47 向量空间:如何实现一个简单的音乐推荐系统?
很多人都喜爱听歌,以前我们用MP3听歌,现在直接通过音乐App在线就能听歌。而且,各种音乐App的功能越来越强大,不仅可以自己选歌听,还可以根据你听歌的口味偏好,给你推荐可能会喜爱的音乐,而且有时候,推荐的音乐还非常适合你的口味,甚至会惊艳到你!如此智能的一个功能,你知道它是怎么实现的吗?
算法解析
实际上,要解决这个问题,并不需要特别高深的理论。解决思路的核心思想非常简单、直白,用两句话就能总结出来。
- 找到跟你口味偏好相似的用户,把他们爱听的歌曲推荐给你;
- 找出跟你喜爱的歌曲特征相似的歌曲,把这些歌曲推荐给你。
接下来,我就分别讲解一下这两种思路的具体实现方法。
1.基于相似用户做推荐
如何找到跟你口味偏好相似的用户呢?或者说如何定义口味偏好相似呢?实际上,思路也很简单,我们把跟你听类似歌曲的人,看作口味相似的用户。你可以看我下面画的这个图。我用“1”表示“喜爱”,用“0”笼统地表示“不发表意见”。从图中我们可以看出,你跟小明共同喜爱的歌曲最多,有5首。于是,我们就可以说,小明跟你的口味非常相似。
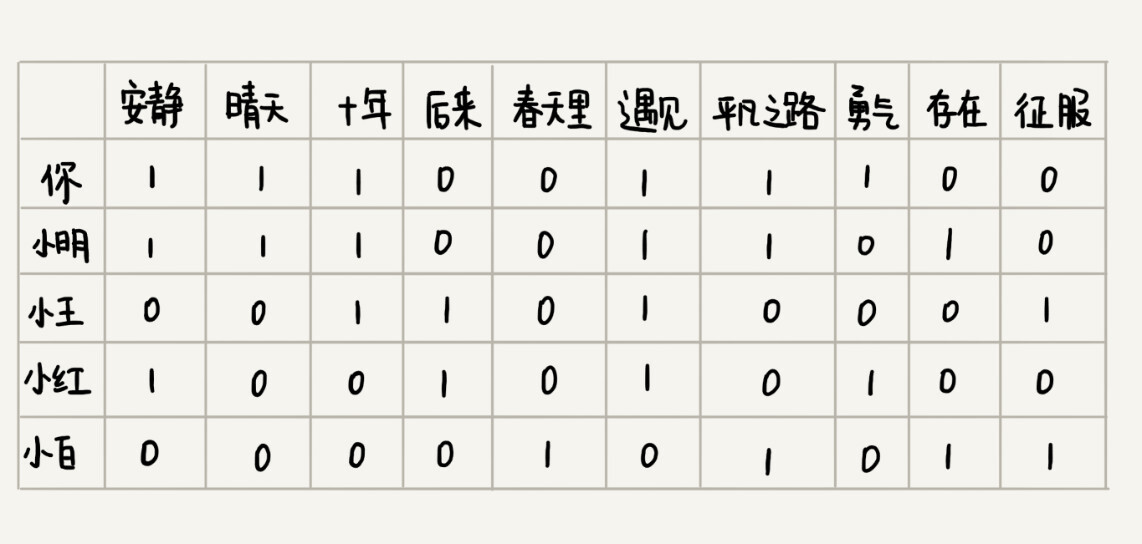
我们只需要遍历所有的用户,对比每个用户跟你共同喜爱的歌曲个数,并且设置一个阈值,如果你和某个用户共同喜爱的歌曲个数超过这个阈值,我们就把这个用户看作跟你口味相似的用户,把这个用户喜爱但你还没听过的歌曲,推荐给你。
不过,刚刚的这个解决方案中有一个问题,我们如何知道用户喜爱哪首歌曲呢?也就是说,如何定义用户对某首歌曲的喜爱程度呢?
