDB这样“万能”的解决方案,我的第一反应是,“天底下哪有这样的好事”。所有的软件系统,都有它的适用场景,想通过一种解决方案适用三个差异非常大的应用场景,显然既不合理,又不现实。接下来,我们就来仔细看一下,这个“不合理”“不现实”在什么地方。
上面我们已经讲过DMP的KV数据库期望的应用场景和性能要求了,这里我们就来看一下数据管道和数据仓库的性能取舍。
对于数据管道来说,我们需要的是高吞吐量,它的并发量虽然和KV数据库差不多,但是在响应时间上,要求就没有那么严格了,1-2秒甚至再多几秒的延时都是可以接受的。而且,和KV数据库不太一样,数据管道的数据读写都是顺序读写,没有大量的随机读写的需求。
数据仓库就更不一样了,数据仓库的数据读取的量要比管道大得多。管道的数据读取就是我们当时写入的数据,一天有10TB日志数据,管道只会写入10TB。下游的数据仓库存放数据和实时数据模块读取的数据,再加上个2倍的10TB,也就是20TB也就够了。
但是,数据仓库的数据分析任务要读取的数据量就大多了。一方面,我们可能要分析一周、一个月乃至一个季度的数据。这一次分析要读取的数据可不是10TB,而是100TB乃至1PB。我们一天在数据仓库上跑的分析任务也不是1个,而是成千上万个,所以数据的读取量是巨大的。另一方面,我们存储在数据仓库里面的数据,也不像数据管道一样,存放几个小时、最多一天的数据,而是往往要存上3个月甚至是1年的数据。所以,我们需要的是1PB乃至5PB这样的存储空间。
我把KV数据库、数据管道和数据仓库的应用场景,总结成了一个表格,放在这里。你可以对照着看一下,想想为什么MongoDB在这三个应用场景都不合适。
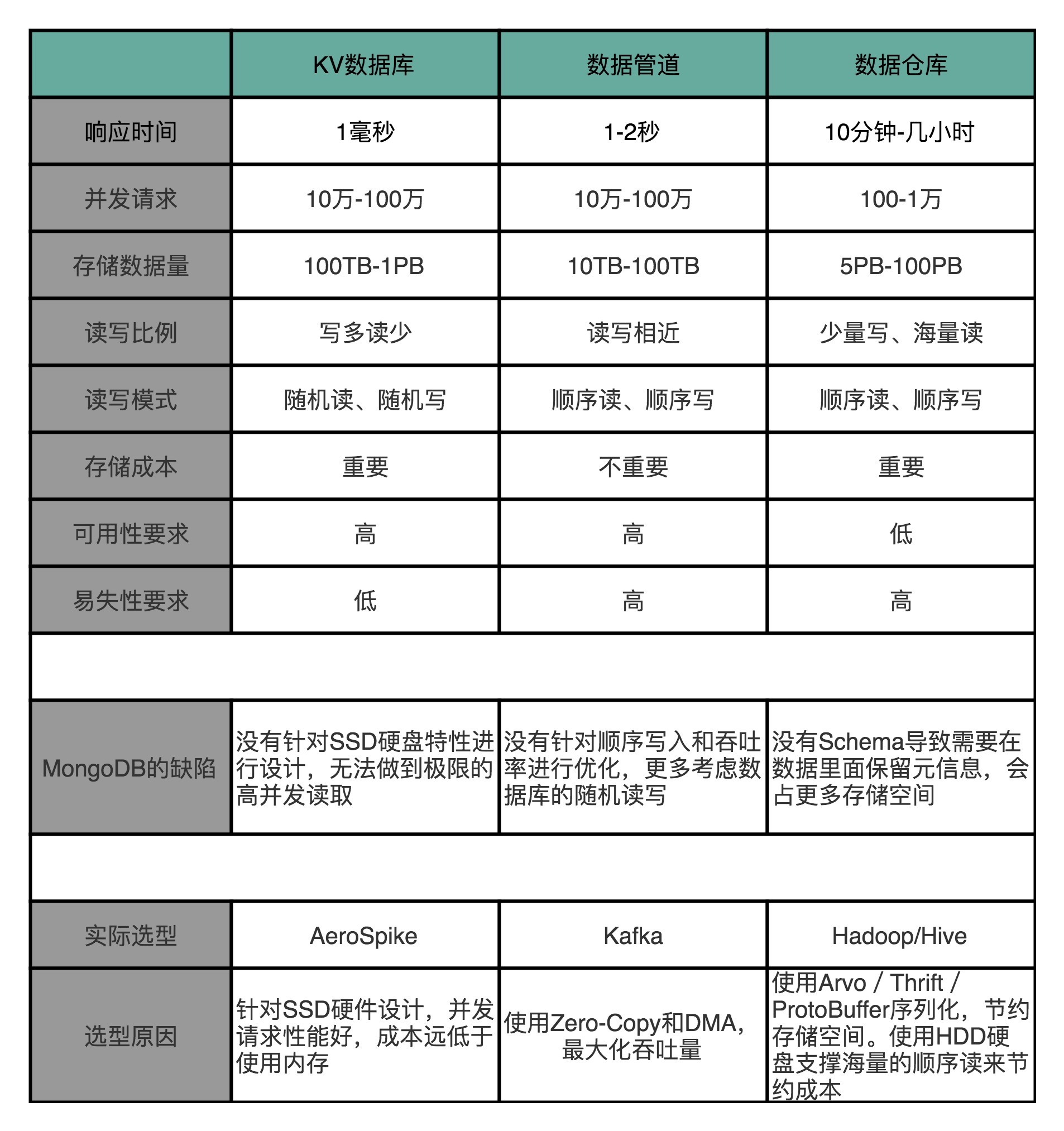
在KV数据库的场景下,需要支持高并发。那么MongoDB需要把更多的数据放在内存里面,但是这样我们的存储成本就会特别高了。
在数据管道的场景下,我们需要的是大量的顺序读写,而MongoDB则是一个文档数据库系统,并没有为顺序写入和吞吐量做过优化,看起来也不太适用。
而在数据仓库的场景下,主要的数据读取时顺序读取,并且需要海量的存储。MongoDB这样的文档式数据库也没有为海量的顺序读做过优化,仍然不是一个最佳的解决方案。而且文档数据库里总是会有很多冗余的字段的元数据,还会浪费更多的存储空间。
那我们该选择什么样的解决方案呢?
拿着我们的应用场景去找方案,其实并不难找。对于KV数据库,最佳的选择方案自然是使用SSD硬盘,选择AeroSpike这样的KV数据库。高并发的随机访问并不适合HDD的机械硬盘,而400TB的数据,如果用内存的话,成本又会显得太高。
对于数据管道,最佳选择自然是Kafka。因为我们追求的是吞吐率,采用了Zero-Copy和DMA机制的Kafka最大化了作为数据管道的吞吐率。而且,数据管道的读写都是顺序读写,所以我们也不需要对随机读写提供支持,用上HDD硬盘就好了。
