48 DMA:为什么Kafka这么快?
过去几年里,整个计算机产业界,都在尝试不停地提升I/O设备的速度。把HDD硬盘换成SSD硬盘,我们仍然觉得不够快;用PCI Express接口的SSD硬盘替代SATA接口的SSD硬盘,我们还是觉得不够快,所以,现在就有了傲腾(Optane)这样的技术。
但是,无论I/O速度如何提升,比起CPU,总还是太慢。SSD硬盘的IOPS可以到2万、4万,但是我们CPU的主频有2GHz以上,也就意味着每秒会有20亿次的操作。
如果我们对于I/O的操作,都是由CPU发出对应的指令,然后等待I/O设备完成操作之后返回,那CPU有大量的时间其实都是在等待I/O设备完成操作。
但是,这个CPU的等待,在很多时候,其实并没有太多的实际意义。我们对于I/O设备的大量操作,其实都只是把内存里面的数据,传输到I/O设备而已。在这种情况下,其实CPU只是在傻等而已。特别是当传输的数据量比较大的时候,比如进行大文件复制,如果所有数据都要经过CPU,实在是有点儿太浪费时间了。
因此,计算机工程师们,就发明了DMA技术,也就是直接内存访问(Direct Memory Access)技术,来减少CPU等待的时间。
理解DMA,一个协处理器
其实DMA技术很容易理解,本质上,DMA技术就是我们在主板上放一块独立的芯片。在进行内存和I/O设备的数据传输的时候,我们不再通过CPU来控制数据传输,而直接通过DMA控制器(DMA Controller,简称DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
DMAC最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用CPU来搬运的话,肯定忙不过来,所以可以选择DMAC。而当数据传输很慢的时候,DMAC可以等数据到齐了,再发送信号,给到CPU去处理,而不是让CPU在那里忙等待。
好了,现在你应该明白DMAC的价值,知道了它适合用在什么情况下。那我们现在回过头来看。我们上面说,DMAC是一块“协处理器芯片”,这是为什么呢?
