玩转Go语言I O:掌握Reader与Writer的使用技巧
你好,我是Tony Bai。
在第2讲中,我们学习了Go语言面向工程的设计哲学,Go的设计者们希望:Go不仅是一门语言,更是一种更好的软件开发方式和编程环境。于是,Go提供了一个“开箱即用”的标准库,这也是Go在早期广受开发者青睐的重要原因之一。
Go语言的标准库功能强大,涵盖了很多常用的功能,如字符串处理、文件操作、日志打印、网络通信、Web编程、并发编程、数据编解码以及加解密等。此外,Go团队发布的Go1兼容性承诺也包含了对标准库包的覆盖,这有助于保持代码的稳定性和兼容性,让开发人员编写代码时更专注于解决实际问题。
在众多标准库包中,io包尤为特殊,因为它定义了整个Go语言的I/O模型,并通过定义Reader和Writer接口,提供了统一的I/O抽象。这使得不同数据源和输出目标可以一致的方式交互,解耦具体实现与使用逻辑。开发者可以轻松替换输入输出实现,并通过组合构建复杂的I/O逻辑。
这一节,我们就来系统聊聊Go语言I/O模型,以及io包中Reader与Writer的使用技巧,帮助你更好地理解和运用Go I/O模型。
Go I/O的核心抽象
Go标准库的io包通过两个核心接口:Writer和Reader,奠定了Go I/O模型的基础,它们也是Go语言中最重要的抽象之一。
下面是io包中Writer和Reader接口的定义:
//$GOROOT/src/io/io.go
type Writer interface {
Write(p []byte) (n int, err error)
}
type Reader interface {
Read(p []byte) (n int, err error)
}
我们看到:Writer接口对写入数据的操作进行了抽象,它只有一个Write方法,该方法接受一个字节切片作为参数,并将字节切片中的数据写入到实现Writer接口的不同目标中(比如文件、网络连接、内存等),并返回写入的字节数和可能的错误。
Reader接口则对读取数据的操作进行了抽象,它只有一个Read方法,该方法可以从实现了Reader接口的不同数据源(比如文件、网络连接、内存等)中读取数据,并将数据存入其字节切片类型的参数中,最后返回读取的字节数和可能的错误。
io包的这种抽象提供了灵活的、可组合的方式来处理I/O操作,使得不同类型的数据源和数据接收方可以通过相同的接口进行数据交互。当我们要向Go代码提供数据源时,只需将其封装为Reader接口的实现,也就是上面的Read方法即可,这样就可以使用Go标准库以及第三方库中已有的支持从Reader读取数据的包。而当我们要向某个目标写入数据时,就将其封装为Writer,即上面的Write方法,这样就可以使用Go标准库以及第三方库中已有的所有支持向Writer写入数据的包。
Go标准库提供了多种封装好的Reader和Writer的实现,用于处理不同的数据源和目标,你可以根据需求选择合适的。
- os.File:用于从文件读取和写入文件的Reader和Writer实现。
- bytes.Buffer:用于在内存中读取和写入数据的Reader和Writer实现。
- strings.Reader:用于从字符串中读取数据的Reader实现。
- bufio.Reader:提供了带缓冲区的读取功能,可以提高读取效率。
- bufio.Writer:提供了带缓冲区的写入功能,可以减少写入操作次数,提高写入效率。
- compress/gzip包中的gzip.Reader和gzip.Writer:用于读取和写入gzip压缩文件的Reader和Writer实现。
- encoding/json包中的json.Decoder和json.Encoder:用于读取和写入JSON格式数据的Reader和Writer实现。
- net/http包中的http.Request.Body和http.Response.Body:用于读取HTTP请求和响应的Reader实现。
- net.TCPConn和net.UDPConn:用于读取和写入TCP和UDP网络连接的Reader和Writer实现。
现在记不住没关系,我们后续也会使用到其中一些Reader和Writer的实现,帮助你理解记忆。下面,我们先来看看如何使用Reader读取数据。
从Reader读取数据
io包提供了多种函数用于从Reader读取数据,其中最常用的函数是ReadFull和ReadAll。我们先来看看ReadFull函数,它的函数原型如下:
ReadFull函数会从Reader类型的参数r中精确地读取len(buf)个字节到buf中,并返回读取到的字节数和可能的错误。如果读取的数据长度小于len(buf),那么它会阻塞直到读满或出现错误(比如EOF或unexpected EOF)。下面是ReadFull函数的使用示例,我们看看在不同情况下ReadFull读取的数据和返回的错误码情况:
//io/readfull.go
func main() {
// 1. 正常读取
reader := strings.NewReader("Hello, World!") // length = 13
buf := make([]byte, 10) // 创建大小为10的缓冲区
n, err := io.ReadFull(reader, buf)
fmt.Printf("正常读取:Read %d bytes: %s, error=%v\n", n, string(buf), err)
// 2. 恰好读完
reader1 := strings.NewReader("Hello, World!") // length = 13
buf1 := make([]byte, 13)
