01 程序的运行过程:从代码到机器运行
你好,我是LMOS。
欢迎来到操作系统第一课。在真正打造操作系统前,有一条必经之路:你知道程序是如何运行的吗?
一个熟练的编程老手只需肉眼看着代码,就能对其运行的过程了如指掌。但对于初学者来说,这常常是很困难的事,这需要好几年的程序开发经验,和在长期的程序开发过程中对编程基本功的积累。
我记得自己最初学习操作系统的时候,面对逻辑稍微复杂的一些程序,在编写、调试代码时,就会陷入代码的迷宫,找不到东南西北。
不知道你现在处在什么阶段,是否曾有同样的感受?我常常说,扎实的基本功就像手里的指南针,你可以一步步强大到不依赖它,但是不能没有。
因此今天,我将带领你从 “Hello World” 起,扎实基本功,探索程序如何运行的所有细节和原理。这节课的配套代码,你可以从这里下载。
一切要从牛人做的牛逼事说起
第一位牛人,是世界级计算机大佬的传奇——Unix之父Ken Thompson。
在上世纪60年代的一个夏天,Ken Thompson的妻子要回娘家一个月。呆在贝尔实验室的他,竟然利用这极为孤独的一个月,开发出了UNiplexed Information and Computing System(UNICS)——即UNIX的雏形,一个全新的操作系统。
要知道,在当时C语言并没有诞生,从严格意义上说,他是用B语言和汇编语言在PDP-7的机器上完成的。

牛人的朋友也是牛人,他的朋友Dennis Ritchie也随之加入其中,共同创造了大名鼎鼎的C语言,并用C语言写出了UNIX和后来的类UNIX体系的几十种操作系统,也写出了对后世影响深远的第一版“Hello World”:
计算机硬件是无法直接运行这个C语言文本程序代码的,需要C语言编译器,把这个代码编译成具体硬件平台的二进制代码。再由具体操作系统建立进程,把这个二进制文件装进其进程的内存空间中,才能运行。
听起来很复杂?别急,接着往下看。
程序编译过程
我们暂且不急着摸清操作系统所做的工作,先来研究一下编译过程和硬件执行程序的过程,约定使用GCC相关的工具链。
那么使用命令:gcc HelloWorld.c -o HelloWorld 或者 gcc ./HelloWorld.c -o ./HelloWorld ,就可以编译这段代码。其实,GCC只是完成编译工作的驱动程序,它会根据编译流程分别调用预处理程序、编译程序、汇编程序、链接程序来完成具体工作。
