31 深度和广度优先搜索:如何找出社交网络中的三度好友关系?
上一节我们讲了图的表示方法,讲到如何用有向图、无向图来表示一个社交网络。在社交网络中,有一个六度分割理论,具体是说,你与世界上的另一个人间隔的关系不会超过六度,也就是说平均只需要六步就可以联系到任何两个互不相识的人。
一个用户的一度连接用户很好理解,就是他的好友,二度连接用户就是他好友的好友,三度连接用户就是他好友的好友的好友。在社交网络中,我们往往通过用户之间的连接关系,来实现推荐“可能认识的人”这么一个功能。今天的开篇问题就是,给你一个用户,如何找出这个用户的所有三度(其中包含一度、二度和三度)好友关系?
这就要用到今天要讲的深度优先和广度优先搜索算法。
什么是“搜索”算法?
我们知道,算法是作用于具体数据结构之上的,深度优先搜索算法和广度优先搜索算法都是基于“图”这种数据结构的。这是因为,图这种数据结构的表达能力很强,大部分涉及搜索的场景都可以抽象成“图”。
图上的搜索算法,最直接的理解就是,在图中找出从一个顶点出发,到另一个顶点的路径。具体方法有很多,比如今天要讲的两种最简单、最“暴力”的深度优先、广度优先搜索,还有A*、IDA*等启发式搜索算法。
我们上一节讲过,图有两种主要存储方法,邻接表和邻接矩阵。今天我会用邻接表来存储图。
我这里先给出图的代码实现。需要说明一下,深度优先搜索算法和广度优先搜索算法,既可以用在无向图,也可以用在有向图上。在今天的讲解中,我都针对无向图来讲解。
public class Graph { // 无向图
private int v; // 顶点的个数
private LinkedList<Integer> adj[]; // 邻接表
public Graph(int v) {
this.v = v;
adj = new LinkedList[v];
for (int i=0; i<v; ++i) {
adj[i] = new LinkedList<>();
}
}
public void addEdge(int s, int t) { // 无向图一条边存两次
adj[s].add(t);
adj[t].add(s);
}
}
广度优先搜索(BFS)