实际上,我们可以通过用户的行为,来定义这个喜爱程度。我们给每个行为定义一个得分,得分越高表示喜爱程度越高。

还是刚刚那个例子,我们如果把每个人对每首歌曲的喜爱程度表示出来,就是下面这个样子。图中,某个人对某首歌曲是否喜爱,我们不再用“1”或者“0”来表示,而是对应一个具体的分值。
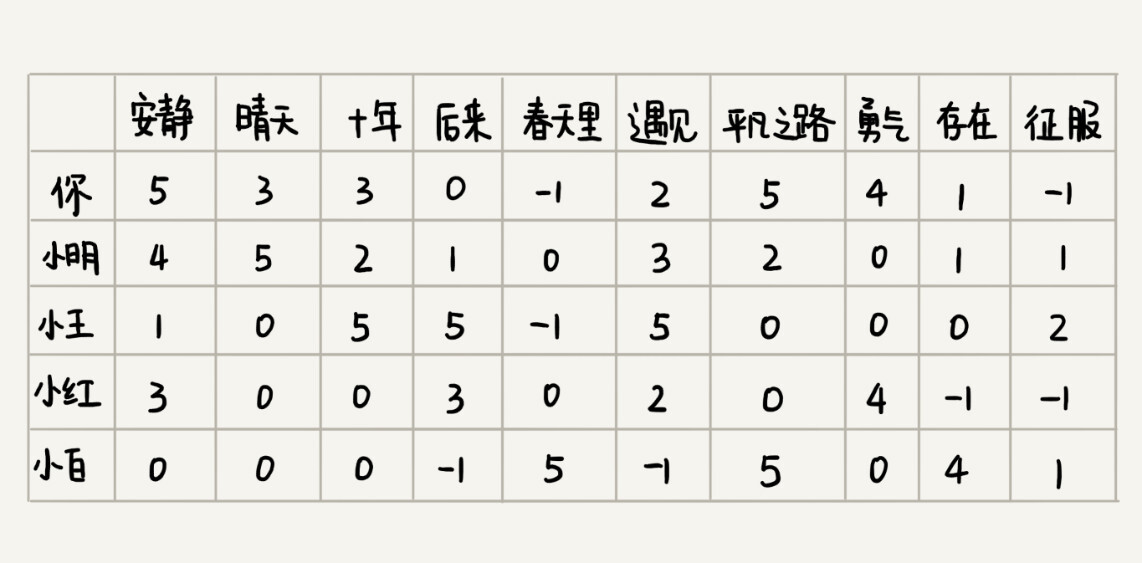
有了这样一个用户对歌曲的喜爱程度的对应表之后,如何来判断两个用户是否口味相似呢?
显然,我们不能再像之前那样,采用简单的计数来统计两个用户之间的相似度。还记得我们之前讲字符串相似度度量时,提到的编辑距离吗?这里的相似度度量,我们可以使用另外一个距离,那就是欧几里得距离(Euclidean distance)。欧几里得距离是用来计算两个向量之间的距离的。这个概念中有两个关键词,向量和距离,我来给你解释一下。
一维空间是一条线,我们用1,2,3……这样单个的数,来表示一维空间中的某个位置;二维空间是一个面,我们用(1,3)(4,2)(2,2)……这样的两个数,来表示二维空间中的某个位置;三维空间是一个立体空间,我们用(1,3,5)(3,1,7)(2,4,3)……这样的三个数,来表示三维空间中的某个位置。一维、二维、三维应该都不难理解,那更高维中的某个位置该如何表示呢?
类比一维、二维、三维的表示方法,K维空间中的某个位置,我们可以写作($X_{1}$,$X_{2}$,$X_{3}$,…,$X_{K}$)。这种表示方法就是向量(vector)。我们知道,二维、三维空间中,两个位置之间有距离的概念,类比到高纬空间,同样也有距离的概念,这就是我们说的两个向量之间的距离。
那如何计算两个向量之间的距离呢?我们还是可以类比到二维、三维空间中距离的计算方法。通过类比,我们就可以得到两个向量之间距离的计算公式。这个计算公式就是欧几里得距离的计算公式:

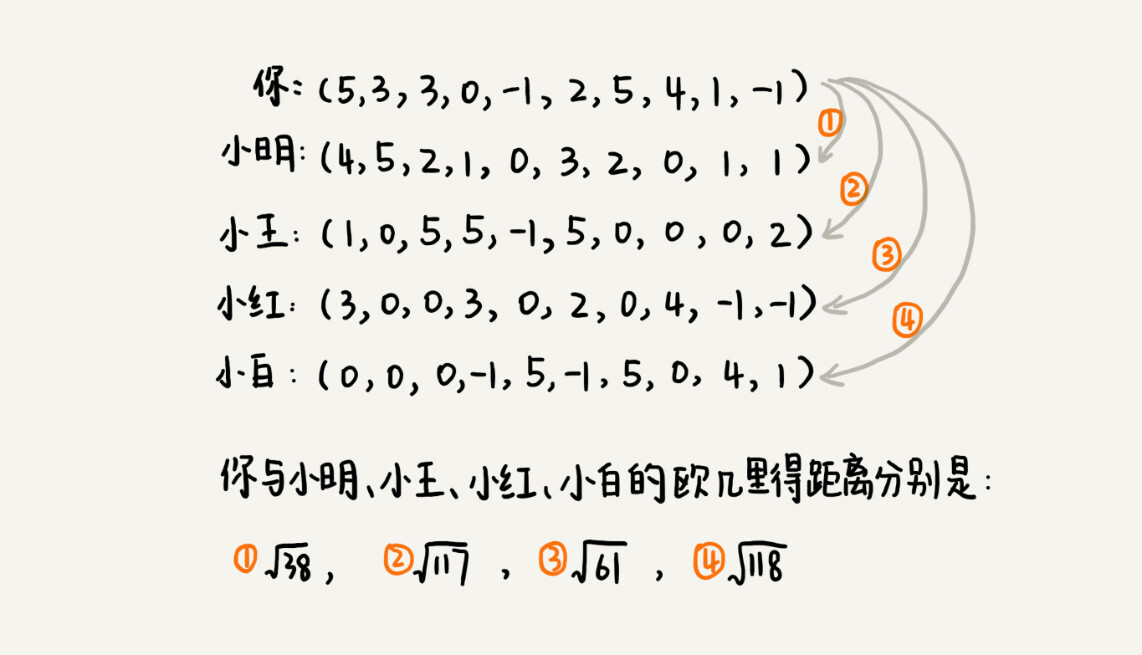
我们把每个用户对所有歌曲的喜爱程度,都用一个向量表示。我们计算出两个向量之间的欧几里得距离,作为两个用户的口味相似程度的度量。从图中的计算可以看出,小明与你的欧几里得距离距离最小,也就是说,你俩在高维空间中靠得最近,所以,我们就断定,小明跟你的口味最相似。
2.基于相似歌曲做推荐
