01 快速入门:Rust中有哪些你不得不了解的基础语法?
你好,我是Mike。今天是我们的Rust入门与实战第一讲。
无论对人,还是对事儿,第一印象都很重要,Rust也不例外。今天我们就来看一看Rust给人的第一印象是什么吧。其实Rust宣称的安全、高性能、无畏并发这些特点,初次接触的时候都是感受不到的。第一次能直观感受到的实际是下面这些东西。
- Rust代码长什么样儿?
- Rust在编辑器里面体验如何?
- Rust工程如何创建?
- Rust程序如何编译、执行?
下面我们马上下载安装Rust,快速体验一波。
下载安装
要做Rust编程开发,安装Rust编译器套件是第一步。如果是在MacOS或Linux下,只需要执行:
按提示执行操作,就安装好了,非常方便。
而如果你使用的是Windows系统,那么会有更多选择。你既可以在WSL中开发编译Rust代码,也可以在Windows原生平台上开发Rust代码。
如果你计划在WSL中开发,安装方式与上面一致。
如果想在Windows原生平台上开发Rust代码,首先需要确定安装 32 位的版本还是 64 位的版本。在安装过程中,它会询问你是想安装GNU工具链的版本还是MSVC工具链的版本。安装GNU工具链版本的话,不需要额外安装其他软件包。而安装MSVC工具链的话,需要先安装微软的 Visual Studio 依赖。
如果你暂时不想在本地安装,或者本地安装有问题,对于我们初学者来说,也有一个方便、快捷的方式,就是Rust语言官方提供的一个网页端的 Rust 试验场,可以让你快速体验。

这个网页Playground非常方便,可以用来快速验证一些代码片段,也便于将代码分享给别人。如果你的电脑本地没有安装Rust套件,可以临时使用这个Playground学习。
编辑器/ IDE
开发Rust,除了下载、安装Rust本身之外,还有一个工具也推荐你使用,就是VS Code。需要提醒你的是,在VS Code中需要安装 rust-analyzer 插件才会有自动提示等功能。你可以看一下VS Code编辑Rust代码的效果。
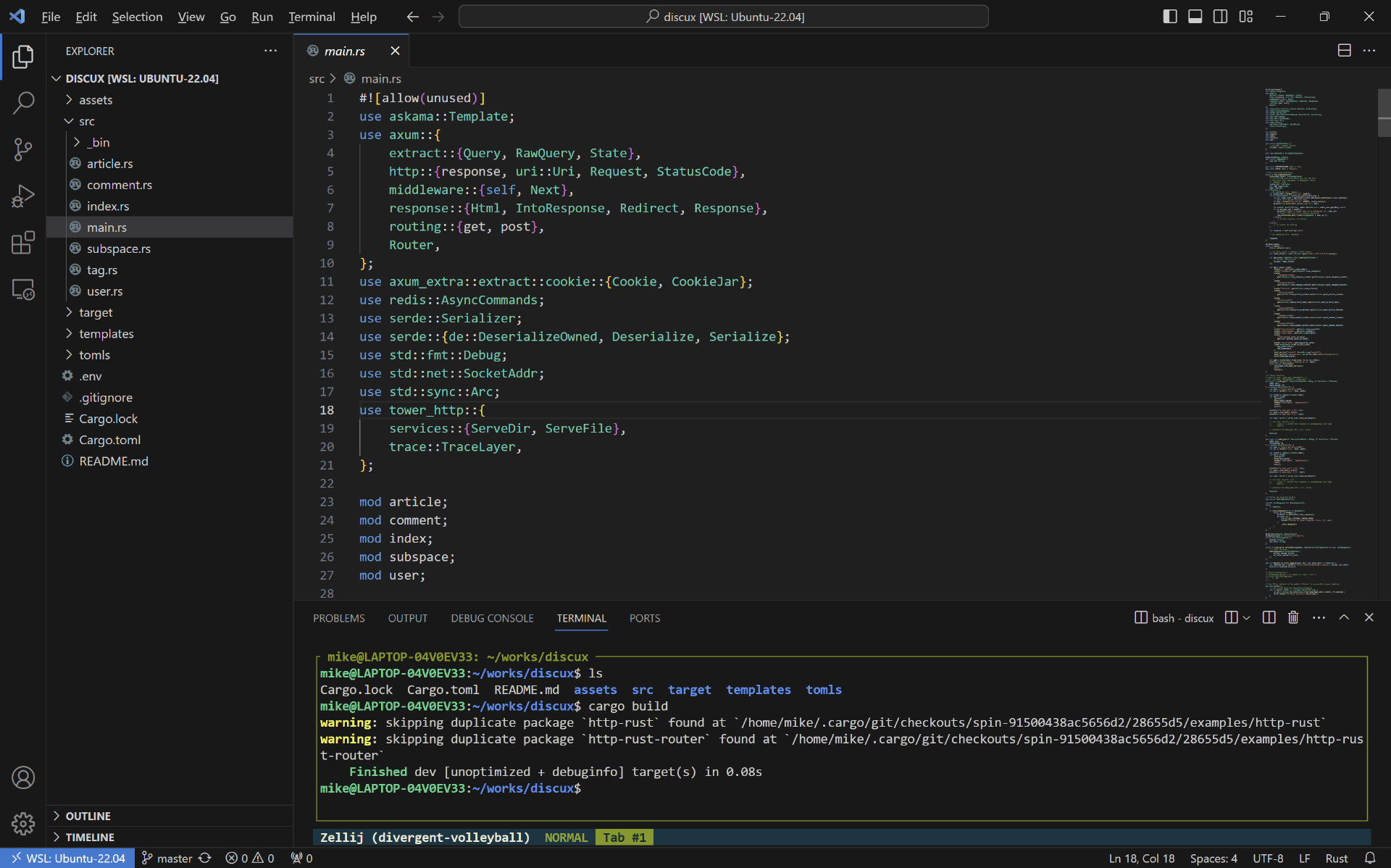
VS Code功能非常强大,除了基本的IDE功能外,还能实现远程编辑。比如在Windows下开发,代码放在WSL Linux里面,在Windows Host下使用VS Code远程编辑WSL中的代码,体验非常棒。
