10 分布式:实现集群化、多副本KV存储引擎
本课程为精品小课,不标配音频
你好,我是文强。
这节课我们将在前三节课基于 Raft 协议构建的集群的基础上,将第 6 课实现的单机 KV 存储扩展为集群化、多副本的 KV 存储引擎。
从技术上看,分布式系统都是基于多副本来实现数据的高可靠存储。因此接下来,我们先来看一下副本和我们前面构建的 Raft 集群的关系。
集群和副本
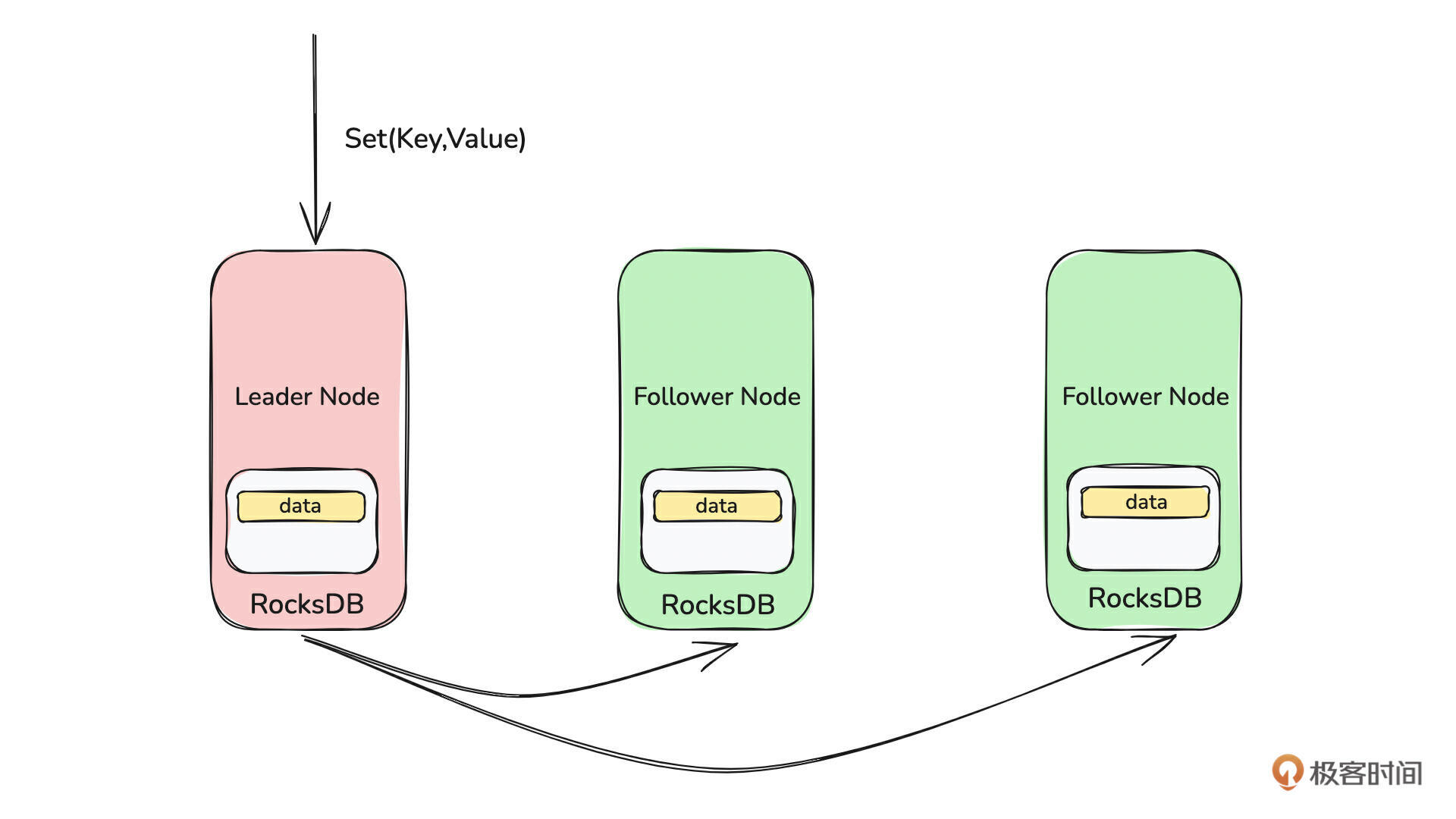
先来看下图:
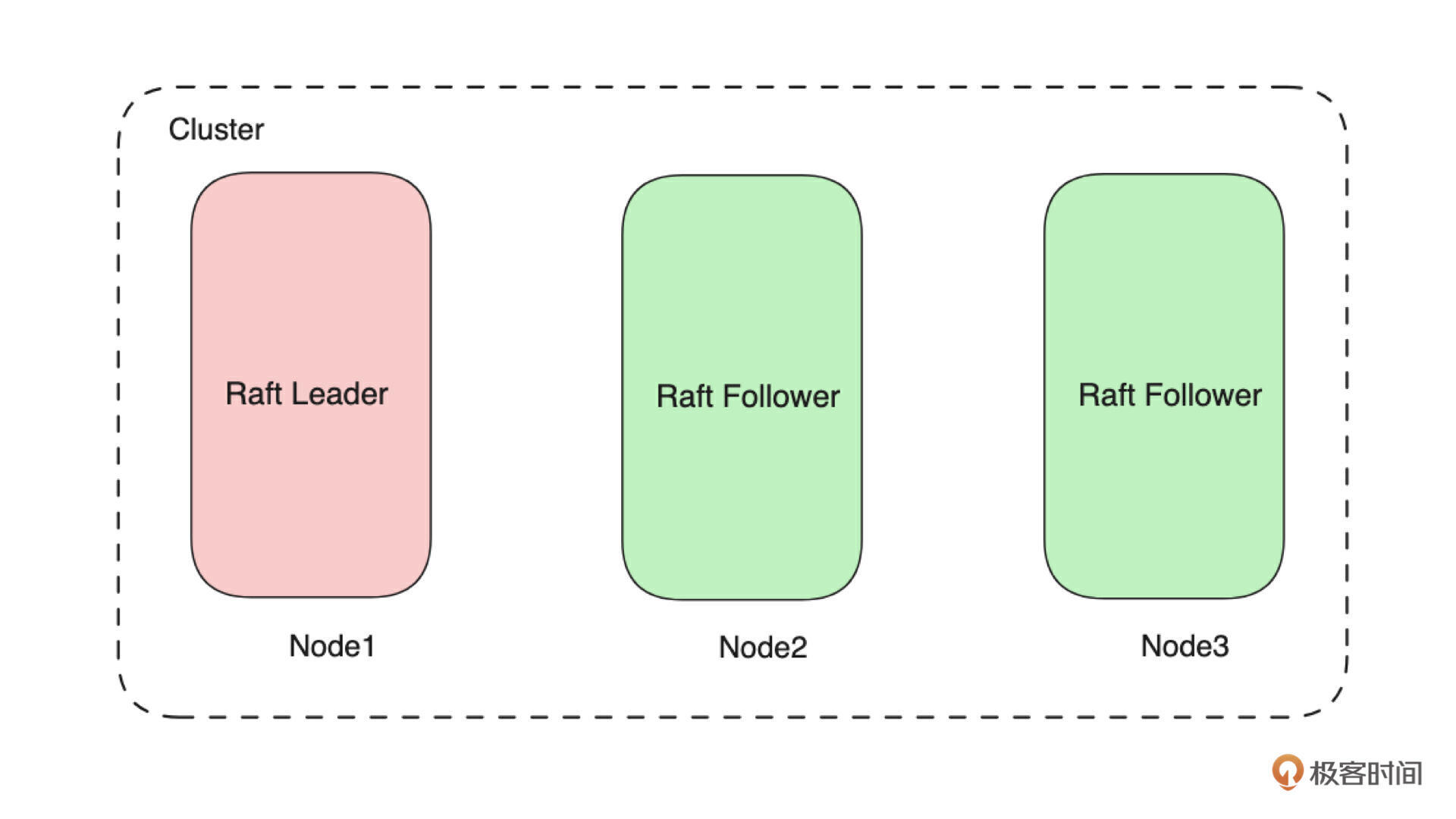
可以看到,这是一个由 3 个节点组成的、基于 Raft 协议构建的集群,它包含 1 个 Leader 节点和 2 个 Follower 节点。因此写入数据时,数据会先写入 Leader 节点,Leader 节点再将数据分发到两个 Follower 节点。
从技术上看这个集群只有一个 Raft 状态机,这个状态机由 3 个 Voter(Node)组成。所以整个集群只能有一个Leader,也就是在上图中一个节点就是一个副本。如下图所示,如果需要需要新增一个副本,就需要再增加一个节点。
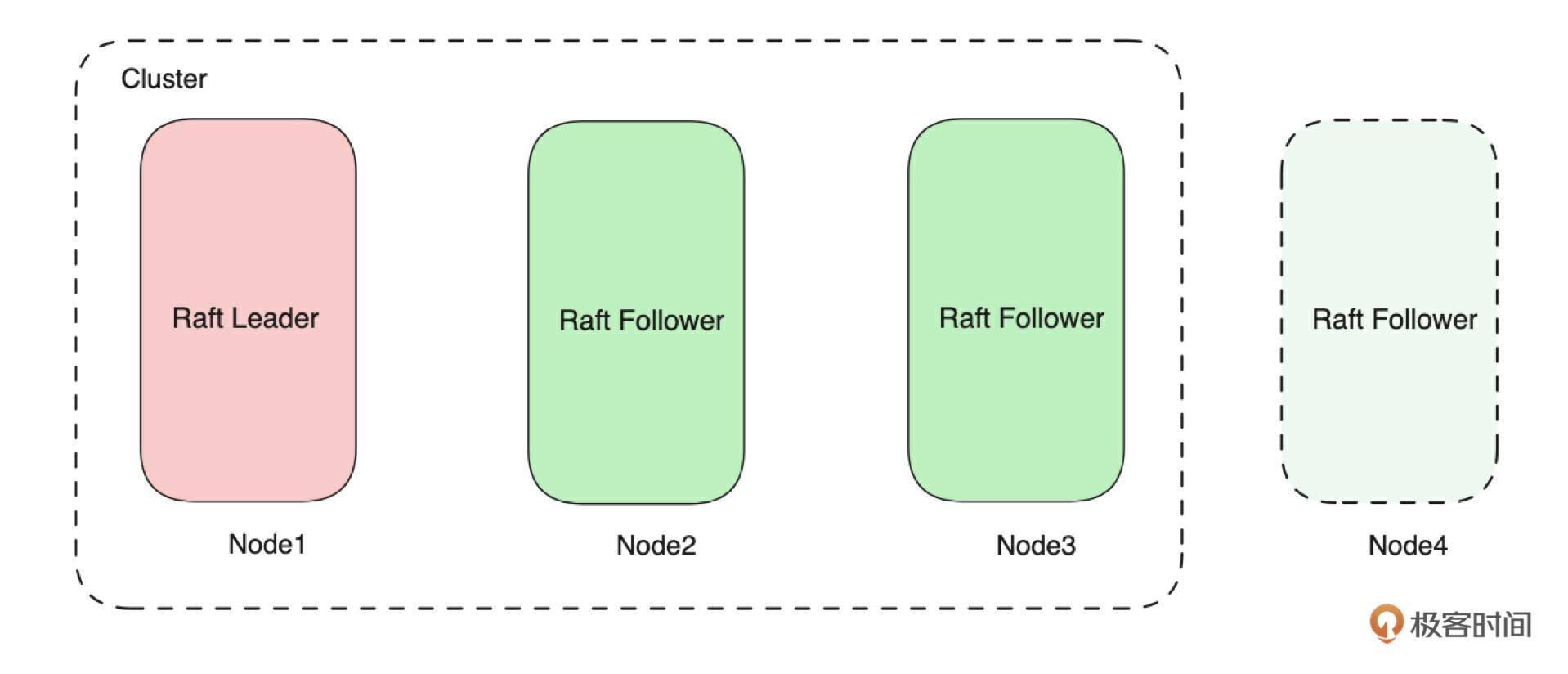
那么就会有一个问题:一个节点上能运行多个副本吗?答案肯定是可以的。来看下图:
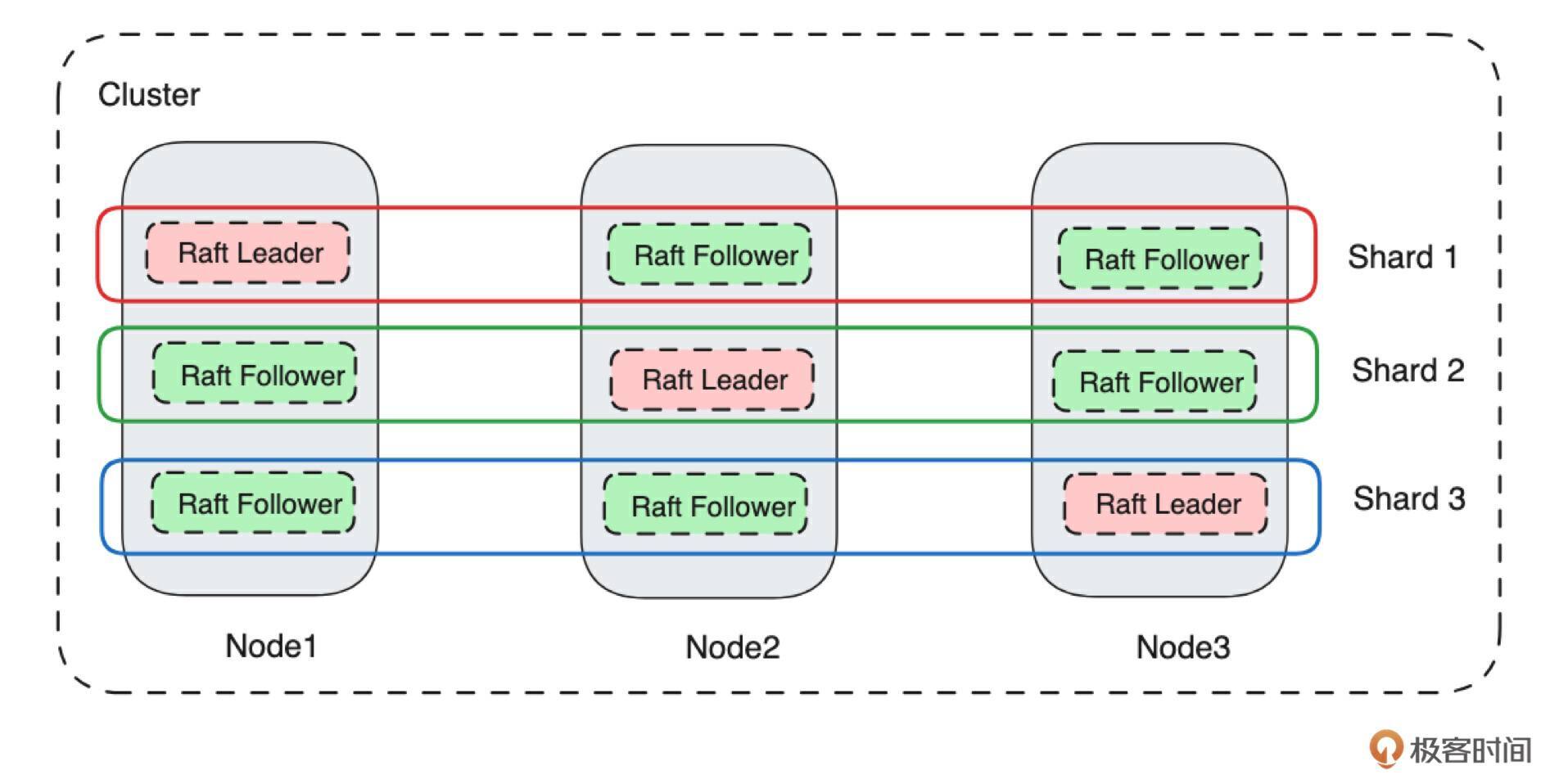
为了在一个节点上运行多个副本,我们首先抽象了 Shard(分片)的概念。从技术上看,一个 Shard 对应一个 Raft 状态机,也就是说每个 Shard 都有自己的 Leader 和 Follower。上图中有 3 个 Shard,每个 Shard 有 1 个 Leader、2个 Follower。因此总共有 3 个Leader及其对应的 6 个 Follower。同一个 Shard 对应的 Leader 和 Follower 都分布在不同的节点上。这是因为副本是为了容灾而存在的,因此同一个 Shard 的不同副本在同一个物理节点上是没有意义的。
