加餐01 Text to SQL:自然语言写SQL查询
你好,我是陈博士。
在AI时代,很多业务人员可以不写SQL就进行数据查询,他们可以通过自然语言向数据库进行提问。这依赖于一种技术,称为Text to SQL。
Text to SQL 技术
Text-to-SQL(文本转 SQL)是将自然语言问题自动转换为结构化的 SQL 查询语句,这样可以让用户更直观的与数据库进行交互。Text-to-SQL的技术演变经历了3个阶段。
- 早期阶段:依赖于人工编写的规则模板,来匹配自然语言和SQL语句之间的对应关系。
- 机器学习阶段:采用序列到序列模型等机器学习方法,来学习自然语言和SQL之间的映射关系。
- LLM 阶段:借助 LLM 强大的语言理解和代码生成能力,利用提示工程、微调等方法将 Text-to-SQL 性能提升到新的高度。
我们目前已处于LLM阶段,基于 LLM 的 Text-to-SQL 系统会包含以下几个步骤:
- 自然语言理解:分析用户输入的自然语言问题,理解其意图和语义。
- 模式链接:将问题中的实体与数据库模式中的表和列进行链接。
- SQL 生成:根据理解的语义和模式链接结果,生成相应的 SQL 查询语句。
- SQL 执行:在数据库上执行SQL查询,将结果返回给用户。
LLM 模型选择
下面我按照闭源、开源、代码大模型,推荐一些我比较常用的大模型。
闭源模型
- GPT-o1-mini:o1模型开启了新的Scaling Law,更专注于推理阶段,在编程和Text to SQL中能力优于GPT-4o,同时mini模型速度更快,价格更低。
- Claude 3.5-sonnet:Anthropic公司发布,支持20万token上下文,性能超过GPT-4o,在Cursor中使用非常顺滑。
- Gemini Pro-1.5:性能强悍,支持100万token上下文。
- Qwen-Turbo:支持100万token上下文,速度快,价格非常便宜。
开源模型
- Qwen:Qwen系列有0.5B、1.5B、3B、7B、14B、32B、72B等多种尺寸,性能优于Llama3.1。
代码大模型
- Qwen-coder:能力强,接近闭源一线大模型,其中Qwen2.5-Coder-32B能力与GPT-4o持平,略落后于Claude 3.5 Haiku。
