47丨如何利用SQL对零售数据进行分析?
我们通过OLTP系统实时捕捉到了用户的数据,还需要在OLAP系统中对它们进行分析。之前我们讲解了如何对数据进行清洗,以及如何对分散在不同地方的数据进行集成,今天我们来看下如何使用SQL分析这些数据。
关于这部分内容,今天我们一起来学习下:
- 使用SQL进行数据分析都有哪几种姿势?
- 如何通过关联规则挖掘零售数据中的频繁项集?
- 如何使用SQL+Python完成零售数据的关联分析?
使用SQL进行数据分析的5种姿势
在DBMS中,有些数据库管理系统很好地集成了BI工具,可以方便我们对收集的数据进行商业分析。
SQL Server提供了BI分析工具,我们可以通过使用SQL Server中的Analysis Services完成数据挖掘任务。SQL Server内置了多种数据挖掘算法,比如常用的EM、K-Means聚类算法、决策树、朴素贝叶斯和逻辑回归等分类算法,以及神经网络等模型。我们还可以对这些算法模型进行可视化效果呈现,帮我们优化和评估算法模型的好坏。
PostgreSQL是免费开源的对象-关系数据库(ORDBMS),它的稳定性非常强,功能强大,在OLTP和OLAP系统上表现都非常出色。同时在机器学习上,配合Madlib项目可以让PostgreSQL如虎添翼。Madlib包括了多种机器学习算法,比如分类、聚类、文本分析、回归分析、关联规则挖掘和验证分析等功能。这样我们可以通过使用SQL,在PostgreSQL中使用各种机器学习算法模型,帮我们进行数据挖掘和分析。
2018年Google将机器学习(Machine Learning)工具集成到了BigQuery中,发布了BigQuery ML,这样开发者就可以在大型的结构化或半结构化的数据集上构建和使用机器学习模型。通过BigQuery控制台,开发者可以像使用SQL语句一样来完成机器学习模型的训练和预测。
SQLFlow是蚂蚁金服于2019年开源的机器学习工具,我们通过使用SQL就可以完成机器学习算法的调用,你可以将SQLFlow理解为机器学习的翻译器。我们在SELECT之后加上TRAIN从句就可以完成机器学习模型的训练,在SELECT语句之后加上PREDICT就可以使用模型来进行预测。这些算法模型既包括了传统的机器学习模型,也包括了基于Tensorflow、PyTorch等框架的深度学习模型。
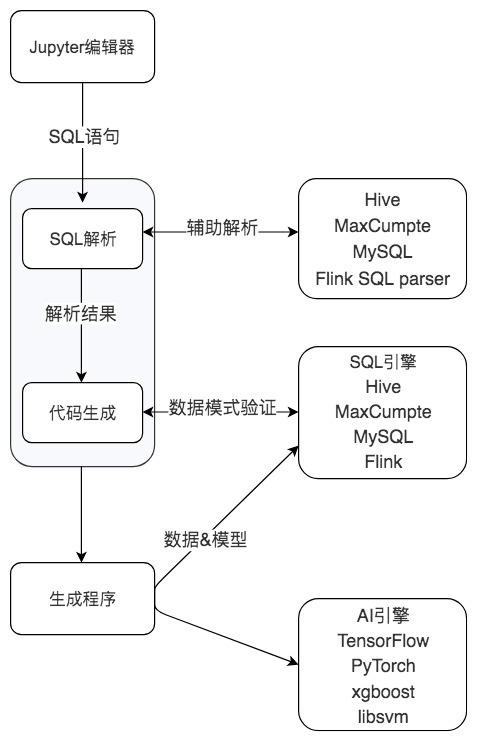
从下图中你也能看出SQLFlow的使用过程,首先我们可以通过Jupyter notebook来完成SQL语句的交互。SQLFlow支持了多种SQL引擎,包括MySQL、Oracle、Hive、SparkSQL和Flink等,这样我们就可以通过SQL语句从这些DBMS中抽取数据,然后选择想要进行的机器学习算法(包括传统机器学习和深度学习模型)进行训练和预测。不过这个工具刚刚上线,工具、文档、社区还有很多需要完善的地方。
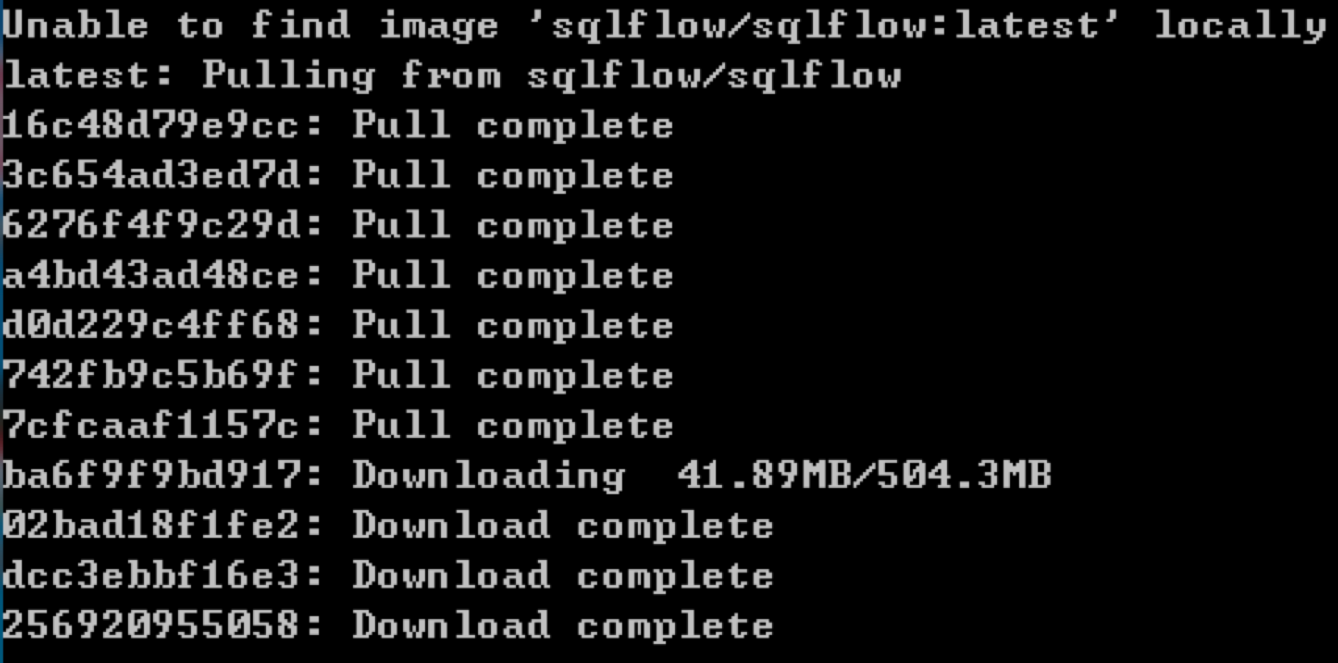