n, err = io.ReadFull(reader1, buf1)
fmt.Printf("恰好读完:Read %d bytes: %s, error=%v\n", n, string(buf1), err)
// 3. 读取不足
reader2 := strings.NewReader("Hello, World!") // length = 13
buf2 := make([]byte, 15) // 创建大小为15的缓冲区
n, err = io.ReadFull(reader2, buf2)
fmt.Printf("读取不足:Read %d bytes: %s, error=%v\n", n, string(buf2), err)
// 4. 未读到任何数据
reader3 := strings.NewReader("") // length = 0
buf3 := make([]byte, 15) // 创建大小为15的缓冲区
n, err = io.ReadFull(reader3, buf3)
fmt.Printf("未读到任何数据:Read %d bytes: %s, error=%v\n", n, string(buf3), err)
}
上述示例的运行结果如下:
$go run readfull.go
正常读取:Read 10 bytes: Hello, Wor, error=<nil>
恰好读完:Read 13 bytes: Hello, World!, error=<nil>
读取不足:Read 13 bytes: Hello, World!, error=unexpected EOF
未读到任何数据:Read 0 bytes: , error=EOF
ReadAll函数则意如其名,它会尝试将实现了Reader接口的数据源中所有数据都读取出来,其原型如下:
和ReadFull函数不同,ReadAll不需要调用者传入用于存储读出数据的Buffer,因为ReadAll和开发者都无法知道数据源中究竟有多少数据。下面是 ReadAll函数使用的示例:
// io/readall.go
func main() {
// 1. 正常读取
reader := strings.NewReader("Hello, World!") // length = 13
buf, err := io.ReadAll(reader)
fmt.Printf("正常读取:Read %d bytes: %s, error=%v\n", len(buf), string(buf), err)
// 2. 未读到任何数据
reader1 := strings.NewReader("") // length = 0
buf1, err := io.ReadAll(reader1)
fmt.Printf("未读到任何数据:Read %d bytes: %s, error=%v\n", len(buf1), string(buf1), err)
}
该示例的运行结果如下:
$go run readall.go
正常读取:Read 13 bytes: Hello, World!, error=<nil>
未读到任何数据:Read 0 bytes: , error=<nil>
接下来,我们再来看看如何向Writer写入数据。和从Reader读取数据一样,它也是构建复杂I/O操作逻辑的基础。
向Writer写入数据
在向Writer写入数据方面,io包提供的可以“直接”写Writer的函数只有WriteString这一个,像Copy/CopyBuffer/CopyN等在Reader和Writer之间进行数据传递的函数我们会在后面介绍。Go标准库的其他包,比如fmt,倒是提供了其它一些可以直接写Writer的函数,比如Fprint系列函数。
我们先来看看可以直接写Writer的WriteString函数,它的函数原型如下:
下面是WriteString函数的一个使用示例:
// io/writestring.go
func main() {
writer := os.Stdout
data := "Hello, World!\n"
n, err := io.WriteString(writer, data)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("Written %d bytes\n", n)
}
这里os.Stdout是一个os.File类型的指针,它实现了io.Writer接口,可以作为参数传给WriteString。WriteString将一个字符串变量data的内容直接写入Writer,即输出到控制台标准输出上,然后返回写入Writer的字节数和相应的错误值。
上述示例运行结果如下:
fmt包提供的Fprint系列函数也支持直接Writer写入数据,其中的Fprintf还可以采用格式化写入方式,下面是这一系列的三个函数的原型:
// $GOROOT/src/fmt/print.go
func Fprint(w io.Writer, a ...any) (n int, err error)
func Fprintf(w io.Writer, format string, a ...any) (n int, err error)
func Fprintln(w io.Writer, a ...any) (n int, err error)
接着,我们来实现一个等价于上面WriteString的示例:
// io/fprintf.go
func main() {
writer := os.Stdout
data := "Hello, World!"