到了数据仓库,存放的数据量更大了。在硬件层面使用HDD硬盘成了一个必选项。否则,我们的存储成本就会差上10倍。这么大量的数据,在存储上我们需要定义清楚Schema,使得每个字段都不需要额外存储元数据,能够通过Avro/Thrift/ProtoBuffer这样的二进制序列化的方存储下来,或者干脆直接使用Hive这样明确了字段定义的数据仓库产品。很明显,MongoDB那样不限制Schema的数据结构,在这个情况下并不好用。
2012年前后做广告系统的时候,我们也曾经尝试使用MongoDB,尽管只是用作DMP中的数据报表部分。事实证明,即使是已经做了数据层面的汇总的报表,MongoDB都无法很好地支撑我们需要的复杂需求。最终,我们也不得不选择在整个DMP技术栈里面彻底废弃MongoDB,而只在Web应用里面用用MongoDB。事实证明,我最初的直觉是正确的,并没有什么万能的解决方案。
总结延伸
好了,相信到这里,你应该对怎么从最基本的原理出发,来选择技术栈有些感觉了。你应该更多地从底层的存储系统的特性和原理去考虑问题。一旦能够从这个角度去考虑问题,那么你对各类新的技术项目和产品的公关稿,自然会有一定的免疫力了,而不会轻易根据商业公司的宣传来做技术选型了。
因为低延时、高并发、写少读多的DMP的KV数据库,最适合用SSD硬盘,并且采用专门的KV数据库是最合适的。我们可以选择之前文章里提过的AeroSpike,也可以用开源的Cassandra来提供服务。
对于数据管道,因为主要是顺序读和顺序写,所以我们不一定要选用SSD硬盘,而可以用HDD硬盘。不过,对于最大化吞吐量的需求,使用zero-copy和DMA是必不可少的,所以现在的数据管道的标准解决方案就是Kafka了。
对于数据仓库,我们通常是一次写入、多次读取。并且,由于存储的数据量很大,我们还要考虑成本问题。于是,一方面,我们会用HDD硬盘而不是SSD硬盘;另一方面,我们往往会预先给数据规定好Schema,使得单条数据的序列化,不需要像存JSON或者MongoDB的BSON那样,存储冗余的字段名称这样的元数据。所以,最常用的解决方案是,用Hadoop这样的集群,采用Hive这样的数据仓库系统,或者采用Avro/Thrift/ProtoBuffer这样的二进制序列化方案。
在大型的DMP系统设计当中,我们需要根据各个应用场景面临的实际情况,选择不同的硬件和软件的组合,来作为整个系统中的不同组件。
推荐阅读
如果通过这一讲的内容,能让你对大型数据系统的设计有了兴趣,那就再好不过了。我推荐你去读一读《数据密集型应用系统设计》这本书,深入了解一下,设计数据系统需要关注的各个核心要点。
课后思考
