一个Go纯计算逻辑调优的故事
你好,我是Tony Bai。今天我想和你分享一个Go纯计算逻辑调优的故事。
在开篇词中我提到过,Go语言是生产力与性能的最佳结合。Go语言提供了足够快的运行效率,可以满足大多数场景下的性能需求,但这并不意味着Go的执行性能已经到了“天花板”。近期国外开发者Ben Dicken做了一个语言性能测试,对比了十多种主流语言执行10亿次循环(一个双层循环:1万 * 10 万)的纯计算逻辑速度。下面是这项测试的结果示意图:
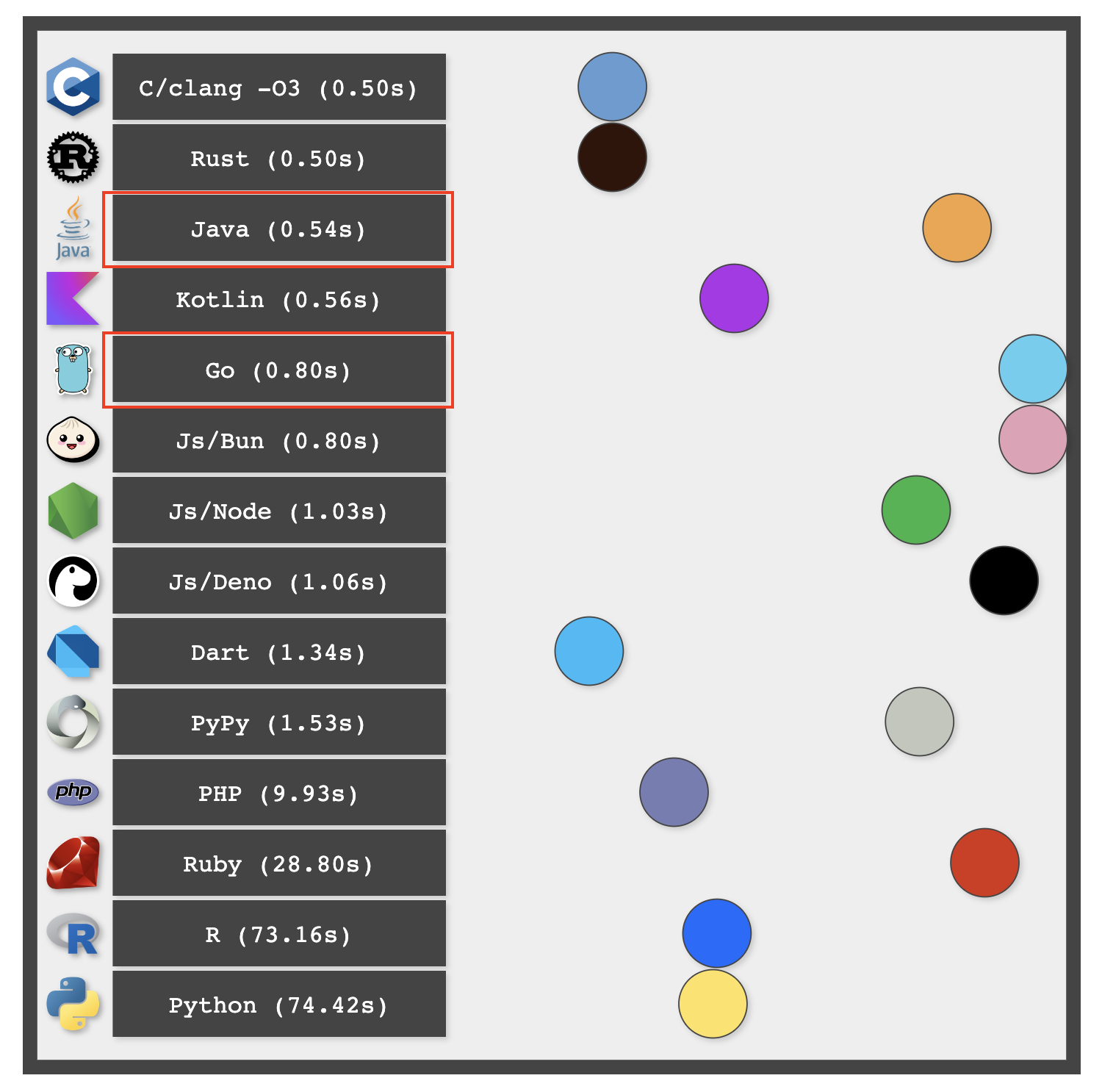
我们看到,在这项测试中,Go的表现不仅远不及NonGC的C/Rust,甚至还落后于同为GC语言的Java。这一结果可能让许多Go开发者感到意外,Go通常被认为是轻量级的高性能语言,然而实际的测试结果却揭示了其在纯计算逻辑运行速率上仍有优化空间。
那在这项测试中,为什么Go的表现不及预期?我们又该如何进一步优化?这篇加餐,我们就来探讨一下可能的原因和具体的优化方案,希望能为你提供更多的思考。
为了更直观地呈现整个过程,我们先要在自己的环境重现该性能问题。
重现性能问题
下面是此项测试的原作者给出的Go测试程序:
// why-go-sucks/billion-loops/go/code.go
package main
import (
"fmt"
"math/rand"
"os"
"strconv"
)
func main() {
input, e := strconv.Atoi(os.Args[1]) // Get an input number from the command line
if e != nil {
panic(e)
}
u := int32(input)
r := int32(rand.Intn(10000)) // Get a random number 0 <= r < 10k
var a [10000]int32 // Array of 10k elements initialized to 0
for i := int32(0); i < 10000; i++ { // 10k outer loop iterations
for j := int32(0); j < 100000; j++ { // 100k inner loop iterations, per outer loop iteration
a[i] = a[i] + j%u // Simple sum
}
a[i] += r // Add a random value to each element in array
}
fmt.Println(a[r]) // Print out a single element from the array
}
这段代码通过命令行参数获取一个整数,然后生成一个随机数,接着通过两层循环对一个数组的每个元素进行累加,最终输出该数组中以随机数为下标对应的数组元素的值。
接下来,我们再来看看“竞争对手”的测试代码。首先是C测试代码:
// why-go-sucks/billion-loops/c/code.c
#include "stdio.h"
#include "stdlib.h"
#include "stdint.h"
int main (int argc, char** argv) {
int u = atoi(argv[1]); // Get an input number from the command line
int r = rand() % 10000; // Get a random integer 0 <= r < 10k
int32_t a[10000] = {0}; // Array of 10k elements initialized to 0
for (int i = 0; i < 10000; i++) { // 10k outer loop iterations
for (int j = 0; j < 100000; j++) { // 100k inner loop iterations, per outer loop iteration
a[i] = a[i] + j%u; // Simple sum
}