下图就是编译这段代码的过程:

其实,我们也可以手动控制以上这个编译流程,从而留下中间文件方便研究:
- gcc HelloWorld.c -E -o HelloWorld.i预处理:加入头文件,替换宏。
- gcc HelloWorld.c -S -c -o HelloWorld.s编译:包含预处理,将C程序转换成汇编程序。
- gcc HelloWorld.c -c -o HelloWorld.o汇编:包含预处理和编译,将汇编程序转换成可链接的二进制程序。
- gcc HelloWorld.c -o HelloWorld链接:包含以上所有操作,将可链接的二进制程序和其它别的库链接在一起,形成可执行的程序文件。
程序装载执行
对运行内容有了了解后,我们开始程序的装载执行。
我们将请出第三位牛人——大名鼎鼎的阿兰·图灵。在他的众多贡献中,很重要的一个就是提出了一种理想中的机器:图灵机。
图灵机是一个抽象的模型,它是这样的:有一条无限长的纸带,纸带上有无限个小格子,小格子中写有相关的信息,纸带上有一个读头,读头能根据纸带小格子里的信息做相关的操作并能来回移动。
文字叙述还不够形象,我们来画一幅插图:
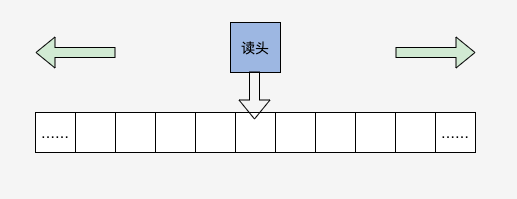
不理解?下面我再带你用图灵机执行一下“1+1=2”的计算,你就明白了。我们定义读头读到“+”之后,就依次移动读头两次并读取格子中的数据,最后读头计算把结果写入第二个数据的下一个格子里,整个过程如下图:

这个理想的模型是好,但是理想终归是理想,想要成为现实,我们得想其它办法。
于是,第四位牛人来了,他提出了电子计算机使用二进制数制系统和储存程序,并按照程序顺序执行,他叫冯诺依曼,他的电子计算机理论叫冯诺依曼体系结构。
根据冯诺依曼体系结构构成的计算机,必须具有如下功能:
- 把程序和数据装入到计算机中;
- 必须具有长期记住程序、数据的中间结果及最终运算结果;
- 完成各种算术、逻辑运算和数据传送等数据加工处理;
- 根据需要控制程序走向,并能根据指令控制机器的各部件协调操作;
- 能够按照要求将处理的数据结果显示给用户。
为了完成上述的功能,计算机必须具备五大基本组成部件:
- 装载数据和程序的输入设备;
- 记住程序和数据的存储器;
- 完成数据加工处理的运算器;
- 控制程序执行的控制器;
- 显示处理结果的输出设备。
根据冯诺依曼的理论,我们只要把图灵机的几个部件换成电子设备,就可以变成一个最小核心的电子计算机,如下图:
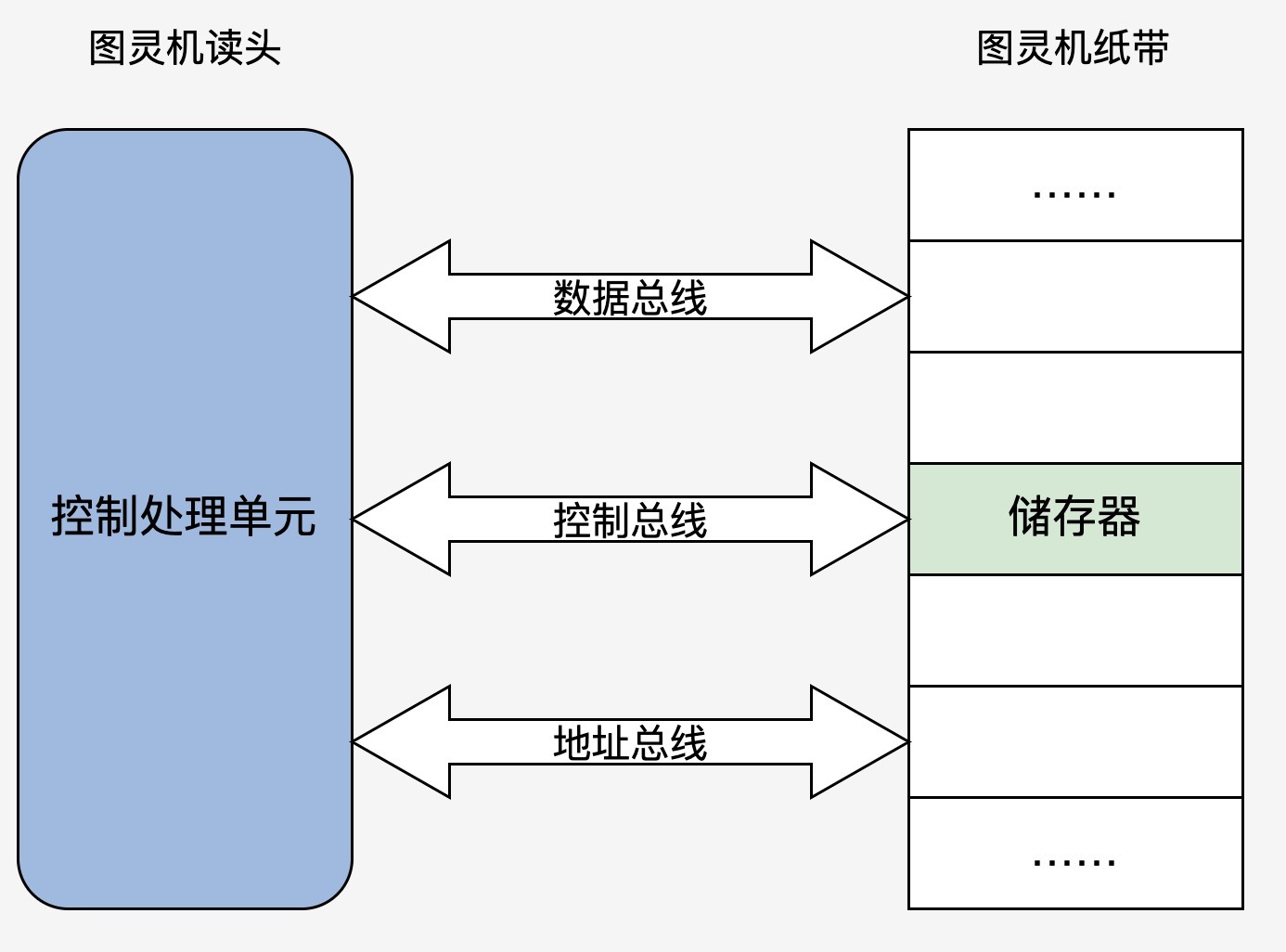
是不是非常简单?这次我们发现读头不再来回移动了,而是靠地址总线寻找对应的“纸带格子”。读取写入数据由数据总线完成,而动作的控制就是控制总线的职责了。
更形象地将HelloWorld程序装入原型计算机
下面,我们尝试将HelloWorld程序装入这个原型计算机,在装入之前,我们先要搞清楚HelloWorld程序中有什么。
我们可以通过gcc -c -S HelloWorld得到(只能得到其汇编代码,而不能得到二进制数据)。我们用objdump -d HelloWorld程序,得到/lesson01/HelloWorld.dump,其中有很多库代码(只需关注main函数相关的代码),如下图:
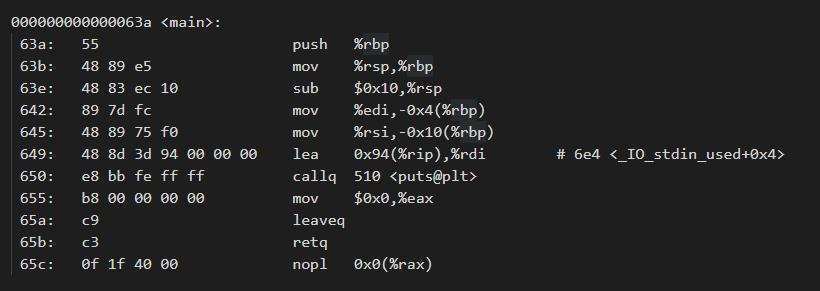
以上图中,分成四列:第一列为地址;第二列为十六进制,表示真正装入机器中的代码数据;第三列是对应的汇编代码;第四列是相关代码的注释。这是x86_64体系的代码,由此可以看出x86 CPU是变长指令集。
接下来,我们把这段代码数据装入最小电子计算机,状态如下图:

重点回顾
以上,对应图中的伪代码你应该明白了:现代电子计算机正是通过内存中的信息(指令和数据)做出相应的操作,并通过内存地址的变化,达到程序读取数据,控制程序流程(顺序、跳转对应该图灵机的读头来回移动)的功能。
这和图灵机的核心思想相比,没有根本性的变化。只要配合一些I/O设备,让用户输入并显示计算结果给用户,就是一台现代意义的电子计算机。
到这里,我们理清了程序运行的所有细节和原理。还有一点,你可能有点疑惑,即printf对应的puts函数,到底做了什么?而这正是我们后面的课程要探索的!
思考题
为了实现C语言中函数的调用和返回功能,CPU实现了函数调用和返回指令,即上图汇编代码中的“call”,“ret”指令,请你思考一下:call和ret指令在逻辑上执行的操作是怎样的呢?