所以说,如果要在一个节点上运行多个副本,那么就需要集群中有多组副本,也就是说一个集群需要运行多个状态机,也就是我们前面提到的状态机组(比如Raft Group)。
tips: 在本次课程中,我们只会实现一个集群只有一个状态机的模式,如果你需要了解状态机组的实现,我们可以在交流群中讨论。
了解了副本和集群的关系后,接下来我们来看一下,如何将单机的 KV 存储扩展为集群化、多副本的 KV 存储,在开发上需要做哪些事情。
从技术上看,主要有下面三部分的工作:
- 网络层:即客户端通过该网络层往集群读写 KV 数据。
- 一致性协议:集群会通过一致性协议(Raft)在 Leader、Follower 节点之间同步数据。从实现上看,这部分是指网络层、状态机、存储层三部分的交互。
- 存储层:单机维度基于 RocksDB 实现数据的持久化存储。
在第 6 课我们其实已经完成了基于 RocksDB 的存储层的开发。接下来我们来实现网络层和一致性协议这两个部分的开发。
先来看网络层的实现。
网络层的实现
我们依旧基于 gRPC 来构建我们的网络层,先来看 proto 的定义。
syntax = "proto3";
package kv;
service KvService {
rpc set(SetRequest) returns(CommonReply){}
rpc delete(DeleteRequest) returns(CommonReply){}
rpc get(GetRequest) returns(GetReply){}
rpc exists(ExistsRequest) returns(ExistsReply){}
}
message SetRequest{
string key = 1;
string value = 2;
}
message GetRequest{
string key = 1;
}
message GetReply{