a[i] += r; // Add a random value to each element in array
}
printf("%d\n", a[r]); // Print out a single element from the array
}
然后是Java的测试代码:
// why-go-sucks/billion-loops/java/code.java
package jvm;
import java.util.Random;
public class code {
public static void main(String[] args) {
var u = Integer.parseInt(args[0]); // Get an input number from the command line
var r = new Random().nextInt(10000); // Get a random number 0 <= r < 10k
var a = new int[10000]; // Array of 10k elements initialized to 0
for (var i = 0; i < 10000; i++) { // 10k outer loop iterations
for (var j = 0; j < 100000; j++) { // 100k inner loop iterations, per outer loop iteration
a[i] = a[i] + j % u; // Simple sum
}
a[i] += r; // Add a random value to each element in array
}
System.out.println(a[r]); // Print out a single element from the array
}
}
你可能不熟悉C或Java,但从代码的形式上来看,C、Java与Go的代码确实处于“同等条件”。它们不仅在相同的硬件和软件环境中运行,还采用了相同的计算逻辑和算法,在输入参数处理等方面也具有相似性。
为了确认一下原作者的测试结果,我在一台阿里云ECS上(AMD64,8C32G,CentOS 7.9),对上面三个程序进行了测试(使用time命令测量计算耗时),得到一个基线结果。我的环境下,C、Java和Go的编译器版本如下:
$go version
go version go1.23.0 linux/amd64
$java -version
openjdk version "17.0.9" 2023-10-17 LTS
OpenJDK Runtime Environment Zulu17.46+19-CA (build 17.0.9+8-LTS)
OpenJDK 64-Bit Server VM Zulu17.46+19-CA (build 17.0.9+8-LTS, mixed mode, sharing)
$gcc -v
使用内建 specs。
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
目标:x86_64-redhat-linux
配置为:../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix --enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu --enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array --disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install --with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install --enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux
线程模型:posix
gcc 版本 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
测试步骤与结果如下:
Go代码测试:
$cd why-go-sucks/billion-loops/go
$go build -o code code.go
$time ./code 10
456953
real 0m3.766s
user 0m3.767s
sys 0m0.007s
C代码测试:
$cd why-go-sucks/billion-loops/c
$gcc -O3 -std=c99 -o code code.c
$time ./code 10
459383
real 0m3.005s
user 0m3.005s
sys 0m0.000s
Java代码测试:
$javac -d . code.java
$time java -cp . jvm.code 10
456181
real 0m3.105s
user 0m3.092s
sys 0m0.027s
我们可以从测试结果中看到(基于real时间):采用-O3优化的C代码最快,Java落后一个身位,Go则比C慢了25%,比Java慢了21%。
这里要补充说明的是,time命令的输出结果通常包含三个主要部分:real、user和sys。
- real是从命令开始执行到结束所经过的实际时间(墙钟时间),我们以这个指标为准。
- user是程序在用户模式下执行所消耗的CPU时间。
- sys则是程序在内核模式下执行所消耗的CPU时间(系统调用)。
如果总时间(real)略低于用户时间(user),表明程序可能在某些时刻被调度或等待,而不是持续占用CPU。这种情况可能是由于输入输出操作、等待资源等原因。如果real时间显著小于user时间,这种情况通常发生在并发程序中,其中多个线程或进程在不同的时间段执行,导致总的用户CPU时间远大于实际的墙钟时间。sys时间保持在较低数值,说明系统调用的频率较低,程序主要是执行计算而非进行大量的系统交互。
上述三种语言的代码都是常规代码,不是最优化的代码。我们还可以优化Go代码,让它的性能超过Java甚至是C,但不能忘了“同等条件”这个前提。Go采用的优化方法,其他语言(C、Java)也可以采用。
那么,在不改变“同等条件”的前提下,我们还能优化点啥?
同等条件前提下的优化尝试
我们从代码中找到了不会改变计算逻辑,但可能会影响代码执行性能的几个点,先从它们入手看看效果:
- 去除不必要的if判断
- 使用更快的rand实现
- 关闭边界检查
- 避免逃逸
下面是修改之后的Go代码:
// why-go-sucks/billion-loops/go/code_optimize.go
package main
import (
"fmt"
"math/rand"
"os"
"strconv"
)
func main() {
input, _ := strconv.Atoi(os.Args[1]) // Get an input number from the command line
u := int32(input)
r := int32(rand.Uint32() % 10000) // Use Uint32 for faster random number generation
var a [10000]int32 // Array of 10k elements initialized to 0
for i := int32(0); i < 10000; i++ { // 10k outer loop iterations
for j := int32(0); j < 100000; j++ { // 100k inner loop iterations, per outer loop iteration
a[i] = a[i] + j%u // Simple sum
}
a[i] += r // Add a random value to each element in array
}
z := a[r]
fmt.Println(z) // Print out a single element from the array
}
我们编译并运行一下测试:
$cd why-go-sucks/billion-loops/go
$go build -o code_optimize -gcflags '-B' code_optimize.go // 使用-B关闭边界检查
