Go语言进化之路:1.19到1.24版本新特性全景回顾(上)
你好,我是Tony Bai。
专栏结课后的这三年间,Go语言发展迅速。从Go开源以来最大规模的语法变化——Go 1.18版本的发布,到即将问世的Go 1.24正式版本,它在TIOBE排行榜上的排名也从第11位上升至第7位。

我在结束语中预测的“Go即将迎来黄金十年的历史时刻”正在逐渐成为现实,种种迹象都表明,Go已经步入了它的黄金10年。
从Go 1.19到即将发布的Go 1.24,新增了许多值得关注的新特性。我将利用两篇加餐带你全面回顾这些新特性,理清Go语言的演进脉络,帮你更好地学习和实践。至于Go 1.18版本的泛型语法,我之前已经讲过,你可以通过这三篇加餐文章来了解。
下面,我们就先从Go最重要的语法特性说起!
语言语法
Go语言以其简洁性著称,在语法层面的变化相对保守。虽然Go 1.18引入了泛型,带来了较大范围的语法变更,但从1.19到1.24版本,Go语言的语法更新频率又回到了之前的步伐,主要集中在对现有功能的完善和增强,而非引入全新的语法结构。以Go 1.19版本为例,它是Go泛型落地后的第一个版本,重点在于修复Go 1.18中发现的泛型相关问题,提升泛型的稳定性和可靠性,并未引入什么语法变更。
下面,我会挑选Go 1.19版本以后的一些主要语法变化点,和你聊聊这些新语法对日常Go编程的影响。
支持切片到数组的转换
Go 1.20版本在语法层面引入了切片到数组的类型转换。这一变化允许开发者在长度匹配的前提下,将切片直接转换为数组或指向数组的指针,提升了Go在处理特定长度数据时的灵活性。下面是一个将切片转换为数组的示例:
// go-evolution/lang/slice2arr.go
func slice2arrOK() {
var sl = []int{1, 2, 3, 4, 5, 6, 7}
var arr = [7]int(sl)
var parr = (*[7]int)(sl)
fmt.Println(sl) // [1 2 3 4 5 6 7]
fmt.Println(arr) // [1 2 3 4 5 6 7]
sl[0] = 11
fmt.Println(arr) // [1 2 3 4 5 6 7]
fmt.Println(parr) // &[11 2 3 4 5 6 7]
}
func slice2arrPanic() {
var sl = []int{1, 2, 3, 4, 5, 6, 7}
fmt.Println(sl)