注意,这里面的“协”字。DMAC是在“协助”CPU,完成对应的数据传输工作。在DMAC控制数据传输的过程中,我们还是需要CPU的。
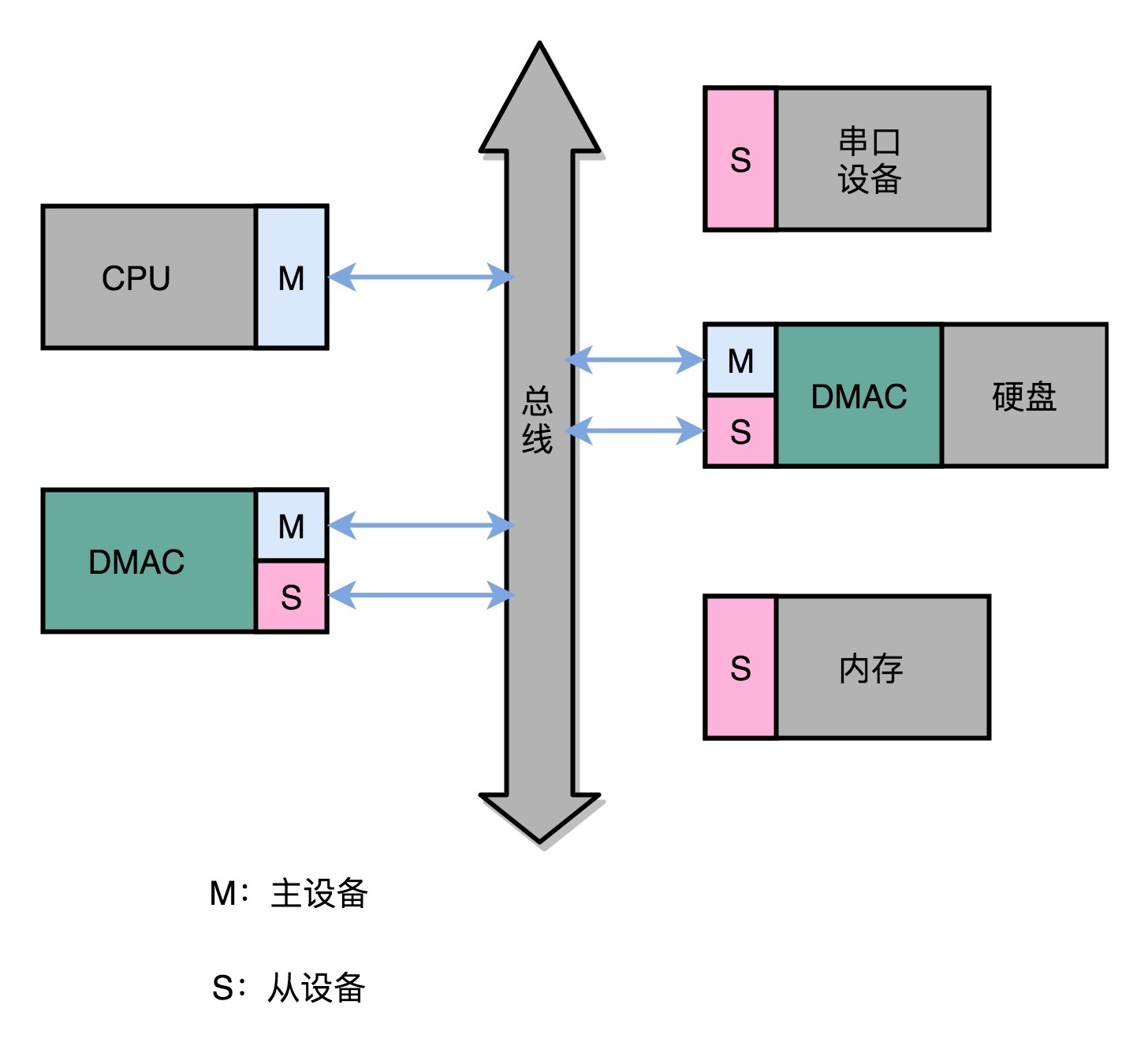
除此之外,DMAC其实也是一个特殊的I/O设备,它和CPU以及其他I/O设备一样,通过连接到总线来进行实际的数据传输。总线上的设备呢,其实有两种类型。一种我们称之为主设备(Master),另外一种,我们称之为从设备(Slave)。
想要主动发起数据传输,必须要是一个主设备才可以,CPU就是主设备。而我们从设备(比如硬盘)只能接受数据传输。所以,如果通过CPU来传输数据,要么是CPU从I/O设备读数据,要么是CPU向I/O设备写数据。
这个时候你可能要问了,那我们的I/O设备不能向主设备发起请求么?可以是可以,不过这个发送的不是数据内容,而是控制信号。I/O设备可以告诉CPU,我这里有数据要传输给你,但是实际数据是CPU拉走的,而不是I/O设备推给CPU的。
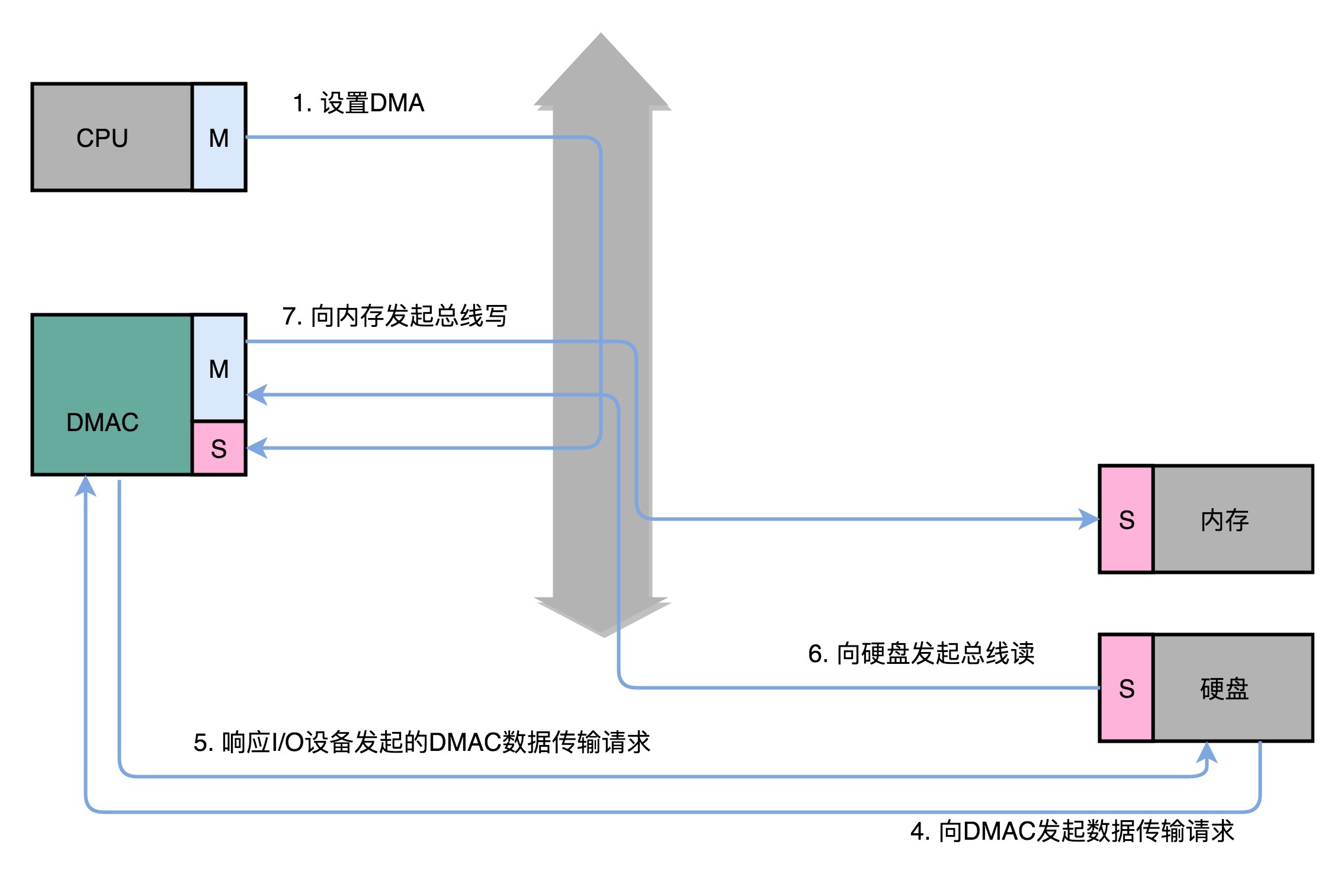
不过,DMAC就很有意思了,它既是一个主设备,又是一个从设备。对于CPU来说,它是一个从设备;对于硬盘这样的IO设备来说呢,它又变成了一个主设备。那使用DMAC进行数据传输的过程究竟是什么样的呢?下面我们来具体看看。
1.首先,CPU还是作为一个主设备,向DMAC设备发起请求。这个请求,其实就是在DMAC里面修改配置寄存器。
2.CPU修改DMAC的配置的时候,会告诉DMAC这样几个信息:
- 首先是源地址的初始值以及传输时候的地址增减方式。 所谓源地址,就是数据要从哪里传输过来。如果我们要从内存里面写入数据到硬盘上,那么就是要读取的数据在内存里面的地址。如果是从硬盘读取数据到内存里,那就是硬盘的I/O接口的地址。 我们讲过总线的时候说过,I/O的地址可以是一个内存地址,也可以是一个端口地址。而地址的增减方式就是说,数据是从大的地址向小的地址传输,还是从小的地址往大的地址传输。