$time ./code_optimize 10
459443
real 0m3.761s
user 0m3.759s
sys 0m0.011s
对比一下最初的测试结果,这些“所谓的优化”并没有起到什么作用,优化前你估计也猜到了。因为除了边界检查,其他优化都没有处于循环执行的热路径之上。
注:rand.Uint32() % 10000的确要比rand.Intn(10000)快,我自己的benchmark结果是快约1倍。
罪魁祸首:Go编译器未能自动优化
那Go程序究竟慢在哪里呢?在“同等条件”下,我能想到的,只有在代码优化方面,Go编译器后端做得还不够,相较于GCC、Java等老牌编译器还有明显差距。
比如说,原先的代码在内层循环中频繁访问a[i],导致数组访问的读写操作较多(从内存加载a[i],更新值后写回)。GCC和Java编译器在后端很可能做了这样的优化:将数组元素累积到一个临时变量中,并在外层循环结束后写回数组,这样做可以减少内层循环中的内存读写操作,充分利用CPU缓存和寄存器,加速数据处理。因为数组要从内存或缓存读,而一个临时变量很大可能是从寄存器读,读取速度相差还是很大的。
如果我们手工在Go中实施这一优化,能达到什么效果呢?我们改一下最初版本的Go代码(code.go),新代码如下:
// why-go-sucks/billion-loops/go/code_local_var.go
package main
import (
"fmt"
"math/rand"
"os"
"strconv"
)
func main() {
input, e := strconv.Atoi(os.Args[1]) // Get an input number from the command line
if e != nil {
panic(e)
}
u := int32(input)
r := int32(rand.Intn(10000)) // Get a random number 0 <= r < 10k
var a [10000]int32 // Array of 10k elements initialized to 0
for i := int32(0); i < 10000; i++ { // 10k outer loop iterations
temp := a[i]
for j := int32(0); j < 100000; j++ { // 100k inner loop iterations, per outer loop iteration
temp += j % u // Simple sum
}
temp += r // Add a random value to each element in array
a[i] = temp
}
fmt.Println(a[r]) // Print out a single element from the array
}
然后我们编译并运行测试,结果如下:
$go build -o code_local_var code_local_var.go
$time ./code_local_var 10
459169
real 0m3.017s
user 0m3.017s
sys 0m0.007s
我们看到,测试结果直接就比Java略好一些了。显然Go编译器没有做这种优化,从code.go的汇编也大致可以看出来:
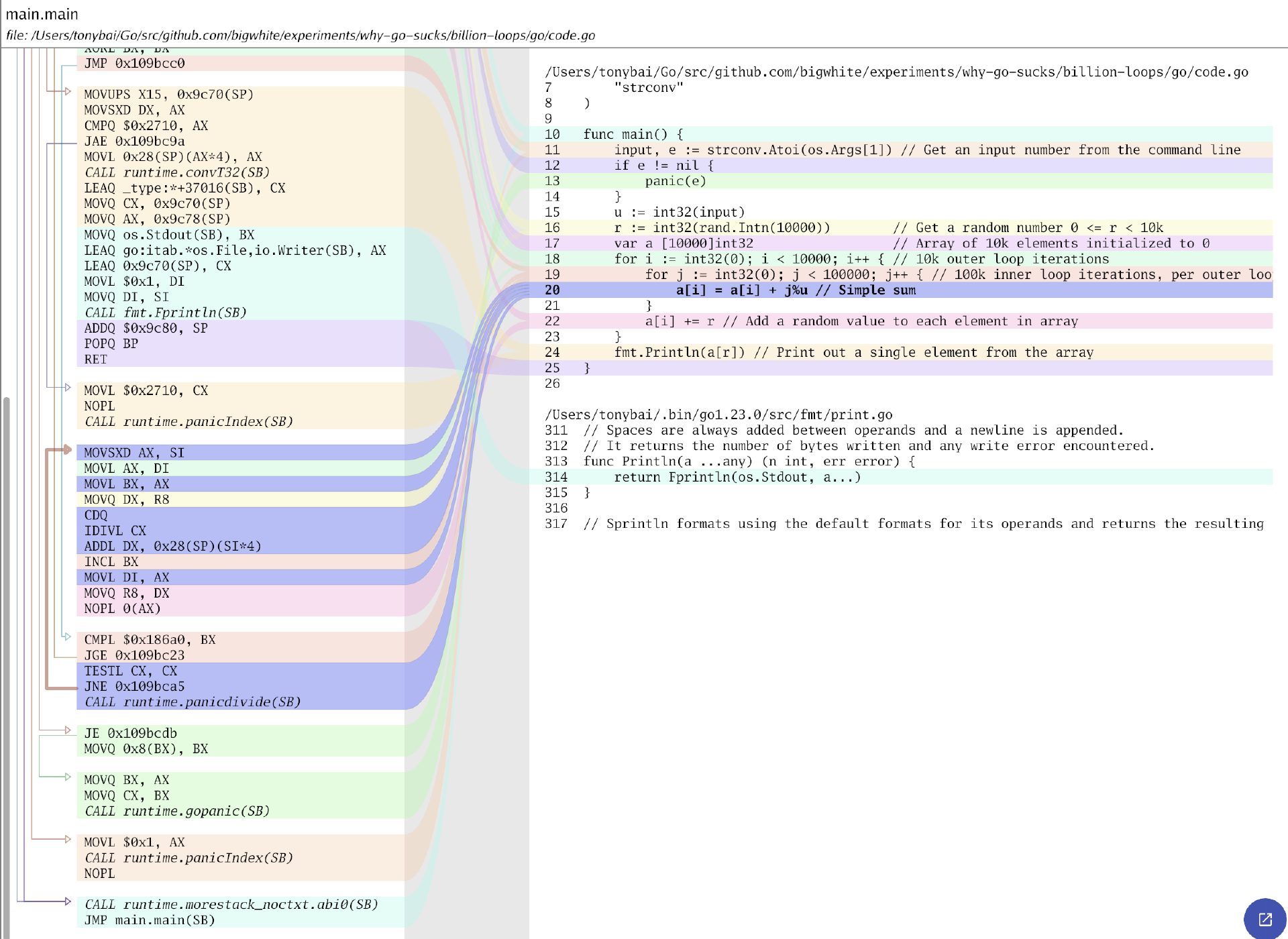
而Java显然做了这类优化,我们在原Java代码版本上也按上述优化逻辑修改一下,代码如下:
// why-go-sucks/billion-loops/java/code_local_var.java
package jvm;
import java.util.Random;
public class code {
public static void main(String[] args) {
var u = Integer.parseInt(args[0]); // 获取命令行输入的整数
var r = new Random().nextInt(10000); // 生成随机数 0 <= r < 10000
var a = new int[10000]; // 定义长度为10000的数组a