其他一些常用的Rust代码编辑器还有VIM、NeoVIM、IDEA、Clion等。JetBrains最近推出了Rust专用的IDE:RustRover,如果有精力的话,你也可以下载下来体验一下。
Rust编译器套件安装好之后,会提供一些工具,这里我们选几个主要的简单介绍一下。
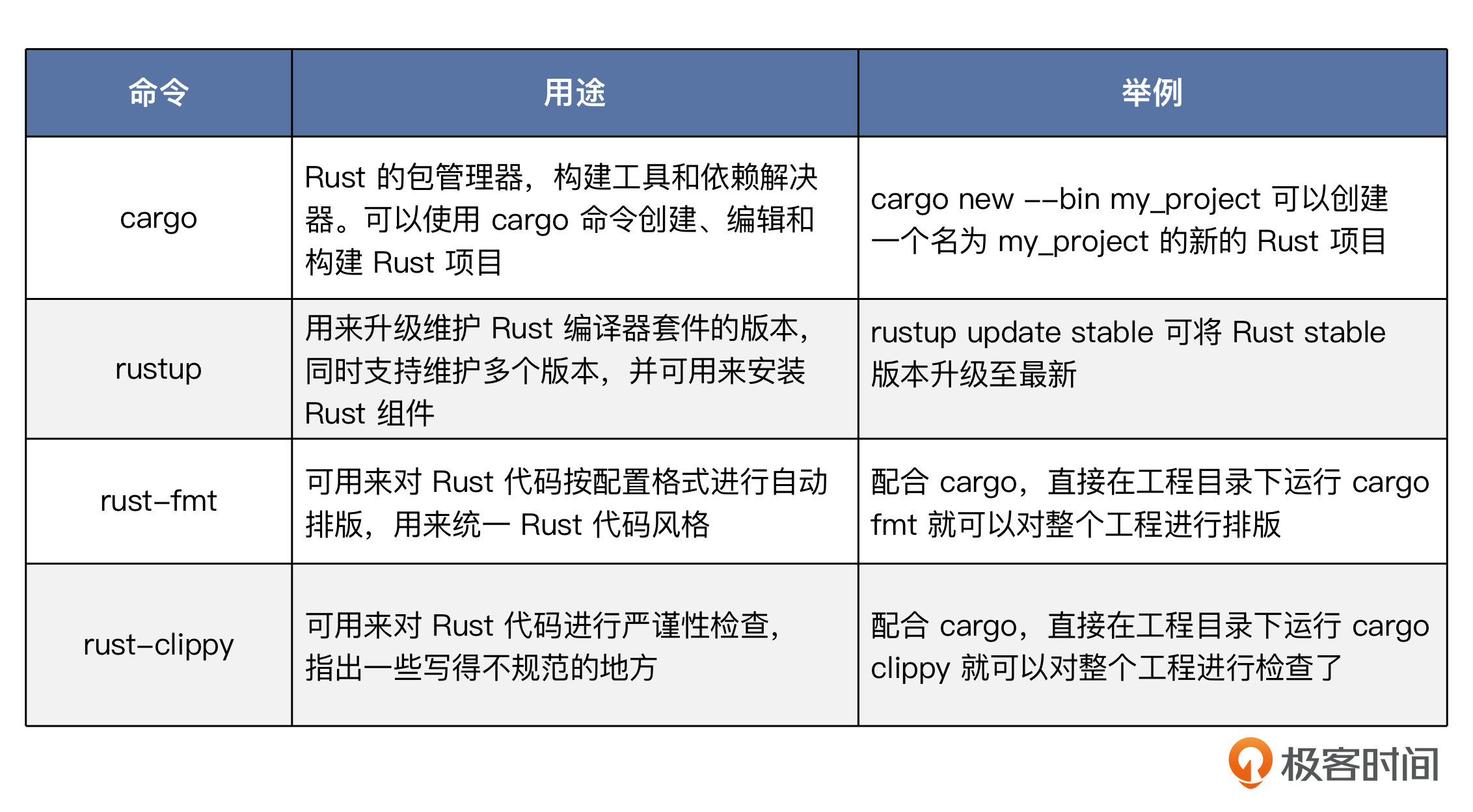
工具齐备了,下面我们马上体验起来,先来创建一个Rust工程。
创建一个工程
创建工程我们应该使用哪个工具呢? 没错,就是刚刚我们提到的 cargo 命令行工具。我们用它来创建一个Rust工程 helloworld。
打开终端,输入:
显示:
这样就创建好了一个新工程。这个新工程的目录组织结构是这样的:
第一层是一个src目录和一个Cargo.toml配置文件。src是放置源代码的地方,而Cargo.toml是这个工程的配置文件,我们来看一下里面的内容。
[package]
name = "helloworld"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Cargo.toml中包含package等基本信息,里面有名字、版本和采用的Rust版次。Rust 3 年发行一个版次,目前有2015、2018和2021版次,最新的是2021版次,也是我们这门课使用的版次。可以执行 rustc -V 来查看我们课程使用的Rust版本。
好了,一切就绪后,我们可以来看看src下的main.rs里面的代码。
Hello, World
这段代码的意思是,我们要在终端输出这个 "Hello, world!" 的字符串。
使用 cargo build 来编译。
$ cargo build
Compiling helloworld v0.1.0 (/home/mike/works/classes/helloworld)
Finished dev [unoptimized + debuginfo] target(s) in 1.57s
使用 cargo run 命令可以直接运行程序。
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/helloworld`
Hello, world!