- 其次是目标地址初始值和传输时候的地址增减方式。目标地址自然就是和源地址对应的设备,也就是我们数据传输的目的地。
- 第三个自然是要传输的数据长度,也就是我们一共要传输多少数据。
3.设置完这些信息之后,DMAC就会变成一个空闲的状态(Idle)。
4.如果我们要从硬盘上往内存里面加载数据,这个时候,硬盘就会向DMAC发起一个数据传输请求。这个请求并不是通过总线,而是通过一个额外的连线。
5.然后,我们的DMAC需要再通过一个额外的连线响应这个申请。
6.于是,DMAC这个芯片,就向硬盘的接口发起要总线读的传输请求。数据就从硬盘里面,读到了DMAC的控制器里面。
7.然后,DMAC再向我们的内存发起总线写的数据传输请求,把数据写入到内存里面。
8.DMAC会反复进行上面第6、7步的操作,直到DMAC的寄存器里面设置的数据长度传输完成。
9.数据传输完成之后,DMAC重新回到第3步的空闲状态。
所以,整个数据传输的过程中,我们不是通过CPU来搬运数据,而是由DMAC这个芯片来搬运数据。但是CPU在这个过程中也是必不可少的。因为传输什么数据,从哪里传输到哪里,其实还是由CPU来设置的。这也是为什么,DMAC被叫作“协处理器”。
现在的外设里面,很多都内置了DMAC
最早,计算机里是没有DMAC的,所有数据都是由CPU来搬运的。随着人们对于数据传输的需求越来越多,先是出现了主板上独立的DMAC控制器。到了今天,各种I/O设备越来越多,数据传输的需求越来越复杂,使用的场景各不相同。加之显示器、网卡、硬盘对于数据传输的需求都不一样,所以各个设备里面都有自己的DMAC芯片了。
为什么那么快?一起来看Kafka的实现原理
了解了DMAC是怎么回事儿,那你可能要问了,这和我们实际进行程序开发有什么关系呢?有什么API,我们直接调用一下,就能加速数据传输,减少CPU占用吗?
你还别说,过去几年的大数据浪潮里面,还真有一个开源项目很好地利用了DMA的数据传输方式,通过DMA的方式实现了非常大的性能提升。这个项目就是Kafka。下面我们就一起来看看它究竟是怎么利用DMA的。