for (var i = 0; i < 10000; i++) { // 10k外层循环迭代
var temp = a[i]; // 使用临时变量存储 a[i] 的值
for (var j = 0; j < 100000; j++) { // 100k内层循环迭代,每次外层循环迭代
temp += j % u; // 更新临时变量的值
}
a[i] = temp + r; // 将临时变量的值加上 r 并写回数组
}
System.out.println(a[r]); // 输出 a[r] 的值
}
}
但从运行这个“优化”后的程序的结果来看,其对Java代码的提升幅度几乎可以忽略不计:
这也直接证明了即便采用的是原版Java代码,Java编译器也会生成带有抽取局部变量这种优化的可执行代码,Java程序员无需手工进行此类优化。
像这种编译器优化还有不少,比如我们比较熟悉的循环展开(Loop Unrolling)也可以提升Go程序的性能。
// why-go-sucks/billion-loops/go/code_loop_unrolling.go
package main
import (
"fmt"
"math/rand"
"os"
"strconv"
)
func main() {
input, e := strconv.Atoi(os.Args[1]) // Get an input number from the command line
if e != nil {
panic(e)
}
u := int32(input)
r := int32(rand.Intn(10000)) // Get a random number 0 <= r < 10k
var a [10000]int32 // Array of 10k elements initialized to 0
for i := int32(0); i < 10000; i++ { // 10k outer loop iterations
var sum int32
// Unroll inner loop in chunks of 4 for optimization
for j := int32(0); j < 100000; j += 4 {
sum += j % u
sum += (j + 1) % u
sum += (j + 2) % u
sum += (j + 3) % u
}
a[i] = sum + r // Add the accumulated sum and random value
}
fmt.Println(a[r]) // Print out a single element from the array
}
我们运行这个Go测试程序,性能如下:
$go build -o code_loop_unrolling code_loop_unrolling.go
$time ./code_loop_unrolling 10
458908
real 0m2.937s
user 0m2.940s
sys 0m0.002s
循环展开可以增加指令级并行性,因为展开后的代码块中可以有更多的独立指令,比如示例中的计算j % u、(j+1) % u、(j+2) % u和(j+3) % u。这些计算操作是独立的,可以并行执行,打破了依赖链,从而更好地利用了处理器的并行流水线。而原版Go代码中,每次迭代都会根据前一次迭代的结果更新a[i],形成一个依赖链,这种顺序依赖性迫使处理器只能按顺序执行这些指令,导致CPU的流水线停顿。
不过,其他语言也可以做同样的手工优化,比如我们对C代码做同样的优化(why-go-sucks/billion-loops/c/code_loop_unrolling.c),C测试程序的性能可以提升至2.7s的水平。这也证明了初版C程序即便在-O3的情况下,编译器也没有自动为其做这个优化。
于是,我们就从以上探索中得到了初步结论:性能测试中,Go性能落后于Java和C的原因是Go编译器优化做得还不到位,未能自动进行一些优化(比如提取局部变量、循环展开等)。期待后续Go团队能在编译器优化方面投入更多精力,早日追上GCC/Clang、Java这些成熟的编译器优化水平。
如果不考虑同等条件,对于上面的Go纯计算逻辑还有哪些优化方案呢?