string value = 1;
}
message DeleteRequest{
string key = 1;
}
message ExistsRequest{
string key = 1;
}
message ExistsReply{
bool flag = 1;
}
message CommonReply{
}
在上面的 proto 中,可以看到,我们定义了 set/get/delete/exists 四个方法及其对应的请求和返回参数,分别对应存储层 KvStorage 里面的 set/get/delete/exists 四个操作。
接下来以 Set 方法举例,看一下 gRPC Service 部分代码的实现。
async fn set(&self, request: Request<SetRequest>) -> Result<Response<CommonReply>, Status> {
let req = request.into_inner();
// 参数校验
if req.key.is_empty() || req.value.is_empty() {
return Err(Status::cancelled(
CommonError::ParameterCannotBeNull("key or value".to_string()).to_string(),
));
}
// 构建StorageData类型的数据
let data = StorageData::new(StorageDataType::KvSet, SetRequest::encode_to_vec(&req));
// 将数据交给 Raft 状态机处理
match self
.placement_center_storage
.apply_propose_message(data, "set".to_string())
.await
{
Ok(_) => return Ok(Response::new(CommonReply::default())),
Err(e) => {
return Err(Status::cancelled(e.to_string()));
}
}
}
这段代码很简单,获取请求参数,判断参数是否为空,构建StorageData类型的数据。然后通过apply_propose_message 方法将 KV 数据传给 Raft 状态机处理,并等待 Raft 状态机的处理结果。
如下所示,StorageData 是一个自定义的数据结构,用来在网络层和状态机之间交互。data_type 表示这是一个什么类型的操作,比如 Kv 的 Set 或 Delete 操作,value 表示具体的数据内容。
在上面的代码中,你可以看到,当网络层收到请求后,是通过调用 apply_propose_message 方法来将消息传递给 Raft 状态机,通过状态机内部的一致性协议来实现数据持久化存储的。
所以接下来,我们来看 apply_propose_message 方法内部的实现,也就是网络层和状态机的交互过程。
网络层和状态机的交互
先来看一张图,这张图是我们在上节课讲到的网络层通过 Tokio Channel 和状态机进行交互的示意图。
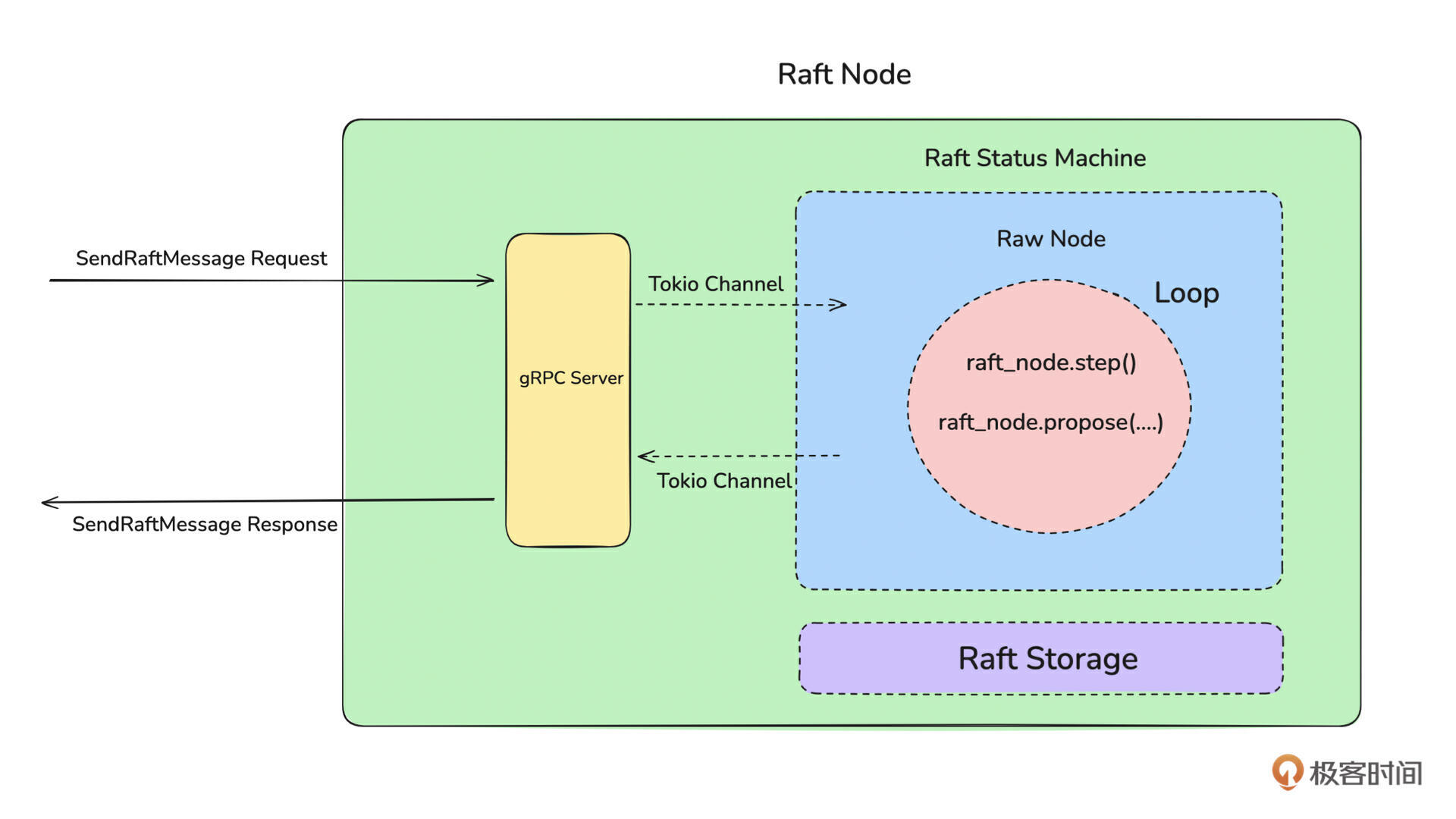
整个交互过程可以分为请求和返回两步,先来看请求。
请求是指网络层将 KV 数据传递给 Raft 状态机处理的过程。从技术上看,它是通过 tokio 的 mpsc 类型的 channel 来完成的。
具体流程是:首先初始化一个 mpsc 类型的 channel。
网络层使用 send(tokio::sync::mpsc::Sender)方法将数据传递给 channel。RawNode 使用 recv(tokio::sync::mpsc::Receiver)接收从网络层传递过来的数据(比如用户写入的数据),并驱动 Raft 运行。
再来看返回。
返回是指 Raft 状态机处理数据成功或失败后,通知网络层处理结果的过程。从技术上看,这个过程是通过一个 oneshot 类型的 channel 来实现的。如下所示:
网络层会调用 oneshot 的 recv 方法接收状态机的运行结果,状态机会将处理结果写入到 sender 中,从而完成交互。
接下来来看整个过程的核心代码段的实现,完整代码请参考《apply.rs》。
pub async fn apply_propose_message(
&self,
data: StorageData,
action: String,
) -> Result<(), CommonError> {
// 定义oneshot channel,用于接收 raft 状态机的返回
let (sx, rx) = oneshot::channel::<RaftResponseMesage>();
// 将数据传给 Raft 状态机处理,比等待 raft 状态机的处理结果
return Ok(self
.apply_raft_status_machine_message(
RaftMessage::Propose {
data: serialize(&data).unwrap(),
chan: sx,
},
action,
rx,
)
.await?);
}
async fn apply_raft_status_machine_message(
&self,
message: RaftMessage,
action: String,
rx: Receiver<RaftResponseMesage>,
) -> Result<(), RobustMQError> {
// 将消息发送给状态机,状态机向前驱动时会处理该消息
let _ = self.raft_status_machine_sender.send(message).await;
// 等待状态机对该消息的处理结果,比如成功或者失败
if !self.wait_recv_chan_resp(rx).await {
return Err(RobustMQError::RaftLogCommitTimeout(action));
}
return Ok(());
}
async fn wait_recv_chan_resp(&self, rx: Receiver<RaftResponseMesage>) -> bool {
// 定义状态机处理消息的最长时间,如果超过 30s 消息没处理成功,就表示写入失败
let res = timeout(Duration::from_secs(30), async {
match rx.await {
Ok(val) => {
return val;
}
Err(_) => {
return RaftResponseMesage::Fail;
}
}
});
// 等待状态机的处理结果
match res.await {
Ok(_) => return true,
Err(_) => {
return false;
}
}
}
可以看到,上面代码有apply_propose_message、apply_raft_status_machine_message、wait_recv_chan_resp 三个方法,它们的主要功能是:
- apply_propose_message:在网络层存储数据时调用,用于保存用户从客户端写入的数据。
- apply_raft_status_machine_message:给 apply_propose_message 方法调用,主要完成将数据发送给 Raft 状态机处理,并等待 Raft 状态机的处理结果,这两个事情。
- wait_recv_chan_resp:给 apply_raft_status_machine_message 调用,通过 timeout 和 oneshot 等待 Raft 状态机的处理结果。
那状态机是如何处理数据的呢?这个答案你去回顾第 9 课就知道了,这里不再重复讲了。
不知道你注意到没有,我们在第 9 课中是没有讲状态机是如何处理业务数据的。比如我们写了一个 KV 数据到集群,此时状态机是如何持久化存储这条KV数据的呢?
