07 Cache与内存:程序放在哪儿?
你好,我是LMOS。
在前面的课程里,我们已经知道了CPU是如何执行程序的,也研究了程序的地址空间,这里我们终于到了程序的存放地点——内存。
你知道什么是Cache吗?在你心中,真实的内存又是什么样子呢?今天我们就来重新认识一下Cache和内存,这对我们利用Cache写出高性能的程序代码和实现操作系统管理内存,有着巨大的帮助。
通过这节课的内容,我们一起来看看内存到底是啥,它有什么特性。有了这个认识,你就能更加深入地理解我们看似熟悉的局部性原理,从而搞清楚,为啥Cache是解决内存瓶颈的神来之笔。最后,我还会带你分析x86平台上的Cache,规避Cache引发的一致性问题,并让你掌握获取内存视图的方法。
那话不多说,带着刚才的问题,我们正式进入今天的学习吧!
从一段“经典”代码看局部性原理
不知道,你还记不记得C语言打印九九乘法表的代码,想不起来也没关系,下面我把它贴出来,代码很短,也很简单,就算你自己写一个也用不了一分钟,如下所示。
#include <stdio.h>
int main(){
int i,j;
for(i=1;i<=9;i++){
for(j=1;j<=i;j++){
printf("%d*%d=%2d ",i,j,i*j);
}
printf("\n");
}
return 0;
}
我们当然不是为了研究代码本身,这个代码非常简单,这里我们主要是观察这个结构,代码的结构主要是顺序、分支、循环,这三种结构可以写出现存所有算法的程序。
我们常规情况下写的代码是顺序和循环结构居多。上面的代码中有两重循环,内层循环的次数受到外层循环变量的影响。就是这么简单,但是越简单的东西越容易看到本质。
可以看到,这个代码大数时间在执行一个乘法计算和调用一个printf函数,而程序一旦编译装载进内存中,它的地址就确定了。也就是说,CPU大多数时间在访问相同或者与此相邻的地址,换句话说就是:CPU大多数时间在执行相同的指令或者与此相邻的指令。这就是大名鼎鼎的程序局部性原理。
内存
明白了程序的局部性原理之后,我们再来看看内存。你或许感觉这跨越有点大,但是只有明白了内存的结构和特性,你才能明白程序局部性原理的应用场景和它的重要性。
内存也可称为主存,不管硬盘多大、里面存放了多少程序和数据,只要程序运行或者数据要进行计算处理,就必须先将它们装入内存。我们先来看看内存长什么样(你也可以上网自行搜索),如下图所示。

从上图可以看到在PCB板上有内存颗粒芯片,主要是用来存放数据的。SPD芯片用于存放内存自身的容量、频率、厂商等信息。还有最显眼的金手指,用于连接数据总线和地址总线,电源等。
其实从专业角度讲,内存应该叫DRAM,即动态随机存储器。内存储存颗粒芯片中的存储单元是由电容和相关元件做成的,电容存储电荷的多、少代表数字信号0和1。
而随着时间的流逝,电容存在漏电现象,这导致电荷不足,就会让存储单元的数据出错,所以DRAM需要周期性刷新,以保持电荷状态。DRAM结构较简单且集成度很高,通常用于制造内存条中的储存颗粒芯片。
虽然内存技术标准不断更新,但是储存颗粒的内部结构没有本质改变,还是电容存放电荷,标准看似更多,实际上只是提升了位宽、工作频率,以及传输时预取的数据位数。
比如DDR SDRAM,即双倍速率同步动态随机存储器,它使用2.5V的工作电压,数据位宽为64位,核心频率最高为166MHz。下面简称DDR内存,它表示每一个时钟脉冲传输两次数据,分别在时钟脉冲的上升沿和下降沿各传输一次数据,因此称为双倍速率的SDRAM。
后来的DDR2、DDR3、DDR4也都在核心频率和预取位数上做了提升。最新的DDR4采用1.2V工作电压,数据位宽为64位,预取16位数据。DDR4取消了双通道机制,一条内存即为一条通道,工作频率最高可达4266MHz,单根DDR4内存的数据传输带宽最高为34GB/s。
其实我们无需过多关注内存硬件层面的技术规格标准,重点需要关注的是,内存的速度还有逻辑上内存和系统的连接方式和结构,这样你就能意识到内存有多慢,还有是什么原因导致内存慢的。