Kafka是一个用来处理实时数据的管道,我们常常用它来做一个消息队列,或者用来收集和落地海量的日志。作为一个处理实时数据和日志的管道,瓶颈自然也在I/O层面。
Kafka里面会有两种常见的海量数据传输的情况。一种是从网络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失。另一种情况呢,则是从本地磁盘上读取出来,通过网络发送出去。
我们来看一看后一种情况,从磁盘读数据发送到网络上去。如果我们自己写一个简单的程序,最直观的办法,自然是用一个文件读操作,从磁盘上把数据读到内存里面来,然后再用一个Socket,把这些数据发送到网络上去。
代码来源这段伪代码,来自IBM Developer Works上关于Zero Copy的文章
在这个过程中,数据一共发生了四次传输的过程。其中两次是DMA的传输,另外两次,则是通过CPU控制的传输。下面我们来具体看看这个过程。
第一次传输,是从硬盘上,读到操作系统内核的缓冲区里。这个传输是通过DMA搬运的。
第二次传输,需要从内核缓冲区里面的数据,复制到我们应用分配的内存里面。这个传输是通过CPU搬运的。
第三次传输,要从我们应用的内存里面,再写到操作系统的Socket的缓冲区里面去。这个传输,还是由CPU搬运的。
最后一次传输,需要再从Socket的缓冲区里面,写到网卡的缓冲区里面去。这个传输又是通过DMA搬运的。
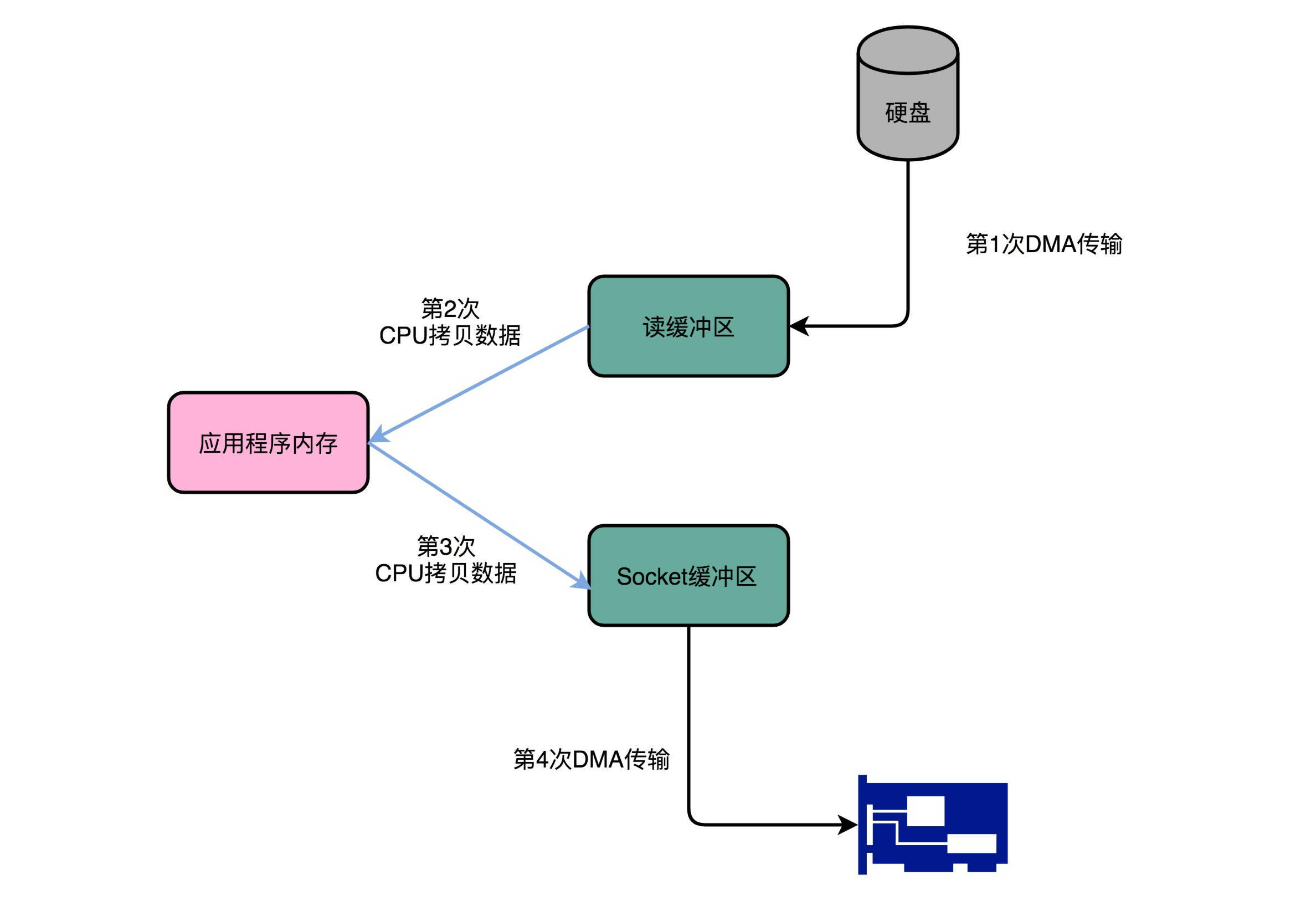
这个时候,你可以回过头看看这个过程。我们只是要“搬运”一份数据,结果却整整搬运了四次。而且这里面,从内核的读缓冲区传输到应用的内存里,再从应用的内存里传输到Socket的缓冲区里,其实都是把同一份数据在内存里面搬运来搬运去,特别没有效率。
像Kafka这样的应用场景,其实大部分最终利用到的硬件资源,其实又都是在干这个搬运数据的事儿。所以,我们就需要尽可能地减少数据搬运的需求。
事实上,Kafka做的事情就是,把这个数据搬运的次数,从上面的四次,变成了两次,并且只有DMA来进行数据搬运,而不需要CPU。