n, err := fmt.Fprint(writer, data, "\n")
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("Fprint: written %d bytes\n", n)
n, err = fmt.Fprintf(writer, "%s\n", data)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("Fprintf: written %d bytes\n", n)
n, err = fmt.Fprintln(writer, data)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("Fprintln: written %d bytes\n", n)
}
我们分别用Fprint、Fprintf和Fprintln实现了与WriteString等同的功能,该示例输出如下:
$go run fprintf.go
Hello, World!
Fprint: written 14 bytes
Hello, World!
Fprintf: written 14 bytes
Hello, World!
Fprintln: written 14 bytes
Reader与Writer间的数据传递
通过Reader和Writer两个抽象类型,我们能够灵活进行复杂的数据传递。常见的数据传递场景包括:
- Reader -> Writer
- Reader -> 多个Writer
- 多个Reader -> Writer
- 多个Reader -> 多个Writer
- Writer -> Reader
接下来,我们就逐一看看如果利用io包实现上述的数据传递场景。
Reader -> Writer
将数据从一个Reader读取出来,然后写入一个Writer中,这是最常见的数据传递场景。io包提供了Copy函数,可以十分方便地实现这个功能。下面是Copy函数的原型:
我们用Copy函数将一个数据源中的字符串数据“传递”到标准输出上:
// io/reader2writer.go
func main() {
writer := os.Stdout
data := "Hello, World!\n"
reader := strings.NewReader(data)
// reader -> writer