我们还是画幅图说明吧,如下图所示。

结合图片我们看到,控制内存刷新和内存读写的是内存控制器,而内存控制器集成在北桥芯片中。传统方式下,北桥芯片存在于系统主板上,而现在由于芯片制造工艺的升级,芯片集成度越来越高,所以北桥芯片被就集成到CPU芯片中了,同时这也大大提升了CPU访问内存的性能。
而作为软件开发人员,从逻辑上我们只需要把内存看成一个巨大的字节数组就可以,而内存地址就是这个数组的下标。
CPU到内存的性能瓶颈
尽管CPU和内存是同时代发展的,但CPU所使用技术工艺的材料和内存是不同的,侧重点也不同,价格也不同。如果内存使用CPU的工艺和材料制造,那内存条的昂贵程度会超乎想象,没有多少人能买得起。
由于这些不同,导致了CPU和内存条的数据吞吐量天差地别。尽管最新的DDR4内存条带宽高达34GB/s,然而这相比CPU的数据吞吐量要慢上几个数量级。再加上多核心CPU同时访问内存,会导致总线争用问题,数据吞吐量会进一步下降。
CPU要数据,内存一时给不了怎么办?CPU就得等,通常CPU会让总线插入等待时钟周期,直到内存准备好,到这里你就会发现,无论CPU的性能多高都没用,而内存才是决定系统整体性能的关键。显然依靠目前的理论直接提升内存性能,达到CPU的同等水平,这是不可行的,得想其它的办法。
Cache
让我们重新回到前面的场景中,回到程序的局部性原理,它告诉我们:CPU大多数时间在访问相同或者与此相邻的地址。那么,我们立马就可以想到用一块小而快的储存器,放在CPU和内存之间,就可以利用程序的局部性原理来缓解CPU和内存之间的性能瓶颈。这块小而快的储存器就是Cache,即高速缓存。
Cache中存放了内存中的一部分数据,CPU在访问内存时要先访问Cache,若Cache中有需要的数据就直接从Cache中取出,若没有则需要从内存中读取数据,并同时把这块数据放入Cache中。但是由于程序的局部性原理,在一段时间内,CPU总是能从Cache中读取到自己想要的数据。
Cache可以集成在CPU内部,也可以做成独立的芯片放在总线上,现在x86 CPU和ARM CPU都是集成在CPU内部的。其逻辑结构如下图所示。

Cache主要由高速的静态储存器、地址转换模块和Cache行替换模块组成。
Cache会把自己的高速静态储存器和内存分成大小相同的行,一行大小通常为32字节或者64字节。Cache和内存交换数据的最小单位是一行,为方便管理,在Cache内部的高速储存器中,多个行又会形成一组。
除了正常的数据空间外,Cache行中还有一些标志位,如脏位、回写位,访问位等,这些位会被Cache的替换模块所使用。
Cache大致的逻辑工作流程如下。
1.CPU发出的地址由Cache的地址转换模块分成3段:组号,行号,行内偏移。
2.Cache会根据组号、行号查找高速静态储存器中对应的行。如果找到即命中,用行内偏移读取并返回数据给CPU,否则就分配一个新行并访问内存,把内存中对应的数据加载到Cache行并返回给CPU。写入操作则比较直接,分为回写和直通写,回写是写入对应的Cache行就结束了,直通写则是在写入Cache行的同时写入内存。
3.如果没有新行了,就要进入行替换逻辑,即找出一个Cache行写回内存,腾出空间,替换行有相关的算法,替换算法是为了让替换的代价最小化。例如,找出一个没有修改的Cache行,这样就不用把它其中的数据回写到内存中了,还有找出存在时间最久远的那个Cache行,因为它大概率不会再访问了。
以上这些逻辑都由Cache硬件独立实现,软件不用做任何工作,对软件是透明的。
Cache带来的问题
Cache虽然带来性能方面的提升,但同时也给和硬件和软件开发带来了问题,那就是数据一致性问题。
为了搞清楚这个问题,我们必须先搞清楚Cache在硬件层面的结构,下面我画了x86 CPU的Cache结构图:

这是一颗最简单的双核心CPU,它有三级Cache,第一级Cache是指令和数据分开的,第二级Cache是独立于CPU核心的,第三级Cache是所有CPU核心共享的。
下面来看看Cache的一致性问题,主要包括这三个方面.