- CodeGeeX:智谱开源的代码大模型,基于GLM底座,性能卓越,在 VSCode 等编辑器中可以找到对应的插件。
- SQLCoder:专为 SQL 生成而设计的开源模型,但是维护更新慢。
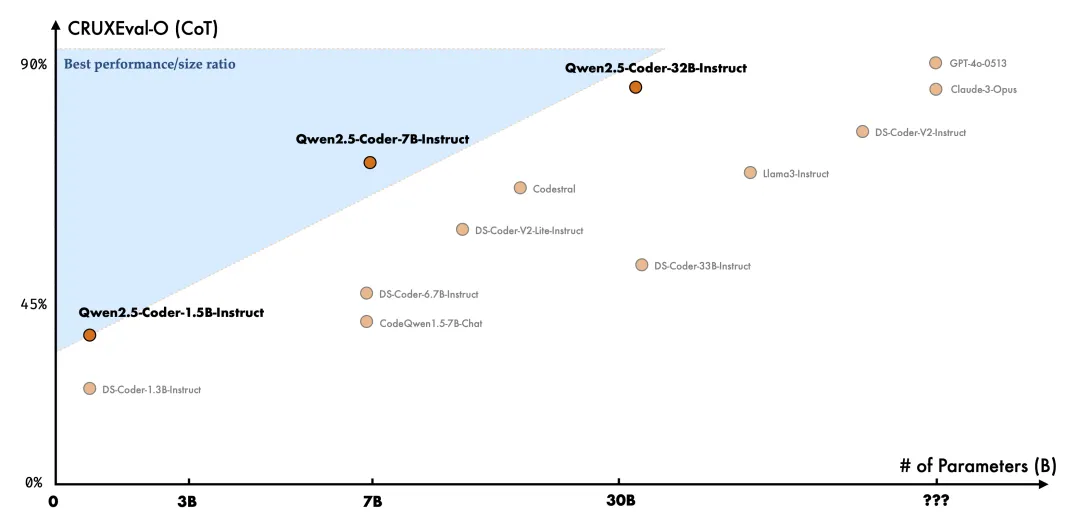
如果是基于数据安全性考虑,可以在本地部署Qwen-7B/72B等开源模型,同时可以进行对话和撰写SQL。如果很重视代码质量(包括SQL),可以部署Qwen-Coder专门用于代码生成。
如果查询的数据是公开的,或者不需要过多考虑数据安全性,可以使用Qwen-Turbo,性能和价格都非常好,通过API调用省去了自己部署的成本。当然你也可以调用o1、Gemini、Claude 等国外最先进的模型,进行SQL的对比和优化。
Text to SQL 工作流程优化
为了让LLM生成高质量的SQL查询语句,你可以使用以下的技术:
- 提示工程(Prompt Engineering):设计更有效的提示模板,以引导 LLM 生成更准确的 SQL 查询语句。
- 上下文学习(In-Context Learning):在提示中提供一些示例,以帮助 LLM 更好地理解任务。
- 推理增强:使用一些技术来增强 LLM 的推理能力,例如使用多步推理方法。
- 执行优化:对生成的 SQL 查询语句进行优化,以提高其执行效率。
这里我们重点讲解下,如何通过prompt更有效地驱动LLM编写SQL。
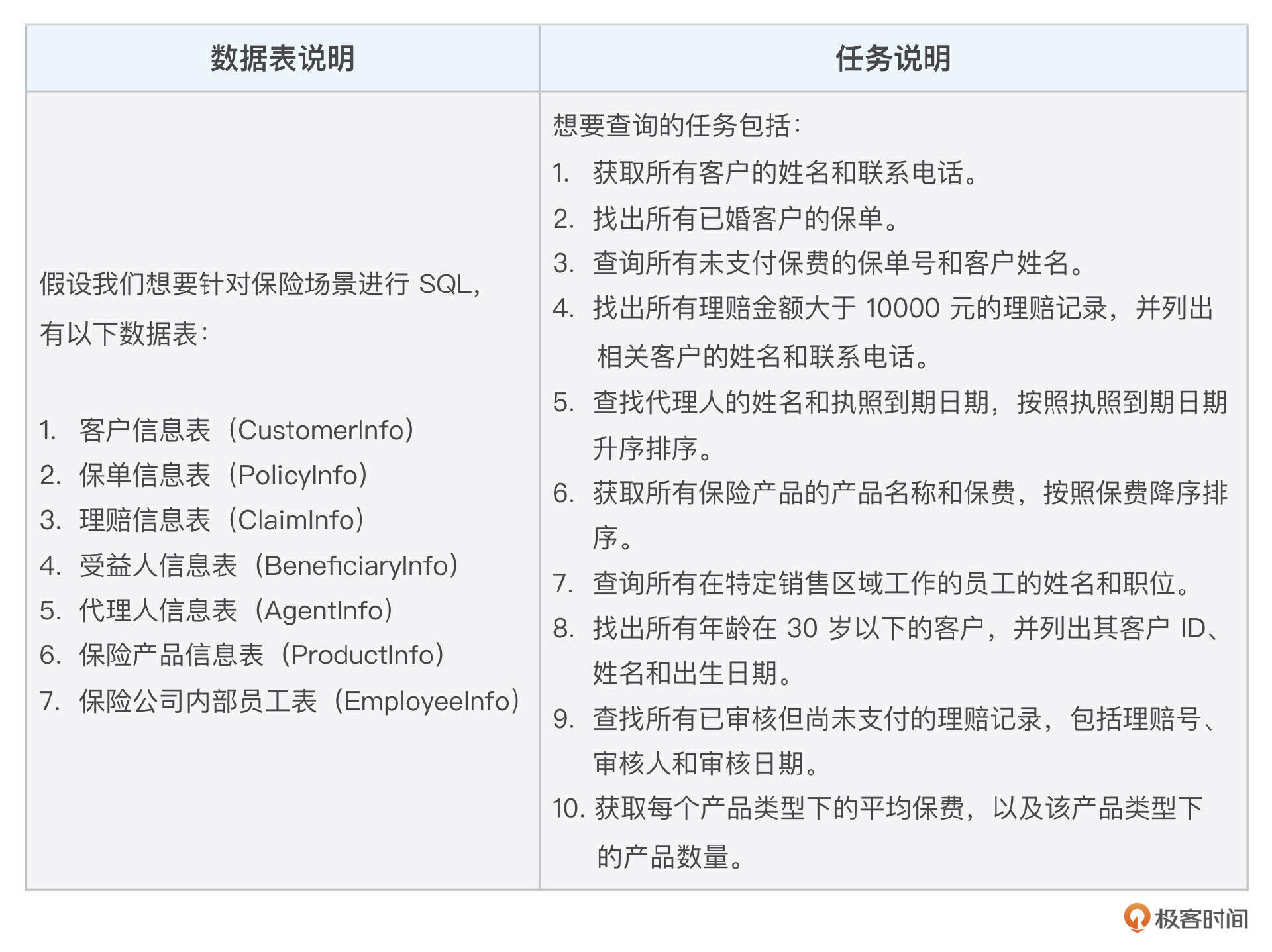

SQL prompt template 撰写:
方法1:
prompt = f"""# language: SQL
/*
{query}你需要先判断需要哪个数据表和字段,然后基于它们编写SQL。数据库中有以下数据表:
=====
{table_description}
*/
方法2:
prompt = f"""
-- language: SQL
/*{query}
以下是数据表
=====
{table_description}
=====
编写一条SQL: {query}
*/"""