刚刚我们讲了基于相似用户的歌曲推荐方法,但是,如果用户是一个新用户,我们还没有收集到足够多的行为数据,这个时候该如何推荐呢?我们现在再来看另外一种推荐方法,基于相似歌曲的推荐方法,也就是说,如果某首歌曲跟你喜爱的歌曲相似,我们就把它推荐给你。
如何判断两首歌曲是否相似呢?对于人来说,这个事情可能会比较简单,但是对于计算机来说,判断两首歌曲是否相似,那就需要通过量化的数据来表示了。我们应该通过什么数据来量化两个歌曲之间的相似程度呢?
最容易想到的是,我们对歌曲定义一些特征项,比如是伤感的还是愉快的,是摇滚还是民谣,是柔和的还是高亢的等等。类似基于相似用户的推荐方法,我们给每个歌曲的每个特征项打一个分数,这样每个歌曲就都对应一个特征项向量。我们可以基于这个特征项向量,来计算两个歌曲之间的欧几里得距离。欧几里得距离越小,表示两个歌曲的相似程度越大。
但是,要实现这个方案,需要有一个前提,那就是我们能够找到足够多,并且能够全面代表歌曲特点的特征项,除此之外,我们还要人工给每首歌标注每个特征项的得分。对于收录了海量歌曲的音乐App来说,这显然是一个非常大的工程。此外,人工标注有很大的主观性,也会影响到推荐的准确性。
既然基于歌曲特征项计算相似度不可行,那我们就换一种思路。对于两首歌,如果喜欢听的人群都是差不多的,那侧面就可以反映出,这两首歌比较相似。如图所示,每个用户对歌曲有不同的喜爱程度,我们依旧通过上一个解决方案中定义得分的标准,来定义喜爱程度。
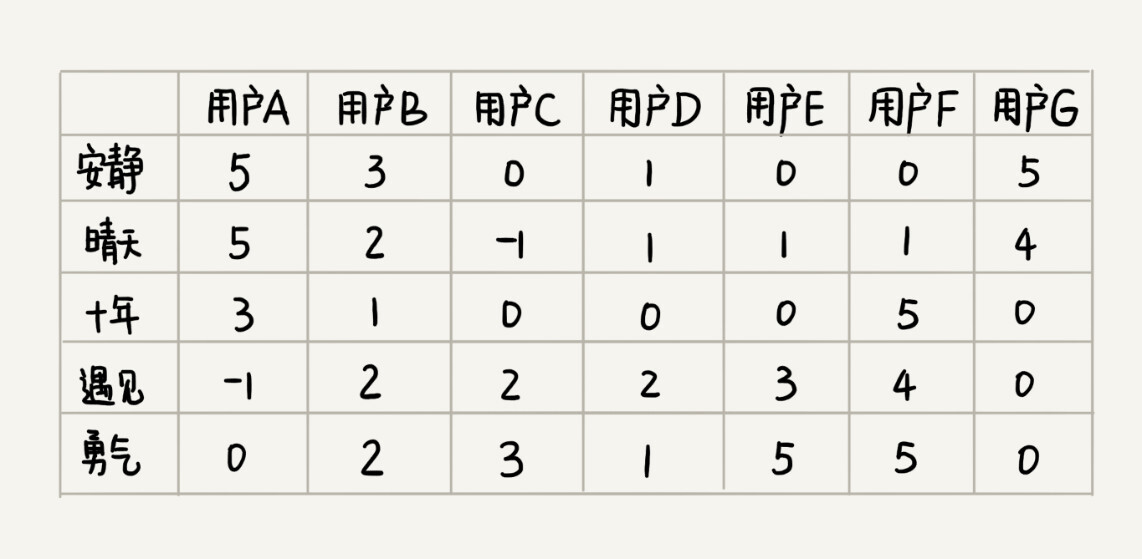
你有没有发现,这个图跟基于相似用户推荐中的图几乎一样。只不过这里把歌曲和用户主次颠倒了一下。基于相似用户的推荐方法中,针对每个用户,我们将对各个歌曲的喜爱程度作为向量。基于相似歌曲的推荐思路中,针对每个歌曲,我们将每个用户的打分作为向量。
有了每个歌曲的向量表示,我们通过计算向量之间的欧几里得距离,来表示歌曲之间的相似度。欧几里得距离越小,表示两个歌曲越相似。然后,我们就在用户已经听过的歌曲中,找出他喜爱程度较高的歌曲。然后,我们找出跟这些歌曲相似度很高的其他歌曲,推荐给他。
总结引申
