54 算法实战(三):剖析高性能队列Disruptor背后的数据结构和算法
Disruptor你是否听说过呢?它是一种内存消息队列。从功能上讲,它其实有点儿类似Kafka。不过,和Kafka不同的是,Disruptor是线程之间用于消息传递的队列。它在Apache Storm、Camel、Log4j 2等很多知名项目中都有广泛应用。
之所以如此受青睐,主要还是因为它的性能表现非常优秀。它比Java中另外一个非常常用的内存消息队列ArrayBlockingQueue(ABS)的性能,要高一个数量级,可以算得上是最快的内存消息队列了。它还因此获得过Oracle官方的Duke大奖。
如此高性能的内存消息队列,在设计和实现上,必然有它独到的地方。今天,我们就来一块儿看下,Disruptor是如何做到如此高性能的?其底层依赖了哪些数据结构和算法?
基于循环队列的“生产者-消费者模型”
什么是内存消息队列?对很多业务工程师或者前端工程师来说,可能会比较陌生。不过,如果我说“生产者-消费者模型”,估计大部分人都知道。在这个模型中,“生产者”生产数据,并且将数据放到一个中心存储容器中。之后,“消费者”从中心存储容器中,取出数据消费。
这个模型非常简单、好理解,那你有没有思考过,这里面存储数据的中心存储容器,是用什么样的数据结构来实现的呢?
实际上,实现中心存储容器最常用的一种数据结构,就是我们在第9节讲的队列。队列支持数据的先进先出。正是这个特性,使得数据被消费的顺序性可以得到保证,也就是说,早被生产的数据就会早被消费。
我们在第9节讲过,队列有两种实现思路。一种是基于链表实现的链式队列,另一种是基于数组实现的顺序队列。不同的需求背景下,我们会选择不同的实现方式。
如果我们要实现一个无界队列,也就是说,队列的大小事先不确定,理论上可以支持无限大。这种情况下,我们适合选用链表来实现队列。因为链表支持快速地动态扩容。如果我们要实现一个有界队列,也就是说,队列的大小事先确定,当队列中数据满了之后,生产者就需要等待。直到消费者消费了数据,队列有空闲位置的时候,生产者才能将数据放入。
实际上,相较于无界队列,有界队列的应用场景更加广泛。毕竟,我们的机器内存是有限的。而无界队列占用的内存数量是不可控的。对于实际的软件开发来说,这种不可控的因素,就会有潜在的风险。在某些极端情况下,无界队列就有可能因为内存持续增长,而导致OOM(Out of Memory)错误。
在第9节中,我们还讲过一种特殊的顺序队列,循环队列。我们讲过,非循环的顺序队列在添加、删除数据的工程中,会涉及数据的搬移操作,导致性能变差。而循环队列正好可以解决这个数据搬移的问题,所以,性能更加好。所以,大部分用到顺序队列的场景中,我们都选择用顺序队列中的循环队列。
实际上,循环队列这种数据结构,就是我们今天要讲的内存消息队列的雏形。我借助循环队列,实现了一个最简单的“生产者-消费者模型”。对应的代码我贴到这里,你可以看看。
为了方便你理解,对于生产者和消费者之间操作的同步,我并没有用到线程相关的操作。而是采用了“当队列满了之后,生产者就轮训等待;当队列空了之后,消费者就轮训等待”这样的措施。
public class Queue {
private Long[] data;
private int size = 0, head = 0, tail = 0;
public Queue(int size) {
this.data = new Long[size];
this.size = size;
}
public boolean add(Long element) {
if ((tail + 1) % size == head) return false;
data[tail] = element;
tail = (tail + 1) % size;
return true;
}
public Long poll() {
if (head == tail) return null;
long ret = data[head];
head = (head + 1) % size;
return ret;
}
}
public class Producer {
private Queue queue;
public Producer(Queue queue) {
this.queue = queue;
}
public void produce(Long data) throws InterruptedException {
while (!queue.add(data)) {
Thread.sleep(100);
}
}
}
public class Consumer {
private Queue queue;
public Consumer(Queue queue) {
this.queue = queue;
}
public void comsume() throws InterruptedException {
while (true) {
Long data = queue.poll();
if (data == null) {
Thread.sleep(100);
} else {
// TODO:...消费数据的业务逻辑...
}
}
}
}
基于加锁的并发“生产者-消费者模型”
实际上,刚刚的“生产者-消费者模型”实现代码,是不完善的。为什么这么说呢?