方法3:
prompt = f"""-- language: SQL
### Question: {query}
### Input: {create_sql}
### Response:
Here is the SQL query I have generated to answer the question `{query}`:
```sql
"""
说明:
- table_description 代表中文的数据表说明

- create_sql 代表建表语句

- query 是用户查询的问题
这里我想请你先思考下:你觉得方法 1-3,哪个写法更容易让 LLM 生成高质量的 SQL?
揭晓答案,方法3的SQL生成质量最高,这是因为:
- create_sql建表语句更适合LLM理解数据表的内容,而且携带了更多的字段定义信息。大模型通过几十亿行的代码训练,包括SQL代码,所以SQL建表语句对于大模型来说更容易理解。
- language:SQL前面的注释要用 --,因为SQL的注释是 --,而Python会用#进行注释。
- 如果我们使用的是代码大模型,它的本质是代码补全,因此最后一句 ```sql 可以让大模型直接写出SQL。否则大模型有可能会在前面进行一堆文字描述,然后才写SQL,你需要对后面的SQL专门进行解析。
我对表格中的10个任务都采用方法1-3进行了实验,在CodeGeeX2-6B的大模型下,采用方法3可以得到10个全对的结果,而采用方法1和方法2,只对了8个。所以你能看出,高质量的 prompt template 可以让 LLM 生成高质量的 SQL。
那么,在接下来的几节课中,我将给你讲述不同场景下的SQL查询需求。当然通过这些场景示例,你也可以看到Text to SQL的撰写能力。另外我也建议你,作为数据分析师,掌握基本的SQL语法还是很有必要的,因为大模型现在还很难做到100%正确。此外自己掌握SQL撰写能力,也有助于SQL语句的校验和优化,当然对于prompt的撰写也是很有帮助的。
好,这节课就到这里,如果今天的内容对你有所帮助,也欢迎你转发给有需要的朋友,一起学习。我们下节课再见!
- 赞迪 👍(0) 💬(0)
牛哇!良心!
2025-01-23