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
如果你层层追踪Kafka的代码,你会发现,最终它调用了Java NIO库里的transferTo方法
Kafka的代码调用了Java NIO库,具体是FileChannel里面的transferTo方法。我们的数据并没有读到中间的应用内存里面,而是直接通过Channel,写入到对应的网络设备里。并且,对于Socket的操作,也不是写入到Socket的Buffer里面,而是直接根据描述符(Descriptor)写入到网卡的缓冲区里面。于是,在这个过程之中,我们只进行了两次数据传输。
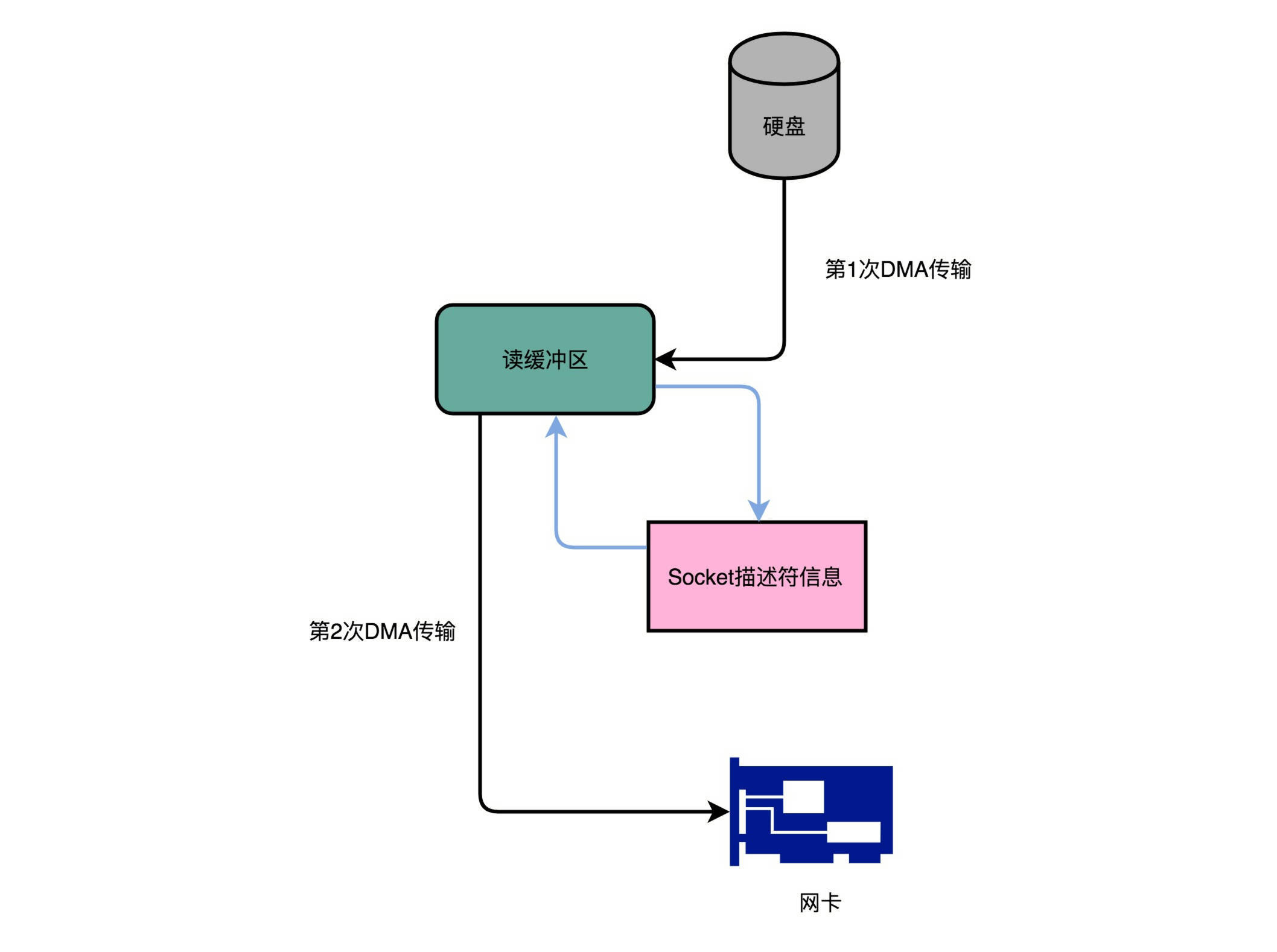
第一次,是通过DMA,从硬盘直接读到操作系统内核的读缓冲区里面。第二次,则是根据Socket的描述符信息,直接从读缓冲区里面,写入到网卡的缓冲区里面。
这样,我们同一份数据传输的次数从四次变成了两次,并且没有通过CPU来进行数据搬运,所有的数据都是通过DMA来进行传输的。
在这个方法里面,我们没有在内存层面去“复制(Copy)”数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。
IBM Developer Works里面有一篇文章,专门写过程序来测试过,在同样的硬件下,使用零拷贝能够带来的性能提升。我在这里放上这篇文章链接。在这篇文章最后,你可以看到,无论传输数据量的大小,传输同样的数据,使用了零拷贝能够缩短65%的时间,大幅度提升了机器传输数据的吞吐量。想要深入了解零拷贝,建议你可以仔细读一读这篇文章。
总结延伸
讲到这里,相信你对DMA的原理、作用和效果都有所理解了。那么,我们一起来回顾总结一下。
如果我们始终让CPU来进行各种数据传输工作,会特别浪费。一方面,我们的数据传输工作用不到多少CPU核心的“计算”功能。另一方面,CPU的运转速度也比I/O操作要快很多。所以,我们希望能够给CPU“减负”。
