21丨范式设计:数据表的范式有哪些,3NF指的是什么?
在日常工作中,我们都需要遵守一定的规范,比如签到打卡、审批流程等,这些规范虽然有一定的约束感,却是非常有必要的,这样可以保证正确性和严谨性,但有些情况下,约束反而会带来效率的下降,比如一个可以直接操作的任务,却需要通过重重审批才能执行。
实际上,数据表的设计和工作流程的设计很像,我们既需要规范性,也要考虑到执行时的方便性。
今天,我来讲解一下数据表的设计范式。范式是数据表设计的基本原则,又很容易被忽略。很多时候,当数据库运行了一段时间之后,我们才发现数据表设计得有问题。重新调整数据表的结构,就需要做数据迁移,还有可能影响程序的业务逻辑,以及网站正常的访问。所以在开始设置数据库的时候,我们就需要重视数据表的设计。
今天的课程你需要掌握以下几个方面的内容:
- 数据库的设计范式都有哪些?
- 数据表的键都有哪些?
- 1NF、2NF和3NF指的是什么?
数据库的设计范式都包括哪些
我们在设计关系型数据库模型的时候,需要对关系内部各个属性之间联系的合理化程度进行定义,这就有了不同等级的规范要求,这些规范要求被称为范式(NF)。你可以把范式理解为,一张数据表的设计结构需要满足的某种设计标准的级别。
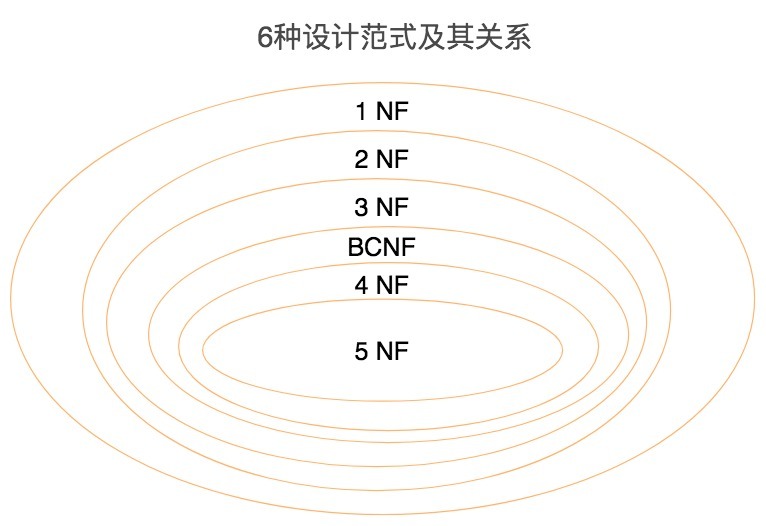
目前关系型数据库一共有6种范式,按照范式级别,从低到高分别是:1NF(第一范式)、2NF(第二范式)、3NF(第三范式)、BCNF(巴斯-科德范式)、4NF(第四范式)和5NF(第五范式,又叫做完美范式)。
数据库的范式设计越高阶,冗余度就越低,同时高阶的范式一定符合低阶范式的要求,比如满足2NF的一定满足1NF,满足3NF的一定满足2NF,依次类推。
你可能会问,这么多范式是不是都要掌握呢?