这一讲里,我们讲到了数据管道通常所使用的开源系统Kafka,并且选择了使用机械硬盘。在Kafka的使用上,我们有没有必要使用SSD硬盘呢?如果用了SSD硬盘,又会带来哪些好处和坏处呢?
请你仔细思考一下,也可以和周围的朋友分享讨论。如果你觉得有所收获,也请你把你的想法写在留言区,分享给其他的同学。
- 胖头小C 👍(66) 💬(1)
SSD硬盘好处是读写更快,但是使用寿命不长,在Kafka经常擦除情况下,机械盘更耐用,经济,而且是顺序读写,机械盘也是很快的,综合还是机械盘更好
2019-09-02 - 鱼向北游 👍(34) 💬(1)
不差钱可以用ssd呀 ssd的顺序写速度更快 但是 kafka这种应该会频繁擦写 ssd的寿命扛不住 对于存档 hdd普遍容量大 存档成本低 组raid价格也便宜 对于和ssd顺序读写的性能差距 可以用扩大partition数量来做些弥补 怎么感觉说到底最后是钱的问题呢
2019-09-02 - 许童童 👍(16) 💬(1)
我觉得没有必要使用SSD,Kafka主要利用PageCache来提高系统写入的性能,而且Kafka对磁盘大多是顺序读写,在磁盘上提高IOPS,并不能显著的提升Kafka的性能。
2019-09-02 - webmin 👍(12) 💬(2)
Kafka使用SSD硬盘: 好处: Kafka是顺序追加写,比较适合SSD硬盘的特性; 坏处: Kafka的落盘数据类似于日志,顺序追加写SSD比机械硬盘没有太多的优势,再者擦写太频繁SSD硬盘有擦写寿命,使用SSD的性价比不如机械硬盘。
2019-09-02 - leslie 👍(7) 💬(3)
以下是个人对此的理解:希望老师可以在下节课把这节课的答案公布。 分成两部分分别阐述个人对此的理解 一.机械硬盘 机械硬盘的好处是寿命:不过机械硬盘的问题在于速度,不同的机械硬盘有不一样的特性,即使用机械硬盘也要选择缓存偏大且读性能较好的蓝盘。由于kafka是充分利用缓存,毕竟kafka只是消息队列-只是中间件,我们不可能把数据放在kafka中,还是会使用的NOSQL数据库,故而其实际需求是对读性能要求较高的存储设备。 二.SSD SSD读写性能比其实是相对固定的:无论是哪个厂商,其实最终发现这是一个定值;有能力其实SSD确实是一个不错的选择。不过我们在讨论SSD的寿命时其实忽略了一个问题,什么操作影响SSD的寿命?SSD存在的硬件条件和场景是什么? 1.SSD的寿命问题:其实这个问题就像早期说液晶屏一样,额定寿命大概是3年左右,其实大多数实际情况都在5年左右;真正影响SSD寿命的不是读,而是写,这个问题其实机械硬盘同样有。 2.SSD存在的硬件条件是什么:服务器、PC;现在一台PC或者服务器基本上5-6年就各种硬件出现问题,SSD如果使用场景和HDD类似其实寿命是几乎一样的;我们不太可能在服务器都出问题的情况下还去使用使用吧。