于是,工程师们就在主板上放上了DMAC这样一个协处理器芯片。通过这个芯片,CPU只需要告诉DMAC,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。后续的实际数据传输工作,都会由DMAC来完成。随着现代计算机各种外设硬件越来越多,光一个通用的DMAC芯片不够了,我们在各个外设上都加上了DMAC芯片,使得CPU很少再需要关心数据传输的工作了。
在我们实际的系统开发过程中,利用好DMA的数据传输机制,也可以大幅提升I/O的吞吐率。最典型的例子就是Kafka。
传统地从硬盘读取数据,然后再通过网卡向外发送,我们需要进行四次数据传输,其中有两次是发生在内存里的缓冲区和对应的硬件设备之间,我们没法节省掉。但是还有两次,完全是通过CPU在内存里面进行数据复制。
在Kafka里,通过Java的NIO里面FileChannel的transferTo方法调用,我们可以不用把数据复制到我们应用程序的内存里面。通过DMA的方式,我们可以把数据从内存缓冲区直接写到网卡的缓冲区里面。在使用了这样的零拷贝的方法之后呢,我们传输同样数据的时间,可以缩减为原来的1/3,相当于提升了3倍的吞吐率。
这也是为什么,Kafka是目前实时数据传输管道的标准解决方案。
推荐阅读
学完了这一讲之后,我推荐你阅读一下Kafka的论文,Kakfa:a Distrubted Messaging System for Log Processing。Kafka的论文其实非常简单易懂,是一个很好的让你了解系统、日志、分布式系统的入门材料。
如果你想要进一步去了解Kafka,也可以订阅极客时间的专栏“Kafka核心技术与实战”。
课后思考
你可以自己尝试写一段使用零拷贝和不使用零拷贝传输数据的代码,然后看一看两者之间的性能差异。你可以看看,零拷贝能够带来多少吞吐量提升。
欢迎你把你运行程序的结果写在留言区,和大家一起讨论、分享。你也可以把这个问题分享给你的朋友,一起试一试,看看DMA和零拷贝,是否真的可以大幅度提升性能。
- 免费的人 👍(36) 💬(1)
从kafka论文里摘的: In addition we optimize the network access for consumers. Kafka is a multi-subscriber system and a single message may be consumed multiple times by different consumer applications. A typical approach to sending bytes from a local file to a remote socket involves the following steps: (1) read data from the storage media to the page cache in an OS, (2) copy data in the page cache to an application buffer, (3) copy application buffer to another kernel buffer, (4) send the kernel buffer to the socket. This includes 4 data copying and 2 system calls. On Linux and other Unix operating systems, there exists a sendfile API [5] that can directly transfer bytes from a file channel to a socket channel. This typically avoids 2 of the copies and 1 system call introduced in steps (2) and (3). Kafka exploits the sendfile API to efficiently deliver bytes in a log segment file from a broker to a consumer.