最后一个方法是SQL+Python,也是我们今天要讲解的内容。刚才介绍的工具可以说既是SQL查询数据的入口,也是数据分析、机器学习的入口。不过这些模块耦合度高,也可能存在使用的问题。一方面工具会很大,比如在安装SQLFlow的时候,采用Docker方式(下图为使用Docker安装sqlflow的过程)进行安装,整体需要下载的文件会超过2G。同时,在进行机器学习算法调参、优化的时候也存在灵活度差的情况。因此最直接的方式,还是将SQL与机器学习模块分开,采用SQL读取数据,然后通过Python来进行机器学习的处理。
案例:挖掘零售数据中的频繁项集与关联规则
刚才我们讲解了如何通过SQL来完成数据分析(机器学习)的5种姿势,下面我们还需要通过一个案例来进行具体的讲解。
我们要分析的是购物篮问题,采用的技术为关联分析。它可以帮我们在大量的数据集中找到商品之间的关联关系,从而挖掘出经常被人们购买的商品组合,一个经典的例子就是“啤酒和尿布”的例子。
今天我们的数据集来自于一个面包店的21293笔订单,字段包括了Date(日期)、Time(时间)、Transaction(交易ID)以及Item(商品名称)。其中交易ID的范围是[1,9684],在这中间也有一些交易ID是空缺的,同一笔交易中存在商品重复的情况。除此以外,有些交易是没有商品的,也就是对应的Item为NONE。具体的数据集你可以从GitHub上下载。
我们采用的关联分析算法是Apriori算法,它帮我们查找频繁项集,首先我们需要先明白什么是频繁项集。
频繁项集就是支持度大于等于最小支持度阈值的项集,小于这个最小值支持度的项目就是非频繁项集,而大于等于最小支持度的项集就是频繁项集。支持度是个百分比,指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
我们来看个例子理解一下,下面是5笔用户的订单,以及每笔订单购买的商品:
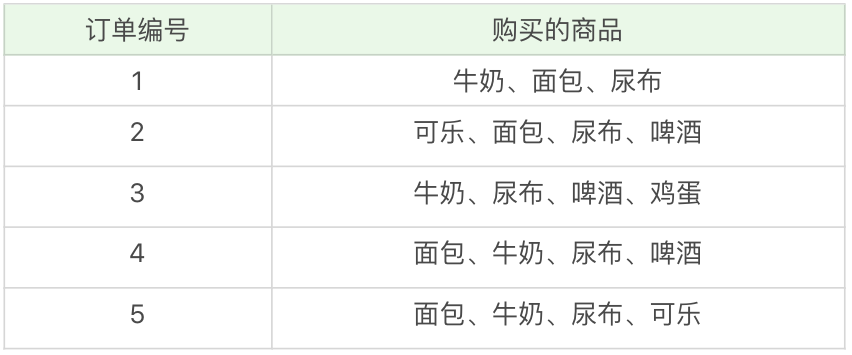
在这个例子中,“牛奶”出现了4次,那么这5笔订单中“牛奶”的支持度就是4/5=0.8。同样“牛奶+面包”出现了3次,那么这5笔订单中“牛奶+面包”的支持度就是3/5=0.6。
同时,我们还需要理解一个概念叫做“置信度”,它表示的是当你购买了商品A,会有多大的概率购买商品B,在这个例子中,置信度(牛奶→啤酒)=2/4=0.5,代表如果你购买了牛奶,会有50%的概率会购买啤酒;置信度(啤酒→牛奶)=2/3=0.67,代表如果你购买了啤酒,有67%的概率会购买牛奶。
所以说置信度是个条件概念,指的是在A发生的情况下,B发生的概率是多少。
我们在计算关联关系的时候,往往需要规定最小支持度和最小置信度,这样才可以寻找大于等于最小支持度的频繁项集,以及在频繁项集的基础上,大于等于最小置信度的关联规则。
使用SQL+Python完成零售数据的关联分析
针对上面的零售数据关联分析的案例,我们可以使用工具自带的关联规则进行分析,比如使用SQL Server Analysis Services的多维数据分析,或者是在Madlib、BigQuery ML、SQLFlow工具中都可以找到相应的关联规则,通过写SQL的方式就可以完成关联规则的调用。