如果我们只有一个生产者往队列中写数据,一个消费者从队列中读取数据,那上面的代码是没有问题的。但是,如果有多个生产者在并发地往队列中写入数据,或者多个消费者并发地从队列中消费数据,那上面的代码就不能正确工作了。我来给你讲讲为什么。
在多个生产者或者多个消费者并发操作队列的情况下,刚刚的代码主要会有下面两个问题:
- 多个生产者写入的数据可能会互相覆盖;
- 多个消费者可能会读取重复的数据。
因为第一个问题和第二个问题产生的原理是类似的。所以,我着重讲解第一个问题是如何产生的以及该如何解决。对于第二个问题,你可以类比我对第一个问题的解决思路自己来想一想。
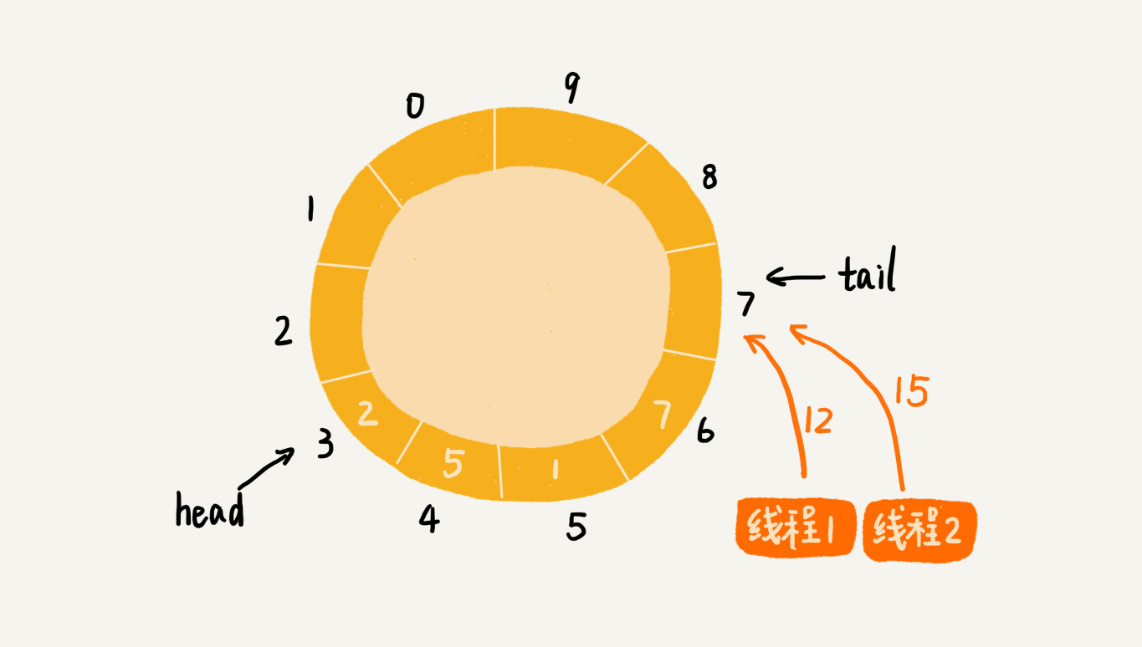
两个线程同时往队列中添加数据,也就相当于两个线程同时执行类Queue中的add()函数。我们假设队列的大小size是10,当前的tail指向下标7,head指向下标3,也就是说,队列中还有空闲空间。这个时候,线程1调用add()函数,往队列中添加一个值为12的数据;线程2调用add()函数,往队列中添加一个值为15的数据。在极端情况下,本来是往队列中添加了两个数据(12和15),最终可能只有一个数据添加成功,另一个数据会被覆盖。这是为什么呢?
为了方便你查看队列Queue中的add()函数,我把它从上面的代码中摘录出来,贴在这里。
public boolean add(Long element) {
if ((tail + 1) % size == head) return false;
data[tail] = element;
tail = (tail + 1) % size;
return true;
}
从这段代码中,我们可以看到,第3行给data[tail]赋值,然后第4行才给tail的值加一。赋值和tail加一两个操作,并非原子操作。这就会导致这样的情况发生:当线程1和线程2同时执行add()函数的时候,线程1先执行完了第3行语句,将data[7](tail等于7)的值设置为12。在线程1还未执行到第4行语句之前,也就是还未将tail加一之前,线程2执行了第3行语句,又将data[7]的值设置为15,也就是说,那线程2插入的数据覆盖了线程1插入的数据。原本应该插入两个数据(12和15)的,现在只插入了一个数据(15)。

 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
那如何解决这种线程并发往队列中添加数据时,导致的数据覆盖、运行不正确问题呢?