n, err := io.Copy(writer, reader)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("written %d bytes\n", n)
}
这个示例的输出结果如下:
Reader -> 多个Writer
有时候,我们需要将一个数据源中的数据传递给多个目标,比如将一个数据源中的字符串数据写入到标准输出的同时,也写一份到特定的文件中。io包提供的MultiWriter可以帮助我们实现这个场景功能。io.MultiWriter的函数原型如下:
MultiWriter函数可以将多个Writer“整合”为一个Writer,然后我们再通过Copy函数可以将Reader数据传递给这个“整合”后的Writer,后者再将数据复制分发给其“整合”的多个Writer,就像如下的示意图:
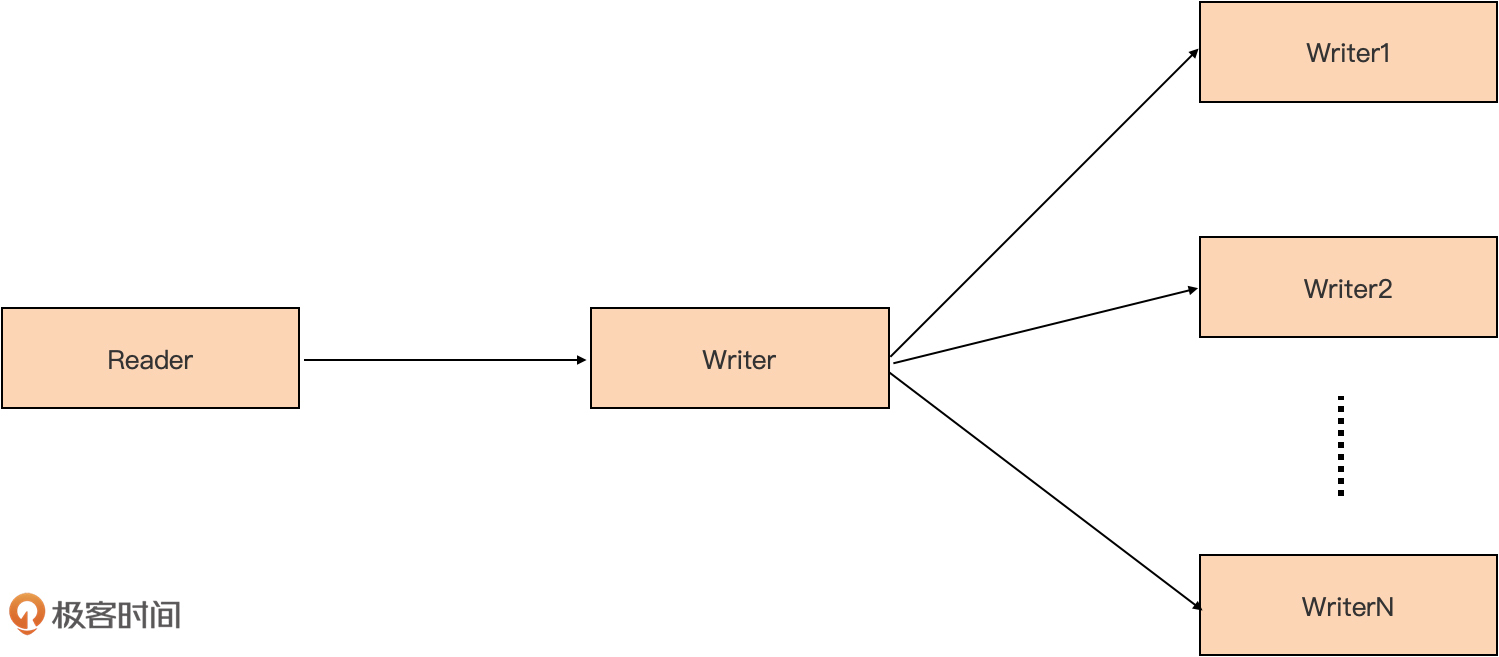
下面是该示例的实现代码:
//io/reader2multiwriter.go
func main() {
data := "Hello, World!\n"
reader := strings.NewReader(data)
writer1 := os.Stdout
writer2, err := os.Create("writer2.txt")
if err != nil {
fmt.Println("创建目标文件错误:", err)
return
}
defer writer2.Close()
writer := io.MultiWriter(writer1, writer2)
// reader -> multi writer
n, err := io.Copy(writer, reader)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("written %d bytes\n", n)
}
这个示例有两个写入目标:writer1代表控制体标准输出,writer2则代表writer2.txt文件。我们通过io.MultiWriter函数将它们整合为一个writer变量,然后通过io.Copy函数实现了从数据源读取数据并写入writer变量的功能。该示例的运行结果如下:
我们看到,“Hello, World!”被同时成功写到标准输出与文件“writer2.txt”中了。
多个Reader -> Writer