一般来说数据表的设计应尽量满足3NF。但也不绝对,有时候为了提高某些查询性能,我们还需要破坏范式规则,也就是反规范化。
数据表中的那些键
范式的定义会使用到主键和候选键(因为主键和候选键可以唯一标识元组),数据库中的键(Key)由一个或者多个属性组成。我总结了下数据表中常用的几种键和属性的定义:
- 超键:能唯一标识元组的属性集叫做超键。
- 候选键:如果超键不包括多余的属性,那么这个超键就是候选键。
- 主键:用户可以从候选键中选择一个作为主键。
- 外键:如果数据表R1中的某属性集不是R1的主键,而是另一个数据表R2的主键,那么这个属性集就是数据表R1的外键。
- 主属性:包含在任一候选键中的属性称为主属性。
- 非主属性:与主属性相对,指的是不包含在任何一个候选键中的属性。
通常,我们也将候选键称之为“码”,把主键也称为“主码”。因为键可能是由多个属性组成的,针对单个属性,我们还可以用主属性和非主属性来进行区分。
看到上面的描述你可能还是有点懵,我举个简单的例子。
我们之前用过NBA的球员表(player)和球队表(team)。这里我可以把球员表定义为包含球员编号、姓名、身份证号、年龄和球队编号;球队表包含球队编号、主教练和球队所在地。
对于球员表来说,超键就是包括球员编号或者身份证号的任意组合,比如(球员编号)(球员编号,姓名)(身份证号,年龄)等。
候选键就是最小的超键,对于球员表来说,候选键就是(球员编号)或者(身份证号)。
主键是我们自己选定,也就是从候选键中选择一个,比如(球员编号)。
外键就是球员表中的球队编号。
在player表中,主属性是(球员编号)(身份证号),其他的属性(姓名)(年龄)(球队编号)都是非主属性。
从1NF到3NF
了解了数据表中的4种键之后,我们再来看下1NF、2NF和3NF,BCNF我们放在后面讲。
1NF指的是数据库表中的任何属性都是原子性的,不可再分。这很好理解,我们在设计某个字段的时候,对于字段X来说,就不能把字段X拆分成字段X-1和字段X-2。事实上,任何的DBMS都会满足第一范式的要求,不会将字段进行拆分。
2NF指的数据表里的非主属性都要和这个数据表的候选键有完全依赖关系。所谓完全依赖不同于部分依赖,也就是不能仅依赖候选键的一部分属性,而必须依赖全部属性。
这里我举一个没有满足2NF的例子,比如说我们设计一张球员比赛表player_game,里面包含球员编号、姓名、年龄、比赛编号、比赛时间和比赛场地等属性,这里候选键和主键都为(球员编号,比赛编号),我们可以通过候选键来决定如下的关系:
(球员编号, 比赛编号) → (姓名, 年龄, 比赛时间, 比赛场地,得分)
上面这个关系说明球员编号和比赛编号的组合决定了球员的姓名、年龄、比赛时间、比赛地点和该比赛的得分数据。
但是这个数据表不满足第二范式,因为数据表中的字段之间还存在着如下的对应关系:
(球员编号) → (姓名,年龄)
(比赛编号) → (比赛时间, 比赛场地)
也就是说候选键中的某个字段决定了非主属性。你也可以理解为,对于非主属性来说,并非完全依赖候选键。这样会产生怎样的问题呢?
- 数据冗余:如果一个球员可以参加m场比赛,那么球员的姓名和年龄就重复了m-1次。一个比赛也可能会有n个球员参加,比赛的时间和地点就重复了n-1次。
- 插入异常:如果我们想要添加一场新的比赛,但是这时还没有确定参加的球员都有谁,那么就没法插入。
- 删除异常:如果我要删除某个球员编号,如果没有单独保存比赛表的话,就会同时把比赛信息删除掉。
- 更新异常:如果我们调整了某个比赛的时间,那么数据表中所有这个比赛的时间都需要进行调整,否则就会出现一场比赛时间不同的情况。
为了避免出现上述的情况,我们可以把球员比赛表设计为下面的三张表。