最简单的处理方法就是给这段代码加锁,同一时间只允许一个线程执行add()函数。这就相当于将这段代码的执行,由并行改成了串行,也就不存在我们刚刚说的问题了。
不过,天下没有免费的午餐,加锁将并行改成串行,必然导致多个生产者同时生产数据的时候,执行效率的下降。当然,我们可以继续优化代码,用CAS(compare and swap,比较并交换)操作等减少加锁的粒度,但是,这不是我们这节的重点。我们直接看Disruptor的处理方法。
基于无锁的并发“生产者-消费者模型”
尽管Disruptor的源码读起来很复杂,但是基本思想其实非常简单。实际上,它是换了一种队列和“生产者-消费者模型”的实现思路。
之前的实现思路中,队列只支持两个操作,添加数据和读取并移除数据,分别对应代码中的add()函数和poll()函数,而Disruptor采用了另一种实现思路。
对于生产者来说,它往队列中添加数据之前,先申请可用空闲存储单元,并且是批量地申请连续的n个(n≥1)存储单元。当申请到这组连续的存储单元之后,后续往队列中添加元素,就可以不用加锁了,因为这组存储单元是这个线程独享的。不过,从刚刚的描述中,我们可以看出,申请存储单元的过程是需要加锁的。
对于消费者来说,处理的过程跟生产者是类似的。它先去申请一批连续可读的存储单元(这个申请的过程也是需要加锁的),当申请到这批存储单元之后,后续的读取操作就可以不用加锁了。
不过,还有一个需要特别注意的地方,那就是,如果生产者A申请到了一组连续的存储单元,假设是下标为3到6的存储单元,生产者B紧跟着申请到了下标是7到9的存储单元,那在3到6没有完全写入数据之前,7到9的数据是无法读取的。这个也是Disruptor实现思路的一个弊端。
文字描述不好理解,我画了一个图,给你展示一下这个操作过程。
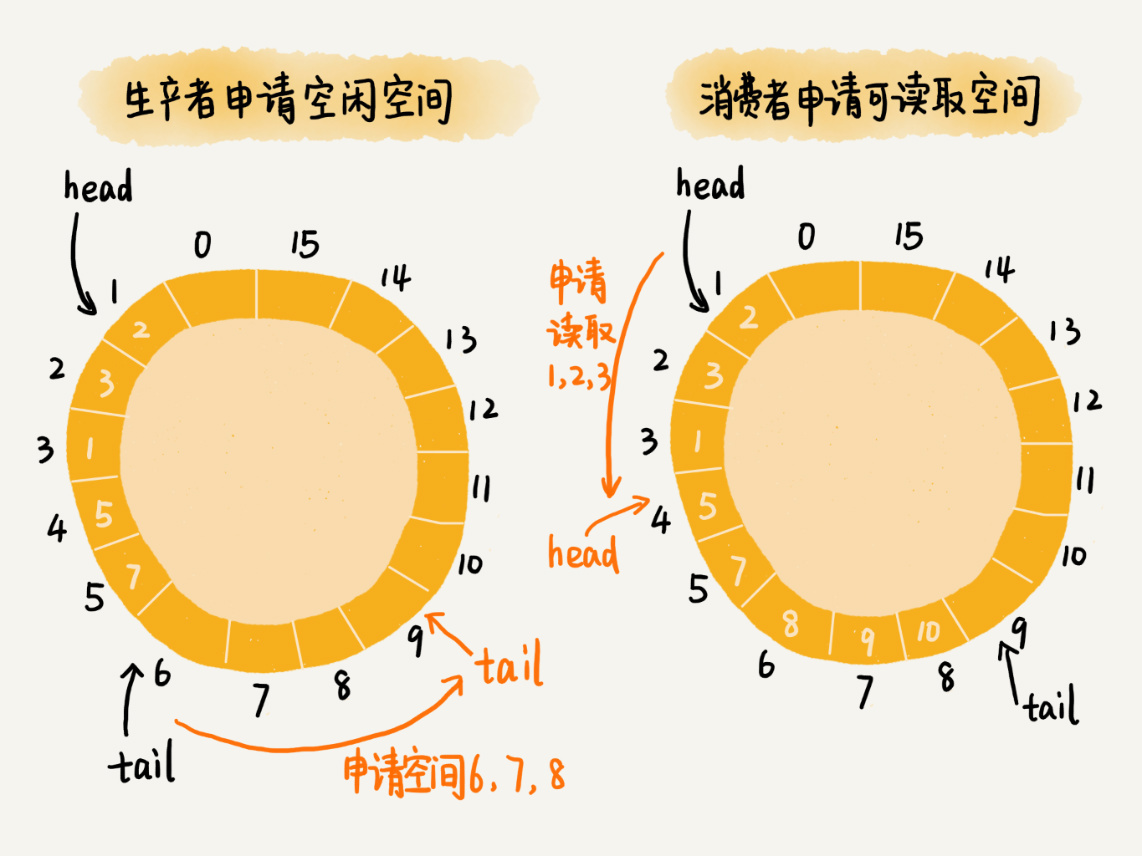
实际上,Disruptor采用的是RingBuffer和AvailableBuffer这两个结构,来实现我刚刚讲的功能。不过,因为我们主要聚焦在数据结构和算法上,所以我对这两种结构做了简化,但是基本思想是一致的。如果你对Disruptor感兴趣,可以去阅读一下它的源码。
总结引申
今天,我讲了如何实现一个高性能的并发队列。这里的“并发”两个字,实际上就是多线程安全的意思。
常见的内存队列往往采用循环队列来实现。这种实现方法,对于只有一个生产者和一个消费者的场景,已经足够了。但是,当存在多个生产者或者多个消费者的时候,单纯的循环队列的实现方式,就无法正确工作了。
这主要是因为,多个生产者在同时往队列中写入数据的时候,在某些情况下,会存在数据覆盖的问题。而多个消费者同时消费数据,在某些情况下,会存在消费重复数据的问题。