非同等条件下的优化方法
如果是非同等条件下,那我们就可以自由发挥了。比如可以考虑算法优化的手段。我们看到原代码中有一个“取余操作”:
在Go语言以及编译型语言中,取余操作%都是一个相对耗时的操作,尤其是在处理大数或频繁取余的情况下。这个时候,我们可以用其他算法来替代直接使用%的取余操作。比如下面示例中使用位运算来替换取余操作:
// why-go-sucks/billion-loops/go/code_remainder.go
package main
import (
"fmt"
"math/rand"
"os"
"strconv"
)
func main() {
input, e := strconv.Atoi(os.Args[1])
if e != nil {
panic(e)
}
u := int32(input)
mask := u - 1 // 只在u为2的幂时有效
r := int32(rand.Intn(10000))
var a [10000]int32
for i := int32(0); i < 10000; i++ {
for j := int32(0); j < 100000; j++ {
a[i] = a[i] + (j & mask) // 使用位运算代替取余运算
}
a[i] += r
}
fmt.Println(a[r])
}
编译运行上述示例:
$go build -o code_remainder code_remainder.go
$time ./code_remainder 10
453870
real 0m1.894s
user 0m1.894s
sys 0m0.004s
相对于最初版本,该Go程序的性能提升了近一倍多!看来为耗时的取余操作寻找更优化的等价算法是一条正确的优化路径。
不过,使用位操作替换取余运算有局限性,这种替换仅在除数是2的次幂(例如2、4、8、16等)的前提下才正确,即取余操作x % n可以替换为x & (n - 1),前提为n是2的幂次。
为了保证所有情况下程序都能正确运行,我们再次改变一下替换取余操作的算法,如下所示:
// why-go-sucks/billion-loops/go/code_remainder1.go
package main
import (
"fmt"
"math/rand"
"os"
"strconv"
)
func main() {
input, e := strconv.Atoi(os.Args[1]) // Get an input number from the command line
if e != nil {
panic(e)
}
u := int32(input)
r := int32(rand.Intn(10000)) // Get a random number 0 <= r < 10k
var a [10000]int32 // Array of 10k elements initialized to 0
for i := int32(0); i < 10000; i++ { // 10k outer loop iterations
var k int32 = 0
for j := int32(0); j < 100000; j++ { // 100k inner loop iterations, per outer loop iteration
a[i] = a[i] + k
k = k + 1
if k == u {
k = 0
}
}
a[i] += r // Add a random value to each element in array
}
fmt.Println(a[r]) // Print out a single element from the array
}
这回我们引入了一个新变量k,在循环中由一个条件语句模拟每次循环的取余操作,并将结果与a[i]加和。编译和运行这个程序,看看效果如何:
$go build -o code_remainder code_remainder.go
$time ./code_remainder1 10
453269
real 0m1.675s
user 0m1.673s
sys 0m0.006s
可以看到,我们得到了非常不错的优化效果,甚至比位操作的算法更快!