可以看到,最后终端打印出了 Hello, world。我们成功地执行了第一个Rust程序。
Rust基础语法
快速体验 Hello World 后,你是不是对Rust 已经有了一个感性的认识?不过只是会Hello World的话,我们离入门Rust尚远。下面我们就从Rust的基础语法入手开始了解这门语言,为今后使用Rust编程打下一个良好的基础。
Rust基础语法主要包括基础类型、复合类型、控制流、函数与模块几个方面,下面我带你一个一个看。
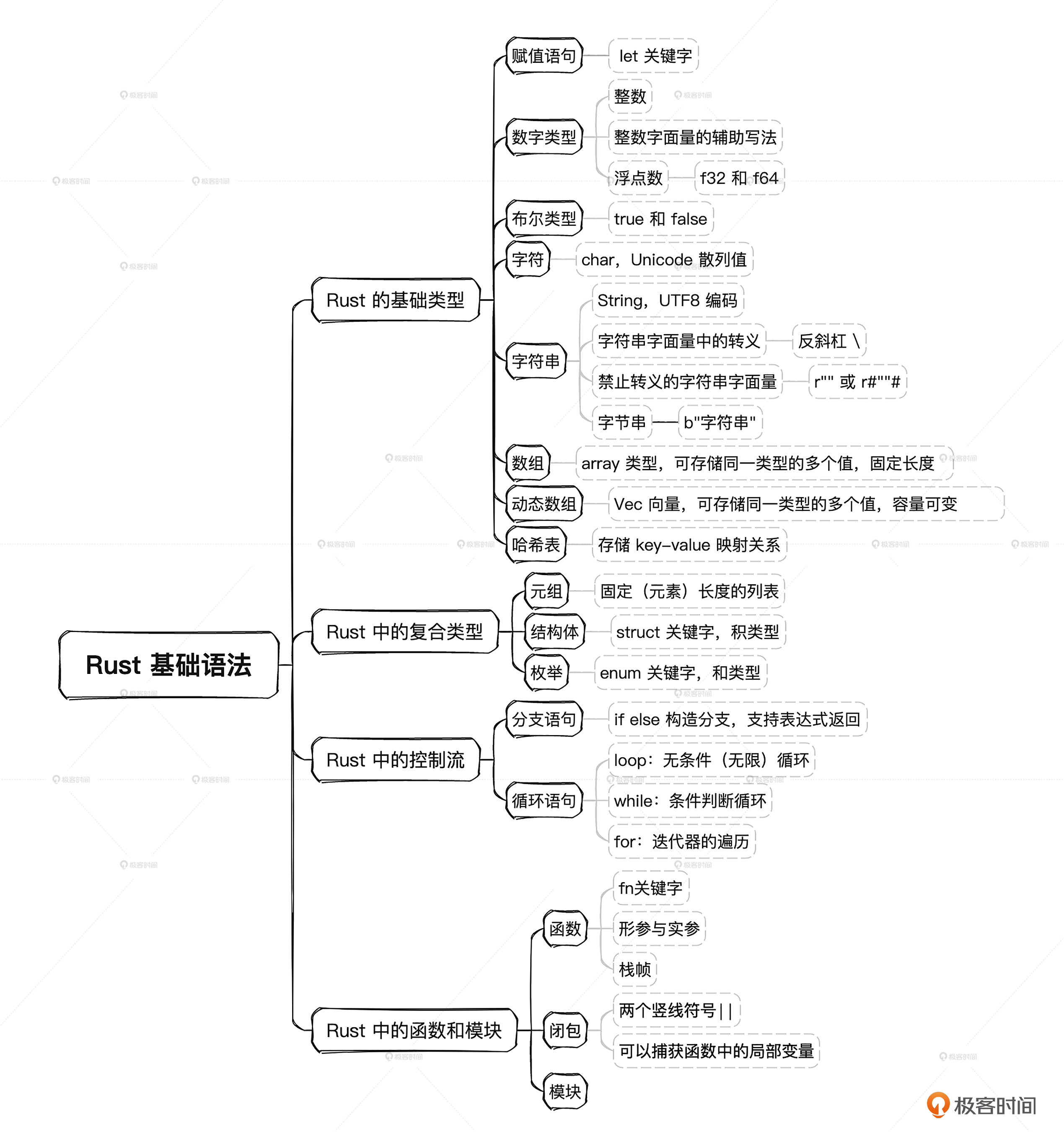
Rust的基础类型
赋值语句
Rust中使用 let 关键字定义变量及初始化,你可以看一下我给出的这个例子。
可以看到,Rust中类型写在变量名的后面,例子里变量a的类型是u32, 也就是无符号32位整数,赋值为1。Rust保证你定义的变量在第一次使用之前一定被初始化过。
数字类型
与一些动态语言不同,Rust中的数字类型是区分位数的。我们先来看整数。
整数
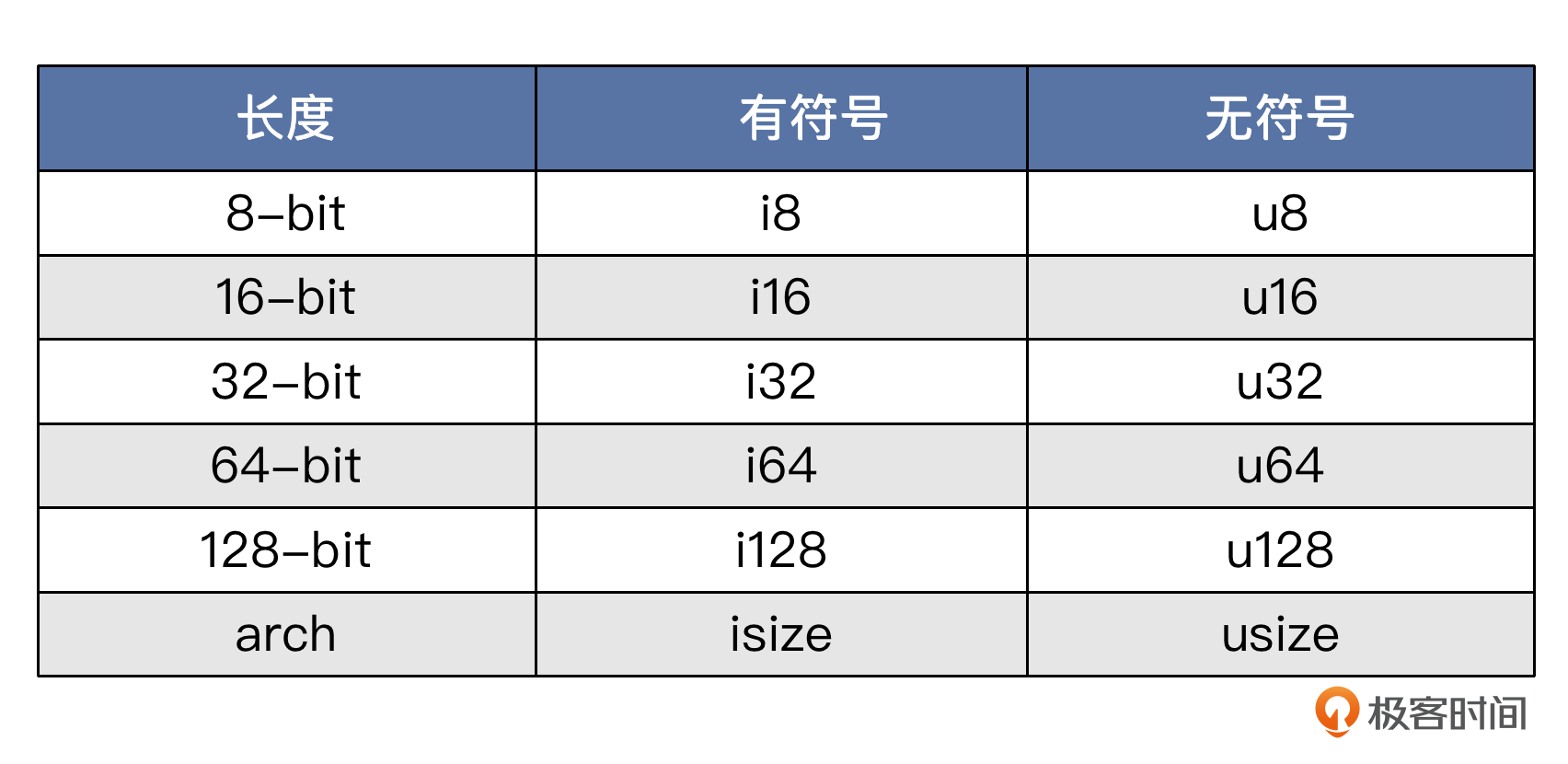
其中,isize和usize的位数与具体CPU架构位数有关。CPU是64位的,它们就是64位的,CPU是32位的,它们就是32位的。这些整数类型可以在写字面量的时候作为后缀跟在后面,来直接指定值的类型,比如 let a = 10u32; 就定义了一个变量a,初始化成无符号32位整型,值为10。
整数字面量的辅助写法
Rust提供了灵活的数字表示方法,便于我们编写整数字面量。比如:
十进制字面量 98_222,使用下划线按三位数字一组隔开
十六进制字面量 0xff,使用0x开头
8进制字面量 0o77,使用0o(小写字母o)开头
二进制字面量 0b1111_0000,使用0b开头,按4位数字一组隔开
字符的字节表示 b'A',对一个ASCII字符,在其前面加b前缀,直接得到此字符的ASCII码值
各种形式的辅助写法是为了提高程序员写整数字面量的效率,同时更清晰,更不容易犯错。
浮点数
浮点数有两种类型:f32和f64,分别代表32位浮点数类型和64位浮点数类型。它们也可以跟在字面量的后面,用来指定浮点数值的类型,比如 let a = 10.0f32; 就定义了一个变量a,初始化成32位浮点数类型,值为10.0。
布尔类型
Rust中的布尔类型为 bool,它只有两个值,true 和 false。
字符
Rust中的字符类型是 char,值用单引号括起来。
Rust的 char 类型存的是 Unicode 散列值。这意味着它可以表达各种符号,比如中文符号、emoji符号等。在Rust中,char类型在内存中总是占用 4 个字节大小。这一点与C语言或其他某些语言中的char有很大不同。
字符串
Rust中的字符串类型是 String。虽然中文表述上,字符串只比前面的字符类型多了一个串字,但它们内部存储结构完全不同。String内部存储的是Unicode字符串的UTF8编码,而char直接存的是Unicode Scalar Value(二者的区别可查阅这里)。也就是说 String不是char的数组,这点与C语言也有很大区别。
通过下面示例我们可以看到,Rust字符串对Unicode字符集有着良好的支持。
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שָׁלוֹם");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
注意,Rust中的String不能通过下标去访问。
为什么呢?你可以想一想。因为String存储的Unicode序列的UTF8编码,而UTF8编码是变长编码。这样即使能访问成功,也只能取出一个字符的UTF8编码的第一个字节,它很可能是没有意义的。因此Rust直接对String禁止了这个索引操作。
字符串字面量中的转义
与C语言一样,Rust中转义符号也是反斜杠 \ ,可用来转义各种字符。你可以运行我给出的这几个示例来理解一下。
fn main() {
// 将""号进行转义
let byte_escape = "I'm saying \"Hello\"";
println!("{}", byte_escape);
// 分两行打印
let byte_escape = "I'm saying \n 你好";
println!("{}", byte_escape);
// Windows下的换行符
let byte_escape = "I'm saying \r\n 你好";
println!("{}", byte_escape);
// 打印出 \ 本身
let byte_escape = "I'm saying \\ Ok";
println!("{}", byte_escape);
// 强行在字符串后面加个0,与C语言的字符串一致。
let byte_escape = "I'm saying hello.\0";