1.一个CPU核心中的指令Cache和数据Cache的一致性问题。 2.多个CPU核心各自的2级Cache的一致性问题。 3.CPU的3级Cache与设备内存,如DMA、网卡帧储存,显存之间的一致性问题。这里我们不需要关注这个问题。
我们先来看看CPU核心中的指令Cache和数据Cache的一致性问题,对于程序代码运行而言,指令都是经过指令Cache,而指令中涉及到的数据则会经过数据Cache。
所以,对自修改的代码(即修改运行中代码指令数据,变成新的程序)而言,比如我们修改了内存地址A这个位置的代码(典型的情况是Java运行时编译器),这个时候我们是通过储存的方式去写的地址A,所以新的指令会进入数据Cache。
但是我们接下来去执行地址A处的指令的时候,指令Cache里面可能命中的是修改之前的指令。所以,这个时候软件需要把数据Cache中的数据写入到内存中,然后让指令Cache无效,重新加载内存中的数据。
再来看看多个CPU核心各自的2级Cache的一致性问题。从上图中可以发现,两个CPU核心共享了一个3级Cache。比如第一个CPU核心读取了一个A地址处的变量,第二个CPU也读取A地址处的变量,那么第二个CPU核心是不是需要从内存里面经过第3、2、1级Cache再读一遍,这个显然是没有必要的。
在硬件上Cache相关的控制单元,可以把第一个CPU核心的A地址处Cache内容直接复制到第二个CPU的第2、1级Cache,这样两个CPU核心都得到了A地址的数据。不过如果这时第一个CPU核心改写了A地址处的数据,而第二个CPU核心的2级Cache里面还是原来的值,数据显然就不一致了。
为了解决这些问题,硬件工程师们开发了多种协议,典型的多核心Cache数据同步协议有MESI和MOESI。MOESI和MESI大同小异,下面我们就去研究一下MESI协议。
Cache的MESI协议
MESI协议定义了4种基本状态:M、E、S、I,即修改(Modified)、独占(Exclusive)、共享(Shared)和无效(Invalid)。下面我结合示意图,给你解释一下这四种状态。
1.M修改(Modified):当前Cache的内容有效,数据已经被修改而且与内存中的数据不一致,数据只在当前Cache里存在。比如说,内存里面X=5,而CPU核心1的Cache中X=2,Cache与内存不一致,CPU核心2中没有X。

- E独占(Exclusive):当前Cache中的内容有效,数据与内存中的数据一致,数据只在当前Cache里存在;类似RAM里面X=5,同样CPU核心1的Cache中X=5(Cache和内存中的数据一致),CPU核心2中没有X。

- S共享(Shared):当前Cache中的内容有效,Cache中的数据与内存中的数据一致,数据在多个CPU核心中的Cache里面存在。例如在CPU核心1、CPU核心2里面Cache中的X=5,而内存中也是X=5保持一致。