当然,优化的方法还有很多,但这里我们就不再展开了,理解思路即可。如果还有更好的优化算法,欢迎你在留言区分享。
除此之外,对于纯计算逻辑的程序,还有一种常见的优化思路,就是使用CPU提供的高级指令,比如SIMD指令。接下来,我们就来聊一聊高级指令优化的思路。
高级指令优化
SIMD是单指令多数据(Single Instruction Multiple Data)的缩写。与之对应的则是SISD(Single Instruction,Single Data),即单指令单数据。
在大学学习汇编时,用于举例的汇编指令通常是SISD指令,比如常见的ADD、MOV、LEA和XCHG等。这些指令每执行一次,仅处理一个数据项。早期的x86架构下,SISD指令处理的数据仅限于8字节(64位)或更小。随着处理器架构的发展,特别是x86-64架构的引入,SISD指令也能处理更大的数据项,使用更大的寄存器。但SISD指令每次仍然只处理一个数据项,即使这个数据项可能比较大。
相反,SIMD指令是一种特殊的指令集,它可以让处理器同时处理多个数据项,提高计算效率。我们可以用一个形象生动的比喻来体会SIMD和SISD的差别。
想象你是一个厨师,需要切100个苹果。普通的方式是一次切一个苹果,这就像普通的SISD处理器指令。而SIMD指令就像是你突然多了几双手,可以同时切4个或8个苹果。显然,多手同时工作会大大提高切苹果的速度。
具体来说,SIMD指令的优势如下:
- 并行处理:一条指令可以同时对多个数据进行相同的操作。
- 数据打包:将多个较小的数据(如32位浮点数)打包到一个较大的寄存器(如256位)中。
- 提高数据吞吐量:每个时钟周期可以处理更多的数据。
这种并行处理方式特别适合需要大量重复计算的任务,如图像处理、音频处理和科学计算等。使用SIMD指令,可以显著提高这些应用的性能。
主流的x86-64(amd64)和ARM系列CPU都有对SIMD指令的支持。以x86-64为例,该CPU体系下支持的SIMD指令就包括MMX(MultiMedia eXtensions)、SSE(Streaming SIMD Extensions)、SSE2、SSE3、SSSE3、SSE4、AVX(Advanced Vector Extensions)、AVX2以及AVX-512等。ARM架构下也有对应的SIMD指令集,包括VFP(Vector Floating Point)、NEON(Advanced SIMD)、SVE(Scalable Vector Extension)、SVE2以及Helium(M-Profile Vector Extension,MVE)等。
每类SIMD指令集都有其特定的优势和应用场景,以x86-64下的SIMD指令集为例:
- MMX主要用于早期的多媒体处理。
- SSE系列逐步改进了浮点运算和整数运算能力,广泛应用于图形处理和音视频编码。
- AVX系列大幅提高了并行处理能力,特别适合科学计算和高性能计算场景。
遗憾的是,截至目前,Go官方并没有提供支持SIMD的simd包。那我们如何使用SIMD指令呢?
一种方案是使用CGO机制在Go中调用更快的C或C++,但CGO的负担又不能不考虑,就像Go语言之父Rob Pike说的那样“CGO不是Go”,因此很多人不愿意引入,我们这里也不采用这种方案。
另外一种方案就是再向下一层,直接上汇编,在汇编中直接利用SIMD指令实现并行计算。但手写汇编难度很高,手写Plan9风格、资料甚少的Go汇编难度则更高。
那什么方法可以避免直接手搓汇编呢?一种可行的方案是使用Uber工程师Michael McLoughlin开源的avo来生成Go汇编。avo包支持以一种相对高级的Go语法编写汇编,至少你可以不必直面那些晦涩难懂的汇编代码。下面我们就采用avo生成汇编的方案。
不过,前面的示例并不是十分适用于采用SIMD汇编优化,所以我们换一个矩阵加法的例子来演示SIMD指令在计算加速方面的巨大优势。
前面说过avo是一个Go库,我们无需安装任何二进制程序,直接使用avo库中的类型和函数编写矩阵加法的实现即可。下面是使用AVX指令实现矩阵加法的Go代码:
// why-go-sucks/matadd-avx/pkg/asm.go
//go:build ignore
// +build ignore
package main
import (
"github.com/mmcloughlin/avo/attr"
. "github.com/mmcloughlin/avo/build"
. "github.com/mmcloughlin/avo/operand"
)
func main() {
TEXT("MatrixAddSIMD", attr.NOSPLIT, "func(a, b, c []float32)")
a := Mem{Base: Load(Param("a").Base(), GP64())}
b := Mem{Base: Load(Param("b").Base(), GP64())}
c := Mem{Base: Load(Param("c").Base(), GP64())}
n := Load(Param("a").Len(), GP64())
Y0 := YMM()
Y1 := YMM()
Label("loop")
CMPQ(n, U32(8))
JL(LabelRef("done"))
VMOVUPS(a.Offset(0), Y0)
VMOVUPS(b.Offset(0), Y1)
VADDPS(Y1, Y0, Y0)
VMOVUPS(Y0, c.Offset(0))
ADDQ(U32(32), a.Base)
ADDQ(U32(32), b.Base)
ADDQ(U32(32), c.Base)
SUBQ(U32(8), n)
JMP(LabelRef("loop"))
Label("done")
RET()
Generate()
}
然后我们运行该代码,生成相应的汇编代码以及stub函数。代码如下:
生成的add.s的全部汇编代码如下:
// why-go-sucks/matadd-avx/pkg/add.s
// Code generated by command: go run asm.go -out add.s -stubs stub.go. DO NOT EDIT.