广度优先搜索(Breadth-First-Search),我们平常都简称BFS。直观地讲,它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。理解起来并不难,所以我画了一张示意图,你可以看下。
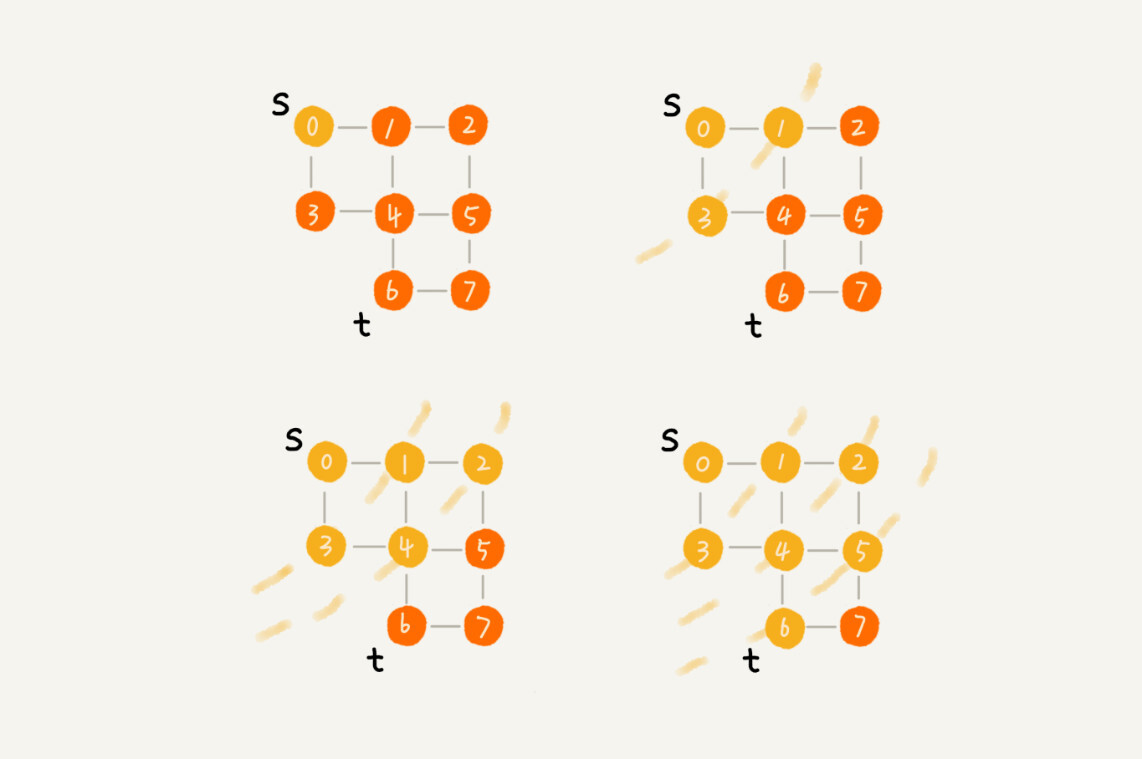
尽管广度优先搜索的原理挺简单,但代码实现还是稍微有点复杂度。所以,我们重点讲一下它的代码实现。
这里面,bfs()函数就是基于之前定义的,图的广度优先搜索的代码实现。其中s表示起始顶点,t表示终止顶点。我们搜索一条从s到t的路径。实际上,这样求得的路径就是从s到t的最短路径。
public void bfs(int s, int t) {
if (s == t) return;
boolean[] visited = new boolean[v];
visited[s]=true;
Queue<Integer> queue = new LinkedList<>();
queue.add(s);
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
while (queue.size() != 0) {
int w = queue.poll();
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
if (q == t) {
print(prev, s, t);
return;
}
visited[q] = true;
queue.add(q);
}
}
}
}
private void print(int[] prev, int s, int t) { // 递归打印s->t的路径
if (prev[t] != -1 && t != s) {
print(prev, s, prev[t]);
}
System.out.print(t + " ");
}
这段代码不是很好理解,里面有三个重要的辅助变量visited、queue、prev。只要理解这三个变量,读懂这段代码估计就没什么问题了。
visited是用来记录已经被访问的顶点,用来避免顶点被重复访问。如果顶点q被访问,那相应的visited[q]会被设置为true。