- 无效(Invalid):当前Cache无效。前面三幅图Cache中没有数据的那些,都属于这个情况。
最后还要说一下Cache硬件,它会监控所有CPU上Cache的操作,根据相应的操作使得Cache里的数据行在上面这些状态之间切换。Cache硬件通过这些状态的变化,就能安全地控制各Cache间、各Cache与内存之间的数据一致性了。
这里不再深入探讨MESI协议了,感兴趣的话你可以自行拓展学习。这里只是为了让你明白,有了Cache虽然提升了系统性能,却也带来了很多问题,好在这些问题都由硬件自动完成,对软件而言是透明的。
不过看似对软件透明,这却是有代价的,因为硬件需要耗费时间来处理这些问题。如果我们编程的时候不注意,不能很好地规避这些问题,就会引起硬件去维护大量的Cache数据同步,这就会使程序运行的效能大大下降。
开启Cache
前面我们研究了大量的Cache底层细节和问题,就是为了使用Cache,目前Cache已经成为了现代计算机的标配,但是x86 CPU上默认是关闭Cache的,需要在CPU初始化时将其开启。
在x86 CPU上开启Cache非常简单,只需要将CR0寄存器中CD、NW位同时清0即可。CD=1时表示Cache关闭,NW=1时CPU不维护内存数据一致性。所以CD=0、NW=0的组合才是开启Cache的正确方法。
开启Cache只需要用四行汇编代码,代码如下:
获取内存视图
作为系统软件开发人员,与其了解内存内部构造原理,不如了解系统内存有多大。这个作用更大。
根据前面课程所讲,给出一个物理地址并不能准确地定位到内存空间,内存空间只是映射物理地址空间中的一个子集,物理地址空间中可能有空洞,有ROM,有内存,有显存,有I/O寄存器,所以获取内存有多大没用,关键是要获取哪些物理地址空间是可以读写的内存。
物理地址空间是由北桥芯片控制管理的,那我们是不是要找北桥要内存的地址空间呢?当然不是,在x86平台上还有更方便简单的办法,那就是BIOS提供的实模式下中断服务,就是int指令后面跟着一个常数的形式。
由于PC机上电后由BIOS执行硬件初始化,中断向量表是BIOS设置的,所以执行中断自然执行BIOS服务。这个中断服务是int 15h,但是它需要一些参数,就是在执行int 15h之前,对特定寄存器设置一些值,代码如下。
_getmemmap:
xor ebx,ebx ;ebx设为0
mov edi,E80MAP_ADR ;edi设为存放输出结果的1MB内的物理内存地址
loop:
mov eax,0e820h ;eax必须为0e820h
mov ecx,20 ;输出结果数据项的大小为20字节:8字节内存基地址,8字节内存长度,4字节内存类型
mov edx,0534d4150h ;edx必须为0534d4150h