日常编码中可能有这样的场景,即将位于多个Reader中的数据片段,按顺序整合为一个Reader,再写入Writer,如下图所示:
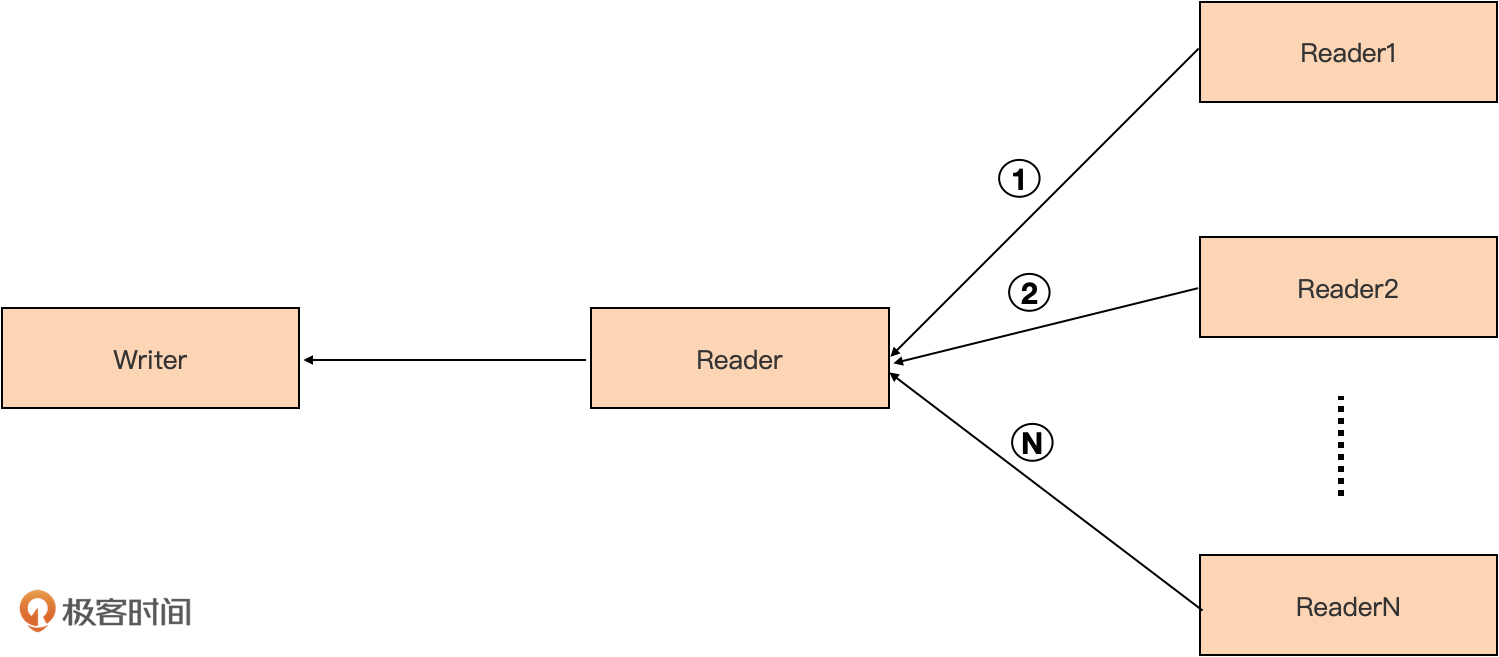
io包提供了MultiReader函数可以帮助我们按顺序将多个Reader“整合”为一个Reader,MultiReader函数的原型如下:
MultiReader函数将多个输入Reader串联在一起,形成一个逻辑上的连续数据流。当读取这个Reader时,它会按顺序从每个输入Reader中读取数据,直到所有输入Reader都返回了EOF。如果在读取过程中任何一个输入Reader返回了错误,Read函数会立即返回该错误,并且后续的读取操作将被中止。这种机制使得我们可以方便地将多个输入数据源串联起来,以便按照顺序连续读取数据,简化了顺序处理多个数据源的任务。
下面是一个使用MultiReader进行多Reader读取的示例:
//io/multireader2writer.go
func main() {
reader1 := strings.NewReader("Hello, ")
reader2 := strings.NewReader("World!\n")
reader3, err := os.Open("reader3.txt")
if err != nil {
fmt.Println("Error:", err)
return
}
defer reader3.Close()
multiReader := io.MultiReader(reader1, reader2, reader3)
// 将合并后的内容写到标准输出
writer := os.Stdout
_, err = io.Copy(writer, multiReader)
if err != nil {
fmt.Println("Error:", err)
return
}
}
在这个示例中,通过MultiReader整合后的multiReader被读取数据并写入os.Stdout代表的writer。multiReader会依次从代表内存数据的reader1和reader2中读取数据,再从代表文件数据的reader3中,将数据从reader3.txt文件中读出。下面是示例运行的结果:
$cat reader3.txt
Welcome to the example.
$go run multireader2writer.go
Hello, World!
Welcome to the example.