tips:这里说的 KV 数据是指客户端写入的数据,不是 Raft 自身运行产生的 Raft Log。这两类数据的区别你可以去回顾一下第7、8、9 这三节课。
接下来,我们就来看一下状态机是如何存储这些业务数据的。
状态机和存储层的交互
直接来看代码,完整代码在《machine.rs》中,状态机和存储层的交互我们只要关注 handle_committed_entries 方法就可以了,来看下面这段代码:
fn handle_committed_entries(
&mut self,
raft_node: &mut RawNode<RaftRocksDBStorage>,
entrys: Vec<Entry>,
) {
let data_route = self.data_route.write().unwrap();
// 循环处理 Entry
for entry in entrys {
// 如果 Entry 的 data 为空,就不需要处理
if !entry.data.is_empty() {
info!("ready entrys entry type:{:?}", entry.get_entry_type());
// 根据不同raft-rs 库定义的不同的消息类型,进行不同的逻辑处理
// 在 raft-rs 库中,主要分为分为EntryNormal和EntryConfChange两种类型的消息。
// EntryNormal 表示客户业务消息
// EntryConfChange 表示 Raft 集群内的消息,比如节点的上线下线
match entry.get_entry_type() {
EntryType::EntryNormal => {
// 用户的消息数据直接通过 DataRoute 方法进行分发处理
match data_route.route(entry.get_data().to_vec()) {
Ok(_) => {}
Err(err) => {
error!("{}", err);
}
}
}
EntryType::EntryConfChange => {
let change = ConfChange::decode(entry.get_data())
.map_err(|e| tonic::Status::invalid_argument(e.to_string()))
.unwrap();
let id = change.get_node_id();
let change_type = change.get_change_type();
match change_type {
// 处理增加节点的消息
ConfChangeType::AddNode => {
match deserialize::<BrokerNode>(change.get_context()) {
Ok(node) => {
let mut cls = self.placement_cluster.write().unwrap();
cls.add_peer(id, node);
}
Err(e) => {
error!("Failed to parse Node data from context with error message {:?}", e);
}
}
}
// 处理节点移除的消息
ConfChangeType::RemoveNode => {
let mut cls = self.placement_cluster.write().unwrap();
cls.remove_peer(id);
}
_ => unimplemented!(),
}
if let Ok(cs) = raft_node.apply_conf_change(&change) {
let _ = raft_node.mut_store().set_conf_state(cs);
}
}
EntryType::EntryConfChangeV2 => {}
}
}
// 消息处理成功后提交更新最新的 commit index
let idx: u64 = entry.get_index();
let _ = raft_node.mut_store().commmit_index(idx);
// 通过上面提到的 oneshot channel 通知网络层消息处理成功
match deserialize(entry.get_context()) {
Ok(seq) => match self.resp_channel.remove(&seq) {
Some(chan) => match chan.send(RaftResponseMesage::Success) {
Ok(_) => {}
Err(_) => {
error!("commit entry Fails to return data to chan. chan may have been closed");
}
},
None => {}
},
Err(_) => {}
}
}
}
参考代码的注释,我们可以知道,handle_committed_entries 中是状态机和存储层交互的入口方法,它的核心逻辑是:处理状态机中已经可以被 commit 的 Entry。
从 Raft 协议可以知道,当业务数据提交给 Raft Leader 节点处理时,此时这个消息还没分发给 Follower,因此这个消息是 uncommit 的消息,也就是 uncommit 的 Entry。只有当集群中超过半数的节点处理成功后,这个消息才会变为 commit 的 Entry。
handle_committed_entries 会拿到可以被 commit 的 Entry。拿到消息后,就需要遍历处理这些消息,这些消息分为客户端写入的消息和 Raft 本身产生的消息两种类型,这两种消息有不同的处理逻辑。
这里我们只讲如何处理客户端写入的消息,Raft 本身产生的消息的处理你可以直接看一下代码,比较简单,有需要的话我们交流群中讨论。