int 15h ;执行中断
jc error ;如果flags寄存器的C位置1,则表示出错
add edi,20;更新下一次输出结果的地址
cmp ebx,0 ;如ebx为0,则表示循环迭代结束
jne loop ;还有结果项,继续迭代
ret
error:;出错处理
上面的代码是在迭代中执行中断,每次中断都输出一个20字节大小数据项,最后会形成一个该数据项(结构体)的数组,可以用C语言结构表示,如下。
#define RAM_USABLE 1 //可用内存
#define RAM_RESERV 2 //保留内存不可使用
#define RAM_ACPIREC 3 //ACPI表相关的
#define RAM_ACPINVS 4 //ACPI NVS空间
#define RAM_AREACON 5 //包含坏内存
typedef struct s_e820{
u64_t saddr; /* 内存开始地址 */
u64_t lsize; /* 内存大小 */
u32_t type; /* 内存类型 */
}e820map_t;
重点回顾
又到了课程尾声,内存和Cache的学习就告一段落了。今天我们主要讲了四部分内容,局部性原理、内存结构特性、Cache工作原理和x86上的应用。我们一起来回顾一下这节课的重点。
首先从一个场景开始,我们了解了程序通常的结构。通过观察这种结构,我们发现CPU大多数时间在访问相同或者与此相邻的地址,执行相同的指令或者与此相邻的指令。这种现象就是程序局部性原理。
然后,我们研究了内存的结构和特性。了解它的工艺标准和内部原理,知道内存容量相对可以做得较大,程序和数据都要放在其中才能被CPU执行和处理。但是内存的速度却远远赶不上CPU的速度。
因为内存和CPU之间性能瓶颈和程序局部性原理,所以才开发出了Cache(即高速缓存),它由高速静态储存器和相应的控制逻辑组成。
Cache容量比内存小,速度却比内存高,它在CPU和内存之间,CPU访问内存首先会访问Cache,如果访问命中则会大大提升性能,然而它却带来了问题,那就是数据的一致性问题,为了解决这个问题,工程师又开发了Cache一致性协议MESI。这个协议由Cache硬件执行,对软件透明。
最后,我们掌握了x86平台上开启Cache和获取物理内存视图的方法。
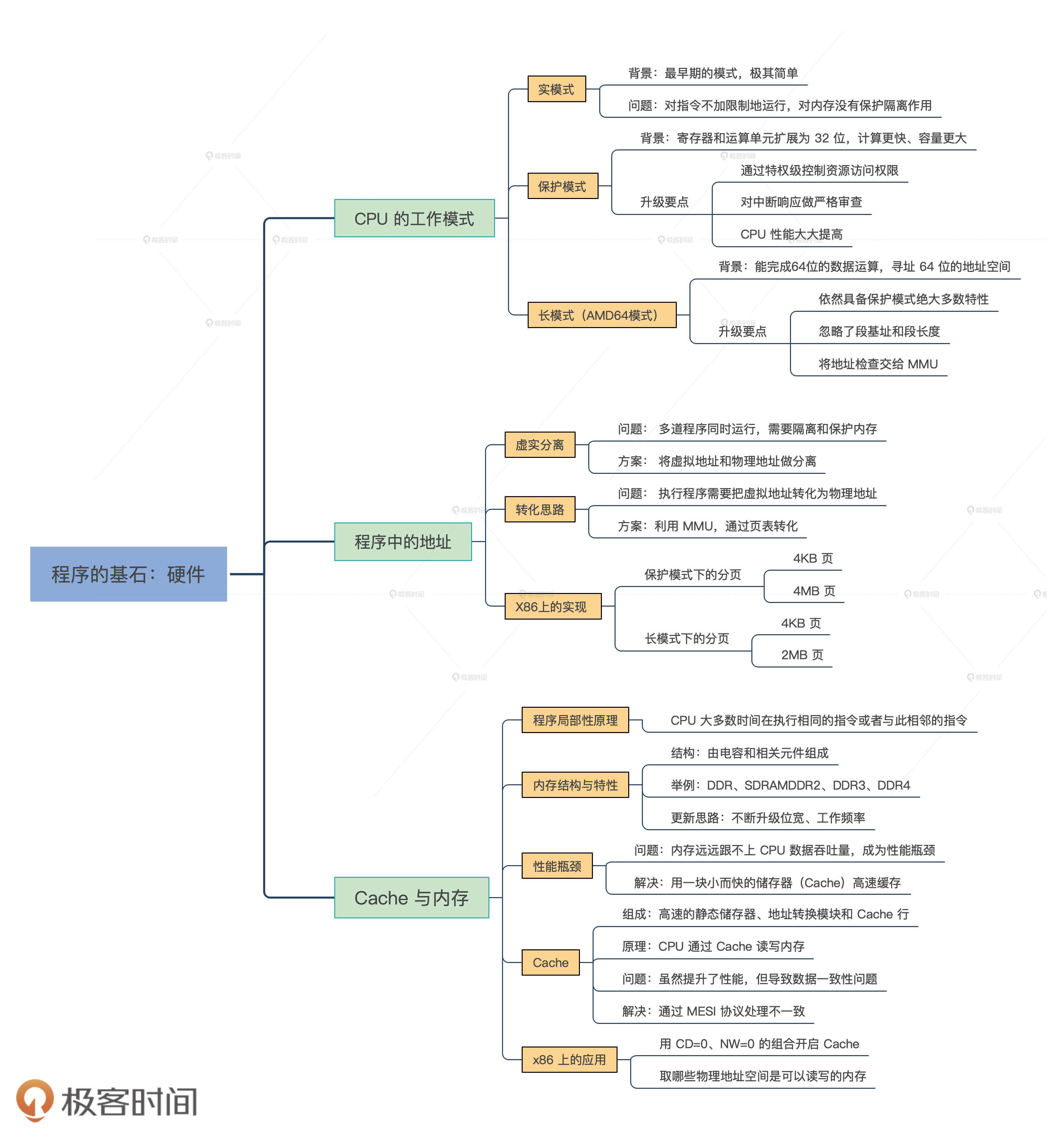
因为这节课也是我们硬件模块的最后一节,可以说没有硬件平台知识,写操作系统就如同空中建楼,通过这个部分的学习,就算是为写操作系统打好了地基。为了让你更系统地认识这个模块,我给你整理了这三节课的知识导图。
思考题
请你思考一下,如何写出让CPU跑得更快的代码?由于Cache比内存快几个数量级,所以这个问题也可以转换成:如何写出提高Cache命中率的代码?