球员player表包含球员编号、姓名和年龄等属性;比赛game表包含比赛编号、比赛时间和比赛场地等属性;球员比赛关系player_game表包含球员编号、比赛编号和得分等属性。
这样的话,每张数据表都符合第二范式,也就避免了异常情况的发生。某种程度上2NF是对1NF原子性的升级。1NF告诉我们字段属性需要是原子性的,而2NF告诉我们一张表就是一个独立的对象,也就是说一张表只表达一个意思。
3NF在满足2NF的同时,对任何非主属性都不传递依赖于候选键。也就是说不能存在非主属性 A 依赖于非主属性 B,非主属性 B 依赖于候选键的情况。
我们用球员player表举例子,这张表包含的属性包括球员编号、姓名、球队名称和球队主教练。现在,我们把属性之间的依赖关系画出来,如下图所示:
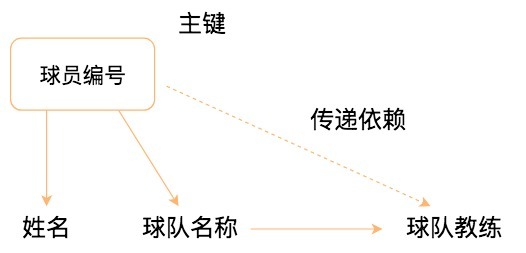
你能看到球员编号决定了球队名称,同时球队名称决定了球队主教练,非主属性球队主教练就会传递依赖于球员编号,因此不符合3NF的要求。
如果要达到3NF的要求,需要把数据表拆成下面这样:
球员表的属性包括球员编号、姓名和球队名称;球队表的属性包括球队名称、球队主教练。
我再总结一下,1NF需要保证表中每个属性都保持原子性;2NF需要保证表中的非主属性与候选键完全依赖;3NF需要保证表中的非主属性与候选键不存在传递依赖。
总结
我们今天讲解了数据表设计的三种范式。关系型数据库的设计都是基于关系模型的,在关系模型中存在着4种键,这些键的核心作用就是标识。
在这些概念的基础上,我又讲了1NF,2NF和3NF。我们经常会与这三种范式打交道,利用它们建立冗余度小、结构合理的数据库。
有一点需要注意的是,这些范式只是提出了设计的标准,实际上设计数据表时,未必要符合这些原则。一方面是因为这些范式本身存在一些问题,可能会带来插入,更新,删除等的异常情况(这些会在下一讲举例说明),另一方面,它们也可能降低会查询的效率。这是为什么呢?因为范式等级越高,设计出来的数据表就越多,进行数据查询的时候就可能需要关联多张表,从而影响查询效率。
2NF和3NF相对容易混淆,根据今天的内容,你能说下这两个范式之间的区别吗?另外,如果我们现在有一张学生选课表,包含的属性有学号、姓名、课程名称、分数、系别和系主任,如果要改成符合3NF要求的设计,需要怎么修改呢?
欢迎你在评论区写下你的答案,也欢迎把这篇文章分享给你的朋友或者同事,一起来交流。
- 夜路破晓 👍(129) 💬(7)
数据库设计三重境: 第一重:山无棱,天地合,乃敢与君绝。(1NF:不可分) 第二重:玲珑骰子安红豆,入骨相思知不知。(2NF:完全性) 第三重:问世间,情为何物,直教人生死相许?(3NF:直接性)
2019-07-29 - 丁丁历险记 👍(49) 💬(4)
啰哩巴嗦的扯一大堆。 姓名,年龄分开就是一范 加个id 就二范 加个foreign key 就三范 三降二 通过冗余字断提效率性能,取了个装x 的名字叫反范式。 其它的范式,没事别管,不论是开发效率,还是查询效率都很感人。 需要时google 下
2019-12-28 - Monday 👍(40) 💬(4)
1NF:列的原子性,不可拆分 2NF:针对于联合主键,非主属性完全依赖于联合主键,而非部分 3NF:非主属性只能直接依赖于主键
2019-08-11 - X5N 👍(27) 💬(2)
又思考了一下课后练习题,感觉可以把“学生选课表”拆分成4个表。 1.学生表:学号(主键),姓名,系别编号(外键)。 2.课程表:课程编号(主键),课程名称。 3.成绩表:学号,课程编号,分数(学号和课程编号,一起构成“联合主键”)。 4.院系表:系别编号(主键),系别(名称),系主任。
2019-07-29 - 未来的胡先森 👍(17) 💬(1)