println!("{}", byte_escape);
}
除此之外,Rust还支持通过 \x 输入等值的ASCII字符,以及通过 \u{} 输入等值的Unicode字符。你可以看一下我给出的这两个例子。
fn main() {
// 使用 \x 输入等值的ASCII字符(最高7位)
let byte_escape = "I'm saying hello \x7f";
println!("{}", byte_escape);
// 使用 \u{} 输入等值的Unicode字符(最高24位)
let byte_escape = "I'm saying hello \u{0065}";
println!("{}", byte_escape);
}
注:字符串转义的详细知识点,请参考 Tokens - The Rust Reference (rust-lang.org)。
禁止转义的字符串字面量
有时候,我们不希望字符串被转义,也就是想输出原始字面量。这个在Rust中也有办法,使用 r"" 或 r#""# 把字符串字面量套起来就行了。
fn main() {
// 字符串字面量前面加r,表示不转义
let raw_str = r"Escapes don't work here: \x3F \u{211D}";
println!("{}", raw_str);
// 这个字面量必须使用r##这种形式,因为我们希望在字符串字面量里面保留""
let quotes = r#"And then I said: "There is no escape!""#;
println!("{}", quotes);
// 如果遇到字面量里面有#号的情况,可以在r后面,加任意多的前后配对的#号,
// 只要能帮助Rust编译器识别就行
let longer_delimiter = r###"A string with "# in it. And even "##!"###;
println!("{}", longer_delimiter);
}
一点小提示,Rust中的字符串字面量都支持换行写,默认把换行符包含进去。
字节串
很多时候,我们的字符串字面量中用不到Unicode字符,只需要ASCII字符集。对于这种情况,Rust还有一种更紧凑的表示法:字节串。用b开头,双引号括起来,比如 b"this is a byte string"。这时候字符串的类型已不是字符串,而是字节的数组 [u8; N],N为字节数。
你可以在Playground里面运行一下代码,看看输出什么。
fn main() {
// 字节串的类型是字节的数组,而不是字符串了
let bytestring: &[u8; 21] = b"this is a byte string";
println!("A byte string: {:?}", bytestring);
// 可以看看下面这串打印出什么
let escaped = b"\x52\x75\x73\x74 as bytes";
println!("Some escaped bytes: {:?}", escaped);
// 字节串与原始字面量结合使用
let raw_bytestring = br"\u{211D} is not escaped here";
println!("{:?}", raw_bytestring);
}
字节串很有用,特别是在做系统级编程或网络协议开发的时候,经常会用到。
数组
Rust中的数组是array类型,用于存储同一类型的多个值。数组表示成[T; N],由中括号括起来,中间用分号隔开,分号前面表示类型,分号后面表示数组长度。
Rust中的数组是固定长度的,也就是说在编译阶段就能知道它占用的字节数,并且在运行阶段,不能改变它的长度(尺寸)。
听到这里你是不是想说,这岂不是很麻烦?Rust中的数组竟然不能改变长度。这里我解释一下,Rust中区分固定尺寸数组和动态数组。之所以做这种区分是因为Rust语言在设计时就要求适应不同的场合,要有足够的韧性能在不同的场景中都达到最好的性能。因为固定尺寸的数据类型是可以直接放栈上的,创建和回收都比在堆上动态分配的动态数组性能要好。
是否能在编译期计算出某个数据类型在运行过程中占用内存空间的大小,这个指标很重要,Rust的类型系统就是按这个对类型进行分类的。后面的课程中我们会经常用到这个指标。
数组常用于开辟一个固定大小的Buffer(缓冲区),用来接收IO输入输出等。也常用已知元素个数的字面量集合来初始化,比如表达一年有12个月。
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
数组的访问,可以用下标索引。
我们再来看看,如果下标索引越界了会发生什么。
提示:
Compiling playground v0.0.1 (/playground)
error: this operation will panic at runtime
--> src/main.rs:3:13