var arr = [8]int(sl) // panic: runtime error: cannot convert slice with length 7 to array or pointer to array with leng th 8
fmt.Println(arr) // &[11 2 3 4 5 6 7]
}
func main() {
slice2arrOK()
slice2arrPanic()
}
示例比较简单,但有两点需要注意:
- 如果将切片转换为数组类型的指针,那么该指针将指向切片的底层数组,就如同上面例子中slice2arrOK的parr变量那样。
- 转换的数组类型的长度不能大于原切片的长度(注意是长度而不是切片的容量哦),否则在运行时会抛出panic。
明确了包初始化顺序算法
在Go中,包既是功能单元,也是构建单元,Go代码通过导入其他包来复用导入包的导出功能(包括导出的变量、常量、函数、类型以及方法等)。Go程序启动时,程序会首先将依赖的包按一定顺序进行初始化。但长久以来,Go语言规范并没有明确依赖包初始化的顺序,这可能会导致一些对包初始化顺序有依赖的Go程序在不同Go版本下出现行为上的差异。
为了消除这些可能存在的问题,Go核心团队在Go 1.21中明确了包初始化顺序的算法。
注:对包的初始化顺序有依赖,这本身就不是一种很好的设计,我们在日常编码时应该注意避免。如果你的程序对包的初始化顺序存在依赖,那么升级到Go 1.21时程序行为可能会受到影响。
这个算法比较简单,其步骤如下:
- 将所有依赖包按照导入路径排序,放入一个list。
- 从list中按顺序找出第一个自身尚未初始化,但其依赖包已经全部初始化了的包,然后初始化该包,并将该包从list中删除。
- 重新执行上面步骤,直到list为空。
不过,再简单的算法,只用文字描述都会很抽象晦涩,所以我们结合一个例子和配图来理解。我们建立一个init_order的目录,里面的包之间的依赖关系如下图:
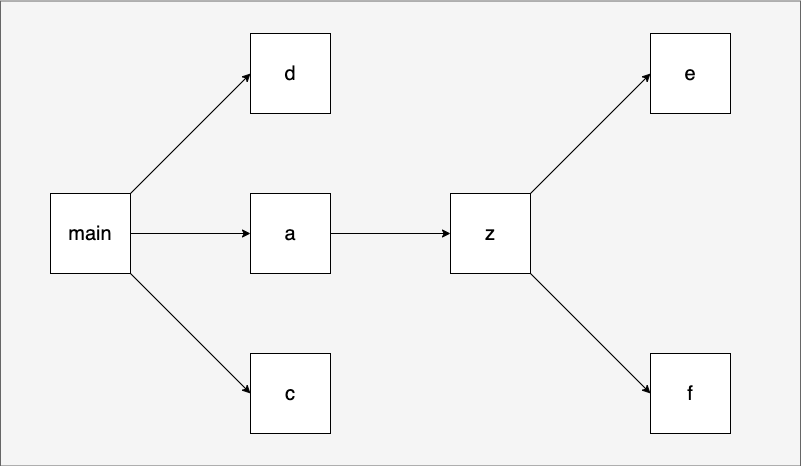
我们在go-evolution/lang/init_order目录下按上面关系建立对应的包:
$tree init_order
init_order
├── a
│ └── a.go
├── c
│ └── c.go
├── d
│ └── d.go
├── e
│ └── e.go
├── f
│ └── f.go
├── go.mod
├── main.go
└── z
└── z.go
我们使用Go 1.21.0运行其中的main.go,得到如下结果:
这个结果是怎么来的呢?我们根据Go 1.21.0明确后的算法来分析一下,具体分析过程见下图:
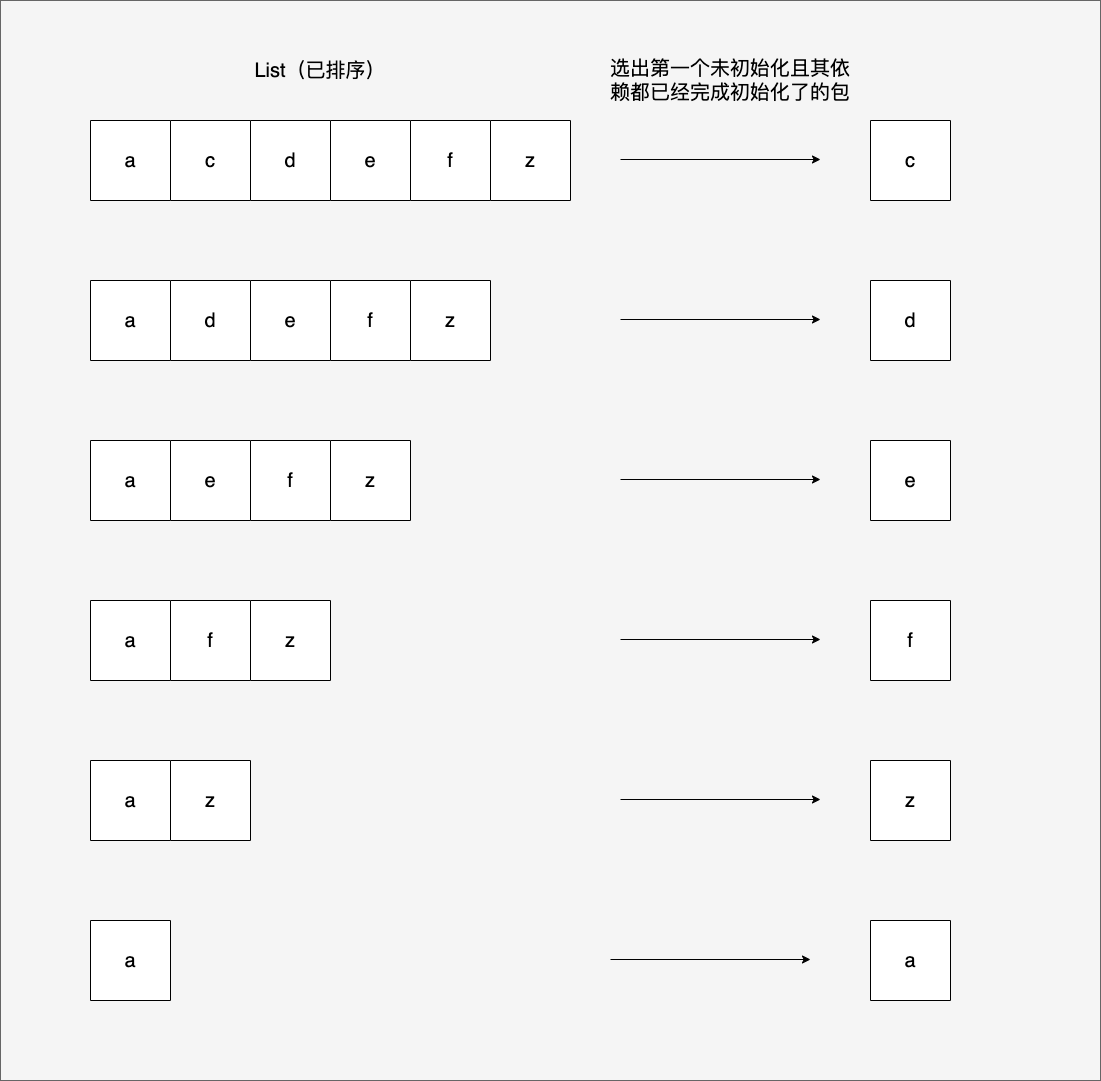
将右侧每一轮选出的包按先后顺序排列,就是main.go的依赖包的初始化顺序:c d e f z a。
我们再用Go 1.20版本运行一下这个示例,得到下面结果:
我们看到由于Go 1.21之前并没有给出明确的包初始化顺序算法,它的输出次序与明确算法的Go 1.21版本的完全不同,这个结果也再次提醒我们代码设计时尽量不要依赖包初始化顺序。
注:专栏第8讲有对Go入口函数与包初始化次序更为系统的讲解,你可以再复习一下。
loopvar语义修正和for range对整型的支持
Go 1.22对语言语法做了两处变更:一个是Go 1.21版本中的试验特性loopvar在Go 1.22中转正落地;另一个也和for循环有关,那就是for range新增了对整型表达式的支持。其中,loopvar带来的影响更大一些。为什么这么说呢?因为这是Go语言发展历史上第一次真正地填语义层面的“坑”,而且修改的是一个在Go源码中最常用的控制结构的执行语义,这很大可能会带来break change。
这次语义修改用一句话表达就是:将经典三段式for循环语句,以及for range语句中的用短声明形式定义的循环变量,从整个循环定义和共享一个,变为每个迭代定义一个。
下面是说明该语义变化的示例:
// go-evolution/lang/loopvar/main.go
package main
import (
"fmt"
"time"
)
func main() {
done := make(chan bool)
values := []string{"a", "b", "c"}
for _, v := range values {
go func() {
time.Sleep(time.Second)
fmt.Println(v)
done <- true
}()
}
// wait for all goroutines to complete before exiting
for _ = range values {
<-done
}
}
为了更直观看到新版本的变化,我们先用Go 1.22.0版本之前的版本,比如用Go 1.21.0运行该示例:
我们看到,由于v是整个循环中各个迭代共享的一个变量,所以在每个迭代新创建的goroutine中输出的v都是循环结束后v的最终值c。
如果我们用Go 1.22.0来运行上述示例,将得到如下结果:
注:关于Go 1.22版本之前的for range的坑,可以复习专栏第19讲。
那么,loopvar这一语义填“坑”究竟对你的代码造成了什么影响呢?