针对这个问题,最简单、暴力的解决方法就是,对写入和读取过程加锁。这种处理方法,相当于将原来可以并行执行的操作,强制串行执行,相应地就会导致操作性能的下降。
为了在保证逻辑正确的前提下,尽可能地提高队列在并发情况下的性能,Disruptor采用了“两阶段写入”的方法。在写入数据之前,先加锁申请批量的空闲存储单元,之后往队列中写入数据的操作就不需要加锁了,写入的性能因此就提高了。Disruptor对消费过程的改造,跟对生产过程的改造是类似的。它先加锁申请批量的可读取的存储单元,之后从队列中读取数据的操作也就不需要加锁了,读取的性能因此也就提高了。
你可能会觉得这个优化思路非常简单。实际上,不管架构设计还是产品设计,往往越简单的设计思路,越能更好地解决问题。正所谓“大道至简”,就是这个意思。
课后思考
为了提高存储性能,我们往往通过分库分表的方式设计数据库表。假设我们有8张表用来存储用户信息。这个时候,每张用户表中的ID字段就不能通过自增的方式来产生了。因为这样的话,就会导致不同表之间的用户ID值重复。
为了解决这个问题,我们需要实现一个ID生成器,可以为所有的用户表生成唯一的ID号。那现在问题是,如何设计一个高性能、支持并发的、能够生成全局唯一ID的ID生成器呢?
欢迎留言和我分享,也欢迎点击“请朋友读”,把今天的内容分享给你的好友,和他一起讨论、学习。
- 郭小菜 👍(16) 💬(8)
一直追老师的课程,每期的质量都很高,收获很多。但是这期确实有点虎头蛇尾,没有把disruptor的实现原理讲得特别明白。不是讲得不好,只是觉得结尾有点突兀,信息量少了。但是瑕不掩瑜,老师的课程总体质量绝对是杠杠的!
2019-02-09 - belongcai蔡炳榕 👍(10) 💬(4)
看完还是有很多困惑(可能跟我不了解线程安全有关) 一是申请一段连续存储空间,怎么成为线程独享的呢?生产者ab分别申请后,消费者为啥无法跨区域读取呢 二是这种方法应该是有实验证明效率高的,私下去了解下。
2019-01-30 - 沉睡的木木夕 👍(1) 💬(1)
还是没说加存储单元是干嘛的啊,为什么在往队列添加元素之前申请存储单元就不用加锁了?能说的在详细点么
2019-01-30 - 小予 👍(0) 💬(1)
一个线程一次读取n个元素,那另外一个线程想要读取元素时,必须等前一个线程的n个元素读取完,本质上读取还是单线程的,不明白这样为何能提高性能,希望老师能解释一下其原理。🙏🙏
2019-07-30 - Geek_c33c8e 👍(0) 💬(1)
老师,线程池的实现是单个线程往队列插入任务,单个线程去队列去任务吗,所以不会处理并发控制吗
2019-04-13 - Tattoo 👍(0) 💬(1)
这就是面试中考的消息队列吗?