|
3 | let b = a[5];
| ^^^^ index out of bounds: the length is 5 but the index is 5
这时候你可能已经发现了,Rust在编译的时候,就给我们指出了问题,说这个操作会在运行的时候崩溃。为什么Rust能指出来呢?就是因为数组的长度是确定的,Rust在编译时就分析并提取了这个数组类型占用空间长度的信息,因此直接阻止了你的越界访问。
不得不说,Rust太贴心了。
动态数组
Rust中的动态数组类型是Vec(Vector),也就是向量,中文翻译成动态数组。它用来存储同一类型的多个值,容量可在程序运行的过程中动态地扩大或缩小,因此叫做动态数组。
fn main() {
let v: Vec<i32> = Vec::new();
let v = vec![1, 2, 3];
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}
动态数组可以用下标进行索引访问。
比如:
fn main() {
let s1 = String::from("superman 1");
let s2 = String::from("superman 2");
let s3 = String::from("superman 3");
let s4 = String::from("superman 4");
let v = vec![s1, s2, s3, s4];
println!("{:?}", v[0]);
}
// 输出
"superman 1"
如果我们下标越界了会发生什么?Rust能继续帮我们提前找出问题来吗?试一试就知道了。
fn main() {
let s1 = String::from("superman 1");
let s2 = String::from("superman 2");
let s3 = String::from("superman 3");
let s4 = String::from("superman 4");
let v = vec![s1, s2, s3, s4];
// 这里下标访问越界了
println!("{:?}", v[4]);
}
运行后,出现了提示。
Compiling playground v0.0.1 (/playground)
Finished dev [unoptimized + debuginfo] target(s) in 0.62s
Running `target/debug/playground`
thread 'main' panicked at 'index out of bounds: the len is 4 but the index is 4', src/main.rs:9:22
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
可以看到,这段代码正确通过了编译,但在运行的时候出错了,并且导致了主线程的崩溃。
你可以将其与前面讲的数组array下标越界时的预警行为对比理解。为什么array的越界访问能在编译阶段检查出来,而Vec的越界访问不能在编译阶段检查出来呢?你可以好好想一想。
哈希表
哈希表是一种常见的结构,用于存储Key-Value映射关系,基本在各种语言中都有内置提供。Rust中的哈希表类型为HashMap。对一个HashMap结构来说,Key要求是同一种类型,比如是字符串就统一用字符串,是数字就统一用数字。Value也是一样,要求是同一种类型。Key和Value的类型不需要相同。
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
}
因为哈希表能从一个键索引到一个值,所以应用场景非常广泛,后面我们还会仔细分析它的用法。
Rust中的复合类型
复合类型可以包含多种基础类型,是一种将类型进行有效组织的方式,提供了一级一级搭建更高层类型的能力。Rust中的复合类型包括元组、结构体、枚举等。
元组
元组是一个固定(元素)长度的列表,每个元素类型可以不一样。用小括号括起来,元素之间用逗号隔开。例如:
元组元素的访问:
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
// 元组使用.运算符访问其元素,下标从0开始,注意语法
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}
与数组的相同点是,它们都是固定元素个数的,在运行时不可伸缩。与数组的不同点是,元组的每个元素的类型可以不一样。元组在Rust中很有用,因为它可以用于函数的返回值,相当于把多个想返回的值捆绑在一起,一次性返回。
当没有任何元素的时候,元组退化成 (),就叫做unit类型,是Rust中一个非常重要的基础类型和值,unit类型唯一的值实例就是(),与其类型本身的表示相同。比如一个函数没有返回值的时候,它实际默认返回的是这个unit值。