在Russ Cox写的《关于loopvar语义变更的设计文档》中提到,只有go.mod中的go version等于Go 1.22.0及以后版本时才会生效,这是一个渐进式过渡的过程。因此,无论是开源项目还是商业项目,只要go.mod中的go version还没更新为大于或等于Go 1.22.0的版本,for循环就依然保留短声明定义的变量的原语义,这些项目也都不会受到影响。
不过,如果是直接在脚本中通过go run xxx.go形式运行某个Go源码,且当前工作目录以及父目录下没有go.mod文件的,Go 1.22.0就会采用新的loopvar语义,这点你要注意了。
此外,当你将go.mod中的go version升级到Go 1.22.0或更高版本时,也要注意语义变更可能带来的问题。在升级go version之前,可以用Go 1.22版本之前的go vet对项目源码进行一次静态分析,对于go vet提示:“loop variable v captured by func literal”的地方务必逐个确认。
除了loopvar语义修正之外,Go 1.22的for range还新增了对整型表达式的支持(本质上就是一种语法糖),这允许我们使用for i := range 10形式进行循环,用起来更为方便:
支持自定义函数迭代器
Go 1.18版本加入了泛型支持,有了泛型后,各种使用泛型实现的集合类型便如“雨后春笋”般出现了。但Go的for range原生并不支持对这些集合类型的迭代,于是对自定义函数迭代器类型的需求便自然而然地出现了。
Go在1.22版本中实现了这个需求,引入了试验特性range-over-func,即for range语句支持以函数形式定义的用户自定义迭代器。在Go 1.23版本中,这个试验特性变为了正式特性。
迭代器(Iterator)是一个用于遍历集合类型的基本语言构造,例如切片、数组、map等。它是一种获取集合中下一个item的机制,并会检查集合中是否还有其他内容,如果没有了,它会停止继续迭代。这种语言构造并非Go专属的,我们在许多语言中都能找到它,比如Python、Java等。
Go 1.23支持自定义迭代器后,for range的语法规格变为如下形式:

我们看到,for range继Go 1.22增加对整型表达式的支持后,在Go 1.23中又增加了对三种形式的自定义函数迭代器的支持。下面是Go spec中带有单个参数(fibo)和带有两个参数的函数迭代器(Walk)的示例:
// fibo generates the Fibonacci sequence
fibo := func(yield func(x int) bool) {
f0, f1 := 0, 1
for yield(f0) {
f0, f1 = f1, f0+f1
}
}
// print the Fibonacci numbers below 1000:
for x := range fibo {
if x >= 1000 {
break
}
fmt.Printf("%d ", x)
}
// output: 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
// iteration support for a recursive tree data structure
type Tree[K cmp.Ordered, V any] struct {
left, right *Tree[K, V]
key K
value V
}
func (t *Tree[K, V]) walk(yield func(key K, val V) bool) bool {
return t == nil || t.left.walk(yield) && yield(t.key, t.value) && t.right.walk(yield)
}
func (t *Tree[K, V]) Walk(yield func(key K, val V) bool) {
t.walk(yield)
}
// walk tree t in-order
var t Tree[string, int]
for k, v := range t.Walk {
// process k, v
}
初看这个示例,for range的形式很简洁,且循环体内部对获得的item的处理也没有受到任何影响。函数迭代器的复杂性更多由提供迭代器的集合类型的作者承担。作为集合类型的作者,你需要弄清楚迭代器的运作原理,尤其要记住需满足何种函数签名,这样才能更好地提供迭代器的实现。这的确会带来一些复杂性,并且初期编写时,你可能会反复参考Go Spec文档。
至于迭代器的运作原理和典型使用方法,这里就不展开了。如果你感兴趣,可以参考我写过的一篇博客文章《Go 1.23中的自定义迭代器与iter包》。
支持带类型参数的类型别名
我们知道传统类型别名的形式如下:
这里的Q是Named Type,包括Predeclared Type、Anonymous Type、Existing Defined Type以及Existing Alias Type。我们甚至可以用泛型类型实例化后的类型作为Q,比如:
type MySlice[T any] []T
func main() {
type P = MySlice[int] // MySlice[int]作为Q
var p P
fmt.Println(len(p)) // 0