queue是一个队列,用来存储已经被访问、但相连的顶点还没有被访问的顶点。因为广度优先搜索是逐层访问的,也就是说,我们只有把第k层的顶点都访问完成之后,才能访问第k+1层的顶点。当我们访问到第k层的顶点的时候,我们需要把第k层的顶点记录下来,稍后才能通过第k层的顶点来找第k+1层的顶点。所以,我们用这个队列来实现记录的功能。
prev用来记录搜索路径。当我们从顶点s开始,广度优先搜索到顶点t后,prev数组中存储的就是搜索的路径。不过,这个路径是反向存储的。prev[w]存储的是,顶点w是从哪个前驱顶点遍历过来的。比如,我们通过顶点2的邻接表访问到顶点3,那prev[3]就等于2。为了正向打印出路径,我们需要递归地来打印,你可以看下print()函数的实现方式。
为了方便你理解,我画了一个广度优先搜索的分解图,你可以结合着代码以及我的讲解一块儿看。
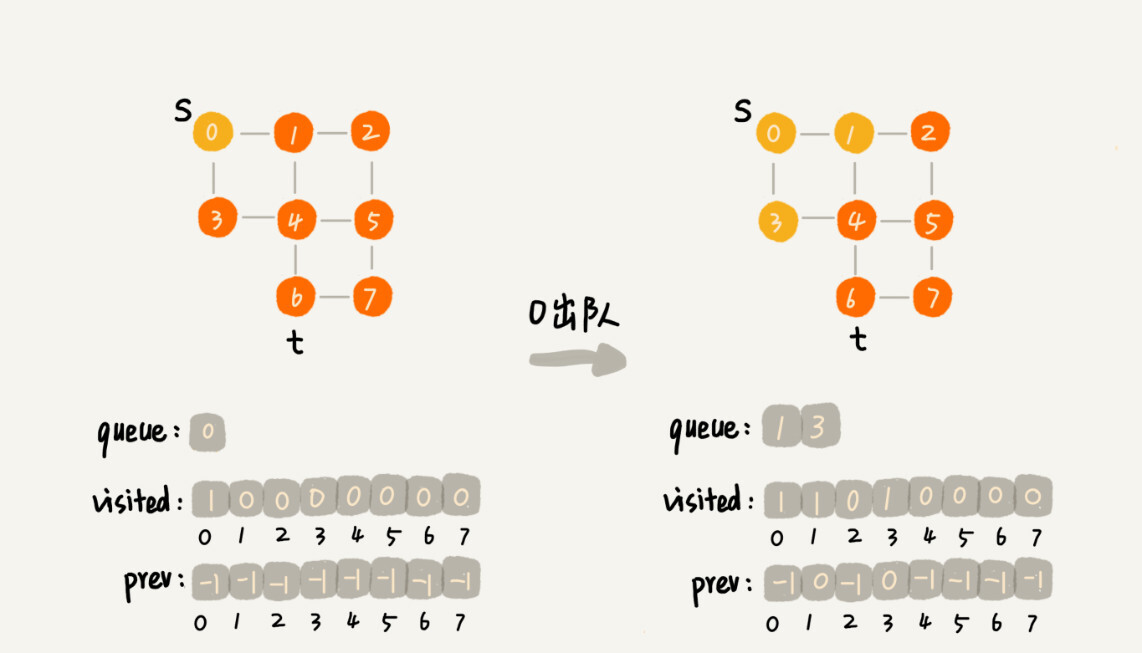
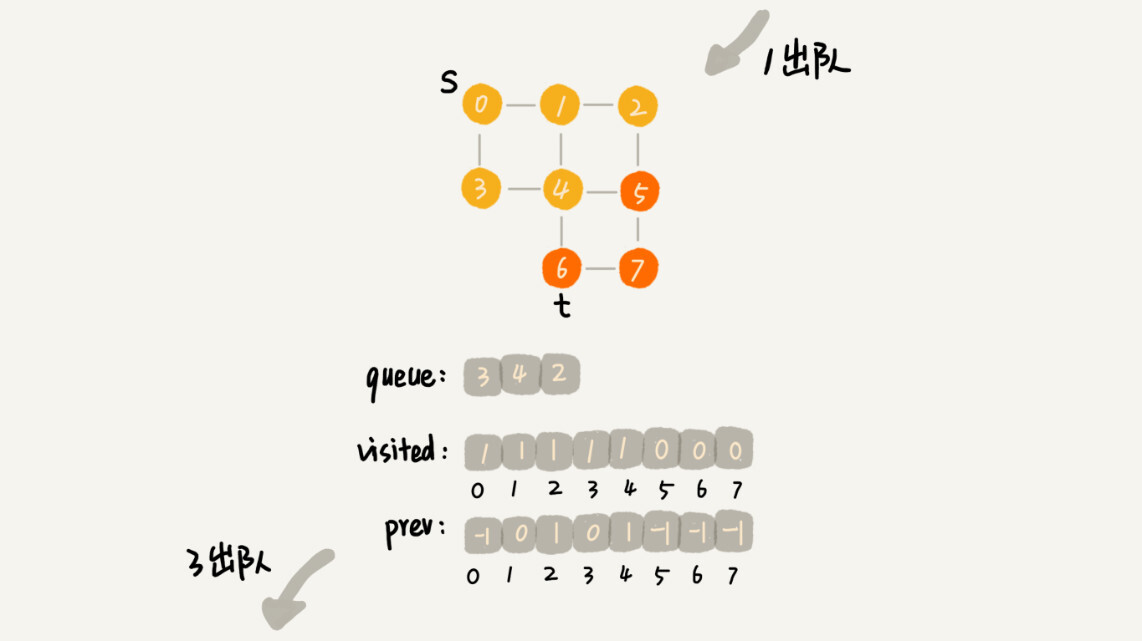
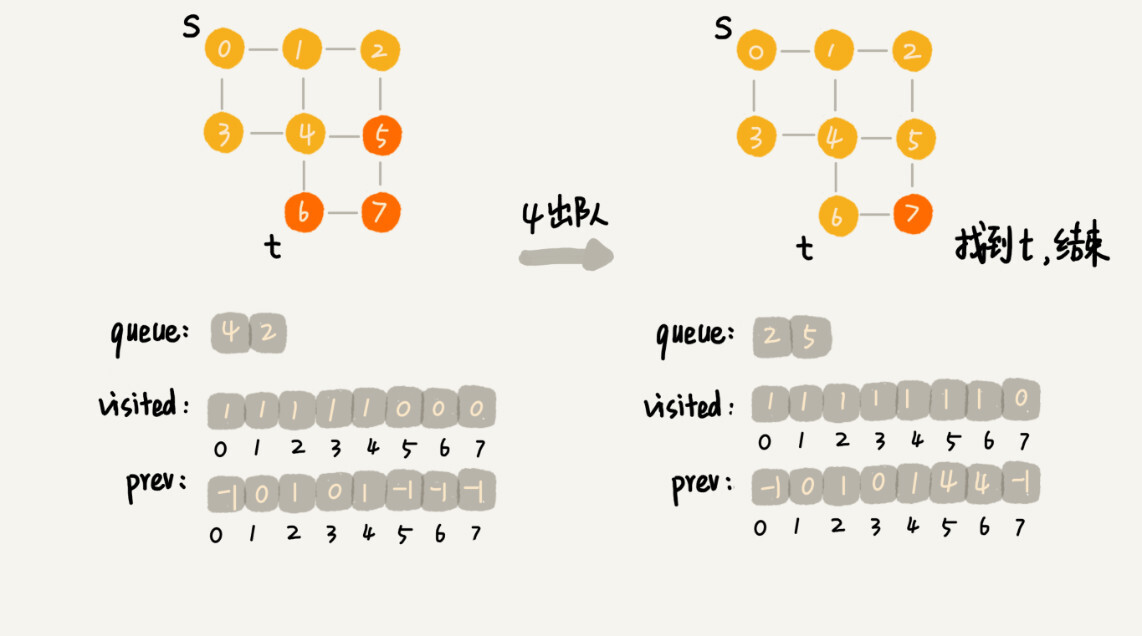 }{:referrerpolicy="no-referrer"}{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"}{:referrerpolicy="no-referrer"
掌握了广度优先搜索算法的原理,我们来看下,广度优先搜索的时间、空间复杂度是多少呢?
最坏情况下,终止顶点t离起始顶点s很远,需要遍历完整个图才能找到。这个时候,每个顶点都要进出一遍队列,每个边也都会被访问一次,所以,广度优先搜索的时间复杂度是O(V+E),其中,V表示顶点的个数,E表示边的个数。当然,对于一个连通图来说,也就是说一个图中的所有顶点都是连通的,E肯定要大于等于V-1,所以,广度优先搜索的时间复杂度也可以简写为O(E)。
广度优先搜索的空间消耗主要在几个辅助变量visited数组、queue队列、prev数组上。这三个存储空间的大小都不会超过顶点的个数,所以空间复杂度是O(V)。
深度优先搜索(DFS)
深度优先搜索(Depth-First-Search),简称DFS。最直观的例子就是“走迷宫”。