Writer -> Reader
我们再来看最后一种复杂的I/O操作场景。有时候,我们需要在某个函数中对输入的内容进行拦截处理,并将处理后的内容再作为一个数据源,即封装为一个Reader供后续程序使用,如下图所示:

io包提供了Pipe函数,可以用于实现拦截处理的Writer,并将处理后的内容重新包装为Reader,就像真实世界的一个管道那样:

io.Pipe函数的原型如下:
io.Pipe函数在内存中创建一个同步的数据管道,返回一个io.Reader和一个io.Writer,用于在不同的goroutine之间传递数据。即通过将io.Pipe返回的Writer传递给一个goroutine作为数据写入操作,而将返回的Reader传递给另一个goroutine作为数据读取操作。
我们经常连接这些管道来构建数据流水线,形成流式处理机制。这是一种非常好用的数据处理模式,示意图如下:
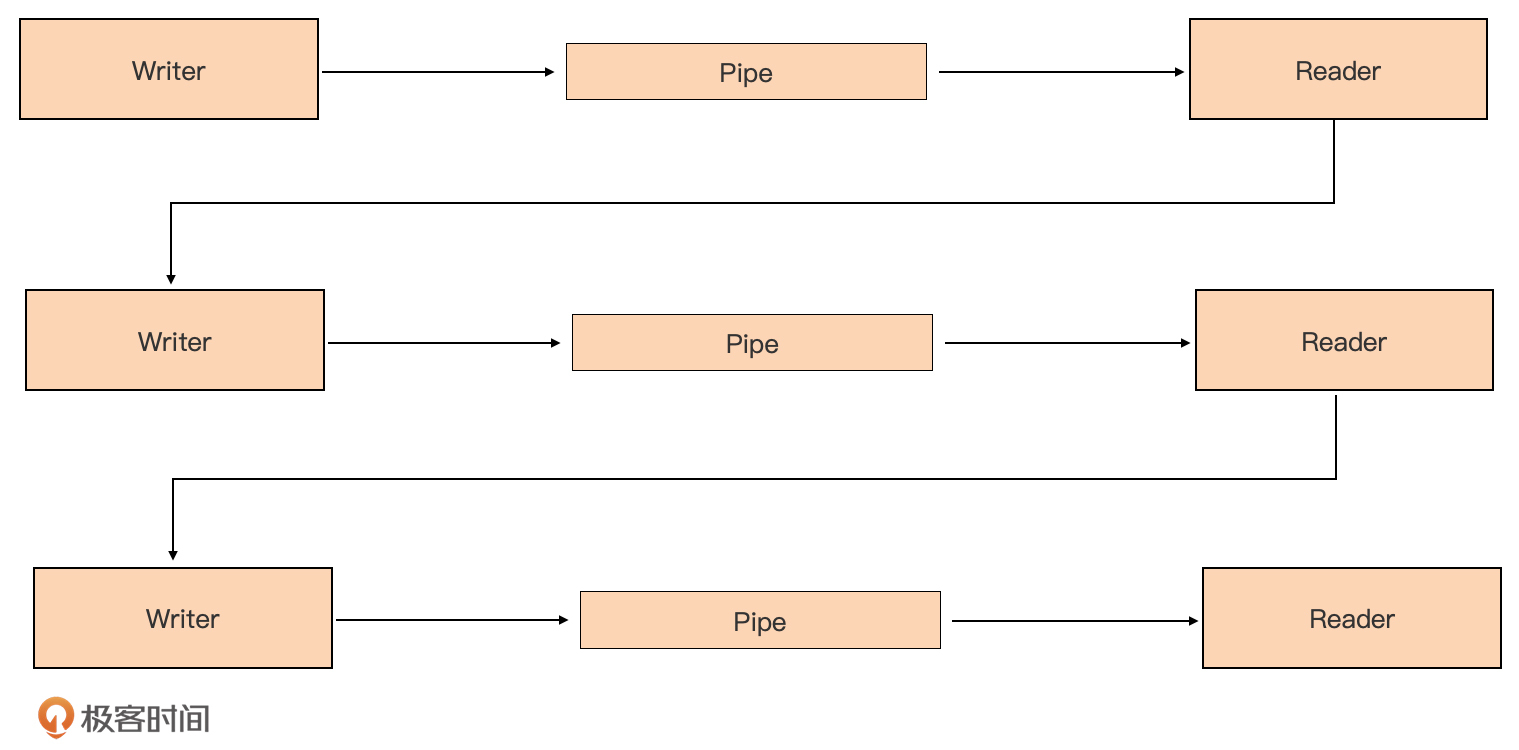
下面我们就用Pipe函数来构建一个简单的数据处理流水线:
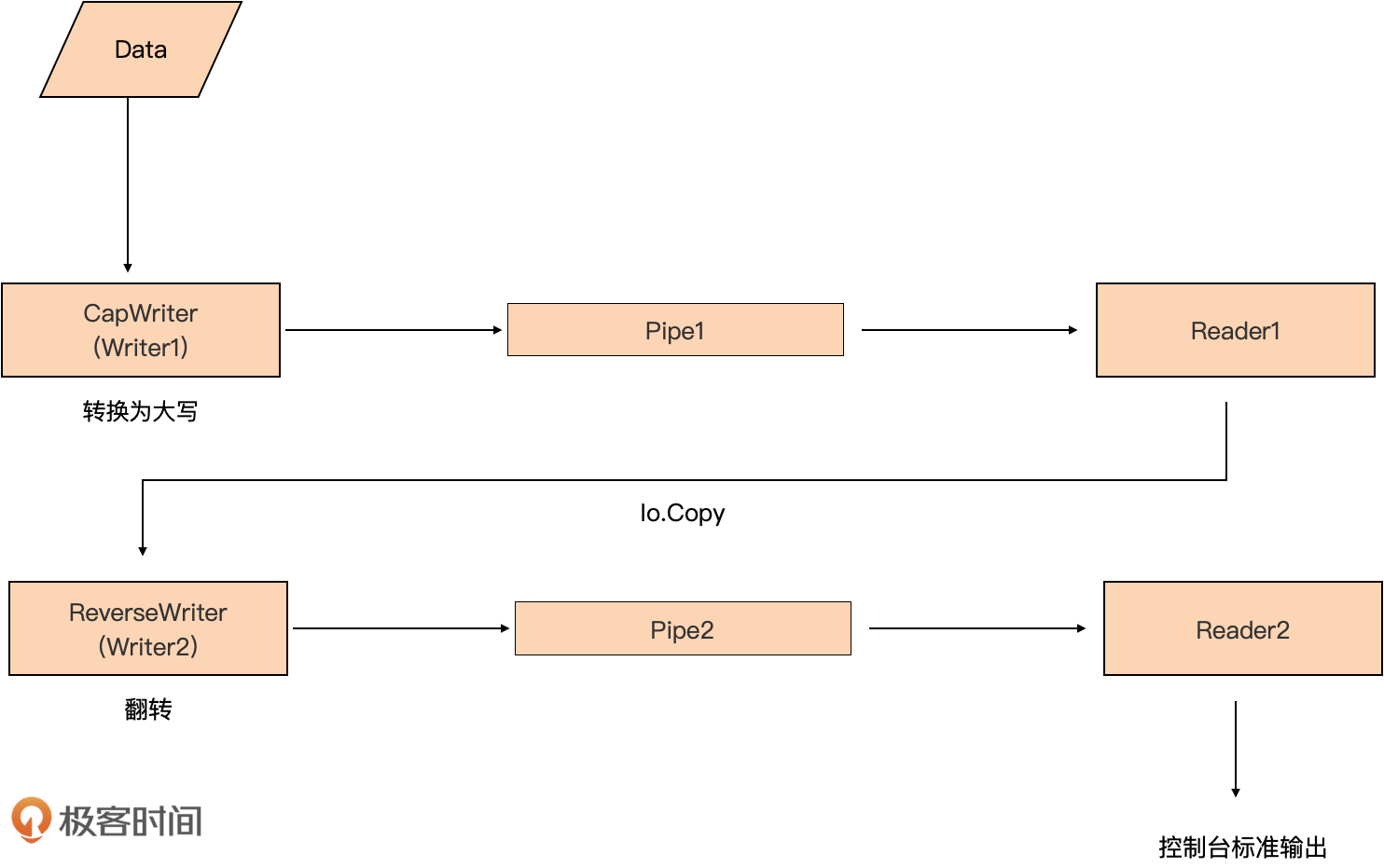
下面是示例代码:
// io/writer2reader.go
type CapWriter struct {
writer io.Writer
}
func NewCapWriter(w io.Writer) *CapWriter {
return &CapWriter{writer: w}
}
func (cw *CapWriter) Write(p []byte) (n int, err error) {
// 将写入的数据转换为大写
upper := strings.ToUpper(string(p))
// 将转换后的数据写入底层的 Writer
return cw.writer.Write([]byte(upper))
}
type ReverseWriter struct {
writer io.Writer
}
func NewReverseWriter(w io.Writer) *ReverseWriter {
return &ReverseWriter{writer: w}
}
func (rw *ReverseWriter) Write(p []byte) (n int, err error) {