}
但P中不能包含类型参数!下面这样的类型别名定义在Go 1.23之前是不合法的:
不过Go 1.23版本以实验特性(需显式使用GOEXPERIMENT=aliastypeparams)支持了带有类型参数的类型别名,在Go 1.24中,这个实验特性转正,成为了默认特性。我们看下面这个示例:
// go-evolution/lang/generic_type_alias.go
package main
import "fmt"
type MySlice[T any] = []T
func main() {
// 使用int类型实例化MySlice
intSlice := MySlice[int]{1, 2, 3, 4, 5}
fmt.Println("Int Slice:", intSlice)
// 使用string类型实例化MySlice
stringSlice := MySlice[string]{"hello", "world"}
fmt.Println("String Slice:", stringSlice)
// 使用自定义类型实例化MySlice
type Person struct {
Name string
Age int
}
personSlice := MySlice[Person]{
{Name: "Alice", Age: 30},
{Name: "Bob", Age: 25},
}
fmt.Println("Person Slice:", personSlice)
}
使用Go 1.24rc1直接运行上面示例,我们可以得到如下结果:
怎么理解带有类型参数的类型别名呢?Russ Cox曾给出过他的理解,即可以将其看成是一种“类型宏”(类似C中的#define),也就是在任何出现 MySlice[T] 的地方,将其换成 []T。
看完了主要语法的演进后,我们再来看看Go编译器和运行时都有哪些值得关注的变化。
编译器与运行时
编译器和运行时是Go语言性能和效率的基石。从1.19到1.24版本,Go编译器和运行时在编译器优化、垃圾回收,以及对WebAssembly的支持等方面都做了很多改进。
引入Soft memory limit
Go 1.19版本之前,GC的唯一调优参数是GOGC。它的默认值为100,通过调整GOGC的值,开发者可以控制GC触发的频率。较小的GOGC值会使GC更频繁地运行,从而带来更多的CPU开销和更大的响应时间;而较大的值则会减少GC的频率,但系统会承担内存占用过多的风险,并且这种Go的GC触发机制无法保证应用在内存使用高峰时不会被OOM(Out Of Memory)杀死。在某些情况下,即使应用的live heap对象未达到硬内存限制,GC也可能因未及时触发而导致OOM。
Twitch公司曾通过“Memory Ballast”方案来减少响应时间,即分配一个大切片来降低GC触发频率,从而减少响应时间。Uber提出的方案则是根据live heap的大小动态调整GOGC值,以避免OOM并提高内存利用率。在一定程度上,这些Go社区方案缓解了Go GC调优的问题,但由于它们不是官方方案,因此在使用上有着较高的门槛。
Go 1.19版本在runtime/debug包中添加了一个名为SetMemoryLimit的函数以及GOMEMLIMIT环境变量,通过它们任意一个都可以设定Go应用的Memory limit。
一旦设定了Memory limit,当Go堆大小达到“Memory limit减去非堆内存后的值”时,一轮GC会被触发。即便你手动关闭了GC(GOGC=off),GC亦会被触发。Memory limit虽然可以在多数场景下帮你避免OOM触发,但我们也要注意:Soft memory limit不保证不会出现oom-killed!
这也很好理解。如果live heap object到达limit了,说明你的应用内存资源真的不够了,是时候扩物理内存条资源了,这是GC无论如何都无法解决的问题。
但是,如果一个Go应用的live heap object超过了Soft memory limit却未被kill,那么GC会被持续触发。为了保证这种情况下业务依然能正常进行,Soft memory limit方案保证GC最多只会使用50%的CPU算力,以此保证业务处理依然能够得到CPU资源。
对于GC触发频率高,需要降低的情况,Soft memory limit的方案就是关闭GC(GOGC=off)。只有当堆内存到达Soft memory limit值时,GC才会触发,这可以提升CPU利用率。不过,有一种情况发生时,Go官方的GC指南不建议你这么做,那就是当你的Go程序与其他程序共享一些有限的内存时。在这种情况下,你只需保留内存限制并将其设置为一个较小的合理值即可,因为这样做可能有助于抑制不良的瞬时行为。
那么多大的值是合理的Soft memory limit值呢?在Go服务独占容器资源时,建议你留下额外的5-10%的空间,以考虑Go运行时不知道的内存来源。Uber在其博客中设定的limit为资源上限的70%,这也是一个不错的经验值。
支持PGO优化
PGO(Profile Guided Optimization)是一种编译器优化技术,利用程序的运行时Profile数据来优化代码的执行路径,从而提高性能。以下是Go语言不同版本中对PGO的支持情况:
- Go 1.20版本引入了PGO的技术预览版。