假设你站在迷宫的某个岔路口,然后想找到出口。你随意选择一个岔路口来走,走着走着发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。这种走法就是一种深度优先搜索策略。
走迷宫的例子很容易能看懂,我们现在再来看下,如何在图中应用深度优先搜索,来找某个顶点到另一个顶点的路径。
你可以看我画的这幅图。搜索的起始顶点是s,终止顶点是t,我们希望在图中寻找一条从顶点s到顶点t的路径。如果映射到迷宫那个例子,s就是你起始所在的位置,t就是出口。
我用深度递归算法,把整个搜索的路径标记出来了。这里面实线箭头表示遍历,虚线箭头表示回退。从图中我们可以看出,深度优先搜索找出来的路径,并不是顶点s到顶点t的最短路径。
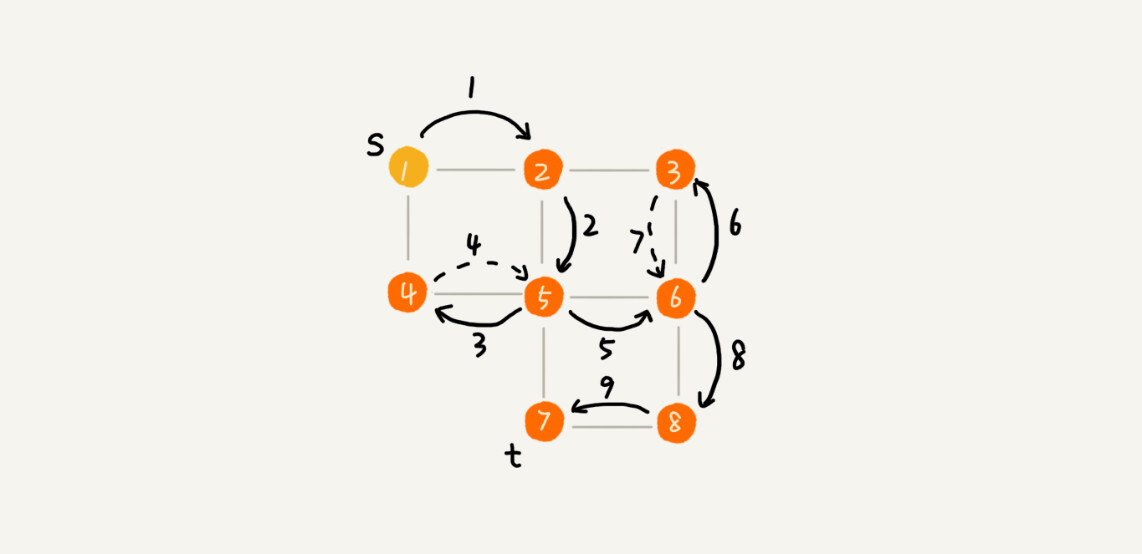
实际上,深度优先搜索用的是一种比较著名的算法思想,回溯思想。这种思想解决问题的过程,非常适合用递归来实现。回溯思想我们后面会有专门的一节来讲,我们现在还回到深度优先搜索算法上。
我把上面的过程用递归来翻译出来,就是下面这个样子。我们发现,深度优先搜索代码实现也用到了prev、visited变量以及print()函数,它们跟广度优先搜索代码实现里的作用是一样的。不过,深度优先搜索代码实现里,有个比较特殊的变量found,它的作用是,当我们已经找到终止顶点t之后,我们就不再递归地继续查找了。
boolean found = false; // 全局变量或者类成员变量
public void dfs(int s, int t) {
found = false;
boolean[] visited = new boolean[v];
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
recurDfs(s, t, visited, prev);
print(prev, s, t);
}
private void recurDfs(int w, int t, boolean[] visited, int[] prev) {
if (found == true) return;
visited[w] = true;