除此以外,我们还可以直接使用SQL完成数据的查询,然后通过Python的机器学习工具包完成关联分析。下面我们通过之前讲解的SQLAlchemy来完成SQL查询,使用efficient_apriori工具包的Apriori算法。整个工程一共包括3个部分。
第一个部分为数据加载,首先我们通过sql.create_engine创建SQL连接,然后从bread_basket数据表中读取全部的数据加载到data中。这里需要配置你的MySQL账户名和密码
第二步为数据预处理,因为数据中存在无效的数据,比如item为NONE的情况,同时Item的大小写格式不统一,因此我们需要先将Item字段都转换为小写的形式,然后去掉Item字段中数值为none的项。在数据预处理中,我们还需要得到一个transactions数组,里面包括了每笔订单的信息,其中每笔订单是以集合的形式进行存储的,这样相同的订单中item就不存在重复的情况,同时也可以使用Apriori工具包直接进行计算。
最后一步,使用Apriori工具包进行关联分析,这里我们设定了参数min_support=0.02,min_confidence=0.5,也就是最小支持度为0.02,最小置信度为0.5。根据条件找出transactions中的频繁项集itemsets和关联规则rules。
具体的代码如下:
from efficient_apriori import apriori
import sqlalchemy as sql
import pandas as pd
# 数据加载
engine = sql.create_engine('mysql+mysqlconnector://root:passwd@localhost/wucai')
query = 'SELECT * FROM bread_basket'
data = pd.read_sql_query(query, engine)
# 统一小写
data['Item'] = data['Item'].str.lower()
# 去掉none项
data = data.drop(data[data.Item == 'none'].index)
# 得到一维数组orders_series,并且将Transaction作为index, value为Item取值
orders_series = data.set_index('Transaction')['Item']
# 将数据集进行格式转换
transactions = []
temp_index = 0
for i, v in orders_series.items():
if i != temp_index:
temp_set = set()
temp_index = i
temp_set.add(v)
transactions.append(temp_set)
else:
temp_set.add(v)
# 挖掘频繁项集和频繁规则
itemsets, rules = apriori(transactions, min_support=0.02, min_confidence=0.5)
print('频繁项集:', itemsets)
print('关联规则:', rules)