// 将写入的数据进行翻转
reversed := reverseString(string(p))
// 将翻转后的数据写入底层的 Writer
return rw.writer.Write([]byte(reversed))
}
func reverseString(s string) string {
runes := []rune(s)
n := len(runes)
for i := 0; i < n/2; i++ {
runes[i], runes[n-1-i] = runes[n-1-i], runes[i]
}
return string(runes)
}
func main() {
// 创建第一个 Pipe,获取对应的 Reader 和 Writer
reader1, writer1 := io.Pipe()
// 创建 CapWriter,将其与第一个 Pipe 返回的 Writer 整合
capWriter := NewCapWriter(writer1)
// 创建第二个 Pipe,获取对应的 Reader 和 Writer
reader2, writer2 := io.Pipe()
// 创建 ReverseWriter,将其与第二个 Pipe 返回的 Writer 整合
reverseWriter := NewReverseWriter(writer2)
// 启动一个 goroutine,向 CapWriter 写入数据
go func() {
defer writer1.Close()
for i := 0; i < 5; i++ {
data := []byte("hello, world!\n")
_, err := capWriter.Write(data)
if err != nil {
fmt.Println("Error:", err)
return
}
time.Sleep(time.Second) //每秒写入一次
}
}()
// 启动另一个 goroutine,从第二个 Pipe 返回的 Reader 中读取数据并处理
go func() {
defer writer2.Close()
io.Copy(reverseWriter, reader1)
}()
// 从第二个 Pipe 返回的 Reader 中读取翻转后的数据并处理