- 数学汤家凤 👍(19) 💬(2)
程序代码优化 基于csapp做的整理 https://blog.csdn.net/u013570834/article/details/117635229?utm_source=app&app_version=4.9.2 1. gcc 编译器优化很蠢并不会猜测程序员编码的意图,只会做非常保守的优化 2.循环对于具有很好的时间局部性,所以我们尽量避免 goto 与非本地跳转 3. 数组在内存中行优先排列,所以数组的遍历方式对cache的命中率影响极大 4. 分支预测失败虽然会带来极大的惩罚,但这不是我们关注的重点,我们应该关注的如何能用条件传送的方式避免分支判断 5. 根据阿姆达尔定律,加速大的部分永远比加速小的要有效,所以我们可以根据对程序的分析来做具体的优化
2021-06-28 - neohope 👍(271) 💬(10)
如何写出让 CPU 跑得更快的代码?可以从以下几方面入手: 1、遵从80-20法则,程序80%的时间在运行20%或更少的代码,针对热代码进行优化,才容易产出效果; 2、遵从数据访问的局部性法则,按数据存放顺序访问内存效率远高于乱序访问内存效率,也就是尽量帮助CPU做好数据Cache的预测工作。同样根据Cache大小,做好数据结构的优化工作,进行数据压缩或数据填充,也是提升Cache效率的好方式; 3、遵从指令访问的局部性法则,减少跳转指令,同样是尽量帮助CPU做好数据Cache的预测工作;现代CPU都有一些预测功能【如分支预测】,利用好CPU的这些功能,也会提升Cache命中率; 4、避免计算线程在多个核心之间漂移,避免缓存重复加载,可以绑定核心【物理核即可,不用到逻辑核】,提高效率; 5、去除伪共享缓存:在多核环境下,减少多个核心对同一区域内存的读写并发操作,减少内存失效的情况的发生; ===开始跑题=== 6、合理提高进程优先级,减少进程间切换,可以变相提供Cache提速的效果 7、关闭Swap,可以变相提供内存提速、Cache提速的效果; 8、使用Intel自家的编译器,开启性能优化,很多时候可以提速运算效率; 9、使用C语言,而不是更高级的语言,很多时候可以提速运算效率; 10、直接使用昂贵的寄存器作为变量,可以变相提供加速效果;
2021-05-24 - zhanyd 👍(25) 💬(1)
我以前写过一篇关于缓存局部性原理的文章,有兴趣的同学可以看看: https://blog.csdn.net/zhanyd/article/details/102631248
2021-05-24 - pedro 👍(62) 💬(15)
在CSAPP第六章对存储器层次架构有详细的探讨,感兴趣的同学可以查阅一下,这里我简单总结一下当做思考题答案。 一个编写良好的计算机程序尝尝具有良好的局部性,这被称为局部性原理,对硬件和软件都有极大的影响。 局部性可分为两种,1.程序数据引用局部性;2.指令局部性。 CPU对数据和指令都存在高速缓存,当缓存中的数据大面积命中时,则该代码拥有良好的空间局部性;当缓存中的指令大面积命中时,也该代码拥有良好的时间局部性。 别忘了,CPU对于指令和数据的操作都需要花时间,那如果二者如果都大面积的缓存命中,可以减少非常多的内存访问操作,对于CPU来说,内存访问就是性能瓶颈所在。 因此编写高速缓存友好的代码是必要的,高手与小白往往只有一步之遥! 基本方法大致如下: 1.让最常见的情况运行得快,核心函数中的核心部分,是影响性能的关键点,它们占据了程序的大部分运行时间,所以要把注意力放在它们身上。 2.尽量减少每个循环内部的缓存不命中数量,循环是缓存工作的重点,一个循环容易带来性能问题,而它恰好也容易被优化成空间、时间局部性良好的代码。 欢迎大家一起交流指正~
2021-05-24 - Spring 👍(107) 💬(9)