if (w == t) {
found = true;
return;
}
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
recurDfs(q, t, visited, prev);
}
}
}
理解了深度优先搜索算法之后,我们来看,深度优先搜索的时间、空间复杂度是多少呢?
从我前面画的图可以看出,每条边最多会被访问两次,一次是遍历,一次是回退。所以,图上的深度优先搜索算法的时间复杂度是O(E),E表示边的个数。
深度优先搜索算法的消耗内存主要是visited、prev数组和递归调用栈。visited、prev数组的大小跟顶点的个数V成正比,递归调用栈的最大深度不会超过顶点的个数,所以总的空间复杂度就是O(V)。
解答开篇
了解了深度优先搜索和广度优先搜索的原理之后,开篇的问题是不是变得很简单了呢?我们现在来一起看下,如何找出社交网络中某个用户的三度好友关系?
上一节我们讲过,社交网络可以用图来表示。这个问题就非常适合用图的广度优先搜索算法来解决,因为广度优先搜索是层层往外推进的。首先,遍历与起始顶点最近的一层顶点,也就是用户的一度好友,然后再遍历与用户距离的边数为2的顶点,也就是二度好友关系,以及与用户距离的边数为3的顶点,也就是三度好友关系。
我们只需要稍加改造一下广度优先搜索代码,用一个数组来记录每个顶点与起始顶点的距离,非常容易就可以找出三度好友关系。
内容小结
广度优先搜索和深度优先搜索是图上的两种最常用、最基本的搜索算法,比起其他高级的搜索算法,比如A*、IDA*等,要简单粗暴,没有什么优化,所以,也被叫作暴力搜索算法。所以,这两种搜索算法仅适用于状态空间不大,也就是说图不大的搜索。
广度优先搜索,通俗的理解就是,地毯式层层推进,从起始顶点开始,依次往外遍历。广度优先搜索需要借助队列来实现,遍历得到的路径就是,起始顶点到终止顶点的最短路径。深度优先搜索用的是回溯思想,非常适合用递归实现。换种说法,深度优先搜索是借助栈来实现的。在执行效率方面,深度优先和广度优先搜索的时间复杂度都是O(E),空间复杂度是O(V)。
课后思考
- 我们通过广度优先搜索算法解决了开篇的问题,你可以思考一下,能否用深度优先搜索来解决呢?