我自己笔记本电脑是单双硬盘:不过由于市场提供的尺寸不一样,大小略有区别,使用场景几乎完全一样,都各自有一个300G的空间跑虚机做测试,目前已经使用了4年多了,性能和4年前没区别,唯一的区别是当时HDD的代价是SSD的一半左右;现实中服务器的使用也就不超过5-6年,此时其实主板、电源、CPU的散热系统已经基本出问题且厂家和市场都没有相应可换的硬件配件了。 综上所述:故而个人觉得Kafka场景其实资金允许的情况下还是SSD,因为它的坏处其实传统硬盘同样有,这是我们不能回避HDD的硬件问题去说SSD的问题。即使使用HDD其实我们还是要选取读性能强于写性能且缓存偏大的硬盘,况且其实SSD的读写速度方面同样是读方面更好。严重写>读的场景下其实HDD的损坏速度同样非常快,只不过硬件代价低一些而已,但是耗时同样高许多。 期待老师的下节课:谢谢老师的教诲。
2019-09-04 - 吴宇晨 👍(3) 💬(1)
成本的问题ssd顺序读速度能更快,但是价格贵了很多,还有大概kafka主要读写是利用pagecache
2019-09-02 - 随心而至 👍(26) 💬(0)
1.重视底层知识,核心知识,万丈高楼平地起。 2.使用场景。没有一招鲜,吃遍天的技术。 3.要有量级的概念。kv数据库,数据管道,数据仓库,就根本不是一个量级的事情,每个量级都应该有自己的最优方案。 刚工作一年多一点,不对之处请老师指出
2019-10-24 - 逍遥法外 👍(11) 💬(1)
看的真过瘾
2019-09-02 - 李伟 👍(2) 💬(0)
读到这里,为我打开了一个世界大门,我知道原来这才是设计和技术选型,而不是以前的bug少,维护快。
2021-06-04 - 活的潇洒 👍(2) 💬(0)
工作中一直在用MongoDB但是并没有想过它不适合那些场景、今天老师从底层原理给我们刨析了个究竟 day52 笔记:https://www.cnblogs.com/luoahong/p/11510567.html
2019-09-15 - 阿卡牛 👍(2) 💬(0)
满满的干货,我先干为敬
2019-09-02 - 陈德伟 👍(1) 💬(0)
图里kv数据库的读写比例是不是写错了,应该读多写少
2022-02-09 - Mr.埃克斯 👍(1) 💬(0)
数据密集型应用系统设计 这本书挺不错,有空二刷一下。
2020-09-21 - 刘冲 👍(1) 💬(0)
数据仓库可以用elasticsearch
2019-11-22 - Geek_88604f 👍(0) 💬(0)
mongodb的使用场景是初创业务,需求不稳定需要灵活应对,schema less,对事务性要求不高,没有文档之间join的情形。适合做业务数据库,不适合做分析性数仓
2024-02-24