结构体
结构体也是一种复合类型,它由若干字段组成,每个字段的类型可以不一样。Rust中使用 struct 关键字来定义结构体。比如下面的代码就定义了一个User类型。
下面这段代码演示了结构体类型的实例化。
fn main() {
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
age: 1,
};
}
枚举
Rust中使用 enum 关键字定义枚举类型。比如:
枚举类型里面的选项叫做此枚举的变体(variants)。变体是其所属枚举类型的一部分。
枚举使用变体进行枚举类型的实例化,比如:
可以看到,枚举类型也是一种复合类型。但是与结构体不同,结构体类型是里面的所有字段(所有类型)同时起作用,来产生一个具体的实例,而枚举类型是其中的一个变体起作用,来产生一个具体实例,这点区别可以细细品味。学术上,通常把枚举叫作和类型(sum type),把结构体叫作积类型(product type)。
枚举类型是Rust中最强大的复合类型,在后面的课程中我们会看到,枚举就像一个载体,可以携带任何类型。
Rust中的控制流
下面我们来了解一下Rust语言的控制流语句。
分支语句
Rust中使用if else来构造分支。
fn main() {
let number = 6;
// 判断数字number能被4,3,2中的哪一个数字整除
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}
与其他C系语言不同,Rust中 if 后面的条件表达式不推荐用()包裹起来,因为Rust设计者认为那个是不必要的,是多余的语法噪音。
还要注意一点,if else 支持表达式返回。
fn main() {
let x = 1;
// 在这里,if else 返回了值
let y = if x == 0 {
// 代码块结尾最后一句不加分号,表示把值返回回去
100
} else {
// 代码块结尾最后一句不加分号,表示把值返回回去
101
};
println!("y is {}", y);
}
像上面这样的代码,其实已经实现了类似于C语言中的三目运算符这样的设计,在Rust中,不需要额外提供那样的特殊语法。
循环语句
Rust中有三种循环语句,分别是loop、while、for。
- loop用于无条件(无限)循环。
fn main() {
let mut counter = 0;
// 这里,接收从循环体中返回的值,对result进行初始化
let result = loop {
counter += 1;
if counter == 10 {
// 使用break跳出循环,同时带一个返回值回去
break counter * 2;
}
};
println!("The result is {result}");
}
请仔细品味这个例子,这种返回一个值到外面对一个变量初始化的方式,是Rust中的习惯用法,这能让代码更紧凑。
- while循环为条件判断循环。当后面的条件为真的时候,执行循环体里面的代码。和前面的 if 语句一样,Rust中的 while 后面的条件表达式不推荐用()包裹起来。比如:
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number -= 1;
}
println!("LIFTOFF!!!");
}
- for循环在Rust中,基本上只用于迭代器(暂时可以想象成对数组,动态数组等)的遍历。Rust中没有C语言那种for循环风格的语法支持,因为那被认为是一种不好的设计。
你可以看一下下面的代码,就是对一个数组进行遍历。
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}
}
上面代码对动态数组Vec的遍历阻止了越界的可能性,因此用这种方式访问Vec比用下标索引的方式访问更加安全。
对于循环的场景,Rust还提供了一个便捷的语法来生成遍历区间: ..(两个点)。
请看下面的示例。
fn main() {
// 左闭右开区间
for number in 1..4 {
println!("{number}");
}
println!("--");
// 左闭右闭区间
for number in 1..=4 {
println!("{number}");
}
println!("--");
// 反向
for number in (1..4).rev() {
println!("{number}");
}
}
// 输出
1
2
3
--
1
2
3
4
--
3
2
1
我们再来试试打印字符。
fn main() {
for ch in 'a'..='z' {
println!("{ch}");
}
}
// 输出:
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
嘿,Rust很智能啊!