运行结果:
频繁项集: {1: {('alfajores',): 344, ('bread',): 3096, ('brownie',): 379, ('cake',): 983, ('coffee',): 4528, ('cookies',): 515, ('farm house',): 371, ('hot chocolate',): 552, ('juice',): 365, ('medialuna',): 585, ('muffin',): 364, ('pastry',): 815, ('sandwich',): 680, ('scandinavian',): 275, ('scone',): 327, ('soup',): 326, ('tea',): 1350, ('toast',): 318, ('truffles',): 192}, 2: {('bread', 'cake'): 221, ('bread', 'coffee'): 852, ('bread', 'pastry'): 276, ('bread', 'tea'): 266, ('cake', 'coffee'): 518, ('cake', 'tea'): 225, ('coffee', 'cookies'): 267, ('coffee', 'hot chocolate'): 280, ('coffee', 'juice'): 195, ('coffee', 'medialuna'): 333, ('coffee', 'pastry'): 450, ('coffee', 'sandwich'): 362, ('coffee', 'tea'): 472, ('coffee', 'toast'): 224}}
关联规则: [{cake} -> {coffee}, {cookies} -> {coffee}, {hot chocolate} -> {coffee}, {juice} -> {coffee}, {medialuna} -> {coffee}, {pastry} -> {coffee}, {sandwich} -> {coffee}, {toast} -> {coffee}]
从结果中你能看到购物篮组合中,商品个数为1的频繁项集有19种,分别为面包、蛋糕、咖啡等。商品个数为2的频繁项集有14种,包括(面包,蛋糕),(面包,咖啡)等。其中关联规则有8种,包括了购买蛋糕的人也会购买咖啡,购买曲奇的同时也会购买咖啡等。
总结
通过SQL完成机器学习往往还是需要使用到Python,因为数据分析是Python的擅长。通过今天的学习你应该能体会到采用SQL工具作为数据查询和分析的入口是一种数据全栈的思路,对于开发人员来说降低了数据分析的技术门槛。
如果你想要对机器学习或者数据分析算法有更深入的理解,也可以参考我的《数据分析实战45讲》专栏,相信在当今的数据时代,我们的业务增长会越来越依靠于SQL引擎+AI引擎。
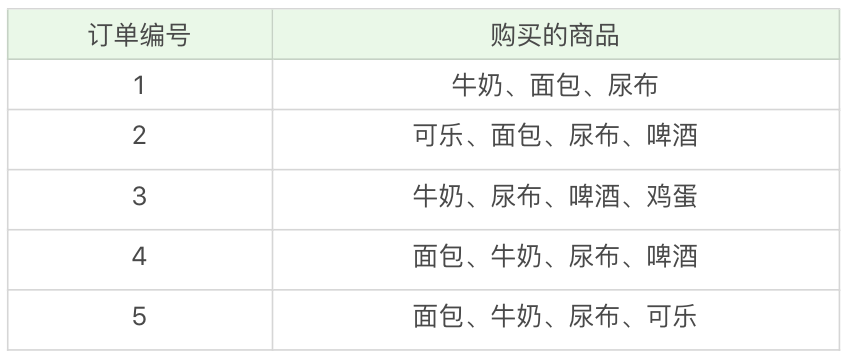
我在文章中举了一个购物篮分析的例子,如下图所示,其中(牛奶、面包、尿布)的支持度是多少呢?