补充一下MESI协议,MESI分别代表了高速缓存行的四种状态: 最开始只有一个核读取了A数据,此时状态为E独占,数据是干净的, 后来另一个核又读取了A数据,此时状态为S共享,数据还是干净的, 接着其中一个核修改了数据A,此时会向其他核广播数据已被修改,让其他核的数据状态变为I失效,而本核的数据还没回写内存,状态则变为M已修改,等待后续刷新缓存后,数据变回E独占,其他核由于数据已失效,读数据A时需要重新从内存读到高速缓存,此时数据又共享了
2021-05-29 - aa 👍(20) 💬(4)
恍然大悟,原来这就是要求我们写高复用性代码的原因,针对经常会用到的功能封装成通用函数或库,供整个程序调用,这些通用函数装载入cache后,因为其高复用性长久的存在于cache中,cpu自然就跑得更快。
2021-09-13 - K菌无惨 👍(11) 💬(1)
1. 减少使用带有jmp指令的代码,提高指令cache的局部性(不过cpu貌似有分支预测器来优化jmp指令带来的性能损耗) 2. 对于需要连续访问的数据,可以将其放在一块以提高数据cache的局部性 3. 对于需要被多个CPU执行写操作的多个数据,可以根据cache line的大小对这些数据进行padding操作,来降低缓存一致性协议带来的读写内存频率
2021-06-13 - 园园 👍(9) 💬(1)
提高Cache的命中率可以从优化指令布局和优化数据布局两个方面开展。比如减少频繁的跳转,数据集中连续存放等。
2021-05-24 - blentle 👍(8) 💬(6)
回答一下思考题. 因为缓存行是固定的,32或64个字节,只能在写入内存的数据上尽量补齐,比如一个int 占4个字节(java),32位系统的对象头占8个字节,这样再多写5个int就对齐一个缓冲行了,jdk也提供了一个 annotation 即@Commented来解决,另外内存队列disruptor也用同样的方式优化了同样的问题,但是如此这数据,势必会造成资源浪费,如何权衡这2者还请老师分享一下经验
2021-05-24 - 88 👍(6) 💬(2)
《深入理解计算机系统》 6.2 局部性 局部性分为:1. 时间局部性 2. 空间局部性 int sumvec(int v[N]) { int i, sum = 0; // sum在每次循环迭代中被引用一次,因此对于sum来说,有好的时间局部性;另一方面因为sum是标量,对于sum来说,没有空间局部性 for (i = 0; i < N; i++) { sum += v[i]; // 向量v的元素是被顺序读取的,因此对于变量v,函数有很好的空间局部性;但是时间局部性很差,因为每个向量元素只被访问一次 } return sum; } // 所以可以说:以被重复访问的次数衡量时间局部性,以访问是否有序、步长大小衡量空间局部性
2021-08-02 - 宇宙的琴弦 👍(5) 💬(2)
尽量让程序少跳转,比如在if else分支结构中,提高if的条件成立的可能性。在循环需要对变量操作时,应尽量考虑到这些变量的空间存储位置,还有尽量使用局部变量?
2021-05-24 - 山不厌高,海不厌深 👍(4) 💬(1)
二级、三级缓存是冯诺依曼结构,一级缓存是哈佛结构。这样的理解对吗?
2021-10-24 - springXu 👍(4) 💬(2)
我认为是不是可以尽量加载cache line为单位的数据从内存中,然后进行操作和运算,再放回内存中? 本质就是减少内存的读与写。像blowfish对一组数据操作时,就可以采取这样的方式。但有像sse,avx512这种指令也是这种理念吧。SIMD单指令多数据流。
2021-05-24 - undefined 👍(4) 💬(1)
摩拳擦掌,跃跃欲试。
2021-05-24 - 学呀学呀学 👍(3) 💬(2)
请问,地址空间中,决定哪些地址给内存,哪些地址给显存,哪些地址给设备IO,这个是由操作系统决定,还是由bios决定呢?
2021-07-14