- Go 1.21版本中,PGO正式GA。如果main包目录下包含default.pgo文件,Go 1.21编译器在编译二进制文件时,就会默认开启基于default.pgo中数据的PGO优化。优化带来的性能提升因程序而异,一般是2%~7%。同时,Go 1.21编译器自身就是基于PGO优化过的,编译速度提升了约6%。
- Go 1.22版本继续在编译上优化PGO,基于PGO的构建可以比以前版本实现更高比例的调用去虚拟化(Devirtualize)。在Go 1.22中,官⽅给出PGO带来的性能提升数字是2%~14%,这应该是基于Google内部一些典型的Go程序测算出来的。
注:在Go编译器中,Devirtualize是一种编译优化技术,旨在消除“虚函数”调用的开销。“虚函数”是指在面向对象编程中,通过基类指针或引用调用的函数。在Go中所谓虚函数调用指的就是通过接口类型变量进行的方法调用。由于是动态调用,基于接口的方法调用需要在运行时进行查找和分派,这可能导致一定的性能损失。
限制对linkname的使用
在Go语言中,//go:linkname指令可以用来链接到标准库或其他包中的未导出符号。如果我们想访问runtime包中的一个未导出函数,例如runtime.nanotime这个函数返回当前时间的纳秒数,那我们可以通过//go:linkname指令链接到这个符号。下面我来演示一下:
// go-evolution/compiler-and-runtime/golinkname/main.go
package main
import (
"fmt"
_ "unsafe" // 必须导入 unsafe 包以使用 //go:linkname
)
// 声明符号链接
//
//go:linkname nanotime runtime.nanotime
func nanotime() int64
func main() {
// 调用未导出的 runtime.nanotime 函数
fmt.Println("Current time in nanoseconds:", nanotime())
}
我们运行该示例:
这种做法一般不推荐,因为它可能导致程序不稳定,并且未来版本的Go可能会改变内部实现(比如nanotime被改名或被删除),破坏你的代码。
Go团队意识到了这种不规范的行为,于是在Go 1.23中明确了//go:linkname的使用规范。Go 1.23链接器现在禁止使用//go:linkname指令,来引用标准库中未标记有//go:linkname的内部符号,并且链接器也禁止从汇编代码中引用这些符号。
不过,为了向后兼容,在一些大型开源代码库中发现的存量//go:linkname用法仍然受支持。为此,Go在标准库和runtime库中为支持linkname的函数增加了//go:linkname标记,以上面示例中的runtime.nanotime为例,在Go 1.23中其源码注释如下:
// runtime/time_nofake.go
// Exported via linkname for use by time and internal/poll.
//
// Many external packages also linkname nanotime for a fast monotonic time.
// Such code should be updated to use:
//
// var start = time.Now() // at init time
//
// and then replace nanotime() with time.Since(start), which is equally fast.
//
// However, all the code linknaming nanotime is never going to go away.
// Do not remove or change the type signature.
// See go.dev/issue/67401.
//
//go:linkname nanotime
//go:nosplit
func nanotime() int64 {
return nanotime1()
}
对于没有标记//go:linkname的标准库内部符号,在外部通过go:linkname引用的操作都将默认被禁止。不过,考虑到调试和实验目的,你也可以通过使用-checklinkname=0这个链接器命令行选项来禁用这个检查。
基于Swiss Table的map运行时实现
Go 1.24版本在运行时方面实现了多个优化,包括采用基于Swiss Tables的原生map实现(#54766)。
Swiss Table 是由Google工程师于2017年开发的一种高效哈希表实现,旨在优化内存使用和提升性能,解决Google内部代码库中广泛使用std::unordered_map所面临的性能问题。目前,Swiss Table已被应用于多种编程语言,包括C++ Abseil库的flat_hash_map(可替换std::unordered_map)、Rust标准库Hashmap的默认实现等。在字节工程师的提案下,Go runtime团队决定替换原生map的底层实现,改为基于Swiss Table。
通过对Go 1.24rc1的实测发现,在大多数测试项中,新版基于Swiss Table的map的性能都有大幅提升,有些甚至接近50%!