期待你在留言区跟我交流互动。如果这节课对你有所启发,也欢迎转发给你的朋友、同事,跟他们一起学习进步。
- 旺仔的菜 👍(4) 💬(1)
讲解思路比较喜欢,知道程序执行的源头及其演变过程,赞一个
2021-08-26 - Kevinlvlc 👍(226) 💬(9)
思考题: 首先假设CPU执行指令是顺序执行的,那么程序的调用需要考虑几个问题: 1,call指令要执行的代码在哪?也就是被调用函数的第一条指令所在的内存地址 2,被调用函数执行完之后,返回哪个位置继续执行? 只要解决上面这两个问题,那么函数调用时指令的间的跳转就迎刃而解了。 针对第一个问题,在gcc编译完成之后,函数对应的指令序列所在的位置就已经确定了,因此这是编译阶段需要考虑的问题 至于第二个问题,在执行完call指令的同时,需要将call指令下面一条指令的地址保存到栈内存中,同时更新%rsp寄存器指向的位置,然后就可以开始执行被调函数的指令序列,执行完毕后,由ret指令从rsp中获取栈顶的returnadress地址,然后跳转到call的下一条指令继续执行。 以上答案参考csapp 3.7.2小节的内容,加上自己的理解😁😁
2021-05-18 - Fan 👍(8) 💬(14)
能不能建个交流群,有问题方便在群中交流。
2021-05-11 - hh 👍(31) 💬(4)
嗯,第一讲或开篇应该描述一下,我们需要准备什么学习环境
2021-05-11 - pedro 👍(92) 💬(2)
call和ret其实是一对相反指令,调用call时会将当前IP入栈,即push IP,然后执行跳转即jmp,而ret也是将栈中的IP推出写入IP寄存器,即pop IP。
2021-05-10 - Jason 👍(57) 💬(5)
实验环境补充: 上面没讲到实验环境。可以这样做: 1、安装虚拟机,windows/macos上都可以装vmware虚拟机,具体百度 2、在虚拟机中安装linux发行版系统,如centos或ubuntu,具体百度 3、在linux系统里安装gcc工具 4、写好源代码,然后就能gcc编译它了,编译命令,引用 AIK 同学的: 程序编译过程填坑 源文件生成预处理文件: gcc -E HelloWorld.c -o HelloWorld.i 预处理文件生成编译文件: gcc -S HelloWorld.i -o HelloWorld.s 编译文件生成汇编文件: gcc -c HelloWorld.s -o HelloWorld.o 汇编文件生成可执行文件:gcc HelloWorld.o -o HelloWorld 源文件生成可执行文件:gcc HelloWorld.c -o HelloWorld Linux系统运行可执行文件:./HelloWorld —— 引用自 AIK 同学
2021-05-11 - 数学汤家凤 👍(28) 💬(9)
王爽汇编的笔记 快速入门,最近在啃 csapp https://blog.csdn.net/u013570834/article/details/108753839
2021-05-12 - thomas 👍(23) 💬(2)
call 指令会把当前的 PC(CS:IP) 寄存器里的下一条指令的地址压栈,然后进行JMP跳转指令; ret 指令则把 call 调用时压入的 PC 寄存器里的下一条指令出栈,更新到 PC 寄存器中
2021-05-15 - 杰良 👍(18) 💬(2)
系统四牛人:Ken Thompson、Dennis Ritchie、阿兰图灵、冯诺依曼。 编译四步骤:预处理(gcc -E -o)、编译(gcc -s -c)、汇编(gcc -c)、链接(gcc -o)。
2021-05-18 - 郑童文 👍(15) 💬(1)
老师能否推荐一份快速入门汇编语言的阅读材料,让我们能看懂这些汇编代码
2021-05-10 - 青玉白露 👍(14) 💬(2)
思考题:答:“call”即“打电话”,“ret”即”返回某个地方“。要想实现这两个指令,那么首先call需要知道调用的东西在哪,ret需要返回的地方在哪。 对于call,在程序编译完成之后,所有的指令代码都已按顺序存储至计算机中,事先在call 之后附上相应的存储地址即可; 对于ret,其实计算机是使用一种叫做“栈”的结构,简单来说“栈”就好像是一个桶,计算机不停地往里扔东西(压栈),只有拿起上面的东西(出栈),才能拿到下面的东西。ret即是利用栈的结构,来存储自己将要返回的地方。 另外,call与ret是配套使用的。call的时候会将此时运行到的位置压入栈中,ret会从栈中弹出自己将要返回的位置。 彭东老师写的真的不错,后面会把笔记精简一下: https://zhuanlan.zhihu.com/p/373996858
2021-05-21 - wanttocry 👍(13) 💬(2)
什么时候可以出书,八九百页那种,贵一点没关系,比较喜欢纸质。
2021-05-27 - 牧牛少年 👍(9) 💬(7)
老师请问电脑上需要装什么东西?
2021-05-10 - Fan 👍(9) 💬(3)
书跟专栏在内容上有什么区别呢?
2021-05-10 - Zexho 👍(7) 💬(3)
推荐一本汇编适合入门的书 ,《汇编语言》作者王爽 https://book.douban.com/subject/25726019/
2021-05-11