#include "textflag.h"
// func MatrixAddSIMD(a []float32, b []float32, c []float32)
// Requires: AVX
TEXT ·MatrixAddSIMD(SB), NOSPLIT, $0-72
MOVQ a_base+0(FP), AX
MOVQ b_base+24(FP), CX
MOVQ c_base+48(FP), DX
MOVQ a_len+8(FP), BX
loop:
CMPQ BX, $0x00000008
JL done
VMOVUPS (AX), Y0
VMOVUPS (CX), Y1
VADDPS Y1, Y0, Y0
VMOVUPS Y0, (DX)
ADDQ $0x00000020, AX
ADDQ $0x00000020, CX
ADDQ $0x00000020, DX
SUBQ $0x00000008, BX
JMP loop
done:
RET
除了生成汇编代码外,asm.go还生成了一个stub函数:MatrixAddSIMD,即上面汇编实现的那个函数,用于Go代码调用。
// why-go-sucks/matadd-avx/pkg/stub.go
// Code generated by command: go run asm.go -out add.s -stubs stub.go. DO NOT EDIT.
package pkg
func MatrixAddSIMD(a []float32, b []float32, c []float32)
在matadd-avx/pkg/add-no-simd.go中,我们放置了常规的矩阵加法的实现:
package pkg
func MatrixAddNonSIMD(a, b, c []float32) {
n := len(a)
for i := 0; i < n; i++ {
c[i] = a[i] + b[i]
}
}
接下来,我们就来做一下benchmark,看看使用AVX指令实现的矩阵加法性能到底提升了多少。
// why-go-sucks/matadd-avx/benchmark_test.go
package main
import (
"demo/pkg"
"testing"
)
func BenchmarkMatrixAddNonSIMD(tb *testing.B) {
size := 1024
a := make([]float32, size)
b := make([]float32, size)
c := make([]float32, size)
for i := 0; i < size; i++ {
a[i] = float32(i)
b[i] = float32(i)
}
tb.ResetTimer()
for i := 0; i < tb.N; i++ {
pkg.MatrixAddNonSIMD(a, b, c)
}
}
func BenchmarkMatrixAddSIMD(tb *testing.B) {
size := 1024
a := make([]float32, size)
b := make([]float32, size)
c := make([]float32, size)
for i := 0; i < size; i++ {
a[i] = float32(i)
b[i] = float32(i)
}
tb.ResetTimer()
for i := 0; i < tb.N; i++ {
pkg.MatrixAddSIMD(a, b, c)
}
}
运行benchmark:
$go test -bench .
goos: darwin
goarch: amd64
pkg: demo
BenchmarkMatrixAddNonSIMD-8 2110710 568.2 ns/op
BenchmarkMatrixAddSIMD-8 10651008 111.7 ns/op
PASS
ok demo 3.086s
我们看到,AVX版SIMD指令的矩阵加法的性能是常规实现的5倍多。在实际生产中,这将大大提升代码的执行效率!
小结
好了,到这里纯计算逻辑调优的故事就告一段落了。我们来总结一下今天的主要内容。
Go语言在十亿次循环测试中的表现令人意外,这一节我们主要探讨了Go逊色于Java等语言的原因。首先,我们通过实验证明,Go在循环执行中的慢速表现,主要是因其编译器优化不足影响了执行效率。然后,我们还给出了在非同等条件下优化示例代码的思路,比如将比较耗时的取余操作替换为更快的算法等。
最后,我们提及了在纯计算逻辑优化领域常见的一种方案,那就是利用SIMD指令。不过Go没有提供对SIMD指令的官方包支持,这让我们在Go中应用SIMD指令优化有了不小的难度。此外,SIMD指令也有其适用范围和场景,我们在使用之前要明确这一点。
本文涉及的源码可以在这里下载。
思考题
学完这一节后,建议你也自己动手实践一遍上面的优化流程,想一想是否还有更好的优化方法。
如果你有新的想法,欢迎留言与我分享。我是Tony Bai,我们下一节见。
- 沿见 👍(0) 💬(1)
之前在公众号上看到了这篇,结果老师竟然作为迭代放到了这门课上,课程常看常新,手动点赞。感觉现在很少有人像在嵌入式平台上开发一样死抠这些小的运行效率问题了,但是整个调优过程确实让人受益匪浅
2025-02-19 - return 👍(0) 💬(1)
太厉害了👍
2025-01-03