- 学习数据结构最难的不是理解和掌握原理,而是能灵活地将各种场景和问题抽象成对应的数据结构和算法。今天的内容中提到,迷宫可以抽象成图,走迷宫可以抽象成搜索算法,你能具体讲讲,如何将迷宫抽象成一个图吗?或者换个说法,如何在计算机中存储一个迷宫?
欢迎留言和我分享,也欢迎点击“请朋友读”,把今天的内容分享给你的好友,和他一起讨论、学习。
- Jerry银银 👍(268) 💬(31)
朗读者原谅我的有强迫症:queue这个单词读错了,付上正确的音标如下[kju] 我觉得避免这种问题,有个方法就是,朗读之前,逐个查询一下单词的正确发音,一篇文章中的单词屈指可数,这个工作量按理说应该不大。 但是这个简单的举措,能大大提高听文章的体验,不然听起来总觉得很怪 往大了说影响,毕竟咱们极客时间做的是知识,做的是学问
2018-12-03 - 李东勇 👍(65) 💬(7)
老师, 我觉得深度优先搜索的代码中有一个可以改进的地方, 可以在21行之后加一句: if (found == true) return; 这样, 在一个顶点的for循环之中, 如果已经找到了t, 就可以跳出这个for循环了。目前的逻辑是, 这个for循环中剩下的还会继续执行, 每次都调用一次recurDfs函数, 但recurDfs函数在第一行就return了。
2018-12-18 - luo 👍(18) 💬(1)
老师针对图这个数据结构的应用 我有点疑惑,从结构来看无论是临近矩阵还是临近表 其实都需要有一个唯一下标作为这个顶点,那么问题来了 在实际数据量庞大的时候,这种数据结构是不是就没法用了(临近矩阵就不说了,临近表的话也是需要一个大的数组存储每个顶点 ),或者只能拆成以hash先分id,之后映射到对应的机器上存储各自的临近表部分,但这样进行深度广度搜索就有网络io了。
2019-01-04 - Liam 👍(14) 💬(2)
对于今天的问题,无权图,如果采用深度优先。拿到的路径不一定是最短路径吧
2019-02-13 - possible 👍(8) 💬(1)
广度优先用的queue(先进先出),深度优先把queue换成stack(后进先出)即可吧?也经常会用stack来替代递归
2019-04-28 - -W.LI- 👍(7) 💬(3)
弱弱的问一句,prev和visited用数组存是正好value和下标一致才行的吧?
2019-10-20 - JzyCc 👍(6) 💬(1)
弱弱的问一下,宽搜代码那块,如果给的图中 1 和 3的位置互换,那么得出来的就不是最短路径了吧
2019-02-09 - 他在她城断了弦 👍(4) 💬(2)
可不可以这样理解,深度优先用递归思想,广度优先用迭代思想?
2018-12-04 - gesanri 👍(3) 💬(1)
没明白文中说的广度优先遍历是起始顶点到终止顶点的最短路径是什么意思?就举的这个例子来说,按照广度优先的算法,一直到倒数第二个顶点才扫描到终止节点,总共经历了七个顶点,而肉眼上看明显有更短的路径,比如0346,只经历了四个顶点
2018-12-08 - Smallfly 👍(3) 💬(2)
老师把广度和深度优先搜索讲的真的是通俗易懂。我有个问题是,如果图中存在相同的节点,两种算法是不是就不能工作了?
2018-12-03 - Smallfly 👍(2) 💬(3)
广度搜索图, 4 出队列的时候 queue 应该是 2 5 6 吧
2018-12-03 - 石将从 👍(1) 💬(1)
有个疑问,广度优先搜索,最短路径不止一个吧,比如 s(0)->t(5) 路径有三种: 0->1->2->5, 0->3->4->5, 0->1->4->5
2019-03-22 - 追风者 👍(1) 💬(1)
王老师,广度优先搜索代码的递归退出条件可以再解释一下吗?
2018-12-07 - meng 👍(1) 💬(1)
提个小建议,代码里有些变量名比如 q, v, t,总是不太清楚它们的意思,能否起个更有意义的名字 ?
2018-12-04 - nothing 👍(1) 💬(1)
老师想问问你,您觉得抽象数据类型重要吗,算法实现采用ADT来实现是否重要呢,因为我看到网上的还是您写的一些代码很多都是直接面向物理存储结构,比如数组链表。 但是我们老师在课上都要求我们一定要用ADT,但是我对这个不是很理解。
2018-12-03