我所理解的第二范式和第三范式的不同: 1、首先第三范式是第二范式的更进一步(要求更严格),要想满足第三范式首先要满足第二范式。 2、而什么情况下能够满足第二范式呢?候选码能确定一条记录的所有信息。以老师文中的例子来对照:知道球员的编号是可以知道球员信息的,但是比赛编号、比赛时间是无法来通过球员信息来确定的。这张表需要两个候选码(球员编号、比赛编号)才能确定一条记录的信息。类似于这样的关系我们称为「部分依赖」,消除后才能算「第二范式」。 3、第三范式的核心 —— 消除传递依赖。老师文中的图已经画的很清晰了,A->B,B->C,A->C,类似于这样依靠中间人串起的关系我们称之为「传递依赖」 学生选课表我的修改: 学生信息表:学号、姓名、系别编号 课程信息表:课程编号、课程名称 课程成绩表:学号、课程编号、分数 系别信息表:系别编号、系别名称、系主任
2019-08-13 - 发条 👍(16) 💬(1)
对于理解1-3NF,CSDN的这篇文章作为辅助阅读挺好的:https://blog.csdn.net/wyh7280/article/details/83350722
2019-08-06 - Cue 👍(9) 💬(1)
第四范式这家公司起名来源难不成是和这个第四范式有关😄
2019-07-29 - 野马 👍(6) 💬(1)
对于非计算机专业人来说,名词太多了,已经被这些名词吓到了,希望老师用大白话讲解每一个知识点,让三岁小孩儿或者八十岁老太太都能听懂的讲解方式讲解,谢谢!
2019-07-30 - law 👍(5) 💬(1)
建议课后习题,老师给出标准答案,或者对一些答案进行点评。
2019-08-03 - cricket1981 👍(5) 💬(2)
1. 学生表:学号、姓名、系别 2. 课程表:课程名称 3. 系别表:系别、系主任 4. 成绩表:学号、课程名称、分数
2019-07-30 - Ronnyz 👍(5) 💬(1)
作业: 3NF区别于2NF是在于:字段非主属性不直接依赖主属性,而是通过依赖于其他非主属性而传递到主属性,解决办法就是让依赖非主属性的字段与依赖字段独立成表 拆分1 学生选课表,包含的属性有学号、姓名、课程名称、分数、系别和系主任 - 姓名和系别都是依赖于学号 - 系主任依赖系别 - 系主任间接依赖学号 院系表:系别(主键) 系主任 学生表:学号 姓名 课程名称 分数 系别 拆分2 学生表,包含的属性有学号 姓名 课程名称 分数 系别 选课那就会有课程表 - 课程名称依赖于学号 - 分数依赖于课程名称和学号 学生表:学号(主键) 姓名 系别(外键) 课程表:课程名称 学号 分数 //主键(课程名称,学号)
2019-07-29 - cricket1981 👍(3) 💬(1)
为什么不把BCNF称为第4范式?难道BCNF是后来发现的?
2019-07-30 - 丁丁历险记 👍(2) 💬(2)
反范式是典型的时间换空间套路,方便已不同纬度去统计
2019-12-28 - 吃饭饭 👍(2) 💬(1)
区分 2NF 和 3NF 的关键点在于 2NF:非主键列是否完全依赖于主键,还是依赖于主键的一部分; 3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列
2019-08-02 - X5N 👍(2) 💬(1)
太好了!我还以为这门课不会讲到“三范式”呢,希望老师在课程中多讲些与“数据库设计”,“表设计”…相关的内容。感谢! …………………… 关于课后练习题,是否可以把“学生选课表”拆分成3个表。 1.学生表:学号(主键),姓名,系别(外键)。 2.成绩表:课程名称,学号,分数(课程名称和学号,一起构成联合主键)。 3.院系表:系别(主键),系主任。 这样似乎就符合3NF的要求了。
2019-07-29