实际上,这个问题是推荐系统(Recommendation System)里最典型的一类问题。之所以讲这部分内容,主要还是想给你展示,算法的强大之处,利用简单的向量空间的欧几里得距离,就能解决如此复杂的问题。不过,今天,我只给你讲解了基本的理论,实践中遇到的问题还有很多,比如冷启动问题,产品初期积累的数据不多,不足以做推荐等等。这些更加深奥的内容,你可以之后自己在实践中慢慢探索。
课后思考
关于今天讲的推荐算法,你还能想到其他应用场景吗?
欢迎留言和我分享,也欢迎点击“请朋友读”,把今天的内容分享给你的好友,和他一起讨论、学习。
- 刑无刀 👍(136) 💬(4)
讲得好!对推荐系统感兴趣,可以订阅《推荐系统36式》,哈哈哈哈哈哈哈。
2019-02-18 - 李冲 👍(63) 💬(5)
快追到课程结束了,从另外一个角度讲一下自己的想法,如有不适还请海涵。 推荐系统加速了系统价值的开发,但领域的价值是有限的,必须不停的挖掘新领域来做大蛋糕。不管是消费用户的钱包,时间,还是情怀,都是有边际效应的。企业前期努力成长,后期做大了在存量市场里为了效益可能会有失偏驳。 话说回来像王争老师这样走心的真少见,为了让用户变得更优秀来做产品值得赞赏。目前我就主动给同事和朋友推荐过王争和丁奇老师的课程,以后看的多了肯定会发现更多值得推荐的老师和课程。 极客时间确实是一股清流,真正有志于而且能够布道的老师可以把自己的理解问题和思考对策的方式授人以渔。希望以后能够碰到更多优秀的老师做出这样的课程,为行业出力。
2019-09-17 - 許敲敲 👍(31) 💬(15)
具体的基于用户相似来推荐的话,如果每个用户喜欢的歌曲数量很大,或者说用户数也很多的情况下,也就是考虑到老师画的表 行列都很多,是不是相当于矩阵的维数很大,这样找到两个向量的距离是有什么trick嘛?或者该用什么算法计算比较好?
2019-01-14 - skull 👍(6) 💬(10)
老师,看了您的很多算法,我都很喜欢,但是我只是一个java后端研发,感觉学了没有用武之地,但因为已经工作几年了,又不可能再去转做算法工程师,看了喜欢却用不上,这种感觉很扎心啊,有办法让我们这种人把算法使用起来么
2019-09-29 - 王楚然 👍(3) 💬(1)
弱弱的问,向量空间是求相似度的,朴素贝叶斯是分类的,但是分类到一起,是不是可以说相似度高?相似度高的,可不可以归为同一类?这俩方法算是解决同问题的方法吗?如果是有什么对比呢?如果不是为啥不是呢?