n, err := io.Copy(os.Stdout, reader2)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("\nRead %d bytes\n", n)
// 关闭 Reader2
err = reader2.Close()
if err != nil {
fmt.Println("Error:", err)
return
}
}
在上述示例中,我们创建了两个Pipe:一个用于将数据转换为大写的CapWriter,另一个用于将数据翻转的ReverseWriter。我们在两个goroutine中同时操作这两个Pipe,实现了流水线式的处理。在第一个goroutine中,我们将数据写入CapWriter;在第二个goroutine中,我们从第一个Pipe返回的Reader中读取数据,并将数据翻转后写入ReverseWriter。最后,在主goroutine中,我们从第二个Pipe返回的Reader中读取翻转后的数据,并输出到控制台上。
下面是示例的运行结果:
$go run writer2reader.go
!DLROW ,OLLEH
!DLROW ,OLLEH
!DLROW ,OLLEH
!DLROW ,OLLEH
!DLROW ,OLLEH
Read 70 bytes
小结
这一节,我们详细探讨了Go语言中的I/O模型,重点介绍了io包中的核心抽象:Reader和Writer接口。这两个抽象类型为数据的输入和输出提供了一种统一的操作方式,使得不同的数据源和目标能够灵活交互。
我们还讨论了多种常见的数据传递场景,包括从Reader到Writer、多个Reader到Writer、多个Reader到多个Writer,以及Writer到Reader的操作。通过示例代码,我们知道了使用io包提供的函数(如MultiWriter、MultiReader、Pipe等)和将这些接口灵活组合高效处理数据的方法,相信你也能从中感受到Go I/O模型的强大与灵活!
思考题
学完之后,建议你回顾一下自己工作中的代码,寻找可以改造为Reader和Writer的地方。动手实践一下,看看这些抽象如何帮助你提升代码的灵活性和可维护性。
如果你有新的想法,欢迎留言与我分享。我是Tony Bai,我们下一节见。