改进的内部互斥锁实现
Go 1.24实现的另外一个重要的性能优化是runtime: improve scaling of lock2中的提案,旨在针对当前runtime.lock2实现的问题进行优化,具体的propsal在design/68578-mutex-spinbit.md文件中。下面,我简略说一下该优化的背景、方案原理以及取得的效果。
当前runtime.lock2的实现通过三态设计(未锁定、锁定、锁定且有等待线程),在高竞争情况下,多个线程反复轮询mutex的状态字,产生大量缓存一致性流量。每个轮询线程需要从内存中加载状态字,并在更新时触发缓存行失效,这导致性能大幅下降。而每次释放锁时,无论是否已有线程在轮询mutex状态字,都会尝试唤醒一个线程,这进一步增加了系统负载。
总之,现有的三态设计不能有效限制线程的忙等待行为。即使锁的临界区操作非常短,线程依然会因为抢占资源而竞争加剧。
新提案引入“spinbit”机制,扩展mutex状态字,增加一个"spinning"位,表示是否有线程处于忙等待状态。一个线程可以独占此位,在轮询状态字时拥有优先权。其他线程无需忙等待,直接进入休眠。同时提案优化了唤醒逻辑,当unlock2检测到已有线程正在忙等待时,不再唤醒休眠线程,从而减少不必要的线程切换和上下文切换。
目前该优化提供了基于futex和非futex系统调用的两个实现,基于futex的版本适用于Linux平台,通过精细控制休眠线程的列表,进一步减少竞争。非futex系统调用的实现则是通过使用原子操作同步的状态字来实现。状态字中使用独立的位分别表示锁定状态、休眠线程存在与否、忙等待标志等,并通过位操作和Xchg8原子操作,确保性能和线程安全。
新方案在高竞争状况下取得了显著的可扩展性提升,新实现的spinbit机制能维持性能稳定,而不是像现有实现那样,随线程数增加而急剧下降。基准测试表明,在GOMAXPROCS=20时,性能提升达3倍。大部分线程可以按设计预期那样,直接休眠而非忙等待,减少了电力消耗和处理器资源占用。同时,通过对休眠线程的显式管理,可实现有针对性的唤醒,降低线程长期休眠的风险(避免饿死)。
上述的基于Swiss table的map实现以及lock2优化是实验特性,但都是默认生效的。在Go 1.24中,你可以在构建阶段,通过显式设置GOEXPERIMENT=noswissmap和GOEXPERIMENT=nospinbitmutex关闭这两个实验特性。
支持WASI
Go从1.11版本就开始支持将Go源码编译为wasm二进制文件,并在支持wasm的浏览器环境中运行。
不过,WebAssembly绝不仅仅被设计为仅限于在Web浏览器中运行,核心的WebAssembly语言是独立于其周围环境的,WebAssembly完全可以通过API与外部世界互动。在Web上,它自然使用浏览器提供的现有Web API。然而,在浏览器之外,之前还没有一套标准的API可以让WebAssembly程序使用。这使得创建真正可移植的非Web WebAssembly程序变得困难。
WebAssembly System Interface(WASI)是填补这一空白的一个倡议,它有一套干净的API,可以由多个引擎在多个平台上实现,并且不依赖于浏览器的功能(尽管它们仍然可以在浏览器中运行)。
Go 1.21版本增加了对WASI的支持,初期先支持WASI Preview1版本,之后会支持WASI Preview2版本,直至最终WASI API版本发布!目前我们可以使用GOOS=wasip1 GOARCH=wasm将Go源码编译为支持WASI的wasm程序,下面是一个例子:
下载Go 1.21及之后版本后,可以执行下面命令将main.go编译为wasm程序:
开源的wasm运行时有很多,wazero是目前比较火且使用纯Go实现的wasm运行时程序,安装wazero后,可以用来执行上面编译出来的main.wasm:
Go 1.24版本又新增了一个编译器指示符go:wasmexport,用于向编译器发出信号,表明某个函数应该在生成的wasm二进制文件中导出。该指示符只能在GOOS=wasip1时使用,否则会导致编译失败。
其中name是导出函数的名称,该参数是必需的。注意:该指示符只能用于函数,不能用于方法。
小结
这一节,我们讲了Go语言1.19到1.24版本中,语言语法以及编译器和运行时的重要更新。
在语言语法方面,包括切片与数组转换、包初始化顺序算法、loopvar语义修正、自定义函数迭代器支持,以及带类型参数的类型别名等特性的增添与完善。在编译器与运行时上,引入Soft memory limit,对PGO优化逐步推进,规范linkname的使用,基于Swiss Table优化map,以及互斥锁实现,还增加了对WASI的支持与相关编译器指示符,推动Go语言不断发展。
这一节的内容就到这里,我是Tony Bai,我们下一节见。