2019-08-20 - yhh 👍(23) 💬(5)
如果我们的应用程序需要对数据做进一步的加工,那还能使用零拷贝吗
2019-08-20 - soimage 👍(20) 💬(3)
看到最后,也没看出kafka快跟dma有关系,倒是跟zero-copy关系大一些,通过砍掉两次内核空间和用户空间的数据拷贝,以及内核态和用户态的切换成本来优化
2019-09-16 - 前端西瓜哥 👍(5) 💬(1)
我记得 Nginx 的静态服务器貌似也是零拷贝。市面上常见的web服务器的静态服务器应该都实现了零拷贝吧?
2019-10-02 - coder 👍(5) 💬(1)
超算里面核与核之间的数据拷贝,一般会通过基于IB总线的RDMA来完成,可以避免过cpu内核的开销,希望徐老师能讲一下rDMA
2019-08-19 - 纵横四海1949 👍(3) 💬(2)
从C盘复制数据到D盘是怎么个过程呢?
2019-09-04 - 安排 👍(3) 💬(3)
C语言可以直接调Linux系统api实现零拷贝吗?有哪些api?
2019-08-19 - fcb的鱼 👍(2) 💬(3)
cpu处理的是用户内存中的数据,访问不到操作系统中的数据。DMA处理的是操作系统内核中的数据,访问不到用户内存。可以这也理解吧?要不然为啥不让DMAC直接将数据从硬盘读到用户的内存呢?
2020-02-07 - 袭 👍(1) 💬(2)
如果不是由硬盘而是要从程序到网卡,可以省略socket buffer这一步吗?
2019-08-23 - 一步 👍(0) 💬(1)
>第一次,是通过 DMA,从硬盘直接读到操作系统内核的读缓冲区里面。第二次,则是根据 Socket 的描述符信息,直接从读缓冲区里面,写入到网卡的缓冲区里面。 这个实现过程是硬盘向DMAC发出控制信号,由DMAC拉取数据,然后又因为目标地址是网卡,地址固定?所以不用经过寻址的过程吗?
2021-09-29 - 焰火 👍(75) 💬(2)
DMAC:我们不加工数据,只是数据的搬运工
2019-10-02 - Hellboy1989 👍(28) 💬(2)
kafkad那么快,零拷贝是其中一面,他的硬盘顺序读写也是一个重要的原因。
2020-07-17 - linker 👍(18) 💬(0)
其实底层还是调用了linux的系统调用sendfile这个函数
2020-03-08 - Monday 👍(14) 💬(1)
面试被问到为什么kafka这么快,这篇文章至少可以作为原因之一。可惜今天才看到
2020-06-16 - QQ怪 👍(9) 💬(0)
以前只知道kafka通过零拷贝技术提高了吞吐量,但不知道为什么?这下老师通过硬件知识体系理解了相关技术原理,简直太棒了
2019-12-11