2019-06-21 - 美美 👍(0) 💬(1)
同问海量用户,这个向量维度太特么高了,老师有空讲讲么
2019-11-17 - $Jason 👍(0) 💬(1)
我看到这篇文章还是可以看懂的,但是对于海量的用户,我总不能一个个的计算他们的向量空间吧。那怎么做?
2019-06-27 - Geek_a0c415 👍(0) 💬(1)
老师,后面会讲到向量夹角余弦么?
2019-06-11 - 林 👍(0) 💬(1)
王前辈,能不能给讲一下原生的协同过滤算法
2019-01-14 - 李皮皮皮皮皮 👍(0) 💬(1)
这个计算量估计得用很多机器在特定时间计算吧。比如网易云音乐的每日推荐。那个第二类有个问题,一个人可能喜欢好几种类型的音乐,文中讲得也不是很清楚。
2019-01-14 - 想当上帝的司机 👍(0) 💬(1)
商品推荐,以前看spark的时候也是这样介绍,发现很多算法的岗位都要求机器学习相关的经验,是不是想做算法的话必须会,如果是的话一般的大学基础可以吗
2019-01-14 - 莫弹弹 👍(33) 💬(0)
高级篇的人越来越少了…… 我觉得,推荐可以看成一种选优,所以思维上可以跳出“推荐”两个字,进而扩展“相似”“热门”等等这类场景 例如搜索引擎关键词拼写错误的推荐词,导航app的推荐路径,电商的热门商品等,都可以用上推荐算法
2019-01-14 - escray 👍(27) 💬(1)
到这里的确留言的人比较少了,看不到浏览量的数据,其实可能是大家觉得没有什么可讨论的。 看到一半的时候就想到了邢无刀老师专栏,然后就看到了头条留言。文中所讲的估计只能算是音乐推荐系统的管中窥豹。现在的推荐系统估计也都是在计算框架和云平台上去进行推荐,作为程序员能做的事情可能不太多。 向量空间计算的代码实现并不难,但是如果是做简单的推荐系统,那么需要考虑因素就太多了。 其实推荐系统可能还有时间上的维度,简单一点的是根据家里小朋友的年龄推荐不同的玩具(习题册),复杂一点的就是根据用户最近几天的情绪推荐歌曲。 看到留言里面有人说学了算法,在工作中无用武之地。对我来说,一来是为了将来能通过面试时的算法关,二来是当做一种思维训练,最后就程序员的三大浪漫(算法/图形学、编译原理、操作系统) 看到 @Edward 的留言,推荐系统的应用场景确实很多,求职、交友、婚恋、购物、新闻、游戏、影音…… 不过话说回来,一个人不能靠推荐系统(头条、抖音)活着,不能只看自己喜欢的东西。
2020-05-31 - 短迪大魔王 👍(18) 💬(0)
先说如果矩阵过大怎么算,矩阵维度过大会有一个致命问题,就是数据太稀疏了,矩阵里0太多了。所以比较常见的矩阵处理方法是矩阵分解,mn的矩阵分解mk,kn的矩阵,k认为是隐语义,对分数高的进行推荐。另外既然是求距离,需要让各个维度数据归一化,否则,本来值大就比其他特征重要了,求解失败。在老师的这个例子不归一是合理的,因为业务上认为这个权重是合理的,一般是产品给的,技术自己定锅背不起啊。 另外,每次都是离线计算完再做推荐,或者准实时,不一定是实时的,而矩阵运算是并行的,不是循环,所以海量用户也不慢甚至非常快。如果用gpu做矩阵运算那快的飞起来。我们用的淘宝,每个物品的推荐都是离线算好的,大家喜好的集合就是这些。新用户推最火的。 老师说的标注的问题真是工业界大难题,标注成本太高,还不能保证一定有效果,时间长。到deadline没输出内心就崩了,若然用每个人评价做特征是牵强点,思考一下也不是很合理,但是也是一个能产出的方案。这时候最好评价的人多一些,太少了有比较大偏差。 另外,可以构建更合适的信息特征,并且构建更合理的约束的神经网络比如时序等,介入粗召回和精排列让线上效果速度跟得上
2020-02-01 - Kudo 👍(18) 💬(0)
推荐系统(Recommender System)是典型的机器学习应用场景。其核心就是通过算法得到用户偏好向量以及内容向量,两个向量的内积即为用户对内容的的评分预测(即用户对某内容的喜好程度)。推荐学习算法本质上就是学习这两个向量的过程。 通常有两种方法: 1. 已知内容向量,学习用户偏好向量的方法就是基于内容的推荐算法(content-based); 2. 用户偏好向量和内容向量都未知,则适合使用联合过滤算法(collaborative filtering)同时学习两个向量。
2019-01-14