Rust中的函数和模块
最后我们来看Rust的函数、闭包和模块,它们用于封装和复用代码。
函数
函数基本上是所有编程语言的标配,在Rust中也不例外,它是一种基本的代码复用方法。在Rust中使用 fn 关键字来定义一个函数。比如:
fn print_a_b(a: i32, b: char) {
println!("The value of a b is: {a}{b}");
}
fn main() {
print_a_b(5, 'h');
}
函数定义时的参数叫作形式参数(形参),函数调用时传入的参数值叫做实际参数(实参)。函数的调用要与函数的签名(函数名、参数个数、参数类型、参数顺序、返回类型)一致,也就是实参和形参要匹配。
函数对于几乎所有语言都非常重要,实际上各种编程语言在实现时,都是以函数作为基本单元来组织栈上的内存分配和回收的,这个基本的内存单元就是所谓的栈帧(frame),我们在下节课会讲到。
闭包(Closure)
闭包是另一种风格的函数。它使用两个竖线符号 || 定义,而不是用 fn () 来定义。你可以看下面的形式对比。
// 标准的函数定义
fn add_one_v1 (x: u32) -> u32 { x + 1 }
// 闭包的定义,请注意形式对比
let add_one_v2 = |x: u32| -> u32 { x + 1 };
// 闭包的定义2,省略了类型标注
let add_one_v3 = |x| { x + 1 };
// 闭包的定义3,花括号也省略了
let add_one_v4 = |x| x + 1 ;
注:可参考完整代码链接
闭包与函数的一个显著不同就是,闭包可以捕获函数中的局部变量为我所用,而函数不行。比如,下面示例中的闭包 add_v2 捕获了main函数中的局部变量 a 来使用,但是函数 add_v1 就没有这个能力。
fn main() {
let a = 10u32; // 局部变量
fn add_v1 (x: u32) -> u32 { x + a } // 定义一个内部函数
let add_v2 = |x: u32| -> u32 { x + a }; // 定义一个闭包
let result1 = add_v1(20); // 调用函数
let result2 = add_v2(20); // 调用闭包
println!("{}", result2);
}
这样会编译出错,并提示错误。
error[E0434]: can't capture dynamic environment in a fn item
--> src/main.rs:4:40
|
4 | fn add_v1 (x: u32) -> u32 { x + a } // 定义一个内部函数
| ^
|
= help: use the `|| { ... }` closure form instead
闭包之所以能够省略类型参数等信息,主要是其定义在某个函数体内部,从闭包的内容和上下文环境中能够分析出来那些类型信息。
模块
我们不可能把所有代码都写在一个文件里面。代码量多了后,分成不同的文件模块书写是非常自然的事情。这个需求需要从编程语言层级去做一定的支持才行,Rust也提供了相应的方案。
分文件和目录组织代码理解起来其实很简单,主要的知识点在于目录的组织结构上。比如下面示例:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden // 子目录
│ └── vegetables.rs
├── garden.rs // 与子目录同名的.rs文件,表示这个模块的入口
└── main.rs
第五行代码到第七行代码组成 garden 模块,在 garden.rs 中,使用 mod vegetables; 导入 vegetables 子模块。
在main.rs中,用同样的方式导入 garden 模块。
整个代码结构就这样一层一层地组织起来了。
另一种文件的组织形式来自2015 版,也很常见,有很多人喜欢用。
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden // 子目录
│ └── mod.rs // 子目录中有一个固定文件名 mod.rs,表示这个模块的入口
│ └── vegetables.rs
└── main.rs
同上,由第五行到第七行代码组成garden模块,在 main.rs 中导入它使用。
你可以在本地创建文件,来体会两种不同目录组织形式的区别。
测试
Rust语言中自带单元测试和集成测试方案。我们来看一个示例,在src/lib.rs 或 src/main.rs 下有一段代码。
fn foo() -> u32 { 10u32 }
#[cfg(test)] // 这里配置测试模块
mod tests {
use crate::foo;
#[test] // 具体的单元测试用例
fn it_works() {
let result = foo(); // 调用被测试的函数或功能
assert_eq!(result, 10u32); // 断言
}
}
在项目目录下运行 cargo test,会输出类似如下结果。
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Rust自带测试方案,让我们能够非常方便地写测试用例,并且统一了社区的测试设计规范。
配置文件 Cargo.toml
这节课开头的时候,我们简单介绍过Cargo.toml,它是Rust语言包和依赖管理器Cargo的配置文件,由官方定义约定。写Rust代码基本都会按照这种约定来使用它,对所在工程进行配置。这里面其实包含的知识点非常多,后面实战的部分,我们会详细解释用到的特性。
我们要对包依赖这件事情的复杂度有所了解。不知道你有没有听说过 npm依赖黑洞?指的就是Node.js的包依赖太多太琐碎了。这怪不得Node.js,其实Rust也类似。包依赖这件事儿,本身就很复杂,可以说这是软件工程固有的复杂性。对固有复杂性,不能绕弯过,只能正面刚。
幸运的是,Cargo工具已经帮我们搞定了包依赖相关方方面面的麻烦事(此刻C++社区羡慕不已)。为了应对这种复杂性,Cargo工具的提供了非常多的特性,配置起来也相对比较复杂。有兴趣的话,你可以详细了解一下各种配置属性。
小结
这节课我们洋洋洒洒罗列了写一个Rust程序所需要用到的基本的语法结构和数据类型,让你对Rust语言有了一个初步印象。这些知识点虽多,但并不复杂。因为这节课呈现的绝大部分元素都能在其他语言中找到,所以理解起来应该不算太难。
这节课出现了一个比较重要的指标:是否能在编译期计算出某个数据类型在运行过程中占用的内存空间的大小。如果能计算出,那我们称之为固定尺寸的数据类型;如果不能计算出,那我们称之为不固定尺寸的数据类型,或动态数据类型。
其实这也很好理解,因为Rust要尽量在编译期间多做一些事情,帮我们做安全性的检查。而在编译期只有能计算出内存尺寸的数据类型,才能被更详尽地去分析和检查,就是这个原理。
思考题
- Rust中能否实现类似 JS 中的 number 这种通用的数字类型呢?