欢迎你在评论区写下你的思考,也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
- mickey 👍(19) 💬(2)
import numpy as np import pandas as pd title = ['牛奶', '面包', '尿布', '可乐', '啤酒', '鸡蛋']; x = [[1, 1, 1, 0, 0, 0], [0, 1, 1, 1, 1, 0], [1, 0, 1, 0, 1, 1], [1, 1, 1, 0, 1, 0], [1, 1, 1, 1, 0, 0]] df = pd.DataFrame(x, columns=title) # 创建两个表 分别作为支持度和置信度的准备表 df1 = pd.DataFrame(np.zeros([1, 6]), index=['支持度'], columns=title) df2 = pd.DataFrame(np.zeros([6, 6]), index=title, columns=title) df3 = pd.DataFrame(np.zeros([6, 6]), index=title, columns=title) # 计算支持度 for i in x: for j in range(1): for k in range(j, 6): if not i[k] : continue df1.iloc[j,k] += 1 support = df1.apply(lambda x: x /5) # 返回支持度的结果 print(support) # 计算置信度 for i in x: for j in range(5): # 如果为0 就跳过 if not i[j] : continue # 如果不0,继续遍历,如果有购买,便+1 for k in range(j+1,5): if not i[k] : continue df2.iloc[j,k] += 1 df2.iloc[k,j] += 1 for j in range(6): df3.iloc[j] = df2.iloc[j] / df.sum()[j] confidence = df3.round(2) # 以3位小数返回置信度表 # 返回置信度的结果 print(confidence) 牛奶 面包 尿布 可乐 啤酒 鸡蛋 支持度 0.8 0.8 1.0 0.4 0.6 0.2 牛奶 面包 尿布 可乐 啤酒 鸡蛋 牛奶 0.00 0.75 1.0 0.25 0.5 0.0 面包 0.75 0.00 1.0 0.50 0.5 0.0 尿布 0.80 0.80 0.0 0.40 0.6 0.0 可乐 0.50 1.00 1.0 0.00 0.5 0.0 啤酒 0.67 0.67 1.0 0.33 0.0 0.0 鸡蛋 0.00 0.00 0.0 0.00 0.0 0.0
2019-09-27 - 学习 👍(2) 💬(1)
牛奶,面包,尿布同时出现是3,支持度是3/5=0.6
2019-09-27 - mickey 👍(1) 💬(1)
支持度 牛奶 0.8 面包 0.8 尿布 1 可乐 0.4 啤酒 0.6 鸡蛋 0.2
2019-09-27 - JustDoDT 👍(1) 💬(1)
efficient-apriori官方文档 https://efficient-apriori.readthedocs.io/en/stable/
2019-09-27 - 骑行的掌柜J 👍(0) 💬(1)
评论里朋友ttttt说” 遇到错误:mysql.connector.errors.NotSupportedError) Authentication plugin 'caching_sha2_password' is not supported “ 换pymysql就可以,不过我这里有另一种解法,可以到我的博客看看,希望对你有帮助!谢谢 https://blog.csdn.net/weixin_41013322/article/details/103427293
2019-12-06 - TKbook 👍(0) 💬(1)
transactions = [] temp_index = 0 for i, v in orders_series.items(): if i != temp_index: temp_set = set() temp_index = i temp_set.add(v) transactions.append(temp_set) print(transactions) else: temp_set.add(v) 老师,这里的transactions = [] 里面的元素,不应该是每个订单所有的商品集合吗? 但是上述代码不是实现这个需求
2019-09-27 - JustDoDT 👍(0) 💬(2)
# 一行代码数据集格式转换 # transactions = list(data.groupby('Transaction').agg(lambda x: set(x.Item.values))['Item']) # 完整代码 from efficient_apriori import apriori import sqlalchemy as sql import pandas as pd # 数据加载 engine = sql.create_engine('mysql+pymysql://root:passwd@localhost/wucai') query = 'SELECT * FROM bread_basket' data = pd.read_sql_query(query, engine) # 统一小写 data['Item'] = data['Item'].str.lower() # 去掉none项 data = data.drop(data[data.Item == 'none'].index) # 得到一维数组orders_series,并且将Transaction作为index, value为Item取值 orders_series = data.set_index('Transaction')['Item'] # 将数据集进行格式转换 transactions = transactions = list(data.groupby('Transaction').agg(lambda x: set(x.Item.values))['Item']) # 挖掘频繁项集和频繁规则 itemsets, rules = apriori(transactions, min_support=0.02, min_confidence=0.5) print('频繁项集:', itemsets) print('关联规则:', rules) # ----------输出结果------------------ # 频繁项集: {1: {('alfajores',): 344, ('bread',): 3096, ('brownie',): 379, ('cake',): 983, ('coffee',): 4528, ('cookies',): 515, ('farm house',): 371, ('hot chocolate',): 552, ('juice',): 365, ('medialuna',): 585, ('muffin',): 364, ('pastry',): 815, ('sandwich',): 680, ('scandinavian',): 275, ('scone',): 327, ('soup',): 326, ('tea',): 1350, ('toast',): 318, ('truffles',): 192}, 2: {('bread', 'cake'): 221, ('bread', 'coffee'): 852, ('bread', 'pastry'): 276, ('bread', 'tea'): 266, ('cake', 'coffee'): 518, ('cake', 'tea'): 225, ('coffee', 'cookies'): 267, ('coffee', 'hot chocolate'): 280, ('coffee', 'juice'): 195, ('coffee', 'medialuna'): 333, ('coffee', 'pastry'): 450, ('coffee', 'sandwich'): 362, ('coffee', 'tea'): 472, ('coffee', 'toast'): 224}} 关联规则: [{cake} -> {coffee}, {cookies} -> {coffee}, {hot chocolate} -> {coffee}, {juice} -> {coffee}, {medialuna} -> {coffee}, {pastry} -> {coffee}, {sandwich} -> {coffee}, {toast} -> {coffee}]
2019-09-27 - JustDoDT 👍(2) 💬(0)
遇到错误:NotSupportedError: (mysql.connector.errors.NotSupportedError) Authentication plugin 'caching_sha2_password' is not supported (Background on this error at: http://sqlalche.me/e/tw8g) 解决方法 engine = sql.create_engine( 'mysql+pymysql://{}:{}@{}/{}'.format(user, passwd, host, database)) mysql+mysqlconnector 改成 mysql+pymysql 就行了
2019-09-27 - 邵家伟 👍(1) 💬(0)
C# string[] item = { "牛奶", "面包", "尿布", "鸡蛋", "啤酒", "可乐" }; int[,] Record = { { 1, 1, 1, 0, 0, 0 }, { 0, 1, 1, 0, 1, 0 }, { 1, 0, 1, 1, 1, 0 }, { 1, 1, 1, 0, 1, 0 }, { 1, 1, 1, 0, 0, 1 } }; double SupportRate; for (int a = 0; a < 6; a++)//列遍历 { int Count = 0;int total = 0; for (int b = 0; b < 5; b++)//行遍历 { total += 1; if (Record[b, a] == 1) Count += 1; } SupportRate = Convert.ToDouble(Count) / Convert.ToDouble(total); Context.Response.Write(item[a] + "支持度为" + SupportRate+"</br>"); } double[,] BelieveRate = new double[6, 6]; for (int a = 0; a < 6; a++)//行 { for (int b = 0; b < 6; b++) //列 { if (a == b) BelieveRate[a, b] = 0; else { int total = 0; int count = 0; for (int c = 0; c < 5; c++) { if(Record[c,a]==1) { total += 1; if (Record[c, b] == 1) count += 1; } } BelieveRate[a,b]=Convert.ToDouble(count)/Convert.ToDouble(total); } } } for (int a = 0; a < 7; a++) { for (int b = 0; b < 7; b++) { if (a == 0 && b == 0) Context.Response.Write("置信度"); if(a==0&&b>0) Context.Response.Write(" " + item[b-1]+ " "); if (a > 0 && b == 0) Context.Response.Write(" " + item[a-1]+ " "); if (a > 0 && b > 0) Context.Response.Write(BelieveRate[a - 1, b - 1].ToString("0.00") + " "); } Context.Response.Write("</br>"); }
2021-07-07 - 邵家伟 👍(0) 💬(0)
结果: 牛奶支持度为0.8 面包支持度为0.8 尿布支持度为1 鸡蛋支持度为0.2 啤酒支持度为0.6 可乐支持度为0.2 置信度 牛奶 面包 尿布 鸡蛋 啤酒 可乐 牛奶 0.00 0.75 1.00 0.25 0.50 0.25 面包 0.75 0.00 1.00 0.00 0.50 0.25 尿布 0.80 0.80 0.00 0.20 0.60 0.20 鸡蛋 1.00 0.00 1.00 0.00 1.00 0.00 啤酒 0.67 0.67 1.00 0.33 0.00 0.00 可乐 1.00 1.00 1.00 0.00 0.00 0.00
2021-07-07