2019-02-01 - 老杨同志 👍(99) 💬(9)
尝试回答老师的思考题 1)分库分表也可以使用自增主键,可以设置增加的步长。8台机器分别从1、2、3。。开始,步长8. 从1开始的下一个id是9,与其他的不重复就可以了。 2)上面同学说的redis或者zk应该也能生成自增主键,不过他们的写性能可能不能支持真正的高并发。 3)开放独立的id生成服务。最有名的算法应该是snowflake吧。snowflake的好处是基本有序,每秒钟可以生成很大的量,容易水平扩展。 也可以把今天的disrupt用上,用自己生成id算法,提前生成id存入disrupt,预估一下峰值时业务需要的id量,比如提前生成50万;
2019-01-30 - ɴɪᴋᴇʀ 👍(43) 💬(6)
我看到很多读者对文中这段话”3 到 6 没有完全写入数据之前,7 到 9 的数据是无法读取的“这句话都不是理解,我仔细看了下disruptor的设计方案,统一来回答一下: 每个线程都是一个生产者。对于其中一个生产者申请写入n个元素,则返回列队中对应的最大下标位置(比如当前申请写入3个,从下标3开始,返回的最大下标就是6),456就是这个生产者所申请到的独享空间。生产者同时会带有一个标记,记录当前写入成功的下标(比如当前写入到5,标记的值就为5,用来标记自身是否全部写入完成),这是对于单独的一个生产者。对于多个生产者来说,都是如此的,比如有两个生产者,A申请了456,B申请了789,此时A写入到了5,A的标记是5,B写入到了8,B的标记是8,队列中对应6和9的位置是没有数据的。这样是没有问题的,此刻暂停,来看下多消费者同时读数据。消费者A*申请到读取3个元素,消费中B*申请读到了3个元素,那么要申请的连续最大元素个数就是6,对应此刻的下标就是9,这里会触发disruptor的设计机制,从3开始,会依次检测对位置的元素是否生产成功,此刻这里A写到了5,B写到了8,6位置还没有生产成功的,那么机制就会返回可消费的最大下标,也就是5,然后消费者只会读取下标4到5两个元素进行消费。也就是文中小争哥所说的”3 到 6 没有完全写入数据之前,7 到 9 的数据是无法读取的“->其实就是disruptor找到了还没有生产出的元素,后面的数据都是无法读取的,其实很简单。不知道这里的解释看懂了没有,有兴趣的话可以自己去看下disruptor的设计实现,而且图片会比文字更加直观。
2020-10-14 - Smallfly 👍(37) 💬(6)
没有读过 Disruptor 的源码,从老师的文章理解,一个线程申请了一组存储空间,如果这组空间还没有被完全填满之前,另一个线程又进来,在这组空间之后申请空间并添加数据,之后第一组空间又继续填充数据,那在消费时如何保证队列是按照添加顺序读取的呢? 即使控制读取时前面不能有空闲空间,是为了保证能按内存空间顺序消费,但是如果生产的时候没有保证顺序存储,似乎就不满足队列的条件了。
2019-01-30 - 想当上帝的司机 👍(21) 💬(10)
为什么3到6没有完全写入前,7到9无法读取,不是两个写入操作吗
2019-01-30 - Keep-Moving 👍(15) 💬(2)
思考题:加锁批量生成ID,使用时就不用加锁了
2019-01-30 - 忍者无敌1995 👍(11) 💬(1)
项目中有使用过分布式id生成器,但是不知道具体是怎么实现的,参考今天的Disruptor的思路: 1. id生成器相当于一个全局的生产者,可以提前生成一批id 2. 对于每一张表,可以类似于Disruptor的消费者思路,从id生成器中申请一批id,用作当前表的id使用,当然申请一批id对于id生成器来说是需要加锁操作的
2019-04-11 - 阳仔 👍(10) 💬(3)
后面有补充这门课的内容吗?我看到老师回复说会补充,为何没有在评论区中反馈呢?对后面学习这门课的学生很困惑啊 “生产者申请连续空间后,后续往队列添加元素就不需要加锁了,因为这个存储单元是这个线程独享的” 这个不好理解,添加元素的不是有可能多个线程吗?那不是会产生竞争资源吗? 希望得到解惑
2019-05-31 - 彳 👍(10) 💬(1)
disruptor使用环的数据结构,内存连续,初始化时就申请并设置对象,将原本队列的头尾节点锁的争用转化为cas操作,并利用Java对象填充,解决cache line伪共享问题
2019-02-23 - QQ怪 👍(7) 💬(0)
雪花算法可以根据不同机子生成不同的id
2019-03-08