- Rust中能否实现Python中那种无限大小的数字类型呢?
希望你可以积极思考这几个问题,然后把你的答案分享到评论区,如果你觉得这节课对你有帮助的话,也欢迎你分享给你的朋友,邀他一起学习,我们共同进步。下节课再见!
- 学会用实力去谈条件 👍(23) 💬(3)
推荐几个Rust的VsCode插件 Rust Syntax:语法高亮 crates:分析项目依赖 Even Better Toml:项目配置管理 Rust Test Lens:Rust快速测试
2023-10-31 - warning 👍(7) 💬(7)
看完了Rust语言圣经,再看这个还感觉有些吃力需要时不时的看看之前的笔记。课程并不适合没接触过Rust的小白,需要自己花些时间去找别的资料进行补充
2023-10-28 - 知夫 👍(4) 💬(2)
可以推荐一个项目结构的最佳实践吗? 能囊括lib,bin,示例,单元测试,性能测试等。
2023-11-11 - 草剑 👍(3) 💬(1)
windows 中,不想安装 visual studio,想使用 gnu 工具链: rustup default stable-gnu
2023-11-12 - eriklee 👍(3) 💬(4)
IDE推荐一波RustRover,jetbrains家新出的,现在免费使用阶段
2023-10-24 - 阿五 👍(3) 💬(2)
虽然 Rust 不像 JavaScript 那样具有动态的通用数字类型,但你可以通过使用 num crate 和 Rust 的强类型系统来实现类似的通用数字操作。
2023-10-24 - Levix 👍(2) 💬(1)
https://synctoai.com/rustclosures 看了老师的第一节课,然后觉得闭包有点难理解,跑去问了下 GPT 后,整理出来一篇文档,希望对大家有用。
2023-11-14 - Ransang 👍(2) 💬(2)
闭包那个测试里,为什么main函数里面可以有其他函数,就是fn里面套了一个fn ,他们之间有什么关系吗
2023-11-03 - 🤔 👍(2) 💬(2)
关于char的unicode散列值,gpt4的说明是: Unicode 是一种字符集(Character Set),用于对世界上大多数语言的字符进行编码。不同于 ASCII 码仅包括了基本的英文字符和控制字符,Unicode 意在包括世界上所有的字符,包括字母、符号、表情符号(emoji)等。 在 Unicode 标准中,每个字符都有一个唯一的标识符,通常称为代码点(Code Point)。这些代码点是用整数表示的,一般用十六进制的形式来展示。例如,英文字母 "A" 的 Unicode 代码点是 U+0041,而中文字符 "中" 的 Unicode 代码点是 U+4E2D。 散列值一般用于描述数据结构中用于快速查找的数值标识,但在这里(Rust 的 char 类型存的是 Unicode "散列值"),这种说法不太准确。实际上,Rust 的 char 类型存储的是 Unicode 代码点。 老师可以解答一下吗
2023-10-24 - 独钓寒江 👍(1) 💬(2)
可以说说GNU 工具链的版本 和 MSVC 工具链的版本 有什么区别吗? 应该怎么选择呢?
2024-02-29 - weineel 👍(1) 💬(1)
老师好 版次是什么? 为什么要 3 年发布一次? 和版本有什么区别?
2023-11-29 - J² 👍(1) 💬(1)
工作之余,正在艰难抽空学习rust,希望这次能坚持学完并且入门。
2023-11-07 - uyplayer 👍(1) 💬(2)
println!("Hello World! this is first commit in Rust")
2023-10-23 - Geek_5c44aa 👍(0) 💬(1)
语音讲解是不是有问题?都在那段IDE介绍里循环播放
2024-08-15 - 独钓寒江 👍(0) 💬(2)
// 强行在字符串后面加个0,与C语言的字符串一致。 let byte_escape = "I'm saying hello.\0"; println!("{}", byte_escape); 以上的代码,按注释,我理解打印出来的结果是在字符串后显示一个0, 实际打印结果是“I'm saying hello.” 看了一下紧接着的参考文章 -- Tokens - The Rust Reference (rust-lang.org), \0代表Null, 那输出结果是正常的 可以多说一下“强行在字符串后面加个0”吗?
2024-03-06