在上面代码中,可以看到客户端写入的消息是由 data_route.route(entry.get_data().to_vec()) 来处理的。DataRoute 的代码如下:
pub struct DataRoute {
rocksdb_engine_handler: Arc<RocksDBEngine>,
}
impl DataRoute {
pub fn new(rocksdb_engine_handler: Arc<RocksDBEngine>) -> DataRoute {
return DataRoute {
rocksdb_engine_handler,
};
}
pub fn route(&self, data: Vec<u8>) -> Result<(), RobustMQError> {
let storage_data: StorageData = deserialize(data.as_ref()).unwrap();
match storage_data.data_type {
StorageDataType::KvSet => {
// 调用KvStorage的 set 方法持久化存储数据
let kv_storage = KvStorage::new(self.rocksdb_engine_handler.clone());
let req: SetRequest = SetRequest::decode(data.as_ref()).unwrap();
return kv_storage.set(req.key, req.value);
}
StorageDataType::KvDelete => {
// 调用KvStorage的 delete 方法删除持久化的数据
let kv_storage = KvStorage::new(self.rocksdb_engine_handler.clone());
let req: DeleteRequest = DeleteRequest::decode(data.as_ref()).unwrap();
return kv_storage.delete(req.key);
}
}
}
}
这段代码很简单,就是根据前面提到的结构体 StorageData 中的 data_type 来区分不同的数据类型,然后调用在第 6 课创建的 KvStorage 对象中的对应的方法来持久化存储数据。
讲到这里,我们就完成了集群化、多副本 KV 存储引擎的开发,接下来我们来总结并展示一下效果。
效果展示
先来看一张全流程示意图:
如上图所示:
- 使用 gRPC 客户端调用名为 Set 的 RPC 方法,往集群的 Leader 节点写入 KV 数据。
- Leader 节点收到数据后,通过 apply_propose_message 方法将消息传递给 Raft 状态机进行处理。
- Raft 状态机根据 Raft 协议的规范将消息分发到多台 Follower 节点。
- 当超过半数的 Raft Node 收到消息后,就可以 commit 这个 Entry。
- 当有可以 commit 的 Entry 后,Raft 状态机会调用 handle_committed_entries 方法,handle_committed_entries 再调用 DataRoute 的 route 方法来完成数据的持久化存储。
最后来写个Set 方法的测试用例,演示一下如何将数据存储到集群中。
#[cfg(test)]
mod tests {
use std::net::TcpStream;
use axum::http::request;
use protocol::kv::{
kv_service_client::KvServiceClient, DeleteRequest, ExistsReply, ExistsRequest, GetRequest,
SetRequest,
};
#[tokio::test]
async fn kv_test() {
let mut client = KvServiceClient::connect("http://127.0.0.1:8871")
.await
.unwrap();
let key = "mq".to_string();
let value = "robustmq".to_string();
let request = tonic::Request::new(SetRequest {
key: key.clone(),
value: value.clone(),
});
let _ = client.set(request).await.unwrap();
}
}
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课,我们把第 3~9 课的内容全部串起来了,主要把第 5 课基于 gRPC 的网络层、第 6 课基于 RocksDB 的存储层,第 7、8、9 课基于 Raft 协议的集群串联起来,完成了单机 KV 存储到分布式、集群化、多副本的KV 存储的演进。
从技术上来看,演进的核心就是我们在 7、8、9 课中基于 Raft 构建的分布式集群。从这一点也可以知道,为什么我们总会看到一个论点:分布式的核心是一致性协议。这是因为一致性协议决定了数据在集群中的流动、同步的方式。
这节课我们没有把所有的代码都贴上来,所以建议你多去看看《robustmq-geek》中的代码,多揣摩一下每段代码的实现,只要你能完整理解这节课的内容,那你就完成了这个课程的学习任务了。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看《Good First Issue》。另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!